




RAGパイプラインのパフォーマンスを高める方法
この記事では、RAGアプリケーションのパフォーマンスを向上させるための様々な一般的なアプローチをまとめました。また、これらのコンセプトやテクニックを素早く理解し、実装や最適化を迅速に行えるよう、わかりやすい図解も用意しました。
シリーズ全体を読む
- 検索拡張ジェネレーション(RAG)でAIアプリを構築する
- LLMの課題をマスターする:検索拡張世代の探求
- ディープラーニングにおける主要なNLPテクノロジー
- RAGアプリケーションの評価方法
- リランカーによるRAGの最適化:役割とトレードオフ
- マルチモーダル検索拡張世代(RAG)のフロンティアを探る
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- RAGパイプラインのパフォーマンスを高める方法
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- Pandas DataFrame:Milvusによるチャンキングとベクトル化
- Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
- 検索拡張世代(RAG)のためのチャンキング戦略ガイド
- 仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
- Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
- RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
Retrieval Augmented Generation(RAG)アプリケーションの人気が高まるにつれ、そのパフォーマンス向上に関する関心が高まっています。この記事では、RAGパイプラインを最適化するすべての可能な方法を紹介し、主流のRAG最適化戦略をすばやく理解できるよう、対応する図解を提供します。
重要なことは、これらの戦略とテクニックをRAGシステムにどのように統合するかに焦点を当て、ハイレベルな探索を提供するだけであるということです。しかし、複雑な詳細を掘り下げたり、ステップバイステップの実装をガイドすることはありません。
標準的なRAGパイプライン
下図は最も単純なRAGパイプラインを示している。まず、ドキュメントのチャンクがベクターストア( Milvus や Zilliz cloud など)にロードされる。次に、ベクターストアはクエリに関連するTop-Kのチャンクを検索する。これらの関連チャンクは、LLMのコンテキスト・プロンプトに注入され、最後に、LLMは最終的な答えを返す。
様々なタイプのRAG拡張技術
RAGパイプライン段階における役割に基づいて、さまざまなRAG強化アプローチを分類することができる。
クエリー強化**:RAG入力のクエリプロセスを修正・操作し、クエリインテントをより適切に表現・処理する。
インデックス作成機能強化**:マルチチャンキング、ステップワイズインデックス、マルチウェイインデックスなどのテクニックを使用して、チャンキングインデックスの作成を最適化する。
リトリーバの強化**:検索プロセスにおける最適化技術と戦略の適用。
ジェネレーターの強化LLMのプロンプトを組み立てる際に、プロンプトを調整・最適化し、より良い回答を提供する。
RAGパイプラインの強化**:RAGパイプラインの主要ステップを最適化するためのエージェントやツールの使用を含む、RAGパイプライン全体のプロセスを動的に切り替える。
次に、それぞれのカテゴリーにおける具体的な方法を紹介する。
クエリの強化
クエリ体験を向上させる4つの効果的な方法を探ってみましょう:仮定の質問、仮定のドキュメントの埋め込み、サブクエリ、ステップバックプロンプトです。
仮想質問の作成
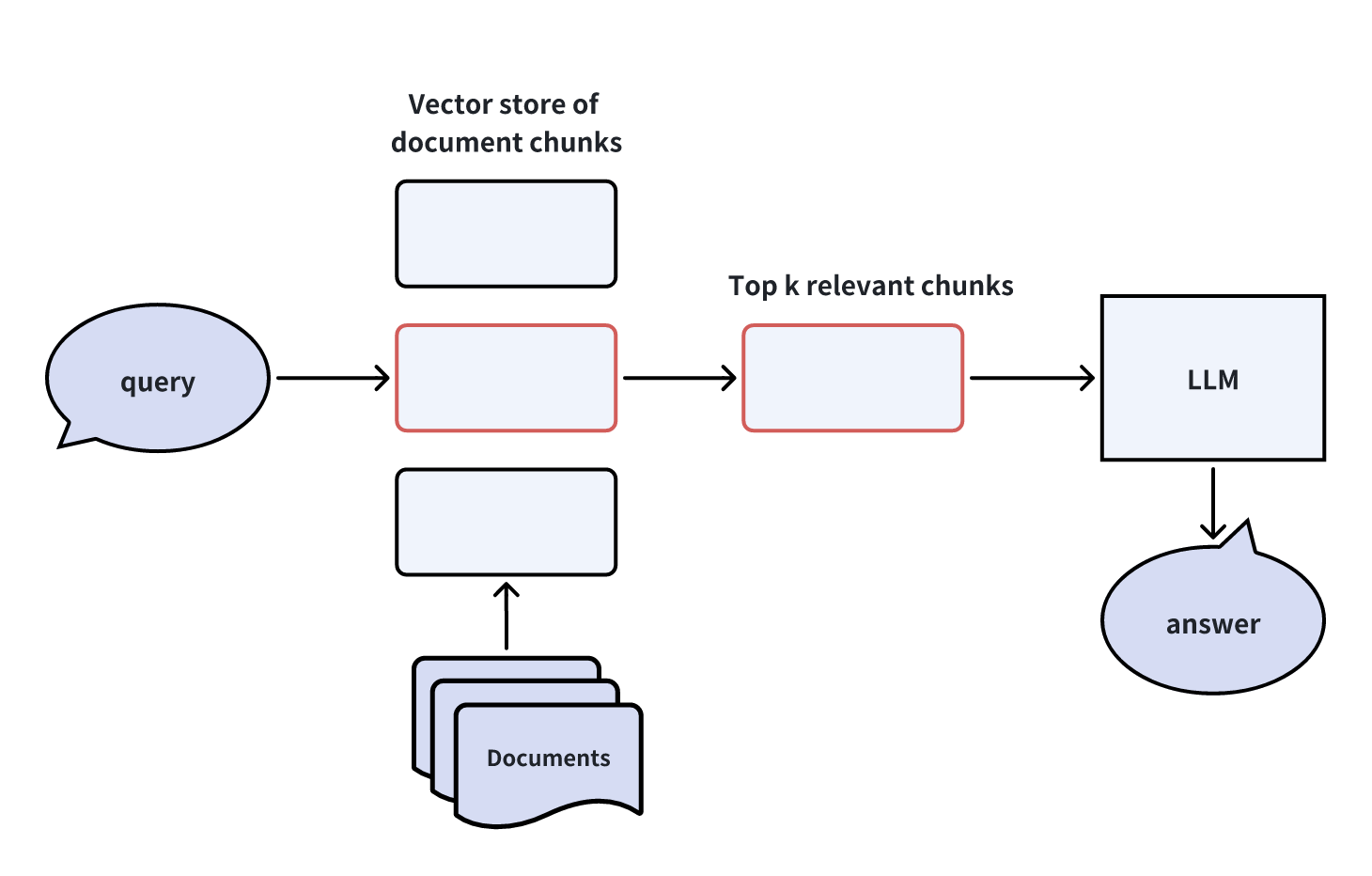
