




RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
RA-DIT、すなわちRetrieval-Augmented Dual Instruction Tuningは、RAGセットアップにおいてLLMとリトリーバの両方を微調整し、全体的なレスポンスの質を高める方法である。
シリーズ全体を読む
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
- Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations
- Top 10 RAG & LLM Evaluation Tools You Don't Want To Miss
RAG(Retrieval-AugmentedGeneration)は、大規模言語モデル(LLMs)のコンテキストとして内部文書を組み込むための強力な方法であることが証明されている。プロンプトに関連するコンテキストを統合することで、LLMの幻覚のリスクを減らすことができる。この場合、モデルは説得力があるように見えるが、正しくない応答を生成する。
しかし、一般的なRAGの実装には限界がある。LLMは本来、検索されたコンテクストを効果的に利用するように訓練されていないからである。そのため、LLMが応答を生成する際に、提供されたコンテキストを十分に利用できず、幻覚が生じる場合がある。
この記事では、応答生成時のコンテキスト利用を最適化する、RAGフレームワーク内の軽量なfine-tuningアプローチについて説明する。このアプローチはRetrieval-Augmented Dual Instruction Tuning (RA-DIT) と呼ばれる。それでは早速、RAGアプローチとRA-DITの動機を簡単に紹介しよう。
RAGの基礎とRA-DITの動機
命令データセットで微調整されたLLMは、入力プロンプトで指定された問題に対処する回答を生成することができる。このようなLLMは、インターネット上で広く公開されている問題に対しては優れた性能を発揮するが、内部知識を必要とする問題では、その回答に幻覚が含まれることが多い。幻覚とは、LLMが説得力はあるが正しくない回答を生成する現象を指す。
LLMの幻覚を避けるためには、LLMがその文脈を利用して適切な回答を生成できるように、入力プロンプトに文脈を提供する必要がある。これがRAG法の出番である。
図1- RAGの仕組み](https://assets.zilliz.com/Figure_1_How_RAG_works_24108cefb1.png)
RAGアプリケーションの完全なワークフロー。
RAGは、元のクエリとともに、LLMがクエリに答えるのを助けるような関連するコンテキストを提供する技術である。その名前が示すように、RAGは検索、補強、生成の3つの主要なコンポーネントから構成される。
検索コンポーネントでは、与えられたクエリに対する有望なコンテキストがフェッチされる。まず、大量の文書を埋め込みモデルを使って埋め込みに変換する。そして、これらの文書埋め込みをすべてベクトルデータベースに格納する。次に、同じretrieverを使って、クエリを埋め込みに変換します。
図2-大量の文書埋め込みをベクトルデータベースに格納するワークフロー](https://assets.zilliz.com/Figure_2_How_to_perform_a_vector_search_f38e8533a2.png)
図2-ベクトルデータベースに大量の埋め込み文書を格納するワークフロー](_)
クエリ埋め込みと文書埋め込みが揃ったら、クエリ埋め込みとベクトルデータベースに格納された文書埋め込みとの間の類似度を計算する。そして、クエリに最も類似した上位k個の文書をコンテキスト候補として選択する。
拡張コンポーネントでは、検索されたコンテキストを元のプロンプトに統合し、最終的なプロンプトが元のクエリと検索されたコンテキストの両方を含むようにする。最後に、生成コンポーネントで、この最終プロンプトをLLMに提供し、LLMが提供されたコンテキストを使用してコンテキスト化された応答を生成し、それによって幻覚を回避することを期待する。
元のプロンプト vs 検索で補強されたプロンプト](https://assets.zilliz.com/Original_prompt_vs_retrieval_augmented_prompt_6a9b05584e.png)
図:元のプロンプトと検索で補強されたプロンプトの比較_。
**一般的なRAG実装の主な問題は、LLMがユーザーのクエリに対する応答を生成するために、検索されたコンテキストを組み込んだ命令データセットでネイティブに訓練されていないことである。さらに、検索されたコンテキストがクエリへの回答に無関係であるにもかかわらず、LLMがそのコンテキストを使用して応答を生成するため、質の低い回答になる場合もあります。
ここで疑問が生じる:LLMとリトリーバの両方を微調整して、指示データセットにコンテキストを組み込むことで、RAGアプリケーションから生成される回答の質を向上させることはできるだろうか?この方法は次のセクションで説明します。
RA-DITとは何か?
