




機械学習をアプリケーション開発者により身近なものに
オープンソースのエンベッディング・パイプラインであるTowheeが、エンベッディングやその他のMLタスクを必要とするアプリ開発をどのように強化するかをご紹介します。
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
#はじめに
人間が生成したコンテンツを理解するためのアルゴリズムを手作業で作ろうとする試みは、一般的に成功していない。例えば、コンピュータが低レベルのピクセルを分析するだけで、画像(例えば車、猫、コートなど)の意味内容を「把握」することは難しい。カラーヒストグラムや特徴検出器はある程度機能しましたが、ほとんどの用途で十分な精度を発揮することはほとんどありませんでした。
過去10年間で、ビッグデータとディープラーニングの組み合わせは、コンピュータビジョン、自然言語処理、その他の機械学習(ML)アプリケーションへのアプローチ方法を根本的に変えた。スパムメールの検出から現実的なテキストからビデオへの合成に至るまで、さまざまなタスクで驚異的な進歩が見られ、特定のタスクの精度指標は超人レベルに達している。このような改良の主なプラスの副次的効果は、埋め込みベクトル、つまりディープニューラルネットワーク内の中間結果を取ることによって生成されるモデルアーティファクトの使用の増加です。OpenAIのdocs pageに概要が掲載されています:
エンベッディングは、機械学習モデルやアルゴリズムが利用しやすい、特別なデータ表現形式です。エンベッディングは、テキストの意味の情報密度の高い表現です。各埋め込みは浮動小数点数のベクトルであり、ベクトル空間における2つの埋め込み間の距離は、元のフォーマットにおける2つの入力間の意味的類似性と相関する。例えば、2つのテキストが類似している場合、それらのベクトル表現も類似しているはずである。
下の表は、3つのクエリ画像と、それに対応する埋め込み空間での上位5つの画像を示しています(データセットとして、Unsplash Liteの最初の1000枚の画像を使いました):
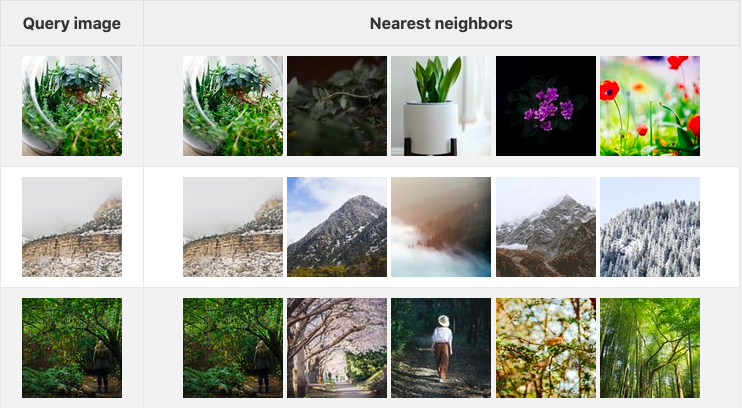 2022-04-20-104339.png
2022-04-20-104339.png
この結果は、純粋な畳み込み画像分類モデルとして有名な resnet50 をベースとした 画像埋め込みモデル で生成されました。エンベッディングは画像に限らず、画像、音声、時系列データ、分子構造など、様々な種類の非構造化データに対して生成することができます。複数の異なるタイプのデータを同じ空間に埋め込むモデル(一般にマルチモーダル埋め込みモデルとしても知られています)も存在し、ますます多くのアプリケーションで使用されています。
次の2つのセクションで説明するように、このような高品質の埋め込みを生成することは、特に規模が大きくなると難しくなります。
埋め込みタスクのための新しいモデルの学習
紙の上では、新しいMLモデルを学習し、それを使って埋め込みを生成することは簡単に聞こえます:最新のアーキテクチャに支えられた、最新かつ最高のプリビルドモデル[1]を使用し、いくつかのデータでそれを訓練します。簡単でしょう?
