




グラフィカル・デザイナーのための知的類似性検索システム
ベクターデータベースを使用して、デザイン資産の類似検索システムを構築する方法をご紹介します。
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
*この記事はアンジェラ・ニーが転記したものです。
グラフィカルデザイナーは通常、広告ポスター、プロモーションビデオ、パンフレットなど、印刷媒体や電子媒体向けのあらゆる種類のビジュアル資産を革新的に作成する必要があります。多くの場合、グラフィカル・デザイナーは魅力的な画像やビデオを作るために、流行のビジュアル要素やテキストさえも一緒に組み立てなければなりません。似たようなビジュアルアセットを探すことは、デザイナーにとって良いインスピレーションの源になるかもしれない。
多くの画像や動画の類似検索システムからヒントを得て、すべてのデザイン資産に対して統合された類似検索システムを構築し、グラフィカルデザイナーにより革新的なアイデアをもたらすこともできる。このタイプの類似検索システムは、画像、ビデオクリップ、テキストを含むすべてのデザイン資産を収集する中心的なハブです。デザイナーが画像をシステムにアップロードすると、システムは類似した画像やビデオクリップ、テキストを複数返します。そして、デザイナーはそのアセットを活用して、自身のクリエイションを充実させることができる。
システムの実装
システム・アーキテクチャ](https://assets.zilliz.com/graphical_design_1_ccc97fdd51.png)
上の図は、グラフィカル・デザインのための類似検索システムのアーキテクチャの説明図である。最下層では、画像、動画、テキストをベクトルに変換するために特定のAIモデルを使用します。また、オープンソースの機械学習パイプラインであるTowheeを使って、非構造化データを埋め込みデータにエンコードすることもできる。そして、オープンソースのベクトルデータベースであるMilvusをベクトル管理とベクトル類似検索のために採用する。また、画像や動画の対応情報を保存するために、Redisキャッシュレイヤーを導入しています。これらの情報は、情報検索の高速化のため、KV(キー・バリュー)の形でRedisに格納される。
Webアプリケーション・サービスに関しては、ユーザーの多くがPython言語に精通していることを考慮し、Nginx、Flask、Gunicorn、supervisorを使用した。
適切なインデックスの選択
今回は、限られたリソースで高速なクエリが保証されるインデックスタイプ IVF_PQ を選択することにした。PQ(Product Quantization) は、元の高次元ベクトル空間をm` 個の低次元ベクトル空間のデカルト積に一様に分解し、分解した低次元ベクトル空間を量子化する。積量子化により、対象ベクトルと全ユニットの中心との距離を計算する代わりに、対象ベクトルと各低次元空間のクラスタリング中心との距離を計算することが可能となり、アルゴリズムの時間的複雑性と空間的複雑性を大幅に削減することができる。
IVF_PQ は,ベクトルの積を量子化する前にIVFインデックスクラスタリングを行います.そのインデックスファイルはIVF_SQ8よりもさらに小さい。欠点は、それに応じて再現率が低下することである。
IVF_PQ インデックス](https://assets.zilliz.com/image_d68d13de13.png)
Milvus doc](https://milvus.io/docs/v2.0.0/index_selection.md#IVF_PQ)による、
- A = 単一セグメントの計算で、
ターゲットベクトル量* (nlist+ (セグメント内のベクトル量) /nlist) に等しい。*nprobe) に等しい。 - B= セグメントの数。これは
総データ量/index_file_sizeに等しい。 - コレクションのクエリの計算は A * B に等しい。
したがって、今回のケースでは、インデックスパラメーターの適切な値は
nlist=1024,m=8 となる。
ベクトル類似検索の高速化のためのパーティションの使用
検索効率を大幅に向上させるためには、パーティションが必要である。ベクトルデータは,その特徴量のデカルト積の値に基づいて,異なるパーティションに挿入される.
例えば、あるベクトルの対応する項目が2つの特徴を持っているとする。特徴Aに基づいて、データセットをA1, A2, A3, A4に分割する。特徴Bに基づいて、データセットをB1, B2, B3に分割する。そして12のパーティションを作り、A1_B1, A1_B2, A1_B3, A2_B1, A2_B2, A2_B3, ......, A4_B3, A4_B3と名付ける。各パーティションは500万ベクトル以下であり、検索性能の向上に寄与する。
注目すべきは、パーティションを作成する際の特徴は簡単に変わるものであってはならないということである。そうでなければ、パーティションを作り直し、データをインポートし直し、インデックスを再構築しなければならず、プロセス全体が複雑になってしまう。また、あまりに多くの機能に基づいてパーティションを作りすぎるのも避けるべきだ。さもないと、各フィーチャーの値を乗算して生成されるデカルト積が非常に大きくなってしまいます。フィルタリングの代替として、Milvusのハイブリッド検索の機能を活用することができます。
ベクトル類似検索 powered by Milvus
検索結果はリアルタイムで返されることが予想されるため、システムは高い並行性に対応する必要があります。そこで、オープンソースのベクトルデータベースであるMilvusをベクトル類似検索に採用することにしました。すぐに使える機能を備えたMilvusは使いやすい。また、システムパラメータを設定することにより、検索精度とリソース消費のトレードオフをサポートする。
さらに、Milvusはvector、Int、Bool、floatなどの複数のデータ型をサポートしています。Milvusでは、特定の条件で検索結果をフィルタリングしながら類似資産を検索するハイブリッド検索も可能です。
パフォーマンス
テストの結果、類似検索システムのパフォーマンスは以下の通りです。
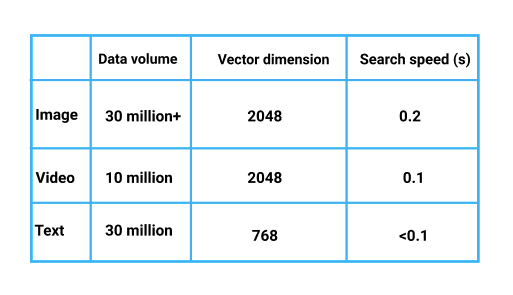 Performance
Performance
より多くのリソースをお探しですか?
- ベクトル類似検索のより多くの産業への応用:
- 画像ベースの商標類似検索システム](image-based-trademark-similarity-search-system):知的財産権保護のよりスマートなソリューション](image-based-trademark-similarity-search-system)
- ベクトル類似検索であなたのワードローブを持続可能にする方法](vector-similarity-search-and-fashion)

読み続けて

ベクトル類似度検索でワードローブを持続可能にする方法
ベクターデータベースを使用して、類似した衣服を検索できるインテリジェントな服の推薦アプリを構築する方法を学ぶ。

PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
Zilliz Cloud PipelineがPDFデータをLLMがセマンティック検索タスクで使用できる形式に変換する方法を学びます。最後に、ベクトル検索を使ってデータ検索を行います。

Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
我々は、ベクトル埋込みの基礎を探求し、Zilliz CloudとOpenAIの埋込みモデルを用いて、実用的な書名検索への応用を実証した。