




GraphRAG Explained: Enhancing RAG with Knowledge Graphs
Introduction to RAG and Its Challenges
Retrieval Augmented Generation (RAG) is a technique that connects external data sources to enhance the output of large language models (LLMs). This technique is perfect for LLMs to access private or domain-specific data and address hallucination issues. Therefore, RAG has been widely used to power many GenAI applications, such as AI chatbots and recommendation systems.
A baseline RAG usually integrates a vector database and an LLM, where the vector database stores and retrieves contextual information for user queries, and the LLM generates answers based on the retrieved context. While this approach works well in many cases, it struggles with complex tasks like multi-hop reasoning or answering questions that require connecting disparate pieces of information.
For example, consider this question: “What name was given to the son of the man who defeated the usurper Allectus?”
A baseline RAG would generally follow these steps to answer this question:
Identify the Man: Determine who defeated Allectus.
Research the Man’s Son: Look up information about this person’s family, specifically his son.
Find the Name: Identify the name of the son.
The challenge usually arises at the first step because a baseline RAG retrieves text based on semantic similarity, not directly answering complex queries where specific details may not be explicitly mentioned in the dataset. This limitation makes it difficult to find the exact information needed, often requiring expensive and impractical solutions like manually creating Q&A pairs for frequent queries.
To address such challenges, Microsoft Research introduced GraphRAG, a brand-new method that augments RAG retrieval and generation with knowledge graphs. In the following sections, we’ll explain how GraphRAG works under the hood and how to run it with the Milvus vector database.
What is GraphRAG and How Does It Work?
Unlike a baseline RAG that uses a vector database to retrieve semantically similar text, GraphRAG enhances RAG by incorporating knowledge graphs (KGs). Knowledge graphs are data structures that store and link related or unrelated data based on their relationships.
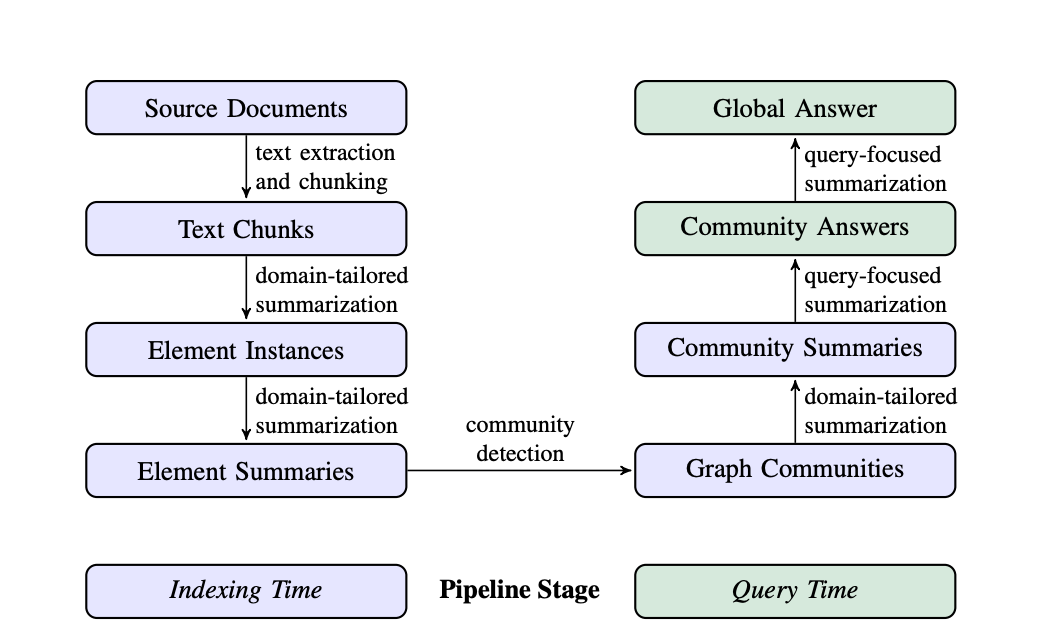
A GraphRAG pipeline usually consists of two fundamental processes: indexing and querying.
