




Voyage AI Embeddings and Rerankers for Search and RAG
Introduction
In the past, AI was primarily utilized to analyze and suggest information; however, with the advent of generative AI, we can now generate new and unique content. It sounds cool, but sometimes the content can be misleading.
Enter RAG (Retrieval Augmented Generation), optimizing the output of a large language model provided the context of the query. Zilliz and Voyage AI have partnered to make it easy to build a RAG pipeline, as we will see in the article later. Voyage AI provides domain-specific customized embedding models and rerankers for search. We will discuss some of them in this article.
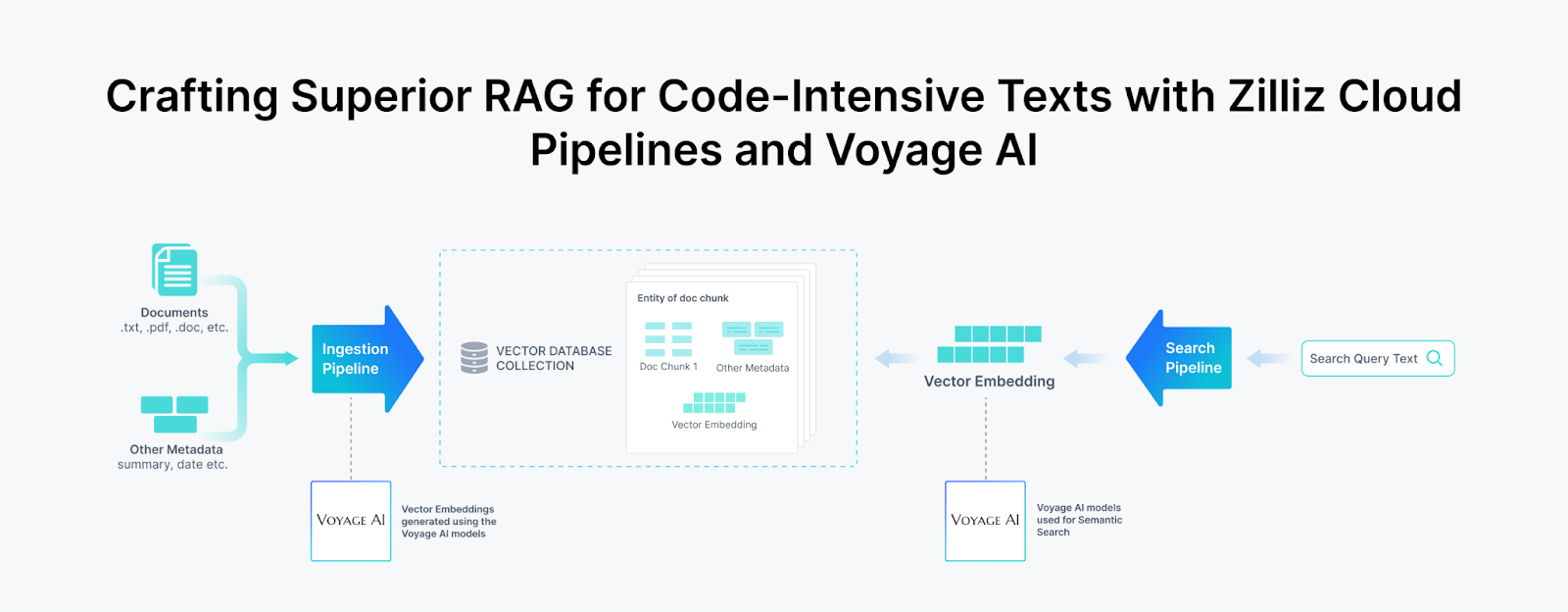 Crafting RAG with Zilliz Cloud Pipelines and Voyage Ai.png
Crafting RAG with Zilliz Cloud Pipelines and Voyage Ai.png
Embedding Models and Voyage AI
Computers cannot understand information from data like text or images. We use embedding models to make computers capable of understanding the semantics behind unstructured data. This section will cover the basics of embedding models, their usefulness in generative AI, and why RAG is the predominant approach for enterprise generative AI.
A brief on embedding models
Embedding models are deep learning models that create vector embeddings for given data. These models convert the provided text, image, voice, or any form of non-numerical or even numerical data into a compact vector representation. This representation, also known as a vector embedding, maps the information to a numerical vector space.
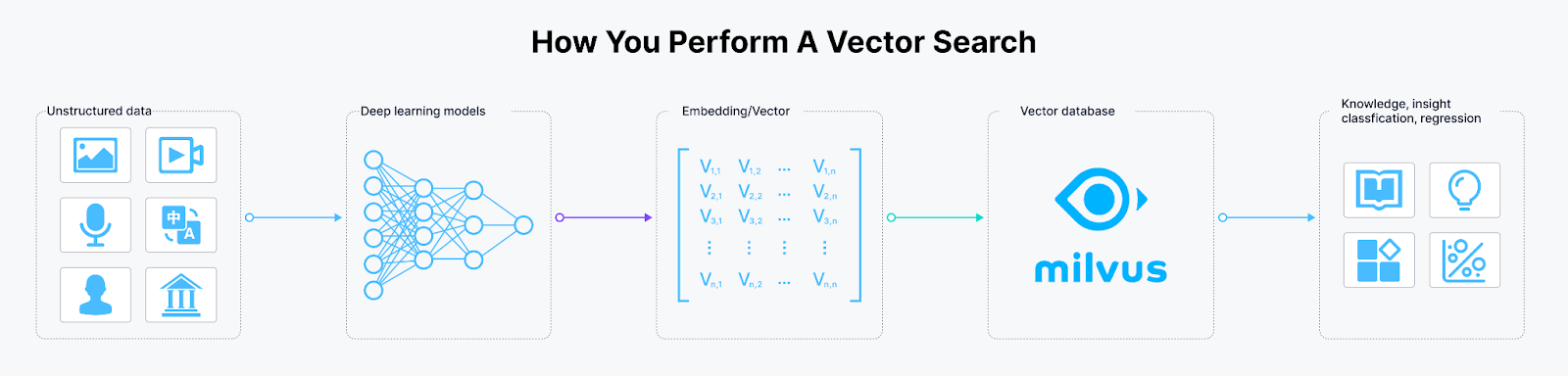 Encoding unstructured data into vector embeddings
Encoding unstructured data into vector embeddings
Generative AI shortcomings
The use of generative AI at the enterprise level is skyrocketing due to its fascinating ability to automate cumbersome tasks and produce results with minimum effort. Even though Gen AI is commendable in assisting us with various scenarios, it also has shortcomings. GenAI models, such as ChatGPT, are generic models trained upon millions or trillions of data entries from multiple domains. This fact can be problematic sometimes. Models are probabilistic and generate the next word based on the context provided. When the context is limited or newer for the model, they start hallucinating. That’s where RAG shines.
