




ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
インデックスがベクトル類似性検索を劇的に高速化する仕組み、さまざまなインデックスの種類、次のAIアプリケーションに適したインデックスの選び方についてご紹介します。
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
コンピュータ・ビジョンから新薬の発見まで、多くの一般的な人工知能(AI)アプリケーションはベクトル・データベースを動力源としている。ビッグデータ検索を飛躍的に加速させるデータ整理のプロセスであるインデックス化により、100万、10億、あるいは1兆スケールのベクトルデータセットへのクエリを効率的に行うことができる。
本記事は前回のブログ「【Accelerating Similarity Search on Really Big Data with Vector Indexing】(https://zilliz.com/blog/Accelerating-Similarity-Search-on-Really-Big-Data-with-Vector-Indexing)」の補足記事であり、ベクトル類似検索の効率化においてインデックスが果たす役割や、FLAT、IVF_FLAT、IVF_SQ8、IVF_SQ8Hを含む様々なインデックスについて解説しています。この記事では、4つのインデックスの性能テスト結果も紹介しています。まずはこのブログをお読みになることをお勧めする。
この記事では、4つの主要なタイプのインデックスの概要を説明し、引き続き4つの異なるインデックスを紹介する:IVF_PQ、HNSW、ANNOY、E2LSHである。
近似最近傍探索(ANNS)はインデックス作成における重要な概念である。この概念とKNN(K nearest neighbor)に対する優位性をより深く理解するには、Marie Stephen Leoが書いたブログ記事を読んでください。
一般的なインデックスにはどのような種類がありますか?
高次元ベクトル類似検索のために設計されたインデックスは数多くあり、それぞれが性能、精度、必要なストレージ容量においてトレードオフの関係にあります。一般的なインデックスには、量子化ベース、グラフベース、ハッシュベース、ツリーベースがあります。ディスクベース ANNSは近似最近傍探索(ANNS)の分野における最近の進歩の産物である。このタイプのインデックスの紹介は、次の記事で紹介する予定である。(ご期待ください!)。
量子化ベースのインデックス
量子化ベースのインデックスは、大きな点の集合を希望する数のクラスターに分割し、点とそのセントロイド間の距離の合計が最小になるようにすることで機能する。セントロイドは、クラスタ内のすべての点の算術平均をとることによって計算される。
セントロイドで表されるグループに点を分割する](https://assets.zilliz.com/quantization_8209236271.png)
上の図では、ベクトルは3つのクラスタに分割され、それぞれがセントロイド点C0, C1, C2を持つ。クエリーベクトルqの最近傍を探索するには、qとC0、C1、C2との距離を比較すればよい。計算の結果、qはC0とC1に近いことがわかる。したがって、さらにqをC0とC1のグループのベクトルと比較するだけでよい。
グラフ・ベースのインデックス
グラフはそれ自体、最近傍情報を含んでいます。下の画像を例にとると、ピンクの点がクエリーベクトルです。その最も近い頂点を見つける必要がある。エントリーポイントはランダムに選択される。エントリーポイントはデータベースに挿入された最初のベクトルであることもあります。例えばAをランダムに選択します。B,C,DはAの近傍であり、その中でDがピンク点に最も近い。しかし、Eの近傍はすべてピンク点に比べて遠い。したがって、Eはピンクの点に最も近いと言える。
グラフベースのインデックスを使ってピンクの点の最近傍を見つける。画像ソースCSDNブログ](https://assets.zilliz.com/graph_dfa3d15b4f.png)
しかし、上記のアプローチにはいくつかの問題がある:
- Kのようないくつかの頂点は照会されない。
- 頂点EとLは近接しているがつながっていない。そのため、ANNSの間、LはEの近傍とみなされない。
- 隣接する頂点の数が多ければ多いほど、ストレージの消費は大きくなる。しかし、接続線が不十分であると、問い合わせ効率が低下する。 これらの問題を解決するのは簡単である:
- グラフを構築するとき、すべての頂点は隣接する頂点を持つ必要がある。この場合、頂点Kは問い合わせ可能である。
- 隣接する頂点はすべて接続されていなければならない。(接続戦略のより詳細な説明は、近接グラフに基づく近似最近傍探索を参照のこと)。
- 問い合わせる隣接頂点の数は設定で指定できる。
