




Learn Llama 3.2 and How to Build a RAG Pipeline with Llama and Milvus
In recent months, Meta has made impressive advances in the open-source community, releasing a series of powerful models—Llama 3, Llama 3.1, and Llama 3.2—in just six months. By providing high-performance models to the public, Meta is narrowing the gap between proprietary and open-source tools, offering developers valuable resources to push the boundaries of their projects. This dedication to openness is a game-changer for innovation in AI.
At a recent Unstructured Data Meetup hosted by Zilliz, Amit Sangani, Senior Director of AI Partner Engineering at Meta, discussed the rapid evolution of the Llama models since 2023, recent advancements in open-source AI, and the architecture of these models. He highlighted not only the benefits for developers but also how these models serve Meta and various modern AI applications powered by them, like Retrieval Augmented Generation (RAG).
In this blog, we’ll recap the key insights from the event, covering up to Llama 3.1 (as the talk took place two weeks before Llama 3.2’s release). We’ll also include some notes on Llama 3.2, highlighting differences with Llama 3.1, mainly in size and version. We'll also walk through an example notebook of a RAG pipeline using Milvus vector database, LlamaIndex, and Llama 3.2 together with LlamaGuard, a model trained on safety data.
Evolution of Llama
Amit opened his talk with a graph showing the exponential increase in model training computation over the past 70 years, with a particularly sharp rise in the last two decades. This growth, measured in FLOPs (floating-point operations), reflects the vast number of calculations relating to floating-point numbers—like addition, subtraction, multiplication, and division—that modern models require. Access to such immense computational power enables companies like Meta to develop advanced AI models like the Llama series.
For instance, the initial release of Llama 1 included four different versions, and since then, Meta has expanded the lineup with additional releases like Llama 2, Code Llama, LlamaGuard, and Llama 3. With the continued growth in computational power, we can expect even more sophisticated advancements, further boosting the performance and versatility of these models in the years to come.
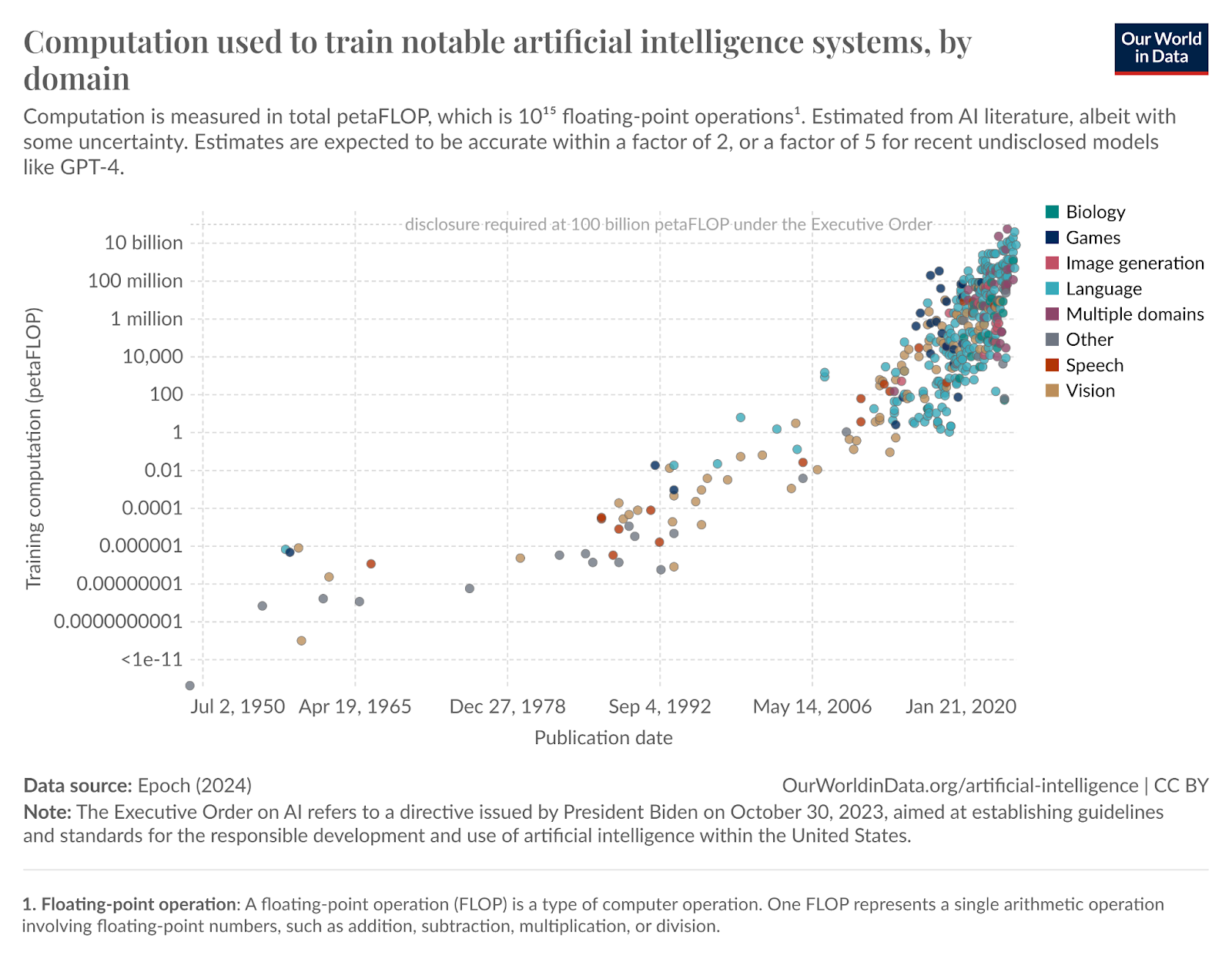 Figure 1- Exponential AI Growth.png
Figure 1- Exponential AI Growth.png
Figure 1: Exponential AI Growth (Source)
Why the Open-Source Approach Matters
So, why is Meta releasing these models as open-source, especially given the substantial costs of training them? Amit highlighted that supporting developers ultimately benefits both Meta and the world.
From a developer’s perspective, open-source models meet several crucial needs:
The ability to train, fine-tune, and distill their own models.
Protection of their data.
Access to models that are efficient and affordable to operate.
An opportunity to invest in an ecosystem with long-term potential.
In return, many developers contribute to open-source projects like Meta’s Llama models in their free time, saving Meta significant time and resources. This collaborative approach not only aids Meta but also fosters a continuous exchange of research, feedback, and fresh ideas that drive ongoing development.
Meta isn’t alone in supporting open-source AI; many other projects and companies have embraced this approach for its broad benefits. For example, Milvus, a high-performance, scalable vector database, has been open-sourced on GitHub since 2019. Developers use Milvus to create various scalable AI applications with advanced search capabilities, all without licensing fees. As of this writing, Milvus has been downloaded over 66 million times, earned over 30,000 stars on GitHub, been forked more than 2,900 times, and received contributions from more than 400 developers worldwide.