そうはいかない。表面的には、最新のモデル・アーキテクチャを使用して最先端の結果を得るのは簡単なように見えるかもしれない[2]。しかし、これは真実からはほど遠い。エンベッディング・モデルの学習に関連する、よくある落とし穴について説明しましょう(これらは一般的な機械学習モデルにも当てはまります):
1.十分なデータがない: 十分なデータがないまま、ゼロから新しい埋め込みモデルをトレーニングすると、オーバーフィッティングと呼ばれる現象が起こりやすくなります。実際には、ゼロから新しいモデルをトレーニングする価値があるような十分なデータを持っているのは、世界でも最大規模の組織だけです。他の組織は、fine-tuningに頼らざるを得ません。これは、大量のデータですでにトレーニングされたモデルを、より小さなデータセットを使って蒸留するプロセスです。
2.*ハイパーパラメータ](https://en.wikipedia.org/wiki/Hyperparameter_(machine_learning))は、学習プロセスを制御するために使用される定数であり、モデルの学習速度や、1回のバッチで学習に使用されるデータ量のようなものです。ハイパーパラメータの適切なセットを選択することは、モデルを微調整する際に非常に重要です。この分野の最近の研究では、ImageNet-1kにおいて、改善された学習手順で同じモデルをゼロから学習させた場合、5%以上の精度向上(これは非常に大きい)も示されています。
3.自己教師ありモデルを過大評価する:自己教師という用語は、入力データの「基礎」が、ラベルを必要とせずにデータ自体を活用することによって学習される学習手順を指します[3]。一般的に、自己教師ありの手法は、事前学習(すなわち、より少ないラベル付きデータセットで微調整を行う前に、多くのラベルなしデータで自己教師ありの方法でモデルを学習すること)には最適ですが、自己教師ありの埋め込みを直接使用すると、パフォーマンスが最適でなくなる可能性があります。
上記の3つの問題に取り組むための一般的な方法は、ラベル付きデータでモデルを微調整する前に、まず大量のデータを使って教師なしモデルを訓練することです。これはNLPには効果的だが、CVにはあまり効果的ではない。
Metaのdata2vecトレーニング技術は、様々な種類の非構造化データでディープニューラルネットワークをトレーニングするための自己教師あり手法である。ソースはこちら:Meta AI blog.](https://assets.zilliz.com/2022_04_20_104656_1a54362798.png)
埋め込みモデルの使用には落とし穴がある
これらは、エンベッディング・モデルのトレーニングに関連する多くの一般的な間違いの一部に過ぎません。その直接的な結果として、埋め込みを使おうとしている多くの開発者は、ImageNet (画像分類用)やSQuAD (質問応答用)のようなアカデミックなデータセット上で訓練済みのモデルを直接利用しています。しかし、埋め込み性能を最大限に引き出すためには、いくつかの落とし穴を避ける必要があります:
1.1.学習データと推論データの不一致: 他の組織によって学習された既製のモデルを使用することは、何千ものGPU/TPU時間を必要とせずにMLアプリケーションを開発する一般的な方法となっています。特定のエンベッディング・モデルの限界と、それがアプリケーションのパフォーマンスにどのような影響を与えるかを理解することは非常に重要です。モデルのトレーニング・データと手法を理解しなければ、結果を誤って解釈することは信じられないほど簡単です。例えば、音楽を埋め込むためにトレーニングされたモデルは、音声に適用するとうまく動作しません。
2.不適切なレイヤー選択: 完全教師ありのニューラルネットワークを埋め込みモデルとして使用する場合、一般的に特徴は、活性の最後から2番目のレイヤー(正式にはペナルティメットレイヤーとして知られています)から取得されます。しかし、これはアプリケーションによっては、最適とは言えない性能になる可能性があります。例えば、画像分類用に学習されたモデルをロゴおよび/またはブランドの画像の埋め込みに使用する場合、より早い活性化を使用することで性能が向上する可能性がある。これは、複雑でない画像を分類するのに重要な低レベルの特徴(エッジや角)をよりよく保持するためです。
3.非同一の推論条件: 埋め込みモデルから最大限の性能を引き出すためには、学習条件と推論条件が全く同じでなければなりません。実際には、そうでないことがよくあります。例えば、torchvisionの標準的なresnet50モデルは、バイキュービック補間と最近傍補間を用いてダウンサンプリングした場合、全く異なる2つの結果を生成します(下記参照)。
 トウヒ。写真:パトリス・ブシャール
トウヒ。写真:パトリス・ブシャール
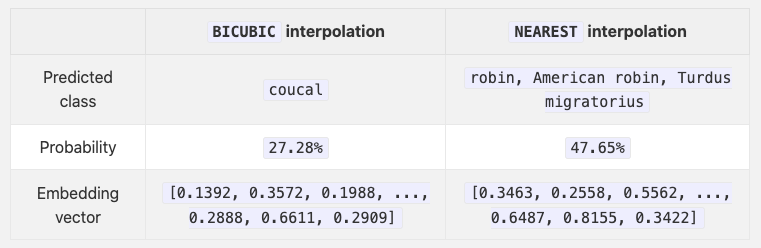 Table 1.