 The GraphRAG Pipeline
The GraphRAG Pipeline
The GraphRAG Pipeline (Image Source: GraphRAG Paper)
Indexing
The indexing process includes four key steps:
Text Unit Segmentation: The entire input corpus is divided into multiple text units (text chunks). These chunks are the smallest analyzable units and can be paragraphs, sentences, or other logical units. By segmenting long documents into smaller chunks, we can extract and preserve more detailed information about this input data.
Entity, Relationship, and Claims Extraction: GraphRAG uses LLMs to identify and extract all entities (names of people, places, organizations, etc.), relationships between them, and key claims expressed in the text from each text unit. We will use this extracted information to construct an initial knowledge graph.
Hierarchical Clustering: GraphRAG uses the Leiden technique to perform hierarchical clustering on the initial knowledge graphs. Leiden is a community detection algorithm that can effectively discover community structures within the graph. Entities in each cluster are assigned to different communities for more in-depth analysis.
Note: A community is a group of nodes within the graph that are densely connected to each other but sparsely connected to other dense groups in the network.
- Community Summary Generation: GraphRAG generates summaries for each community and its members using a bottom-up approach. These summaries include the main entities within the community, their relationships, and key claims. This step gives an overview of the entire dataset and provides useful contextual information for subsequent queries.
 Figure 1- An LLM-generated knowledge graph built using GPT-4 Turbo.
Figure 1- An LLM-generated knowledge graph built using GPT-4 Turbo.
Figure 1: An LLM-generated knowledge graph built using GPT-4 Turbo.
(Image Source: Microsoft Research)
Querying
GraphRAG has two different querying workflows tailored for different queries.
Global Search for reasoning about holistic questions related to the whole data corpus by leveraging the community summaries.
Local Search for reasoning about specific entities by fanning out to their neighbors and associated concepts.
This global search workflow includes the following phases.
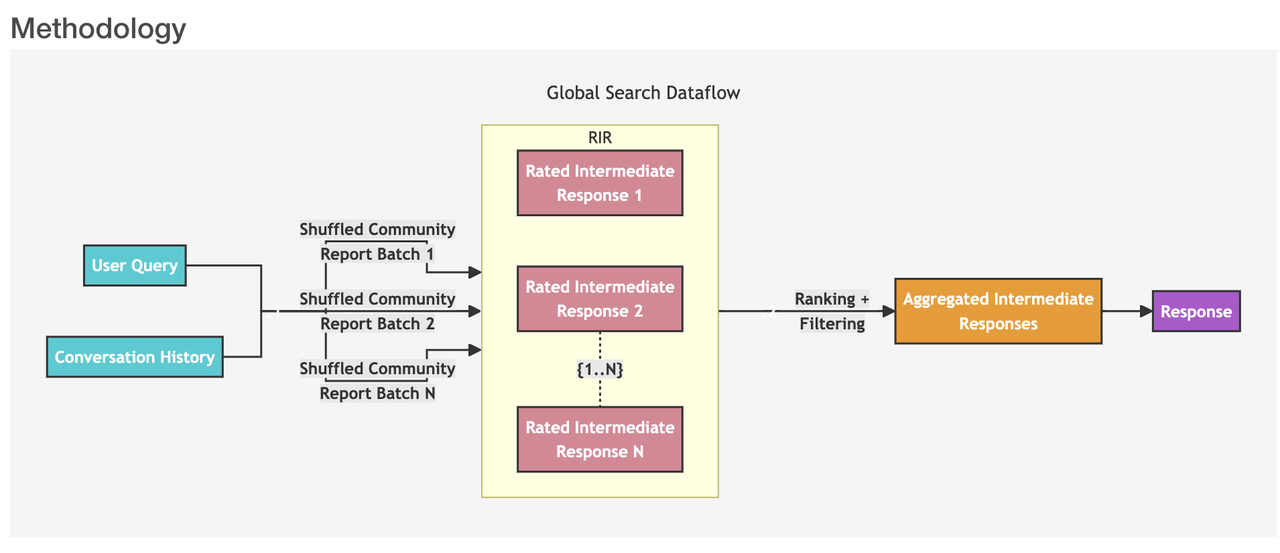 Figure 2- Global search dataflow
Figure 2- Global search dataflow
Figure 2: Global search dataflow (Image Source: Microsoft Research)
User Query and Conversation History: The system takes user query and conversation history as the initial input.
