




仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
HyDE(Hypothetical Document Embeddings)は、LLMとRAGの回答を改善するために「偽」の文書を使用する検索手法である。
シリーズ全体を読む
- 検索拡張ジェネレーション(RAG)でAIアプリを構築する
- LLMの課題をマスターする:検索拡張世代の探求
- ディープラーニングにおける主要なNLPテクノロジー
- RAGアプリケーションの評価方法
- リランカーによるRAGの最適化:役割とトレードオフ
- マルチモーダル検索拡張世代(RAG)のフロンティアを探る
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- RAGパイプラインのパフォーマンスを高める方法
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- Pandas DataFrame:Milvusによるチャンキングとベクトル化
- Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
- 検索拡張世代(RAG)のためのチャンキング戦略ガイド
- 仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
- Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
- RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
近年、情報検索において、ニューラルネットワークを利用した高密度検索が、用語頻度に基づく従来の疎な手法に代わる最新の手法として登場している。これらのモデルは、大規模な学習セットが利用可能なデータセットやタスクにおいて、最先端の結果を得ている。しかし、大規模なラベル付きデータセットが常に利用できるとは限らないし、使用上の制約から適切なデータセットとは限らない。さらに、これらのデータセットは実世界の検索シナリオの全領域を網羅していないことが多く、有効性が制限される。
したがって、ゼロショット法は、明示的な関連性監視に依存することなく、タスクやドメインを横断して汎化できる検索システムを実現することで、これらの制限を超えることを目指している。タスク固有のデータを事前に学習することなく文書検索を実行することで、学習のオーバーヘッドを最小化し、データセット作成のコストを下げることができる。
このブログでは、ゼロショット検索手法であるHypothetical Document Embeddings (HyDE)の詳細を取り上げる。この手法は、教師なし検索や微調整された密な検索を凌駕する。その後、OpenAIとMilvusベクトルデータベースを使ってHyDE法を実装する。
Hypothetical Document Embeddings (HyDE) とは?
HyDE (Hypothetical Document Embeddings)は、大規模言語モデル(LLMs)が生成する回答を改善するために、「偽の」(仮説上の)文書を使用する検索手法である。
具体的には、HyDEはLLM(オリジナルの実装ではGPT-3.5が使われた)を使って、クエリに対する仮の答えを作成する。この答えはvector embeddingに変換され、実際のドキュメントと同じ空間に配置されます。あなたが何かを検索すると、システムはこの仮説的な答えに最もマッチする実際の文書を、たとえそれがあなたの検索に含まれる単語と完全に一致しなくても、見つける。HyDEは、クエリの背後にある意図を捉え、検索された文書が文脈に関連したものであることを保証することを目指している。
HyDE**検索にはいくつかの利点があります:
ゼロショット検索**:関連するラベルや特定のデータセットに関する事前のトレーニングを必要とせずに、関連する文書を効果的に検索します。
再生的アプローチ**:仮想的な文書を生成することで、詳細が不正確であっても関連性のパターンを捉えることができる。
汎用性ウェブ検索、質問応答、事実確認など様々なタスクに対応し、多言語に対応。
次のセクションでは、HyDEの詳細な機能について説明する。
HyDE アプローチの仕組み
HyDEの動作に飛びつく前に、HyDEがどのような問題を解決するのかを見てみよう:
問題: 従来の高密度検索手法では、通常、クエリと文書を単一ベクトル表現-埋め込みにエンコードする。そして、この高次元ベクトル空間で近似最近傍(ANN)を検索することにより、データ検索を行う。