RAG and how it reduces hallucinations
The RAG technique requires using domain-specific embedding models to embed the provided query. This query is then taken to a vector database, where the semantic search is applied to fetch similar contextual vector embeddings. All relevant documents from the vector database and the provided query are then passed to the model. The model uses the additional information and context from the query to formulate relevant, up-to-date, and accurate results. This way, the RAG architecture reduces any hallucinations from the model and allows for a more robust and reliable LLM.
 The RAG architecture
The RAG architecture
Now that we have discussed embedding models and their role in RAG, let's discuss some Voyage AI embedding models. Voyage AI provides various customized embedding models across many domains to carry out effective and efficient RAG techniques. These models are connected with vector databases, such as Milvus by Zilliz, to store and retrieve vector embeddings related to the generated query.
Voyage AI Embedding Models
Voyage AI provides many different efficient and effective domain-specific and general-purpose embedding models. These models contribute significantly to search and RAG. They provide higher retrieval quality than most embedding models.
Among multiple embedding models, the best ones include voyage-code-2, voyage-law-2, and voyage-large-2-instruct. Voyage AI has developed these models for specific code, law, finance, and multilingual domains. Moreover, we can customize these models according to our specific use cases. Let's have a look at their latest models:
- voyage-code-2: A model well versed in providing codes related to query with pinpoint accuracy. The following figure shows the performance of voyage-code-2 for the code retrieval task:
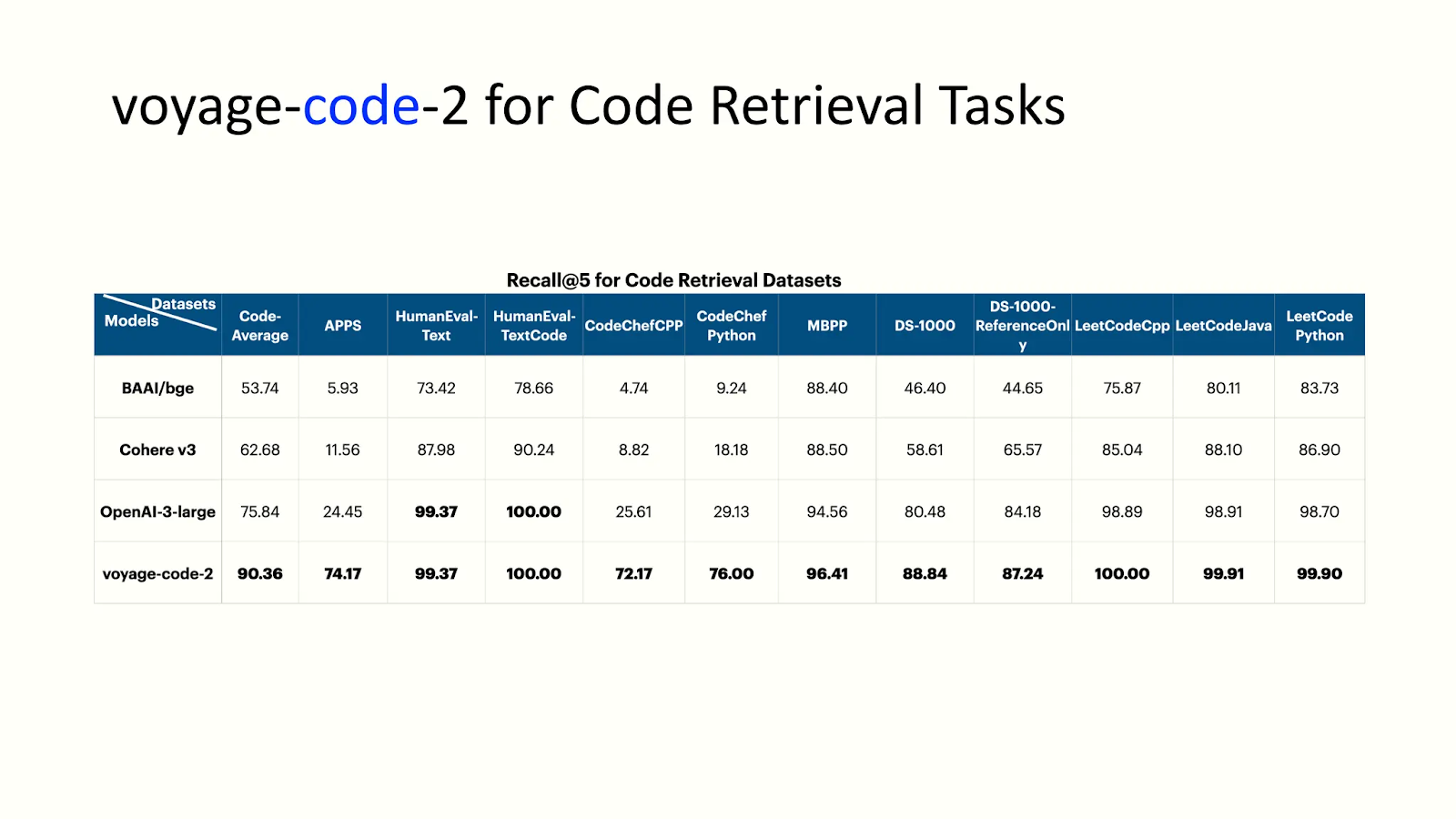 voyage-code-2 performance analysis.png
