




HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
グラフに基づく類似性検索のための新しいHM-ANNアルゴリズムについての紹介。
シリーズ全体を読む
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogenous Memoryは、2020 Conference on Neural Information Processing Systems (NeurIPS 2020)に採択された研究論文である。本論文では、HM-ANNと呼ばれる、グラフに基づく類似性探索のための新しいアルゴリズムを提案する。このアルゴリズムは、最新のハードウェア環境におけるメモリの不均一性とデータの不均一性の両方を考慮する。HM-ANNは圧縮技術を用いずに、1台のマシンで10億スケールの類似性検索を可能にする。ヘテロジニアスメモリ(HM)は、高速だが小さいダイナミックランダムアクセスメモリ(DRAM)と、低速だが大きいパーシステントメモリ(PMem)の組み合わせを表す。HM-ANNは、特にデータセットがDRAMに収まらない場合に、低い探索レイテンシと高い探索精度を達成する。このアルゴリズムは、最新の近似最近傍(ANN)探索ソリューションに対して明確な優位性を持つ。
動機
ANN検索アルゴリズムは、その登場以来、DRAMの容量が限られているため、クエリの精度とクエリのレイテンシとの間に基本的なトレードオフが存在する。高速なクエリアクセスのためにインデックスをDRAMに保存するためには、データポイント数を制限するか、圧縮されたベクトルを保存する必要があります。グラフベースのインデックス(HNSW:Hierarchical Navigable Small World)は、クエリ実行時の性能とクエリ精度に優れている。しかし、これらのインデックスは、10億スケールのデータセットで動作する場合、1TiBレベルのDRAMを消費することもある。
億スケールのデータセットを生フォーマットでDRAMに保存させないための回避策は他にもある。データセットが大きすぎて1台のマシンのメモリに収まらない場合、データセットのポイントの積量子化などの圧縮アプローチが使われる。しかし、量子化の際に精度が落ちるため、圧縮されたデータセットを用いたインデックスの再現性は通常低い。Subramanyaらは、ソリッドステートドライブ(SSD)を活用して、単一マシンで10億スケールのANN検索を実現することを模索している。このアプローチはDisk-ANNと呼ばれ、生のデータセットをSSDに、圧縮された表現をDRAMに保存する。
ヘテロジニアスメモリ入門
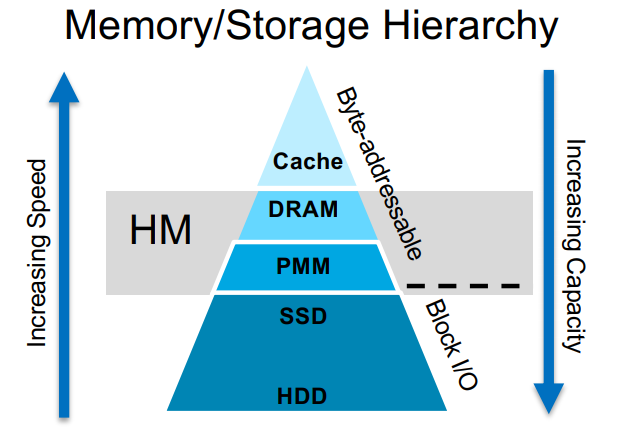 HMによるメモリ/ストレージ階層
HMによるメモリ/ストレージ階層
ヘテロジニアスメモリ(HM)は、高速だが小さいDRAMと、低速だが大きいPMemの組み合わせを表します。DRAMは、最新のサーバーには必ず搭載されている通常のハードウェアであり、そのアクセスは比較的高速です。Intel® Optane™ DC Persistent Memory Modulesのような新しいPMemテクノロジーは、NANDベースのフラッシュ(SSD)とDRAMの間のギャップを埋め、I/Oボトルネックを解消します。PMemはSSDのように耐久性があり、メモリのようにCPUから直接アドレス指定が可能です。Renenらは、設定された実験環境において、PMemの読み取り帯域幅がDRAMより2.6倍、書き込み帯域幅が7.5倍低いことを発見した。
HM-ANN設計
HM-ANNは正確で高速な10億スケールのANN探索アルゴリズムであり、圧縮なしでシングルマシン上で動作する。HM-ANNの設計はHNSWのアイデアを一般化したもので、その階層構造はHMに自然に適合する。HNSWは複数の層から構成され、第0層のみがデータセット全体を含み、残りの各層はその直下の層の要素のサブセットを含む。
 3層のHNSWの例
3層のHNSWの例
データセットのサブセットのみを含む上位レイヤーの要素は、全体のストレージ消費量のごく一部を消費する。この観察から、これらの要素はDRAMに配置するのに適した候補となる。このように、HM-ANNにおける検索エスの大部分は上位層で起こると予想され、DRAMの高速アクセス特性を最大限に利用することができる。しかし、ほとんどの検索は下層で行われる。
