




リランカーによるRAGの最適化:役割とトレードオフ
再ランカーは、RAGシステムにおける回答の精度と関連性を高めることができるが、こうした利点には待ち時間と計算コストの増加が伴う。
シリーズ全体を読む
- 検索拡張ジェネレーション(RAG)でAIアプリを構築する
- LLMの課題をマスターする:検索拡張世代の探求
- ディープラーニングにおける主要なNLPテクノロジー
- RAGアプリケーションの評価方法
- リランカーによるRAGの最適化:役割とトレードオフ
- マルチモーダル検索拡張世代(RAG)のフロンティアを探る
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- RAGパイプラインのパフォーマンスを高める方法
- ChatGPTをMilvusで強化する:長期記憶でAIを強化する
- Pandas DataFrame:Milvusによるチャンキングとベクトル化
- Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
- 検索拡張世代(RAG)のためのチャンキング戦略ガイド
- 仮説的文書埋め込み(HyDE)による情報検索とRAGの改善
- Milvus Lite、Llama3、LlamaIndexを使ったRAGの構築
- RA-DITによるRAGの強化:LLM幻覚を最小化する微調整アプローチ
#RAGの基本
検索補強型生成(RAG)は、大規模言語モデル(LLMに追加の最新知識を供給することで、その能力を強化する新進AIスタックである。標準的なRAGアプリケーションは、4つの主要な技術コンポーネントで構成されている:
外部文書とユーザークエリをベクトル埋め込みに変換する埋め込みモデル、
ベクトルデータベース](https://zilliz.com/learn/what-is-vector-database)は、これらの埋め込みを保存し、トップKの最も関連性の高い情報を検索する、
プロンプト-アズ-コード](https://zilliz.com/glossary/prompt-as-code-(prompt-engineering))は、ユーザークエリと検索されたコンテキストの両方を結合する、
回答を生成するためのLLM。
Zilliz Cloudのようないくつかのベクトルデータベースは、組み込み埋め込みパイプラインを提供し、ドキュメントとユーザークエリを自動的に埋め込みに変換し、RAGアーキテクチャを効率化する。
基本的なRAGのセットアップは、モデルの応答をドメイン固有または独自のコンテキストに基づかせることで、LLMが信頼できないまたは'幻覚'のコンテンツを生成するという問題に効果的に対処する。しかし、企業ユーザーの中には、生産ユースケースでより高いコンテキストの関連性を必要とし、より洗練されたRAGセットアップを求める人もいる。ますます普及しているソリューションの一つは、RAGシステムにリランカーを統合することである。
リランカーとは?
リランカーは情報検索(IR)のエコシステムにおいて重要なコンポーネントであり、特定のクエリとの関連性を高めるために、検索結果や文章を評価し、並べ替えます。RAGでは、このツールは一次ベクトル近似最近傍(ANN)検索を基に構築され、文書とクエリ間の意味的関連性をより効果的に決定することで検索品質を向上させます。
再ランカーは主に2つのカテゴリーに分類される:**スコアベースとニューラルネットワークベースである。
スコアベースの再ランカーは、さまざまなソースから複数の候補リストを集約し、重み付けスコアリングやRRF(Reciprocal Rank Fusion)を適用して、元のリストにおけるスコアや相対的な位置に基づいて、これらの候補を単一の優先順位付きリストに統一し、並べ替えることで機能する。このタイプのリランカーはその効率の良さで知られており、その軽量性から従来の検索システムで広く使われている。
一方、ニューラルネットワークベースのリランカーは、しばしばクロスエンコーダーリランカーと呼ばれ、クエリと文書の関連性を分析するためにニューラルネットワークを活用する。これらは特に、2つの間の意味的な近接性を反映する類似性スコアを計算するように設計されており、単一または複数のソースからの結果の洗練された並べ替えを可能にする。この方法により、より意味的な関連性が確保されるため、有用な検索結果が提供され、検索システムの全体的な有効性が向上する。
##リランカーはRAGアプリをどのように強化しますか?
