




最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
非構造化データソースから有用な情報をスケーラブルに抽出する方法をご紹介します。
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
人類の文明黎明期以降に作成されたデータ(https://techjury.net/blog/how-much-data-is-created-every-day/)のなんと[90%]が過去2年間に作成されたものである!ソーシャルメディアやモノのインターネット(IoT)などのデジタル技術の普及と、5Gなどの無線通信技術の高速化により、データの生成速度は増加の一途をたどっている。しかし、新たに生み出されるデータのほとんどは、テキスト、画像、音声、動画などの「非構造化」である。
非構造化データの名前の由来は、行と列からなる表とは異なり、固有の構造を持たないからである。その代わり、非構造化データには、いくつかの可能な形式の情報が含まれる。例えば、電子商取引の画像、カスタマーレビュー、ソーシャルメディアへの投稿、監視ビデオ、音声コマンドなどは、従来の表形式のデータ形式には従わない豊富な情報源である。
人工知能(AI)と機械学習(ML)技術の最近の進歩は、"埋め込み "を使用することにより、スケーラブルな方法で非構造化データソースから有用な情報を抽出する方法を生み出しました。非構造化データを埋め込みデータに変換し、Milvusのようなベクトルデータベースに保存することで、ほんの数年前には想像もできなかったような、いくつかの優れたアプリケーションが可能になった。例えば、ビジュアル画像検索、セマンティックテキスト検索、レコメンデーションエンジン、誤情報対策、創薬などである!
この投稿では、KaggleのDigikala Products Color Classificationデータセットを使って、簡単なeコマースの画像ベースの類似商品検索サービスを構築してみます。データセットのライセンスはGPL 2です。
埋め込みとは
私たちのコンピュータは、人間のように画像やテキストを直接理解することはできません。しかし、コンピュータは数字を理解することは得意です!したがって、コンピュータが画像やテキストの内容を理解するためには、それらを数値表現に変換する必要があります。例えば、画像のユースケースを考えてみると、私たちは本質的に、画像のコンテクストとシーンを、ベクトル形式の一連の数値に「エンコード」または「エンベッド」していることになります。
**埋め込み "ベクトルとは、コンピュータが画像の文脈や情景を理解できるように、画像データを数値で表現したものです。
コンピュータは画像を直接理解することはできませんが、数字を理解することはできます!](https://assets.zilliz.com/embedding_a031609fb3.svg)
いくつかのライブラリを使えば、画像から埋め込みデータを生成することができます。一般的に、これらのライブラリは2つのカテゴリに大別できます。
1.1.事前に学習されたモデルを含むAPIを提供するライブラリ:日常的なオブジェクトの画像を含む多くの実世界の問題では、おそらくモデルを学習する必要はないでしょう。その代わりに、世界中の研究者によってオープンソース化された、多くの高品質な事前学習済みモデルに頼ることができます。研究者は、ImageNetデータセットからいくつかの日常的なオブジェクトを認識し、クラスタリングするために、これらのモデルを訓練しています。 2.モデルの訓練と微調整を可能にするライブラリ: 名前が示すように、これらのモデルでは、データを持ち込んでゼロからモデルを訓練したり、私たちのユースケースのために特別に訓練済みのモデルを微調整したりすることができます。私たちがこの道を進む必要があるのは、事前に訓練されたモデルが、私たちの問題ドメインに適した埋め込みをまだ提供していない場合だけです。
この投稿では、その1のためのライブラリをいくつか見ていきましょう。しかしその前に、類似検索アプリケーションで埋め込みを定性的に評価するために、いくつかの画像データをロードしてみましょう。
データを読み込む
まず、様々な埋め込み戦略をテストするために、画像データを読み込む必要があります。今回はKaggleのDigikala Products Color Classification datasetを使ってみましょう。このデータセットには、6K以上のeコマース商品の画像が含まれており、eコマースの画像ベースの類似商品検索サービスのテストに最適だ。
ステップ1:Kaggle環境のセットアップ
1.kaggle.comでアカウントを作成する。
2.プロフィール画像をクリックし、ドロップダウンメニューから「アカウント」をクリックします。
3.API」セクションまでスクロールダウンします。
4.ユーザー名とAPIキーを含むJSONファイルをダウンロードします。
5.5.macOSまたはLinuxを使用している場合は、JSONファイルを~/.kaggle/ディレクトリにコピーします。Windowsシステムの場合、ルートディレクトリに移動し、次に.kaggleフォルダに移動し、ダウンロードしたファイルをこのフォルダにコピーする。.kaggle`ディレクトリが存在しない場合は、作成してJSONファイルをコピーしてください。
新しいKaggle APIトークンを作成する](https://assets.zilliz.com/Kaggle_screenshot_46eda43e77.png)
ステップ2:Kaggleからデータをダウンロードする
このプロジェクトの仮想環境を管理するためにAnacondaを使用する。Anacondaはそのウェブサイトからインストールできる。Anacondaをダウンロードしてインストールしたら、semantic_similarityという新しい環境をセットアップし、kaggleやpandasといった必要なライブラリをインストールし、ターミナルウィンドウで以下のコマンドを実行することでkaggle.comからデータセット全体をダウンロードすることができる。Anacondaを使いたくない場合は、pythonの venv を使ってこのプロジェクトのための仮想環境を作成し、管理することもできる。
# ノートブック用のディレクトリとデータをダウンロードするためのディレクトリを作成する。
mkdir -p semantic_similarity/notebooks semantic_similarity/data/cv
# CDをデータディレクトリに入れる
cd semantic_similarity/data/cv