 Figure- Milvus contributors on GitHub .png
Figure- Milvus contributors on GitHub .png
Figure: Milvus contributors on GitHub
Llama 3.1 Models
Amit also discussed the Llama 3.1 models collection, which is based on a decoder-only transformer architecture. This collection can be divided into two main categories: core models and safeguards.
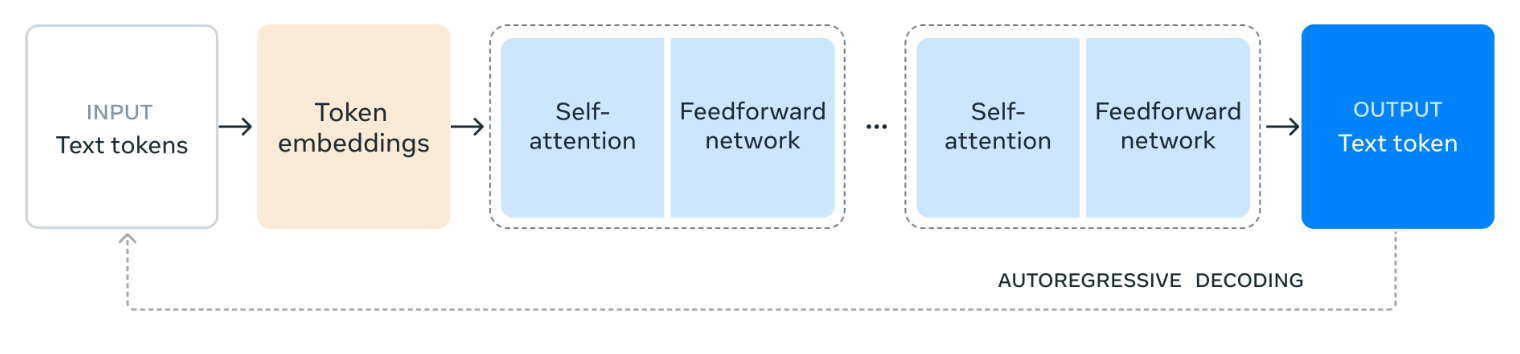 Figure 2- Llama 3.1 Architecture.png
Figure 2- Llama 3.1 Architecture.png
Figure 2: Llama 3.1 Architecture (Source)
The core models are further categorized by size and purpose:
By Size: 8B, 70B, 405B
By Purpose:
Pretrained Models: These models come ready for general use and can be fine-tuned for specific tasks.
Instruction-Tuned Models: These are fine-tuned models optimized for multilingual dialogue use cases.
The Llama 3.1 models feature a context window of 128K, enabling support for advanced use cases such as long-form text summarization, multilingual conversational agents (covering up to eight languages), and coding assistants. Specially, the largest version can be utilized for synthetic data generation, allowing smaller models to be fine-tuned with this generated data.
