




ディープラーニングにおける主要なNLPテクノロジー
ディープラーニングにおける主要な自然言語処理(NLP)技術の根底にある進化と基本原理を探る。
シリーズ全体を読む
- 検索拡張ジェネレーション(RAG)でAIアプリを構築する
- LLMの課題をマスターする:検索拡張世代の探求
- ディープラーニングにおける主要なNLPテクノロジー
- RAGアプリケーションの評価方法
- リランカーによるRAGの最適化:役割とトレードオフ
- マルチモーダル検索拡張世代(RAG)のフロンティアを探る
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- RAGパイプラインのパフォーマンスを高める方法
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- Pandas DataFrame:Milvusによるチャンキングとベクトル化
- Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
- 検索拡張世代(RAG)のためのチャンキング戦略ガイド
- 仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
- Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
- RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
前節では、Retrieval Augmented Generation (RAG)技術の基本的な枠組みを簡単に紹介しました。しかし、このアプリケーションには、embeddings、Transformers、BERT、LLMなど、聞いたことはあっても理解するのに手助けが必要なキーテクノロジーがいくつか含まれています。本稿では、これらのキーテクノロジーの開発の歴史と基本原理を包括的に説明します。
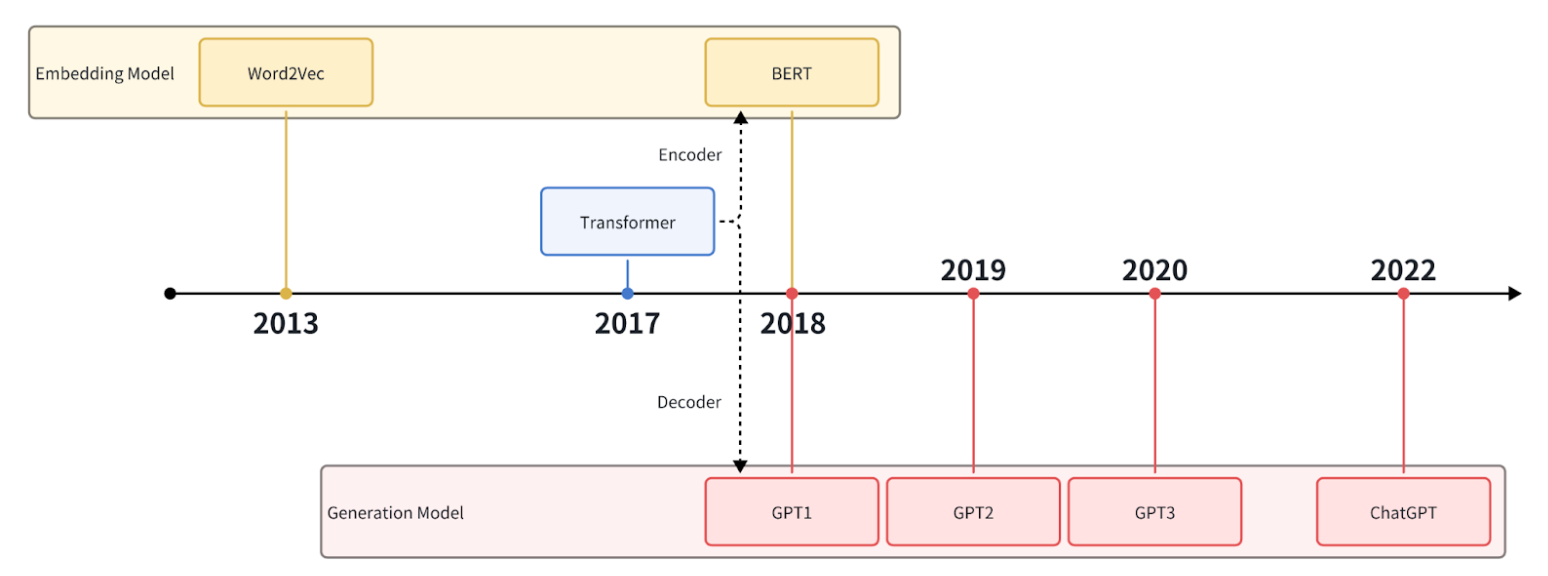
ディープラーニングの発展は、数多くの主要な自然言語処理(NLP)技術を生み出した。その中には、word2vecのような初期のモデルや、ChatGPTのような最新のモデルも含まれ、単語の埋め込みからテキスト生成まで、様々な応用がなされている。本稿では、これらの技術の応用例とその進展について紹介する。
 ChatGPTの歴史.png
ChatGPTの歴史.png
埋め込みとは?