# conda 環境を作成し、有効化する
conda create -n semantic_similarity python=3.8
condaを有効化する semantic_similarity
## conda を使わない場合は venv を使って仮想環境を作成する。
# python -m venv semantic_similarity
# ソース semantic_similarity/bin/activate
# Pip で必要なライブラリをインストールする
pip install jupyterlab kaggle pandas matplotlib scikit-learn tqdm ipywidgets
# kaggle APIを使ってデータをダウンロードする
kaggle datasets download -d masouduut94/digikala-color-classification
# データをfashion/ディレクトリに解凍します。
unzip digikala-color-classification.zip -d ./fashion
# Zip ファイルを削除する
rm digikala-color-classification.zip
このデータには、様々なeコマース商品の6K以上の画像が含まれている。下の画像でデータセットからいくつかのサンプル画像を見ることができる。このデータセットには、紳士服、婦人服、バッグ、ジュエリー、時計など、様々なファッション商品が含まれている。
データセットに含まれるサンプル商品。デジカラ商品色分類データセットの画像を使った著者による合成画像](https://assets.zilliz.com/1_r_If_Azpym_I_Wdtzhl_W_Cb7_E1g_ef839f0725.png)
ステップ3:各フォルダの画像を親フォルダに移動する。
semantic_similarity/notebooks`ディレクトリに新しいjupyterノートブックを作成し、様々な埋め込み戦略をテストしてみよう。まず、必要なライブラリをインポートする。
from matplotlib import pyplot as plt
np として numpy をインポートする。
import os
import pandas as pd
from PIL import Image
from random import randint
shutil をインポート
from sklearn.metrics.pairwise import cosine_similarity
インポート sys
from tqdm import tqdm
tqdm.pandas()
ダウンロードした画像はいくつかのサブフォルダにあります。それらをすべてメインの親ディレクトリに移動して、すべてのパスを簡単に取得できるようにしましょう。
def move_to_root_folder(root_path, cur_path):
# https://stackoverflow.com/questions/8428954/move-child-folder-contents-to-parent-folder-in-python からのコード
for filename in os.listdir(cur_path):
if os.path.isfile(os.path.join(cur_path, filename)):
shutil.move(os.path.join(cur_path, filename), os.path.join(root_path, filename))
elif os.path.isdir(os.path.join(cur_path, filename)):
move_to_root_folder(root_path, os.path.join(cur_path, filename))
さもなければ
sys.exit("Should never reach here.")
# 空のフォルダを削除する
if cur_path != root_path:
os.rmdir(cur_path)
move_to_root_folder(root_path='../data/cv/fashion', cur_path='../data/cv/fashion')
コードはStackOverflowから、作者によって修正された。
ステップ 4: 画像パスを pandas データフレームに読み込む
次に、すべての画像ファイルのパスのリストをpandas dataframeに読み込みましょう。
# ダウンロードしたすべての画像へのパス
img_path = '../data/cv/fashion'
# パス内の全ファイルのリストを検索
images = [
f'../data/cv/fashion/{f}'
for f in os.listdir(img_path)
if os.path.isfile(os.path.join(img_path, f))
]
# ファイル名をデータフレームに読み込む
image_df = pd.DataFrame(images, columns=['img_path'])
print(image_df.shape)
image_df.head()
データフレームの最初の5行 ](https://assets.zilliz.com/Untitled_86c6d783f2.png)
埋め込みを生成するための戦略
近年のComputer Vision技術の進歩により、画像を数値埋め込みに変換する多くの方法が開かれています。そのいくつかを見てみましょう。
1.生の画素値を平坦化する 2.分類目的で事前に訓練された畳み込みニューラルネットワーク 3.メトリック学習目的で事前に訓練された畳み込みニューラルネットワーク 4.メトリック学習目的で事前学習された画像-テキストマルチモーダルニューラルネットワーク
生のピクセル値の平坦化
カラー画像はピクセルの3次元配列からなる。1次元目は画像の高さ、2次元目は画像の幅、そして最後の3次元目はRGBと総称される色チャンネルで、下図に示すように赤、緑、青を含んでいます。各ピクセルの値は0~255の整数で、255が可能な限り高い輝度です。
したがって、RGBの値が(0,0,0)のピクセルは完全に暗い、つまり真っ黒なピクセルであり、(255,255,255)は完全に飽和した真っ白なピクセルです。画像に表示される他のすべての色は、RGBの基本的な3つの値のさまざまな組み合わせで構成されています。RapidTablesウェブサイト](https://www.rapidtables.com/web/color/RGB_Color.html)にあるRGBカラーコードチャートでは、任意の色を選んでそのRGB値を見ることができますので、ぜひお試しください!