これらの問題点を解決しても、問い合わせの効率はまだ向上していない。そこで、ここでは「高速道路」機構を導入する必要がある。
高速化メカニズム
クエリは、クエリベクトルから非常に離れたエントリーポイントから開始されるため、クエリベクトルに最も近い近傍頂点を見つけるためには、多くの頂点を通過し、長い距離を移動しなければなりません。高速道路メカニズムを導入することで、近傍頂点のいくつかをスキップして探索を高速化することができる。下図のように、赤の矢印(高速道路)をたどって、緑のクエリーポイントの最近傍を見つけることができる。たった3つの頂点を通過するだけである。
検索を高速化する高速道路の仕組み】(https://assets.zilliz.com/expressway_9d457f3e51.png)
ハッシュベースのインデックス
ハッシュベースのインデックスは、一連のハッシュ関数を使用する。複数のハッシュ関数が衝突する確率はベクトルの類似度を表す。データベース内の各ベクトルは複数のバケットに分類されます。最近傍探索の間、十分な数のバケットを持つために、探索半径は連続的に増加する。そして、クエリベクトルとバケット内のベクトルとの距離がさらに計算される。
ベクトルを複数のバケットに分割する](https://assets.zilliz.com/hash_c266fa1a77.png)
ツリーベースのインデックス
木ベースのインデックスのほとんどは、高次元空間全体を特定のルールで上から下に分割します。例えば、KD-treeは分散が最も大きい次元を選択し、その次元の中央値に基づいて空間内のベクトルを2つの部分空間に分割する。一方、ANNOYはランダム射影により超平面を生成し、その超平面を用いてベクトル空間を2つに分割する。
インデックスはどのシナリオに最適か?
以下の表は、いくつかのインデックスとその分類の概要である。
最初の4種類のインデックスとその性能テスト結果については、以前の記事「【ベクトルインデックスで本当にビッグデータ上の類似検索を高速化】(https://zilliz.com/blog/Accelerating-Similarity-Search-on-Really-Big-Data-with-Vector-Indexing)」で取り上げています。この記事では主にIVF_PQ、HNSW、ANNOY、E2LSHに焦点を当てる。
| インデックス | ---- | ---- | | FLAT|該当なし | 量子化ベース|IVF_FLAT | 量子化ベース|IVF_SQ8 | 量子化ベース|IVF_SQ8H | IVF_PQ|量子化ベース | HNSW|グラフベース | ANNOY|ツリーベース | E2LSH|ハッシュベース
*注:この記事では、IVFインデックスを量子化ベースのインデックスに分類していますが、IVFインデックスを量子化ベースとして扱うべきではないと考える研究者もいるため、学界ではまだ論争が続いています。
IVF_PQ:IVFインデックスの中で最も高速なタイプであるが、想起率にかなりの妥協がある。
PQ (Product Quantization) は、元の高次元ベクトル空間を m 個の低次元ベクトル空間のデカルト積に一様に分解し、分解された低次元ベクトル空間を量子化します。IVF_PQは、ターゲットベクトルとデータベースベクトル間の距離を計算する代わりに、残差ベクトルを積量子化器(ベクトルとそれに対応する粗セントロイドベクトルとの差)で符号化します。つまり、データベース内のベクトルは、そのセントロイドと量子化された残差ベクトルによって表現されます。
ターゲットクエリベクトルと選択されたバケツからのベクトルとの距離を計算する際、IVF_PQはルックアップテーブルを用いて残差ベクトルの距離を素早くデコードします。
IVF_PQはベクトルの積を量子化する前にIVFインデックスのクラスタリングを行います。そのインデックスファイルはIVF_SQ8よりもさらに小さくなりますが、ベクトル検索時の精度が低下します。
HNSW: 高速・高リコール・インデックス。
HNSW (Hierarchical Navigable Small World Graph)はグラフベースのインデックス作成アルゴリズムであり、格納された要素の入れ子になった部分集合に対して、近接グラフの階層集合(レイヤー)からなる多層構造をインクリメンタルに構築する。上位層は、下位層から指数関数的に減衰する確率分布でランダムに選択される。探索は最上位レイヤから開始し、このレイヤでターゲットに最も近いノードを見つけ、次のレイヤに降りて別の探索を開始する。何度も繰り返すうちに、素早く目標に近づくことができる。
HNSWは性能を向上させるために、グラフの各層のノードの最大次数をMに制限している。さらに、インデックスを構築する際には efConstruction を、ターゲットを検索する際には ef を用いて検索範囲を指定することができる。