一般的にトランスフォーマーに基づくエンコーダのようなニューラルネットワークに基づく高密度検索モデルは、クエリや文書のような意味的に関連するエンティティに対して、固定次元のベクトルを生成することを目的としている。シャムネットワークのようなアーキテクチャを使用して、これらのモデルは、多くの場合、トリプレットロスを採用し、類似ペア(ポジティブ)間の距離を最小化し、異種ペア(ネガティブ)間の距離を最大化するように訓練される。これがトリプレットロスだ:
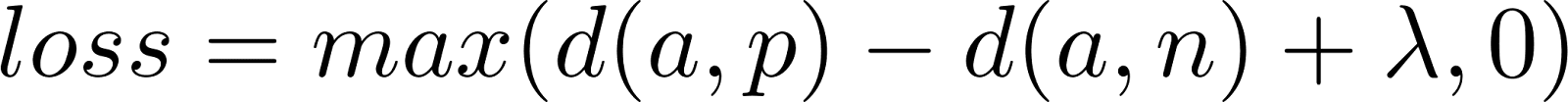 トリプレットロスの公式.png
トリプレットロスの公式.png
三重項損失の公式
ここで、aはアンカー、pは正、nは負、dは距離関数、λは負例間の距離を十分に確保するためのマージン値である。
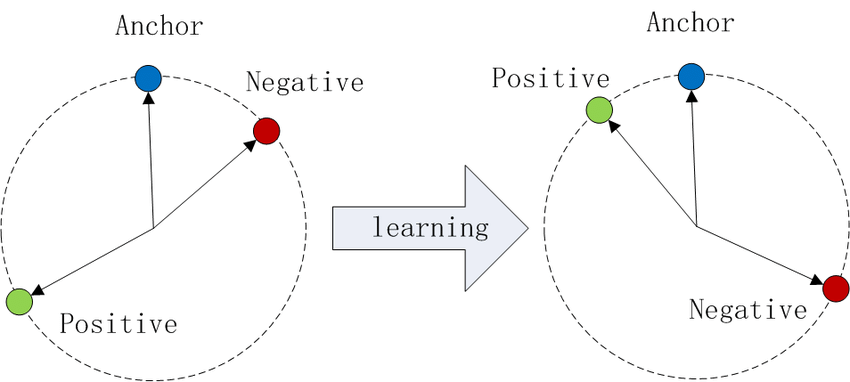 図1- コサイン類似度におけるトリプレットロスの説明図.png
図1- コサイン類似度におけるトリプレットロスの説明図.png
図1:コサイン類似度におけるTriplet Lossの説明図
このような高密度検索システムの主な課題は、多くの場合、クエリと文書(q,d)のペアである大規模なラベル付きデータセットを必要とすることである。 もう一つの課題は、関連性マッチングにおいて、単一ベクトル表現ではクエリと文書の異なる側面を捉えることができないことである。
解決策: HyDEの解決策は、生成的大規模言語モデル(LLM)と対照的エンコーダーの長所を組み合わせたものである。HyDEの核心は、大規模言語モデルを用いてクエリに対する仮想的な答えを生成することである。このアプローチにより、生成された仮説的文書との類似度に基づいて実際の文書を効果的に検索することができ、タスク固有の学習データの必要性を回避することができる。アーキテクチャを見て、ステップバイステップで理解しよう:
図2- HyDEモデルの説明.png](https://assets.zilliz.com/Fig_2_Illustration_of_Hy_DE_model_258ef062f7.png)
図2:HyDEモデルの図解
以下は、アーキテクチャの内訳である:
1.**クエリー入力
このプロセスは、GPT-3.5のような命令追従型大規模言語モデル(LLM)にクエリーを入力することから始まる。
このモデルは、クエリに答える仮想文書を生成するよう指示される。
2.**仮説文書を生成する:
LLMはクエリに対する仮の答えとして文書を生成する。
この生成された文書は、事実誤認を含む可能性があるにもかかわらず、関連性の本質を捉えている。
3.**仮説の文書を埋め込む:
仮説的文書は、対照的エンコーダを使ってベクトル埋め込みにエンコードされる。
エンコーダーは不要な詳細を削除し、本質的な意味を維持することでテキストを単純化する。
4.検索と取得:
仮想文書のベクトル埋め込みは、コーパス中のあらかじめエンコードされた実文書の埋め込みに対する検索に使われる。
文書は仮説文書のベクトルとの類似度に基づいて検索される。
その結果、最も類似した実文書が検索結果として返される。
次に、HyDEをPythonで実装してみよう。
PythonでHyDEを実装するためのステップバイステップガイド with Milvus
このガイドを以下のステップに分解します:
1.セットアップとインポート
まず、必要なライブラリをインポートし、環境をセットアップする。LLMの役割を果たすGPT-3.5 APIにアクセスするために OpenAI ライブラリを使用し、文書の保存と類似検索のためにMilvusベクトルデータベースと対話するために pymilvus を使用する。さらに、json や numpy といった標準的なライブラリもインポートしている。
from openai import OpenAI
from pymilvus import MilvusClient
json をインポートする。
np として numpy をインポートする
2.Milvusのセットアップ
Milvusは10億規模のベクトル類似度検索、高次元ベクトルの保存、クエリに最適化されたベクトルデータベースです。ここでは、Milvusに接続し、hyde_retrievalという名前の新しいコレクションを作成し、ドキュメントの埋め込みを保存する。
# OpenAI GPT-3.5のセットアップ
openai_client = OpenAI()
# Milvusに接続する
client = MilvusClient("milvus_demo.db")
OpenAIの text-embedding-ada-002 を使って、サイズを1536に設定する。
# Milvusコレクションを作成する
if client.has_collection(collection_name="hyde_retrieval"):
