




Pandas DataFrame:Milvusによるチャンキングとベクトル化
チャンクテキストとエンベッディングを含むすべてのデータをPandas DataFrameに格納すれば、Milvusベクトルデータベースに簡単に統合してインポートできる。
シリーズ全体を読む
- 検索拡張ジェネレーション(RAG)でAIアプリを構築する
- LLMの課題をマスターする:検索拡張世代の探求
- ディープラーニングにおける主要なNLPテクノロジー
- RAGアプリケーションの評価方法
- リランカーによるRAGの最適化:役割とトレードオフ
- マルチモーダル検索拡張世代(RAG)のフロンティアを探る
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- RAGパイプラインのパフォーマンスを高める方法
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- Pandas DataFrame:Milvusによるチャンキングとベクトル化
- Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
- 検索拡張世代(RAG)のためのチャンキング戦略ガイド
- 仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
- Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
- RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
チャンクテキストと埋め込みを含むすべてのデータをPandas DataFrameに格納すれば、Milvusベクトルデータベースに簡単に統合してインポートできる。
チャンキングまたはテキスト分割は、長いテキストを "チャンク "と呼ばれるいくつかの小さな断片に分割するデータ前処理ステップです。この方法は、LLMsの強力な性能をフルに活用したり、テキストデータで様々なカスタム分析ソリューションを実行したい場合、今日の世界でますます関連性が高まっている。
この記事では、チャンキングの概念と、自然言語処理 (NLP)におけるその完全な意味と重要性に飛び込み、チャンクを作成するさまざまな方法の例を紹介します。
チャンキングの重要性
自然言語処理プロジェクトを扱うとき、データは通常生のテキストの形で送られてきます。これらの生のテキストは、文章、段落、あるいは本の一部分を表すこともあります。
テキストデータが短い文章だけであれば、チャンキングは必要ありません。しかし、テキストデータが個々の文、複数の文、複数の段落、本の一部分を表す場合、チャンキングは重要なステップとなります。これにはいくつかの理由がある。
機械学習モデルには最大トークン長がある
機械学習モデルは生のテキストを理解することができないため、モデルが理解できる形式に変換する必要がある。
これを行う標準的な方法は、トークン化と呼ばれるプロセスを通じて、生のテキストを数値表現に変換することである。入力テキストはトークンの列にトークン化され、各トークンの整数マッピングに変換される。
画像は著者による](https://assets.zilliz.com/Image_by_author_5b377970c5.png)
問題は、ディープラーニング・モデルが扱えるトークン長には一定の限界があることだ。例えば、BERTが扱えるトークンの長さは最大512である。トークンのシーケンスがそれよりも長い場合、BERTはシーケンスを自動的に切り捨てますが、これは私たちが望まないことです。
テキストをより小さなセグメントにチャンクすることで、トークン化された入力がディープラーニング・モデルの最大トークン長の制限内に収まるようにすることができる。
情報検索の場合
1つのテキストデータが1冊の本を表しているようなユースケースを想像してみよう。クエリーがあり、その本から最も関連性の高いコンテンツを取得したい場合、そこから効率的に情報を取得する方法を見つける必要がある。
その一つの方法が、データのセグメンテーション、つまりテキストを分割してチャンクを生成することである。各チャンクは、個々の文章、段落、あるいはセクションを表すことができる。テキスト分割の粒度が細かいほど、より具体的な情報を得ることができる。
また、テキストとチャンキング戦略は、RAGシナリオにおいて有益である。望ましいチャンクサイズを見つけることができれば、LLMがより正確な応答を生成するのに役立つ、関連性の高いコンテキストを得ることができる。
問題は、テキストのチャンキングは、特にコンテキストを保持するために微調整するのが非常に難しいということです。テキストデータを非常に細かいレベルにチャンクすると、あまり意味のない情報を得る危険性がある。一方、データを非常に広いレベルにチャンクすると、あまり具体的でない情報を得る可能性がある。したがって、チャンキング手法を適用する前に、データの性質を理解することが重要です。
チャンキング手法
チャンクを作成するために一般的に適用されるチャンキング手法には、固定サイズのチャンキングとコンテンツを考慮したチャンキングの2つがあります。それぞれのテクニックについて1つずつ説明します。