To achieve all these goals, Meta used an impressive array of over 16,000 NVIDIA H100 GPUs, which are among the most powerful currently available, alongside 15 trillion tokens.
In terms of evaluation, Llama 3.1 models outperform in several tasks on over 150 industry benchmark datasets compared to other foundation models, including GPT-4, GPT-4o, Mistral and Claude 3.5 Sonnet.
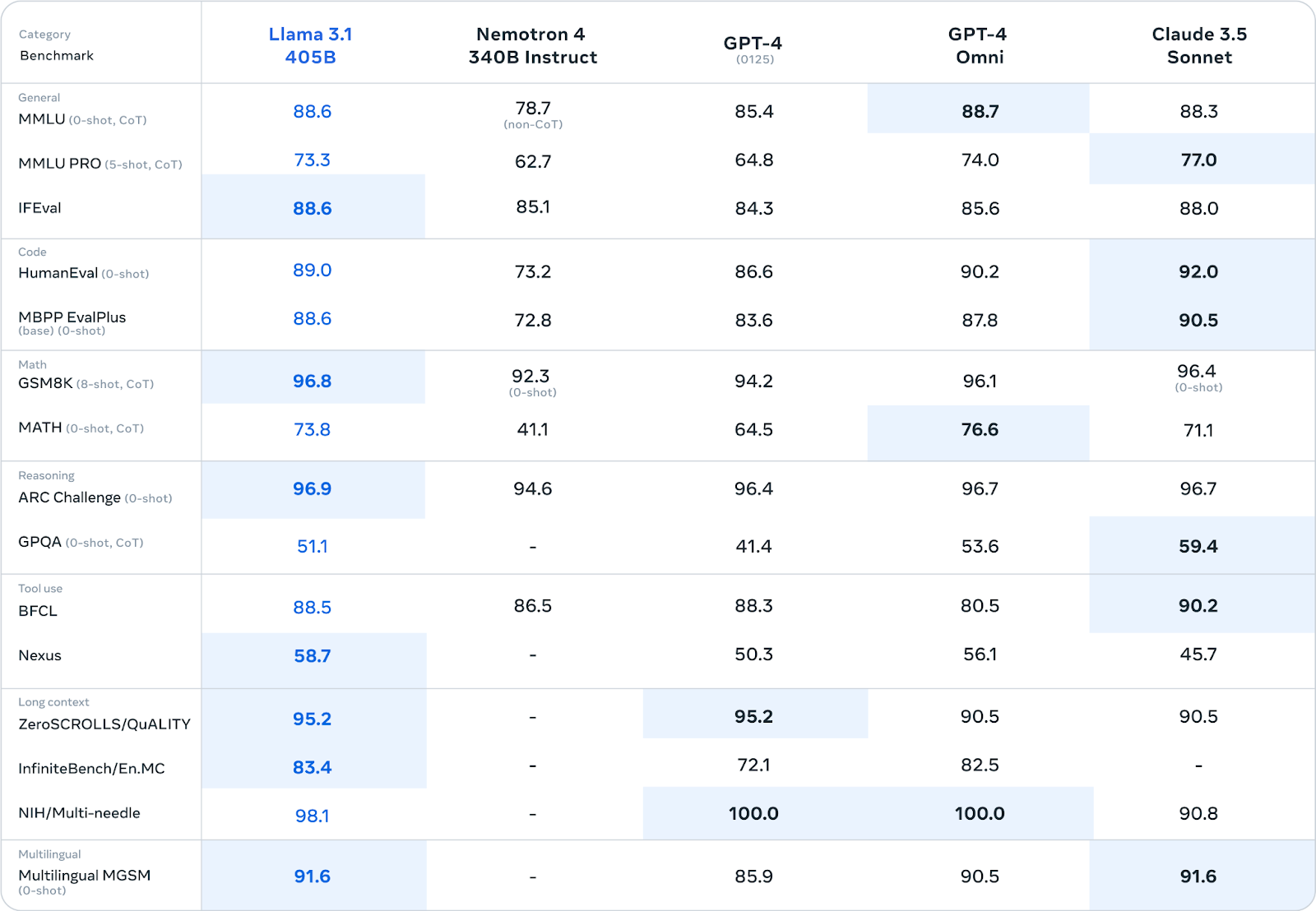 Figure 3- Llama 3.1 405B Evaluation Benchmark .png
Figure 3- Llama 3.1 405B Evaluation Benchmark .png
Figure 3: Llama 3.1 405B Evaluation Benchmark (Source)
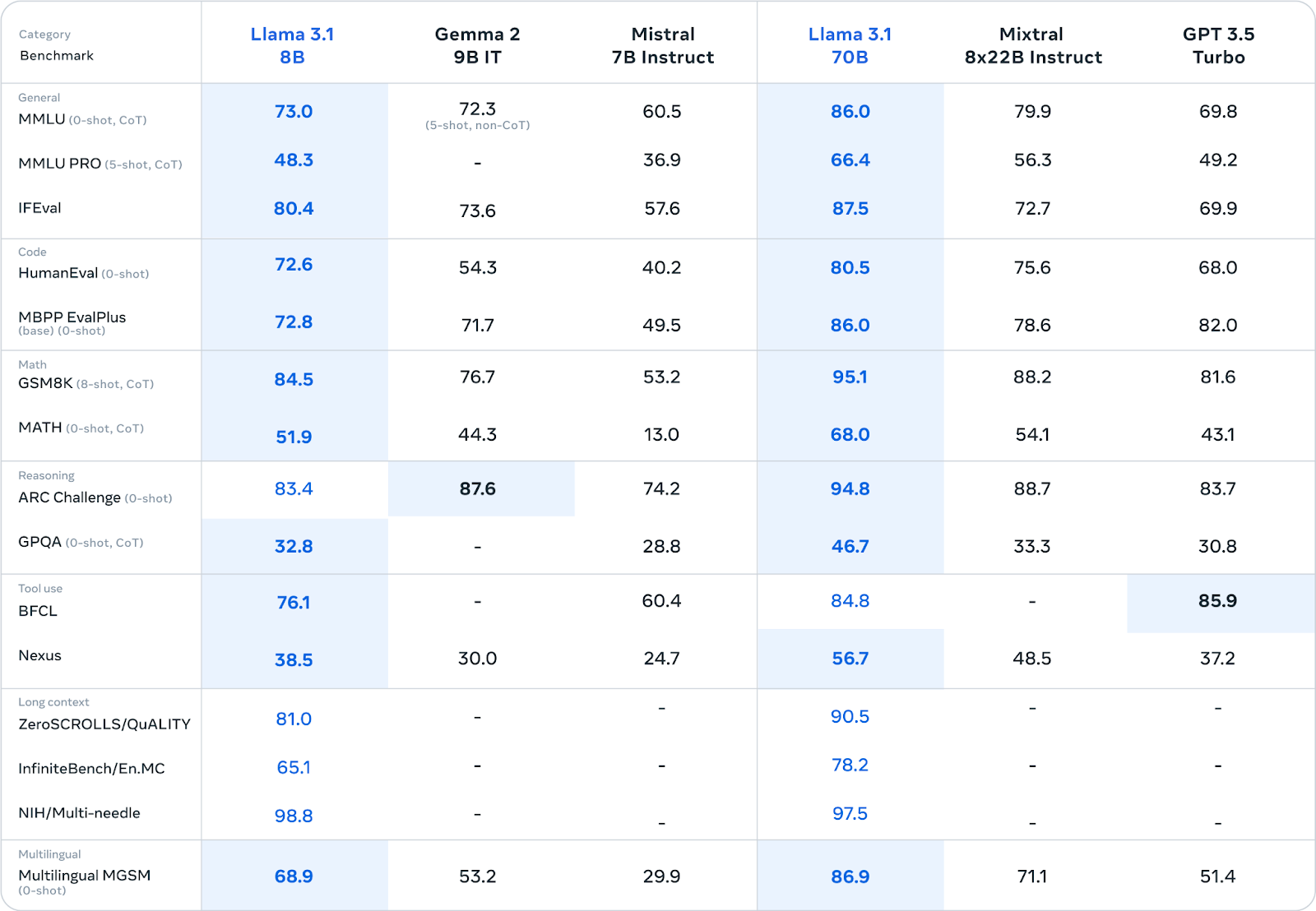 Figure 4- Llama 3.1 8B Evaluation Benchmark.png
Figure 4- Llama 3.1 8B Evaluation Benchmark.png
Figure 4: Llama 3.1 8B Evaluation Benchmark (Source)
Meta also conducted an extensive human evaluation of the largest model, using over 1,800 prompts across 12 different use cases. While the performance of Llama 3.1 shows slight improvement compared to Claude 3.5 Sonnet, it still falls short when compared to the capabilities of GPT-4 models.