client.drop_collection(collection_name="hyde_retrieval")
client.create_collection(
collection_name="hyde_retrieval"、
dimension=1536)
3.データ
検索プロセスを実証するために、文書のダミー・コーパスを定義する。このコーパスにはいくつかのサンプル・テキストが含まれる。
# ダミー文書コーパス
コーパス = [
"親知らずを抜くのに通常30分から2時間かかる"、
"COVID-19の大流行はメンタルヘルスに大きな影響を与え、うつ病や不安症を増加させている"、
"人類は約80万年前から火を使ってきた"、
"Milvusはベクトル保存のためのクラウドベースのデータベースである。"
]
4.埋め込みモジュール
この節では、OpenAIの埋め込みモデル(text-embedding-ada-002)を用いてコーパス文書の埋め込みベクトルを取得する関数 get_embeddings を定義する。これらの埋め込みはベクトルベースの類似性検索にとって重要である。オリジナルのHyDE実装では埋め込みに Contriever モデルを使っていたことに注意してほしい。
def get_embeddings(texts, model="text-embedding-ada-002"):
response = openai_client.embeddings.create(
input=texts、
model=model
)
embeddings = [data.embedding for data in response.data] (data.embedding for data in response.data)
return embeddings
埋め込み生成モジュールを定義した後、コーパス文書をエンコードしてMilvusに挿入します。
vector = get_embeddings(corpus)
data = [
{"id": i, "vector": vectors[i], "text": corpus[i]}.
for i in range(len(vectors))
]
client.insert(collection_name="hyde_retrieval", data=data)
5.チャットモジュール
GPT-3.5を活用し、クエリに基づいて仮想文書を生成する関数 generate_hypothetical_document を作成する。このドキュメントはクエリの本質を捉え、類似検索のためのコンテキストを提供する。
# GPT-3.5 を使って仮説ドキュメントを生成する関数
def generate_hypothetical_document(query):
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[{"role":"system", "content":「質問に答える文書を書いてください、}
{"role":"user", "content": f"{クエリ}"}]、
max_tokens=100
)
return response.choices[0].message
6.HyDE モジュール
HyDE実装の中核は、与えられたクエリに対する仮想文書を生成し、この文書を埋め込み、コーパスから最も関連性の高い実際の文書を検索するためにMilvusで類似検索を実行することである。
# HyDEベースの検索を行う関数
def hyde_retrieve(query):
hypo_doc = generate_hypothetical_document(query)
hypo_embedding = get_embeddings(hypo_doc)
results = client.search(collection_name="hyde_retrieval",data=hypo_embedding)
return [コーパス[results[0][i]['id']] for i in range(len(results[0]))].
7.結果
最後に、クエリの例で実装をテストし、検索されたドキュメントを表示します。
# クエリの例
query = "Milvusとは?"
retrieved_docs = hyde_retrieve(query)
print("Retrieved Documents:", retrieved_docs)
検索結果は以下の通りである:
検索されたドキュメント['Milvusはベクターストレージのクラウドベースのデータベースである', 'COVID-19のパンデミックはメンタルヘルスに大きな影響を与え、うつ病や不安を増大させている', '人類は約80万年前から火を使っている', '親知らずを抜くのに通常30分から2時間かかる']].
