




RAGアプリケーションの評価方法
RAG申請における効果的な評価戦略
シリーズ全体を読む
- 検索拡張ジェネレーション(RAG)でAIアプリを構築する
- LLMの課題をマスターする:検索拡張世代の探求
- ディープラーニングにおける主要なNLPテクノロジー
- RAGアプリケーションの評価方法
- リランカーによるRAGの最適化:役割とトレードオフ
- マルチモーダル検索拡張世代(RAG)のフロンティアを探る
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- RAGパイプラインのパフォーマンスを高める方法
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- Pandas DataFrame:Milvusによるチャンキングとベクトル化
- Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
- 検索拡張世代(RAG)のためのチャンキング戦略ガイド
- 仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
- Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
- RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
RAG(Retrieval Augmented Generation)アプリケーションの評価に関する比較分析で、相対的な有効性を判断するという課題に取り組んでいる。開発者がRAGアプリケーションのパフォーマンスを向上させるための定量的な指標を探る。
以前の記事では、RAGアプリケーションの基本的なフレームワークを簡単に紹介した。しかし、2つの異なる検索拡張世代アプリケーションを比較する場合、どちらが優れているかをどのように判断すればよいのだろうか?また、開発者にとって、RAGアプリケーションのパフォーマンスを定量的に向上させるにはどうすればよいのでしょうか?
RAGアプリケーションの性能を正確に評価することは、ユーザーと開発者の双方にとって極めて重要です。いくつかの例の単純な比較は、RAGアプリケーションの回答の品質ラグ性能を完全に測定するには不十分です。私たちは、RAGアプリケーションを定量的に評価するために、信頼性が高く、再現可能なメトリクスを必要としています。以下のセクションでは、ブラックボックスとホワイトボックスの両方の観点からRAGアプリケーションを評価することについて議論する。
RAGの評価はソフトウェアシステムのテストに例えることができる。RAGシステムの品質を評価するには、ブラックボックス評価とホワイトボックス評価の2つの方法があります。
ブラックボックス評価では、RAGアプリケーションの内部構造を見ることはできません。我々は、入力と出力の情報に基づいてRAGのパフォーマンスを評価することができます。一般的に、我々は3つの情報にアクセスすることができる:ユーザのクエリ、検索されたコンテキスト、RAGの応答。これらの3つの情報は、RAGアプリケーションの性能を評価するために使用される。このブラックボックスアプローチは、クローズドソースのRAGアプリケーションの評価に適したエンドツーエンドの評価方法である。
ホワイトボックス評価では、RAG アプリケーションのすべての内部プロセスを見ることができます。したがって、アプリケーションのパフォーマンスは、その中の主要なコンポーネントによって決定することができます。例えば、典型的なRAGアプリケーションのフローでは、主要な要素として、埋め込みモデル、リランクモデル、LLMがある。RAGアプリケーションの中には、多方向検索機能を持ち、用語頻度検索アルゴリズムを含むものもある。これらの主要なコンポーネントを交換したりアップグレードしたりすることで、RAGアプリケーションの性能を向上させることができる。このホワイトボックスアプローチは、オープンソースのRAGアプリケーションの評価や、カスタマイズされたRAGアプリケーションの改善に役立つ。
