




LLaVA: Advancing Vision-Language Models Through Visual Instruction Tuning
Current state-of-the-art large language models (LLMs) like ChatGPT, LLAMA, and Claude Sonnet have demonstrated that human language-based instructions can be a powerful tool for improving response quality. Using techniques such as prompt engineering, we can guide LLMs to generate responses that align more closely with our specific use cases.
Initially, LLMs were designed exclusively for text-based inputs. When given textual instruction, they would generate a corresponding response. While this approach has been highly successful, expanding these capabilities to visual inputs is a natural progression. Visual-based models take both a text instruction and an image as input, enabling tasks such as summarizing an image’s content, extracting information, or translating text within an image.
In this article, we’ll explore LLaVA (Large Language and Vision Assistant), one of the pioneering efforts to implement text-based instruction for visual-based models. Before going into details about its implementation, let’s take a step back to understand the evolution of visual-based models and how they are transforming the field.
Development of Visual-Based Models
In their early development stages, most vision-based models relied on convolutional neural network (CNN)-based architectures to perform common vision tasks. In its simplest form, a visual-based model can be built with a pair of CNN layers to perform a simple image classification task, such as determining whether a given image is of a dog or a cat.
However, to classify more complex images with more classes, we need to build deeper models consisting of hundreds of CNN layers. The deeper the layers of the model, the higher the risk of encountering the vanishing gradient problem. Vanishing gradient refers to the phenomenon during model training where the gradient becomes so small that the model is unable to learn anything and update its weights.
To address this issue, sophisticated algorithms like residual connections were implemented within the model's architecture to avoid vanishing gradient problems commonly occurring in deep learning models. This method proved effective, leading to the inception of ResNet, which subsequently achieved state-of-the-art performance in many image classification benchmark datasets.
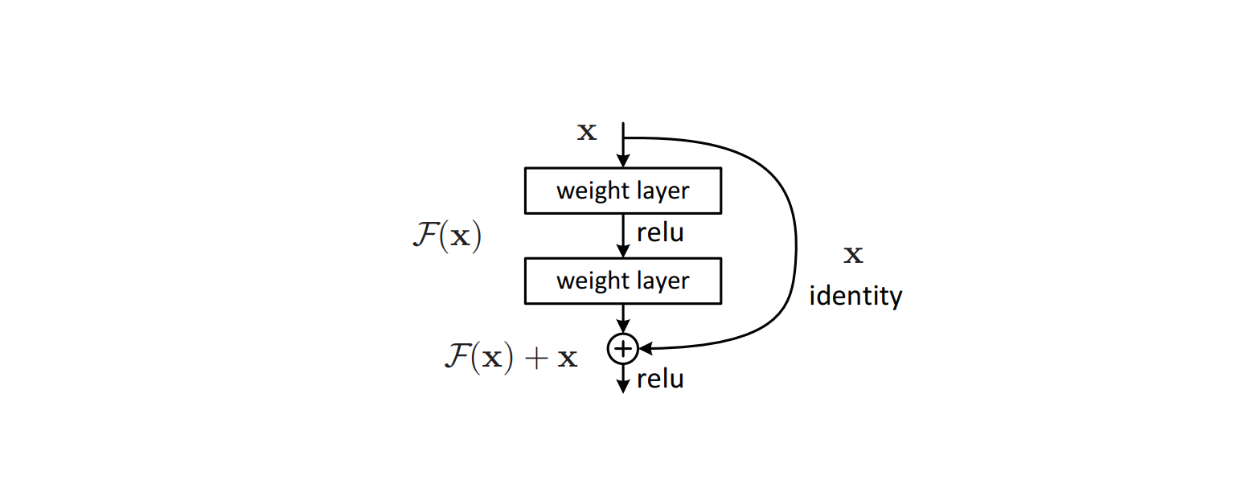
Figure: Building block of a residual connection inside a model’s architecture. Source.
The success of ResNet inspired other model architectures capable of performing more complex image tasks. Visual models such as YOLO implemented residual connections in their architecture to perform object detection tasks. At the same time, U-Net used a combination of U-shaped architecture and residual connections to perform image segmentation tasks.
Although these visual models can perform visual-based tasks, each can only perform one specific task. If a model has been trained for image classification, it can only be used for that purpose. Additionally, if we ask the model to classify an image significantly different from those in the training data, we may observe some randomness in the model's predictions.
