




PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
Zilliz Cloud PipelineがPDFデータをLLMがセマンティック検索タスクで使用できる形式に変換する方法を学びます。最後に、ベクトル検索を使ってデータ検索を行います。
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
#はじめに
大規模言語モデル(LLM)を自然言語タスクに効果的に活用するためには、データソースを適切に扱うことが不可欠である。なぜなら、データはPDF、CSV、HTML、Markdown、Docsなど、様々なフォーマットで提供される可能性があるからだ。問題は、それらのデータをディープラーニング・モデルが期待する形式に変換するのが面倒で面倒であることだ。
さらに、RAGのようなLLMの応答精度を向上させる最先端の手法は、生テキストから検索可能なベクトルへの入力データの適切な高度データ処理ワークフローに依存している。各処理ステップには、深い専門知識と専門的なエンジニアリングが必要である。
この記事では、Zillizのクラウドパイプラインを活用してこれらの課題に対処する方法を紹介します。具体的には、私たちのパイプラインがPDFデータをLLMが意味検索タスクで使用できる形式に変換する方法を学びます。最後に、ベクトル検索を使ったデータ検索を行います。
生のデータから検索可能なベクトルへ
RAGの実装でベクトル検索を行うには、入力がベクトル埋め込みである必要がある。しかし、テキスト文書のような非構造化データを検索可能なベクトルに変換するのは簡単ではなく、いくつかのステップが必要である。
最初のステップはデータの読み込みである。PDF形式の文書であれば、複数ページにまたがり、非常に長いテキストになる可能性が高い。このような長いテキストは、ベクトル検索タスクにおいて課題となります。長いテキストの課題の一つは、テキストデータを埋め込みに変換するディープラーニングモデルのコンテキスト長の制限から生じる。例えば、BERTには512という最大トークン制限があります(簡単のため、トークンは単語に相当すると考えることができます)。テキストがこの制限を超えると、切り捨てられ、ベクトル検索結果が大幅に不正確になる可能性がある。
2つ目の問題は、ベクトル検索タスクの性質そのものに起因する。深層学習モデルによって生成される埋め込みは、テキスト全体の文脈をカプセル化する。その結果、非常に長いテキストがある場合、埋め込みは幅広い情報やトピックを表すことになり、テキストから関連するコンテキストを抽出することは実質的に不可能になる。