voyage-code-2 performance analysis.png
- voyage-law-2: A model trained to get context and embedding for legal documents. This model provides the best result regarding long-context legal documents across domains and performs better on general purpose corpora across domains. Following figures highlighting voyage-law-2 performance:
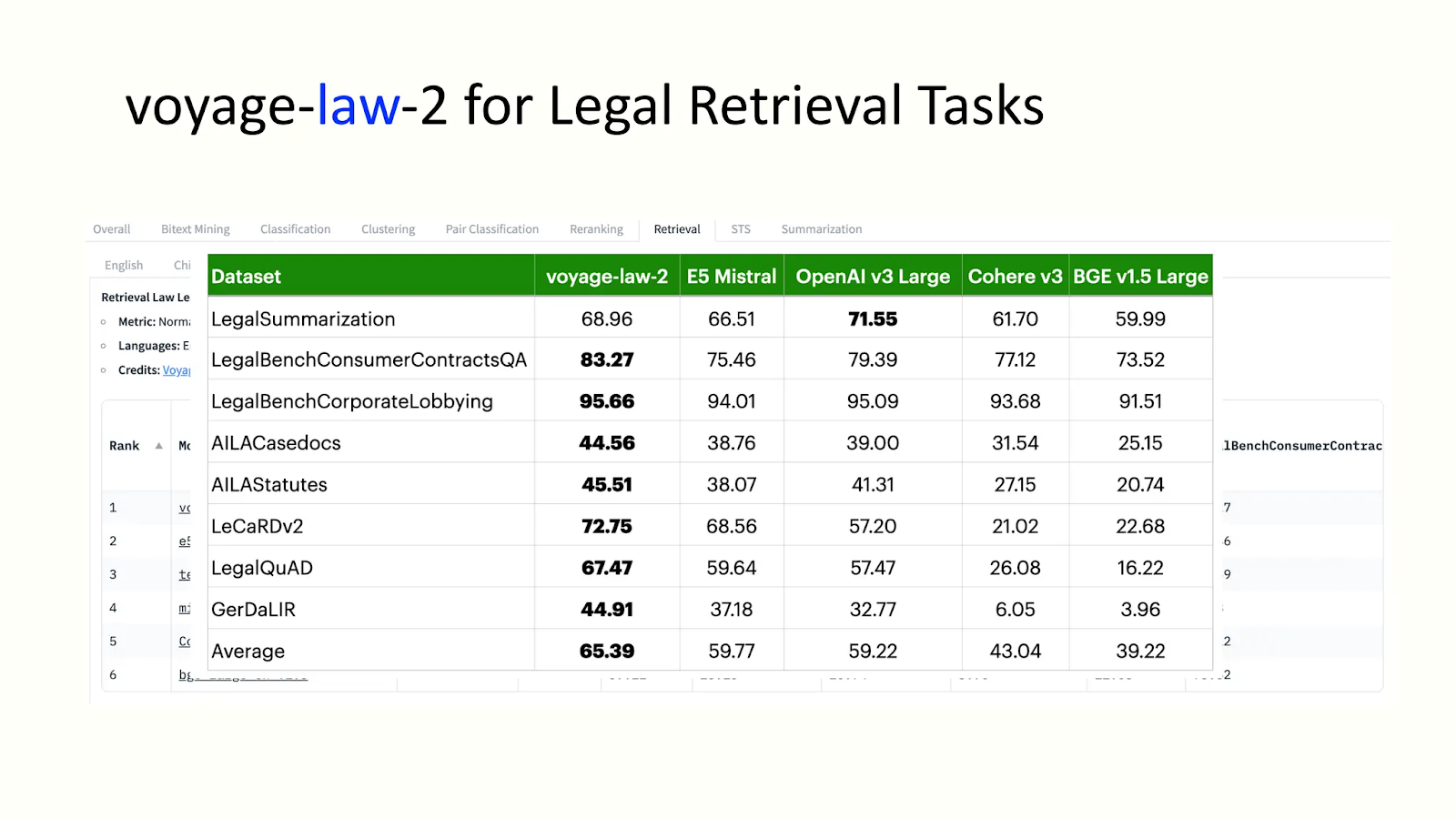 voyage-law-2 performance analysis
voyage-law-2 performance analysis
The above figure shows the performance capabilities of Voyage AI embedding models, which are ranked top by the Massive Text Embedding Benchmark (MTEB).
Rerankers and Voyage AI
We have discussed how RAG improves the quality of GenAI output by reducing such models' hallucinations. However, one slight problem is still related to the GenAI models' context window. The context window refers to the maximum amount of information the AI model can take at any given time for processing. A smaller window means the model gets less information; a larger one means increased processing cost and time.
A reranker ranks the fetched documents from vector databases for optimal results by computing their relevance score with the provided query. The ranking helps filter the most relevant (informative) documents to fit within the context window and generate the most accurate results.
While RAG techniques fetch vector embeddings to provide contextual information and assist in searches, these models rerank all those fetched embeddings using a relevancy score to provide the most relevant data to the LLMs.
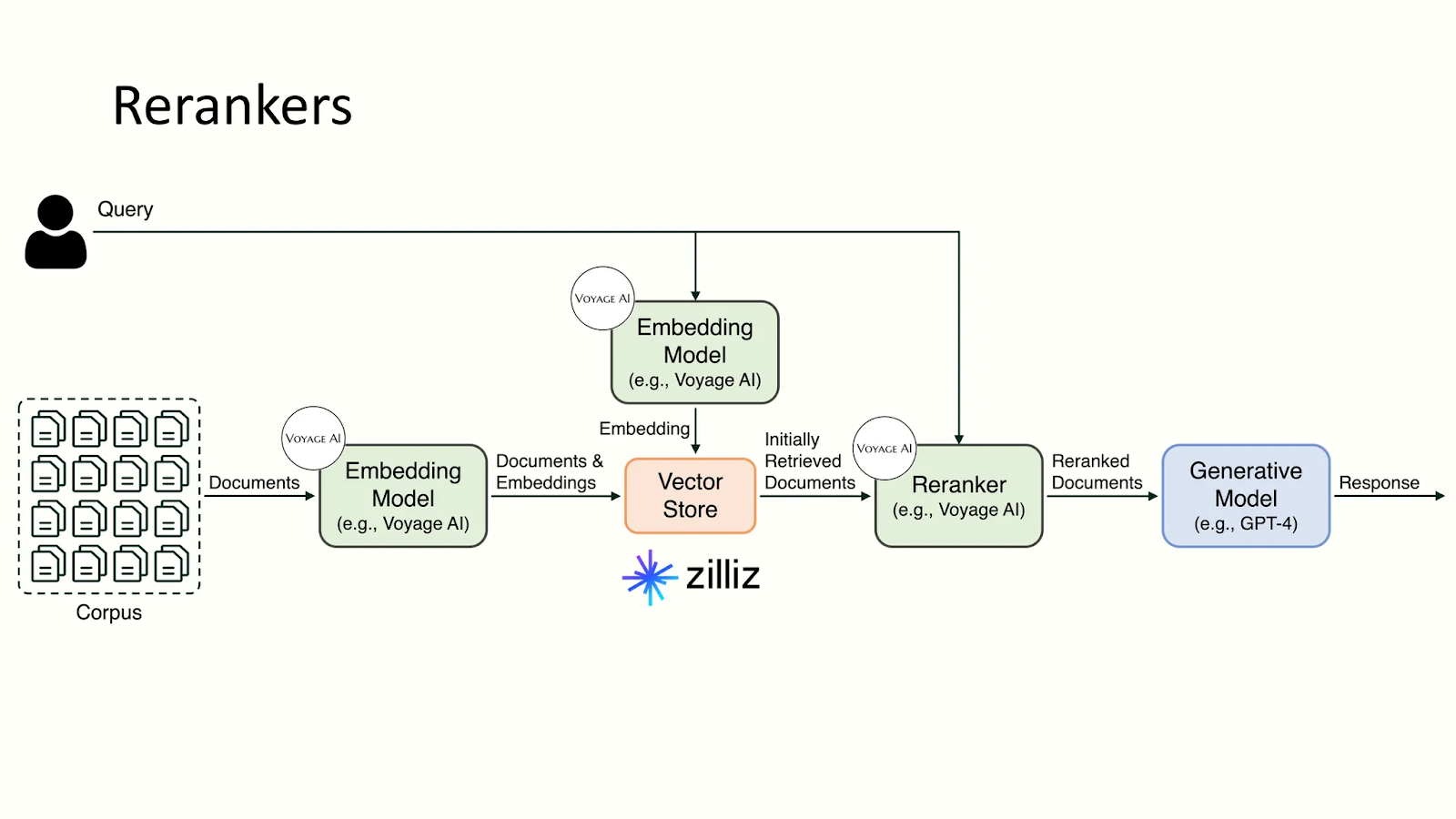 Simple Reranker Architecture
Simple Reranker Architecture
Voyage AI Rerankers
Voyage AI has developed a reranker model known as rerank-lite-1. This voyage model is a generalist reranker optimized for latency and quality. It has a context window of 4000 tokens. The following figure shows the performance of this model.