固定サイズ・チャンキング
固定サイズチャンキングとは、テキストを固定された同じサイズの小さなチャンクに分割するプロセスを指します。つまり、あらかじめチャンクサイズを定義しておき、テキストの各チャンクは定義済みの値と同じサイズになります。
オプションで、オーバーラップ値を定義することもできます。オーバーラップは、テキストの意味的な意味が2つの小さなチャンクの間で失われないようにするためのバッファとして機能します。
このテクニックは実装が最も簡単で、他のテクニックほど計算量が多くありません。
では、このテクニックを実装してみよう。バスケットボールについて書かれた次のテキストを考えてみよう。
text_input= ""
バスケットボールはチームスポーツであり、長方形のコートで2つのチーム(最も一般的なのは5人ずつ)が対戦し、相手チームが自陣のフープからシュートするのを防ぎながら、バスケットボール(直径約9.4インチ(24cm))を防御側のフープ(直径18インチ(46cm)のバスケットで、コートの両端にあるバックボードまで高さ10フィート(3.048m)取り付けられている)を通してシュートすることを主目的として競う。フィールドゴールは2点の価値があり、スリーポイントラインの後ろからでない限り、3点の価値がある。ファウルの後、タイムプレーは停止し、ファウルを受けたプレーヤーまたはテクニカルファウルを指定されたプレーヤーは、1点、2点または3点のフリースローを与えられる。試合終了時に得点の多いチームが勝利するが、同点のまま規定プレーが終了した場合は、延長戦が行われる。
プレーヤーは、歩いたり走ったりしながらボールをバウンドさせたり(ドリブル)、味方にパスしたりしてボールを進めるが、いずれもかなりの技術を要する。オフェンスでは、レイアップ、ジャンプシュート、ダンクなど、さまざまなシュートを使うことができる。ディフェンスでは、ドリブルをする相手からボールを盗んだり、パスをインターセプトしたり、シュートをブロックしたりすることができる。ボールをドリブルせずにピボットフットを持ち上げたり引きずったりすること、ボールを運ぶこと、両手でボールを持ってからドリブルを再開することは違反である。
"""
固定サイズのチャンク・テクニックを説明するために、このバスケットボールのテキストを3つの異なるサイズのチャンクに分割します:50文字、250文字、1000文字です。
Pythonのデータ処理ライブラリはたくさんあります。しかし、このデモではLangChainを使います。
from langchain_text_splitters import CharacterTextSplitter
for n in [50, 250, 500]:
print(f"-------------------------------")
text_splitter = CharacterTextSplitter(
chunk_size = n、
separator=""、
chunk_overlap=0、
length_function=len、
is_separator_regex=False、
)
chunk_text = text_splitter.split_text(text_input)
for i in range(3):
print(f "chunk {i}: {chunk_text[i]}")
"""
-------------------------------
チャンク0:バスケットボールはチームスポーツである。
チャンク 1: 5人ずつの一般的なチームが、1人のアノ選手と対戦する。
-------------------------------
チャンク0:バスケットボールはチームスポーツであり、長方形のコートで5人ずつの2チームが対戦し、バスケットボール(直径約9.4インチ(24cm))をフーに通してシュートすることを主目的に競い合う。
相手チームが自陣のフープにシュートを通さないようにしながら、フェンダーのフープ(コートの両端にあるバックボードに高さ10フィート(3.048m)の直径18インチ(46cm)のバスケットを取り付けたもの)を通してバスケットボール(直径約9.4インチ(24cm))をシュートすることを主目的に競う。フィールドゴールは2点の価値がある。
-------------------------------
チャンク0:バスケットボールはチームスポーツであり、長方形のコートで対 戦する2つのチーム(最も一般的には5人ずつ)が、相手チームが自陣のフープを通 してシュートするのを防ぎながら、バスケットボール(直径約9.4インチ (24cm))を防御側のフープ(直径18インチ(46cm)のバスケットで、コートの両端に あるバックボードまでの高さ10フィート(3.048m)に取り付けられている)を 通してシュートすることを第一の目的として競う。フィールドゴールは2点の価値がある。
ただし、スリーポイントラインの後方からの場合は3点となる。ファウルの後、タイムプレーは停止し、ファウルを受けたプレーヤーまたはテクニカルファウルを指定されたプレーヤーは、1点、2点または3点のフリースローを与えられる。試合終了時に得点の多いチームが勝利するが、同点のまま規定プレーが終了した場合は、延長戦が行われる。
プレーヤーは、歩いたり走ったりしながらボールをバウンドさせたり(ドリブル)、味方にパスしたりしてボールを前進させる。