エンベッディングとは、離散的で構造化されていないデータを連続的なベクトル表現に変換する技術です。
自然言語処理では、エンベッディングは一般的にテキストデータの単語、センテンス、ドキュメントを固定長の実数値ベクトルにマッピングするために使用されます。エンベッディングは、各単語や文を意味情報を含む実数値ベクトルで表現することができる。その結果、類似した単語や文は埋め込み空間内で類似したベクトルにマッピングされ、類似した意味情報を持つ単語や文はベクトル空間内の距離が短くなる。これにより、ベクトル間の距離や類似性を計算することで、自然言語処理における単語や文のマッチング、分類、クラスタリングなどのタスクが可能になる。
 非構造化データからベクトルへ.png
非構造化データからベクトルへ.png
Word2Vec
Word2Vecは、Googleが2013年に提唱した単語埋め込み手法です。2018年以前は、より主流な単語埋め込み手法の一つでした。Word2Vecは、単語ベクトルの古典的なアルゴリズムとして、様々な自然言語処理タスクで広く使われている。コーパスに対する学習によって単語間の意味的・構文的関係を学習し、単語を高次元空間の密なベクトルにマッピングする。Word2Vecの登場は、単語をベクトル表現に変換するパイオニアであり、自然言語処理分野の発展を広範囲に促進した。
Word2Vecモデルは、各単語をベクトルに対応付け、単語間の関係を表現することができる。下図は2次元ベクトル空間(より高次元の可能性もある)の例である。
 2次元ベクトル.png
2次元ベクトル.png
描かれた2次元空間はユニークな単語の分布を示し、意味的な関係を強調する。例えば、「男」から「女」への移行は、右上の方向にベクトルを追加することを含み、"男性性から女性性への変換 "に似ている。同様に、"Paris "を "France "に変換する構造ベクトルが観察され、これは "country-to-capital "の遷移を表している。
この興味深い現象は、埋め込み空間におけるベクトルの分布が無秩序でランダムなものではないことを示している。見かけ上の特徴は、どの地域がどのカテゴリーを表しているか、また地域間の違いを示している。このことから、ベクトルの類似性は元データの類似性を表していると結論づけられる。
したがって、ベクトル探索は、実際には元データの意味的探索を表している。ベクトル検索を使って、多くの意味的類似性検索操作を実装することができる。
しかし、初期の技術であるWord2Vecには、ある限界もある。単語とベクトルが一対一の関係であるため、多義性の問題を解決できない。例えば、以下の例における "bank "という単語は同じ意味を持たない:
...川や雨で流されないように、土手や斜面を保護するのにとても役立つ...
...その場所は川の土手から約100フィートと高かったため...
...この銀行は全国に支店を出す計画を持っている...
...彼らは番頭の首を絞めて銀行を襲った...
Word2Vecは静的メソッドであり、汎用性はあるが、特定のタスクのために動的に最適化することはできない。
トランスフォーマーの台頭
Word2Vecは単語ベクトル表現において優れた性能を発揮するが、コンテキスト間の複雑な関係を捉えることはできない。コンテキストの依存関係や意味理解をより適切に扱うために、変換モデルが導入された。
トランスフォーマーは、Googleの研究者が最初に提案し、2017年に自然言語処理タスクに適用した自己注意メカニズムに基づくニューラルネットワークモデルである。入力文の異なる位置にある単語間の関係をモデル化し、文脈情報をより適切に捉えることができる。Transformerの導入は、自然言語処理におけるニューラルネットワークモデルに大きな革新をもたらし、テキスト生成や機械翻訳などのタスクにおいて大幅な性能向上をもたらした。
当初、Transformerは機械翻訳タスクのために提案され、大幅な性能向上が達成された。このモデルは「エンコーダー」と「デコーダー」で構成され、エンコーダーは入力言語シーケンスを一連の隠れ表現にエンコードし、デコーダーはこれらの隠れ表現をターゲット言語シーケンスにデコードする。各エンコーダーとデコーダーは、多層の自己注意機構とフィードフォワード神経回路網で構成されている。
従来のCNN(畳み込みニューラルネットワーク)やRNN(リカレントニューラルネットワーク)に比べ、Transformerは自己保持機構により全ての入力位置を同時に計算できるため、より効率的な並列計算を実現できる。同時に、CNNとRNNは逐次計算を必要とする。従来のCNNやRNNは、長距離の依存関係を扱うことが困難であったが、Transformerは自己注意メカニズムを用いて長距離の依存関係を学習する。