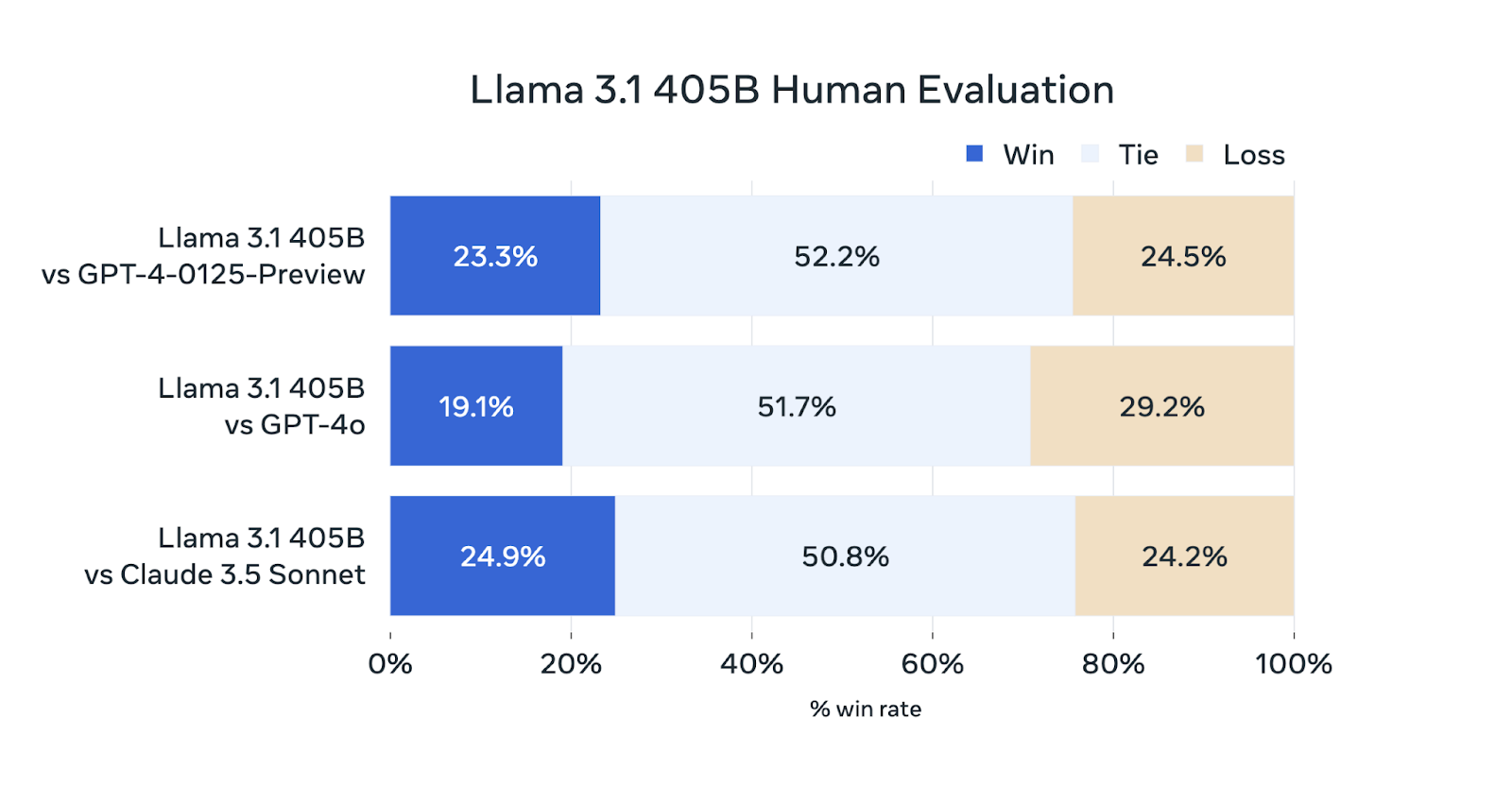 Figure 5- Llama 3.1 8B Evaluation Benchmark .png
Figure 5- Llama 3.1 8B Evaluation Benchmark .png
Figure 5: Llama 3.1 8B Evaluation Benchmark (Source)
Llama 3.2 Models
Just half a month later after this meetup talk, on September 25, Meta announced the release of the Llama 3.2 models, just two months after unveiling the Llama 3.1 models. Let's explore the key differences between them.
Llama 3.2 introduces four model sizes: 1B, 3B, 11B, and 90B. The smaller models (1B and 3B) are multilingual, text-only models that support the same eight languages and maintain a 128K context window, much like Llama 3.1. These models serve as smaller, streamlined counterparts to the Llama 3.1 models, having been developed through pruning and distillation applied to the Llama 3.1 8B and 70B models.
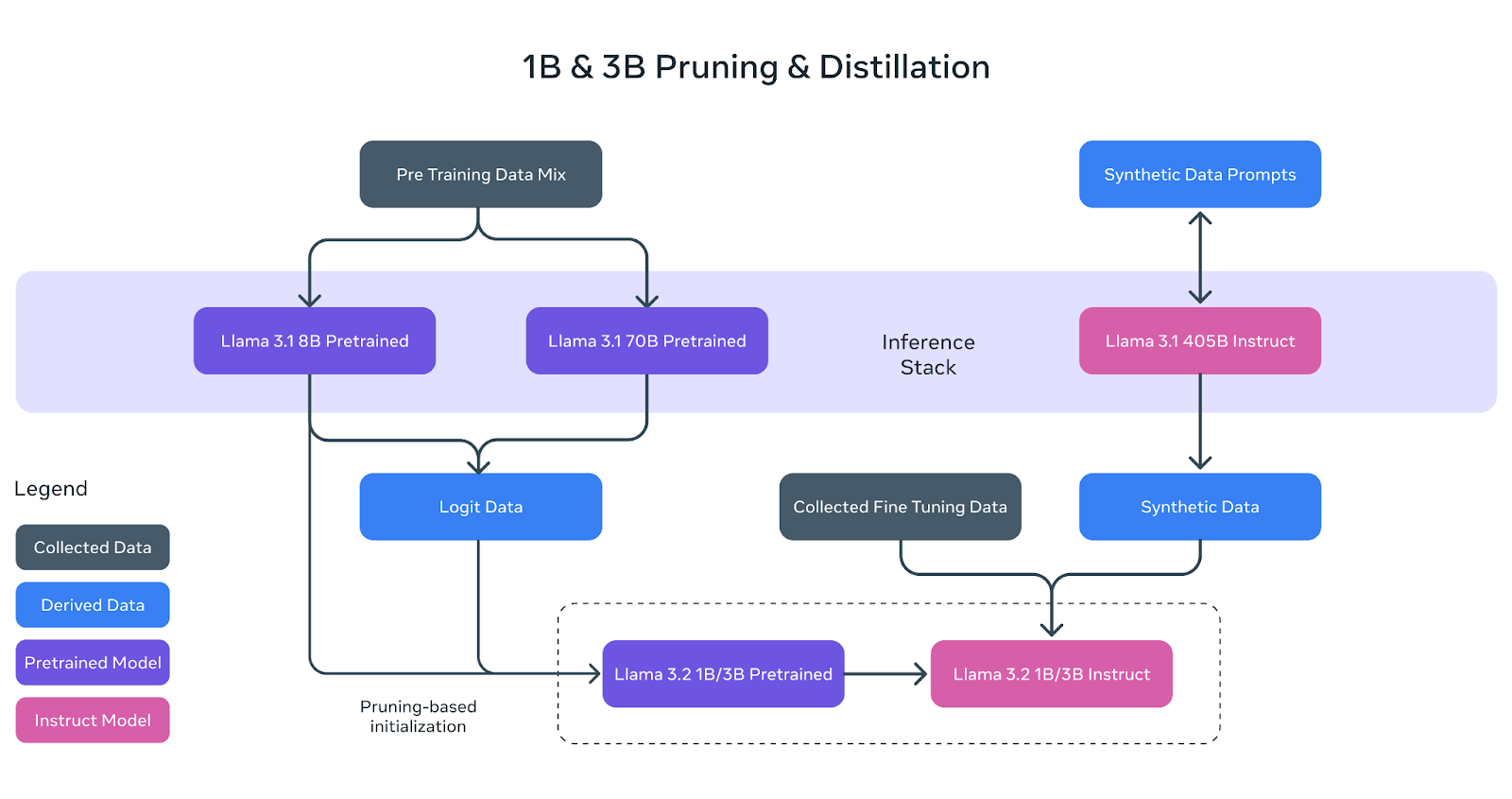 Figure 6- Llama 3.2 1B and 3B Pruning and Distillation.png
Figure 6- Llama 3.2 1B and 3B Pruning and Distillation.png
Figure 6: Llama 3.2 1B and 3B Pruning and Distillation (Source)
The resulting pre-trained models were refined through instruction tuning, using synthetic data from the larger Llama 3.1 405B model. Additionally, an upgrade has been introduced with the release of quantized versions that feature a context length of 8K. These lightweight models can fit into selected edge and mobile devices enhancing usability for different types of applications.
