




推薦システムとベクターデータベース技術の利用について知っておくべきすべて
ベクトル検索でAIを活用した推薦システムを構築する方法
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
推薦システム入門
レコメンデーション・システム(別名RecSys)は、ユーザーに関連する情報を提案するように設計されたシステムである。人工知能と機械学習を搭載したこれらのシステムは、ユーザーの行動を研究し、ユーザーが好むかもしれない結果を提案する。
伝統的に、開発者は、従来のデータベース管理システムと、データを処理し分析するための計算技術を使用して、これらの推薦システムを構築した。これらのシステムは、フルテキストフィルタリングやコンテンツベースフィルタリングに基づいて設計されていた。これらの方法はある程度有効であったが、スケーラビリティと正確性という課題に直面していた。この技術における最新の進歩は、ベクトル・データベースの導入であり、これによりデータ処理と分析の効率が向上し、より適切でパーソナライズされたレコメンデーションが実現される。
推薦システムを理解する
進化するテクノロジーの世界において、レコメンデーションシステムの重要性は増しており、商品、音楽、映画、仕事、ソーシャルメディアコンテンツなどを発見する方法に影響を与えている。例えば、eコマース業界では、レコメンデーションシステムはユーザーの行動やアクティビティを調査し、ユーザーが興味を持ちそうな商品を提案するために使われている。同様に、音楽業界では、Spotifyのようなプラットフォームがレコメンデーションシステムを使って、あなたが興味を持ちそうな音楽を提案している。ネットフリックスはレコメンデーションシステムを活用し、ユーザーの行動や振る舞いを研究して、あなたが好きそうな映画を提案している。
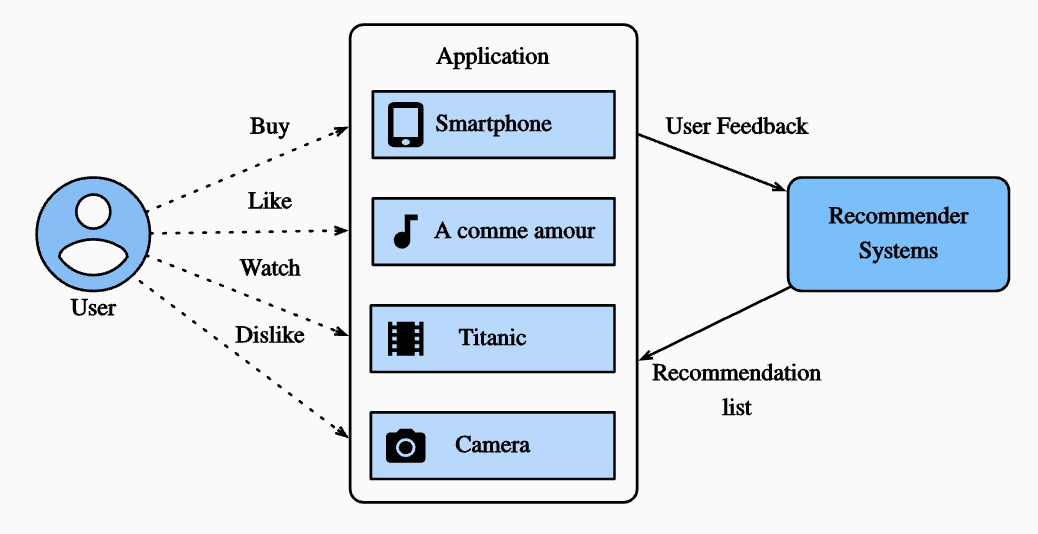 レコメンデーションプロセスのイラスト.png
レコメンデーションプロセスのイラスト.png
ユーザーの行動を見ることから始めれば、これらのレコメンデーション・システムが取るアプローチを知ることができる。
| インタラクションレベル|レコメンデーションアプローチ |---------------|-------------| |インタラクションなし(別名「コールドスタート」)|最も人気のあるアイテム
|最大相互作用|協調フィルタリング(相互作用ベース)アイテム
コンテンツを推薦する一般的なアプローチの1つは、人気アイテムやトレンドアイテムを紹介することです。この方法は、しばしば「*人気アイテム」レコメンデーションと呼ばれ、プラットフォームで最も広く消費されたアイテムや高評価のアイテムのリストを表示することを含む。コンテンツプラットフォームの文脈では、これは「最も人気のある記事」または「今トレンドになっている」セクションの形を取ることができ、現在最も高いレベルのエンゲージメントまたは視聴率を集めている記事を特集します。
もう一つのアプローチは、コンテンツベースのレコメンダーで、与えられたコンテキストのアイテムに似たアイテムを特定し、レコメンドする。このタイプのレコメンダーは、アイテムのコンテンツや特徴を分析して、その類似性を判断する。コンテンツプラットフォームの場合、コンテンツベースのレコメンダーは、ユーザーが読む記事にトピック的またはスタイル的に似ている記事を提案するかもしれない。これらのレコメンデーションは、しばしば「類似記事」のような見出しの下に表示され、読者がより関連するコンテンツを探索するよう促す。
コラボレーション・フィルタリング(インタラクション・ベース)は、Tapestryシステム(Goldberg et al., 1992 )によって最初に作られたもので、異なるアプローチをとるレコメンダーである。コンテンツ分析だけに頼るのではなく、このモデルは現在のユーザーと似たようなインタラクション履歴を持つユーザーを特定する。そして、現在のユーザーがすでに見たり関与したりしたものを除いて、ユーザーが相互作用した類似のアイテムを収集する。これらのアイテムは、パーソナライズされたリストとしてユーザーに推薦され、多くの場合、"他の人も読んでいる "または "パーソナライズされた推薦 "と題される。このようなタイトルを使用することで、類似したユーザーの嗜好や行動に基づいて、そのユーザーのために特別にカスタマイズされた推薦であることをユーザーに明示的に伝えることができる。