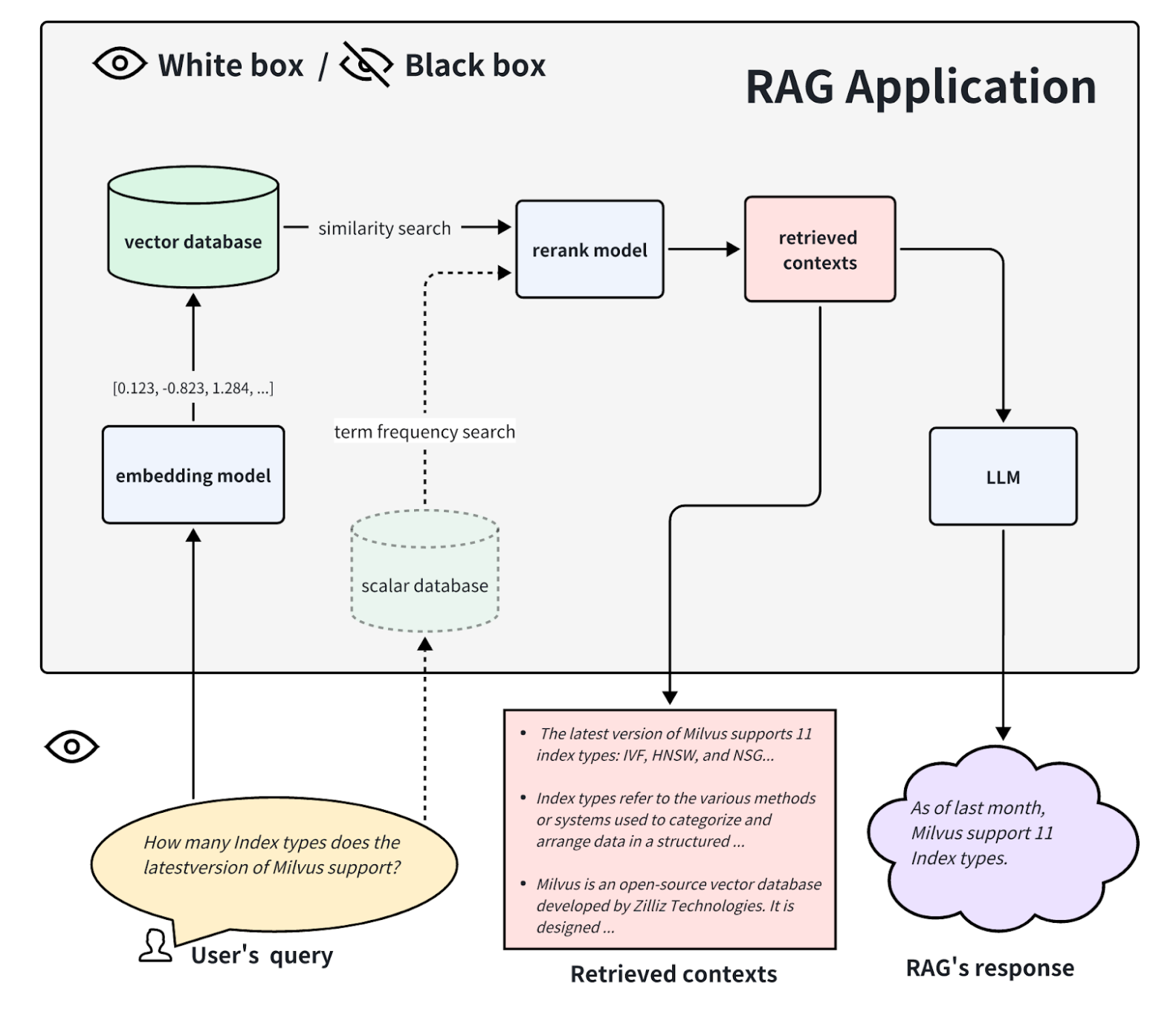 ホワイトボックスとブラックボックスの評価.png
ホワイトボックスとブラックボックスの評価.png
ブラックボックス評価
評価指標
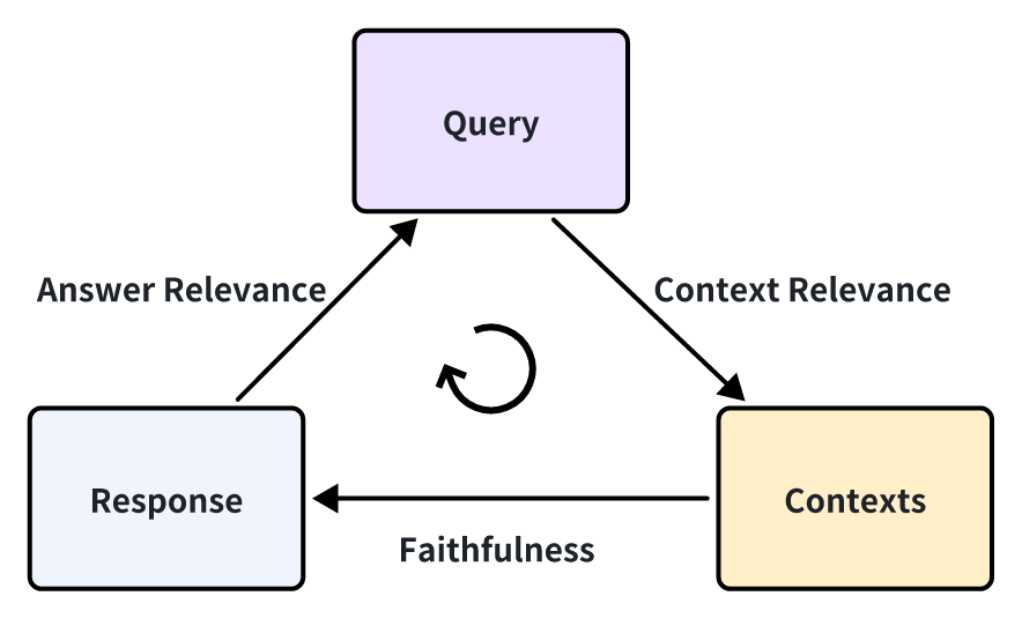
Retrieval Augmented Generation(RAG)アプリケーションをブラックボックスとして扱う場合、そのパフォーマンスを評価する能力は、ユーザーのクエリ、検索されたコンテキスト、およびRAGシステムによって生成された最終的な応答という3つの重要なコンポーネントの相互作用にかかっている。これら3つの要素は、RAG評価フレームワークの骨格を形成し、相互に深く依存している。RAGアプリケーションの有効性を評価するには、これらのコンポーネント間の相関関係を測定することが不可欠である。
RAGアプリケーションの評価には、これらのコンポーネントがどの程度うまく連動しているかを定量化するのに役立つ、いくつかの主要な評価指標が含まれます。これらの評価指標を綿密に分析することで、開発者はRAGシステムの長所と短所についての洞察を得ることができ、さらなる最適化と改善を導くことができます。 RAG Triad.png
{kind=link}
RAGの評価において、これらの3つの側面を評価するために、以下の評価指標を使用することができます:
コンテキストの関連性**:この評価指標は、検索されたコンテキスト(関連文書)がユーザーのクエリとどの程度一致しているかを評価する。関連性のないコンテンツや関連性の低いコンテンツは、最終的なアウトプットの質を低下させる可能性があるため、コンテキストの関連性が鍵となる。コンテキストの関連性のスコアが低いと、検索プロセスで、クエリを十分にサポートしない、またはクエリに関連しないコンテンツが表示されたことになり、その結果、LLMの回答が不正確になったり、トピックから外れたりする可能性があります。文脈関連性が高ければ、LLMは意味のある正確な回答を生成するために必要な情報を確実に得ることができます。
忠実性:忠実度:検索された関連文書に対する、生成された回答の事実上の一貫性を測定する。これは、回答が適切であるだけでなく、提供された情報に基づいて事実上正しいことを保証する重要な指標です。忠実度のスコアが低いと、LLMの出力と検索された文脈の間に不一致があることを示し、幻覚-もっともらしいが検索されたデータに基づかない回答-を生成するリスクが高まる。高い忠実度を維持することは、正確さと信頼性が最優先されるアプリケーションにとって不可欠である。
回答の関連性**:このメトリクスは、生成された回答がユーザーのクエリにどれだけ直接的かつ完全に対応しているかに焦点を当てる。LLMの回答の適切さを評価し、不完全であったり、冗長であったり、質問に適切に対応できていない回答には低いスコアが割り当てられます。回答の妥当性は、ユーザーが事実上正しいだけでなく、クエリに直接適用できる回答を受け取ることを保証するために重要であり、RAGシステムの全体的な有用性とユーザーの満足度を高めます。
これらの評価指標を体系的に評価することで、開発者はRAGの評価が優れている部分や不足している部分を特定することができます。これにより、検索方法の改良、チャンキング戦略の調整、LLMの応答生成機能の微調整など、的を絞った改善が可能になります。
回答の関連性を説明するために、次の例を考えてみましょう:
質問フランスはどこにあり、首都は?