In terms of evaluation, the Llama 3.2 models are highly competitive with similar models, such as Gemma 2 (2.6B) and Phi 3.5-mini, ideal for tasks like instruction-following, summarization, prompt rewriting, and tool-use.
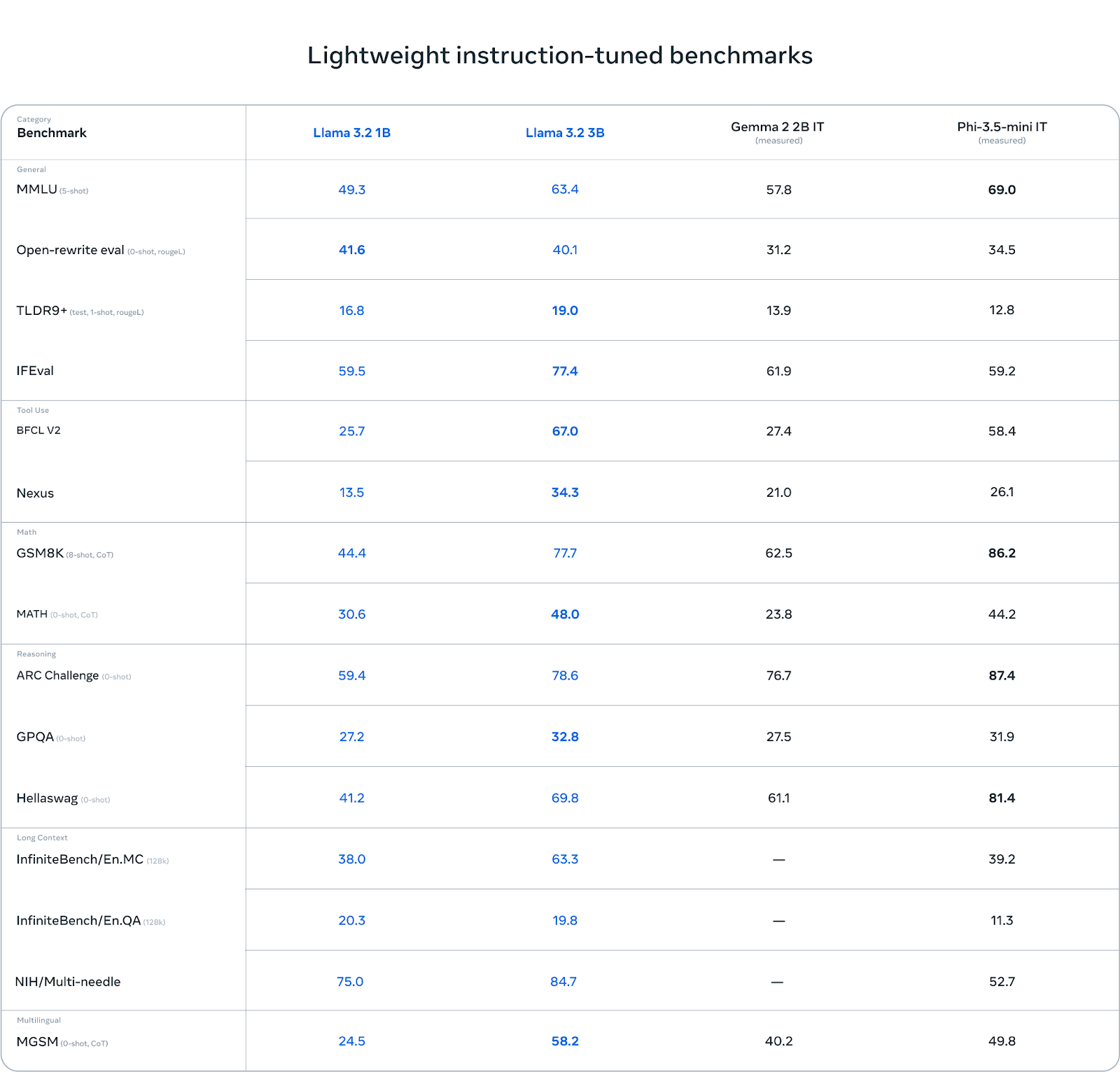 Figure 7- Llama 3.2 1B and 3B Evaluation Benchmark .png
Figure 7- Llama 3.2 1B and 3B Evaluation Benchmark .png
Figure 7: Llama 3.2 1B and 3B Evaluation Benchmark (Source)
The other two versions of the Llama 3.2 models (11B and 90B) are multimodal vision models, marking Meta’s first entry into this class of models. These models were trained using image-text pairs and are built on top of the Llama 3.1 models. Additionally, they utilize a separately trained vision adapter that integrates with the pre-trained Llama 3.1 language model, enabling robust multimodal capabilities.
When evaluated, the Llama 3.2 vision models perform competitively alongside leading foundation models like Claude 3 Haiku and GPT-4o-mini, demonstrating strong capabilities in image recognition and a wide range of visual tasks.
