




近接グラフに基づく近似最近傍探索
シリーズ全体を読む
- 画像ベースの商標類似検索システム:知的財産権保護のよりスマートなソリューション
- HM-ANN 効率的なヘテロジニアスメモリ上の10億点最近傍探索
- ベクトル類似度検索でワードローブを持続可能にする方法
- 近接グラフに基づく近似最近傍探索
- 画像類似性検索でオンラインショッピングをよりインテリジェントにするには?
- グラフィカル・デザイナーのための知的類似性検索システム
- ベクトル類似性検索にフィルタリングをベストフィットさせるには?
- ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
- 最先端の埋め込みを用いたコンピュータビジョンにおける意味的類似性検索の強化
- プロダクションにおける超高速意味的類似性検索
- ベクトル・インデックスによるビッグデータ上の類似検索の高速化(後編)
- ニューラルネットワークの埋め込みを理解する
- 機械学習をアプリケーション開発者により身近なものに
- ベクターデータベースによる対話型AIチャットボットの構築
- 2024年のプレイブックベクトル検索のトップユースケース
- ベクター・データベースの活用による競合他社のインテリジェンス強化
- ベクターデータベースでIoT分析とデバイスデータに革命を起こす
- 推薦システムとベクターデータベース技術の利用について知っておくべきすべて
- ベクターデータベースでスケーラブルなAIを構築する:2024年の戦略
- アプリの機能強化:ベクターデータベースによる検索の最適化
- リスクと不正分析のための金融におけるベクトル・データベースの応用
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
- PDFをインサイトに変換:Zilliz Cloud Pipelinesによるベクトル化と取り込み
- データの保護ベクターデータベースシステムにおけるセキュリティとプライバシー
- ベクターデータベースを既存のITインフラと統合する
- 医療を変える:患者ケアにおけるベクター・データベースの役割
- ベクターデータベースによるパーソナライズされたユーザー体験の創造
- 予測分析におけるベクトル・データベースの役割
- ベクターデータベースでコンテンツ発見の可能性を引き出す
- ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
- Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
- ベクターデータベースによる顧客体験の向上:戦略的アプローチ
ANNSとは?
ANNSは近似最近傍探索の略で、画像類似検索システム、QAチャットボット、レコメンダーシステム、テキスト検索エンジン、情報検索システムなど、様々なアプリケーションを支える基盤となっている。ANNSは、データセットのサイズが大きくなっているにもかかわらず、与えられたクエリに最も近いk個の近傍探索を瞬時に行うために、適切に設計されたインデックスを使用する。ANNSのインデックスは、クエリとデータセット内の各ベクトル間の距離を計算する手間を省くのに役立ち、最終的には、検索効率を大幅に改善するために検索精度をわずかに犠牲にすることで、精度と検索レイテンシのトレードオフを実現している。[1]
採用されているインデックスによって、既存のANNSアルゴリズムは大きく4つのタイプに分けられる:
- ハッシュベース
- ツリーベース
- 量子化ベース
- 近接グラフ(PG)ベース
最近、PGベースのANNSアルゴリズムが、非常に効果的であるとして台頭してきた。これらのPGベースのアルゴリズムのおかげで、データセット中のより多くのベクトルを比較・評価することなく、より正確な結果を得ることができる。
PG-based ANNSはどのように機能するのか?