仮定の質問を作成するには、LLMを利用して、各ドキュメントチャンク内のコンテンツについてユーザーが質問する可能性のある複数の質問を生成します。ユーザーの実際のクエリがLLMに到達する前に、ベクトルストアは実際のクエリに関連する最も関連性の高い仮定の質問を、対応するドキュメントチャンクとともに取得し、LLMに転送します。
この方法論は、クエリ間の検索に直接関与することで、ベクトル検索プロセスにおけるクロスドメインの非対称性問題を回避し、ベクトル検索の負担を軽減する。しかし、仮想的な質問を生成する際に、さらなるオーバーヘッドと不確実性が生じます。
HyDE (仮説的文書埋め込み)
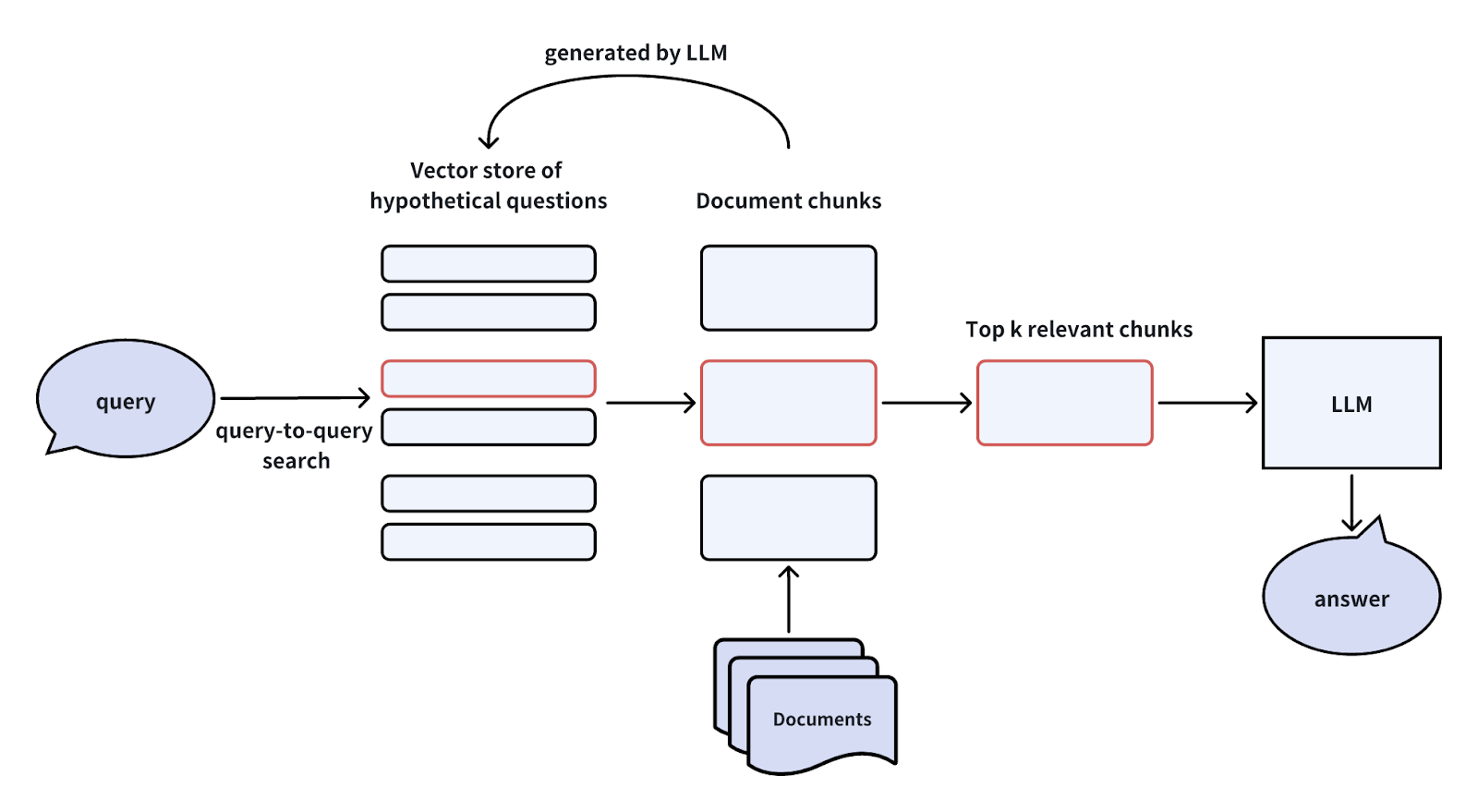
HyDEはHypothetical Document Embeddingsの略です。LLMを活用し、文脈情報のないユーザークエリに対して「Hypothetical Document」すなわち「fake」の答えを作成する。この偽の回答はベクトル埋め込みに変換され、ベクトルデータベース内の最も関連性の高い文書チャンクにクエリされる。その後、ベクトルデータベースは上位K個の最も関連性の高いドキュメントチャンクを検索し、LLMと元のユーザークエリに送信して最終的な回答を生成する。
この方法は、ベクトル検索におけるクロスドメインの非対称性に対処するという点で、仮説的質問手法に似ている。しかし、計算コストの増加や偽の回答を生成する不確実性などの欠点もあります。
詳しくはHyDEの論文を参照してください。
サブクエリの作成
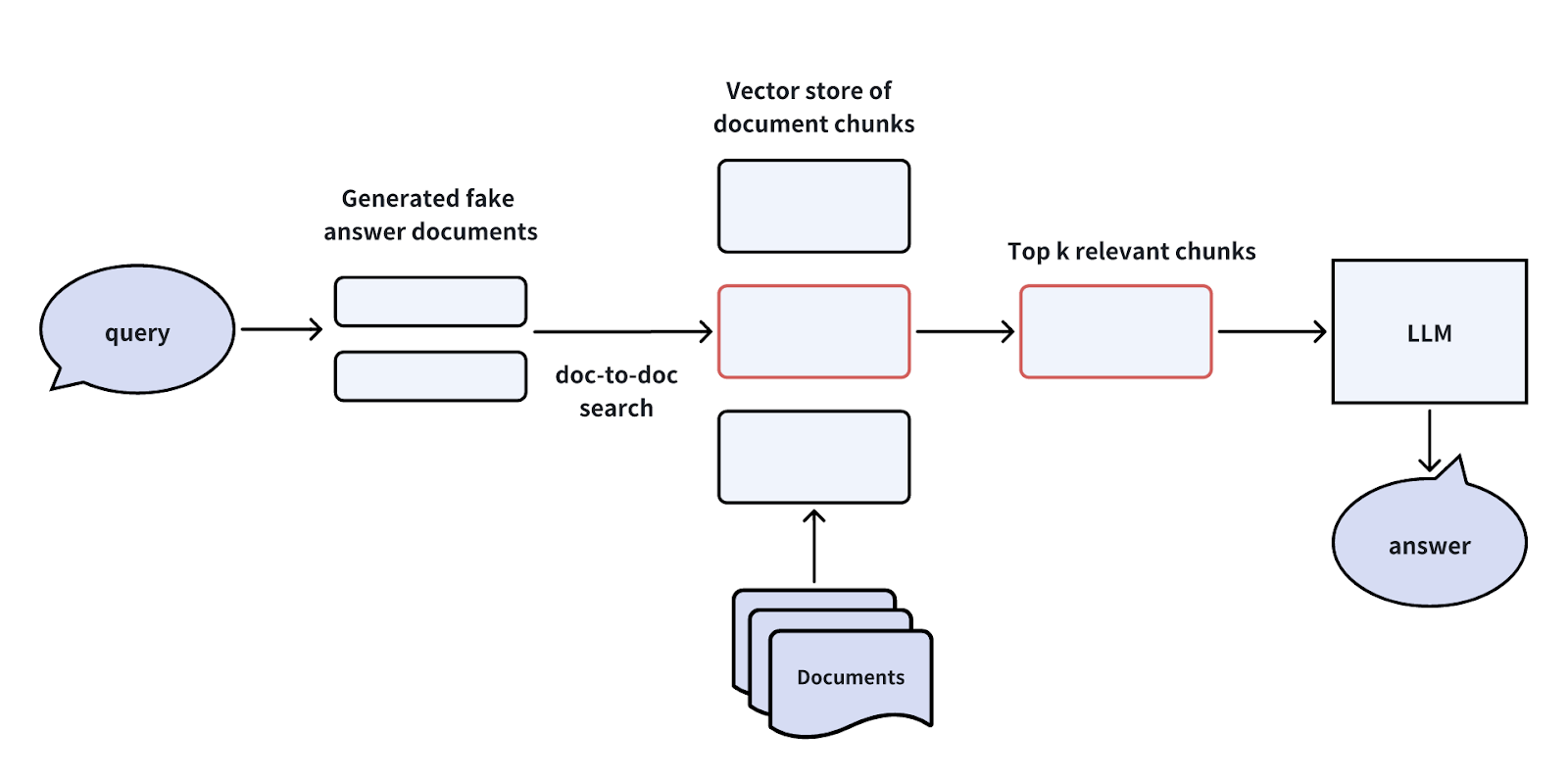
ユーザークエリが複雑すぎる場合、LLMを使ってそれをより単純なサブクエリに分解してから、ベクトルデータベースとLLMに渡すことができます。例を見てみましょう。
あるユーザーが尋ねてきたとします:「MilvusとZilliz Cloudの機能の違いは何ですか?この問題に取り組むために、2つの単純なサブクエリに分割することができます:
サブクエリ1:"Milvusの特徴は何ですか?"
サブクエリ2:"Zilliz Cloudの特徴は?"