カラー画像は、赤、緑、青の3つのチャンネルで構成されている](https://assets.zilliz.com/RGB_cf1d9ff1f3.svg)
画像は3D配列形式の数値の羅列であることを考えると、reshape演算を使って1Dベクトルに変換するのは、下の図に示すように簡単である。また、各ピクセルの値を255で割ることで、0と1の間のピクセルを正規化することもできる。これはコードの中で行う。
 平坦化は3D配列を1Dベクトルに変換する
平坦化は3D配列を1Dベクトルに変換する
def flatten_pixels(img_path):
# 画像を python に読み込む
img = Image.open(img_path).convert('RGB')
# 画像を1次元に整形し、値を正規化する
flattened_pixels = np.array(img).reshape(-1)/255.
return flattened_pixels
# データフレームに変換を適用
# 警告!1K行のデータセットに対してのみ実行、
データセット全体で実行すると, # コンピュータがクラッシュするかもしれない.
# 実行しない方が良い。エンベッディングを生成するもっと良い方法があります!
pixels_df = styles_df.sample(1_000).reset_index(drop=True).copy()
pixels_df['flattened_pixels'] = pixels_df['img_path'].progress_apply(flatten_pixels)
この方法の問題点
この方法は理解しやすく、実装も簡単ですが、画像をベクトルに「埋め込む」このアプローチにはいくつかの重大な欠点があります。
1.巨大なベクトル: Kaggleからダウンロードした画像は、[高さ×幅×チャンネル]に対応するサイズ[80×60×3]とかなり小さく、この3D配列を1Dベクトルに変換すると、サイズ14400のベクトルになります!こんな小さな画像にしては巨大なベクトルだ!データセット全体でこのベクトルを生成している間、私のコンピューターは何度もクラッシュした。結局、この方法を説明するために、より小さなサブセット(1K行)のみで実行しました。 2.空の(白い)スペースが多い疎なベクトル:ファッションデータセットの画像を視覚的に検査すると、画像の中に大きな白い部分があることに気づく。つまり、この14400要素のベクトルの多くの要素は、値255(白の場合)だけであり、画像内のオブジェクトに関連する情報を追加していない。言い換えれば、この "埋め込み "スキームは、画像のオブジェクトを効率的にエンコードするのではなく、多くの無駄なホワイトスペースを含んでいるのです。 3.局所構造の欠如: 最後に、画像を直接平坦化すると、画像の局所構造がすべて失われます。例えば、人間の顔の画像は、目、耳、鼻、口の相対的な位置によって識別されます。これらは様々な "特徴 "レベルの情報であり、一度に一列のピクセルを見ると完全に見逃してしまう。この損失の影響は、同じ人間の顔の写真であるにもかかわらず、逆さまの顔と右上がりの顔では、平坦化された埋め込みが大きく異なるということです!
我々は、畳み込みニューラルネットワークCNNとTransformerアーキテクチャに基づく新しいニューラルネットワークアーキテクチャの出現により、これらの問題をほぼ克服した。この記事の残りは、画像を埋め込みに変換するためにこれらのニューラルネットワークを使用する方法について掘り下げます。
分類の目的で事前に学習された畳み込みニューラルネットワーク
おそらく最もよく知られているコンピュータビジョンのタスクの1つは、画像を異なるカテゴリに分類することです。一般的に、このタスクでは、下の画像に示すように、画像をベクトルに変換するエンコーダとしてResNetのようなCNNモデルを使い、このベクトルを多層パーセプトロン(MLP)モデルに通して画像のカテゴリを決定します。研究者は、画像のカテゴリを正確に分類するために、Cross-Entropy lossを用いて、このCNN + MLPモデルを訓練します。
CNN.svg](https://assets.zilliz.com/CNN_2417817db9.svg)
このアプローチは、ほとんどの人間の能力を凌駕する最先端の精度を提供しています。このようなモデルを学習した後、MLP層を省き、CNNエンコーダの出力を各入力画像の埋め込みベクトルとして直接取り出すことができます。
現実には、多くの実世界の問題に対して、ゼロから独自のCNNモデルを訓練する必要はない。その代わりに、ImageNetデータセットにあるカテゴリのような、日常的なオブジェクトを認識するために既に訓練されたモデルを直接ダウンロードして利用する。Towhee`はpythonのライブラリで、これらの事前に訓練されたモデルを使って埋め込みを素早く生成します。それでは、その方法を見てみましょう。
Towhee パイプライン
Towheeは、非常に使いやすい埋め込み生成パイプラインを提供するpythonライブラリです。towheeを使えば、5行以下のコードで画像を埋め込みに変換することができます!まず、ターミナルウィンドウで pip を使って towhee をインストールしましょう。
# もしまだであれば、conda環境を有効にする。
# conda をアクティブにする semantic_similarity
pip install towhee