一言で言えば、RA-DITはRAGセットアップにおいてLLMとリトリーバの両方を微調整し、全体的な応答品質を向上させる手法である。したがって、RA-DITは2つの別々のステップで構成される:
LLMの微調整:LLMの微調整:クエリ、それに対応するコンテキスト、および真正ラベルを含むプロンプトが与えられた場合、LLMは応答生成のためのソースとして提供されたコンテキストの利用を最適化するように微調整される。
レトリバーの微調整**:LLMは、プロンプトと真偽判定ラベルが与えられたときに、LLMが正しい応答を生成する可能性を高めるコンテキストを検索するように微調整される。
図-LLMとリトリーバを別々に微調整するRA-DITアプローチの概要](https://assets.zilliz.com/Figure_Overview_of_the_RA_DIT_approach_that_separately_fine_tunes_the_LLM_and_the_retriever_bb28e3f1b0.png)
図:LLMとレトリバーを別々に微調整するRA-DITアプローチの概要_ ソース..
LLMの微調整
命令チューニング](https://zilliz.com/blog/llava-visual-instruction-training)に使用されるLLMは、Llamaモデルである。具体的には、7B、13B、65B の 3 種類の Llama モデルがファインチューニングされた。データセットは、対話、オープンドメインQA、読解、思考連鎖(CoT)推論の5つのカテゴリにわたる20の異なるソースから構成される。
ファインチューニングの過程で、入力クエリとそれに対応するグランドトゥルースの応答の各ペアに対して、クエリへの回答に関連する上位k個のコンテキストが検索される。検索された各コンテキストはクエリの前に付加され、1つのまとまったプロンプトを形成する。例えば、入力クエリに最も関連する上位10個のコンテキストを検索すると、10個のプロンプトができあがる。微調整の実装では、kはk=3に設定され、任意のクエリに対して最も関連性の高い上位3つのコンテキストのみを取得することを意味する。
このプロンプトのコレクションを収集したら、以下に示すテンプレートを使用して、インストラクションチューニングのためにデータをシリアライズする必要がある:
図-データセットの微調整に使用する命令テンプレート](https://assets.zilliz.com/Figure_Instruction_template_used_for_fine_tuning_datasets_4f2e65bc02.png)
図:データセットの微調整に使われる命令テンプレート_ ソース..
図示されているように,データセットをシリアライズするために使用される3つの特別なマーカーがある.<inst_s>,<inst_e>,<answer_s>である.これらのマーカーは、各フィールドの開始と終了を示す。微調整の過程で、これらのマーカーはプロンプトのコレクション全体にランダムに適用され、オーバーフィッティングを回避する。
入力クエリと取得されたコンテキストからなるプロンプトを得たので、次の損失関数を最適化することで、標準的なネクストトークン予測を使用してLLMを微調整することができる:
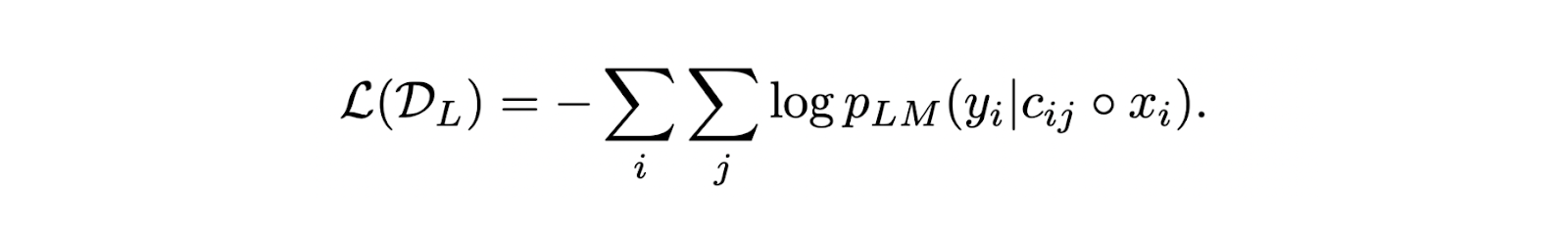
最終的なLLM確率スコアは2つの要素から計算される:(1)入力クエリとそれに対応する検索されたコンテキストが与えられたときに正しい応答を生成するLLM確率スコア、(2)上位k個の関連するコンテキストを検索した後に再正規化されたリトリーバからのコンテキスト関連性スコア。
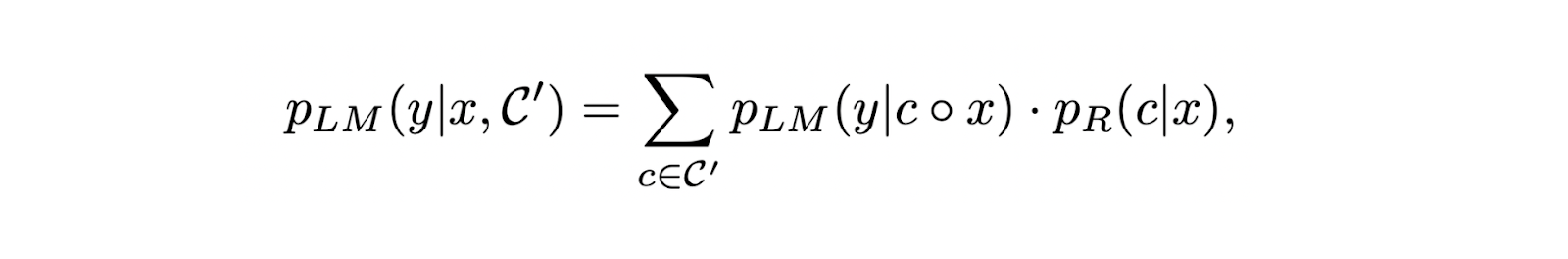