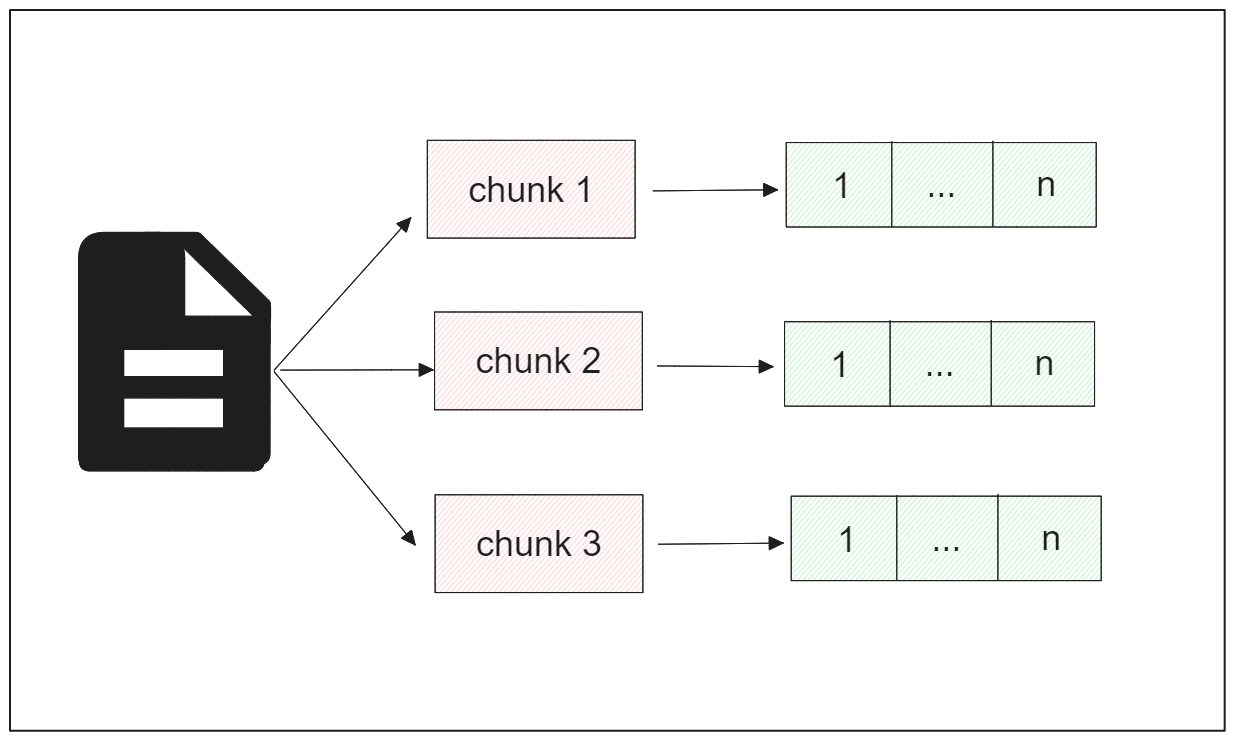
このような問題を解決するために、長い文書の処理ワークフローは通常、いわゆるチャンキング法から始まる。
PDF チャンキング
チャンキングは、長すぎるテキストを処理するという課題に対処するために使用される一般的な方法です。チャンキングとは、長いテキストをより小さなセグメントに分割することです。テキスト・チャンキングには様々なアプローチがありますが、今日は固定サイズ・チャンキングとコンテント・アウェア・チャンキングの2つに焦点を当ててみましょう。

固定サイズのチャンキングでは、テキストをあらかじめ決められた同じサイズのチャンクに分割します。そのため、各チャンクは同じサイズになります。
一方、内容を考慮したチャンキングでは、チャンクサイズは入力というよりも結果として扱われます。たとえば、空白、句読点、段落の区切り、見出し、小見出しなど、特定のマーカーに基づいてテキストをセグメ ントすることができます。あるいは、使用するモデルの要件に基づいてテキストをセグメント化することもできる。たとえば、コンテキストサイズが 512 個のトークンで BERT を使用する場合、各チャンクには 512 個を超えないトークンが含まれます。
しかし、テキストチャンキングを実行する前に、適切なチャンクサイズを決定する問題に対処しなければならない:
- チャンクサ イズが小さいと、各セグメントからより詳細な情報が得られるが、意味のあるコンテキストが失われる危険性がある。
- 逆に、チャンクサイズを大きくすると、より詳細な情報が得られますが、各セグメントに含まれるコンテンツが広くなるため、検索結果の精度が低下する可能性があります。
このように、データの性質と求める検索結果を理解することは非常に重要である。さらに、選択したモデルのコンテキストの制限も考慮しなければならない。
PDFベクトル化
テキストデータをチャンクに変換した後、次のステップではこれらのチャンクをエンベッディングに変換します。エンベッディングとは、単語、文、段落、テキストの塊などのエンティティの数値ベクトル表現です。エンベッディングには主に、密なエンベッディングと疎なエンベッディングの2種類があります。
密な埋め込みは、エンティティのコンパクトな数値表現を提供し、ベクトルの次元数は使用されるディープラーニングモデルの仕様と一致します。このタイプの埋め込みは、表現されたエンティティに関する豊富な情報を含んでいます。
一方、スパース埋込みは、密な埋込みに比べて次元が高いが、その値の大部分はゼロであるため、「スパース」と呼ばれる。