これらのサブクエリができたら、それらをすべてベクトル埋め込みに変換してベクトルデータベースに送る。そしてベクトル・データベースは、各サブクエリに最も関連性の高いTop-Kの文書チャンクを見つける。最後に、LLMはこの情報を使ってより良い答えを生成する。
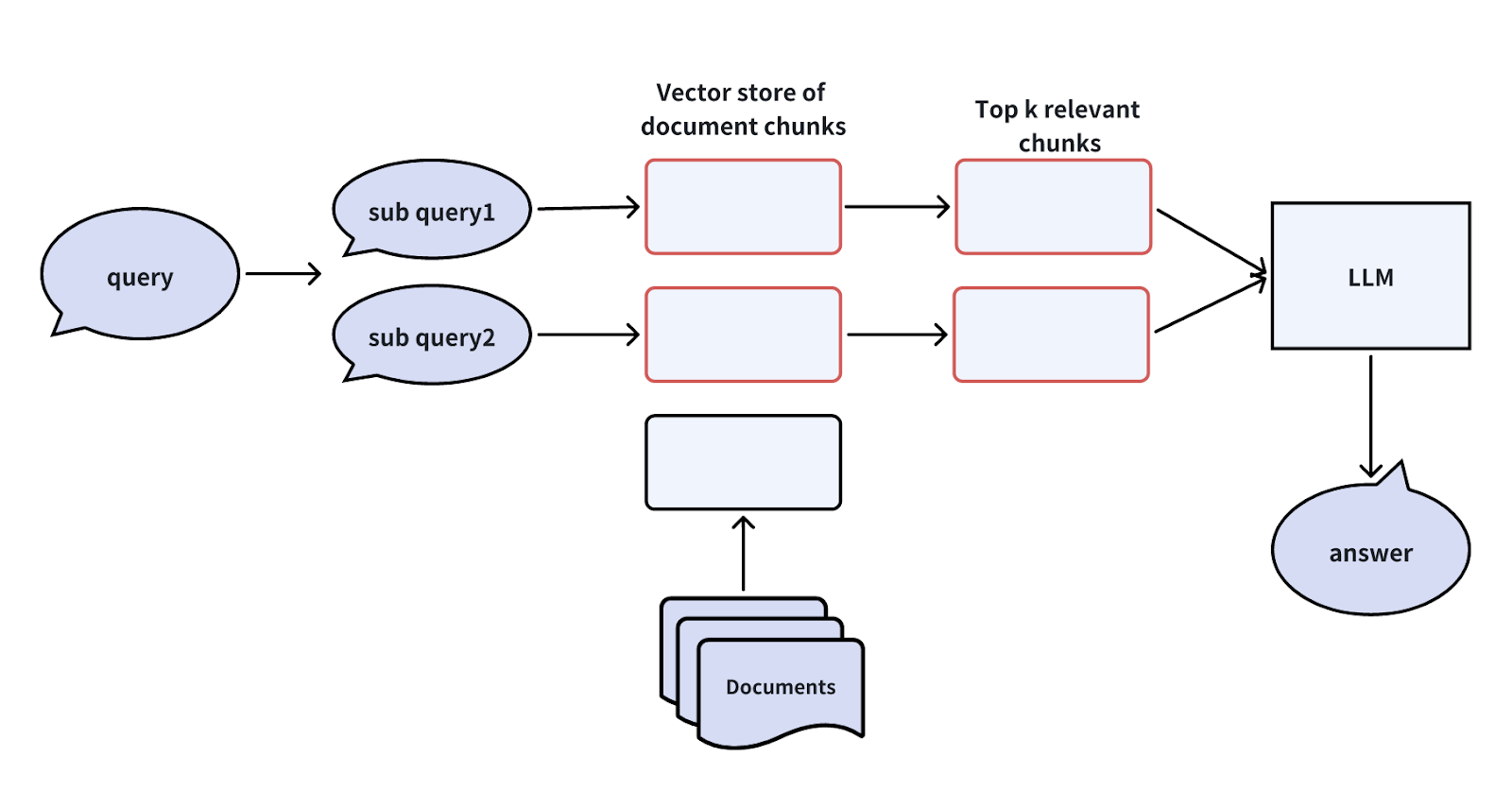
ユーザークエリをサブクエリに分解することで、複雑な質問であっても、システムが関連情報を見つけやすくし、正確な回答を提供することができます。
ステップバックプロンプトの作成
複雑なユーザークエリを単純化するもう一つの方法は、ステップバックプロンプトを作成することです。このテクニックは複雑なユーザークエリをLLMを使って"stepback questions"**に抽象化する。そして、ベクトルデータベースはこれらのステップバッククエスチョンを使って、最も関連性の高いドキュメントチャンクを検索する。最後に、LLMはこれらの検索された文書チャンクに基づいて、より正確な回答を生成する。
このテクニックを例で説明しよう。次のクエリを考えてみよう。このクエリは非常に複雑で、直接答えるのは簡単ではない:
**オリジナルのユーザークエリー:「100億レコードのデータセットがあり、Milvusに保存してクエリーしたい。可能ですか?
このユーザークエリを単純化するために、LLMを使用して、より簡単なステップバッククエリを生成することができます:
ステップバック質問"Milvusが扱えるデータセットサイズの上限は?"_。

このメソッドは、複雑なクエリに対してより正確な回答を得るのに役立ちます。元の質問をより単純な形に分解し、システムが関連情報を見つけやすくし、正確な回答を提供できるようにします。
インデックスの強化
インデックスの強化は、RAGアプリケーションのパフォーマンスを向上させるもう一つの戦略です。ここでは、3つのインデックス強化テクニックを紹介します。
ドキュメントのチャンクを自動的にマージする