Community Report Batches: The system uses node community reports generated by the LLM from a specified level of the community hierarchy as context data. These community reports are shuffled and divided into multiple batches (Shuffled Community Report Batch 1, Batch 2... Batch N).
RIR (Rated Intermediate Responses): Each batch of community reports is further divided into predefined-sized text chunks. Each text chunk is used to generate an intermediate response. The response contains a list of information pieces called points. Each point has a numerical score indicating its importance. These generated intermediate responses are the Rated Intermediate Responses (Rated Intermediate Response 1, Response 2... Response N).
Ranking and Filtering: The system ranks and filters these intermediate responses, selecting the most important points. The selected important points form the Aggregated Intermediate Responses.
Final Response: The aggregated intermediate responses are used as context to generate the final reply.
When users ask questions about specific entities (such as names of people, places, organizations, etc.), we recommend you use the local search workflow. This process includes the following steps:
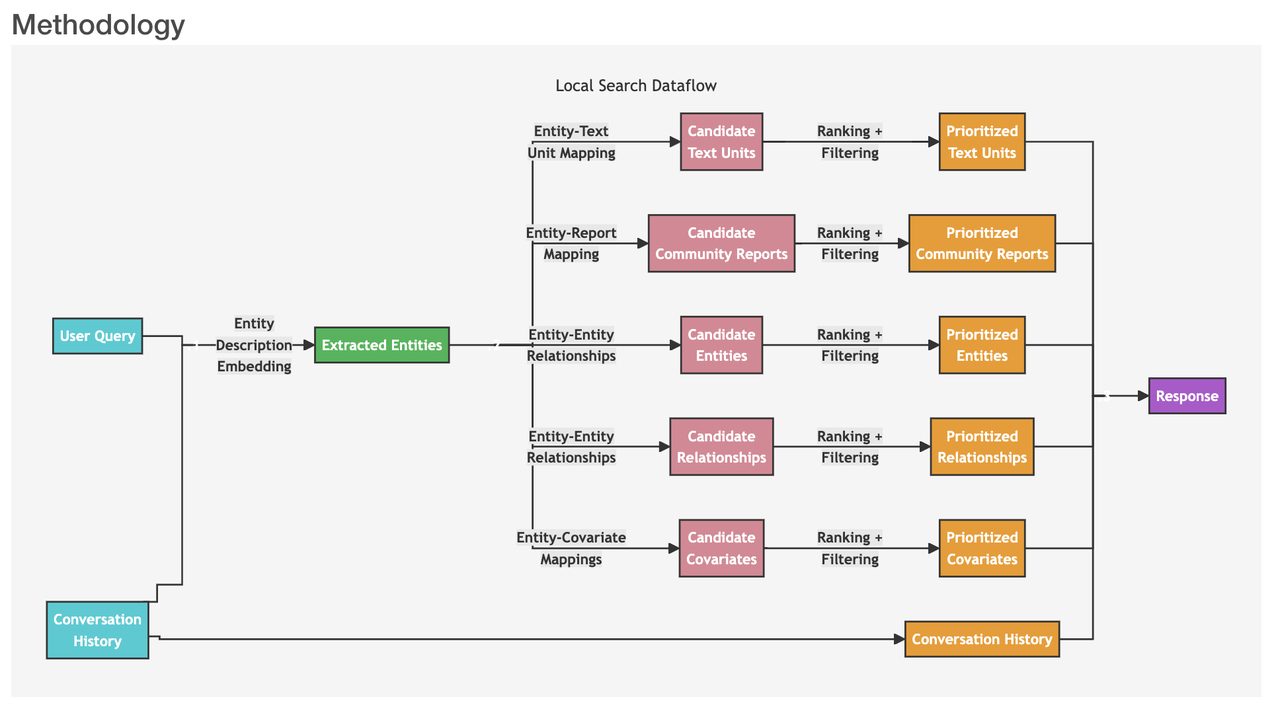 Figure 3- Local search dataflow
Figure 3- Local search dataflow
Figure 3: Local search dataflow (Image Source: Microsoft Research)
User Query: First, the system receives a user query, which could be a simple question or a more complex query.
Similar Entity Search: The system identifies a set of entities from the knowledge graph that are semantically related to the user input. These entities serve as entry points into the knowledge graph. This step uses a vector database like Milvus to conduct text similarity searches.