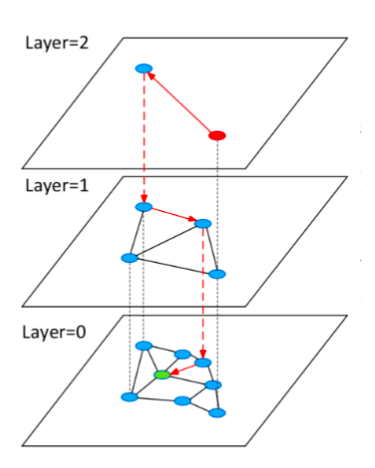 HNSWグラフを用いた効率的でロバストなANNS
HNSWグラフを用いた効率的でロバストなANNS
ANNOY: 低次元ベクトルに対する木ベースのインデックス
ANNOY (Approximate Nearest Neighbors Oh Yeah)は、超平面を用いて高次元空間を複数の部分空間に分割し、それらを木構造に格納するインデックスである。
Annoyはn_tree(n_treeはフォレスト内の木の本数を表す)のバイナリツリーで、ツリー上の各ノードはデータベースの超平面部分空間である。ツリー上の各中間ノードで、空間を2つの部分空間に分割するランダムな超平面が選択される。葉は _K 以下のベクトルを持つ超平面部分空間である。
下図に示すように、ANNOYは空間をいくつかの部分空間に分割する。まず、空間を2つの部分空間に分割する。
空間分割](https://assets.zilliz.com/ANNOY_1_57303a8e9f.png)
次に、2つの部分空間のそれぞれを半分に切り、4つの小さな部分空間を生成する。
空間分割](https://assets.zilliz.com/ANNOY_2_25ca57951c.png)
空間全体を分割し続けると、最終的に下の図のようになる。
空間分割](https://assets.zilliz.com/ANNOY_3_dd52b64f4b.png)
この空間を分割するプロセス全体は、二分木に似ている。
バイナリーツリー](https://assets.zilliz.com/binary_tree_7b82d5ad7b.png)
ベクトルを探索するとき、ANNOYは木構造をたどって目的のベクトルに近い部分空間を見つけ、その部分空間内のすべてのベクトルを比較して最終結果を得ます。ANNOY は最大 search_k 個のノードを検査し、その値は n_trees * n である。Annoyは十分なノード数を確保するために、全ての木を同時に探索する優先キューを使用する。明らかに、ターゲットベクトルがある部分空間の端に近い場合、高い再現率を得るためには探索する部分空間の数を大幅に増やす必要がある。
ANNOYはユークリッド距離、マンハッタン距離、余弦距離、ハミング距離など複数の距離メトリックをサポートする。さらに、ANNOYインデックスは複数のプロセス間で共有することができる。しかし、その欠点は低次元で小さなデータセットにしか適さないことである。ANNOYはデータIDとして整数しかサポートしていないため、ベクトルIDが整数でない場合は余分なメンテナンスが必要となる。GPU処理もANNOYではサポートされていません。
E2LSH: 非常に大量のデータに対して非常に効率的なインデックス。
E2LSH は p-stable 分布に基づいて LSH 関数を構築する。E2LSHは、LSH関数のセットを使って、類似ベクトルの衝突確率を高め、非類似ベクトルの衝突確率を下げる。LSH関数は、まず物体をランダムな線に沿って射影し、次に射影にランダムなシフトを与え、最後にフロア関数を使って、シフトされた射影が入る幅wの区間を見つけることによって、物体をバケツに分割する。
検索や問い合わせの際には、E2LSHはまずハッシュ関数群 h1 に従ってベクトルオブジェクトが位置するバケットを見つけ、次にハッシュ関数群 h2 を使ってバケット内の位置を特定する。E2LSH の二次ハッシュ構造は、データベース内の全てのベクトルのハッシュプロジェクション値を格納することによる高いストレージオーバーヘッドを削減するだけでなく、クエリベクトルが存在するハッシュバケットを素早く見つけることができる。
E2LSHは検索速度を大幅に向上させることができるため、データセット量が多いシナリオに特に適している。
参考文献
本記事では以下のソースを使用した:
- "Encyclopedia of database systems", Ling Liu and M. Tamer Özsu.
- "A Survey of Product Quantization", Yusuke Matsui, Yusuke Uchida, Herve Jegou, Shinichi Satoh.
- "Milvus: A Purpose-Built Vector Data Management System", Jianguo Wang, Xiaomeng Yi, Rentong Guo et al.
- "Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs", Yu.A. Malkov, D. A. Yashunin.
謝辞
本論文のレビューに協力し、貴重な示唆を与えてくれたXiaomeng Yi、Qianya Cheng、Weizhi Xuに感謝する。