PGベースのANNSはデータセットS上のインデックスとして最近傍グラフG = (V,E)を構築する。Vは頂点集合、Eは辺集合を表す。V内の任意の頂点vはS内のベクトルを表し、E内の任意の辺e**は連結された頂点間の近傍関係を記述する。与えられたクエリの最近傍を探すプロセスは「適切なルーティング戦略」によって実行され、エントリから結果頂点までのルーティング経路を決定する。このように、build PGとrouting on PGに従って、PGベースのANNSを説明することができます。
図1:PGインデックス(KNNG, k=2)の構築](https://assets.zilliz.com/image_upimage_upload_load_0_dc10d55b7e.jpeg)
PGの構築
距離関数d(,)が与えられた時、PGを構築する1つの簡単な方法は、すべての頂点をデータセットS中のk個の最近傍にリンクすることである。このプロセスにより、厳密なk 最近傍グラフ(KNNG)が生成・構築される。KNNGでは、頂点はデータセットSの点に対応し、隣接する頂点(x, yと記される)は、それらの距離d(x, y)を評価することによって辺と関連付けられる。図1(b)では、黒い頂点に接続された2つの頂点(番号1,2)がその近傍(k=2)であり、黒い頂点はこれらの辺に沿ってその近傍を訪れることができる(矢印は黒い頂点からその近傍を指している)。構築過程が複雑になりすぎないように、厳密なKNNGよりも早く構築できる近似KNNGを考えることもできる。
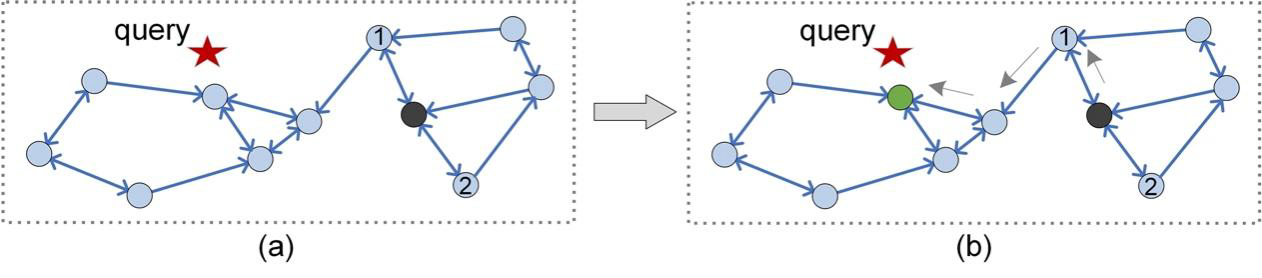 図2: PGインデックス(KNNG, k=2)のルーティング手順
図2: PGインデックス(KNNG, k=2)のルーティング手順
PG上のルーティング
図2に示すように、PGとクエリq(赤い星印)が与えられたとき、PGベースのANNSはルーティングによってqに近い頂点の集合を得ることを目的とする。ルーティングがどのように機能するかを示すために、qの最近傍を返す場合を例にとる。最初に、結果頂点rとしてシード頂点(ランダムにサンプリングするか、tree[16]などの追加インデックスで得られる黒頂点)を選択し、このシード頂点からルーティングを行えばよい。具体的には、d(n, q) < d(r, q)、ここでnがrの近傍の1つである場合、rはnに置き換えられる。終了条件が満たされるまで(例えば、任意のnに対して、d(n, q)≧d(r, q))この処理を繰り返し、最終的なr(緑の頂点)はqの最近傍となる。
PGベースのANNSを改善するには?
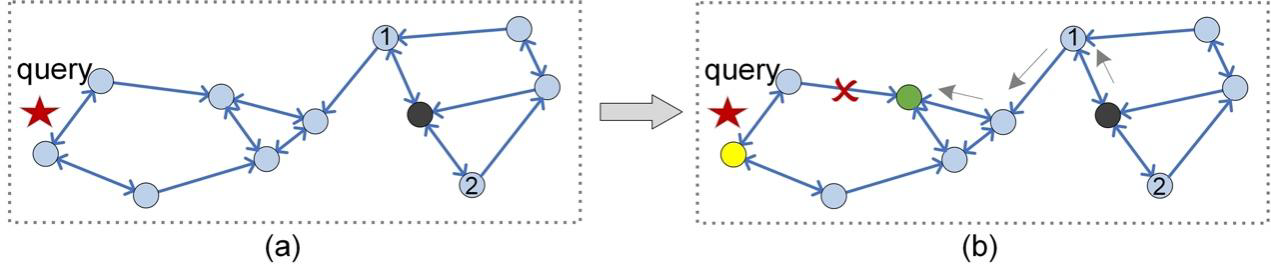 図3: 黒い頂点から出発するルーティングは黄色い頂点に到達できない
図3: 黒い頂点から出発するルーティングは黄色い頂点に到達できない