リランカーをRAGアプリケーションに組み込むことで、生成される回答の精度を大幅に向上させることができます。文脈が短くなるため、LLMは文脈のすべてに「参加」しやすくなり、集中力が途切れるのを防ぐことができます。
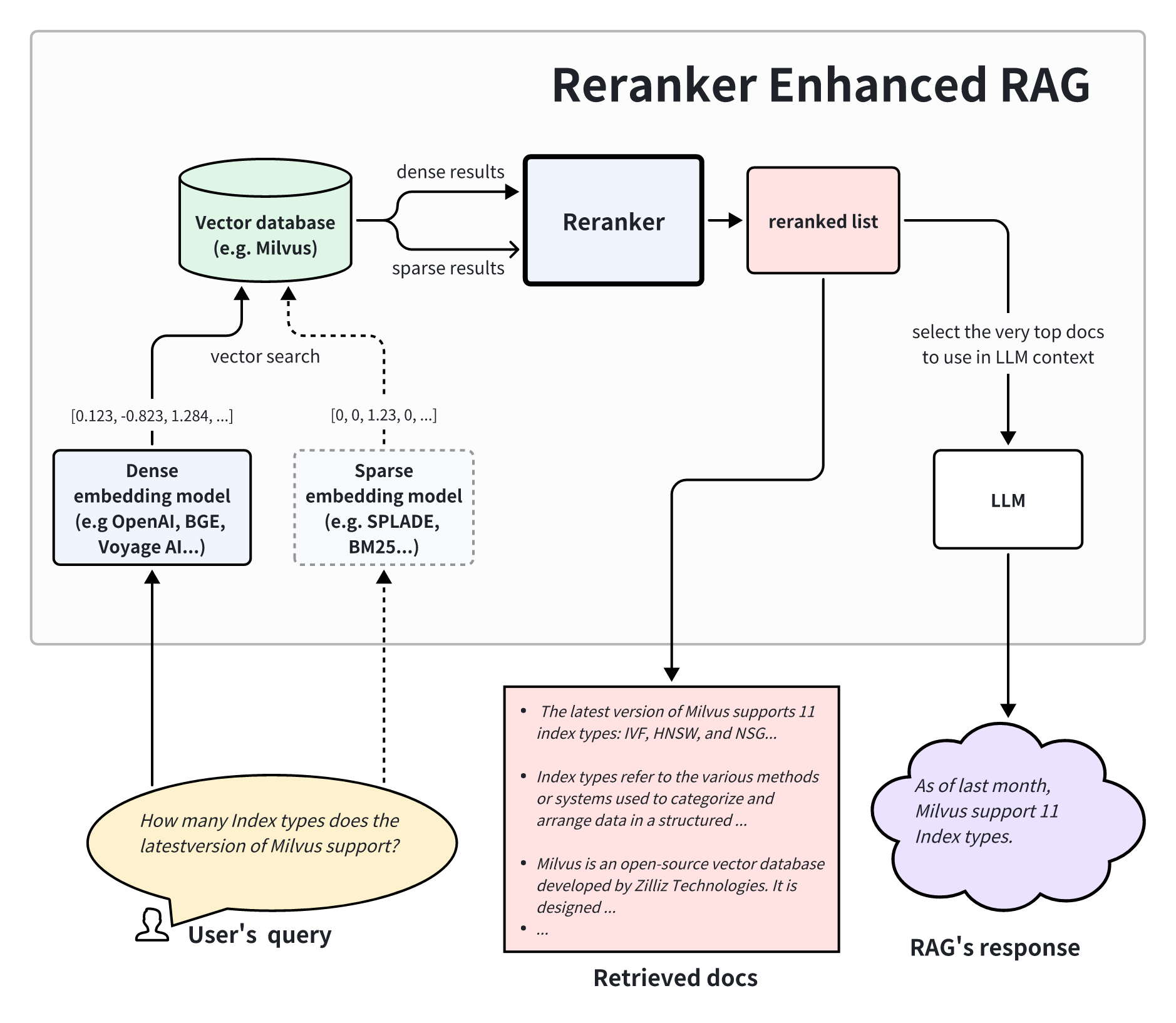
上記のアーキテクチャは、リランカーを強化したRAGが2段階の検索システムを含むことを示している。第一段階では、ベクトル・データベースがより大きなデータセットから関連文書の集合を検索する。次に第2段階では、リランカーがクエリとの関連性に基づいてこれらの文書を分析し、優先順位をつける。最後に、再ランク付けされた結果は、より質の高い回答を生成するためのより関連性の高いコンテキストとしてLLMに送られる。
とはいえ、RAGフレームワークにリランカーを統合するには、課題や費用が伴う。リランカーを追加するかどうかを決定するには、ビジネスニーズを徹底的に分析し、潜在的な待ち時間と計算コストの増加に対する検索品質の向上のバランスを取る必要がある。
リランカーの隠れた価格
リランカーはRAGシステムにおいて検索された情報の関連性を高めることができますが、このアプローチには代償が伴います。
再ランカーは検索待ち時間を大幅に増加させる
リランカーを使用しない基本的なRAGシステムでは、ユーザーがクエリを実行する前に、ドキュメントのベクトル表現が前処理され、保存される。その結果、システムはcosine similarityのようなメトリクスに基づいてトップKの文書を特定するために、比較的安価な近似最近傍(ANN)ベクトル検索を実行するだけでよい。Zilliz Cloudのようなプロダクショングレードのベクトルデータベースでは、ベクトル検索はミリ秒しかかからない。
対照的に、リランカー、特にクロスエンコーダは、ディープニューラルネットワークを介してクエリと各候補文書を処理する必要があります。モデルのサイズやハードウェアの仕様にもよりますが、この処理には数百ミリ秒から数秒と大幅に時間がかかります。リランカーを強化したRAGは、最初のトークンを生成する前に、それだけの時間を要することになる。
リランカーは計算コストが高い
基本的なRAGワークフローのオフライン・インデックス作成では、文書ごとに1回ニューラルネットワーク処理の計算コストが発生するが、リランカーでは、結果セットの各潜在文書に対するクエリごとに同様のリソースを費やす必要がある。この反復的な計算コストは、ウェブや電子商取引の検索プラットフォームのようなトラフィックの多いIR設定では、法外なものになる可能性がある。
リランカーがいかにコストがかかるかを理解するために、簡単な計算をしてみよう。