インデックスを構築する際、子チャンクとそれに対応する親チャンクという2つの粒度レベルを採用することができます。最初に、より細かいレベルで子チャンクを検索します。最初のk個の子チャンクから特定の個数(n個)の子チャンクが同じ親チャンクに属する場合、この親チャンクを文脈情報としてLLMに提供する。
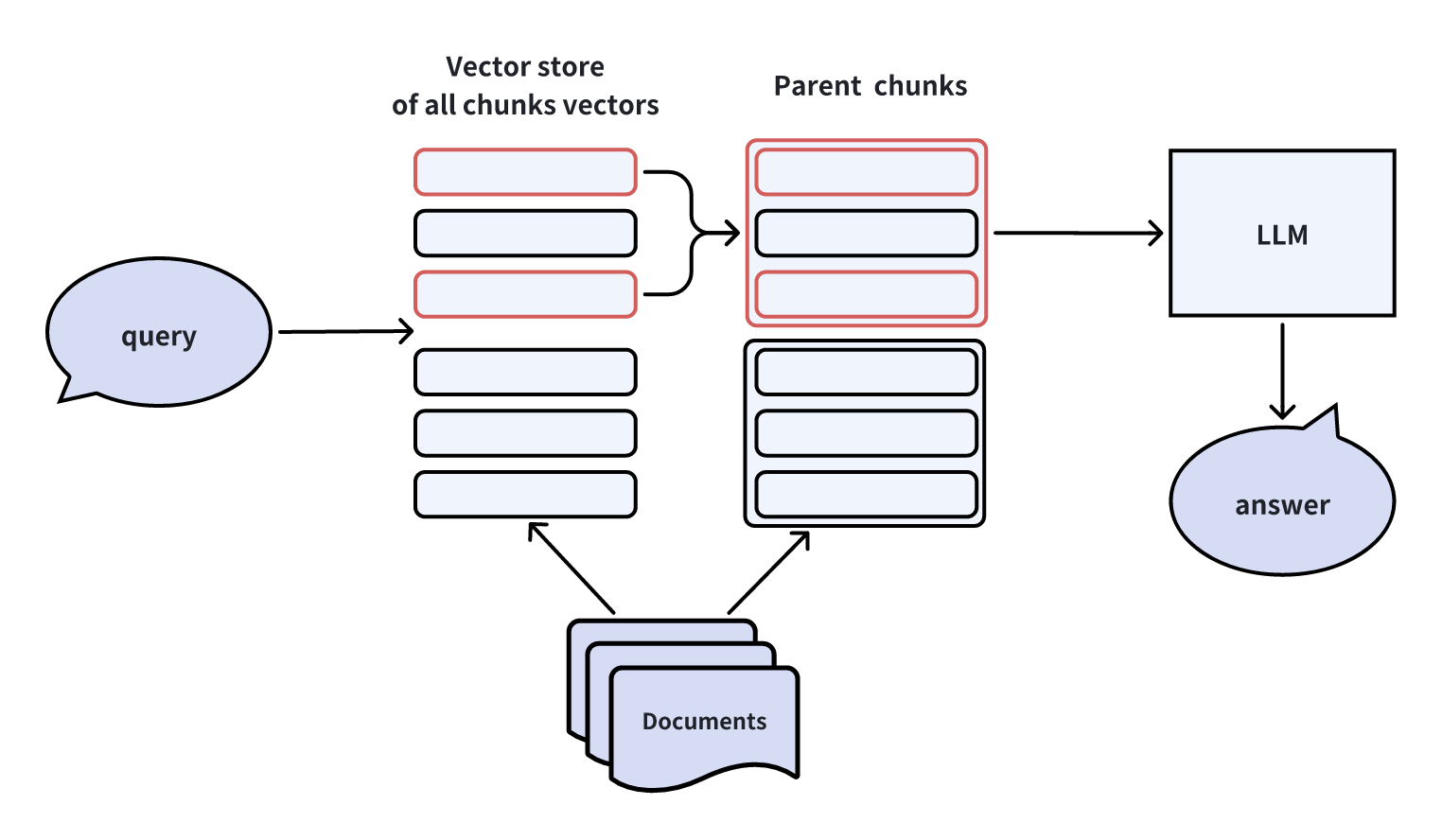
この方法はLlamaIndexで実装されています。
階層インデックスの構築
文書に対するインデックスを作成する場合、文書の要約に対するインデックスと、文書の塊に対するインデックスの2つのレベルのインデックスを構築することができる。ベクトル検索プロセスは2つの段階から構成される。まず、要約に基づいて関連文書をフィルタリングし、その後、これらの関連文書の中だけで対応する文書チャンクを検索する。
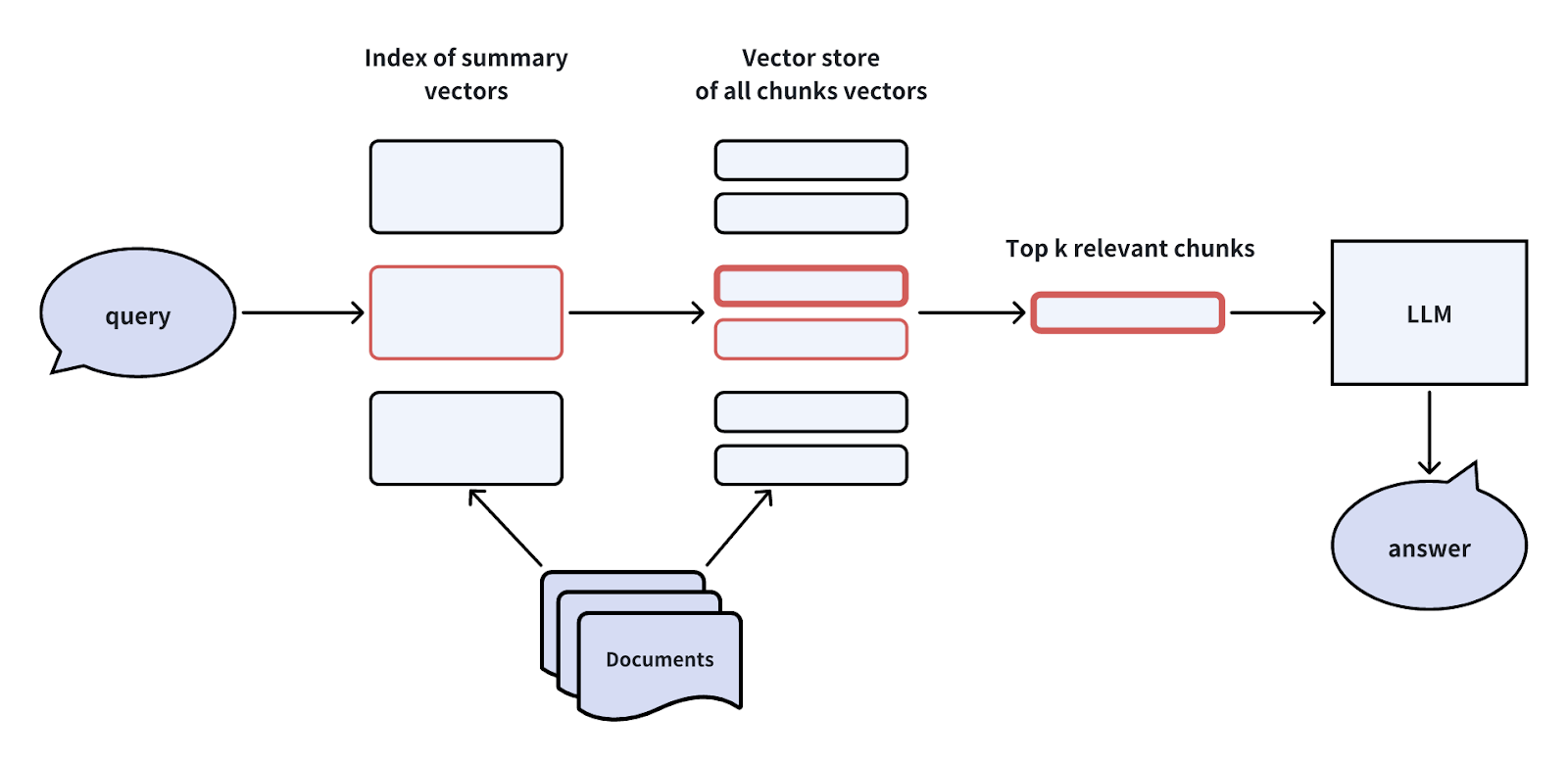
このアプローチは、膨大なデータ量や、図書館コレクション内のコンテンツ検索のようにデータが階層化されているような場合に有効である。
ハイブリッド検索と再ランク付け
ハイブリッド検索と再ランク付け技術は、1つ以上の補助的な検索方法をベクトル類似度検索と統合する。そして、リランカーが、検索された結果を、ユーザーのクエリとの関連性に基づいて再ランクする。
一般的な補助検索アルゴリズムには、BM25のような語彙頻度ベースの手法や、Spladeのようなスパース埋め込みを利用したビッグモデルがある。再ランク付けアルゴリズムには、RRFや、Cross-Encoderのような、より洗練されたモデルがあり、BERTのようなアーキテクチャに似ている。

このアプローチは、検索品質を向上させ、ベクトル想起における潜在的なギャップに対処するために、多様な検索手法を活用する。
レトリーバーの強化
RAGシステム内のレトリーバーコンポーネントを改良することで、RAGアプリケーションを改善することもできる。レトリーバーを強化するための効果的な方法をいくつか探ってみよう。
センテンスウィンドウの検索
