




ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
Milvusベクターデータベースを使用して、アーカイブストレージから重複するビデオコンテンツを特定し、フィルタリングする自動化ソリューションを構築する方法をご紹介します。
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
*この記事はアンジェラ・ニーが転記したものです。
重複排除とは、データベース内の冗長なデータを排除することである。これは業界では新しいアイデアではない。しかし、今日の爆発的なデータ増加、特に動画のような非構造化データの増加を管理するために必要なソリューションと思われる。
Youtubeのようなオンライン動画ストリーミング・プラットフォームには、大量のアーカイブ動画が保存されている。アーカイブには重複した動画リソースが多数存在する可能性が高い。しかし、データの冗長性は2つの問題をもたらす:
1.1.重複動画がストレージの多くを占める。統計によると、非圧縮の4Kの1分間の長いクリップは、40GB以上のストレージを必要とする可能性がある。 2.重複した動画は優れたユーザー体験につながらない。オンライン動画プラットフォームは通常、ユーザーの興味を計算するAIアルゴリズムを採用し、ユーザーに様々な動画を推薦する。しかし、アーカイブリソースが重複している場合、推薦の際にユーザーに冗長なコンテンツのリストが表示される可能性が高い。
したがって、より効率的にデータを管理し、ユーザー体験を最適化するために、オンライン動画プラットフォームには動画重複排除システムが必要である。
このチュートリアルでは、ベクトル管理とベクトル類似検索のために設計されたベクトルデータベースを用いて、インテリジェントなビデオ重複排除システムを構築する方法を説明する。
システムの実装
一般的に、ビデオの類似性検索を行う場合、システムはビデオクリップのいくつかのキーフレームを抽出し、ディープラーニングモデルを使用して、これらのキーフレームを複数の特徴ベクトルに変換します。ここで問題が発生する。どうやって複数の特徴ベクトルの類似度を計算するのか?一般的な方法としては、すべての特徴ベクトルを結合し、次の段階であるベクトルの類似性検索のために1つのベクトルを生成する。しかし、リソースが限られている中小企業にとっては、別の方法があります。もう一つの解決策は、ビデオクリップを複数の画像の集合体として扱うことである。ビデオ重複排除システムはビデオクリップから一定数のキーフレーム(画像)を抽出し、画像セットを作成する。このようにして、ビデオクリップは画像集合で表現される。ビデオ重複排除システムは、2つのビデオ間の類似度を2つの画像セットの類似度と定義し、オープンソースのベクトルデータベースであるMilvusを使って類似度を計算する。このチュートリアルでは、MVP重複排除システムを構築することを意図しているので、特徴ベクトルを組み合わせる代わりに、2番目の方法を使用します。
ビデオ重複排除システムのワークフロー](https://assets.zilliz.com/video_dedupte_system_workflow_a285028292.jpeg)
1.アーカイブ動画は、オンライン動画プラットフォームのエンジニアによってサーバーにアップロードされる。一方、これらのアーカイブ動画の対応するメタデータは、リレーショナルデータベースに格納される。また、データの永続化のために分散ファイルシステム(DFS)も採用されている。 2.アーカイブ動画がアップロードされると、システム内で動画処理タスクが起動する。その結果、システムはアップロードされたアーカイブビデオを前処理し、キーフレームを抽出し、キーフレーム画像を特徴ベクトルに変換し、ベクトルデータベースに格納する。なお、各動画はキーフレームから変換された特徴ベクトルの集合で表現される。 3.新しい動画がアップロードされるたびに、システムは新しくアップロードされた動画を新しい特徴ベクトルの集合に変換する。次に、システムは同じベクトルデータベースでベクトルの類似度検索を行い、新しくアップロードされた動画とデータベースに保存されているアーカイブ動画との類似度を計算し、TopKの類似動画を返す。