どちらのタイプの埋め込みも文書解析タスクに利用することができ、ハイブリッド検索によって組み合わせることも可能です。しかし、以下のセクションでの実装では、密な埋め込みに焦点を当てる。各チャンクを密な埋め込みに変換するために、いくつかのディープラーニングモデルを採用することができる。
ベクターデータベースの統合
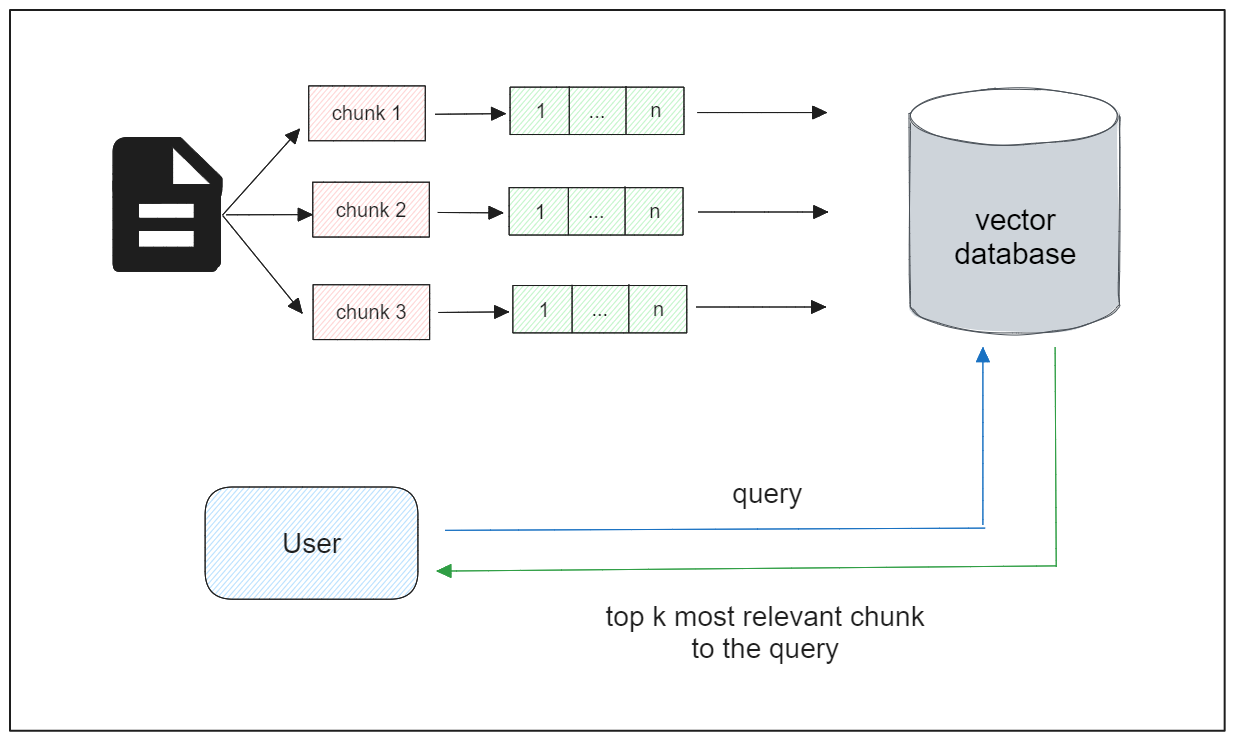
チャンクの埋め込み数が限られている状況では、意味的類似性タスクを直接進めることができる。しかし、実際のアプリケーションでは、それぞれが多くのチャンクを含む、長い文書の大規模なコレクションを含むことがよくあります。
埋め込みデータの取り扱いと保存の複雑さは、文書数が増えるにつれて増大します。さらに、データ数が増えるにつれて、ベクトル探索のレイテンシも遅くなる傾向がある。そのため、大量の埋め込みデータを効率的に管理できる強固な技術が必要であり、ベクトルデータベースの出番となります。
ベクトルデータベースは、ベクトル埋め込みデータの膨大なコレクションを効率的に格納することができ、ベクトル検索時の検索プロセスを最適化する高度なインデックス戦略を採用しています。埋め込みデータをベクトルデータベースに格納したら、ベクトル検索を行うことができる。つまり、ユーザのクエリが与えられたとき、ベクトルデータベースはそのクエリに最も関連するテキストチャンクを返すようにしたい。
Zilliz クラウドデータ取り込みパイプライン
前のセクションからわかるように、生のPDFテキストを検索可能なベクトルのコレクションに変換するプロセスには、いくつかの重要なステップがあり、それぞれに慎重な検討が必要です。
例えば、チャンキングプロセスでは、各チャンクのサイズとディープラーニングモデルの選択という2つの重要な要素に対処する必要があります。これらの要因の相性が悪いと、下流で問題が発生する可能性があり、不正確な結果となります。
同様に、ベクトル・データベースをアプリケーションに統合する際にも、いくつかの考慮事項が生じます。
例えば、チャンクID、チャンクテキスト、ドキュメントID、ドキュメントの発行年など、各チャンクのベクトル埋め込みと一緒に追加のフィールドを保存したいとします。このような場合、データの正確な表現を保証するために、各フィールドに特定のデータ型を割り当てる必要が出てきます。
さらに、ベクトル埋め込みをベクトルデータベースに格納する前に、ベクトルのインデックスタイプを定義しなければならない。各インデックス・タイプには独自のパラメータ・セットが付属しており、私たちの特定のユースケースに最適な構成を達成するために、これらのパラメータを微調整することが不可欠です。しかし、このプロセスはドメインの知識を必要とし、非常に面倒なものとなる。