基本的なRAGシステムでは、LLMに渡される文書チャンクは、検索された埋め込みチャンクを包含する大きなウィンドウである。これにより、LLMに提供される情報には、より広い範囲の文脈の詳細が含まれ、情報の損失を最小限に抑えることができる。センテンスウィンドウ検索技術は、埋め込み検索に使われる文書チャンクと、LLMに提供されるチャンクを切り離す。
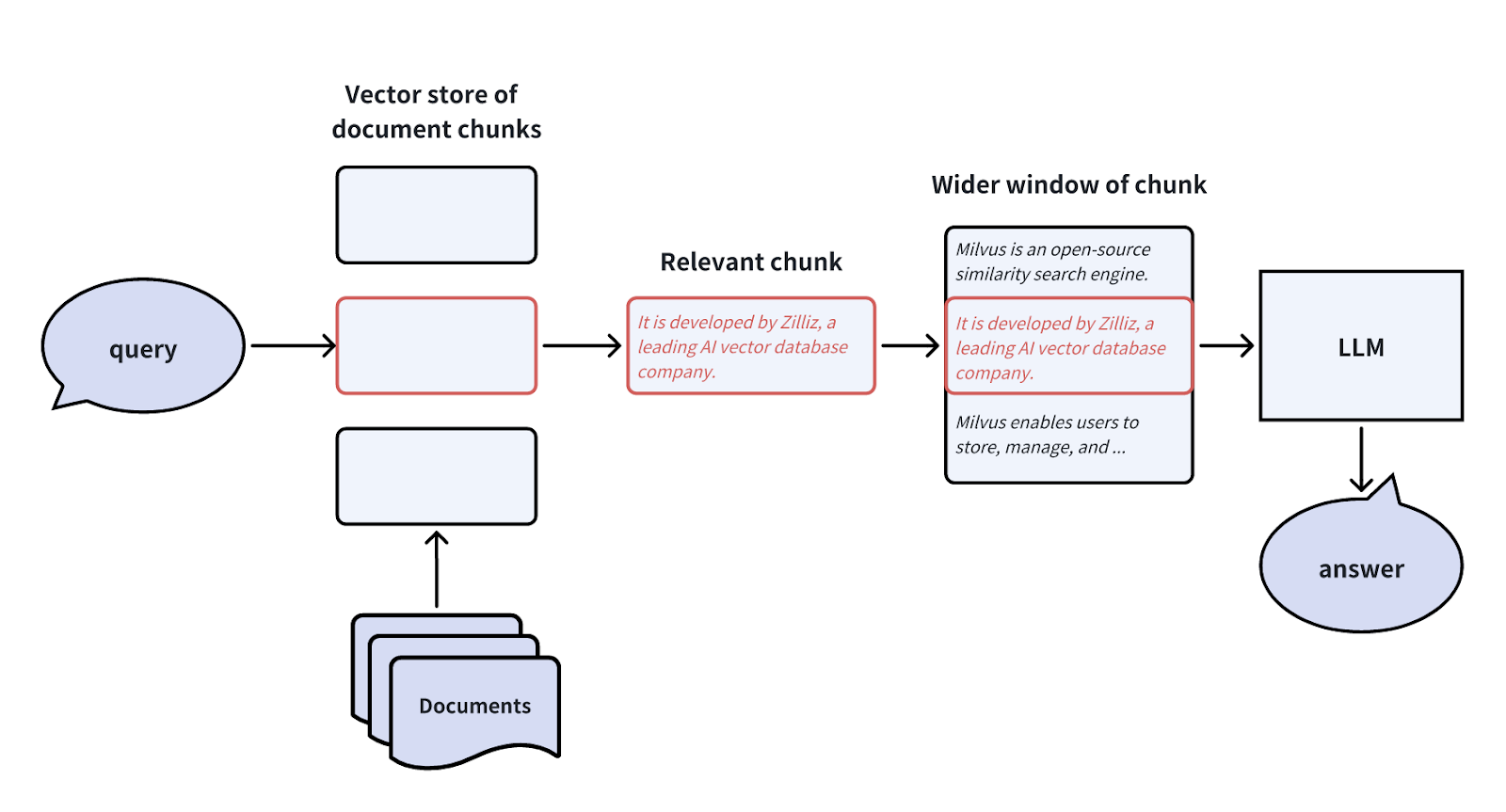
しかし、ウィンドウサイズを拡大すると、干渉する情報が追加される可能性がある。我々は、特定のビジネスニーズに基づいて、ウィンドウの拡張サイズを調整することができる。
メタデータのフィルタリング
より正確な回答を得るために、LLMに渡す前に、時間やカテゴリーなどのメタデータをフィルタリングすることで、検索されたドキュメントを絞り込むことができます。例えば、複数年にわたる財務報告書が検索された場合、希望する年に基づいてフィルタリングすることで、特定の要件を満たすように情報を絞り込むことができます。この方法は、図書館コレクションのコンテンツ検索など、広範なデータと詳細なメタデータがある状況で効果的である。
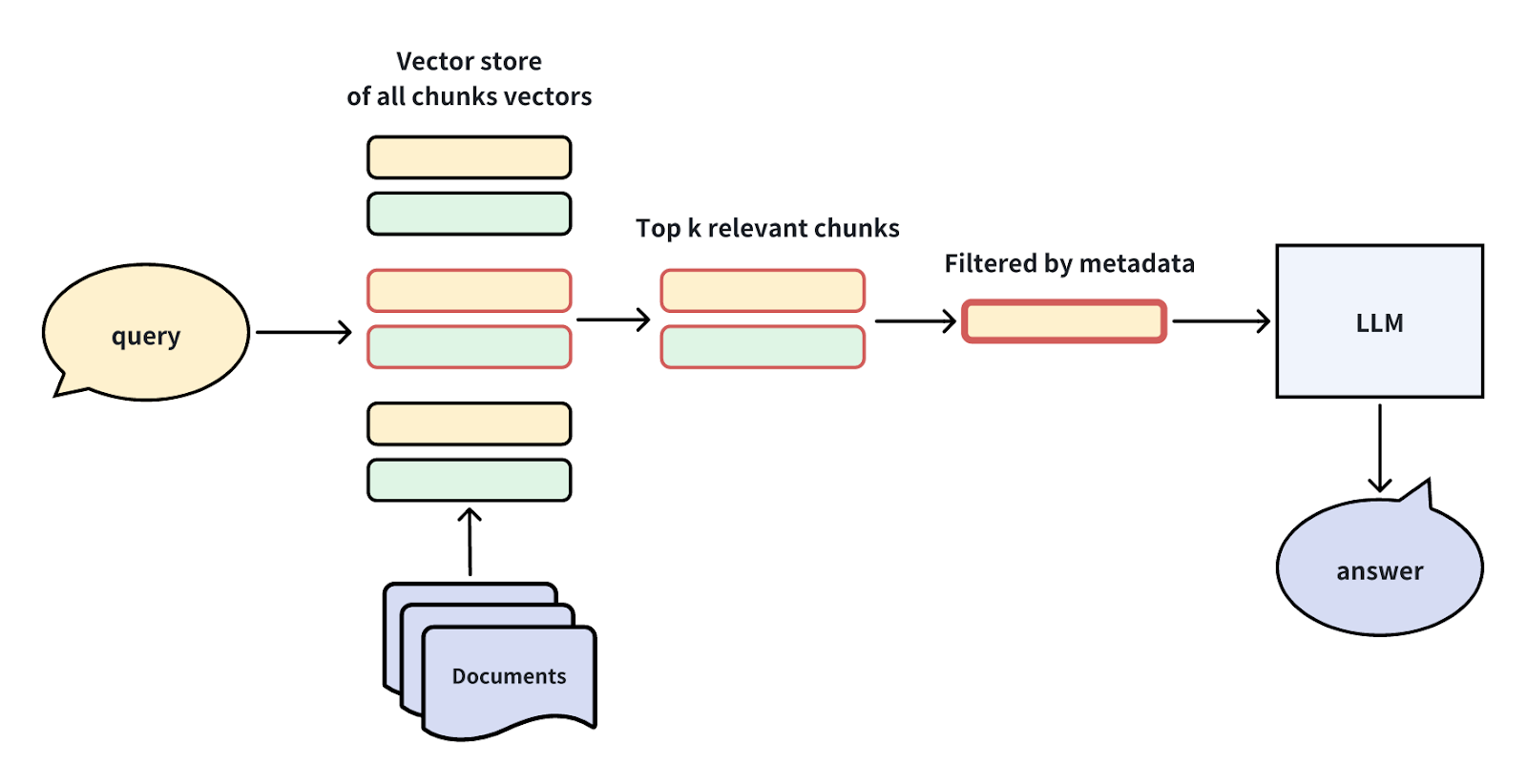
ジェネレータの強化
RAGシステム内のジェネレーターを改良することで、RAGの最適化技術をさらに探求してみよう。
LLM プロンプトの圧縮
検索されたドキュメントチャンク内のノイズ情報は、RAGの最終的な回答の精度に大きな影響を与える可能性がある。LLMの限られたプロンプトウィンドウもまた、より正確な回答のハードルとなる。この課題に対処するために、私たちは無関係な詳細を圧縮し、重要な段落を強調し、検索された文書チャンクの全体的なコンテキストの長さを減らすことができる。

このアプローチは、先に議論したハイブリッド検索とリランキング手法に似ており、リランカーを利用して無関係な文書チャンクをふるい落とす。
プロンプトのチャンク順序の調整