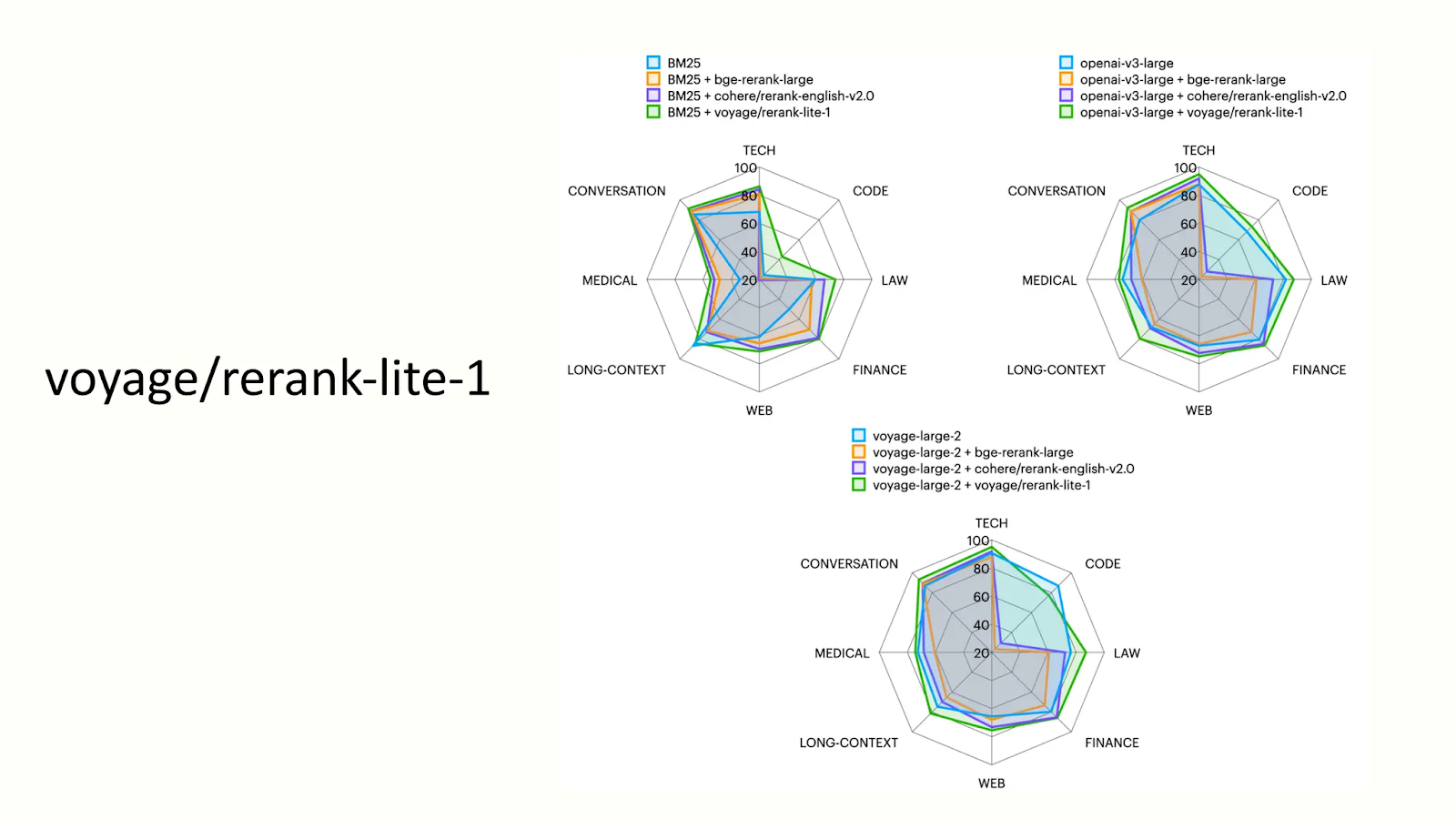 voyage:ranke-lite-1 performance analysis
voyage:ranke-lite-1 performance analysis
Use Voyage Embeddings on Zilliz Cloud Pipelines
Zilliz and Voyage AI have partnered to streamline the conversion of unstructured data into searchable vector embeddings on Zilliz Cloud.
This section will show how to integrate the Zilliz Cloud and Voyage AI embedding models for streamlined embedding generation and retrieval. We’ll also show you how to use this integration and Cohere (the LLM) to build a RAG application. Let's get started.
Set up Zilliz Cloud
The first step is to step up the Zilliz Cloud. If you don’t have a Zilliz Cloud account yet, sign up for free.
Upon logging in for the first time, the following console will be displayed on the screen.
 Zilliz cloud console for creating a cluster
Zilliz cloud console for creating a cluster
- We will create a cluster as needed. Zilliz provides a free tier for learning, experimenting, and prototyping, which can later be migrated to different production plans.
 Creating a new Cluster in Zilliz.png
Creating a new Cluster in Zilliz.png
- After creating the new cluster, all the information required to connect will be displayed.