Entity-Text Unit Mapping: The extracted text units are mapped to the corresponding entities, removing the original text information.
Entity-Relationship Extraction: The step extracts specific information about the entities and their corresponding relationships.
Entity-Covariate Mapping: This step maps entities to their covariates, which may include statistical data or other relevant attributes.
Entity-Community Report Mapping: Community reports are integrated into the search results, incorporating some global information.
Utilization of Conversation History: If provided, the system uses conversation history to better understand the user's intent and context.
Response Generation: Finally, the system constructs and responds to the user query based on the filtered and sorted data generated in the previous steps.
Baseline RAG vs. GraphRAG in Output Quality
To showcase the effectiveness of GraphRAG, its creators compare the output quality of a baseline RAG and GraphRAG in their announcement blog. I'll cite a simple example for illustration here.
Dataset used
The GraphRAG creators used the Violent Incident Information from News Articles (VIINA) dataset for their experiments.
Note: This dataset contains sensitive topics. It was chosen solely due to its complexity and the presence of differing opinions and partial information. It is a messy real-world test case that was recent enough not to be included in the LLM base model’s training.
Experiment overview
Both the Baseline RAG and GraphRAG were asked the same question, which requires aggregating information across the dataset to compose an answer.
Q: What are the top 5 themes in the dataset?
The answers are shown in the image below. The Baseline RAG's results were irrelevant to the war themes, as the vector search retrieved unrelated text, leading to an inaccurate assessment. In contrast, GraphRAG provided a clear and relevant answer, identifying the main themes and supporting details. The results were aligned with the dataset, with references to source material.
 Figure 4- BaselineRAG vs. GraphRAG in answering complex summarization questions
Figure 4- BaselineRAG vs. GraphRAG in answering complex summarization questions
Figure 4: BaselineRAG vs. GraphRAG in answering complex summarization questions
Further experiments in the paper “From Local to Global: A Graph RAG Approach to Query-Focused Summarization.” demonstrate that GraphRAG significantly improves multi-hop reasoning and complex information summarization. The research indicates that GraphRAG surpasses Baseline RAG in both comprehensiveness and diversity:
Comprehensiveness: The extent to which the answer covers all aspects of the question.
Diversity: The variety and richness of perspectives and insights the answer provides.
We recommend you read the original GraphRAG paper for more details about these experiments.
How to Implement GraphRAG with the Milvus Vector Database
GraphRAG enhances RAG applications with knowledge graphs and also relies on a vector database to retrieve relevant entities. This section demonstrates how to implement GraphRAG, create a GraphRAG index, and query it using the Milvus vector database.
Prerequisites
Before running the code in this blog, make sure you have installed the following dependencies:
pip install --upgrade pymilvus
pip install git+https://github.com/zc277584121/graphrag.git
Note: We installed GraphRAG from a forked repository because the Milvus storage feature is still pending an official merge at the time of writing.
Let’s start with the indexing workflow.
Data Preparation
Download a small text file with about a thousand lines from Project Gutenberg and use it for GraphRAG indexing.
This dataset is about Leonardo Da Vinci's story. We use GraphRAG to build a graph index of all relationships related to Da Vinci and the Milvus vector database to search for relevant knowledge to answer questions.
import nest_asyncio
nest_asyncio.apply()
import os
import urllib.request
index_root = os.path.join(os.getcwd(), 'graphrag_index')
os.makedirs(os.path.join(index_root, 'input'), exist_ok=True)
url = "https://www.gutenberg.org/cache/epub/7785/pg7785.txt"
file_path = os.path.join(index_root, 'input', 'davinci.txt')
urllib.request.urlretrieve(url, file_path)
with open(file_path, 'r+', encoding='utf-8') as file:
# We use the first 934 lines of the text file, because the later lines are not relevant for this example.
# If you want to save api key cost, you can truncate the text file to a smaller size.
lines = file.readlines()
file.seek(0)
file.writelines(lines[:934]) # Decrease this number if you want to save api key cost.
file.truncate()
Initialize the workspace
Now, let’s use GraphRAG to index the text file. To initialize your workspace, let's first run the graphrag.index --init command.
python -m graphrag.index --init --root ./graphrag_index
Configure the env file and settings
You will find the .env file in the index's root directory. To use it, add your OpenAI API key to the .env file.