論文「Lost in the middle」において、研究者はLLMが推論プロセスにおいて、与えられた文書の途中の情報をしばしば見落とすことを観察した。その代わりに、彼らは文書の最初と最後に提示された情報にもっと依存する傾向がある。
複数の知識チャンクを検索する場合、相対的に信頼度の低いチャンクは真ん中に、相対的に信頼度の高いチャンクは両端に配置する。

RAG パイプラインの強化
RAGパイプライン全体を強化することで、RAGアプリケーションのパフォーマンスを向上させることも可能です。
自省
このアプローチでは、AIエージェントに自己反省の概念を取り入れています。では、この手法はどのように機能するのだろうか?
最初に検索されたTop-K文書の塊の中には曖昧なものがあり、ユーザーの質問に直接答えられない場合がある。そのような場合、2回目の内省を行い、これらのチャンクが純粋にクエリに対応できるかどうかを検証することができる。
自然言語推論(NLI)モデルのような効率的な推論手法や、検証のためのインターネット検索のような追加ツールを使って推論を行うことができる。
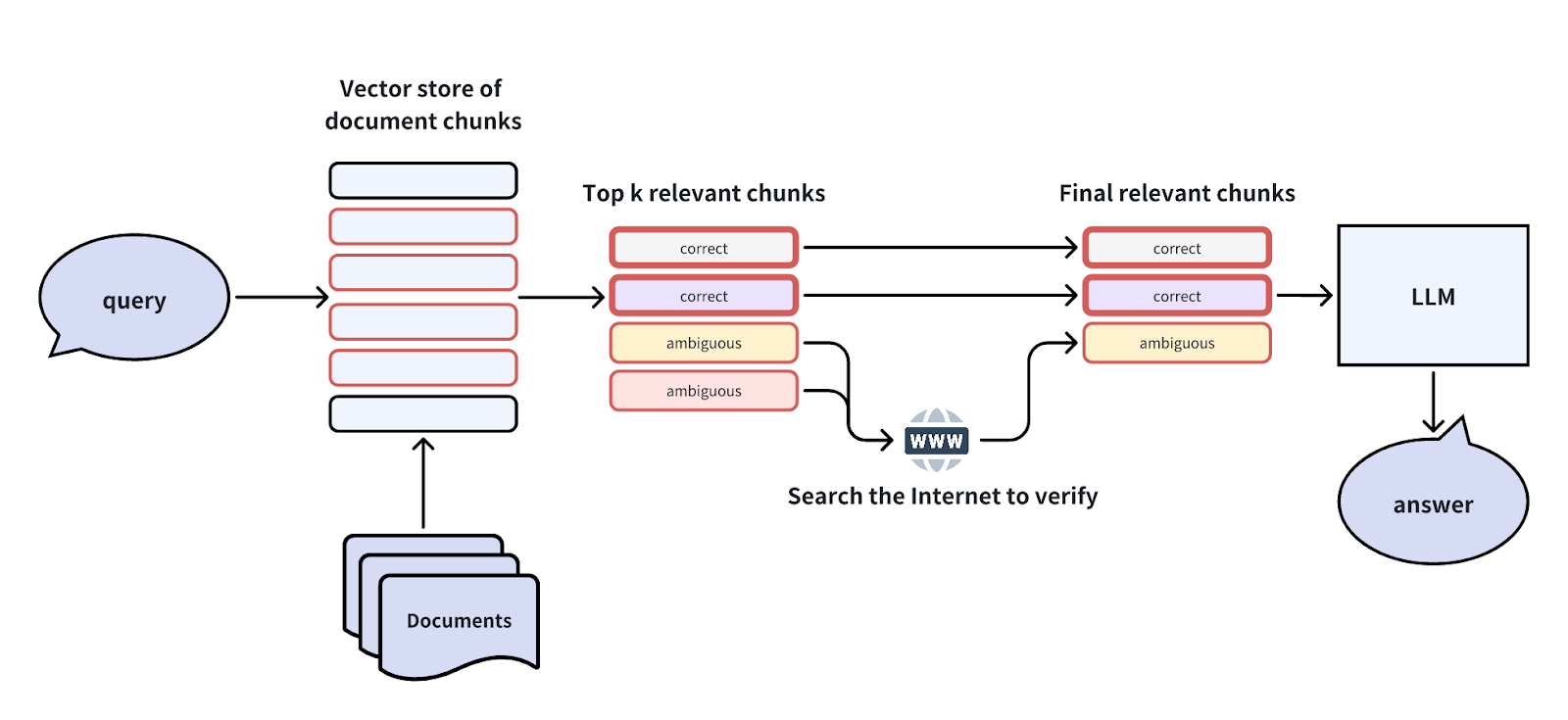
この自己反省の概念は、 Self-RAG, Corrective RAG, LangGraph などの論文やプロジェクトで研究されている。
エージェントによるクエリ・ルーティング
単純な質問に答えるためにRAGシステムを使うことは、誤解を招いたり、誤解を招くような情報から推論することになるかもしれないので、使う必要がないこともある。そのような場合、問い合わせの段階でエージェントをルーターとして使うことができる。このエージェントは、クエリがRAGパイプラインを通過する必要があるかどうかを評価する。そうでなければ、LLMが直接問い合わせに対応する。
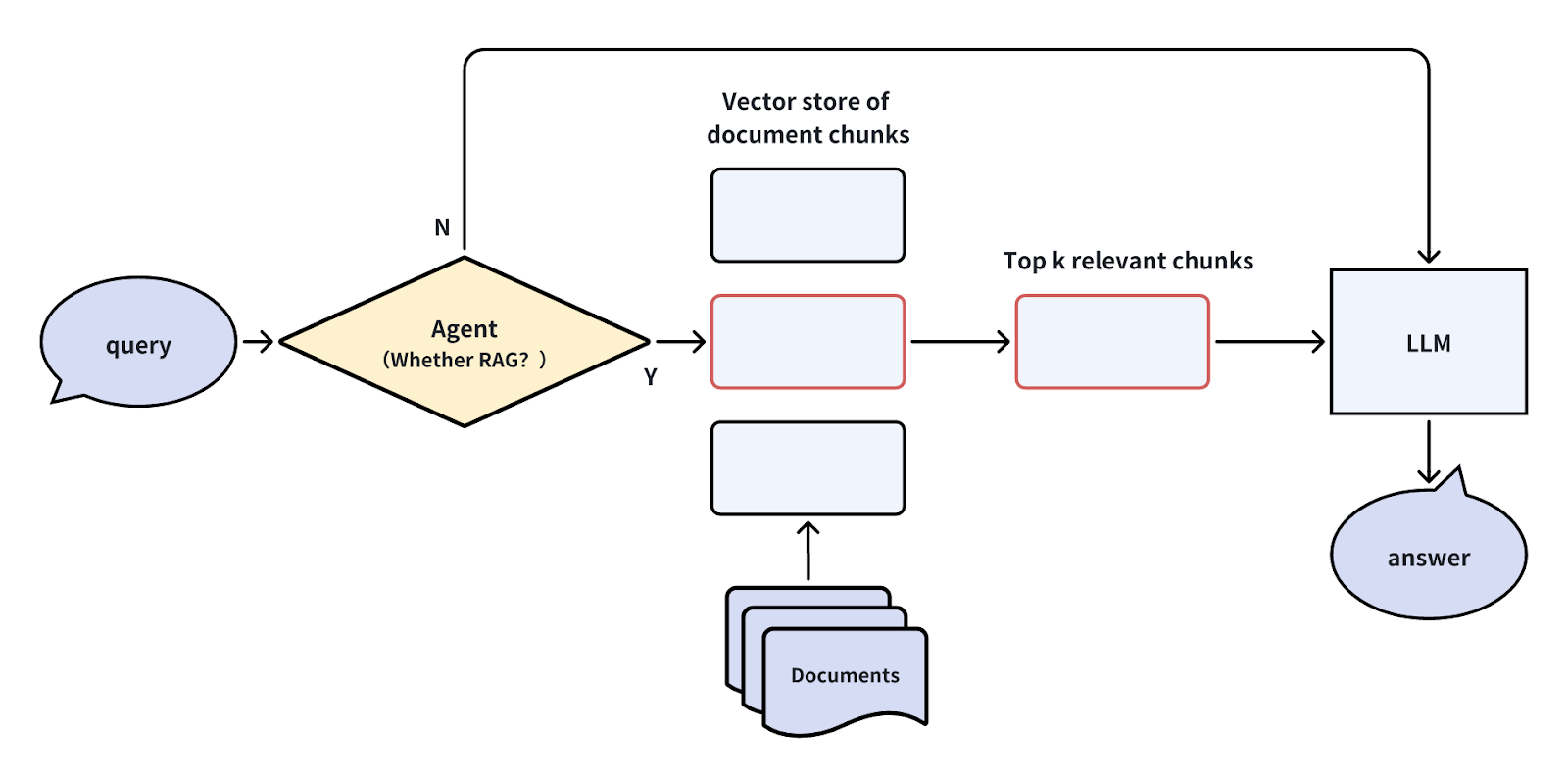
エージェントは、LLM、小さな分類モデル、あるいはルールのセットなど、様々な形をとることができる。