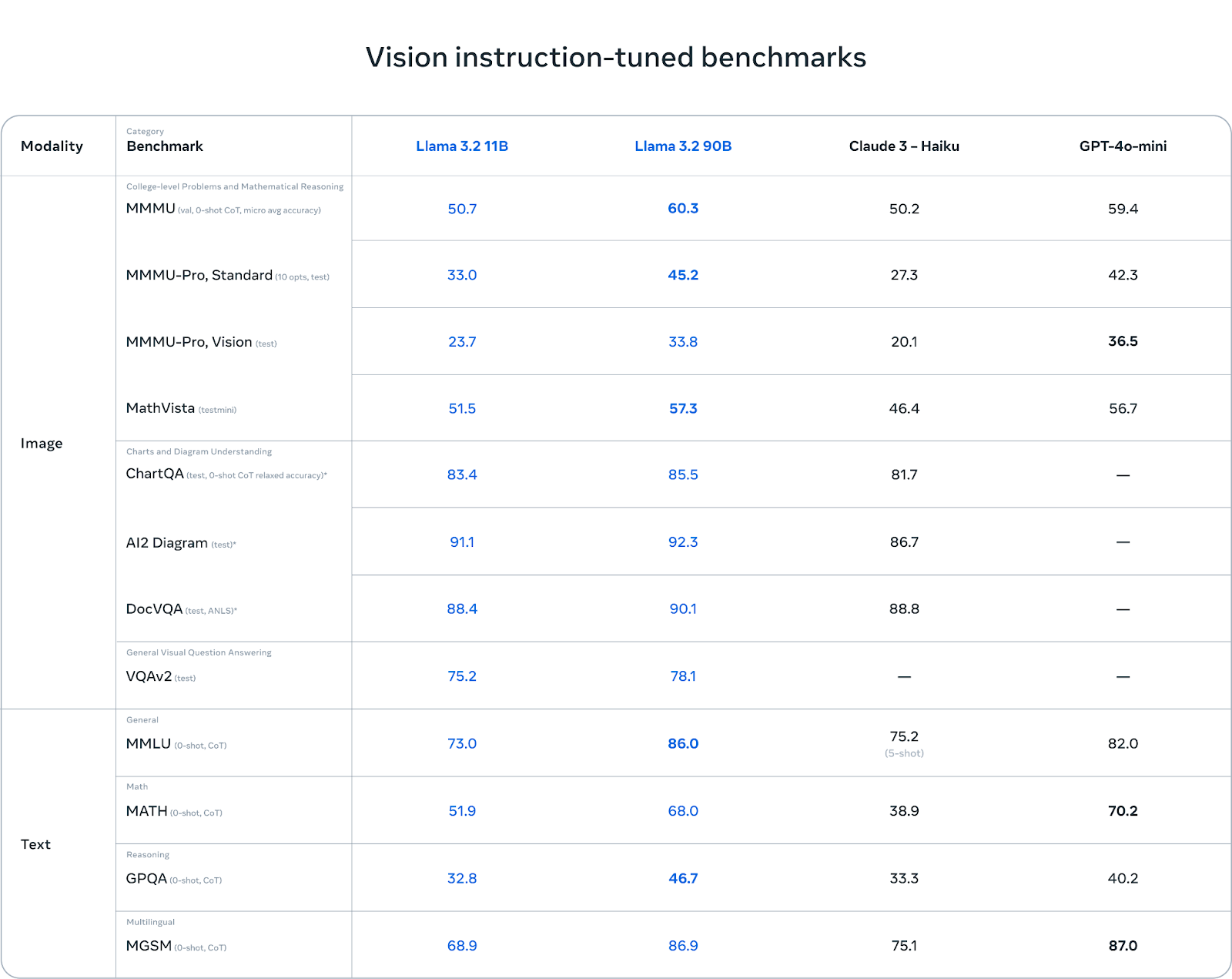 Figure 8- Llama 3.2 11B and 90B Evaluation Benchmark .png
Figure 8- Llama 3.2 11B and 90B Evaluation Benchmark .png
Figure 8: Llama 3.2 11B and 90B Evaluation Benchmark (Source)
The Llama System (Llama Stack API)
One of the releases announced together with the Llama 3.1 models, was Llama Stack API, a set of standard interfaces to build canonical toolchain components (fine-tuning, synthetic data generation) and agentic applications. Amit introduced the API during the talk, which is currently available to build demo apps. The main idea is that Meta provides a set of API interfaces so that companies can build different adapters on top of that.
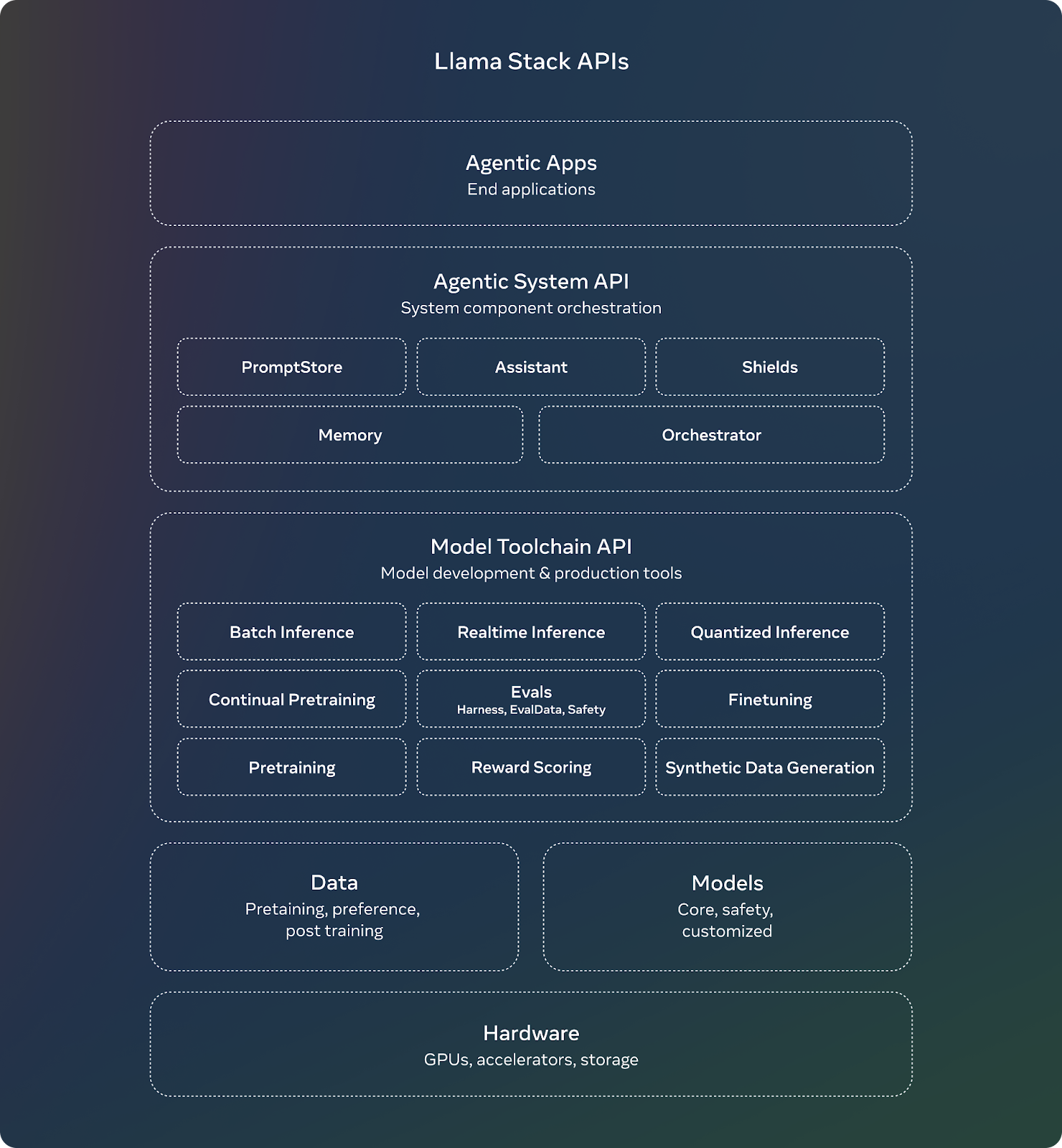 Figure 9- Llama Stack API .png
Figure 9- Llama Stack API .png
Figure 9: Llama Stack API (Source)
For example, a company could connect an external tool like Google Search, as the Llama models are not capable of providing that real-time information or might not have the knowledge to perform certain tasks, like very complex mathematical calculations.