VectorDBBench](https://zilliz.com/learn/open-source-vector-database-benchmarking-your-way)のstatisticsによると、毎秒200クエリ(QPS)以上のクエリを処理するベクターデータベースでは、月額利用料がわずか100ドルで、1クエリあたり0.0000002ドルです。これに対して、リランカーを使って第1段階で検索された文書から上位100件を並び替えると、1件あたり0.001ドルものコストがかかります。これは、ベクトル検索のコストと比較すると、5,000倍の増加です。
ベクトルデータベースは常に最大限のクエリ容量で動作するとは限らず、再順序付けはより少ない結果数(例えば上位10件)に制限されるかもしれないが、それでもクロスエンコーダー再順序付けを採用する費用は、ベクトル検索のみの検索アプローチよりも桁高い。
別の角度から見ると、リランカーを使用することは、クエリ時間中にインデックス作成コストが発生することに等しい。推論コストは、入力サイズ(トークン)とモデルサイズに関連している。エンベッディングモデルとリランカーモデルの両方が通常数百MBから数GBであることを考えると、両者は同等であると仮定しよう。1文書あたり平均1,000トークンで、1クエリあたりわずか10トークンだとすると、上位10文書をクエリと一緒に再ランクすることは、1文書のインデックスを作成する計算コストの10倍に相当する。つまり、1,000万ドキュメントのコーパスに対して100万クエリを提供することは、コーパス全体のインデックスを作成するのと同じだけの計算パワーを消費することになり、トラフィックの多いユースケースでは現実的ではない。
コスト分析:基本RAG < 再ランカー強化RAG < 純粋LLM
リランカーを強化したRAGは、基本的なベクトル検索ベースのRAGよりもコストがかかるが、回答を生成するためにLLMだけに頼るよりも大幅にコスト効率が高い。RAGのフレームワークでは、リランカーはベクトル検索からの予備的な結果をふるいにかけ、クエリとの関連性が弱い文書を破棄する役割を果たす。このプロセスは、LLMが余計な情報を処理するのを防ぐことで、時間とコストを削減する。
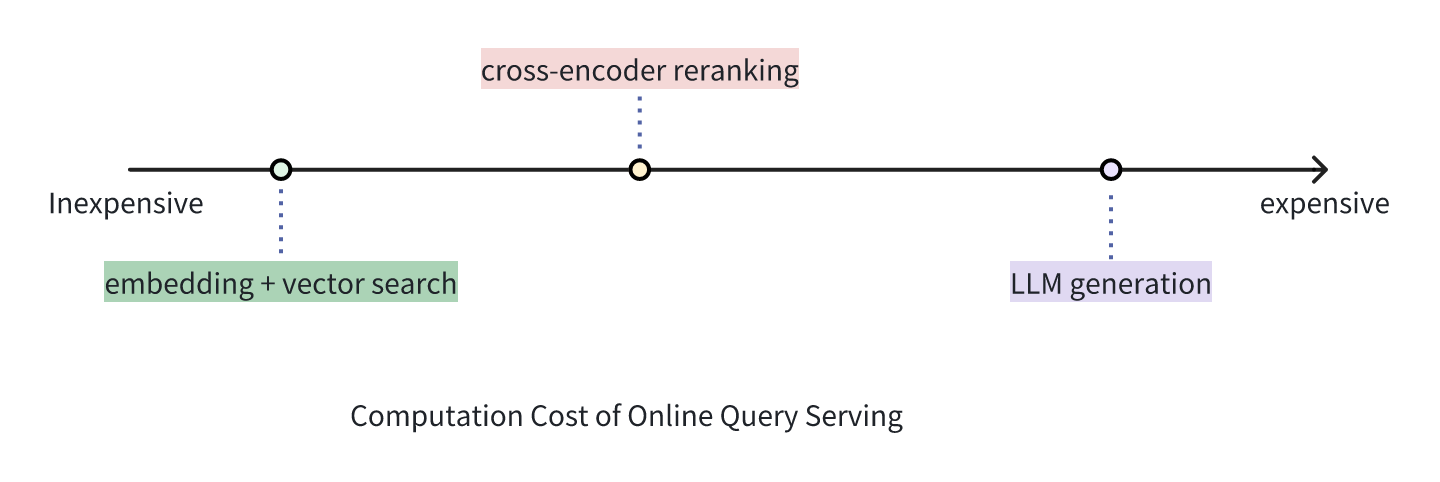
実世界の例を挙げよう:ベクトル検索エンジンのような第一段階の検索は、何百万もの候補を素早くふるいにかけ、最も関連性の高い上位20文書を特定する。リランカーは、よりコストがかかるが、その後、順序を再計算し、トップ20のリストを5つに絞り込む。最終的には、最も高価な大規模言語モデル(LLM)が、クエリとともに上位5つの文書を分析し、レイテンシーとコストのバランスをとりながら、包括的で高品質なレスポンスを作成する。