The introduction of the famous Transformers model in 2017 triggered rapid development in deep learning models in general. Models adopting Transformers in their architecture significantly outperformed more traditional models. Originally intended only for text-based models, the Transformers architecture proved versatile enough to be used in vision-based models as well.
Transformer-based vision models, such as Vision Transformers (ViT), demonstrated high capability in performing image classification tasks. As a result, ViT is now used by many popular text-vision models, such as CLIP, as their backbone architecture.
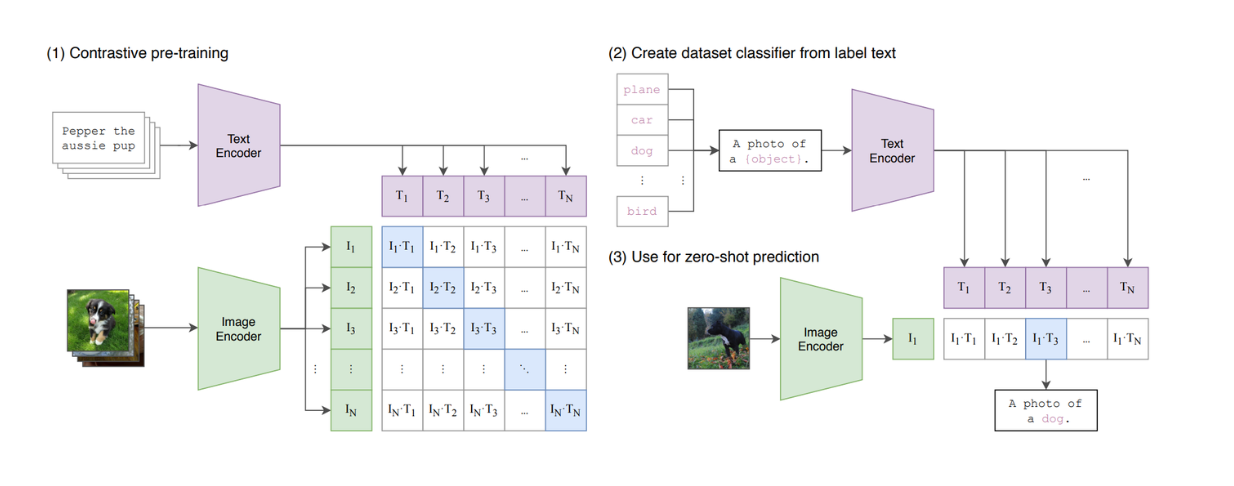
Figure: A summary of the CLIP model. Source.
CLIP is a model that combines ViT and a BERT-like model in its architecture. ViT processes image input, while the BERT-like model processes textual input. CLIP has been trained using contrastive learning, whereby, when given a text and an image as an input pair, CLIP calculates the similarity between the text and the image. However, we can see that CLIP is still limited in terms of its ability to mimic text-based LLMs, as it's not a generative model.
LLaVA is one of the earliest visual-based LLMs capable of taking text-based instruction and images as inputs and generating an appropriate response. We'll discuss the details of LLaVA in the next section.
What is LLaVa?
LLaVA (Large Language and Vision Assistant) is a multimodal model that combines text-based large language models (LLMs) with visual processing capabilities, enabling it to handle text and image inputs. It is designed to perform tasks like summarizing visual content, extracting information from images, and answering questions about visual data.
LLaVA builds on the success of LLMs by incorporating visual understanding and aligning text-based instructions with image analysis. This integration allows the model to process paired inputs—text prompts and images—delivering coherent and contextually relevant responses.
LLaVA Architecture
The architecture of LLaVA is relatively simple. It uses a pre-trained LLM to process textual instructions and the visual encoder from pre-trained CLIP, a ViT model, to process image information.
Among several publicly available pretrained LLMs, the authors of LLaVA chose Vicuna as the backbone to process textual information and generate the final response, given a pair of text-image input.
Since most text-based LLMs are based on the Transformer architecture, the process of transforming text until response generation is quite straightforward. Each token in the input text is transformed into an embedding, then it passes through several stacks of attention and dense layers before producing the final feature output with a fixed-size dimension.