協調フィルタリング・レコメンダーは、コンテンツ分析だけではユーザーの嗜好やインタラクションを十分に把握できず、ユーザーの興味に関する貴重なシグナルを提供できない場合に特に効果的である。類似ユーザーの集合的な知恵を活用することで、これらのレコメンダーは、コンテンツだけではすぐにはわからないようなアイテムを表示することができ、そうでなければ発見できなかったかもしれない、新しく関連性のあるコンテンツをユーザーに見せることができる可能性がある。
人気アイテム推薦、コンテンツベース推薦、協調フィルタリング推薦の3つのアプローチは、推薦システムにおいて重要な役割を果たしている。それぞれが明確な利点を提供し、ユーザーに包括的でパーソナライズされた体験を提供するために他のアプローチを補完する。これらのアプローチを組み合わせることで、プラットフォームは多様なレコメンデーションを提供し、様々なユーザーの嗜好やシナリオに対応し、最終的にユーザーのエンゲージメントと満足度を高めることができる。
ベクターデータベースとRecSysの関係は?
上述したように、コンテンツベースと協調フィルタリングベースのアプローチは、類似したアイテムをユーザーに推薦することを目的としている。従来は、開発者がアイテムにキーワードをタグ付けし、そのキーワードとのマッチングに基づいて類似検索を行っていた。しかし、ベクトル埋め込みとベクトルデータベースの登場により、より洗練された類似検索のアプローチが可能になった。
ベクトル埋め込みは、テキスト、画像、音声などの複雑なデータタイプの本質を捉える高密度の数値表現である。これらの埋め込みは、データの意味的・文脈的情報を高次元ベクトル空間に符号化し、意味のある比較や類似度計算を可能にする。
ベクトルデータベース](https://zilliz.com/learn/what-is-vector-database)は、キーワードマッチングに頼る代わりに、これらのベクトル埋め込みを活用し、近似最近傍(ANN)検索や特殊なインデックス構造のような高度な技術を用いて類似検索を行う。アイテムのベクトル表現を格納し、インデックス化することで、ベクトルデータベースは、与えられたクエリアイテムやユーザー嗜好に最も類似したアイテムを効率的に特定し、検索することができる。
このアプローチは、従来のキーワードベースの方法と比較していくつかの利点がある:
1.意味理解:ベクトル埋め込みは、データの意味的な意味を捉え、単純なキーワードの一致を超えた、より微妙な類似性の比較を可能にする。 2.文脈認識:ベクトル埋め込みが持つ高次元の性質は、文脈情報の保存を可能にし、より関連性の高い、文脈に適したレコメンデーションにつながります。 1.柔軟性:ベクトルデータベースは、テキスト、画像、音声など様々なデータタイプに対応できるため、様々なレコメンデーションシナリオに対応できる。 1.スケーラビリティ:ベクターデータベースは、特殊なインデックス技術と近似最近傍探索アルゴリズムを活用することで、精度や速度を損なうことなく、大規模なデータセットの類似性検索を効率的に処理することができます。
ベクトル埋め込みとベクトルデータベースのパワーを活用することで、recsysはより正確で、文脈に関連した、多様なレコメンデーションを提供し、全体的なユーザーエクスペリエンスとコンテンツプラットフォームとのエンゲージメントを向上させることができます。
レコメンデーションシステム構築ツール
今日、リコメンデーションシステムの開発とデプロイメントをサポートする多くのツールとテクノロジーがあり、ベクトルデータベースとシームレスに統合してその機能を強化しています。
ミルバス
Milvusは、スケーラブルな類似検索用に設計されたオープンソースのベクトルデータベースである。複数のインデックスタイプと互換性があり、スケーリングが容易なため、推薦システムやAI研究にますます人気が高まっている。
また、Milvusをバックエンドデータベースとして利用し、アイテムの特徴をベクトルとして保存することで、推薦システムに統合することもできます。Milvusは類似アイテムの高速検索を容易にし、リアルタイム推薦状況におけるシステムの応答性と精度を高めます。
Tensorflowレコメンダー(TFRS)
TFRSは、Tensorflow(機械学習のための広く使われているフレームワーク)の拡張です。TFRSは、Tensorflowの機能を利用し、複雑な推薦システムを構築するための柔軟で強力なライブラリを提供します。効率的な類似性マッチングのために、ベクトルデータベースと統合した複雑な推薦モデルを作成することができます。