ユーザーの意図に基づいてクエリをルーティングすることで、クエリの一部をリダイレクトすることができ、レスポンスタイムの大幅な向上と不要なノイズの顕著な減少につながります。
クエリ・ルーティング技術をRAGシステム内の他のプロセス、例えばウェブ検索のようなツールの利用時期の決定、サブクエリの実施、画像の検索などに拡張することができる。このアプローチにより、RAGシステムの各ステップがクエリの特定の要件に基づいて最適化され、より効率的で正確な情報検索につながる。
要約
単純なRAGパイプラインはシンプルに見えるかもしれないが、最適なビジネスパフォーマンスを達成するには、より洗練された最適化技術が必要になることが多い。
この記事では、RAG アプリケーションのパフォーマンスを向上させるための一般的なさまざまなアプローチをまとめました。また、これらの概念とテクニックを素早く理解し、実装と最適化を迅速に行えるよう、分かりやすい図解も用意しました。
 Cheney Zhang
Cheney ZhangCheney Zhang is an accomplished Algorithm Engineer at Zilliz. With a profound passion for and expertise in cutting-edge AI technologies such as LLMs and Retrieval Augmented Generation (RAG), Cheney has actively contributed to many innovative AI projects, including Towhee, Akcio, and OSSChat. Before joining Zilliz, he worked for CMB Network Technology as an Algorithm Engineer. Cheney holds a master's degree from Nanjing University of Aeronautics and Astronautics.