To process the image input, LLaVA uses the pretrained ViT model inside CLIP to transform the input image into a feature representation with a fixed-size dimension. However, the dimension of the image feature from CLIP differs from the text feature from Vicuna. Therefore, LLaVA implements a simple dense layer afterwards to project the image feature to have the same size as the textual feature from Vicuna.
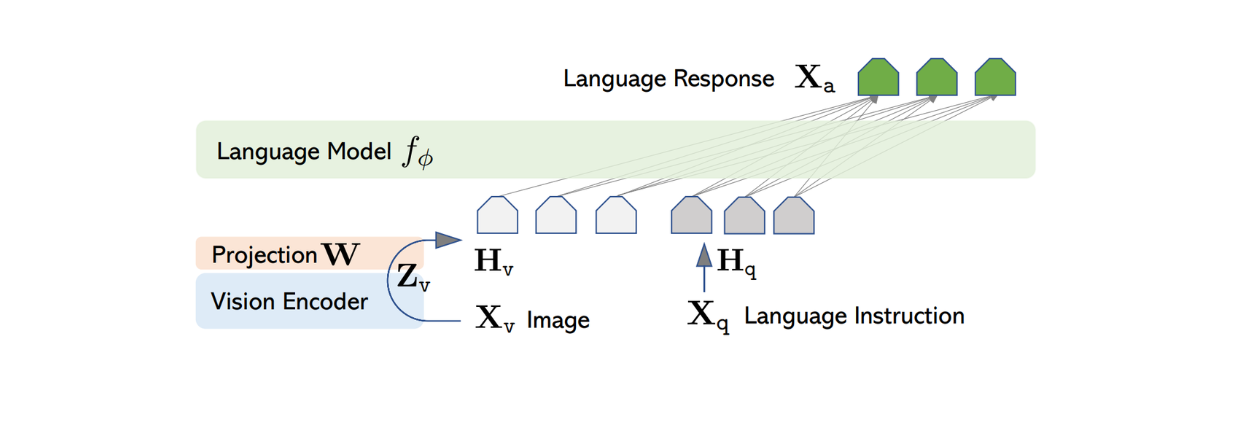
Figure: LLaVA architecture. Source.
Now that the image and textual features have the same size, an approach is needed to combine these two features into one. There are several approaches commonly used to do this, such as simply prepending the image feature in front of the token feature ([image feature] + [text feature]), or using more sophisticated algorithms such as gated cross-attention and Q-former. The combined image and textual features are then fed into Vicuna, enabling it to generate an appropriate response.
However, by implementing the approach mentioned above, the response quality generated by Vicuna or any other similar LLMs might not be optimal. This is expected as LLMs are trained purely on textual data. Therefore, LLaVA needs to be fine-tuned before it can generate coherent responses based on a pair of image-text inputs. This fine-tuning process is called visual instruction tuning, which we'll discuss in the next sections.
Data Generation Process for Visual Instruction Tuning
Visual Instruction Tuning is a process of training multimodal AI models to understand and respond to text-based instructions paired with visual inputs, such as images or videos. This technique aligns visual understanding with natural language processing capabilities, enabling the model to perform tasks like image captioning, visual question answering, object recognition, and information extraction.
One of the key challenges of visual instruction tuning is the lack of publicly available multimodal instruction-following data. While several datasets consisting of image-text pairs, such as CC and LAION, exist, they are not exactly the type of dataset we would like to use to fine-tune visual-based LLMs to follow user instructions.
Figure: Example of CC Dataset. Source.
On the other hand, manually creating a massive amount of multimodal instruction-following data to tune LLaVA would require significant effort and time. Therefore, we can leverage GPT-4 or ChatGPT to speed up the creation process of multimodal instruction-following data.
As seen in the CC image example above, common multimodal datasets consist of a pair of image-caption text in each data record. With ChatGPT, given an image and its caption, we can generate a set of possible questions intended to instruct the LLMs to describe the content of the image. The format of multimodal instruction-following data will then look like this: Human: Xq Xv
However, we know that previous iterations of ChatGPT only accept text as input. To use it to curate a list of questions regarding a specific image, we need to provide information or metadata about the image. The authors used two different approaches to give ChatGPT the necessary information about any input image: captions and bounding boxes. Captions usually consist of detailed descriptions of the image, while bounding boxes provide helpful information about the exact location of objects in the image to ChatGPT.