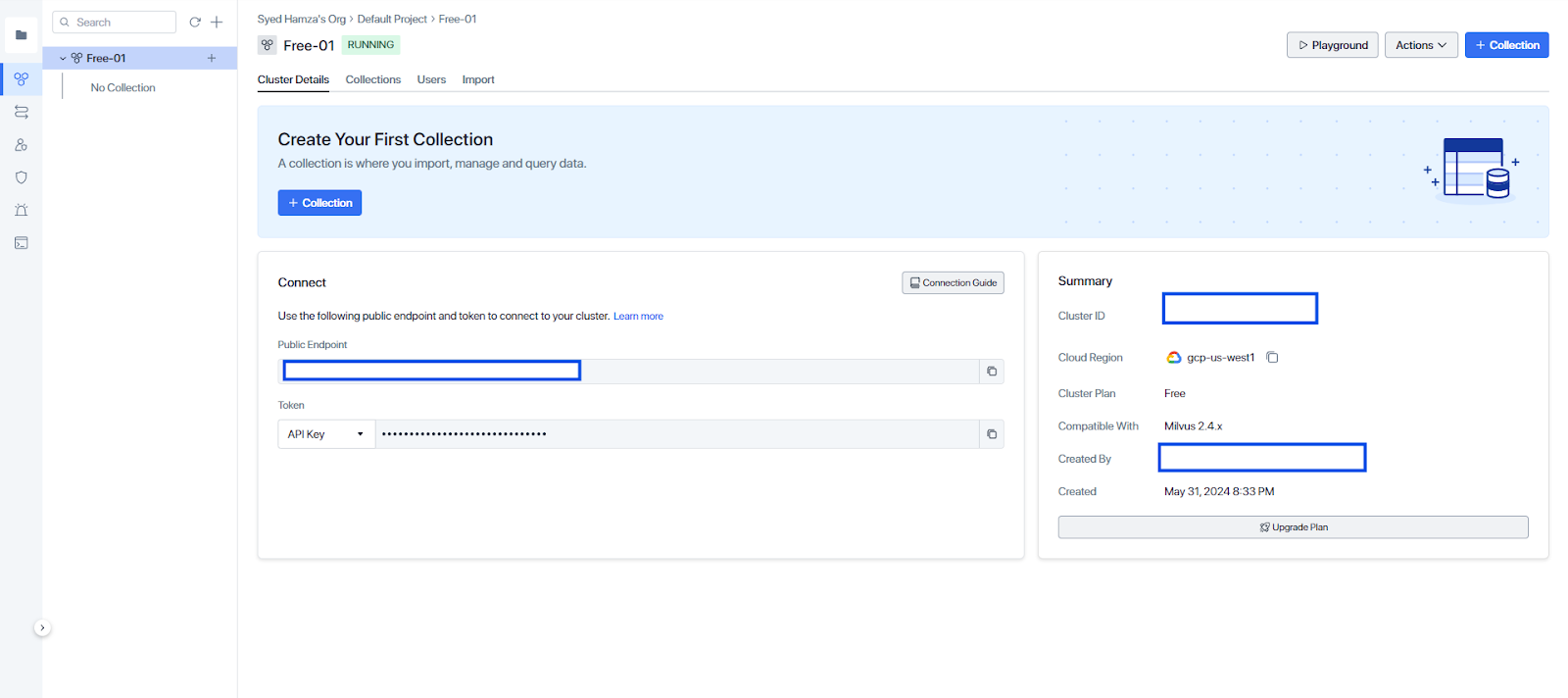 Connection to the cluster
Connection to the cluster
The project ID can be retrieved from Projects in the top menu bar. Locate the target project and copy its ID into the Project ID column.
 Projects Dashboard for Project ID
Projects Dashboard for Project ID
- Now, we have all the ingredients required for our connection to the cluster. It's time to build our pipelines. We will use Cohere as the LLM for the RAG application. For that, we will install
cohere.
%pip install cohere
Here are the imports we require for this notebook.
import os
import requests
In the code below, we have set up our CLOUD_REGION, CLUSTER_ID, API_KEY, and PROJECT_ID:
CLOUD_REGION = 'gcp-us-west1'
CLUSTER_ID = 'your CLUSTER_ID'
API_KEY = 'your API_KEY'
PROJECT_ID = 'your PROJECT_ID'
Zilliz Cloud Pipelines
Zilliz Cloud Pipelines convert unstructured data into a searchable vector collection, handling embedding, ingestion, search, and deletion processes. Zilliz Cloud offers three types of pipelines:
- Ingestion Pipeline: Converts unstructured data into searchable vector embeddings and stores them in Zilliz Cloud Vector Databases. It includes various functions for transforming input fields and preserving additional information for retrieval.
Search Pipeline: This pipeline enables semantic search by converting a query string into a vector embedding and retrieving the Top-K similar vectors along with their corresponding text and metadata. It allows only one function type.
Deletion Pipeline: Removes specified entities from a collection, allowing only one function type.
Ingestion Pipeline
In the Ingestion pipeline, you can specify functions to customize its behavior based on the input data. Currently, it supports four functions:
INDEX_DOC: Takes a document as input, splits it into chunks, and generates a vector embedding for each chunk. It maps an input field to four output fields (doc_name, chunk_id, chunk_text, and embedding) in the collection.PRESERVE: Stores user-defined input as an additional scalar field in the collection, typically used for meta information such as publisher info and tags.INDEX_TEXT: Processes texts by converting each text into vector embedding and mapping an input field (text_list) to two output fields (text and embedding).INDEX_IMAGE: Processes images by generating an image embedding, mapping two input fields (image_url and image_id) to two output fields (image_id and embedding).
In the code snippet below, we will use the requests library to post the request to the Zilliz cloud. A post request comprises URL, headers, and data to send. Let's make our header:
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