最下層はデータセット全体を格納するため、PMemに配置するのに適している。 第0層へのアクセスは低速であるため、各クエリでアクセスされるのはごく一部とし、アクセス頻度を下げることが望ましい。
グラフ構築アルゴリズム
HM-ANNのグラフ構築例](https://assets.zilliz.com/graph_construction_algorithm_8635d5d96b.png)
HM-ANNの構築のキーとなる考え方は、レイヤ0での検索のためのより良いナビゲーションを提供するために、高品質の上位レイヤを作成することである。したがって、ほとんどのメモリアクセスはDRAMで起こり、PMemでのメモリアクセスは減少する。これを可能にするために、HM-ANNの構築アルゴリズムは、トップダウンの挿入フェーズとボトムアップの昇格フェーズを持つ。
トップダウン挿入フェーズでは、最下層のレイヤーをPMem上に配置し、ナビゲート可能なスモールワールドグラフを構築する。
ボトムアップ昇格フェーズでは、最下位レイヤからピボットポイントを昇格させ、精度をあまり落とさずにDRAM上に配置される上位レイヤを形成する。レイヤ0からの要素の高品質な投影がレイヤ1に作成された場合、レイヤ0での検索はわずか数ホップでクエリの正確な最近傍を見つける。
HNSWのランダム選択による昇格の代わりに、HM-ANNは高次数の昇格戦略を用い、レイヤ0で最も次数の高い要素をレイヤ1に昇格させる。それ以上のレイヤでは、HM-ANNは昇格率に基づいて高次ノードを上位レイヤに昇格させる。
HM-ANNは、より多くのノードをレイヤ0からレイヤ1に昇格させ、レイヤ1の各要素の最大隣接数を大きく設定する。上位レイヤのノード数は、使用可能なDRAM容量によって決定されます。レイヤ0はDRAMに保存されないため、DRAMに保存される各レイヤをより密にすることで、探索品質が向上します。
グラフ探索アルゴリズム
HM-ANNのグラフ探索例](https://assets.zilliz.com/hm_ann_7c7e110c0f.png)
探索アルゴリズムは、高速メモリ探索とプリフェッチによるレイヤ0並列探索の2つのフェーズから構成される。
高速メモリ探索
HNSWと同様に、DRAM内の探索は最上層のエントリポイントから開始し、最上層からレイヤ2まで1-greedy探索を行う。レイヤ0での探索空間を絞り込むため、HM-ANNはefSearchL1による探索バジェットでレイヤ1での探索を行い、レイヤ1での候補リストのサイズを制限する。HNSWは1つのエントリーポイントしか使用しないが、レイヤ0とレイヤ1の間のギャップは、HM-ANNの他の2つのレイヤ間のギャップよりも特別に扱われる。
プリフェッチによるレイヤー0の並列探索
最下層では、HM-ANNはレイヤー1の探索で得られた前述の候補を均等に分割し、スレッドによる並列マルチスタート1-greedy探索を実行するためのエントリーポイントと見なす。各探索から上位の候補を集め、最良の候補を見つける。周知のように、レイヤ1からレイヤ0に降りることは、まさにPMemに行くことである。 並列探索はPMemの待ち時間を隠し、メモリ帯域幅を最大限に利用することで、探索時間を増加させることなく探索品質を向上させる。
HM-ANNは、DRAMにソフトウェアで管理されたバッファを実装し、メモリアクセスが発生する前にPMemからデータをプリフェッチする。レイヤ1を検索するとき、HM-ANNは非同期にefSearchL1の候補の近傍要素とレイヤ1の接続をPMemからバッファにコピーする。レイヤ0の検索が行われるとき、データの一部はすでにDRAMにプリフェッチされているため、PMemにアクセスするレイテンシが隠蔽され、問い合わせ時間の短縮につながる。これは、ほとんどのメモリアクセスがDRAMで行われ、PMemでのメモリアクセスが削減されるというHM-ANNの設計目標にマッチしている。
評価
論文 "HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogenous Memory "では、広範な評価が行われている。すべての実験は、Intel Xeon Gold 6252 CPU@2.3GHz を搭載したマシンで行われた。高速メモリとしてDDR4(96GB)、低速メモリとしてOptane DC PMM(1.5TB)を使用している。5つのデータセットを評価した:BIGANN、DEEP1B、SIFT1M、DEEP1M、GIST1M。億スケールのテストでは、以下のスキームが含まれる:億スケールの量子化ベースの手法(IMI+OPQとL&C)、および非圧縮ベースの手法(HNSWとNSG)。