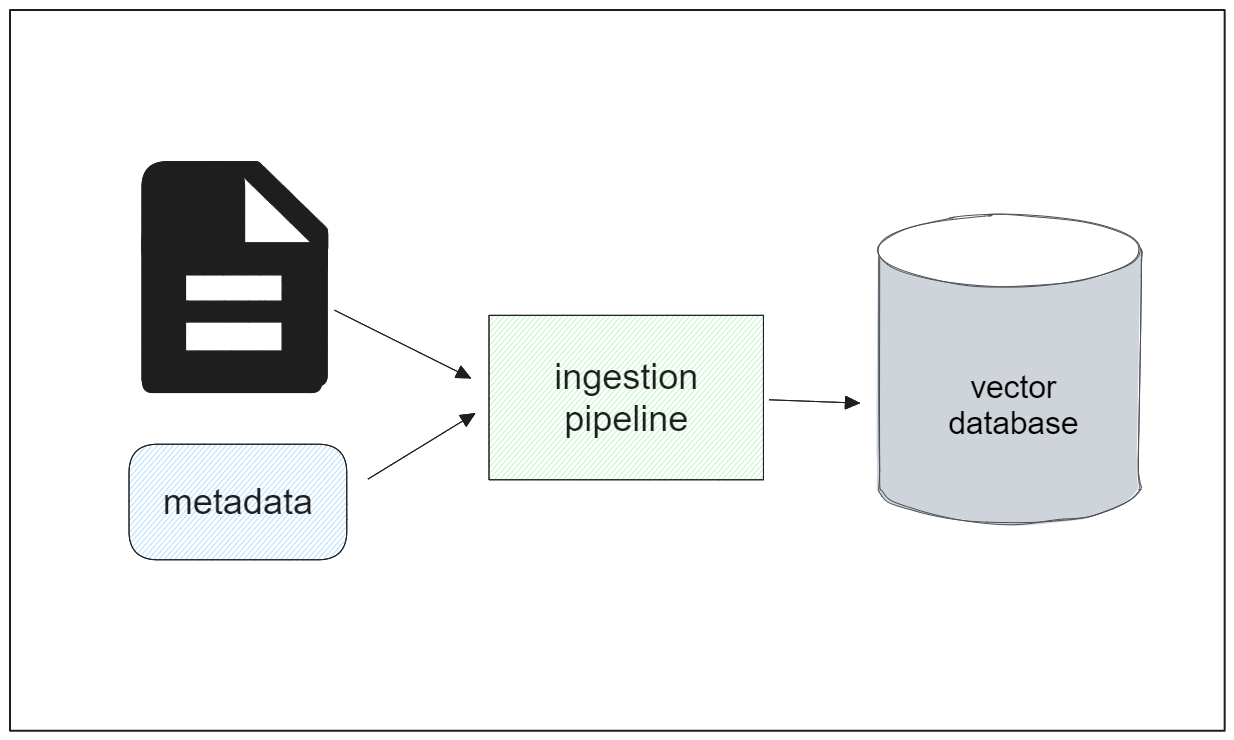
Zilliz Cloud Pipelineは、上述の課題に対する包括的なソリューションとして機能するデータ取り込みパイプラインです。このパイプラインを使用すると、ソースロケーションから生のPDFテキストを検索可能なベクトルに変換するプロセス全体を、簡単な設定でシームレスに自動化できます。
一般的に、Zilliz Cloud Pipelinesのワークフローは以下のようになります:
データが保存されるクラスタとコレクションの名前を設定する。
インジェストパイプラインを定義し、使用する埋め込みモデル、入力言語、チャンクサイズ、各テキストをチャンクするセパレータなどのパラメータを指定する。
必要であれば、メタデータとともに入力ドキュメントのパスを添付または指定する。
パイプラインは、入力文書をチャンクに分割し、各チャンクを埋め込みに変換し、指定されたコレクション内に格納する。
次のセクションで、このパイプラインのステップバイステップの実装を掘り下げます。
Zillizクラウドデータ取り込みパイプラインの実装
このセクションでは、Zilliz Cloudのパイプラインを活用し、入力されたドキュメントを検索可能なベクトルに変換する実装をステップバイステップで説明します。
このデモでは、オープンソースの政府データセットであるLibrary of Congressから入手可能なPDFファイルの1つを利用します。データセット全体を政府のウェブサイトからダウンロードすることもできますし、コードの後半に記載されている公開リンクを使用して、この実装に使用する特定のPDFファイルをダウンロードすることでフォローアップすることもできます。完全なコードの実装については、このノートブックを参照してください。
データ取り込みパイプラインの実装に進む前に、サーバーレスクラスターを作成したことを確認してください。これは簡単なプロセスで、無料だ。このcreate-cluster documentation pageに従って作成できる。
サーバーレスクラスターをセットアップしたら、クラスターID、クラウド地域、APIキー、プロジェクトIDなど、データインジェストパイプラインの作成と実行に使えるいくつかの認証情報が得られる。次に、各クレデンシャルを以下のコードにコピーすればいい:
インポート os
CLOUD_REGION = 'gcp-us-west1'
CLUSTER_ID = 'あなたのCLUSTER_ID'
API_KEY = 'あなたのAPI_KEY'