We will define our collection_name and embedding_service in the code below. The embedding service will utilize Voyage AI models, specifically voyage-2, which have shown exceptional performance in retrieval tasks, technical documentation, and general applications.
create_pipeline_url = f"https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines"
collection_name = 'Documents'
embedding_service = "voyageai/voyage-large-2"
In the code snippet below, we will define the index function for our ingestion_pipeline:
data = {
"name": "ingestion_pipeline",
"description": "A pipeline that generates text embeddings and stores title information.",
"type": "INGESTION",
"projectId": PROJECT_ID,
"clusterId": CLUSTER_ID,
"collectionName": collection_name,
"functions": [
{
"name": "index_doc",
"action": "INDEX_DOC",
"language": "ENGLISH",
"embedding": embedding_service
}
]
}
response = requests.post(create_pipeline_url, headers=headers, json=data)
print(response.json())
The pipelineId will be later used to ingest the data into the database. After this step, we can see our collection created in the cluster as well as our ingestion pipeline:
ingestion_pipe_id = response.json()["data"]["pipelineId"]
print(ingestion_pipe_id)
>> pipe-cf…
Here is the collection created in the cloud:
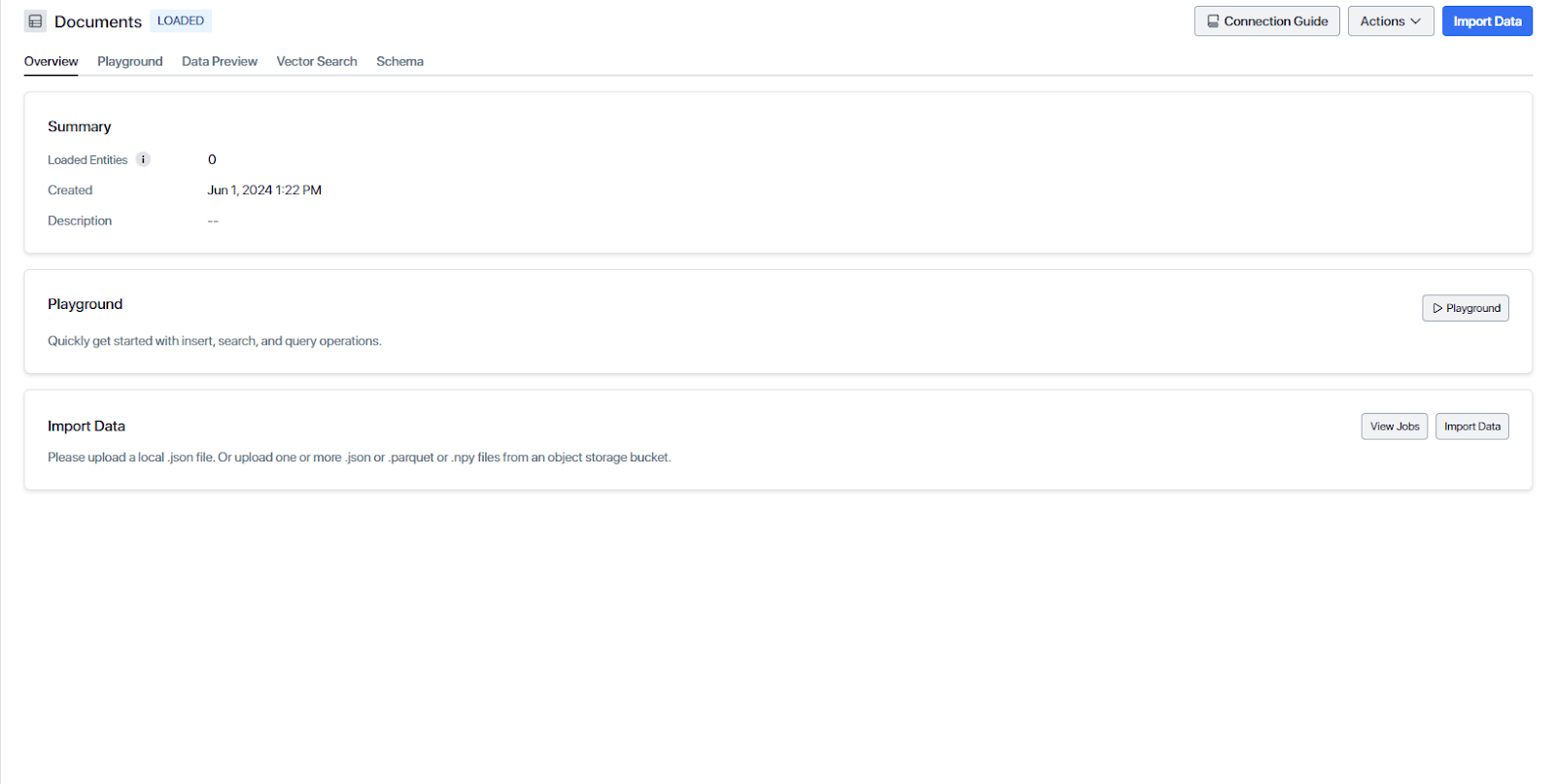 Collection created in the cloud
Collection created in the cloud
And our ingestion pipeline looks like this:
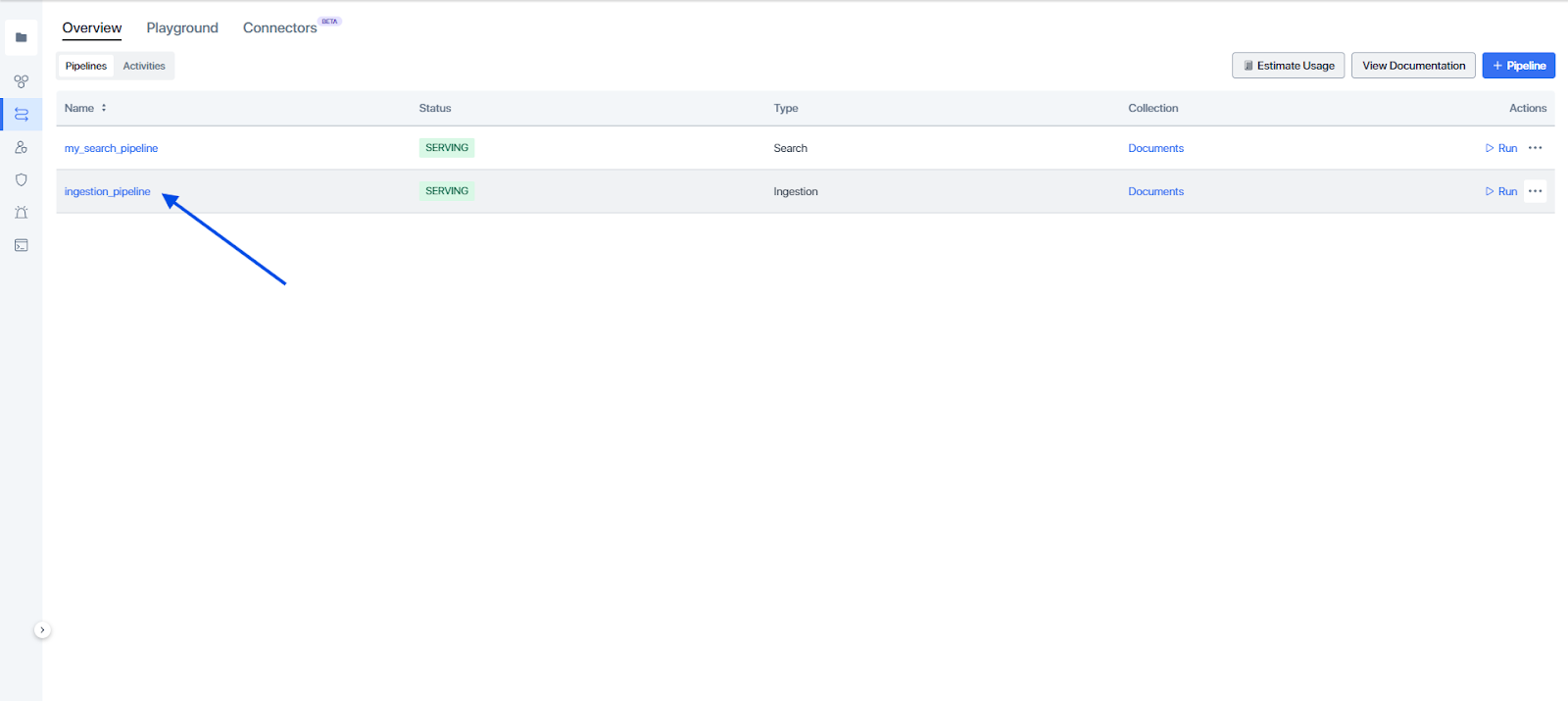 Ingestion Pipeline in Zilliz Cloud
Ingestion Pipeline in Zilliz Cloud
Search Pipeline
Search pipelines facilitate semantic search by converting a query string into a vector embedding and retrieving the Top-K nearest neighbor vectors. The Search pipeline features the SEARCH_DOC_CHUNK function, which requires cluster specification and collection to search from.
Zilliz supports many functions. Here, we will use SEARCH_DOC_CHUNK, which inputs a user query and returns relevant doc chunks from the knowledge base.
data = {
"projectId": PROJECT_ID,
"name": "search_pipeline",
"description": "A pipeline that receives text and search for semantically similar doc chunks",
"type": "SEARCH",
"functions": [
{
"name": "search_chunk_text",
"action": "SEARCH_DOC_CHUNK",
"inputField": "query_text",
"clusterId": f"{CLUSTER_ID}",
"collectionName": f"{collection_name}",
"embedding": embedding_service
}
]
}
response = requests.post(create_pipeline_url, headers=headers, json=data)
search_pipe_id = response.json()["data"]["pipelineId"]
We have created our ingestion and search pipelines. It's time to insert this article into our ingestion pipeline and run our search pipeline.
