ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
ベクトル埋め込みとベクトルデータベースの概念と、eコマースにおけるユーザーエクスペリエンスの向上におけるその役割を探る。
シリーズ全体を読む
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
Eコマースが競争の激しい業界であることは周知の事実だ。そのため、プラットフォームを差別化するためには、継続的なイノベーションが不可欠である。この目標を達成する効果的な方法のひとつが、パーソナライズされた商品レコメンデーションを導入してユーザー体験を向上させることだ。
パーソナライゼーションによってユーザー体験を向上させるためには、各ユーザーの嗜好に関する有意義な情報を取得するための高度な技術が必要となる。そこで必要となるのが、ベクトル埋め込みとベクトルデータベースの組み合わせである。
この記事では、ベクトル埋め込みとベクトルデータベースの概念を探求し、Eコマースにおけるユーザー体験を向上させる上での役割を探ります。それでは、飛び込んでみましょう!
Eコマースにおけるベクトル埋め込みの役割
過去において、パーソナライズされた商品推薦をユーザに提供するための最も一般的な方法は、ユーザのクエリと商品説明の間のキーワードマッチングまたはファジーマッチングであった。しかし、この方法には重大な欠点があり、いくつかの理由でユーザーに関連商品を提供する機会を逃してしまう:
ユーザーのクエリー用語に一致するアイテムを見つけることだけに焦点を当てる。
ユーザーはしばしば検索語のスペルを間違える。
例えば、"ハイキングに最適な靴は?"といった具合です。
ユーザーは、"車のホイール "と "車のタイヤ "のように、製品カタログで使用されている用語とは異なる用語を使用することがあります。
さらに、ユーザーはテキスト以外にも多くの非構造化コンテンツ(オーディオ、ビデオ、画像など)とやりとりしており、これらは適切な結果を提供するための貴重な情報を提供する可能性がある。
これらの課題に対処するためには、2つの重要な側面を捉える洗練された手法が必要です:
ユーザーの意図
eコマース・カタログに掲載されている各商品の背後にある意味(テキスト、画像、音声など)。
ここでベクター埋め込みが活躍します。
ベクトル埋め込みは、特定のアイテムの数値表現です。eコマースでは、ベクトル埋め込みは、商品、ユーザーのセッション履歴、クエリ、商品説明、その他何でも表すことができます。ベクトルに含まれる意味情報は豊富で、似たようなアイテムは、高次元のベクトル空間で互いに近くに配置されたベクトルによって表現される。
単純な2次元ベクトル空間の可視化](https://assets.zilliz.com/Visualization_of_simple_2_D_vector_space_5b75bb2637.png)
一般に、ベクトルには2つのタイプがあります:疎ベクトルと密ベクトルである。
密なベクトルは、テキストや画像などの非構造化データを表現するために、BERTのような深層学習モデルによって生成される。これは、ほとんどが非ゼロ値で構成され、その次元は、使用する特定の深層学習モデルに依存する。密なベクトルは入力テキストのセマンティクスを捉え、比較的コンパクトな形で多くの情報を含んでいる。私たちのデータを密なベクトルに変換する一般的な深層学習モデルには、 文変換 と OpenAIがある。
一方、スパース・ベクトルもテキストを表現することができ、ほとんどの値がゼロである高次元性を持つ。入力テキストの単語を含む要素だけが、そのベクトルの中でゼロでなくなる。BM25のようなbag-of-wordsモデルによって生成されたスパースベクトルは、通常キーワードマッチングに使用される。SPLADE](https://zilliz.com/learn/discover-splade-revolutionize-sparse-data-processing)のような機械学習モデルによって生成される最新のlearned sparse vectorsは、キーワードマッチング機能を保持しながら、文脈情報を用いてスパース表現を強化する。
eコマースでは、商品の特徴、説明、画像をベクトル埋め込みに変換し、クエリに対して意味的に類似したレコメンデーションをユーザーに提供することができる。例えば、商品の色をベクトル埋め込みに変換することで、ユーザーがターコイズやマルーンといった非標準的な色の用語を使って検索した場合でも、意味的に類似した色の商品を含むレコメンデーションを提供することができます。さらに、特定のニーズに応じて、商品の色、ブランド、価格、カテゴリーなどのカテゴリーメタデータをメタデータとして保存することもできます。このメタデータは、ベクトル検索を実行する前にフィルターとして使用することができ、検索結果の効率性と関連性を高めることができます。
アイテムをベクトル埋め込みに変換し、Milvusのようなベクトルストアに格納したら、ベクトル検索を実行することができる。ベクトル検索は、コサイン類似度、コサイン距離、内積などのメトリックスを用いて、ベクトル埋め込み間の意味的類似度を計算する。
ベクトル検索は、完全一致しないクエリに対しても関連する結果を返すことができ、「結果なし」の発生を減らすことができる。また、会話形式の検索クエリを処理し、ユーザーの意図を理解し、視覚的な発見を提供し、コンテキストベースの推奨を提供するのにも適しています。これらはすべて、よりパーソナライズされた効率的なユーザー体験に貢献します。
電子商取引におけるベクトル・データベースの役割
ベクトルがアイテムに関する豊富な情報を含んでいることがわかった今、問題は、数百、数千、数百万、あるいは数十億のベクトル埋め込みがあった場合はどうするか?それらをどのように扱うべきか?