PROJECT_ID = 'あなたのPROJECT_ID'
上記で定義した認証情報を使って、データ取り込みパイプラインを定義するための適切な場所に認証情報を置くことができる。以下のコードでは、"ingestion_demo "というコレクションがクラスタ内に作成されます。
インポートリクエスト
headers= {
"Content-Type":"application/json"、
"Accept":"application/json"、
"Authorization": f "ベアラ{API_KEY}"
}
create_pipeline_url= f "https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines"
コレクション名= 'ingestion_demo'
data = {
"projectId":PROJECT_ID、
"name":「my_ingestion_pipeline"、
"description":"テキストファイルをチャンクに分割し、埋め込みを生成するパイプライン。また、各チャンクと一緒にdocのバージョンも保存する。"、
"type":「INGESTION"、
"clusterId": f"{CLUSTER_ID}"、
"newCollectionName": f"{コレクション名}".
}
それでは、新しく作成したコレクションの中に入れるデータを作成してみましょう。
Zilliz Cloud Pipelinesでは、コレクションに格納するデータの種類を functions キーで指定する。利用可能なfunctionsは2種類ある:INDEX_DOCとPRESERVEです。
INDEX_DOC関数はパイプラインの中心的な入力データである。つまり、txt, pdf, doc, docx, csv, xlsx, pptxなどの拡張子を持つドキュメントを入力として期待します。この関数はドキュメントをチャンクに分割し、エンベッディングに変換します。この関数は入力フィールド(入力文書へのパス)を4つの出力フィールド(doc_name、chunk_id、chunk_text、embedding)にマッピングします。
PRESERVE関数はデータ取り込みパイプラインのオプション関数です。PRESERVE関数は、入力文書を記述するユーザー定義のメタデータを保存します。
つのデータ取り込みパイプラインで、1つのINDEX_DOC関数と最大5つのPRESERVE関数を持つことが許されます。
次のコード・スニペットは、INDEX_DOC関数の作成方法を示しています。
data = {
....