まず、環境とMilvusベクトルデータベースをセットアップし、コーパスを定義し、OpenAIの埋め込みモデルを用いて埋め込みを取得し、GPT-3.5を用いて仮想的な文書を生成し、関連する文書を検索するために類似検索を実行する。このアプローチは、文脈に関連した仮の答えを生成することで、問い合わせと文書検索のギャップを効果的に埋める。
HyDEはどのように検索拡張世代(RAG)アプリケーションを改善するか
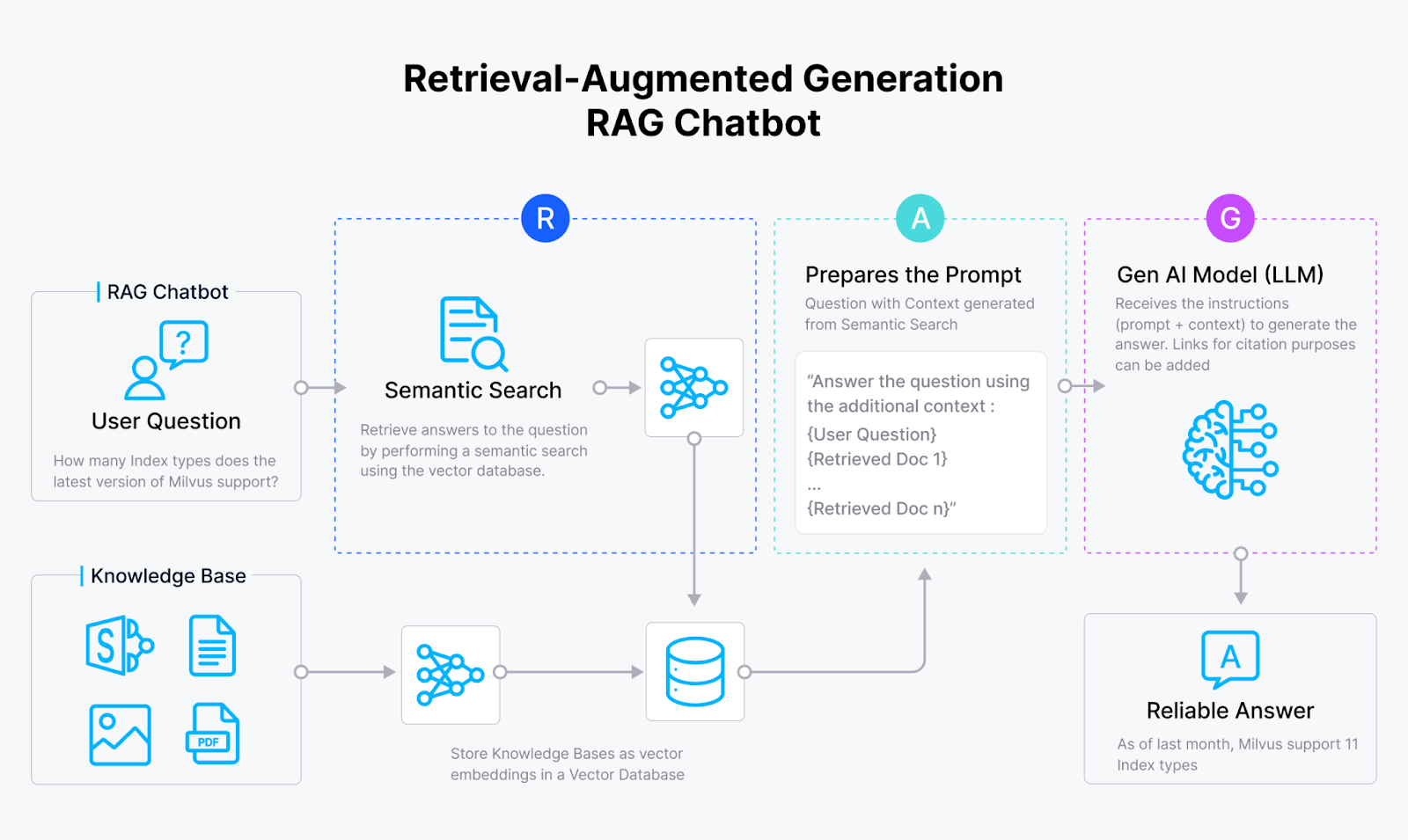
Retrieval Augmented Generation](https://zilliz.com/vector-database-use-cases/llm-retrieval-augmented-generation) (RAG)は、従来の情報検索システムに生成的LLMを統合したものである。 このアプローチにより、LLMは文脈に基づいた回答、説明、または自然言語による指示を生成することができる。基本的なRAG(Milvusのようなベクトルデータベース、埋め込みモデル、LLMで構成される)は実装が容易であることが多いが、実世界のアプリケーションにおける性能と精度は検索要素の最適化に依存する。
 RAGチャットボット.png
RAGチャットボット.png
図3:RAG]の基本アーキテクチャ(https://zilliz.com/vector-database-use-cases/llm-retrieval-augmented-generation)
RAGは2つのコア・コンポーネントを利用する:ジェネレーター、典型的にはLLM、そしてベクトル・データベースに似たリトリーバー。HyDEがRAGパイプラインをどのように改善するかについて説明します:
1.仮説文書の生成:HyDEの革新的な点は、クエリに基づいて仮の文書を生成し、それに基づいて文書を検索することにある。つまり、コーパスから検索された文書に直接頼るのではなく、HyDEはこの生成された文書を使って関連性の本質を捉える。
2.難しい質問に答える:漠然とした、あるいは文脈が曖昧な質問に遭遇した場合、的確な答えを導き出すことは難しい。HyDEはLLMの助けを借りて、より多くの文脈でクエリを豊かにすることでこれを改善する。
3.文書クエリの最適化:ほとんどのデータベースは質問というよりむしろ答えを含んでいるので、ドキュメントのクエリとして仮定の答えを使うことは理にかなっている。
実験により、性能、堅牢性、汎用性の向上が実証された:
1.性能の向上: HyDEは、様々なデータセットと測定基準(例えば、NDCG@10、リコール)において、従来のBM25と教師なしContrieverを一貫して上回る。
2.頑健性:HyDEは、TREC DL19/20のような教師ありタスクにおいて、微調整されたモデルに対しても競争力を維持しています。