商品カタログやeコマース・プラットフォームのユーザー数が増えるにつれて、膨大な数のベクトル埋め込みを管理・処理することはますます複雑になっていきます。そこでベクターデータベースの出番です。
ベクトル・データベースは、高次元のベクトル埋め込みデータの大規模なコレクションを効率的に保存するように設計されています。各埋め込みデータを格納する過程で、ベクトルデータベースは専用のインデックスを作成します。このインデックスにより、ベクトルデータベースは各埋め込みデータに対して、ベクトル類似度検索やデータフィルタリングなどの処理を高い効率で実行することができます。
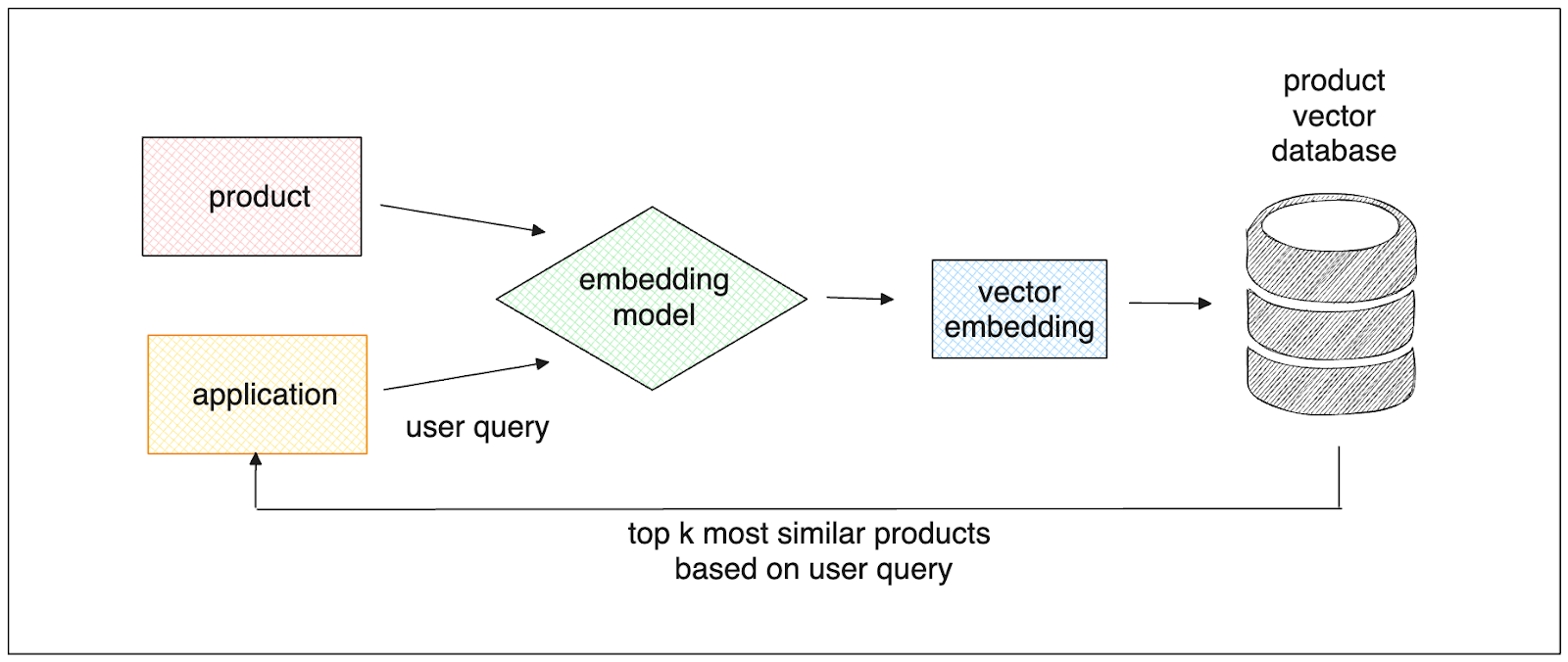 ユーザのクエリに基づく類似商品の簡単な検索処理
ユーザのクエリに基づく類似商品の簡単な検索処理
Milvusは、堅牢なベクトルデータベースの主要な例です。様々なカスタマイズされたベクトル検索操作を行うことができ、各ユーザーのパーソナライズを強化することができます。
例えば、Milvusの中に密なベクトル埋め込みコレクションがあり、それぞれが商品のテキスト説明を表しているとします。ユーザーがクエリを作成するとすぐに、Milvusはベクトル検索を実行し、そのユーザーのクエリに類似した説明を持つ製品を返します。
ユーザーにさらにパーソナライズされた具体的なレコメンデーションを提供するために、Milvusではいわゆるハイブリッド検索を実装することもできる。この検索機能により、密なベクトルと疎なベクトルに含まれる情報を同時に利用することができる。このハイブリッド検索の詳細な実装については次のセクションで説明する。
製品の構造化されたメタデータを、対応するベクトル埋め込みと一緒に保存したい場合もあるでしょう。例えば、ユーザが特定の価格帯でクエリを作成したときに、適切な商品を推薦できるように、各商品の価格を保存したい場合があります。Milvusを使えば、これらのメタデータをベクトル埋め込みと一緒に保存し、特定のクエリに従ってデータをフィルタリングすることができます。次のセクションでその実装も見てみましょう。
Eコマースユースケースのためのベクターデータベースの実装
このセクションでは、Milvusを使ってeコマースにおけるユーザのパーソナライゼーションを強化する方法を紹介します。このnotebookの全コードをご覧ください。
まず、MilvusスタンドアロンとSDKをインストールしてください。
# Milvusのインストールと起動
wget <https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh>
bash standalone_embed.sh start
# Python SDKをインストール
pip install pymilvus==2.4.0
まず、この実装で使用するデータを定義しましょう。4つの商品があり、それぞれにタイトル、説明、色があるとします。
我々は、all-MiniLM-L6-v2センテントトランスフォーマモデルの助けを借りて、商品の説明を密なベクトルに変換します。また、scikit-learnのTF-IDFを使って、商品のタイトルを疎なベクトルに変換する。
pip install sentence-transformers
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
dense_vector_model = SentenceTransformer("all-MiniLM-L6-v2")
sparse_vector_encoder = TfidfVectorizer()
product_color = ['白','緑','青','青'].
product_title = ['便座バンパー', 'サウンドコアアンカーモーションブームスピーカー', 'ネルソンウッドシム', 'モモホ多機能']] 製品名