このように、リランカーは、効率的だが近似的な最初の検索段階と、高コストのLLM推論段階との間の重要な仲介役を果たす。
リランカーをRAGシステムに組み込むタイミング
リランカーをRAG(Retrieval-Augmented Generation)のセットアップに組み込むことは、専門的な知識ベースやカスタマーサービスシステムなど、回答の高い精度と関連性が重要な場合に有益である。このような設定では、各クエリが高いビジネス価値を持ち、情報のフィルタリングの精度が向上するため、リランカーの追加コストと待ち時間が正当化されます。リランカーは、最初のベクトル検索結果を改良し、ラージ・ランゲージ・モデル(LLM)が正確な回答を生成するためにより関連性の高いコンテキストを提供し、全体的なユーザー・エクスペリエンスを向上させます。
しかし、ウェブや電子商取引の検索エンジンのようなトラフィックの多いユースケースでは、迅速なレスポンスとコスト効率が最優先されるため、クロスエンコーダー・リランカーを使用するよりも良い選択肢があるかもしれない。計算負荷の増大と応答時間の低下は、ユーザーエクスペリエンスと運用コストに悪影響を及ぼす可能性がある。このような場合、効率的なベクトル検索のみ、あるいは軽量なスコアベースのリランカーを使用した基本的なRAGアプローチが、許容可能なレベルの精度と関連性を維持しながら、速度とコストのバランスを取るために好まれる。
RAGアプリケーションにリランカーを適用することを決定した場合、Zilliz Cloud Pipelines内で簡単に有効化したり、Milvusでリランカーモデルを使用することができます。
まとめ
再ランカーは検索結果を改良し、検索補強生成(RAG)システムにおける回答の精度と関連性を向上させ、コストとレイテンシが柔軟で精度が重要なシナリオで価値を発揮します。しかし、その利点は、待ち時間の増加や計算コストなどのトレードオフを伴い、トラフィックの多いアプリケーションには適していない。最終的には、リランカーを統合するかどうかは、RAGシステムの具体的なニーズに基づいて決定されるべきであり、高品質な応答に対する要求と、性能およびコストの制約とを天秤にかける必要がある。
次回のブログポストでは、ハイブリッド検索アーキテクチャの複雑さを掘り下げ、sparse embedding、ナレッジグラフ、ルールベースの検索、ColBERTやCEPEのような実運用を待つ革新的な学術的コンセプトなど、様々なテクノロジーを探求する。さらに、リランカーを実装した場合の結果品質の向上と待ち時間への影響を評価するために、定性的な分析を採用する。また、Cohere、BGE、Voyage AIなど、市場で普及しているリランカー・モデルの比較レビューも行い、その性能と有効性についての洞察を提供する。