さらに、TFRSモデルをレコメンデーションシステムのパイプラインに統合することができ、その中には、モデルのレコメンデーションがユーザのアクションにリアルタイムで応答してクエリされるサービングレイヤも含まれます。
FAISS](https://zilliz.com/learn/faiss)(フェイスブックAI類似検索)
Facebook AI Researchは、効率的な類似性検索と密なベクトルのクラスタリングのために設計されたライブラリであるFAISSを作成した。大規模データを扱うテック企業も、その性能と類似性から愛用している。
通常、開発者はFAISSを類似検索のバックエンド・サービスとしてレコメンデーション・システムに統合する。メインのアプリケーション・ロジックは、FAISSへのAPIコールを通じてユーザーとのインタラクションやレコメンデーション要求を処理する。
近似最近傍オーイエー(Annoy)
AnnoyはPythonバインディングを持つC++ライブラリで、高次元空間における効率的な最近傍探索に焦点を当てています。高次元データの近似最近傍探索を高速に行うように設計されており、推薦システムのアニメーショ ン探索や体性探索に有用なツールとなっている。
Annoyは、ランダム投影やツリーベースの構造などの技術を利用して、効率的に近似最近傍探索を行い、大規模データベース内の類似データ点を見つける際の精度と速度のバランスをとっている。
Annoyは軽量でスタンドアロンなサービス、またはアプリケーション内のライブラリとして機能します。ベクトル類似度に基づく推奨アイテムの高速検索を処理します。
推薦システム構築におけるベクトルデータベースの利点
ベクターデータベースは、高次元データの複雑さを扱う能力を提供することで、推薦システムの構築と効率を大幅に向上させます。ベクターデータベースは、レコメンデーションシステムを正確でスケーラブルにし、リアルタイムのユーザーインタラクションに対応できるようにします。推薦システム構築におけるベクトルデータベースの主な利点は以下の通りです。
**効率的な類似検索 ベクトル・データベースは、ユーザーの嗜好にマッチするコンテンツを特定し、類似検索を迅速に行います。これにより、レコメンデーションシステムはより速く、より関連性の高いレコメンデーションを表示することができ、全体的なユーザーエクスペリエンスを向上させることができます。
**スケーラビリティ ベクターデータベースは、推薦システムが大規模なデータセットを容易に扱うことを可能にします。推薦システムの品質を保証しながら、スピードとパフォーマンスを維持します。
**パーソナライゼーションの向上 機械学習モデルを使用して詳細なベクトル埋め込みを生成することで、ベクトルデータベースはユーザーの嗜好とアイテムの特性の両方をより深く理解することができ、その結果、よりパーソナライズされたレコメンデーションが可能になります。
**リアルタイム・レコメンデーション ベクターデータベースは、新しいユーザーデータが入ってきたときにベクターインデックスをリアルタイムで更新することをサポートし、レコメンデーションシステムが最新のインタラクションに基づいて提案を動的に調整することを可能にします。この機能は、タイムリーで関連性の高いコンテンツでユーザーを惹きつける鍵となります。
**プライバシーとセキュリティ ベクターデータベースは異なるタイプのデータを扱うため、マルチモデルの推薦システムの構築が可能です。このアプローチは、様々なコンテンツタイプを考慮することで推薦プロセスを豊かにし、より多様で魅力的なユーザー体験をもたらします。
推薦システムの最新動向
ベクトルデータベースの採用は、推薦システムの進化において重要な役割を果たしており、ユーザーの複雑な要求に対応するために必要な技術的基盤を提供している。特にベクトルデータベースを統合した後のレコメンデーションシステムの現在のトレンドは、パーソナライズされたコンテンツ配信とユーザーエクスペリエンスの未来を形成している。これらのトレンドはシフトを浮き彫りにしている。以下に現在のトレンドの一部を紹介する。