3.多用途性:ウェブ検索と低リソースタスクの両方で強力な性能を発揮し、ベースラインモデルを大幅に上回る。
4.**韓国語や日本語などの言語では、mContrieverを凌駕しています。
5.効率性: HyDEは、大規模な微調整を必要とせずに検索品質を向上させるため、多様な検索タスクに効果的かつ効率的な選択肢となります。
RAGパイプラインのためのHyDEは、その限界が不明であれば、良いことよりも悪いことの方が多くなる可能性がある。次のセクションでは、それについて明らかにする。
HyDEの課題と限界
仮説的文書検索にはいくつかの課題と限界がある。そのいくつかを紹介しよう:
知識のボトルネック:** HyDEが生成した文書には事実誤認が含まれている可能性があり、検索結果の精度に影響を与える可能性がある。例えば、トピックが言語モデルにとって全く新しいものである場合、このアプローチは効果がないかもしれない。その結果、誤った情報を生成するケースがより頻繁に発生する可能性がある。
多言語への挑戦:**多言語検索は、HyDEにいくつかのさらなる挑戦をもたらす。小さなサイズの対照エンコーダーは、言語数が増えるにつれて飽和してしまう。一方、生成LLMは逆の問題に直面する。英語やフランス語ほどリソースが高くない言語では、大容量のLLMは訓練不足に陥る可能性がある。
研究者たちはこれらの課題に積極的に取り組んでおり、曖昧なクエリに取り組み、タスクに特化した命令を改善し、より良いパフォーマンスを達成するためにHyDEと微調整されたエンコーダーの統合を模索している。ゼロショットに関する他の研究は、検索エージェントとハイブリッド環境を含み、エージェントベースのクエリ絞り込みとハイブリッド検索システムの統合に焦点を当てている。
結論
最後に、議論された重要なポイントをまとめよう:
HyDEは仮想文書を生成することで、ゼロショット検索を可能にする。
HyDEは効果的な検索のために、生成的LLMと対照的エンコーダを組み合わせる。
HyDEは様々なタスクにおいて、従来のモデルやいくつかの微調整されたモデルを凌駕する。
HyDEは文書クエリを最適化し、曖昧な質問を処理することでRAGパイプラインを改善する。
HyDEの重要性は、事前の訓練やラベルなしで関連文書を見つけるので、自然言語処理 (NLP)にとっても重要である。HyDEは関連性を捕捉するために仮想的な文書を使用し、ウェブ検索や複数言語にわたる質問応答のようなタスクに優れている。この記事では、OpenAIとMilvusを使ったPythonによるHyDEの簡単なステップバイステップの実装も紹介する。
HyDEについての詳細は、この学術的な論文をお読みください。
その他のリソース
以下は、脳を養うためのさらなる探求のリソースである:
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