次に、Jupyterノートブックのセルで、ライブラリをインポートし、パイプラインオブジェクトをインスタンス化してみましょう。
from towhee import pipeline
embedding_pipeline = pipeline('image-embedding')
次に、パイプラインを使って画像を埋め込みに変換してみましょう。これはたった1行のコードです!エンベッディングパイプラインの出力には、np.squeezeを使用して取り除くことができる追加の次元がいくつかあります。
styles_df['embedding'] = styles_df['img_path'].progress_apply(lambda x: np.squeeze(embedding_pipeline(x)))
styles_df.head()
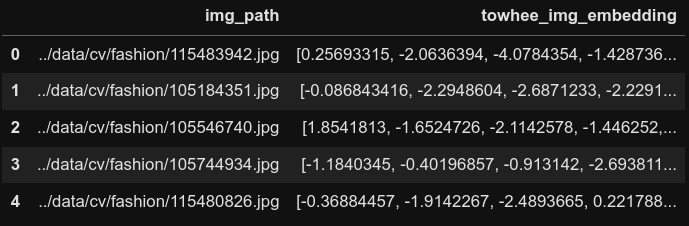 towhee埋め込み作成後のデータフレームの最初の5行
towhee埋め込み作成後のデータフレームの最初の5行
先に進む前に、埋め込み画像を含むカラム名、クエリ画像となるデータフレームのインデックス、検索する類似画像の数 k を受け取るヘルパー関数を作ってみましょう。この関数は、クエリ画像の埋め込み画像と、データフレーム内の他のすべての画像の埋め込み画像の間の余弦類似度 を計算し、上位 k 個の最も類似した画像を見つけ、表示します。
def plot_similar(df, embedding_col, query_index, k_neighbors=5):
'''データフレームのインデックスを入力クエリとして受け取り、k個の最近傍を表示するヘルパー関数
'''
# クエリと全行間のコサイン類似度を計算する
similarities = cosine_similarity([df[embedding_col][query_index]], df[embedding_col].values.tolist())[0].
# 近傍インデックスを求める
k = k_neighbors+1
nearest_indices = np.argpartition(similarities, -k)[-k:] # 最近傍インデックスを求める。
nearest_indices = nearest_indices[nearest_indices != query_index] # 最近傍インデックスを見つける。
# 入力画像のプロット
img = Image.open(df['img_path'][query_index]).convert('RGB')
plt.imshow(img)
plt.title('Query Product')
# 最近傍画像をプロット
fig = plt.figure(figsize=(20,4))
plt.suptitle('類似商品')
for idx, neighbor in enumerate(nearest_indices):
plt.subplot(1, len(nearest_indices), idx+1)
img = Image.open(df['img_path'][neighbor]).convert('RGB')
plt.imshow(img)
plt.title(f'コサインシム:{similarities[neighbor]:.3f}')
plt.tight_layout()
次に、データフレームからランダムな画像をクエリし、上記のヘルパー関数を使用して k 最も類似した画像を表示することで、towheeの埋め込みの品質をテストすることができます。下図に示すように、towheeの埋め込みは、ドレス、時計、バッグ、化粧品など様々な商品を含む画像セット全体から類似画像を見つけるために実行した全てのクエリにおいて、かなり的確です!わずか3行のコードでこれらの埋め込みを生成したことを考えると、さらに印象的です!
plot_similar(df=styles_df、
embedding_col='embedding'、
query_index=randint(0, len(styles_df)), # ランダムな画像を問い合わせる
k_neighbors=5)
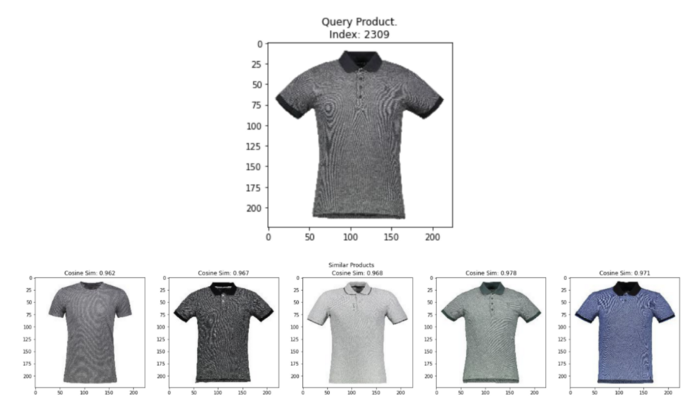 ランダムなクエリ画像と、towhee embeddingsから最も類似した上位5つの画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
ランダムなクエリ画像と、towhee embeddingsから最も類似した上位5つの画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
この結果から、towheeは類似検索アプリケーションのための埋め込みを素早く生成するための素晴らしい出発点であると結論づけることができます。しかし、我々は、類似画像が互いに同一の埋め込みを持つことを保証するために、これらのモデルを明示的に訓練していません。したがって、類似検索の文脈では、このようなモデルからの埋め込みは、すべてのユースケースで最も正確とは限りません。今、皆さんが抱いている自然な疑問は、"類似した画像が、互いに類似した埋め込みを持つように、モデルを訓練する方法はあるのだろうか?" ありがたいことに、あります!