大規模なタスクにおけるオリジナルのTransformerモデルの卓越した性能のため、研究者は性能を向上させるためにそのサイズを調整する試みを始めた。モデルの深さ、幅、パラメーターの数を増やすことで、Transformerは入力シーケンス間の関係とパターンをよりよく捉えることができることを発見した。
Transformerのもう一つの重要な発展は、大規模な事前学習済みモデルの出現である。大量の教師なしデータで学習することで、事前学習済みモデルは、より豊富な意味的・構文的特徴を学習し、下流のタスクで微調整を行うことができる。このような事前学習済みモデルには、BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)などがあり、様々な自然言語処理タスクで劇的な成功を収めている。
トランスフォーマーの開発は、人工知能に大きな変革をもたらした。例えば、エンコーダ部分は、BERTシリーズや様々な埋め込みモデルへと発展した。デコーダ部はGPTシリーズに発展し、現在のChatGPTを含むLLM(Large Language Model)の革命をもたらした。
BERTと文埋め込み
TransformerのEncoder部分は、BERTへと発展しました。 BERTは2段階の事前学習法を採用しています:マスク言語モデル(MLM)と次文予測(NSP)である。MLM 段階では、BERT は、シーケンス全体の文脈を理解するために、マスクされた語彙を予測する。NSP 段階では、BERT は、文の関係を理解するのに役立つように、2 つの文が連続しているかどうかを判断する。これら 2 つの段階における事前学習により、BERT は強力な意味学習能力を持ち、様々な自然言語処理タスクで優れた性能を発揮することができる。
BERT の重要な応用の 1 つは文の埋め込みで、これは文の埋め込みベクトルを生成する。このベクトルは、文の類似度計算、テキスト分類、センチメント分析など、様々な下流の自然言語処理タスクに使用することができる。文埋め込みを使用すると、文を高次元空間のベクトル表現に変換することができ、コンピュータが文の意味論 を理解し表現できるようになる。
従来の単語埋め込みベースの手法と比較して、BERT の文埋め込みは、より多くの意味情報と文レベルの関係を捕捉することができる。文全体を入力とすることで、このモデルは、文内の単語間の文脈的関係や文間の意味的関連性を包括的に考慮することができる。これにより、自然言語処理タスクを解くための、よりロバストで柔軟なツールが提供される。
単語頻度に基づく検索よりも埋め込み検索の方が有効な理由
単語頻度検索に基づく従来のアルゴリズムには、TF-IDFやBM25がある。単語頻度検索は、テキスト中の単語の頻度のみを考慮し、単語間の意味的関係を無視します。一方、埋め込み検索は、各単語をベクトル空間のベクトル表現にマッピングし、単語間の意味的関係を把握する。そのため、検索時に単語間の類似度を計算し、関連するテキストをより正確にマッチングさせることができる。
単語頻度検索は完全一致しかできないため、同義語や意味的に関連する単語には不向きである。これに対して、埋め込み検索は、単語間の類似度を計算することで、同義語や意味的に関連する単語のファジーマッチングを実現し、検索のカバー率と精度を向上させることができる。埋め込み検索は、単語間の意味的関係をよりよく利用することができ、検索結果の精度とカバー率を向上させ、頻度ベースの検索よりも良い結果をもたらす。
単語頻度ベースの検索方法を使うと、「cat」と検索した場合、「cat」という単語の頻度が高い記事が検索結果で上位にランクされる可能性がある。しかし、この方法では、"cat "と他の動物、例えば "British Shorthair "や "Ragdoll "との意味的な関係は考慮されない。一方、埋め込み検索を使えば、単語を高次元空間のベクトルにマッピングすることができ、意味的に似た単語ほど距離が近くなる。私たちが「猫」と検索すると、埋め込み検索は「ブリティッシュショートヘア」や「ラグドール」のような意味的に類似した単語を見つけ出し、これらの単語に関連する記事を検索結果の上位にランク付けすることができる。これにより、より正確で関連性の高い検索結果が得られる。
大規模言語モデルの開発
LLMとは
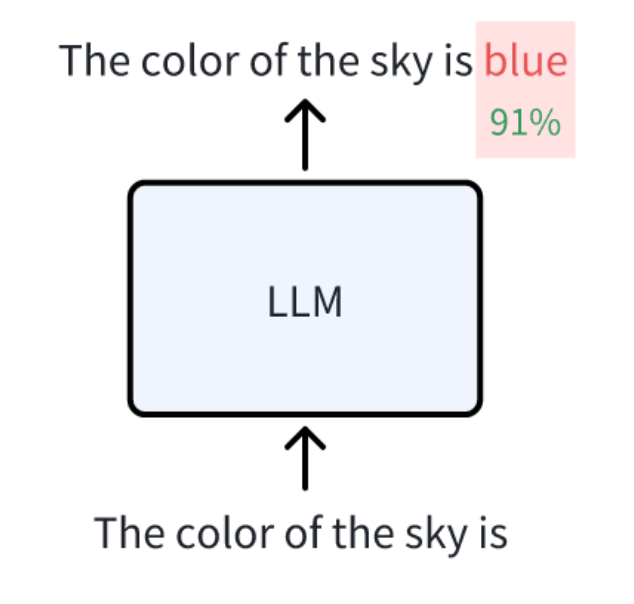
現在、ほとんどの大規模言語モデル(LLM)は、GPTのような「デコーダのみ」のTransformerアーキテクチャから派生している。Transformerエンコーダのみを使用するBERTのようなモデルに比べ、デコーダのみを使用するLLMは、一定の文脈的意味合いを持つテキストを生成することができる。