"""
チャンクの長さの違いによる影響は、上記のテキスト・チャンキング出力から観察できる:
50文字:小さいチャンクの情報は非常に細かく、チャンクから意味のある情報を抽出するのは難しい。
250文字:各チャンクで多かれ少なかれ十分な情報を提供。
500文字:500文字:1つのチャンクでより詳細な情報を提供する。ただし、文脈に関係のないノイズの多い情報を得るリスクが高くなる。
一般的に、チャンクサイズが小さいテキストに含まれる情報は粒度が細かすぎるため、意味のある洞察を抽出することが難しく、チャンクサイズが大きいテキストは広すぎる傾向があるため、特定の情報を抽出することが難しい。
コンテンツを考慮したチャンキング
コンテンツ・アウェア・チャンキングは、チャンクサイズに対してより柔軟なアプローチを採用している。固定サイズのチャンキング手法とは異なり、ここでのチャンクサイズは入力パラメーターというよりむしろ出力パラメーターです。チャンクサイズは、実装されているコンテキストによって、分割されたテキストごとに異なる場合があります。
単純な方法は、カンマ、ピリオド、コロン、セミコロンなどの空白やマーカーに基づいてテキストを分割することです。入力タイプによっては、HTMLセクションやMarkdown小見出しに基づいてテキストを分割することもできます。
それでは、テキストの空白に基づいたテキスト分割を実装してみましょう:
text_splitter = CharacterTextSplitter(
chunk_size = 25、
separator="、
chunk_overlap=0、
length_function=len、
is_separator_regex=False、
)
chunk_text = text_splitter.split_text(text_input)
print(chunk_text[0])
"""
出力:
バスケットボールはチームである
"""
上記のコードでは、空白に基づくテキスト分割を実装しており、各チャンクには約25文字が含まれる。しかし、以前の固定サイズのチャンキング方法とは異なり、テキストは空白の間で分割され、隣接する単語が途中で切断されることはありません。
さらに高度なテキスト処理方法として、再帰的方法がある。この方法では、テキストを階層的に小さなセグメントに分割する。最初に最小チャンクサイズを定義する。次に、段落レベルなどの最も広いレベルでテキストを分割しようとする。段落レベルでの分割が最小チャンクサイズを満たさない場合は、さらに文レベルで分割し、次に空白レベルで分割し、最後に文字レベルで分割する。
テキスト構造に加えて、使用する埋め込みモデルに基づいてテキストを分割することもできる。前のセクションで述べたように、すべての深層学習モデルには、扱えるトークンのチャンクの長さが決まっている。埋め込みモデルとしてSentence Transformersのモデルを使用することを目的とする場合、そのモデルに適したトークン長に合わせてチャンクサイズを調整することができます。以下は、LangChain を使った実装方法です。
from langchain_text_splitters import SentenceTransformersTokenTextSplitter
splitter = SentenceTransformersTokenTextSplitter(chunk_overlap=0, model_name='sentence-transformers/all-mpnet-base-v2')
text_chunks = splitter.split_text(text=text_to_split)
テキストチャンキングの実装
さて、さまざまなチャンキング・テクニックを探ったところで、実装に移ろう。以下のnotebookを参考にしてください。
今回使用するデータは、Wikipediaから入手した大規模なテキストデータセットで、HuggingFace datasetからダウンロードできる。何十万ものテキストが利用可能ですが、このデモを書くために、バスケットボールについて議論しているテキストに焦点を当てます。
pip install datasets
import pymilvus
import pandas as pd
from pymilvus import MilvusClient
from pymilvus import (
ユーティリティ
FieldSchema, CollectionSchema, DataType、
Collection, AnnSearchRequest, RRFRanker, connections、
)
from langchain_text_splitters import CharacterTextSplitter
from datasets import load_dataset, Dataset
dataset = load_dataset(
"wikimedia/wikipedia", "20231101.ja", split="train", streaming=True
)
data = Dataset.from_dict({})
for i, entry in enumerate(dataset):