メトリック学習目的で事前学習された畳み込みニューラルネットワーク
メトリック学習](https://paperswithcode.com/task/metric-learning?page=6)は、埋め込みを生成する最も有望な方法の1つで、特に類似検索アプリケーションのためのものです。その最も基本的なレベルでは、メトリック学習では
1.CNNやTransformerのようなニューラルネットワークを使って、画像を埋め込みに変換する。 2.2.意味的に類似した画像同士は近くに集まり、非類似の画像同士は離れるように埋め込みを構築する。
ベクトル空間における手書き画像の例。画像ソース:Brian WilliamsによるMedium Blog Post。 ](https://assets.zilliz.com/metric_learning_a727d76d18.png)
計量学習モデルのトレーニングには、データの処理方法やモデルの学習方法に工夫が必要だ。
1.データ: メトリック学習では、"アンカー "画像と呼ばれる各ソース画像に対して、"ポジティブ "と呼ばれる少なくとも1つの類似画像が必要である。また、埋め込み表現を向上させるために、"ネガティブ "と呼ばれる非類似の第3の画像を組み込むこともできる。最近の計量学習のアプローチでは、各ソース画像に対して、下の画像に示すように、様々なデータ補強を用いて "アンカー "画像と "ポジ "画像を合成的に生成します。どちらの画像も同じソース画像のバリエーションであるため、アンカーとポジのペアとしてラベル付けすることは論理的である。一方、同じ画像バッチの中から「アンカー」以外のすべての画像を取り出して、「ネガ」を合成的に生成する。
2.モデル: メトリック学習モデルの多くはシャムネットワークアーキテクチャを採用している。アンカー画像、正画像、負画像は順次同じモデルに通され、埋め込みが生成される。このような損失関数の1つはcontrastive lossと呼ばれるもので、モデルの目的は、アンカー画像と正画像の埋め込みを近づけ、両者の距離を0に近づけることです。逆に、モデルの目的は、アンカー画像とネガティブ画像の埋め込みを、それらの間の距離が大きくなるように、互いに遠ざけることです。
アンカーとポジは同じソース画像の拡張バージョンである。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.Google AI Blogにインスパイアされた](https://assets.zilliz.com/Diagram_drawio_c49a84bbc8.svg)
このアプローチでモデルを学習した後、コサイン距離などの尺度を用いて埋め込みベクトル間の距離を数学的に計算することで、任意の2つの画像間の類似性を見つけることができます。下の画像に示すように、いくつかの距離尺度が存在しますが、コサイン距離は埋め込みベクトルの比較によく使われます。
SimCLRは、対照学習と呼ばれる計量学習の一種を用いて画像埋め込みを生成する、一般的なアプローチの一つです。それでは、SimCLRと、我々のデータセット上でSimCLR埋め込みを生成する方法を見てみましょう。
SimCLR: 単純な対照学習
SimCLRとは、Simple framework for Contrastive Learning of Visual Representationsの略です。対比学習では、対比損失関数は2つの埋め込みが似ているか(0)、似ていないか(1)を比較します。
SimCLRの優れた点は、シンプルな自己教師ありアルゴリズム(画像クラスにラベルを必要としない)でありながら、下図に示すように、いくつかの教師ありアプローチと同等の性能を達成することです!