言語モデルの学習タスクは、過去の文脈に基づいて次の単語の確率を予測することである。継続的に予測し、次の単語を追加することで、モデルはより正確で流暢な予測を得ることができる。この学習プロセスにより、言語モデルは言語パターンと文脈情報をよりよく理解し、自然言語処理能力を向上させることができる。
 空の色.png
空の色.png
GPT-1からGPT-3まで
GPTシリーズは、2018年からOpenAIが開発したLLMモデルを継続的に反復・改良したものです。
初期バージョンであるGPT-1では、長文を生成する際に意味的な支離滅裂さや繰り返しの問題があった。2019年にリリースされたGPT-2は、GPT-1をベースにいくつかの改良を加えることで、これらの問題に対処した。これらの改善には、より大規模な訓練データの使用、より深いモデル構造、より多くの訓練反復が含まれる。GPT-2では、生成されるテキストの品質と一貫性が大幅に向上し、ゼロショット学習の機能が導入されたことで、未見のタスクに対しても推論してテキストを生成できるようになった。GPT-3は、GPT-2をベースにモデルの規模と機能をさらに強化・拡張した。1,750億ものパラメータを持つGPT-3は、強力な生成能力を持ち、より長く、より論理的で、一貫性のあるテキストを生成することができます。また、GPT-3では、文脈の理解と推論能力をさらに向上させ、問題をより深く分析し、より正確な解答を提供できるようになりました。
| GPT-1、GPT-2、GPT-3 |---------|---------|----------|----------| | パラメータ|1億1700万個|15億個|1750億個 | デコーダーレイヤー|12|48|96 | コンテキスト・トークン・サイズ|512|1024|2048 | 隠しレイヤー|768|1600|12288 | バッチサイズ|64|512|3.2M | プレトレーニングデータセットサイズ|5GB|40GB|45TB
GPT-1からGPT-3まで、OpenAIの言語生成モデルは、データ規模、モデル構造、トレーニング技術において大幅な改善を行い、より高品質で、より論理的で、一貫性のあるテキスト生成機能を実現しました。OpenAIがGPT-3を開発した際、これまでのLLMと比較していくつかの明確な効果を示しました。GPT-3には以下のような能力があります:
- 言語補完:言語補完:プロンプトが与えられると、GPT-3はプロンプトを補完する文章を生成することができる。
- 文脈内学習**:与えられたタスクに関連するいくつかの例に従って、GPT-3はそれらを参照し、新しいユースケースのための同様の応答を生成することができます。文脈内学習は、数ショット学習としても知られている。
- 世界の知識**:これは事実知識と一般的な知識を含む。
チャットGPT
2022年11月、OpenAIはほとんどの質問に答えることができるチャットボット、ChatGPTをリリースした。その性能は素晴らしく、ドキュメントの要約、翻訳、コードの記述、あらゆる種類のテキストの下書きに使うことができる。いくつかのツールの助けを借りれば、食べ物の注文やフライトの予約、コンピュータの乗っ取り支援など、これまで想像もつかなかったような仕事をこなすこともできる。
この強力な機能の背後には、モデルと人間との会話の満足度を高める、人間フィードバックからの強化学習(RLHF)のような技術のサポートがある。RLHFは、人間のフィードバックを利用してモデルの出力を人間の好みに合わせる強化学習法である。具体的なプロセスとしては、与えられたプロンプトに基づいて複数の回答候補を生成し、人間の評価者にこれらの回答をランク付けしてもらい、これらのランク付け結果を使用してプリファレンス・モデルをトレーニングし、人間の好みを反映したスコアを回答に割り当てる方法を学習し、最後にプリファレンス・モデルを使用して言語モデルを微調整します。これがChatGPTが便利な理由です。GPT-3と比較すると、ChatGPTはさらに進化し、強力な機能を解き放ちます:
- 人間の指示への対応**:GPT-3の出力は、たとえそれが命令であっても、通常はプロンプトから続きます。GPT-3はより多くの命令を生成するかもしれませんが、ChatGPTはこれらの命令に効果的に答えることができます。
- コード生成と理解**:ChatGPTは高品質で実行可能なコードを生成することができます。
- 思考の連鎖による複雑な推論**:GPT-3の初期バージョンは、思考連鎖推論の機能が弱いか、全くありませんでした。この機能により、ChatGPTはより高いレベルのアプリケーションにおいて、プロンプト・エンジニアリングによってより堅牢で正確なものになります。