Important Notes: __
We will use OpenAI models for this example; ensure you have an API key ready.
GraphRAG indexing is costly as it processes the entire text corpus with LLMs. Running this demo may cost a few dollars. To save money, consider truncating the text file to a smaller size.
Running the indexing pipeline
The indexing process will take some time. Once completed, you’ll find a new folder at ./graphrag_index/output/<timestamp>/artifacts containing a series of parquet files.
python -m graphrag.index --root ./graphrag_index
Querying with the Milvus vector database
During the querying stage, we use Milvus to store entity description embeddings for GraphRAG local search. This method combines structured data from the knowledge graph with unstructured data from input documents, enhancing the LLM context with relevant entity information for more precise answers.
import os
import pandas as pd
import tiktoken
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (
# read_indexer_covariates,
read_indexer_entities,
read_indexer_relationships,
read_indexer_reports,
read_indexer_text_units,
)
from graphrag.query.input.loaders.dfs import (
store_entity_semantic_embeddings,
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import (
LocalSearchMixedContext,
)
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.vector_stores import MilvusVectorStore
output_dir = os.path.join(index_root, "output")
subdirs = [os.path.join(output_dir, d) for d in os.listdir(output_dir)]
latest_subdir = max(subdirs, key=os.path.getmtime) # Get latest output directory
INPUT_DIR = os.path.join(latest_subdir, "artifacts")
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
RELATIONSHIP_TABLE = "create_final_relationships"
COVARIATE_TABLE = "create_final_covariates"
TEXT_UNIT_TABLE = "create_final_text_units"
COMMUNITY_LEVEL = 2
Load data from the indexing process
During the indexing process, a few parquet files will be generated. We load them into memory and store the entity description information in the Milvus vector database.
Read entities:
# read nodes table to get community and degree data
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
description_embedding_store = MilvusVectorStore(
collection_name="entity_description_embeddings",
)
# description_embedding_store.connect(uri="http://localhost:19530") # For Milvus docker service
description_embedding_store.connect(uri="./milvus.db") # For Milvus Lite
entity_description_embeddings = store_entity_semantic_embeddings(
entities=entities, vectorstore=description_embedding_store
)
print(f"Entity count: {len(entity_df)}")
entity_df.head()
Entity count: 651
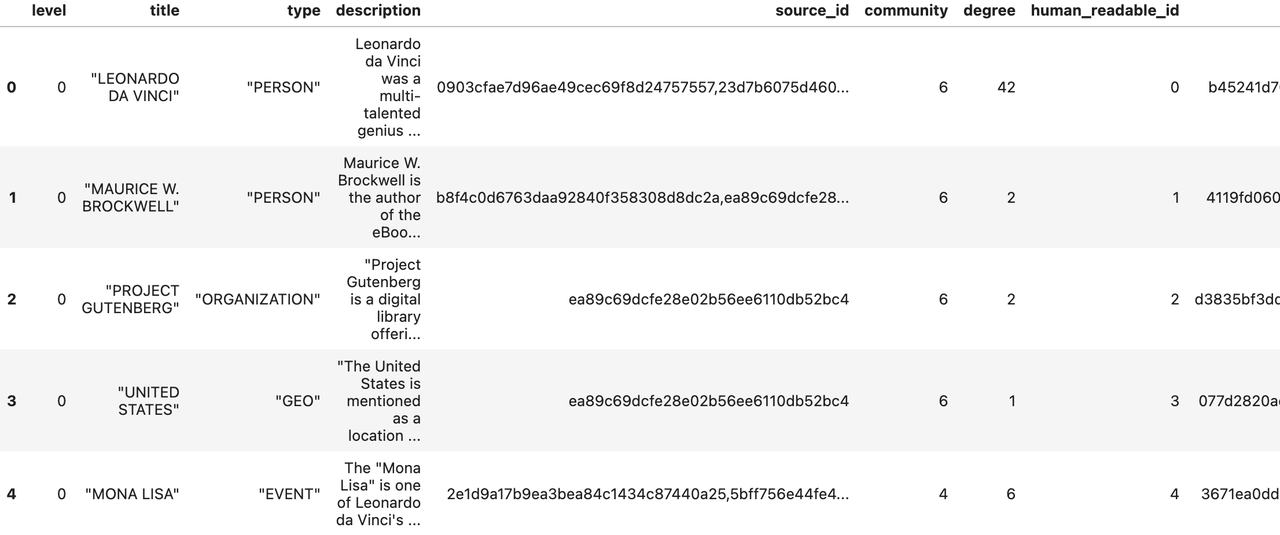 Figure 5: a screenshot of entities
Figure 5: a screenshot of entities
Figure 5: a screenshot of entities
Read relationships
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
relationships = read_indexer_relationships(relationship_df)
print(f"Relationship count: {len(relationship_df)}")
relationship_df.head()
Relationship count: 290
 Figure 6- a screenshot of relationships
Figure 6- a screenshot of relationships
Figure 6: a screenshot of relationships
Read community reports
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
print(f"Report records: {len(report_df)}")
report_df.head()
Report records: 45
 Figure 7- a screenshot of report records
Figure 7- a screenshot of report records