Run the Ingestion Pipeline
The Ingestion pipeline can intake files from Object Storage Services like AWS S3 or Google Cloud Storage (GCS). Accepted file formats encompass .txt, .pdf, .md, .html, etc. We can run the ingestion pipeline from the Zilliz console. Let’s do that step-by-step.
1. Go to Pipelines from the left and navigate to ingestion_pipeline as shown below:
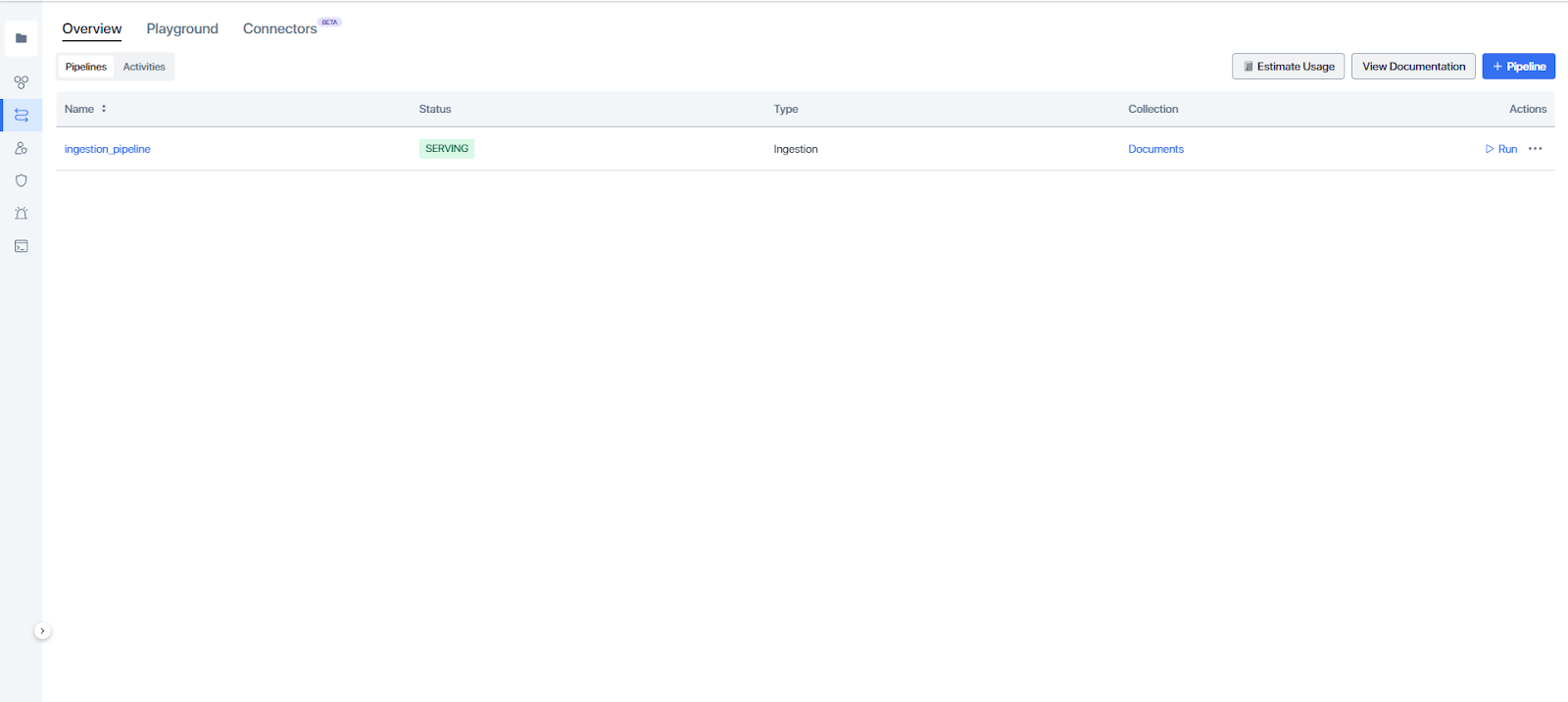 Ingestion Pipeline created in the cloud
Ingestion Pipeline created in the cloud
2. After clicking on Run, we will be prompted to the following page:
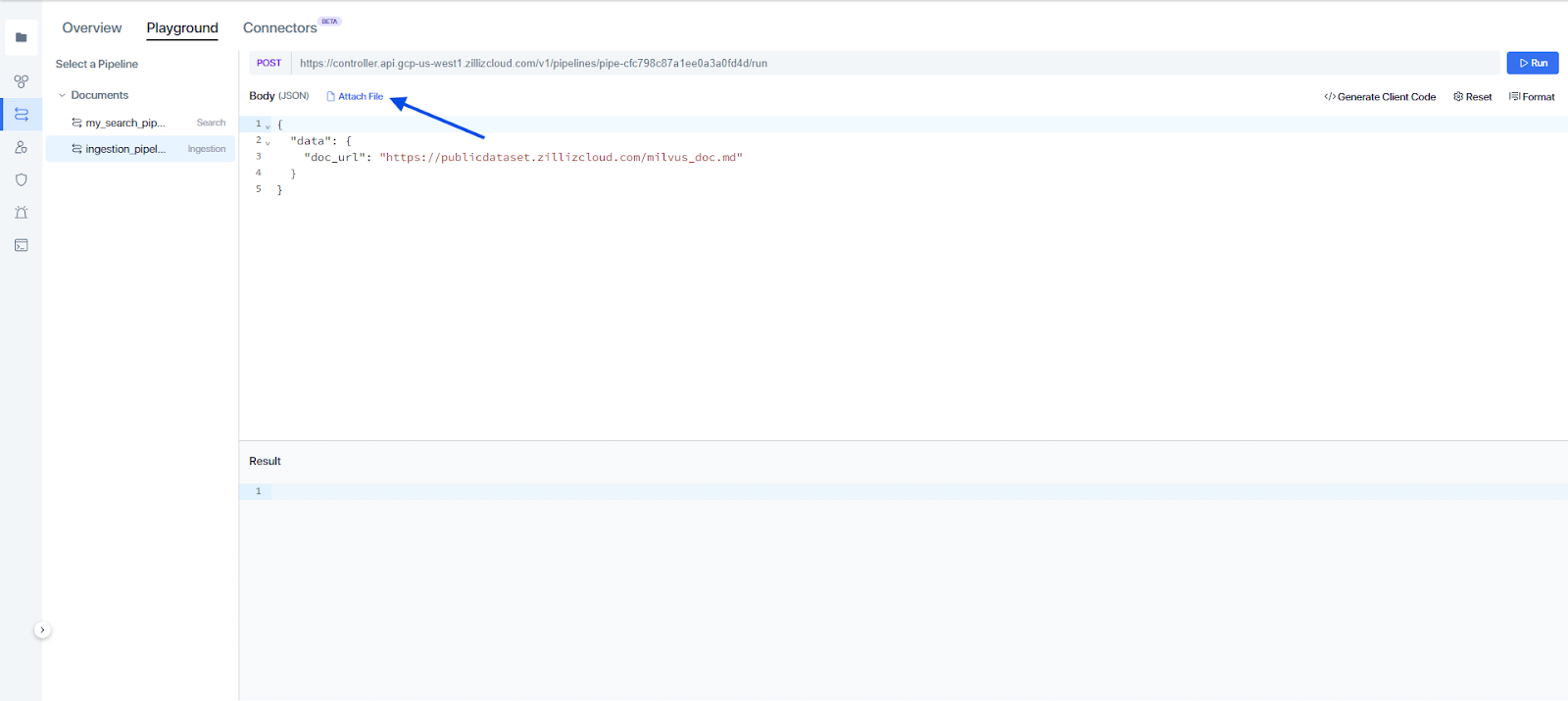 Attach file in the ingestion pipeline
Attach file in the ingestion pipeline
Attach the text file and run the pipeline. After success, the text file will be loaded into the collection. Here is the data preview:
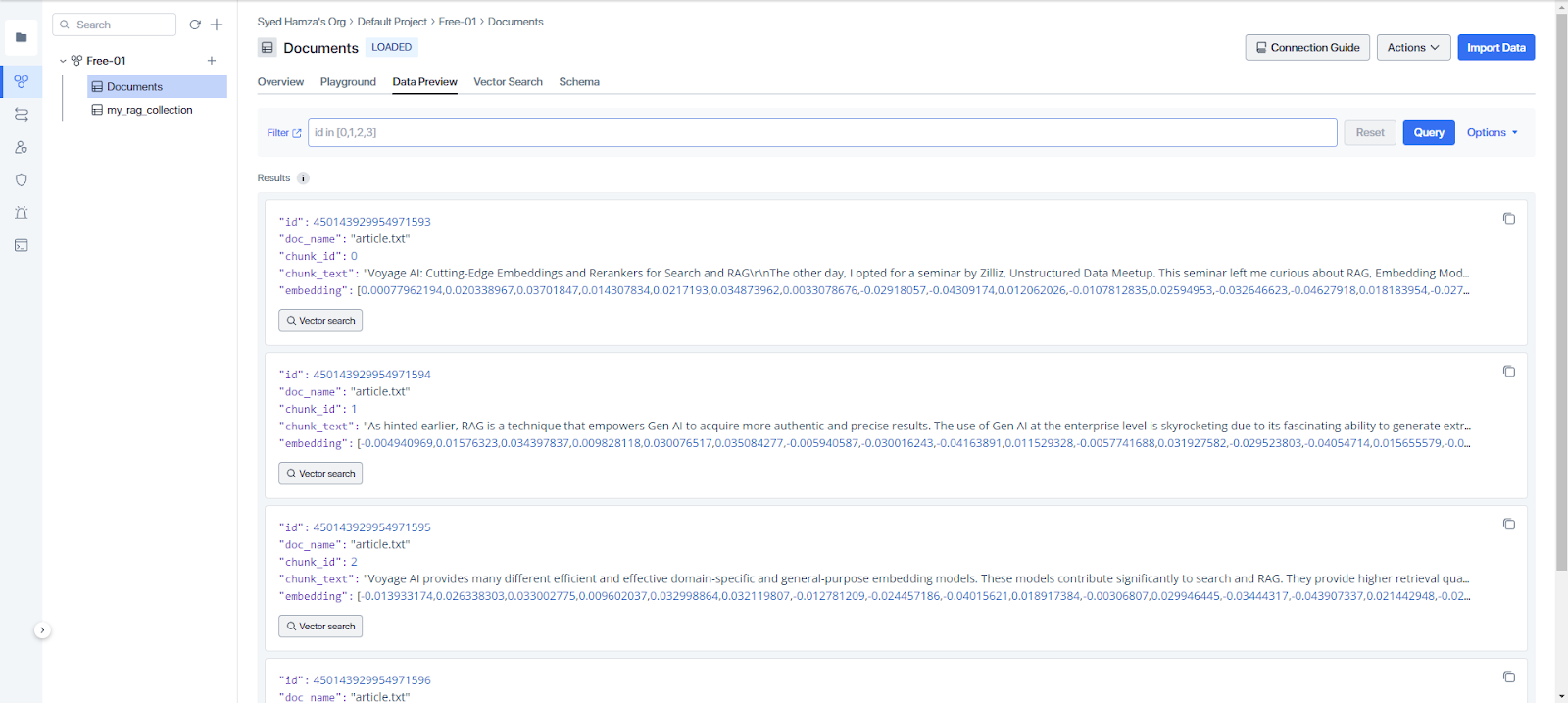 Data preview of the collection
Data preview of the collection
Run the Search Pipeline
RAG (retrieval augmented generation) has two major components: the retriever and LLM. Creating a retriever is as simple as running the search pipeline. The search pipeline takes in the query and retrieves the most relevant chunk from the database. In the code below, the function retriever takes in the query and topk (the number of documents to pick ) and runs the search pipeline.
def retriver(question, topk):
run_pipeline_url = f"https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines/{search_pipe_id}/run"
data = {
"data": {
"query_text": question
},
"params": {
"limit": topk,
"offset": 0,
"outputFields": [
"chunk_text",
"id",
"doc_name"
],
}