自己教師ありSimCLR 4Xは、完全教師ありResNet50と同等の精度を達成!画像ソースSimCLR論文](https://assets.zilliz.com/simclr_accuracy_cf91a9ed68.png)
画像データの補強例。 画像ソース:SimCLR論文](https://assets.zilliz.com/data_augmentation_815ba18fa1.png)
SimCLRの基本的な考え方は以下の通りである。
1.画像が与えられたら、同じ画像の2つの拡張バージョンを作成する。これらの補強は、トリミングやリサイズ、色の歪み、回転、ノイズの追加などである。下の画像はオーグメントの例を示しています。
2.バッチ内のすべての画像の補強バージョンは、画像を埋め込みに変換するCNNエンコーダを通過します。これらのCNNエンベッディングは、その後、1つの隠れ層を持つ単純な多層パーセプトロン(MLP)を通過し、別の空間に変換されます。
3.最後に、MLPの出力における埋め込みは、余弦距離を用いて互いに比較される。このモデルは、同じ画像からの埋め込みはコサイン距離が0になり、異なる画像からの埋め込みは距離が1になることを期待します。そして、損失関数は、埋め込みが期待値に近づくように、CNNとMLPの両方のパラメータを更新します。
4.学習が完了すると、MLPは不要となり、CNNエンコーダの出力を直接埋込み量として使用します。
下の画像は、全体のプロセスを概念的に説明しています。詳しくは、こちらのGoogle blog postをご覧ください。
SimCLRの概念的な説明。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.Google AI Blogにインスパイアされた](https://assets.zilliz.com/Diagram_drawio_1_66ef378795.svg)
著者らはいくつかの実験を行い、以下に示すように、ランダムなトリミングと色の歪みが最適な補強の組み合わせであると判断しました。
データ補強の異なるセットによるダウンストリームモデルの精度。画像ソース:SimCLR論文](https://assets.zilliz.com/downstream_accuracy_49b44e6b04.png)
Towheeのように、我々はSimCLRの埋め込みを抽出するために、他の研究者によってImageNet上で事前に訓練されたモデルを直接使用しています。ただし、この記事を書いている時点では、SimCLRの事前学習済み埋め込みを得るためには、Pytorch Lightning Bolts ライブラリを使って数行のコードを書く必要があります。以下は公式のLightning Bolts documentationを参考にしました。まず、ターミナルウィンドウで pip を使って必要なライブラリをインストールする。
# まだの場合は conda 環境を有効にする。
# conda activate semantic_similarity
pip install lightning-bolts wandb gym opencv-python
次に、Jupyterノートブックのセルで、必要なライブラリをインポートし、コンピュータにGPUがあるかどうかに応じてデバイスをcudaまたはcpuに設定しよう。
from pl_bolts.models.self_supervised import SimCLR
インポートトーチ
from torch.utils.data import Dataset, DataLoader
from torchvision import io, transforms
# GPUがあれば使う
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
次に、ImageNetで事前にトレーニングされたSimCLRモデルをロードし、モデルからエンベッディングを取得したいだけなので、evalモードに設定します。
# imagenet上でSimCLRを使って事前に訓練されたresnet50をロードする。
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/simclr/bolts_simclr_imagenet/simclr_imagenet.ckpt'
simclr = SimCLR.load_from_checkpoint(weight_path, strict=False, batch_size=32)
# SimCLRエンコーダをデバイスに送信し、evalに設定します。
simclr_resnet50 = simclr.encoder.to(device)
simclr_resnet50.eval();
次の2つのステップはPytorch特有のもので、モデルを実装するために使用されるライブラリです。まず、データフレームを入力とするデータセットを作成し、img_path列から画像を読み込み、いくつかの変換を施し、最後にモデルに入力できる画像のバッチを作成します。
# Pytorch 用のデータセットを作成する
class FashionImageDataset(Dataset):
def __init__(self, styles_df, transform=None):
self.styles_df = styles_df
self.transform = transform
def __len__(self):
return len(self.styles_df)
def __getitem__(self, idx):
# 画像を読み込む
img_path = self.styles_df.loc[idx, 'img_path'] # 画像を読み込む。
image = io.read_image(img_path, mode=io.image.ImageReadMode.RGB)/255.
# 変換を適用する
if self.transform:
image = self.transform(image)
画像を返す
# 変換
## 画像がImageNetと同様の強度分布を持つように変換を正規化する
バッチ内のすべての画像が同じサイズであることを保証するために ## 変換のサイズを変更する
transformations = transforms.Compose([)
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))、
transforms.Resize(size=(64, 64))
])
# 画像を一括で読み込むDataLoaderを作成します。
emb_dataset = FashionImageDataset(styles_df=styles_df, transform=transformations)
emb_dataloader = DataLoader(emb_dataset, batch_size=32)
最後に、dataloader内のバッチを繰り返し処理し、すべての画像の埋め込みデータを生成して、dataframeのカラムとして格納します。
# 埋め込みデータを生成する
embeddings = [].
for batch in tqdm(emb_dataloader):
batch = batch.to(デバイス)
embeddings += simclr_resnet50(batch)[0].tolist()
# 埋め込みをデータフレームの列に割り当てる
styles_df['simclr_embeddings'] = embeddings
styles_df.head(2)
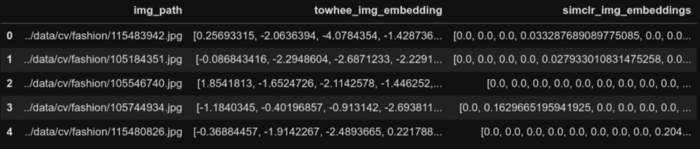 SimCLR埋め込み生成後のデータフレームの最初の5行
SimCLR埋め込み生成後のデータフレームの最初の5行
ここからが楽しいところです!同じヘルパー関数を使って、SimCLRエンベッディングの品質をテストすることができます。データフレームからランダムな画像をクエリし、k最も類似した画像を表示します。下図に示すように、SimCLRエンベッディングは全てのクエリで類似画像を見つけることができます!