Figure 7: a screenshot of report records
Read text units
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
text_units = read_indexer_text_units(text_unit_df)
print(f"Text unit records: {len(text_unit_df)}")
text_unit_df.head()
Text unit records: 51
 Figure 8- a screenshot of text unit records
Figure 8- a screenshot of text unit records
Figure 8: a screenshot of text unit records
Create a local search engine
We have prepared the necessary data for the local search engine. Now, we can build a LocalSearch instance with them, an LLM, and an embedding model.
We have prepared the necessary data for the local search engine. Now, we can build a LocalSearch instance with them, an LLM, and an embedding model.
api_key = os.environ["OPENAI_API_KEY"] # Your OpenAI API key
llm_model = "gpt-4o" # Or gpt-4-turbo-preview
embedding_model = "text-embedding-3-small"
llm = ChatOpenAI(
api_key=api_key,
model=llm_model,
api_type=OpenaiApiType.OpenAI,
max_retries=20,
)
token_encoder = tiktoken.get_encoding("cl100k_base")
text_embedder = OpenAIEmbedding(
api_key=api_key,
api_base=None,
api_type=OpenaiApiType.OpenAI,
model=embedding_model,
deployment_name=embedding_model,
max_retries=20,
)
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
covariates=None, #covariates,#todo
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID, # if the vectorstore uses entity title as ids, set this to EntityVectorStoreKey.TITLE
text_embedder=text_embedder,
token_encoder=token_encoder,
)
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": False,
"return_candidate_context": False,
"embedding_vectorstore_key": EntityVectorStoreKey.ID, # set this to EntityVectorStoreKey.TITLE if the vectorstore uses entity title as ids
"max_tokens": 12_000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 5000)
}
llm_params = {
"max_tokens": 2_000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 1000=1500)
"temperature": 0.0,
}
search_engine = LocalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
response_type="multiple paragraphs", # free form text describing the response type and format, can be anything, e.g. prioritized list, single paragraph, multiple paragraphs, multiple-page report
)
Make a query.
result = await search_engine.asearch("Tell me about Leonardo Da Vinci")
print(result.response)
# Leonardo da Vinci
Leonardo da Vinci, born in 1452 in the town of Vinci near Florence, is widely celebrated as one of the most versatile geniuses of the Italian Renaissance. His full name was Leonardo di Ser Piero d'Antonio di Ser Piero di Ser Guido da Vinci, and he was the natural and first-born son of Ser Piero, a country notary [Data: Entities (0)]. Leonardo's contributions spanned various fields, including art, science, engineering, and philosophy, earning him the title of the most Universal Genius of Christian times [Data: Entities (8)].
## Early Life and Training
Leonardo's early promise was recognized by his father, who took some of his drawings to Andrea del Verrocchio, a renowned artist and sculptor. Impressed by Leonardo's talent, Verrocchio accepted him into his workshop around 1469-1470. Here, Leonardo met other notable artists, including Botticelli and Lorenzo di Credi [Data: Sources (6, 7)]. By 1472, Leonardo was admitted into the Guild of Florentine Painters, marking the beginning of his professional career [Data: Sources (7)].