}
response = requests.post(run_pipeline_url, headers=headers, json=data)
return [result['chunk_text'] for result in response.json()['data']['result']]
RAG Application Using Cohere as the LLM
After retrieving the documents, we will use Cohere as our LLM. We will provide the retrieved documents to Cohere chat API wrapped in a prompt and ask questions about it.
import cohere
co = cohere.Client(api_key="your_api_key")
def chatbot(query, topk):
chunks = retriver(query, topk)
response = co.chat(
model="command-r-plus",
message= f"Given this information: '{[chunk for chunk in chunks]}', generate a response for the following {query}"
)
return response.text
question = "I'm looking for a good model for legal retrieving tasks?"
print(chatbot(question, 2))
Here is the response from the chatbot:
Based on the provided information, it seems you are specifically interested in a proficient model in legal retrieving tasks. In that case, the model best suits your needs is "voyage-law-2."
Conclusion
Voyage AI provides domain-specific customized embedding models and rerankers for advanced search. Zilliz Cloud Pipelines seamlessly integrates Voyage AI models with Zilliz Cloud, making RAG development much more streamlined.
This article discussed the popular voyage AI embedding models and rerankers and their integration with Zilliz Cloud. We also demonstrated how to build a RAG with Voyage AI, Zilliz Cloud Pipeline, and Cohere.
For further details, watch the replay of Tengyu Ma’s talk at the Unstructured Data Meetup by Zilliz.

Keep Reading

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.