 Jiang Chen
Jiang ChenJiang is currently Head of Ecosystem and Developer Relations at Zilliz. He has years of experience in data infrastructures and cloud security. Before joining Zilliz, he had previously served as a tech lead and product manager at Google, where he led the development of web-scale semantic understanding and search indexing that powers innovative search products such as short video search. He has extensive industry experience handling massive unstructured data and multimedia content retrieval. He has also worked on cloud authorization systems and research on data privacy technologies. Jiang holds a Master's degree in Computer Science from the University of Michigan.
読み続けて

ディープラーニングにおける主要なNLPテクノロジー
ディープラーニングにおける主要な自然言語処理(NLP)技術の根底にある進化と基本原理を探る。

ChatGPTをMilvusで強化する:長期記憶でAIを強化する
GPTCacheとMilvusをChatGPTと統合することで、企業はより強固で効率的なAIを活用したサポートシステムを構築することができる。このアプローチは、ジェネレーティブAIの高度な機能を活用し、長期記憶の形式を導入することで、AIが効率的に情報を呼び出し、再利用することを可能にします。
Llama3、Ollama、DSPy、Milvusを使った検索支援生成(RAG)システムの作り方
この記事では、4つの主要技術を使ったRAGシステムの構築を読者に案内することを目的としている:Llama3、Ollama、DSPy、Milvusである。まず、これらが何であるかを理解しよう。