Figure: Example of caption and bounding boxes to capture visual information for text-only GPT-4. Source.
The authors created three types of multimodal instruction-following dataset:
Conversation: This consists of a back-and-forth conversation between the LLM and the user. The LLM's answers are set with the tone as if it is looking at the image and then answering the user's questions. Typical questions include the visual content of the image, counting objects in the image, relative positions of objects in the image, etc.
Detailed descriptions: consists of a list of questions intended to generate comprehensive descriptions of an image.
Complex reasoning: consists of questions that go beyond the above two types. Instead of merely describing an image's visual content, these questions aim to force the LLM to explain the logic behind its responses, requiring step-by-step reasoning.

Figure: Example of three types of multimodal instruction-following dataset. Source.
Below is an example prompt used by the authors to generate a conversation-type dataset:
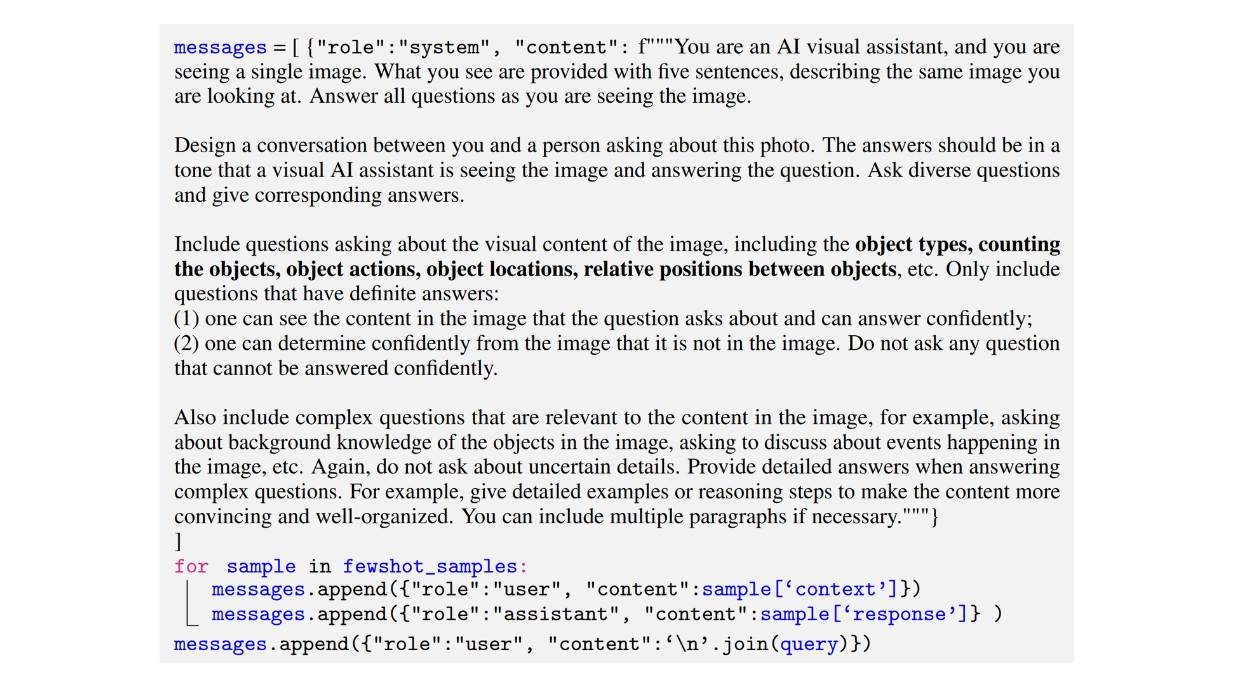
Figure: Example of a prompt used to generate a conversation-type multimodal instruction-following dataset. Source.
Obtaining the desired output with the correct format from LLM-generated multimodal instruction-following data is quite tricky. Therefore, when asking ChatGPT to generate all three types of multimodal instruction-following datasets, the authors used few-shot samples to leverage the power of in-context learning.
With few-shot samples, the authors provided a couple of manually created examples of conversations between the LLM and the user alongside the prompt. These few-shot examples help ChatGPT better understand the structure of expected output. Below is an example of a few-shot sample implemented by the authors in the prompt to generate a conversation dataset.

Figure: Example of a few-shot example to be passed alongside the prompt for in-context learning. Source.