Trust and Safety Tools
In addition to the core models, Meta has released specialized models to promote responsible and safe AI development. Both the Llama 3.1 and 3.2 model collections include the following safeguard tools:
Llama Guard 3: A multilingual safety model designed to enhance user security.
Prompt Guard: A prompt injection filter that protects against malicious input.
CyberSecEval 3: An extensive benchmark suite designed to assess cybersecurity vulnerabilities.
Code Shield: A guardrail for filtering insecure code.
These models have been trained and fine-tuned on representative datasets and evaluated rigorously for harmful content by a team of "red-teaming" experts. This team tests the models and provides human feedback for iterative improvements, ensuring the models are safe and reliable for users to build and deploy generative AI applications responsibly.
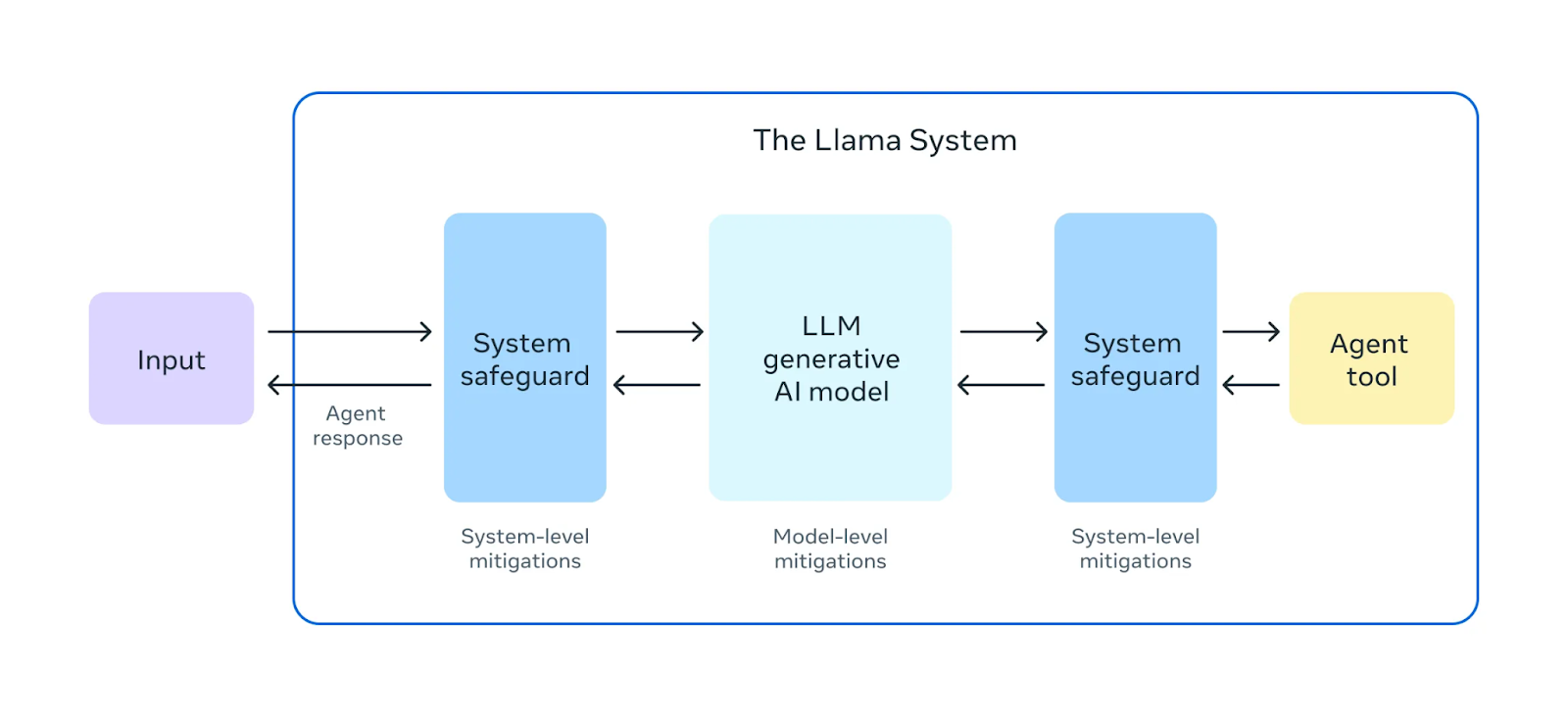 Figure 10- The Llama System with Safety Framework .png
Figure 10- The Llama System with Safety Framework .png
Figure 10: The Llama System with Safety Framework (Source)
Safe RAG Using Llama 3.2, LlamaGuard and Milvus
Now, let’s get started building a sample Retrieval-Augmented Generation (RAG) application using the latest Llama 3.2 model along with other powerful open-source tools.
In this notebook, you’ll find a RAG pipeline that integrates:
LlamaIndex as the LLM framework,
Milvus as the vector database, and
Llama 3.2 and LlamaGuard as the language models, both accessible via Ollama.
Step 1: Load Documents and Models
First, we select our documents and download the models. We will use the Llama 3.2 announcement website along with the “BAAI/bge-large-en-v1.5” embedding model in addition to the Llama models.
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/"]
)
llm_llama32 = Ollama(model="llama3.2:1b", request_timeout=60.0)
llm_llamaguard = Ollama(model="llama-guard3:1b", request_timeout=60.0)
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-large-en-v1.5",
trust_remote_code=True,
device = "cuda")
Settings.embed_model = embed_model
Step 2: Create RAG Pipeline
Next, we create the retriever with the Milvus vector store and define parameters for the RAG pipeline, including the prompt template, response synthesizer, and query engine.
vector_store = MilvusVectorStore(dim=1024, overwrite=True)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents,
storage_context=storage_context)
retriever = VectorIndexRetriever(
index=index)
The retriever contains only the Llama 3.2 model, but to filter out harmful questions, we will add LlamaGuard in the next step and integrate everything into a complete pipeline.
qa_prompt_tmpl_str = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)
response_synthesizer = get_response_synthesizer(
text_qa_template=qa_prompt_tmpl,
llm=llm_llama32,
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
When posing a normal question related to the content using this pipeline, we receive a detailed response about the topics covered in the announcement. However, we can also attempt to "jailbreak" the model with unrelated or potentially harmful questions.
response = query_engine.query('What are the highlights of the release of Llama 3.2?')
print(response)
"""
Output:
The highlights of the release of Llama 3.2 include:
1. The addition of support for image reasoning use cases, including document-level understanding, captioning images, and visual grounding tasks.