- 詳細な応答ChatGPTの回答は一般的に詳細で、ユーザーはより簡潔な回答を受け取るために「簡潔な回答をください」と明示的に要求しなければならないほどです。
- 公平な回答**:ChatGPTは通常、複数の関係者の関心を扱う場合、すべての人が満足することを目指し、バランスの取れた回答を提供します。また、不適切な質問には回答しません。
- 例えば、2021年6月以降に発生した事象に関する質問には、それ以降のデータを学習していないため、回答を拒否します。また、トレーニングデータで見たことのない質問に対する回答も拒否します。
しかし、ChatGPTには現在いくつかの制限があります:
- 数学的能力が比較的低い**:ChatGPTの数学的能力はもっと優れているはずです。複雑な数学的問題や高度な数学的概念を扱うと、混乱したり、不正確な答えを出したりすることがあります。
- 幻覚を見ることがある:ChatGPTは幻覚を見ることがあります。現実世界に関連する問題に答えるとき、誤った、あるいは不正確な情報を提供することがあります。これは、トレーニング中に不正確な例や誤解を招くような例に遭遇し、特定の質問に対する答えがずれてしまうことが原因である可能性があります。
- リアルタイムで知識を更新できない**:ChatGPTはリアルタイムで知識を更新することができません。人間のように継続的に学習し、最新の情報を取得することはできません。このため、ニュース報道や金融市場分析など、タイムリーな情報更新が必要な分野での応用には限界があります。
幸いなことに、私たちはRAG(Retrieval Augmented Generation:検索拡張世代)技術を使って、この2つの限界-幻覚の生成とリアルタイムでの知識更新ができないこと-に対処することができる。RAGはベクトル・データベースと言語モデル(LLM)を組み合わせたもので、RAGの導入と最適化技術については他の記事を参照していただきたい。
ディープラーニングにおけるNLPのまとめ
本記事では、特にNLPにおけるディープラーニングの現在の主流モデルと応用例を、埋め込みから紹介します。初期のWord Embeddingから現在のChatGPTの人気まで、AIの開発は急速に進んでいます。継続的な技術の進歩と豊富なデータにより、さらに強力なモデルの出現が期待できる。ディープラーニングの応用はさらに広まり、自然言語処理だけでなく、視覚や音声など他の分野にも広がっていくだろう。技術のブレークスルーと社会の進歩により、私たちは今後さらにエキサイティングな進歩とイノベーションを目撃することになるだろう。
 Cheney Zhang
Cheney ZhangCheney Zhang is an accomplished Algorithm Engineer at Zilliz. With a profound passion for and expertise in cutting-edge AI technologies such as LLMs and Retrieval Augmented Generation (RAG), Cheney has actively contributed to many innovative AI projects, including Towhee, Akcio, and OSSChat. Before joining Zilliz, he worked for CMB Network Technology as an Algorithm Engineer. Cheney holds a master's degree from Nanjing University of Aeronautics and Astronautics.
読み続けて

マルチモーダル検索拡張世代(RAG)のフロンティアを探る
マルチモーダルRAGは、テキスト、画像、音声、動画など様々なデータタイプを含むマルチモーダルデータを取り入れた拡張RAGフレームワークである。

ChatGPTをMilvusで強化する:長期記憶でAIを強化する
GPTCacheとMilvusをChatGPTと統合することで、企業はより強固で効率的なAIを活用したサポートシステムを構築することができる。このアプローチは、ジェネレーティブAIの高度な機能を活用し、長期記憶の形式を導入することで、AIが効率的に情報を呼び出し、再利用することを可能にします。

検索拡張世代(RAG)のためのチャンキング戦略ガイド
このガイドでは、RAG(Retrieval-Augmented Generation)システムにおけるチャンキング戦略の様々な側面を探った。