LLMの微調整中に、検索された文脈を入力プロンプトに組み込むことは、少なくとも2つの利点をもたらす。第一に、LLMが提供されたコンテキストを応答生成のための主要なソースとして利用する方法を学習することを促し、それによって幻覚のリスクをさらに減らすことができる。第二に、提供されたコンテキストがクエリへの回答に無関係であったとしても、微調整中の損失関数は、応答生成中の信頼できない無関係なコンテキストに対するLLMのロバスト性を高める。
次のセクションでは、RA-DIT法を用いたLLMの微調整がどのように全体的な応答品質を向上させるかについて検討する。
レトリバーの微調整
LLM自体の微調整に加え、RA-DITはレトリーバーの微調整も行います。このプロセスで使用されるレトリーバーはDragon+モデルで、文書用とクエリー用の2つのエンコーダーを備えている。
その名の通り、ドキュメントエンコーダはドキュメントの集合を埋め込みに変換し、クエリーエンコーダはクエリーを埋め込みに変換する。微調整の際、両方のエンコーダを更新すると全体的なリトリーバの性能に悪影響を与えるため、クエリーエンコーダのみが更新されます。
ファインチューニングに使用されるデータセットには、RA-DITの著者によってコンパイルされたQAデータセット、FreebaseQA、MS-MARCOが含まれる。LLMのファインチューニングと同様に、これらのデータセットは上表に示すテンプレートを用いて命令チューニングのためにシリアライズされる。
RA-DITはレトリーバーを微調整するために、LLM自身による監視を採用している。入力クエリとそれに対応するグランドトゥルースラベルの各ペアに対して、検索された各コンテキストのスコアは以下の式を用いて決定される:
(https://assets.zilliz.com/equation_3_842ecbc288.png)
この式の結果が高いほど、特定のコンテキストはLLMからの応答品質を向上させるのに効果的である。したがって、リトリーバの微調整の主な目標は、LLMが正しく質の高い応答を生成する可能性を高めるコンテキストに高いスコアを割り当てることである。
RA-DIT の評価結果
ファインチューニングされたレトリーバの結果を評価するために、WikipediaとCommonCrawlから収集された合計3億9900万個のコンテキストがコーパスとしてコンパイルされた。一方、MMLU、TriviaQA、Natural Questions、KILTベンチマークのサブセットなどの知識集約型評価データセットを用いて、ファインチューニングされたLLMを評価した。
評価の焦点は、Llama 65Bモデルを3つの異なるバリエーション(RA-DITでファインチューニングしたもの、ベースモデル、命令データセット(Llama instruction)でファインチューニングしたオリジナルモデル)で比較することである。また、REPLUGと呼ばれる別の最先端のRAGベースのアプローチに対するRA-DITの性能も評価した。また、Dragon+モデルは、3種類全てのRAG応答を評価する際にリトリーバとして使用されたことも重要である。
Dragon+モデルが他の埋め込みモデルよりも選択された理由は、MMLU、NQ、TQA、HoPoを含む、Llamaモデルと共にRAGフレームワークで使用された場合、いくつかのベンチマークデータセットで最高のパフォーマンスを示したからである。特に、Dragon+モデルの性能は、ContrieverとContriever-SMarcoの性能と比較された。
図-ベンチマークデータセットにおける各検索エンジンの性能](https://assets.zilliz.com/Figure_Performance_of_different_retrievers_on_benchmark_datasets_14fa55ee7d.png)
図:ベンチマークデータセットにおける異なる検索エンジンの性能_ ソース..