Training Procedure of LLaVA
The total multimodal instruction-following data generated with the approach mentioned above was approximately 158K. Next, a LLaVA model was fine-tuned with these multimodal data.
In the dataset, for each image Xv, there are multi-turn conversations between the LLM and users (X1q, X1a, · · · , XTq, XTa), where T is the total number of turns. For each turn t, the answer Xta is treated as the response of the LLM, and therefore, the instruction at turn t would be:
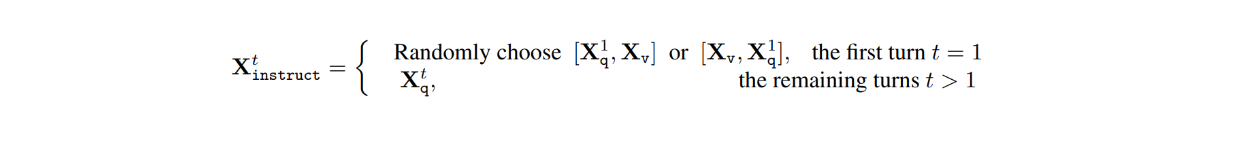
Next, during the visual instruction tuning process, two stages were conducted: pre-training for feature alignment and fine-tuning end-to-end.
During the pre-training for feature alignment stage, the main purpose is to train the projection layer that maps the output of the ViT model from the pretrained CLIP encoder into a final visual feature that has the same dimension as the text feature. At this stage, the training process was done using the filtered CC dataset, which contains 596K image-text pairs. For each image Xv, the question Xq is randomly sampled from a pool of questions, and the corresponding Xc is used as the ground-truth label. Therefore, the questions sampled for the training are ones that ask the LLM to describe the image briefly, as you can see in the image below:

Figure: Example of prompts to briefly explain the content of an image. Source.
Since we're only training the projection layer, the weights of both ViT and LLM are frozen in this stage.
Meanwhile, during the second stage, which is fine-tuning end-to-end, the LLaVA model is fine-tuned with the 158K generated multimodal instruction-following data. In this stage, only the ViT weights are frozen, while the weights of the projection layer and LLM are updated during the fine-tuning process.
LLaVA Results
To assess the performance of LLaVA, a comparison with other state-of-the-art models like GPT-4 and visual-based models such as BLIP-2 and OpenFlamingo was conducted. For the evaluation of the results, the authors used text-only GPT-4 as the judge to score the quality of the responses based on helpfulness, relevance, accuracy, and level of detail.
As the first evaluation, 30 random images from the COCO-Val-2014 dataset were selected, and using the data generation process explained in the previous section, three types of datasets were generated. This resulted in a total of 90 data points: 30 for conversation, 30 for detailed descriptions, and 30 for complex reasoning. The responses from LLaVA were then compared with the output from the text-only GPT-4 model that uses textual description/caption as the label and bounding boxes as visual input. The results are as follows:
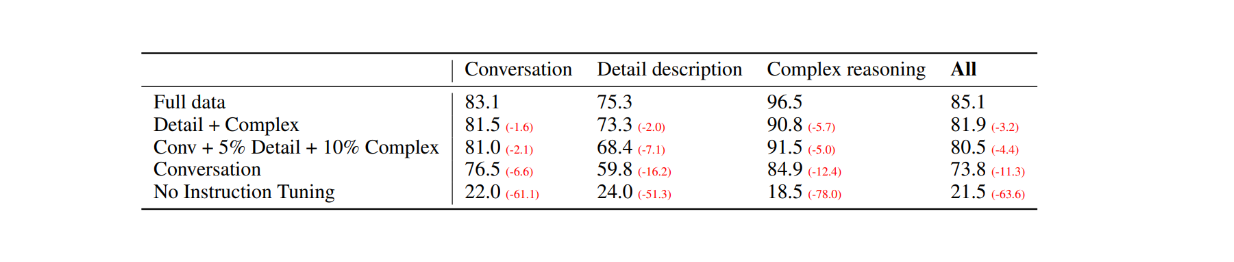
Figure: Performance comparison between LLaVA and text-only GPT-4 on 30 random images. Source.
With visual instruction tuning, the model's ability to follow instructions increased by at least 50 points in each dataset type. Meanwhile, the relative score of LLaVA was not far off compared to the text-only GPT-4 model that uses image captions as visual input, as shown by the numbers inside parentheses in each category.