"functions":[
{
"name":"index_my_doc"、
"action":"INDEX_DOC"、
"inputField":"doc_url"、
"language":「ENGLISH"、
"chunkSize":100,
"embedding":"zilliz/bge-base-ja-v1.5"、
"splitBy":["\nn", "\n", "", "" ]。
},
}
関数の中でカバーしなければならないフィールドがいくつかある:
name` : 関数の名前で、3~64文字の文字列を指定する。文字列には英数字とアンダースコアのみを含めることができる。
このフィールドには2つのオプションしかない:INDEX_DOCまたはPRESERVEである。
関数のタイプがINDEX_DOCの場合、
inputFieldには常にdoc_urlを設定する。一方、関数のタイプがPRESERVEであれば、追加したいメタデータに応じて名前をカスタマイズすることができる。しかし、名前はoutputFieldと同じでなければならない。language` : 入力文書の言語。
各チャンクのサイズ。使用する埋め込みモデルに応じてカスタマイズすることができる。
embedding: チャンクを埋め込みに変換する際に使用するモデル。splitBy: チャンキング処理に使用する区切り文字。
chunkSizeフィールドはembedding` フィールド内で使用したい埋め込みモデルに応じてカスタマイズする必要がある。Zillizはいくつかの最先端の埋め込みモデルをサポートしており、すぐに実装することができる。以下は、サポートされている埋め込みモデルのリストと、各モデルのチャンクサイズの範囲である。
| :---------------------------:| :---------------------------:| :--------------------------------------------------------------------------------------:| | モデル | チャンクサイズレンジ(トークン) | モデル情報 | | zilliz/bge-base-ja-v1.5 | 20-500 | https://huggingface.co/BAAI/bge-base-en-v1.5 | | zilliz/bge-base-zh-v1.5 | 20-500 | https://huggingface.co/BAAI/bge-base-zh-v1.5 | | voyageai/voyage-2 | 20-3,000 | https://docs.voyageai.com/docs/embeddings || voyageai/voyage-2 | https://docs.voyageai.com/docs/embeddings | voyageai/voyage-code-2 | 20-12,000 | https://blog.voyageai.com/2024/01/23/voyage-code-2-elevate-your-code-retrieval/ | | voyageai/voyage-large-2 | 20-12,000 | https://docs.voyageai.com/docs/embeddings | | openai/text-embedding-3-small|250-8,191|https://platform.openai.com/docs/guides/embeddings/embedding-models | openai/text-embedding-3-large|250-8,191|https://platform.openai.com/docs/guides/embeddings/embedding-models
チャンクの分割方法をカスタマイズすることもできます。再帰的分割はデフォルトで ["nn", "n", " ", ""] によって実装されています。しかし、各チャンクが文、段落、セクション全体を表すようにテキストを分割することもできます。例として、文章(".", "")、段落("nn", "")、行("n", "")、あるいはカスタマイズした文字列でテキストを分割することができます。
ここまでで、INDEX_DOC関数を定義しました。ここで、入力文書のメタデータとして出版年を含めたいとしましょう。そのためにはPRESERVE関数を実装します。
{
"name":"keep_doc_info"、
"action":"INDEX_DOC"、
"inputField":"publishing_year"、
"outputField":"publishing_year"、
"fieldType":"Int32"
}
PRESERVE関数を実装すると、入力フィールドの名前をカスタマイズすることができる。しかし、重要なことは、inputFieldとoutputFieldは同一でなければならないということである。フィールドのデータ型も定義しなければならない。データ型には Bool、Int8、Int16、Int32、Int64、Float、Double、VarChar が使用できる。今回のメタデータは出版年なので、データ型は Int16 とする。
基本的にはこれで終わりです。以下は、INDEX_DOC関数とPRESERVE関数を実装した後に、data変数の中に含めるべきものの完全なリストである。
data = {
"projectId":PROJECT_ID、
"name":"name": "my_ingestion_pipeline"、
"description":"テキストファイルをチャンクに分割し、埋め込みを生成するパイプライン。また、各チャンクと一緒にdocのバージョンも保存する。"、
"type":「INGESTION"、
"clusterId": f"{CLUSTER_ID}"、
"newCollectionName": f"{コレクション名}"、
"functions":[
{
"name":"index_my_doc"、
"action":"INDEX_DOC"、
"inputField":"doc_url"、
"language":「ENGLISH"、
"chunkSize":100,
"embedding":"zilliz/bge-base-ja-v1.5"、
"splitBy":["\nn", "\n", "", "" ]。
},
{
"name":「keep_doc_info"、
"action":"PRESERVE"、
"inputField":"publishing_year"、
"outputField":"publishing_year"、
"fieldType":"Int16"
}
]
}
次に、以下のコードでインジェスト・パイプラインを作成する。
response = requests.post(create_pipeline_url, headers=headers, json=data)
print(response.json())
ingestion_pipe_id = response.json()["data"]["pipelineId"].