plot_similar(df=image_df、
embedding_col='simclr_img_embeddings'、
query_index=randint(0, len(image_df))、
k_neighbors=5)
 ランダムなクエリ画像と、SimCLRの埋め込み画像から最も類似した上位5つの画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
ランダムなクエリ画像と、SimCLRの埋め込み画像から最も類似した上位5つの画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
画像-テキストマルチモーダルニューラルネットワークは、メトリック学習目的で事前学習される
最後に、画像とテキストの両方を統一された埋め込み空間に埋め込むモデルOpen AI's CLIP Paper、Google's ALIGN Paper、Microsoft's PixelBERT Paperの改良は目覚ましく、画像-テキスト、テキスト-画像の類似検索など、いくつかの優れたアプリケーションを開拓している。現在、このパラダイムで最も人気のあるモデルの一つは、CLIP (Contrastive Language-Image Pre-Training) です。
CLIPは、メトリック学習の枠組みをベースにしたニューラルネットワークである。CLIPは、純粋に画像のアンカーとポジのペアで学習する代わりに、画像をアンカーとして使い、対応するテキストの説明をポジとして使って画像とテキストのペアを構築する。CLIPは、Text-to-Image、Image-to-Text、Image-to-Image、Text-to-Textの類似検索など、いくつかのアプリケーションで利用できる。
画像はResNetまたはViTエンコーダに渡され、画像埋め込みが生成される。テキスト記述はGPTベースのエンコーダに通され、テキスト埋め込みが生成される。CLIPは、画像とテキストのペアのバッチの中で、番目の画像の埋め込みが、番目のテキストの埋め込みと、下図に示すように、最も高いドット積を持つように、画像とテキストのエンコーダの両方を共同で学習する。
CLIPのコントラスト事前学習 画像出典:CLIP論文](https://assets.zilliz.com/Untitled_4_3b7481d9f6.png)
学習が完了したら、下図のように、両者をそれぞれの埋め込みに変換し、ドット積や余弦距離を使って比較するだけで、クエリ画像に最も似ているテキストの行を見つけることができる。逆に、クエリテキストから最も類似した画像を検索することもできます。では、これを例題にどのように実装するか見てみましょう。
CLIP 2.png](https://assets.zilliz.com/CLIP_2_5109fa4ed6.png)
文の変形 (CLIP)
優れたSentence-Transformers libraryを使えば、CLIPエンベッディングを生成するのは簡単です。しかし、一度に開くことができるファイル数にOSの制限があるため、何万もの画像を扱う場合には、数行の定型的なコードを書く必要があります。まず、ターミナルウィンドウで pip を使って必要なライブラリをインストールする。
# まだインストールしていない場合は、conda環境を有効にする。
# conda activate semantic_similarity
pip install sentence_transformers spacy ftfy
次に、Jupyterノートブックのセルで、ライブラリをインポートし、CLIPモデルをインスタンス化してみよう。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('clip-ViT-B-32')
次に、一度に開くことができるファイル数に対するOSの制限を回避するために、一度に10K枚の画像を繰り返し処理する必要があります。各反復の間にすべての画像を読み込み、CLIPエンベッディングを生成します。
# エンベッディングを収集するために空のリストを初期化する
clip_embeddings = [] # 埋め込みを収集するために空のリストを初期化する。
# 各繰り返しで10_000枚の埋め込み画像を生成する
ステップ = 10_000
for idx in range(0, len(styles_df), step):
# step` 個の画像を読み込む
images = [
Image.open(img_path).convert('RGB')
for img_path in styles_df['img_path'].iloc[idx:idx+step].
]
# 読み込んだ画像に対してCLIPエンベッディングを生成する
clip_embeddings.extend(model.encode(images, show_progress_bar=True).tolist())
# 埋め込みをデータフレームに割り当てる
styles_df['clip_image_embedding'] = clip_embeddings
styles_df.head()
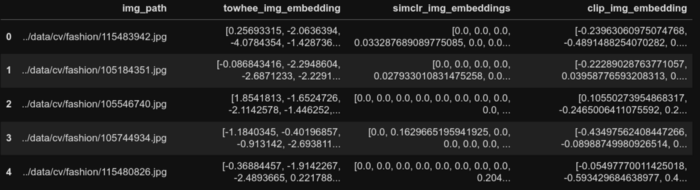 CLIP画像埋め込み生成後のデータフレームの最初の5行
CLIP画像埋め込み生成後のデータフレームの最初の5行
すべての画像に対するCLIP埋め込みができたので、同じヘルパー関数を使って埋め込み品質をテストすることができます。データフレームからランダムな画像を取得し、最も類似した画像kを表示します。下図に示すように、CLIPエンベッディングは全てのクエリに対して類似画像を見つけることができます!