product_desc = ['Universal Toilet Replacement Bumper for Bidet Attachment Toilet Seat Bumper', 'Portable Bluetooth Speaker with Titanium Drivers, BassUp Technology', 'DIY Bundle Wood Shims 8-Inch Shims and High Performance Natural Wood', 'IPX7 Waterproof Bluetooth Speaker, Micro SD Support TWS Pairing']] 製品名 = ['Universal Toilet Replacement Bumper for Bidet Attachment Toilet Seat Bumper', 'Portable Bluetooth Speaker with Titanium Drivers, BassUp Technology', 'IPX7 Waterproof Bluetooth Speaker, Micro SD Support TWS Pairing'
product_description_vector = dense_vector_model.encode(product_desc)
product_title_vector = sparse_vector_encoder.fit_transform(product_title)
お気づきのように、様々な形式のデータがある:密なベクトル (product_description_vector)、疎なベクトル (product_title_vector)、スカラー (color) です。次に、これらのレコードをすべてMilvusに格納したい。スキーマを定義し、データを挿入してみましょう。
from pymilvus import (
ユーティリティをインポートします、
FieldSchema, CollectionSchema, DataType、
Collection, AnnSearchRequest, RRFRanker, connections、
)
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR、
is_primary=True, auto_id=True, max_length=100)、
FieldSchema(name="product_title",dtype=DataType.VARCHAR,max_length=512)、
FieldSchema(name="product_description",dtype=DataType.VARCHAR,max_length=512)、
FieldSchema(name="color", dtype=DataType.VARCHAR, max_length=512)、
FieldSchema(name="product_title_vector", dtype=DataType.SPARSE_FLOAT_VECTOR)、
FieldSchema(name="product_description_vector",dtype=DataType.FLOAT_VECTOR,dim=384))。
]
schema = CollectionSchema(fields, "")
col = Collection("product_color_demo", schema)
sparse_index = {"index_type":"SPARSE_INVERTED_INDEX", "metric_type":"IP"}。
dense_index = {"index_type":"FLAT", "metric_type":"COSINE"}。
col.create_index("product_title_vector", sparse_index)
col.create_index("product_description_vector", dense_index)
# スキーマにデータを挿入する
entities = [product_title, product_description, product_color, product_title_vector, product_description_vector].