# 各エントリーは以下のカラムを持つ
# ['id', 'url', 'title', 'text'].
if entry["title"] =="Basketball":
data = data.add_item(エントリ)
if i == 30000:
ブレーク
# メモリを解放する
データセットを削除する
前のセクションで紹介したチャンキング戦略を試すこともできるが、ここでは、1つのチャンクが1つの段落を表すような、内容を考慮したチャンキング方法を実装することにする。そのためには、LangChainのCharacterTextSplitter()クラスのセパレーター引数に "n "を使う必要があります。
text_splitter = CharacterTextSplitter()
separator="\n"、
chunk_size = 10、
chunk_overlap=0、
length_function=len、
is_separator_regex=False、
)
chunk_text = [text_splitter.split_text(text) for text in data["text"]][0].
print(len(chunk_text))
"""
出力:196
"""

上の図からわかるように、各チャンクはトピック・センテンスまたはパラグラフを表している。チャンキングの結果、合計196個のチャンクができました。DataFame最適化のために、チャンクIDとテキストチャンクだけをPandasの中に入れてみましょう。
df = pd.DataFrame()
df["chunk_id"] = [i for i in range(len(chunk_text))].
df["text_chunk"] = chunk_text
テキストのベクトル化
さて、テキストをチャンクに分割したので、次のステップは各チャンクをエンベッディングに変換することです。
埋め込みは、テキストの数値表現であり、特定の次元のベクトルで構成されます。使用するモデルによって、2種類のベクトル埋め込みがあります:密なベクトルと疎なベクトルです。
密なベクトルは通常、OpenAIやSentence Transformersのような深層学習モデルによって生成される。密なベクトルには、テキストに関する豊富な情報がコンパクトな形で含まれており、それが "密な "という名前の由来となっている。
一方、スパースベクトルは通常、密なベクトルよりも次元が高く、その値のほとんどがゼロである。このベクトルは、BM25のようなBag-of-words法を用いたモデルによって生成されることが多い。さらに最近の進歩として、SPLADEと呼ばれるモデルを介して学習されたスパースベクトルが導入され、スパースベクトルにさらに文脈情報が追加されるようになった。
画像は著者による](https://assets.zilliz.com/Image_by_author_2_1e14a65147.png)
チャンクをエンベッディングに変換した後、そのチャンクに対してテキスト解析、意味解析、ベクトル検索を行うことができる。
このデモでは、Sentence Transformersのall-MiniLM-L6-v2モデルを利用して、チャンクを高密度の埋め込みに変換します。このモデルは各チャンクに対して384次元の埋め込みを生成する。
Sentence Transformer modelとMilvusの統合は簡単です。MilvusのSentenceTransformerEmbeddingFunctionクラスを呼び出し、使用したいモデル名を指定するだけです。Sentence Transformersの利用可能なモデルのリストについては、そのドキュメントを参照してください。
from pymilvus import model
sentence_transformer_ef = model.dense.SentenceTransformerEmbeddingFunction(
model_name='all-MiniLM-L6-v2', # モデル名を指定する。
device='cpu' # 'cpu'や'cuda:0'など、使用するデバイスを指定する。
)
各チャンクを埋め込みに変換するには、 encode_documents() メソッドを使うことができる。
chunk_text = df["text_chunk"].values.tolist()
chunk_embeddings = sentence_transformer_ef.encode_documents(chunk_text)
df["chunk_embeddings"] = chunk_embeddings
print(chunk_embeddings[0])
"""
出力
[3.87127437e-02 6.21908298e-03 -2.17081346e-02 -7.02043846e-02
4.95888777e-02 2.59143058e-02 3.53455357e-02 -1.74768399e-02
.............................................................