関連性の低い答えフランスは西ヨーロッパにあります。
関連性の高い答えフランスは西ヨーロッパにあり、首都はパリです。
これらの指標を定量的に計算する方法
さて、「フランスは西ヨーロッパにある」という回答は、人間の事前知識に基づいて決定される「フランスはどこにあり、首都はどこか」という質問に対して関連性が低いと考えられることが理解できたと思いますが、この回答に対して定量的なスコアを0.2とし、別の回答を0.4とする方法はあるのでしょうか?また、0.4のスコアが0.2より優れていることを保証するにはどうすればよいでしょうか?
さらに、すべての回答を人間の採点に頼るには、かなりの量の手作業と、人間の採点者が学習し遵守するための特定のガイドラインを確立する必要があります。この方法は時間がかかり、現実的ではありません。採点プロセスを自動化する方法はあるのでしょうか?幸いなことに、GPT-4のような高度な言語モデル(LLM)は、人間のアノテーターに近い熟練度に達している。GPT-4は、定量的かつ客観的に解答を採点し、そのプロセスを自動化するという、前述の2つの要件を満たすことができます。
論文LLM-as-a-Judgeでは、著者はLLMを審査員として利用することを提案し、このコンセプトに基づいて多くの実験を行った。その結果、GPT-4のような優れたLLMジャッジは、コントロールされたクラウドソーシングによる人間の嗜好と密接に一致し、人間同士の一致レベルと同等の80%以上の一致を達成できることが明らかになった。したがって、LLM-as-a-judgeは、そうでなければコストのかかる人間の嗜好を近似するためのスケーラブルで説明可能なアプローチを提供する。
LLMと人間の評価者の間の80%の一致は、高いスコアではないと思うかもしれない。しかし、このような主観的な質問を評価する場合、たとえ指導を受けていたとしても、2人の人間が100%の一致を達成するとは限りません。したがって、GPT-4が人間との間で80%の一致を達成したという事実は、GPT-4が有能な判定者として十分に適格であることを示しています。GPT-4がどのように得点を割り当てるかについて、例として「回答の関連性」を考えてみましょう。GPT-4に関連する文書を質問するために、次のようなプロンプトを使用します:
既存の知識ベースのチャットボットアプリケーションがあります。このアプリケーションに質問をして、返答をもらいました。この回答は質問に対する良い回答だと思いますか?この回答を評価してください。スコアは0から10の間の整数でなければなりません。0はその回答が質問に全く答えていないことを意味し、10はその回答が質問に完璧に答えていることを意味します。
質問フランスはどこにあり、首都はどこですか?
回答フランスは西ヨーロッパにあり、首都はパリです。
GPT-4の回答
10
このように、上の例のように、あらかじめ適切なプロンプトのテンプレートを設計しておけば、質問と回答のペアを置き換えるだけで、すべての質問と回答のペアの評価を自動化することができる。したがって、プロンプトの設計は非常に重要である。上の例はあくまでもプロンプトのサンプルです。実際には、GPTによる公平で確実な採点を保証するために、プロンプトはしばしば長くなる。そのため、マルチショットや思考連鎖(CoT)のような高度なプロンプトエンジニアリング技術が必要となる。これらのプロンプトを設計する際には、コモン・ポジション・バイアスなどのLLMバイアスを考慮する必要がある場合がある。LLMはプロンプトが長い場合、最初の内容に注意を払い、途中の内容を見落とす傾向がある。
幸いなことに、RAGアプリケーションの評価ツールはすでによく統合されており、コミュニティは長期にわたってプロンプトの質をテストすることができるため、プロンプトのデザインに過度に気を配る必要はない。GPT-4のようなLLMにアクセスする際にAPIトークンを大量に消費することをもっと懸念すべきである。将来的には、信頼できるジャッジとして機能する、より費用対効果の高い、あるいはオンデバイスのLLMが登場することを期待したい。
グラウンドトゥルースにアノテーションを付ける必要があるか?