評価結果によると、RA-DITアプローチで微調整されたLLMは、プロンプトに文脈補強を組み込んだ場合、様々なベンチマークデータセットでテストされた手法の中で最高の性能を示した。
以下の表に示すように、1、3、あるいは10など、取得するコンテキストの数に関係なく、RA-DITで微調整したLLMは他の2つの手法を一貫して上回っている。このことは、RA-DITアプローチが、応答生成時にコンテキストの利用を最適化するようLLMを促すことに成功したことを示唆している。文脈がクエリへの回答に完全に関連していない場合でも、LLMは事前学習で獲得した内部知識に効果的に依存する。
図-RA-DITと他の方法で微調整されたLlama 65Bの性能比較.png](https://assets.zilliz.com/Figure_Performance_comparison_of_Llama_65_B_fine_tuned_with_RA_DIT_and_other_methods_d5c0d9a077.png)
図:RA-DITと他の方法で微調整したLlama 65Bの性能比較_ ソース..
レトリーバーについても、どのデータセットがファインチューニングに最適かを判断する必要がある。評価結果は、コーパスデータ(RA-DITの著者によって組み立てられたデータセット)(95%)とMTIデータセット(5%)の組み合わせでレトリーバーを微調整することで、どちらかのデータセットだけで微調整するよりも良いパフォーマンスが得られることを示している。また、以下の表は、文書エンコーダを凍結したまま、クエリーエンコーダのみを微調整することが、Dragon+にとって最も効果的であることを示しており、クエリーエンコーダのみを微調整するという判断に至った。
図-複数のデータセットで微調整したDragon+のパフォーマンス](https://assets.zilliz.com/Figure_Performance_of_Dragon_fine_tuned_on_several_datasets_c516590c09.png)
図:複数のデータセットで微調整したDragon+のパフォーマンス_ ソース..
ここまでは、ファインチューニングされたLLMとリトリーバーを別々に使用し、他は学習前の設定に固定した場合の結果を見てきた。次に、同じRAGフレームワークの中でfine-tuned LLMとretrieverの両方を使用した場合の性能を評価してみよう。そのために、命令チューニングされたLlamaとDragon+を利用したREPLUG法に対する性能を評価した。
下の表に示すように、RAGフレームワークでファインチューニングされたLlamaとDragon+の両方を併用した場合、REPLUG法と比較して平均0.8ポイントの性能向上が見られます。
図- RA-DIT法におけるLLMとRetrieverのファインチューニングの影響](https://assets.zilliz.com/Figure_The_impact_of_LLM_and_Retriever_fine_tuning_in_the_RA_DIT_method_f91918b76d.png)
図:RA-DIT法におけるLLMとRetrieverの微調整の影響_ ソース..
結論
RA-DITアプローチは、一般的なRAG実装の主要な制限に対処することで、RAGフレームワークの最適化における一歩進んだ改善を示している:LLMは、プロンプトにコンテキストを組み込むことによってネイティブに学習されるわけではない。RA-DITは、RAGセットアップのLLMとリトリーバの両方を微調整することで、応答を生成する際に検索されたコンテキストを考慮するようにLLMを強制し、効果的に幻覚を減らし、生成された応答の頑健性を向上させる。
微調整されたLlamaモデルは、様々なベンチマークで優れた性能を示し、ベースラインとREPLUGのような最先端の手法の両方を凌駕した。これは、関連性の低い文脈を扱う場合でも、生成された出力の関連性と信頼性を確保するRA-DITの有効性を強調するものである。また、RA-DITに実装されたデュアルチューニングアプローチは、この手法が個々のコンポーネントを改善するだけでなく、RAGパイプライン全体の性能も改善することを保証する。
関連リソース
RAGアプリ構築のベストプラクティス ](https://zilliz.com/blog/best-practice-in-implementing-rag-apps)
この無料計算機でRAGパイプラインの構築コストを素早く見積もる](https://zilliz.com/rag-cost-estimator/)
高度なRAGテクニック:テキストとビジュアルの橋渡し](https://zilliz.com/blog/advanced-rag-techniques-bridging-text-and-visuals-for-accurate-responses)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
MilvusでAIアプリを作る:チュートリアル&ノートブック](https://zilliz.com/learn/milvus-notebooks)
RAGを知識グラフで強化するGraphRAGとは](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
RAGアプリケーションの評価方法](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)

読み続けて

ディープラーニングにおける主要なNLPテクノロジー
ディープラーニングにおける主要な自然言語処理(NLP)技術の根底にある進化と基本原理を探る。

マルチモーダル検索拡張世代(RAG)のフロンティアを探る
マルチモーダルRAGは、テキスト、画像、音声、動画など様々なデータタイプを含むマルチモーダルデータを取り入れた拡張RAGフレームワークである。

ChatGPTをMilvusで強化する:長期記憶でAIを強化する
GPTCacheとMilvusをChatGPTと統合することで、企業はより強固で効率的なAIを活用したサポートシステムを構築することができる。このアプローチは、ジェネレーティブAIの高度な機能を活用し、長期記憶の形式を導入することで、AIが効率的に情報を呼び出し、再利用することを可能にします。