Table 1.
埋め込みモデルの展開
モデルのトレーニングと検証に関連するすべてのハードルを飛び越えたら、スケーリングとデプロイが次の重要なステップになります。繰り返しになりますが、エンベッディングモデルのデプロイは、言うは易く行うは難しです。DevOpsに隣接する分野であるMLOpsは、特にこの目的のために存在する。
1.*エンベッディング・モデルは、他のほとんどのMLモデルと同様に、標準的な日常的なCPUからプログラマブル・ロジック(FPGA)まで、様々な種類のハードウェア上で実行することができます。コストと効率のトレードオフを分析した研究論文があり、ほとんどの組織がここで直面する難しさを強調している。
2.モデル展開プラットフォーム: 利用可能なMLOpsや分散コンピューティングプラットフォームは数多くある(オープンソースのものも多い)。これらがアプリケーションにどのように適合するかを見極めること自体が課題となり得る。
3.*アプリケーションの規模が大きくなるにつれて、埋め込みベクターのためのスケーラブルで永続的なストレージソリューションを見つける必要があります。そこで、vector databases の出番です。
自分で勉強しよう!
あなたの熱意に拍手を送りたい!覚えておいてほしいことがいくつかある:
**MLはソフトウェア工学とは大きく異なる: **従来の機械学習は、ソフトウェア工学とは大きく異なる数学の一分野である統計学からそのルーツを得ている。正則化や特徴選択といった重要な機械学習のコンセプトは、すべて数学に強く根ざした基本的なものです。学習と推論のための最新のライブラリ(PyTorchとTensorflowの2つがよく知られています)は、埋め込みモデルの学習と生産を著しく容易にしましたが、異なるハイパーパラメータと学習方法が埋め込みモデルの性能にどのように影響するかを理解することは、依然として非常に重要です。
PyTorchやTensorflowの使い方は直感的ではありません: 前述のように、これらのライブラリは、最新のMLモデルの学習、検証、デプロイを大幅に高速化しました。新しいモデルの構築や既存のモデルの実装は、熟練したML開発者やHDLに精通したプログラマーにとっては非常に直感的なものですが、ほとんどのソフトウェア開発者にとっては、基礎となる概念を理解するのは難しいかもしれません。また、これら2つのフレームワークで使用される実行エンジンにはかなりの違いがあるため、どちらのフレームワークを選ぶべきかという問題もあります(個人的にはPyTorchをお勧めします)。
あなたのコードベースに合うMLOpsプラットフォームを見つけるには時間がかかる:ここにMLOpsプラットフォームとツールのキュレーションリストがある。何百もの異なる選択肢から選ぶことができ、それぞれの長所と短所を評価することは、それ自体が何年もの研究プロジェクトになる。
以上のことを踏まえて、私は上記の私の発言を修正して言いたい:あなたの熱意には拍手を送りたいが、MLとMLOpsを学ぶことはお勧めしない。MLとMLOps*を学ぶことは、かなり長く退屈なプロセスであり、最も重要なこと、つまりユーザーに愛される確かなアプリケーションの開発から時間を奪うことになりかねない。
Towheeでデータサイエンスを強化する
Towheeはオープンソースプロジェクトであり、ソフトウェアエンジニアがわずか数行のコードでエンベッディングを利用するアプリケーションを開発し、デプロイするのを支援する[4]。Towheeは、エンベッディングモデルや機械学習を深く学ぶことなく、独自のMLアプリケーションを開発する自由と柔軟性をソフトウェア開発者に提供します。
簡単な例
Pipelineは、複数のサブタスク(TowheeではOperatorとも呼ばれる)から構成される1つの埋め込み生成タスクである。タスク全体をPipeline` 内で抽象化することで、Towhee はユーザーが前述のエンベッディング生成の落とし穴の多くを回避することを支援します。