"""
出力:
{'code': 200, 'data': {'pipelineId': 'pipe-7636f4340ec77ab1886816', 'name': 'my_ingestion_pipeline', 'type': 'INGESTION', 'description': 'テキストファイルをチャンクに分割し、エンベッディングを生成するパイプライン。また、各チャンクと一緒にdocのバージョンも保存します。', 'status': 'SERVING', 'functions':['action': 'INDEX_DOC', 'name': 'index_my_doc', 'inputField': 'doc_url', 'language': 'ENGLISH', 'chunkSize': 100, 'splitBy':'splitBy': ['\nn', '\n', ' ', ''], 'embedding': 'zilliz/bge-base-ja-v1.5'}, {'action': 'PRESERVE', 'name': 'keep_doc_info', 'inputField': 'publishing_year', 'outputField': 'publishing_year', 'fieldType': 'Int16'}], 'clusterId': 'in03-6e1134e6a5a7d33', 'newCollectionName': 'ingestion_demo', 'totalTokenUsage': 0}}.
"""
パイプラインの作成が成功すると、JSONレスポンスとして200のステータスコードとパイプラインIDが表示されます。これでパイプラインが作成されたので、入力データドキュメントを添付してパイプラインを実行できます。パイプラインはデータを取り込み、コレクション内で検索可能なベクトルに変換します。
一つはAWS S3やGoogle Cloud Storage (GCS)のようなクラウドストレージシステム経由、もう一つはローカルコンピュータ経由です。次の例では、パブリックなGCSリンクからPDFファイルを取得します。
input_doc_path= 'https://storage.googleapis.com/ingestion_demo_zilliz/pdf_data.pdf'
run_pipeline_url = f "https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines/{ingestion_pipe_id}/run"
data = {
"data":
{
"doc_url": f"{input_doc_path}",
"publishing_year":'2000'
}
}
response = requests.post(run_pipeline_url, headers=headers, json=data)
print(response.json())
"""
出力:
{code': 200, 'data': {'token_usage': 1510, 'doc_name': 'pdf_data.pdf', 'num_chunks': 19}} 出力されます。
"""
上で見たように、dataフィールドの内部には、以前にINDEX_DOCとPRESERVE関数の両方で作成したinputFieldに関する情報も提供する必要があります。実行が成功すれば、doc_name や num_chunks といった情報が表示される。
コレクションの中身を見てみると、6つのフィールドがあることがわかる:id、doc_name、chunk_id、chunk_text、embedding、publishing_yearである。doc_name、chunk_id、chunk_text、embeddingはINDEX_DOC関数によって自動的に生成されるフィールドである。
それでは、コレクションに取り込まれたデータを使用してベクトル検索を実行してみましょう。ZillizとMilvusでベクトル検索を実行する方法はいくつかあるが、パイプラインの話をしているので、ベクトル検索に特化したパイプラインを作成しよう。
data = {
"projectId":PROJECT_ID、
"name":"search_pipeline"、
"description":"テキストを受け取り、意味的に類似したdocチャンクを検索するパイプライン"、
"type":"search"、
"functions":[
{
"name":"search_chunk_text"、
"action":"search_doc_chunk"、
"inputField":"query_text"、
"clusterId": f"{CLUSTER_ID}"、
"collectionName": f"{コレクション名}"
}
]
}
response = requests.post(create_pipeline_url, headers=headers, json=data)
print(response.json())
search_pipe_id = response.json()["データ"]["パイプラインID"].