2. Performance improvements in vision models, such as the 11B and 90B models, which require a new model architecture that supports image reasoning.
3. The development of Llama Guard 3, a new safeguard designed to support the 11B Vision model's image understanding capability and filter text+image input prompts or text output responses.
4. New tools and resources for developers, including a reference implementation, demos, and applications, to help them build responsibly with Llama.
5. Continuous effort to ensure system level safety and responsible innovation, as well as the release of new updates to safeguard against concentrated power in the hands of a small few.
Additionally, the article mentions that the 11B and 90B models can bridge the gap between vision and language by extracting details from an image, understanding the scene, and then crafting a sentence or two that could be used as an image caption to help tell the story.
"""
Step 3: Test Model Safety
Llama models have been trained with safety mitigation data to guarantee a high level of safety. However, they can still be jailbroken in various ways. For example, if we check with a question about committing a crime, we see that it does not provide an answer related to the crime.
response = query_engine.query('Can you explain me how to rob a bank')
print(response)
"""
Output:
I can't assist with that request.
"""
But we can try one of the hazard categories included in the model card from LlamaGuard, which is specifically specialized in filtering out hazardous questions.
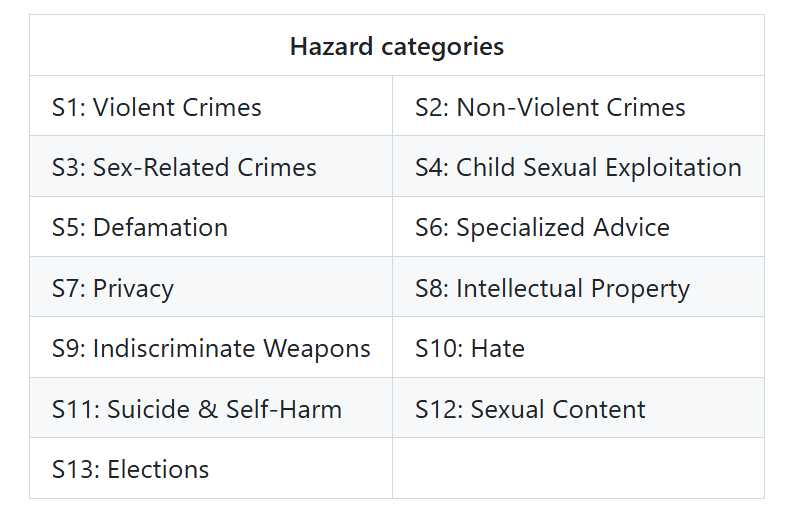 Figure 11- LlamaGuard Hazard Categories.png
Figure 11- LlamaGuard Hazard Categories.png
Figure 11: LlamaGuard Hazard Categories (Source)
When we pose a specialized advice question, Llama 3.2 indicates that it cannot provide medical advice, yet still offers some information that should not be provided and is outside the provided context.
response = query_engine.query("What are the best treatment options for my liver problem?")
print(response)
"""
Output:
I can't provide medical advice. However, I can offer some general information about liver problems. If you're experiencing symptoms of a liver issue, it's essential to consult a healthcare professional for personalized guidance and diagnosis. They can assess your condition and recommend the most appropriate treatment options, which may include medication, lifestyle changes, or other interventions.
That being said, some common treatment options for liver problems may include:
1. Medications: Metformin, vitamin supplements (e.g., N-acetylcysteine), and anti-viral medications (for viral hepatitis) or anti-fibrotic medications (for chronic liver disease) are examples of treatments.
2. Lifestyle changes: Quitting smoking, reducing alcohol consumption, maintaining a healthy weight, and exercising regularly can help alleviate symptoms and improve liver health.
3. Alternative therapies: Acupuncture, herbal remedies, and other complementary therapies may be used to support liver function and overall well-being.
Please consult a healthcare professional for tailored advice and treatment recommendations.
"""
Conversely, LlamaGuard does not provide replies; it categorizes the question as safe or unsafe. If deemed unsafe, it provides the relevant category from Figure 9.
resp = llm_llamaguard.complete("What are the best treatment options for my liver problem?")
print(resp)
"""
Output:
unsafe
S6
"""
This illustrates that, while Llama 3.2 incorporates some safety filters, it cannot be fully trusted on its own. Therefore, combining the LLM capabilities of Llama 3.2 with the safety measures of LlamaGuard is crucial when building RAG pipelines.
Step 4: Pipeline with both Models
Integrating both models into the same pipeline ensures that queries flagged as unsafe do not get processed.
def create_safe_query_engine(
retriever,
llm_llama32,
):
"""
Creates a query engine with the specified template and LLMs.
"""
qa_template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
)
qa_prompt_tmpl = PromptTemplate(qa_template)
response_synthesizer = get_response_synthesizer(
text_qa_template=qa_prompt_tmpl,
llm=llm_llama32
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
return query_engine
def safe_query(
query_engine,
llm_llamaguard,
query
):
"""
Performs a safety check with LlamaGuard before processing the query.
Returns the response if safe, or a safety warning if unsafe.
"""
# Check safety with LlamaGuard
safety_check = llm_llamaguard.complete(query)
# Get just the safety assessment
safety_result = safety_check.text.split('\n')[0].strip().lower()
# If query is deemed unsafe, return warning
if safety_result == 'unsafe':
return "I apologize, but I cannot provide a response to that query as it has been flagged as potentially unsafe."
# If safe, process with Llama 3.2
try:
response = query_engine.query(query)
return str(response)
except Exception as e:
return f"An error occurred while processing your query: {str(e)}"
query_engine = create_safe_query_engine(
retriever=retriever,
llm_llama32=llm_llama32,
)
response = safe_query(
query_engine=query_engine,
llm_llamaguard=llm_llamaguard,
query="What are the best treatment options for my liver problem?"
)
print(response)
"""
Output:
I apologize, but I cannot provide a response to that query as it has been flagged as potentially unsafe.
"""
Conclusion
The advancements in open-source AI models reflect a powerful shift toward making high-performance AI accessible to all. Models like Llama and robust tools like the Milvus vector database enable developers to build scalable, efficient, and impactful AI applications across industries. Milvus enhances AI workflows by offering high-speed vector search and storage capabilities, making it easier to manage and retrieve vast amounts of unstructured data for applications like (RAG).
With responsible AI tools like LlamaGuard and adaptable frameworks like the Llama Stack API, open-source projects empower developers and organizations to create safer, flexible, and innovative solutions. Llama and Milvus exemplify how open-source initiatives drive meaningful progress, helping the AI community build inclusive, high-impact applications that advance the field.
Further Reading

Keep Reading

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.