表1】(https://assets.zilliz.com/table1_606cd16225.png)
表1では、異なるグラフベースのインデックスのインデックス作成時間とメモリ消費量を比較している。HNSWはインデックス構築において最も高速であり、HM-ANNはHNSWより8%の追加時間を必要とする。全体的なストレージ使用量に関しては、HM-ANNインデックスはHSNWよりも5~13%大きい。
図1](https://assets.zilliz.com/figure1_b664b4e043.png)
図1では、異なるインデックスのクエリー性能を分析している。図1の(a)と(b)は、HM-ANNが1ms以内に95%以上のトップ1リコールを達成していることを示している。図1の(c)と(d)は、HM-ANNが4ミリ秒以内に90%以上のトップ100リコールを達成していることを示している。HM-ANNは、他のすべてのアプローチよりも優れた遅延-想起性能を提供する。
ミリオンスケールのアルゴリズム比較
図2](https://assets.zilliz.com/figure2_3440161c0d.png)
図2では、純粋なDRAM環境において、異なるインデックスのクエリ性能を分析しています。HNSW、NSG、HM-ANNは、DRAMの容量に収まる300万スケールのデータセットで評価されています。HM-ANNは依然としてHNSWより優れた問い合わせ性能を達成している。その理由は、HM-ANNの距離計算の総数(平均850/クエリ)が、共に99%の想起目標を達成することを目指した場合、HNSWの距離計算の総数(平均900/クエリ)よりも少ないからである。
高次プロモーションの効果
図3](https://assets.zilliz.com/figure3_1df454877a.png)
図3では、ランダム昇格と高次昇格を同じ構成で比較している。高次プロモーションはベースラインを上回った。高次プロモーションは、ランダムプロモーションよりも1.8倍、4.3倍、3.9倍速く、それぞれ95%、99%、99.5%の想起目標に到達する。
メモリ管理技術のパフォーマンス
図5](https://assets.zilliz.com/figure5_e815265b74.png)
図5は、HNSWとHM-ANNの間の一連のステップを含み、HM-ANNの各最適化がその改善にどのように寄与するかを示している。BPはインデックス構築におけるボトムアップ促進、PL0は並列レイヤ0探索、DPはPMemからDRAMへのデータプリフェッチを表しています。それぞれのステップで、HM-ANNの検索性能はさらに向上している。
結論
HM-ANNと呼ばれる新しいグラフベースの索引付けと探索アルゴリズムは、グラフベースのANN探索アルゴリズムの階層的な設計とHMのメモリヘテロジニアリティをマッピングする。評価の結果、HM-ANNは10億点データセットのための新しい最先端インデックスとみなされるべきであることが示された。
学術界や民間企業において、永続記憶装置上にインデックスを構築することがますます一般的になってきている。しかし、HM-ANNの構築にはまだ数日かかり、Disk-ANNと大差はない。我々は、Pmemの特性をより注意深く利用し(例えば、Pmemの256バイトという粒度を意識する)、キャッシュラインをバイパスするためにフロー命令を使用することで、HM-ANNのインデックス作成時間を最適化できると考えている。また、今後、耐久性のある記憶装置へのアプローチがさらに提案されることが期待される。
他のリソースをお探しですか?
- 他のインデックスやアルゴリズムについてはこちらをご覧ください:
- DiskANN: A Disk-based ANNS Solution with High Recall and High QPS on Billion-scale Dataset](https://zilliz.com/blog/diskann-a-disk-based-anns-solution-with-high-recall-and-high-qps-on-billion-scale-dataset?from=from_parent_mindnote)