.............................................................
-2.22174134e-02 2.56354176e-02 3.62051129e-02 -7.05866441e-02
2.83311424e-03 6.06332906e-02 2.30652522e-02 -2.65785996e-02]である。
"""
これで完成だ。これですべてのチャンクと埋め込みをベクターデータベースにインポートできる。
Milvus データベース統合とセマンティック検索
今あるのは、各チャンクのテキスト、ID、エンベッディングをカラムとして持つPandas DataFrameです。データがPandas DataFrameに整理されていれば、簡単な方法でMilvusデータベースにインポートすることができます。
Collectionクラスのconstruct_from_dataframe()` メソッドを使用することで、Pandas DataFrame内のデータをデータベースにインポートすることができます。必要なことは、コレクションの名前とプライマリフィールドを指定し、DataFrame 自体を提供することだけです。
connections.connect("default", host="localhost", port="19530")
col, results = Collection.construct_from_dataframe(
name="chunk_demo"、
primary_field="chunk_id"、
dataframe=df、
)
dense_index = {"index_type":"FLAT", "metric_type":"COSINE"}(コサイン
col.create_index("chunk_embeddings", dense_index)
col.flush()
上記のコードでは、ベクトル検索時に高速かつ簡単に検索できるように、チャンク埋め込み用のインデックスも作成している。後の意味的類似性検索に使用する距離メトリックはcosine similarityです。
さて、データをデータベースにインポートしたので、それを使って様々なタスクを実行することができる。中でも意味的類似度は最もポピュラーである。このタスクでは、下の可視化図に示すように、特定のクエリに基づいてデータベース内の最も類似したアイテムを検索する:
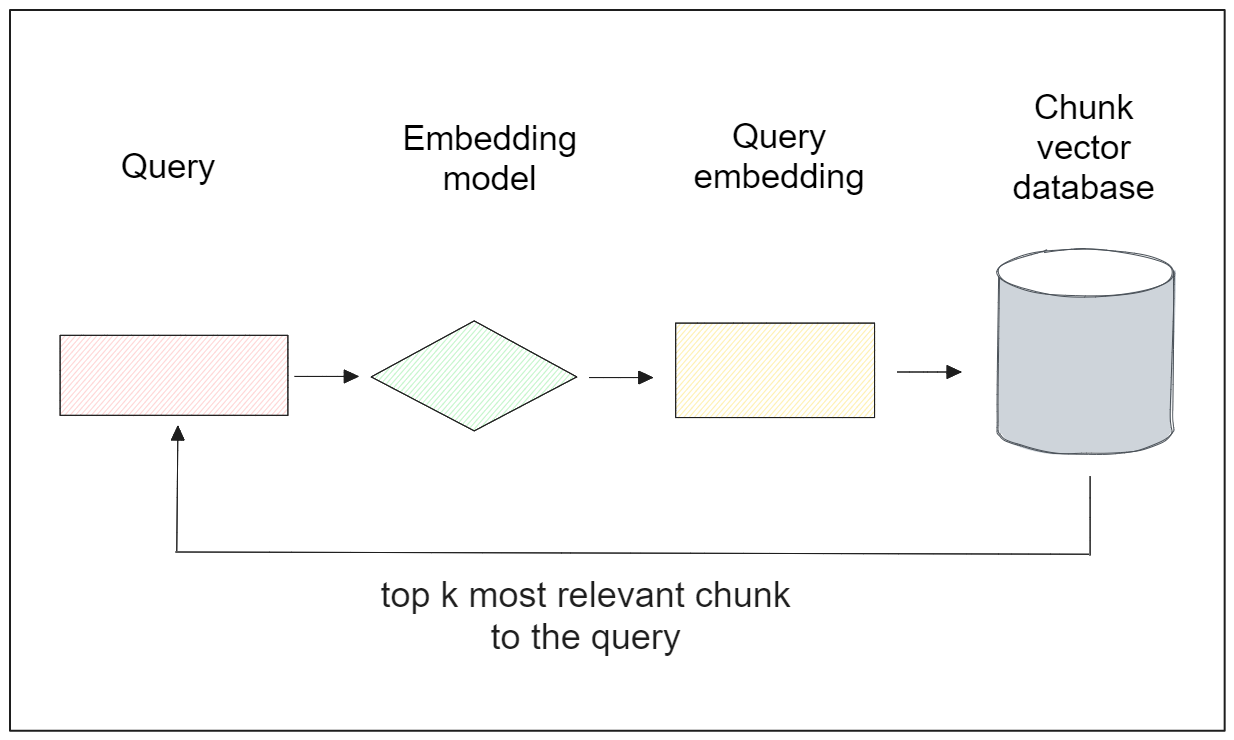
次のようなクエリがあるとしよう:"バスケットボールの歴史の中で最も偉大な選手は誰ですか?" そして、このクエリに対応する関連する段落を取得したいとします。これを実現するには、Sentence Transformersモデルを使ってクエリをベクトル埋め込みに変換する必要があります。Milvusでは、encode_queries()メソッドでこれを簡単に行うことができます。