以下では、インテリジェントなビデオ重複排除システムを構築するための主要なステップを詳細に説明する。
主要ステップ
1.ビデオを画像セットに変換する
ffprobeは、特にマルチメディア資産を分析するために設計されたツールです。ffprobeは、マルチメディアストリームで使用されているコンテナのフォーマットや、各マルチメディアアセットのフォーマットとタイプを検出するためにも使用できます。ビデオの再生時間に関する情報を取得するには、次のコマンドを使用します。
ffprobe -show_format -print_format json -v quiet input.mp4
FFmpegは、オーディオとビデオクリップの録音と複数のフォーマットへの変換をサポートする、オーディオとビデオ解析のためのオープンソースツールである。FFmpegを使用して、ビデオ内の一定間隔のフレームを抽出する。例えば、ビデオクリップが100秒続き、10秒ごとにフレームを抽出する場合、抽出比率は0.1となる。以下のコマンドを実行してビデオフレームを抽出します。
ffmpeg -i input.mp4 -r 0.1 ./images/frames_%02d.jpg
2.画像を特徴ベクトルに変換する
画像の前処理には、画像の切り抜き、拡大、縮小、画像のグレースケールの調整などが含まれる。画像の前処理が終わったら、事前に学習させたディープラーニングモデルVGGまたはResNetを用いて、画像を1000次元の特徴ベクトルに変換する。
# NativeImageLoaderを使って数値行列に変換する。
File f=new File(absolutePath, "drawn_image.jpg");
NativeImageLoader loader = new NativeImageLoader(height, width, channels);
# 画像を
INDArrayINDArray image = loader.asMatrix(f);
# 値のスケーリングが必要
DataNormalization scalar = new ImagePreProcessingScaler(0, 1);
# 画像データセットに対してスカラーを呼び出す
scalar.transform(画像);
# ニューラルネットを通過させ、出力配列に格納する。
output = model.output(image);
3.動画の類似度を計算する
上述したように、ビデオの類似度は2つの画像セットの類似度と等価である。しかし、2つのベクトル集合の類似度を直接計算することはできません。計算できるのは2つの単一ベクトルの類似度だけである。そこで、2つの画像集合の類似度を計算するルールを定義する必要がある:
- A = ある画像と別の画像の類似度 = 画像特徴ベクトルの内積(IP)
- B = 画像と画像集合の類似度 = Aの最大値。
- 画像集合と別の画像集合の類似度 = AとBの平均値。
ルールをさらに明確にするために、2つのベクトル集合があり、それらの類似度を知りたいとする。
- 集合1(Vec_1, Vec_2, ..., Vec_10を含む)
- 集合2 (Vec_11, Vec_12, ..., Vec_20)
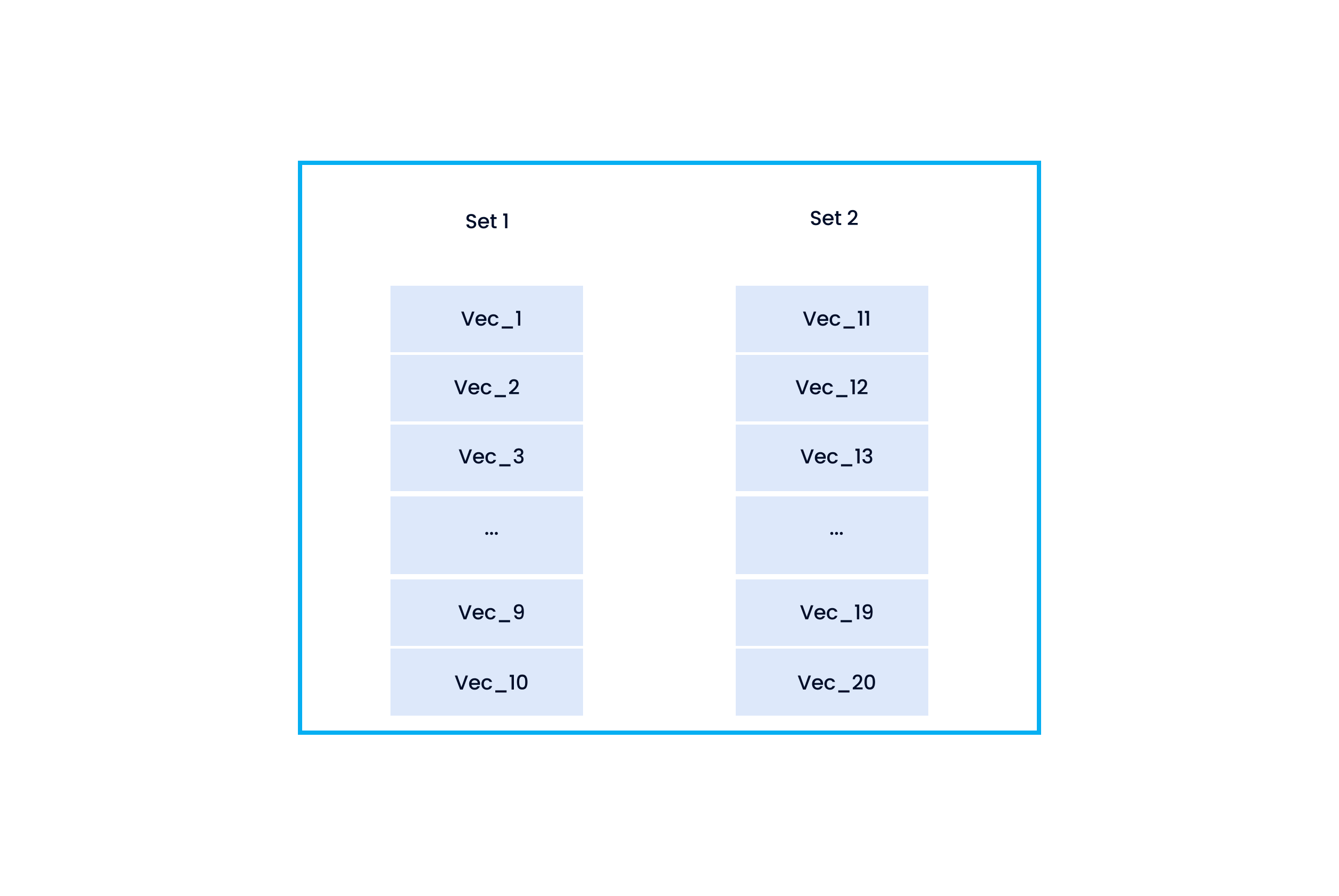 2つの画像集合、それぞれ10個のベクトルを含む