>>> from towhee import pipeline
>> embedding_pipeline = pipeline('image-embedding-resnet50')
>> embedding = embedding_pipeline('https://docs.towhee.io/img/logo.png')
上の例では、画像デコード、画像変換、特徴抽出、埋め込み正規化の4つのサブステップが1つのパイプラインにまとめられています。Towheeは、オーディオ/音楽埋め込み、画像埋め込み、顔埋め込みなど、様々なタスクのための埋め込みパイプラインをあらかじめ用意しています。パイプラインの全リストは、Towhee hub をご覧ください。
メソッド連結API
Towheeは DataCollection というPythonicな非構造化データ処理フレームワークも提供している。つまり、DataCollectionはメソッドチェイニングAPIであり、開発者は実世界のデータに対してエンベッディングやその他のMLモデルを迅速にプロトタイプ化することができます。以下の例では、DataCollection を使って resnet50 埋め込みモデルを使って埋め込みを計算している。
この例では、1桁が 3 の素数をフィルタリングするアプリケーションを作る:
>>> from towhee.functional import DataCollection
>> def is_prime(x):
... if x <= 1:
... return False
... for i in range(2, int(x/2)+1):
... if x % i:
... Falseを返す
... 真を返す
...
>>> dc = (
... DataCollection.range(100)
... .filter(is_prime) # 第1段階、素数を見つける
... .filter(lambda x: x%10 == 3) # 第2段階、'3'で終わる素数を見つける。
... .map(str) # 第3段階、文字列に変換する
...)
...
>>> dc.to_list()
DataCollectionを使うと、たった1行のコードでアプリケーション全体を開発することができる。次のセクションでは、DataCollection` を使って逆引き画像検索アプリケーションを開発する方法を紹介する。
トウヒ・トレーナー
上述したように、完全または自己教師ありの学習済みモデルは、多くの場合、一般的なタスクに適しています。しかし、例えば猫と犬を区別するような、非常に特殊なことを得意とする埋め込みモデルを作りたいこともあるでしょう。Towheeは、このような目的に特化した学習/微調整フレームワークを提供します:
>>> from towhee.trainer.training_config import TrainingConfig
>> training_config = TrainingConfig(
... batch_size=2、
... epoch_num=2、
... output_dir='quick_start_output'
...)
また、学習するデータセットを指定する必要がある:
>>> train_data = dataset('train', size=20, transform=my_data_transformer)
>> eval_data = dataset('eval', size=10, transform=my_data_transformer)
すべての準備が整えば、既存のオペレータから新しい埋め込みモデルを学習するのは朝飯前です:
>>> op.train(
... training_config、
... train_dataset=train_data、
... eval_dataset=eval_data
...)