ベクトル検索を行うには、 MilvusClient() クラスの search() メソッドを利用し、コレクション名、クエリ埋め込み、ベクトルデータベース内のターゲットカラム、出力フィールドなどの引数を指定します。
# Milvus クライアントのセットアップ
client = MilvusClient(
uri="<http://localhost:19530>"
)
コレクション = コレクション("chunk_demo")
コレクション.load()
query = "バスケットボール史上最も偉大な選手は誰ですか?"
query_vector = sentence_transformer_ef.encode_queries([query])
res = client.search(
コレクション名="chunk_demo"、
data=query_vector、
anns_field="chunk_embeddings"、
limit=1、
search_params={"metric_type":"COSINE", "params":{}},
output_fields =["text_chunk"])
)
print(res)
"""
出力:
[[{'id': 25, 'distance':0.695060670375824, 'entity':{'text_chunk':'NBAには、最初の圧倒的な「ビッグマン」であるジョージ・ミカン、ボールハンドリングの魔術師ボブ・クーシー、ボストン・セルティックスのディフェンスの天才ビル・ラッセル、元々ハーレム・グロベトロッターズで活躍したカリスマセンター、ウィルト・チェンバレン、万能スター、オスカー・ロバートソン、ジェリー・ウェストなど、多くの有名選手がいた;カリーム・アブドゥル・ジャバー、シャキール・オニール、ハキーム・オラジュウォン、カール・マローン、ジョン・ストックトン、アイザイア・トーマス、スティーブ・ナッシュ、ジュリアス・アーヴィング、チャールズ・バークレー;ヨーロッパのスター、ダーク・ノビツキー、パウ・ガソル、トニー・パーカー、ラテンアメリカのスター、マヌ・ジノビリ、最近のスーパースター、アレン・アイバーソン、コービー・ブライアント、ティム・ダンカン、レブロン・ジェームズ、ステファン・カリー、ジャンニス・アンテトクンポなど。そして、1980年代から1990年代にかけて、プロ野球の人気を最高レベルにまで押し上げたと多くの人が評価している3人の選手たち:ラリー・バード、アービン・マジック・ジョンソン、マイケル・ジョーダンだ。]
"""
ご覧のように、このクエリ結果は、過去から現在までの有名なNBA選手数名の名前に言及しているため、関連性が非常に高い。
では、別のクエリで別の実験をしてみましょう。クエリが「誰がバスケットボールを発明したのか?先ほどと同じ方法で、以下のような回答が得られました。
query = "誰がバスケットボールを発明したのか?"