col.insert(entities)
col.flush()
基本的なベクトル検索
ここまでで、Milvusデータベースにデータを挿入した。次に、このデータを使って基本的なベクトル検索を行います。
例えば、ユーザーとして、音楽体験を向上させる製品を見つけたいとします。Milvusのようなベクトルデータベースは、私たちのクエリとデータベース内の各商品の説明の間のベクトル類似性検索を実行することによって、適切な商品を簡単に推薦することができます。
from pymilvus import MilvusClient
# Milvusクライアントをセットアップする
クライアント = MilvusClient(
uri="<http://localhost:19530>"
)
collection = Collection("product_color_demo")# 既存のコレクションを取得する.
collection.load()
product_query = "音楽体験を向上させるために、どの製品を買うべきか?"
product_query_vector = dense_vector_model.encode([product_query])
res = client.search(
コレクション名="product_color_demo"、
data=product_query_vector、
anns_field="product_description_vector"、
limit=2、
search_params={"metric_type":"COSINE", "params":{}},
output_fields =["product_title", "product_description", "color"])
)
print(res)
"""
# 出力:
[[{'id': '449184705451132150', 'distance':0.1673874706029892, 'entity':{'product_title':'Soundcore Anker Motion Boom Speaker', 'product_description': 'チタニウムドライバー搭載ポータブルBluetoothスピーカー、BassUpテクノロジー', 'color': 'green'}}, {'id': '449184705451132152', 'distance': '0.1478978152', 'entity': {'product_title': 'Soundcore Anker Motion Boom Speaker', 'product_description': 'チタニウムドライバー搭載ポータブルBluetoothスピーカー、BassUpテクノロジー', 'color': 'green'}}:0.14789678156375885, 'entity':{'product_title':'Momoho Multifunctional', 'product_description': 'IPX7防水Bluetoothスピーカー、マイクロSDサポートTWSペアリング', 'color': 'blue'}}]].
"""
ご覧の通り、私たちのクエリによると、上位2つの製品の推奨は、2つの異なるブランドのポータブルBluetoothスピーカーです。
スカラーフィルター付きベクトル検索
次のユースケースを考えてみよう:音楽体験を向上させるために、ある製品を買いたい。しかし、その製品は青色であってほしい。
この場合、Milvusを使えば、より具体的なレコメンデーションを得ることができる。メタデータをクエリーのフィルタリング基準として使うことができるからだ。この方法は、上記の基本的なベクトル検索とよく似ている。必要なのは、検索メソッド内でフィルタリング基準を指定することだけだ。
res = client.search(
コレクション名="product_color_demo"、
data=product_query_vector、
anns_field="product_description_vector"、
filter='color == "blue"'、
limit=1、
search_params={"metric_type":"COSINE", "params":{}},
output_fields =["product_title", "product_description", "color"])
)
print(res)
"""
# 出力:
[[{'id': '449184705451132152', 'distance':0.14789678156375885, 'entity':{'product_description': 'IPX7防水Bluetoothスピーカー、マイクロSDサポートTWSペアリング', 'color': 'blue', 'product_title':'Momoho多機能'}}]].