上記の例では、グランドトゥルース(ground-truth)を使っていないことにお気づきかもしれない。グランドトゥルースとは、質問に対応して人間が書いた標準的な回答のことである。例えば、RAGの解答の正確さを測定するために「解答の正しさ」メトリックを定義することができます。スコアリングメソッドはLLMスコアリングに基づいており、前述のAnswer Relevanceメトリックと同じです。
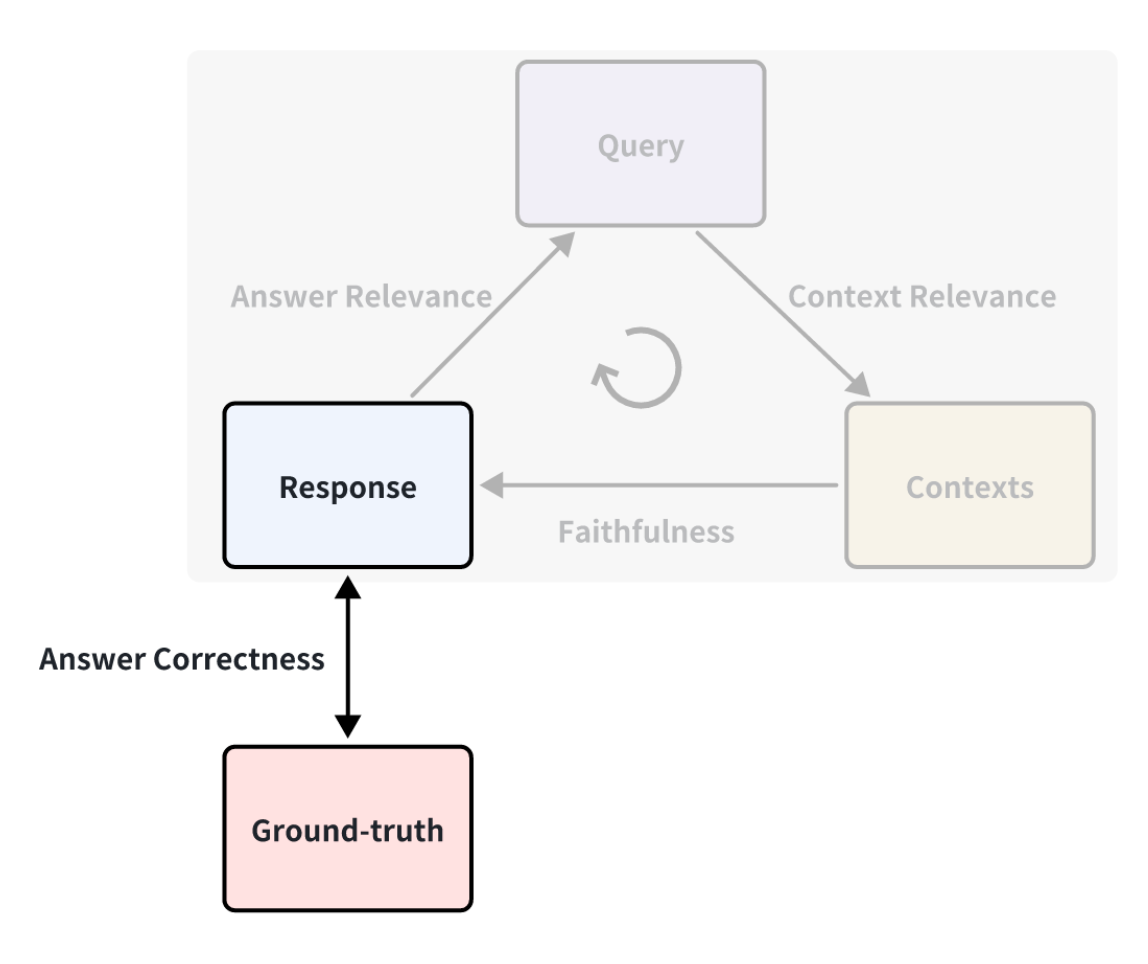 Ground Truth.png
Ground Truth.png
したがって、グランドトゥルースを取得すれば、様々な観点から検索拡張世代アプリケーションの性能を測定することができるため、より包括的な評価指標の結果を得ることができます。しかし、多くの場合、グランドトゥルースを含むデータセットを得るにはコストがかかる。訓練データにアノテーションを付けるには、かなりの手作業と時間が必要になるかもしれない。迅速にアノテーションを行う方法はあるのだろうか?