## Artistic Masterpieces
Leonardo is perhaps best known for his iconic paintings, such as the "Mona Lisa" and "The Last Supper." The "Mona Lisa," renowned for its subtle expression and detailed background, is housed in the Louvre and remains one of the most famous artworks in the world [Data: Relationships (0, 45)]. "The Last Supper," a fresco depicting the moment Jesus announced that one of his disciples would betray him, is located in the refectory of Santa Maria delle Grazie in Milan [Data: Sources (2)]. Other significant works include "The Virgin of the Rocks" and the "Treatise on Painting," which he began around 1489-1490 [Data: Relationships (7, 12)].
## Scientific and Engineering Contributions
Leonardo's genius extended beyond art to various scientific and engineering endeavors. He made significant observations in anatomy, optics, and hydraulics, and his notebooks are filled with sketches and ideas that anticipated many modern inventions. For instance, he anticipated Copernicus' theory of the earth's movement and Lamarck's classification of animals [Data: Relationships (38, 39)]. His work on the laws of light and shade and his mastery of chiaroscuro had a profound impact on both art and science [Data: Sources (45)].
## Patronage and Professional Relationships
Leonardo's career was significantly influenced by his patrons. Ludovico Sforza, the Duke of Milan, employed Leonardo as a court painter and general artificer, commissioning various works and even gifting him a vineyard in 1499 [Data: Relationships (9, 19, 84)]. In his later years, Leonardo moved to France under the patronage of King Francis I, who provided him with a princely income and held him in high regard [Data: Relationships (114, 37)]. Leonardo spent his final years at the Manor House of Cloux near Amboise, where he was frequently visited by the King and supported by his close friend and assistant, Francesco Melzi [Data: Relationships (28, 122)].
## Legacy and Influence
Leonardo da Vinci's influence extended far beyond his lifetime. He founded a School of painting in Milan, and his techniques and teachings were carried forward by his students and followers, such as Giovanni Ambrogio da Predis and Francesco Melzi [Data: Relationships (6, 15, 28)]. His works continue to be celebrated and studied, cementing his legacy as one of the greatest masters of the Renaissance. Leonardo's ability to blend art and science has left an indelible mark on both fields, inspiring countless generations of artists and scientists [Data: Entities (148, 86); Relationships (27, 12)].
In summary, Leonardo da Vinci's unparalleled contributions to art, science, and engineering, combined with his innovative thinking and profound influence on his contemporaries and future generations, make him a towering figure in the history of human achievement. His legacy continues to inspire admiration and study, underscoring the timeless relevance of his genius.
The results from GraphRAG are specific, with cited data sources clearly marked.
Question Generation
GraphRAG can also generate questions based on historical queries, which is useful for creating recommended questions in a chatbot dialogue. This method combines structured data from the knowledge graph with unstructured data from input documents to produce candidate questions related to specific entities.
question_generator = LocalQuestionGen(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
)
question_history = [
"Tell me about Leonardo Da Vinci",
"Leonardo's early works",
]
Generate questions based on history.
candidate_questions = await question_generator.agenerate(
question_history=question_history, context_data=None, question_count=5
)
candidate_questions.response
["- What were some of Leonardo da Vinci's early works and where are they housed?",
"- How did Leonardo da Vinci's relationship with Andrea del Verrocchio influence his early works?",
'- What notable projects did Leonardo da Vinci undertake during his time in Milan?',
"- How did Leonardo da Vinci's engineering skills contribute to his projects?",
"- What was the significance of Leonardo da Vinci's relationship with Francis I of France?"]
You can remove the index root if you want to delete the index to save space.
# import shutil
#
# shutil.rmtree(index_root)
Summary
In this blog, we explored GraphRAG, an innovative method that enhances RAG technology by integrating knowledge graphs. GraphRAG is ideal for tackling complex tasks such as multi-hop reasoning and answering comprehensive questions that require linking disparate pieces of information.
When combined with the Milvus vector database, GraphRAG can navigate intricate semantic relationships within large datasets, providing more accurate and insightful results. This powerful combination makes GraphRAG an invaluable asset for various practical GenAI applications, providing a robust solution for understanding and processing complex information.
Further Resources
The GraphRAG Paper: From Local to Global: A Graph RAG Approach to Query-Focused Summarization
GraphRAG GitHub: https://github.com/microsoft/graphrag
Other RAG enhancement techniques:

Keep Reading

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.