plot_similar(df=styles_df、
embedding_col='clip_image_embedding'、
query_index=randint(0, len(styles_df))、
k_neighbors=5)
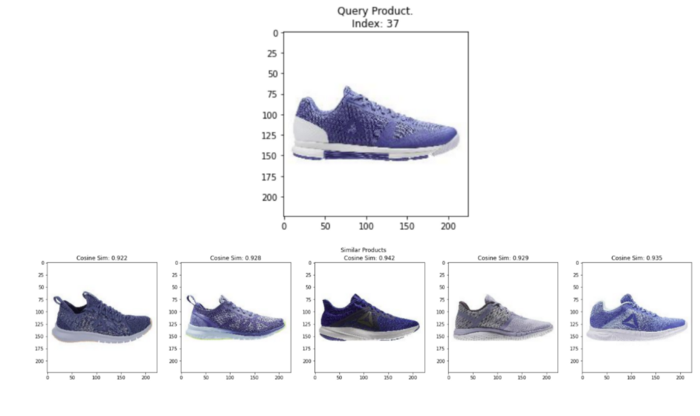 ランダムなクエリ画像とCLIP画像埋め込みから最も類似した上位5画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
ランダムなクエリ画像とCLIP画像埋め込みから最も類似した上位5画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
CLIP埋め込みを生成するために、いくつかの追加コードを書かなければならなかったが、CLIPが提供する1つの重要な利点は、Text to Image検索である。言い換えれば、与えられたテキスト記述にマッチするすべての画像を検索できる。以下、これを見てみよう。
すでに画像をCLIPエンベッディングに変換したので、あとはテキストクエリをCLIPエンベッディングに変換するだけです。そして、テキスト埋め込みとデータフレーム内のすべての画像埋め込みとの間の余弦類似度を用いて、類似商品を検索することができます。以下に示すように、これをすべてやってくれる簡単なヘルパー関数を書きます。最後に、すべての類似商品画像 k をプロットします。
def text_image_search(text_query, df, img_emb_col, k=5):
'''テキストクエリを入力とし、k個の最近傍画像を表示するヘルパー関数
'''
# テキスト埋め込みを計算する
text_emb = model.encode(text_query).tolist()
# すべての行のテキストクエリと画像のコサイン類似度を計算する
similarities = cosine_similarity([text_emb], df[img_emb_col].values.tolist())[0].
# 最近傍を見つける
nearest_indices = np.argpartition(similarities, -k)[-k:] # 最近傍を見つける。
# クエリテキストを表示
print(f'クエリテキスト: {text_query}')
# 最近傍画像をプロット
fig = plt.figure(figsize=(20,4))
plt.suptitle('Similar Products')
for idx, neighbor in enumerate(nearest_indices):
plt.subplot(1, len(nearest_indices), idx+1)
img = Image.open(df['img_path'][neighbor]).convert('RGB')
plt.imshow(img)
plt.title(f'{df["productDisplayName"][neighbor]}nCosine Sim: {similarities[neighbor]:.3f}')
plt.tight_layout()
コンピュータビジョンにおける意味的類似度探索
さて、ヘルパー関数を使ってサンプルテキストクエリをテストしてみましょう。下の画像に示すように、テストクエリが "a photo of a women's dress"(女性用ドレスの写真)である場合、最も類似している商品はすべて女性用ドレスである!各商品のタイトルに "dress "という単語が明示されていなくても、CLIPモデルはテキストと画像の埋め込みから、これらの画像が "women's dress "というクエリに最も関連していると推測することができました。他のクエリでも試してみてください!
text_query = "女性のドレスの写真"
text_image_search(text_query、
df=styles_df、
img_emb_col='clip_image_embedding'、
k=5)
 ランダムなクエリ画像と、CLIPテキスト埋め込みから最も類似した上位5つの画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
ランダムなクエリ画像と、CLIPテキスト埋め込みから最も類似した上位5つの画像。Image by Author using images from the Digikala Products Color Classification dataset with GPL 2 license.
結論
ディープラーニング研究の現状とオープンソースコードライブラリは、画像やテキストデータから高品質の埋め込みを生成する多くの簡単な方法をオープンにしています。これらの既製のエンベッディングは、多くの実世界の問題に対するプロトタイプを構築するための優れた出発点です!以下のフローチャートは、初期エンベッディングの選択に役立ちます。しかし、本番環境に導入する前に、いくつかの複雑なサンプルクエリを用いて、埋め込みモデルの精度を常に評価してください!
実運用について言えば、ここで使用したデータセットは、たった44K画像のおもちゃのデータセットです。実際のアプリケーション、例えばeコマースストアでは、何億枚もの商品画像を埋め込み、保存し、ほんの数秒のうちに最近傍検索を実行しなければなりません!このような規模の問題を解決するには、Milvusのような強力なベクトル検索データベースを使用する必要があります!ベクターデータベースについては、こちらのリンクをご覧ください。
エンベッディングとベクトル類似性データベースの様々なクールなアプリケーションに関するより多くのインスピレーションについては、私たちの"learn "チャンネルをご覧ください!
埋め込みアプローチの選択著者による画像 ](https://assets.zilliz.com/1_eew_WI_Cs_IKJ_Ma_H6jlg9b0v_A_5305379567.png)