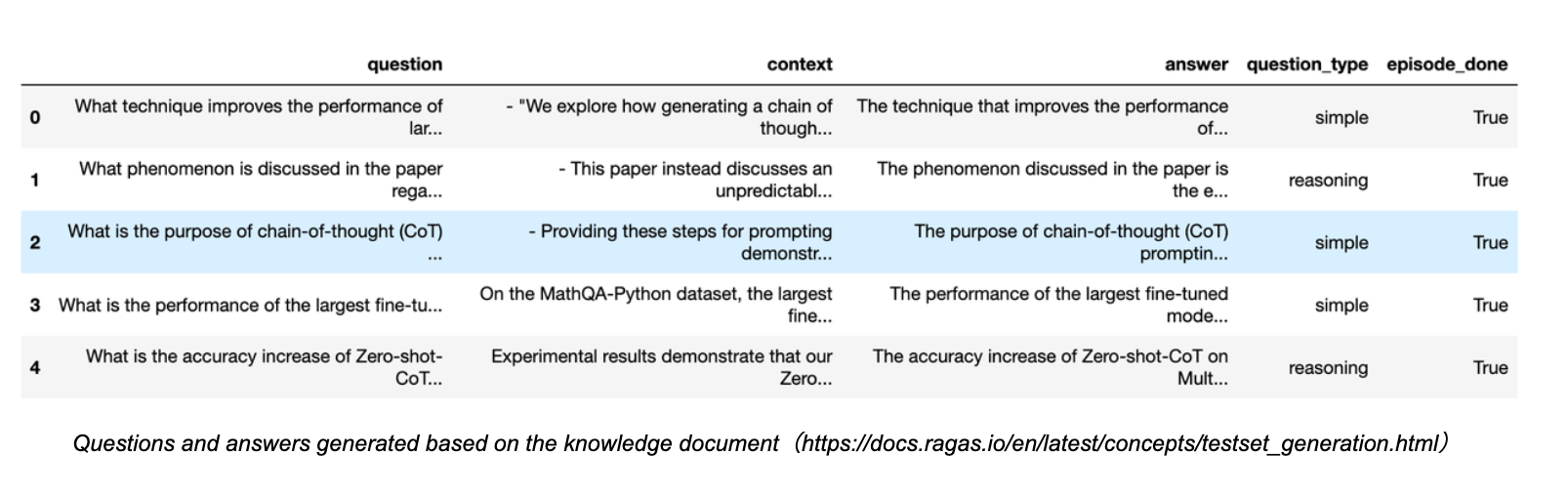
優れたLLMは何でも生成することができるので、LLMを使って知識文書に基づいたクエリーやグランドトゥルースを生成することは可能である。例えば、RagasのSynthetic Test Data generationやLlama-IndexのQuestionGenerationでは、様々な統合インターフェースを簡単に使うことができる。
Ragasの知識文書に基づくクエリの生成を見てみよう:
 Ragasクエリ.png
Ragasクエリ.png
ご覧のように、多くのクエリの質問とそれに対応する回答が、関連するコンテキストとソースを含めて生成されます。生成される質問の多様性を確保するために、単純な質問や推論質問のような異なるタイプの割合を選択することもできます。
このようにして、様々なオンラインベースラインデータセットを検索することなく、RAGアプリケーションを定量的に評価するために、これらの生成された質問とグランドトゥルースを便利に使用することができます。このアプローチは、企業内で独自にカスタマイズされたデータセットを評価するために使用することもできます。
ホワイトボックス評価
ホワイトボックスRAGパイプライン
ホワイトボックスの観点から、RAG](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)アプリケーションの内部実装[パイプライン]を調べることができる。一般的なRAGアプリケーションのプロセスを例にとると、いくつかの主要なコンポーネントには、埋め込みモデル、リランクモデル、および[LLM(言語モデル)](https://zilliz.com/glossary/large-language-models-(llms))が含まれる。RAGモデルの中には、多方向検索の機能を持つものもあり、用語頻度検索アルゴリズムを含む場合もある。これらの主要コンポーネントをテストすることで、特定のステップにおけるRAGパイプラインの性能を反映することもできる。これらの主要コンポーネントを交換したりアップグレードしたりすることで、RAGアプリケーションの性能を向上させることもできる。以下では、これら3つの代表的なキーコンポーネントを個別に評価する方法を紹介する。
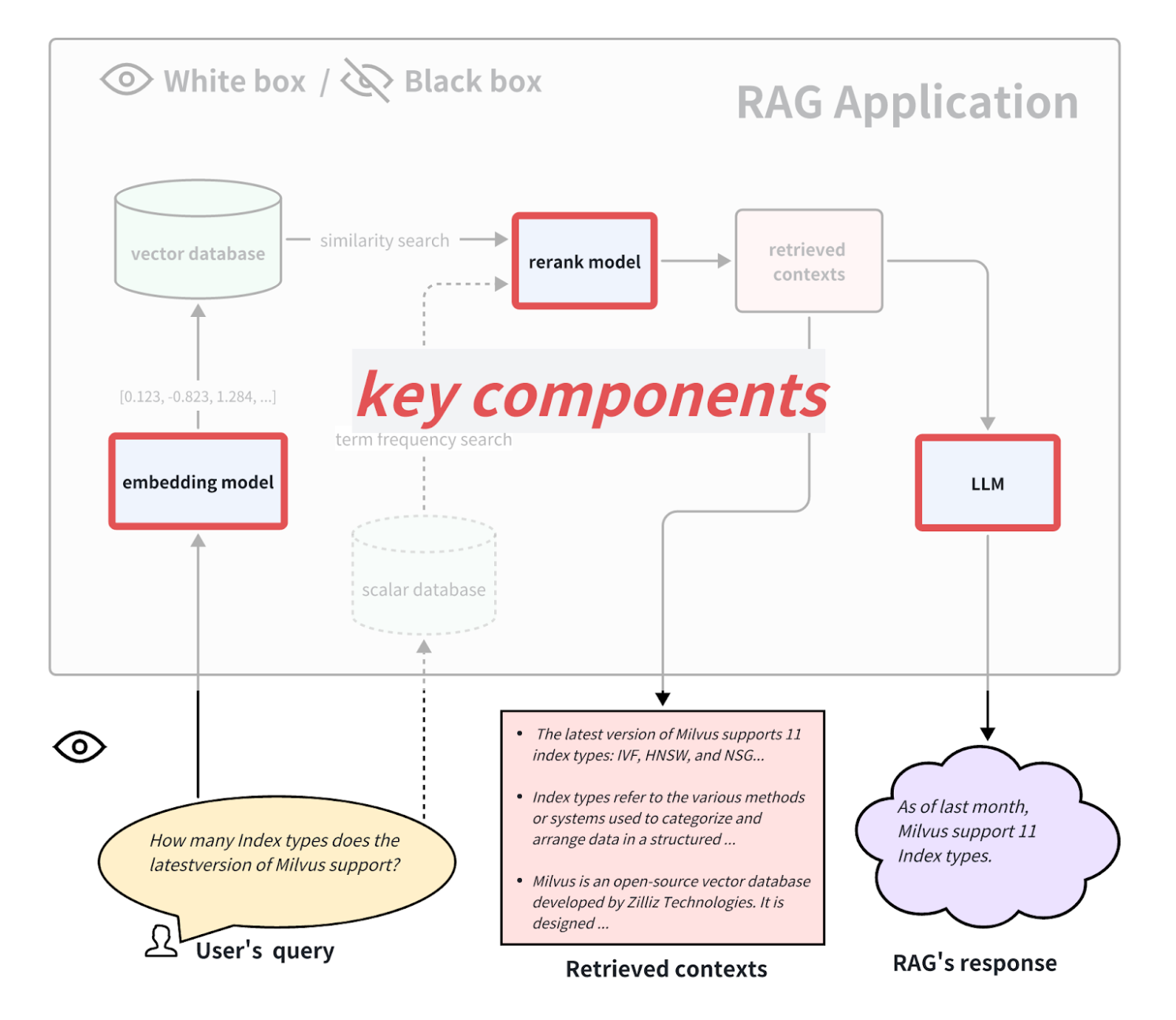 キーコンポーネント.png
キーコンポーネント.png
埋め込みモデルと再ランクモデルの評価方法