"""
出力:
{code': 200, 'data': {'pipelineId': 'pipe-ea047e284b82d13a7e1238', 'name': 'search_pipeline', 'type': 'SEARCH', 'description': 'テキストを受け取り、意味的に類似したdocチャンクを検索するパイプライン', 'status': 'SERVING', 'functions':[{'action': 'SEARCH_DOC_CHUNK', 'name': 'search_chunk_text', 'inputField': 'query_text', 'clusterId': 'in03-6e1134e6a5a7d33', 'collectionName': 'ingestion_demo', 'embedding': 'zilliz/bge-base-en-v1.5'}], 'totalTokenUsage': 0}}.
"""
上記のコード構造は、インジェストパイプラインと同じような構造なので、もうお馴染みのはずだ。typeをINGESTではなくSEARCHに設定し、query_textという名前をinputField`に設定している。最後に、データを取得するクラスタIDとコレクション名を指定する。上記の検索パイプラインの作成が成功すると、一意のパイプライン ID が取得できる。
クエリがあれば、検索パイプラインを実行して、指定されたクエリに最も関連するチャンクをコレクションから取得できます。例として、次のような質問があるとします:「放送技術者の給料はいくらですか?_" という質問があったとします:
インポート pprint
def retrieval_with_pipeline(question, search_pipe_id, top_k=1, verbose=False):
run_pipeline_url = f "https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines/{search_pipe_id}/run"
data = {
"data":{
"query_text": question
},
「params":{
"limit": top_k、
"オフセット":0,
"outputFields":[
"chunk_text"、
],
}
}
response = requests.post(run_pipeline_url, headers=headers, json=data)
if verbose:
pprint.pprint(response.json())
results = response.json()["データ"]["結果"].
retrieved_texts = [{'chunk_text': result['chunk_text']} for result in results].
return retrieved_texts
query = '放送技術者の給料はいくらですか?
result = retrieval_with_pipeline(query, search_pipe_id, top_k=1, verbose=True)
print(result)
"""
出力:
{'code': 200、
'data': {'result':['chunk_text': '放送技術者、3ページ中3ページ目'
'Audiovisual Communications '
'Technologies/Technicians, Other. - 任意の'
'instructional program in audiovisualn'
'communications technologies not listed'
above.
Wages
In NY the average wage for this
職業は
初級で$33,030、経験者で$65,350だった。
経験者は$65,350だった。
職業展望
年間総求人数とその伸び率から
'年間求人総数とその伸び率から、'
'employment prospects for this occupation'、
distance':0.7437874674797058,
'id':448985674931815193}],
'token_usage': 18}}.
"""
これで完了だ。見ての通り、レスポンスはクエリーにマッチしている。例えば、異なるクエリーを尋ねたり、コレクションにドキュメントを追加したり、チャンキング処理中のチャンクサイズ戦略を試してみたりして、自分で試してみることができます。
結論
入力文書をLLMで使える形式に変換するには、いくつかのステップが必要である。まず、入力文書を一定の大きさのチャンクに分割する必要がある。次に、各チャンクをディープラーニングモデルを使って埋め込みに変換する。最後に、埋め込みをベクトルデータベースに入れ、効率的な保存と検索を行う。
この投稿では、Zilliz Cloud Pipelinesが、生のドキュメントをデータベース内で検索可能なベクトルに変換するプロセスをいかに簡素化するかを見てきた。これらのベクトルを意味的類似性タスクに使用することで、RAGメソッドによるLLMの応答精度を向上させることができる。