query_vector = sentence_transformer_ef.encode_queries([query])
res = client.search(
コレクション名="chunk_demo"、
data=query_vector、
anns_field="chunk_embeddings"、
limit=1、
search_params={"metric_type":"COSINE", "params":{}},
output_fields =["text_chunk"])
)
print(res)
"""
出力:
[[{'id': 8, 'distance':0.5980502963066101, 'entity':{'text_chunk': 'バスケットボールはもともとサッカーボールでプレーされていた。当時、"アソシエーション・フットボール "の丸いボールは、ボールカバーの縫い合わされた他の部分を外側に反転させた後、膨張式ブラダーを挿入するために必要な穴を塞ぐために、一組の紐で作られていた。この紐のせいで、バウンドパスやドリブルが予測できないことがあった。最終的に、ひもを使わないボール構造が発明され、このゲームへの変更はネイスミスによって支持された(一方、アメリカンフットボールでは、ひも構造はグリップに有利であることが証明され、今日に至っている)。バスケットボール専用に作られた最初のボールは茶色で、1950年代後半になってようやく、選手にも観客にも見やすいボールを探していたトニー・ヒンクルが、現在一般的に使われているオレンジ色のボールを発表した。ドリブルは、チームメイトへの "バウンドパス "を除けば、オリジナルのゲームにはなかった。パスがボールを動かす主な手段だった。ドリブルは最終的に導入されたが、初期のボールの形状が非対称であったため、制限されていた。1896年までにはドリブルは一般的になり、1898年にはダブルドリブルを禁止するルールが設けられた。]
"""
この回答自体はバスケットボールの起源を説明し、バスケットボールの発明者について言及しているが、私たちの質問には直接答えていない。その理由は、チャンクが長すぎて、多くの情報ノイズを含んでいるからです。この2つの実験から、クエリが詳細な回答を要求する場合は、チャンクが長い方が有益であることがわかります。しかし、クエリが非常にきめ細かい回答を要求する場合は、チャンクは短い方が望ましい。
チャンキングの考察
これまでのセクションで、セマンティック・チャンキングを行う際に特定のサイズを選択することの長所と短所をいくつか見てきました。残念ながら、適切なチャンクサイズを選択するのは非常に難しいことであり、すべての問題に対して普遍的な「ベスト」チャンクサイズは存在しません。そこでこのセクションでは、あなたのユースケースに応じて最適なセマンティックチャンキングサイズを決定するためのガイダンスを提供します。
データの種類とレスポンスに対する期待値を考慮してください。データに長いテキストが含まれ、長く、無傷で、詳細な回答が予想される場合は、より長いチャンクを選択する方がよいでしょう。逆に、より簡潔で詳細な回答を期待する場合は、短いチャンクの方がセマンティック・チャンキングには適しています。
モデルによってコンテキストの長さが異なるため、使用する埋め込みモデルを考慮に入れてください。例えば、BERTは最大512トークンを扱うことができますが、この記事で実装されている全MiniLM-L6-v2モデルは256トークンの制限があります。
ユーザーからの潜在的なクエリを考慮する。クエリーベクターは各チャンクベクターと比較されるため、クエリーが長くなると予想される場合は、より長いチャンクが良い出発点になるかもしれません。
結論
セマンティックチャンキングは自然言語処理でテキストデータを扱う際の重要なステップです。長いテキストをいくつかの小さなセグメントに分割し、より良い情報検索の結果と様々な埋め込みモデルのスムーズな実装を容易にする。すべてのユースケースに「最適な」セマンティックチャンキングとサイズは存在せず、ユースケースに応じて微調整する必要がある。
長いテキストがいくつかのチャンクになったら、それぞれのチャンクをディープラーニングモデルで埋め込みにベクトル化することができる。チャンクテキストとエンベッディングを含む全てのデータをPandasのDataFrameに格納すれば、Milvus vector databaseに簡単に統合してインポートできる。Milvus](https://milvus.io/)ベクトルデータベースを使えば、意味解析や意味類似性検索など、様々なNLPタスクを実行することができる。

読み続けて

ディープラーニングにおける主要なNLPテクノロジー
ディープラーニングにおける主要な自然言語処理(NLP)技術の根底にある進化と基本原理を探る。

仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
HyDE(Hypothetical Document Embeddings)は、LLMとRAGの回答を改善するために「偽」の文書を使用する検索手法である。

Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
Retrieval Augmented Generation (RAG)は、LLMの幻覚を軽減するための手法です。Milvus、Llama3、LlamaIndexを使ってチャットボットRAGを構築する方法を学びましょう。