文書検索では、埋め込みモデルと再ランクモデルが協調して動作する。前節では、検索された文書の関連性を評価するために使用できるコンテキスト関連性メトリックを紹介した。しかし、グランドトゥルースを含むデータセットを扱う場合には、情報検索で一般的に用いられる決定論的なメトリクスを用いて検索性能を測定することが推奨される。これらのメトリクスの処理は、LLMベースのコンテキスト関連度メトリクスよりも高速で、費用対効果が高く、決定論的である(ただし、グランドトゥルースのコンテキストを必要とする)。
情報検索におけるメトリクス
情報検索では、2種類の一般的なメトリクスがあります:ランキングを意識したメトリクスと、ランキングにとらわれないメトリクス**です。順位考慮型メトリクスは、検索された全文書のうち、真正文書の順位に敏感である。つまり、検索されたすべての文書の順序を変更すると、このメトリクスのスコアが変化する。一方、順位にとらわれない検索メトリクスは、順位が異なっても影響を受けない。
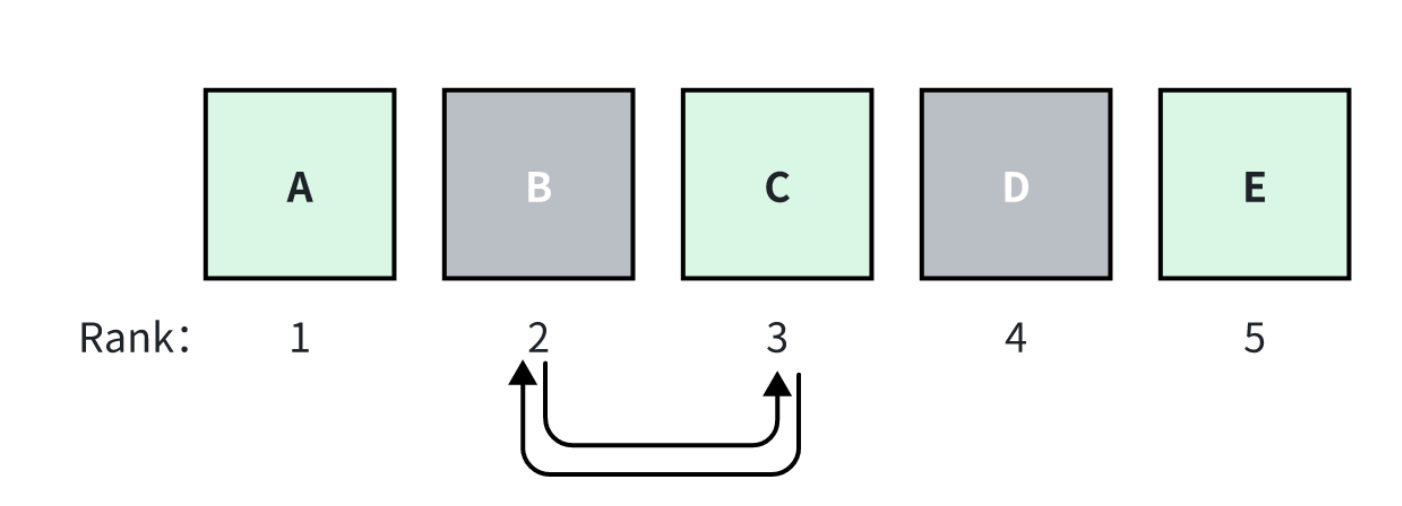 ランキング.png
ランキング.png
例えば、RAGがトップ_k=5の文書、A, B, C, D, Eを検索したとする。Aは関連度スコアが最も高く、左から右へスコアが下がっていく。BとCの順位が入れ替わると、順位を意識したメトリクスのスコアは変わるが、順位を意識しないメトリクスのスコアは変わらない。
具体的な指標をいくつか挙げてみましょう:
順位にとらわれない評価指標: **順位にとらわれない評価指標: **順位にとらわれない評価指標
- Context Recall: すべての関連するコンテキストのうち、どの程度の割合が検索されたかを測定します。
- コンテキストの精度**:検索されたコンテキストのうち、どの程度の割合が関連性のあるものかを測定する。
ランキングを考慮したメトリクス:。
- 平均精度 (AP)**:すべての関連するブロックを検索する際の重み付けされたスコアを測定する。データセット上の平均APはしばしばMAPと呼ばれる。
- 逆順位(RR)**:検索における最初の関連ブロックの位置を測定する。データセット上の平均RRはしばしばMRRと呼ばれる。
- 正規化割引累積利得(NDCG)**:関連性の分類が二値でない場合を考慮する。
最も人気のある評価ベンチマーク:MTEB
Massive Text Embedding Benchmark](https://zilliz.com/glossary/massive-text-embedding-benchmark-(mteb)) (MTEB)は、様々なタスクやデータセットに対するテキスト埋め込みモデルの性能を評価するために設計された包括的なベンチマークです。MTEBは、バイトテキスト・マイニング、分類、クラスタリング、分類、リランキング、検索、意味的テキスト類似度(STS)、要約という8つの埋め込みタスクをカバーしている。112の言語にまたがる58のデータセットをカバーしており、これまでで最も包括的なテキスト埋め込みベンチマークの1つとなっている。