**強化されたベクトル埋め込みのためのディープラーニング ユーザーの嗜好やアイテムの特徴をより正確にベクトル埋め込みするために、ディープラーニング技術を利用する研究者が増えています。これにより、データ内の複雑な関係を捉えることができ、高度にパーソナライズされたレコメンデーションシステムが実現されている。
**リアルタイム・パーソナライゼーション ベクトルデータベースが高速に類似性検索を実行できるようになったことで、レコメンデーションシステムにおけるリアルタイムのパーソナライゼーションが可能になりました。ユーザーは、即時の行動に基づいたレコメンデーションを即座に受け取ることができるようになり、ユーザーエンゲージメントと満足度が向上しました。
**プライバシー重視のレコメンデーション ユーザーのプライバシーに対する懸念が高まる中、機密性の高い個人情報の使用を最小限に抑えたレコメンデーションシステムを開発する傾向があります。ベクターデータベースは、ユーザーの嗜好や行動を匿名でベクターとして表現することを可能にし、個人データを直接扱う必要性を減らすことで、これを促進します。
**マルチモデル・レコメンデーション 単一のベクトル空間にマルチモデルデータ(テキスト、画像、動画)を使用することが一般的になりつつあります。これにより、レコメンデーションシステムは、異なるタイプのコンテンツ間で、より包括的で文脈に関連した提案を提供できるようになります。
**クラウドベースとマネージドベクターデータベース ベクトルデータベースがクラウドベースのサービスやマネージドソリューションとして利用できるようになったことで、高度なレコメンデーションシステムへの参入障壁が低くなりました。この傾向により、小規模な組織でも最小限のインフラ投資で高度なレコメンデーション・エンジンを導入できるようになった。 レコメンデーションシステム活用のベストプラクティス レコメンデーションシステムのベストプラクティスを活用することで、レコメンデーションシステムが効果的でありながら、責任感があり、ユーザー中心であることを保証することができます。
ユーザーのコンテクストを理解する。 レコメンデーション・システムは、ユーザーのニーズとレコメンデーションが行われる特定のコンテキストを理解するように設計する。これには、ユーザーの行動、嗜好、文脈の推薦を深く分析することが含まれる。
**ハイブリッド・アプローチ このアプローチは、協調フィルタリングやコンテンツベースのフィルタリングなど、異なるレコメンデーション戦略を組み合わせることで、より正確で包括的なレコメンデーションを実現します。ハイブリッド・システムは、各手法の長所を利用し、より幅広いユーザーの興味や行動をカバーする。
**データ・プライバシーの確保 もう一つのベストプラクティスは、ユーザーデータを細心の注意を払って扱い、データ保護規制の遵守を徹底することである。ユーザーのデータを不正アクセスから守るため、強固なセキュリティ対策を実施する。
**モニターとアップデート 推薦システムのパフォーマンスを常に監視しましょう。ユーザーの行動や嗜好の変化に適応し、システムの精度と効率を向上させるためには、定期的なアップデートと調整が必要です。
**倫理的であること 常に倫理的であり、推薦システムが偏見や差別を助長しないようにする。定期的にシステムの公平性を監査し、必要に応じて是正措置をとる。
リアルタイムのフィードバックを取り入れる。 リアルタイムのユーザーからのフィードバックやインタラクションに基づいて、推薦を動的に調整する。これにより、システムの応答性が高まり、推薦の妥当性が長期的に改善される。
レコメンデーションの多様化とパーソナライズ。 レコメンデーションに多様性を導入することで、フィルターバブル効果を回避する。パーソナライゼーションが鍵となる一方で、予期せぬ発見を含む様々な選択肢をユーザーに提供することで、ユーザーの満足度とエンゲージメントを高めることができる。
結論
ベクトルデータベースをレコメンデーションシステムに組み込むことで、正確でパーソナライズされたコンテンツ配信が可能になり、最新のアプリケーションが大幅に強化された。ベクトルデータベースは、高速な類似性検索と、正確な推薦を生成するために重要な高次元データの効率的な処理により、推薦システムに力を与える。さらに、リアルタイムのパーソナライゼーション、スケーラビリティ、多様なデータタイプを処理する能力を促進し、よりユーザー中心のレコメンデーションにつながります。ハイブリッド・アプローチや倫理的AIを含むベスト・プラクティスを採用することで、これらのシステムが効果的で、責任感があり、ユーザーのニーズに沿ったものであることを保証し、その利点をさらに最大化することができる。レコメンデーション・システムは、ベクトル・データベースの助けを借りて、アプリケーションがユーザーと関わり、ユーザーを理解する方法を再定義し、デジタル体験を向上させる。データサイエンティストや熟練した機械学習エンジニアを目指すなら、今こそこの素晴らしいテクノロジーを学ぶ時だ。