2つの画像集合、それぞれ10個のベクトルを含む
まず、Vec_1とVec_11, Vec_12, ..., Vec_20をそれぞれ比較し、内積を計算する。そして、IP_1, IP_2, ..., IP_10を求める。その中の最大値がVec_1と集合1の類似度であり、最大値をMax_1と呼ぶ。例えば、IP_3はIP_1からIP_10の中で最大である。つまり、Vec_1と集合1の類似度はIP_3(Vec_1とVec_13の類似度)に等しい。IP_3の名前をMax_1に変更する。続いて、集合1の残りのベクトルと集合2の各ベクトルを比較して、同じプロセスを繰り返す。この後、Max_1、Max_2、...、Max_10が得られる。集合1と集合2の類似度は、Max_1, Max_2, ..., Max_10の平均に等しい。
ベクトルとベクトル集合の類似度の計算](https://assets.zilliz.com/2_video_datasets_ba9b1deb32.png)
4.ベクトル類似度検索 powered by Milvus
Milvus](milvus.io)は、入力ベクトルに対するクエリを処理するために特別に設計されたデータベースとして、1兆スケールのベクトルをインデックス化することができる。あらかじめ定義されたパターンに従った構造化データを主に扱う既存のリレーショナルデータベースとは異なり、Milvusは非構造化データから変換された埋め込みベクトルを扱うためにボトムアップから設計されている。
Milvusのデータワークフローへの組み込み](https://assets.zilliz.com/Milvus_workflow_1922c6af2a.png)
インターネットが成長し進化するにつれ、電子メール、論文、IoTセンサーデータ、フェイスブックの写真、タンパク質の構造など、非構造化データがますます一般的になってきた。コンピュータが非構造化データを理解し処理するために、これらは埋め込み技術を使ってベクトルに変換される。Milvusはこれらのベクトルを保存し、インデックス化する。Milvusは、2つのベクトルの類似距離を計算することで、2つのベクトル間の相関を分析することができます。2つの埋め込みベクトルが非常に類似している場合、元のデータソースも類似していることを意味します。
このチュートリアルでは、以下の手順に従ってMilvusでベクトルの類似性検索を行います:
- ベクトルデータベースMilvusに画像特徴ベクトルを保存します。Milvusは自動的に特徴ベクトルに対応するIDを生成します。
- Milvusでベクトル類似度検索を一括して行い、TopKの暫定結果を得る。
- ステップ3であらかじめ定義された計算式に従って動画間の類似度を計算し、TopKの結果を返す。
システム最適化
このチュートリアルは、最小実行可能製品(MVP)を構築するための基本的なインストラクションとして機能します。しかし、システムをさらに最適化するために、より多くの作業を行うことができます:
- フレーム抽出戦略を最適化する。よりビデオを代表するフレームを抽出する。
- ビデオの類似性に対するビデオの持続時間の影響を最小化する。
- ビデオの類似度の加重平均を計算する際に、より正確な結果を得るために、より長い時間のビデオに重みを加える。
より多くのリソースをお探しですか?
- より多くの産業におけるベクトル類似検索の応用:
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション](image-based-trademark-similarity-search-system)
- ベクトル類似検索であなたのワードローブを持続可能にする方法](vector-similarity-search-and-fashion)