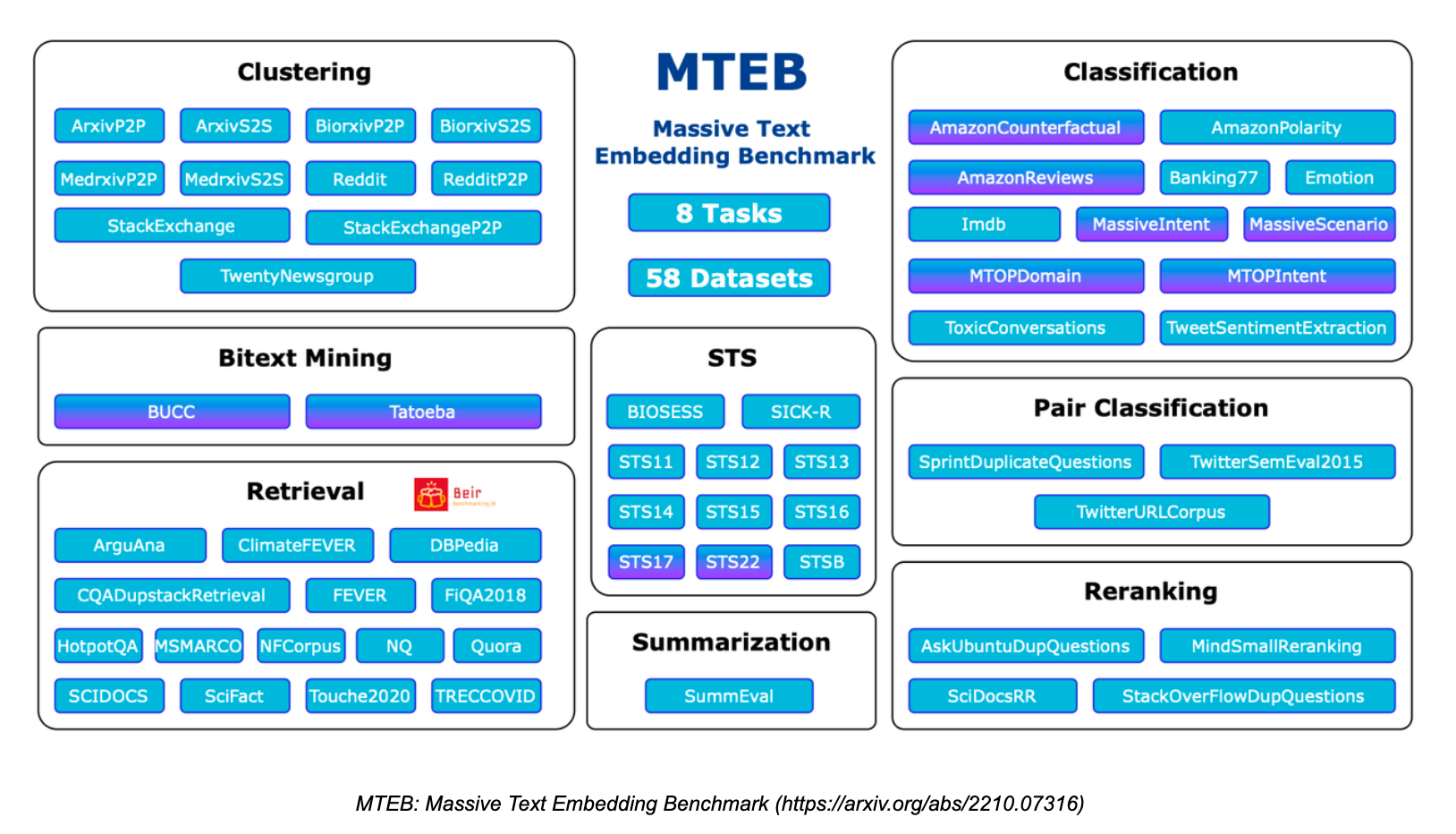 MTEB.png
MTEB.png
MTEBには、検索タスクとリランキングタスクが含まれている。RAGアプリケーションで埋め込みとリランキングモデルを評価する場合、これら2つのタスクで高いスコアを出すモデルに注目することが重要です。MTEB論文](https://arxiv.org/abs/2210.07316)は、埋め込みモデルにはNDCGを、リランキングモデルにはMAPを最も重要な評価指標として提案している。
ハグする顔.png](https://assets.zilliz.com/Hugging_Face_3803ff0b3c.png)
MTEBはHuggingFaceのリーダーボードとして高く評価されています。しかし、このデータセットは公開されているため、モデルによってはこのデータセットをオーバーフィットさせる必要があり、実際のデータセットでは性能が低下する。そのため、検索性能を評価する際には、実際のビジネスドメインに合致したカスタマイズされたデータセットの評価性能に着目することも不可欠である。
LLMの評価方法
一般に、生成処理では、前節で紹介したLLMに基づく指標である「忠実度」を直接用いて、ContextからResponseまでを評価することができる。
しかし、いくつかの比較的単純なクエリテスト、例えば標準的な回答としていくつかの単純なフレーズしかないようなクエリテストでは、古典的なメトリクスを使用することもできます。例えば、ROUGE-L PrecisionやToken Overlap Precisionなどです。この決定論的評価には、十分に注釈付けされたグランド・トゥルースのコンテキストも必要です。
- ROUGE-L**精度は、生成された回答と検索されたコンテキスト間の最長共通部分列を測定します。
- トークンオーバーラップ精度**は生成された回答と検索されたコンテキスト間のトークンオーバーラップの精度を計算します。 たとえば、以下のような比較的単純な質問では、ROUGE-L PrecisionとToken Overlap Precisionを使用して評価することができます。
質問Milvusの最新バージョンはいくつのインデックスタイプをサポートしていますか?