一旦完了すれば、残りのコードを変更することなく、アプリケーションで同じ演算子を使うことができる。
 上図:埋め込みモデルがエンコードしようとする画像の核となる部分を示すアテンション・ヒートマップ。Towheeの将来のバージョンでは、アテンションヒートマップやその他の視覚化ツールを、微調整フレームワークに直接統合する予定です
上図:埋め込みモデルがエンコードしようとする画像の核となる部分を示すアテンション・ヒートマップ。Towheeの将来のバージョンでは、アテンションヒートマップやその他の視覚化ツールを、微調整フレームワークに直接統合する予定です
アプリケーション例:逆画像検索
Towheeの使い方を示すために、小さな逆画像検索アプリケーションを作ってみましょう。逆画像検索はよく知られています。さっそくやってみましょう:
>>> import towhee
>> from towhee.functional import DataCollection
このアプリケーションの例では、small dataset と 10 枚のクエリ画像を使用します。DataCollection` を使うと、データセットとクエリ画像の両方を読み込むことができます:
>> dataset = DataCollection.from_glob('./image_dataset/dataset/*.JPEG').unstream()
>> query = DataCollection.from_glob('./image_dataset/query/*.JPEG').unstream()
次のステップは、データセットコレクション全体に対する埋め込みを計算することです:
>>> dc_data = (
... dataset.image_decode.cv2()
... .image_embedding.timm(model_name='resnet50')
...)
...
このステップは、埋め込みベクトルのローカルコレクションを作成します。これで、最近傍を問い合わせることができます:
>>> result = (
... query.image_decode.cv2() # クエリ集合内のすべての画像をデコードします.
... .image_embedding.timm(model_name='resnet50') # `resnet50` 埋め込みモデルを用いて、埋め込み画像を計算します。
... .towhee.search_vectors(data=dc_data, cal='L2', topk=5) # データセットを検索する。
... .map(lambda x: x.ids) # 類似した結果のID(ファイルパス)を取得する
... .select_from(dataset) # 結果画像の取得
...)
...
Ray](https://github.com/ray-project/ray)を使ってアプリケーションをデプロイする方法も提供しています。query.set_engine('ray')`を指定するだけです!
おわりに
最後に一言:Towheeは本格的な、エンドツーエンドのモデルサービングやMLOpsのプラットフォームだとは考えていませんし、それを目指しているわけでもありません。むしろ、エンベッディングやその他のMLタスクを必要とするアプリケーションの開発を促進することを目指しています。Towheeでは、エンベッディングモデルとパイプラインの迅速なプロトタイピングをローカルマシンで可能にし(Pipeline + Trainer)、ML中心のアプリケーションをわずか数行のコードで開発できるようにし(DataCollection)、独自のクラスタに簡単かつ迅速にデプロイできるようにしたいと考えています(Rayを介して)。
私たちは、オープンソースコミュニティに参加してくれる仲間を常に探しています。もしあなたが興味をお持ちなら、Githubで私たちに星を付けてください。また、SlackやTwitterでも私たちと連絡を取ることができます。
以上です。この記事が参考になったでしょうか?ご質問、ご意見、ご不明な点などございましたら、下記までお気軽にコメントをお寄せください。今後もお楽しみに!
脚注
1.画像分類を例にとると、畳み込みニューラルネットワーク(CNN)の急速な進化を見ることができる:VGGアーキテクチャーはAlexNetと比較してより深く、より小さなカーネルサイズを持ち、ResNetsはスキップ接続とバッチ正規化を導入し、超ディープモデルのバックプロポゲーションを容易にし、より最近のTransformer-CNNハイブリッドアーキテクチャーは自己注意を加え、最先端の結果を達成する。
2.Transformerベースのモデルは、オーバーフィッティングを防ぐために、より大きなデータセットサイズ(および/または、より多くのデータ補強)と共に、よりモデルおよびデータセット固有のハイパーパラメータチューニングを必要とする。さらに[最近の研究](https://arxiv.org/abs/2201.03545)では、深さ方向の畳み込みを利用した純粋な畳み込みモデルが、視覚タスクにおいてトランスフォーマーを凌駕することも示されているが、それはまた別の日の話である。
3.3.これは単純化しすぎです。ファンダメンタルズ」とはどういう意味かについては、今後のブログ記事で詳しく説明するつもりだ。
4.Towheeは、機械翻訳、物体検出、画像間のパイプラインのような一般的な機械学習パイプラインを作成し、共有するために使用することもできます。
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.