"""
そして、これだ。今回はいつもと違う、ブルーのポータブルBluetoothスピーカーのおすすめです。
ハイブリッド検索
ハイブリッド検索は、密なベクトルと疎なベクトルの情報を組み合わせたベクトル検索である。これは、eコマース・プラットフォームがユーザーによりパーソナライズされたレコメンデーションを提供するのに役立ちます。商品エンベッディング(密なベクトル)とタイトルエンベッディング(疎なベクトル)を使ってハイブリッド検索を実装したいシナリオを探ってみよう。
この目標を達成するために、Milvusは近似最近傍(ANN)を使用して、密なベクトルと疎なベクトルの別々のベクトル検索セッションを開始する。そして、これら2つのセッションを融合させ、融合法を用いて結果をランク付けする。一般的に使用されるフュージョン手法は相互ランクフュージョンであり、相互の位置に基づいてドキュメントをランク付けする。
次のようなユースケースを想像してほしい:私たちはスピーカーを購入したいが、そのスピーカーは特にAnkerのものであって欲しい。幸いなことに、我々のMilvusデータベースには各製品のタイトルを表す疎なベクトルがある。
そして、商品の説明を表す密なベクトルとタイトルを表す疎なベクトルを組み合わせ、ハイブリッド検索を利用してユーザーに商品を推薦することができる。以下はMilvusを使った実装方法である。
product_query = "スピーカーを買いたい"
product_title_query = "Anker"
product_query_vector = dense_vector_model.encode([product_query])
product_title_query_vector = sparse_vector_encoder.transform([product_title_query])
sparse_req = AnnSearchRequest(product_title_query_vector、
「product_title_vector", {"metric_type":"IP"}, limit=2)
dense_req = AnnSearchRequest(product_query_vector、
"product_description_vector", {"metric_type":"COSINE"}, limit=2)
res = collection.hybrid_search([sparse_req, dense_req], rerank=RRFRanker()、
limit=1, output_fields=["product_title", "product_description", "color"])
print(res)
"""
['["id:449184705451132150, distance:0.032786883413791656, entity:{ʕ'color':\\ʡ'green', 𪆡'product_title, 𪆡':\\Soundcore Anker Motion Boom Speaker:\\Portable Bluetooth Speaker with Titanium Drivers, BassUp Technology' }"]'
"""
そして、これだ。AnkerのポータブルBluetoothスピーカーは、私たちの問い合わせと好みの色と同じで、おすすめをいただきました。
ベクターデータベース成功事例
上記のすべての利点は、eコマースプラットフォームでベクターデータベースを使用する必要性を強調しています。オープンソースのベクターデータベースであるMilvusをeコマースに活用することで、以下のような成功事例があります:
VIPSHOP
中国に本社を置くオンライン小売業者であるVIPSHOPは、ビジネスの急速な拡大に伴い、スケーラブルなインフラストラクチャの構築という課題に直面していました。同社は、ベクトルを保存し、ユーザーにパーソナライズされたレコメンデーションを提供するため、より効率的で高速なソリューションを求めていました。
以前は、レコメンデーションシステムにElasticsearchを使用していましたが、数百万のコレクションから類似のベクトルを検索するのに約300ミリ秒かかっていました。しかし、Milvusに切り替えた後、VIPSHOPは大幅なパフォーマンスの向上を経験しました。
Milvusの効率的なベクトルデータの更新と呼び出し処理により、VIPSHOPは同じタスクを以前のElasticsearchの実装よりも10倍速く達成することができました。さらに、Milvusは分散デプロイと水平スケーリングをサポートしており、パフォーマンスを損なうことなくデータ量の増加に対応することができます。
トコペディア
インドネシア最大のeコマースプラットフォームであるTokopediaの例。同社はMilvusをベクトル検索最適化エンジンとして活用し、低フィルレートのユーザー検索キーワードと高フィルレートのユーザー検索キーワードをマッチングさせている。
この最適化により、Tokopediaのクリックスルー率とコンバージョン率は10倍に増加しました。セマンティック検索システムの安定性と信頼性を確保するため、TokopediaはMishardsと呼ばれるクラスターシャーディングミドルウェアなど、Milvusが提供するツールも利用している。
もっと読む Milvusの成功事例 eコマースの風景。
結論
ベクトル埋め込みは、ユーザーの意図と各商品の意味的な意味を効率的に捉える高度な手法である。ベクトル埋め込みに対してベクトル検索を行うことで、完全一致しないクエリに対しても、パーソナライズされた商品をユーザーに返すことができる。
これらの埋め込みデータの大規模なコレクションを効率的に保存するには、Milvusのようなベクトルデータベースに頼ることができる。Milvusは、基本検索、スカラーフィルタ検索、ハイブリッド検索など、いくつかのベクトル検索操作を提供する。
これらの利点を考慮すると、eコマース・ビジネスは、競争上の優位性を獲得するために、ベクトル・データベースの戦略的導入を検討する必要がある。