回答先月現在、Milvusは11種類のIndexをサポートしています。
根拠となる文脈このバージョンでは、Milvusは11種類のIndexをサポートしています。
しかし、これらのメトリクスは複雑なRAGシナリオには適していないことに注意する必要があります。例えば、このような自由形式の質問です:
質問Milvusの最新バージョンの機能に基づいてテキスト検索アプリケーションを設計し、アプリケーションの使用シナリオをリストアップしてください。
一般的な評価ツールの紹介
現在、オープンソースコミュニティでは、ユーザが便利かつ迅速に定量的評価を行うために使用できる専門的なツールが利用可能です。ここでは、一般的に使用されている優れたRAG評価ツールを紹介する。Ragas**:RagasはRAGアプリケーションを評価するための専用ツールで、評価基準のためのシンプルなインターフェースを提供します。RAGアプリケーションのための幅広いメトリクスを提供し、特定のRAG構築フレームワークに依存しません。langsmith](https://www.langchain.com/langsmith)を使って評価プロセスを監視することができ、各評価の理由を分析し、APIトークンの消費を観察するのに役立ちます。Continuous Eval**: Continuous-evalは、LLMアプリケーションパイプラインを評価するためのオープンソースパッケージです。より安価で迅速な評価オプションを提供する。さらに、数学的保証のある信頼できるアンサンブル評価パイプラインを作成することができます。TruLens-Eval:TruLens-Evalは、RAGメトリクスを評価するために特別に設計されたツールです。LangChainとLlama](https://zilliz.com/blog/a-beginners-guide-to-using-llama-3-with-ollama-milvus-langchain)-Indexとうまく統合されており、これら2つのフレームワークで構築されたRAGアプリケーションを簡単に評価することができます。さらに、ブラウザで起動して各評価を監視・分析し、APIトークンの消費を観察することができる。Llama-Index**:Llama-IndexはRAGアプリケーションの構築に適しており、そのエコシステムは現在非常に堅牢で、迅速かつ反復的な開発が行われている。Llama-IndexにはRAGの評価や合成データセットの生成機能もあり、Llama-Indexを使って構築されたRAGアプリケーションを評価するのに便利である。
さらに、他の評価ツールも機能的には上記のものと同様である。例えば、Phoenix、DeepEval、LangSmith、OpenAI Evalsなどがある。
これらの評価ツールも常に進化しており、それぞれの公式ドキュメントに具体的な機能や使用方法が記載されています。
RAG 評価のまとめ
RAG 評価は、ユーザーと開発者にとって非常に重要です。この記事では、ブラックボックスとホワイトボックスの観点から、あなたのアプリケーションのための定量的な RAG 評価方法を紹介し、読者が評価テクニックを素早く理解し、始められるように、実用的な評価ツールを提供します。RAGの詳細については、このシリーズの他の記事を参照してください。
 Cheney Zhang
Cheney ZhangCheney Zhang is an accomplished Algorithm Engineer at Zilliz. With a profound passion for and expertise in cutting-edge AI technologies such as LLMs and Retrieval Augmented Generation (RAG), Cheney has actively contributed to many innovative AI projects, including Towhee, Akcio, and OSSChat. Before joining Zilliz, he worked for CMB Network Technology as an Algorithm Engineer. Cheney holds a master's degree from Nanjing University of Aeronautics and Astronautics.
読み続けて

リランカーによるRAGの最適化:役割とトレードオフ
再ランカーは、RAGシステムにおける回答の精度と関連性を高めることができるが、こうした利点には待ち時間と計算コストの増加が伴う。

RAGパイプラインのパフォーマンスを高める方法
この記事では、RAGアプリケーションのパフォーマンスを向上させるための様々な一般的なアプローチをまとめました。また、これらのコンセプトやテクニックを素早く理解し、実装や最適化を迅速に行えるよう、わかりやすい図解も用意しました。

仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
HyDE(Hypothetical Document Embeddings)は、LLMとRAGの回答を改善するために「偽」の文書を使用する検索手法である。