The performance of LLaVA was also compared with visual-based models such as BLIP-2 and OpenFlamingo by first taking 24 random images with 60 questions in total. As shown in the table below, LLaVA's performance is far superior to the other two visual-based models. This demonstrates the power of visual instruction tuning, as BLIP-2 and OpenFlamingo haven't been fine-tuned explicitly with a multimodal instruction-following dataset.

Figure: Performance comparison between LLaVA and BLIP-2 and OpenFlamingo. Source.
Now let's examine an example of the models' responses in action. Consider a picture of chicken nuggets forming a world map, and we ask, "Can you explain this meme in detail?" Below are the example responses from LLaVA, text-only GPT-4, BLIP-2, and OpenFlamingo.

Figure: Example responses from LLaVA, GPT-4, BLIP-2, and OpenFlamingo. Source.
As you can see, both BLIP-2 and OpenFlamingo models failed to follow the instruction as they haven't been fine-tuned with visual instruction tuning. Meanwhile, LLaVA demonstrated its visual reasoning capability in understanding humor. Along with GPT-4, it was able to provide a concise answer according to the instruction.
When fine-tuned on the ScienceQA dataset for approximately 12 epochs, LLaVA also achieved very competitive results compared to the MM-CoT model, which is the current state-of-the-art (SOTA) model on this dataset. As shown in the table below, LLaVA achieved 90.92% overall accuracy across several different subjects compared to 91.68% from the MM-CoT model. However, when the output of LLaVA was combined with GPT-4, the performance achieved a new SOTA on the ScienceQA dataset with 92.53% accuracy.
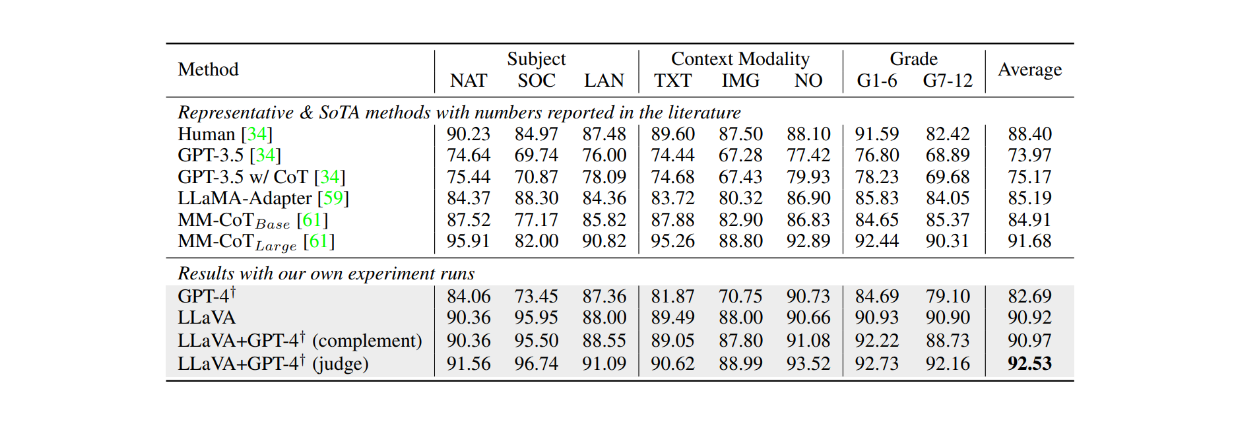
Figure: LLMs’ accuracy on the ScienceQA dataset. Source.
Conclusion
LLaVA represents an early advancement in developing visual-based Large Language Models (LLMs) capable of following textual instructions. The model combines a pre-trained Vision Transformer (ViT) from CLIP for image processing with Vicuna as its language model backbone, using a projection layer to align the feature dimensions between the two components. The model is then fine-tuned on 158K multimodal instruction-following data samples.
Thanks to this visual instruction tuning approach, LLaVA can describe and perform complex reasoning on a given image according to the instructions in the prompt. The evaluation results demonstrate the effectiveness of visual instruction tuning, as LLaVA's performance consistently outperforms two other visual-based models: BLIP-2 and OpenFlamingo.
Further Reading
Keep Reading

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.