図2(b)で、黒い頂点からのルーティングでは他のすべての頂点にアクセスできないことにお気づきだろうか。したがって、PGインデックス(KNNG, k=2)はKGraph [2]よりも接続性が悪いと主張する。このことは、クエリqがルーティングで到達できない領域に位置する場合、想起率で測定される検索精度に影響する。例えば、図3のクエリqの場合、やはり黒い頂点からルーティングを行い、緑の頂点でルーティングが終了します。しかし、qの最近傍は緑の頂点ではなく、黄色の頂点である。残念ながら、緑の頂点と黄色の頂点の間には経路がない(辺は有向)ので、不正確な結果が得られる。
従って、我々は以下の2つの観点からPGベースのANNSアルゴリズムの性能を向上させることができる。
PGインデックスの最適化
上記の問題を解決するために、KNNGの有向辺をすべて無向辺(つまり二重 矢印)に変えるという簡単な方法がある(NSW [3], DPG [4])。図4(a)が示すように、リンクされた頂点間にはパスが存在する。従って、図3と同じクエリの場合、緑の頂点を訪れると、その近傍(図4(b)の番号9)に沿って経路を進み、最終的に黄色の頂点で終了することができる。しかし、各有向辺に逆辺を追加すると、頂点の近傍に余分な辺(例えば、図4(a)の頂点1, 6)が追加されることになり、インデックスサイズが大きくなり、探索効率が低下するという2つの問題が発生する。より多くの近傍関係(図3では22近傍、図4では28近傍)を保存しなければならないため、インデックスサイズが非常に大きくなることは容易に理解できる。探索効率の低さについては、頂点3から頂点7への経路探索の例(図3(b)と図4(b)の比較)を用いて説明できる。KNNG(k=2、図3(b))では、クエリqから評価する頂点の数で表される距離が6回計算される(すなわち、図4の1, 2, 3, 6, 7, 8と番号付けされた頂点)。一方、図4(b)では、距離は8回計算される(すなわち、1-8と番号付けされた頂点)。このように、余分な計算が探索効率を悪くしている。
図4:修正KNNGインデックスにおけるルーティング手順(逆辺の追加)](https://assets.zilliz.com/4_2848784016.png)
最適化のもう一つの類似のアプローチは、kを増やすことである。例えば、図5ではk=3である。クエリqの本当の最近傍(黄色の頂点)に到達することはできるが、このアプローチでは逆リンクに参加するのと同じ問題が生じる(図4)。
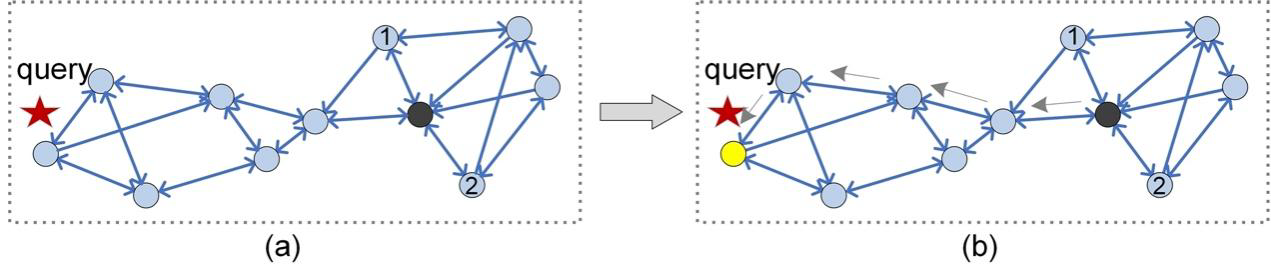 図5: KNNGインデックス(k=3)のルーティング手順
図5: KNNGインデックス(k=3)のルーティング手順
さて、以上の最適化は、正確な検索結果を得るために新たな問題をもたらすことがわかった。効率、精度、インデックスサイズを同時に解決できるPGインデックスは存在するのだろうか?いくつかの最先端のPGベースのANNSアルゴリズムを分析した結果、相対近傍グラフ(RNG)と呼ばれる種類のPGが広く使われていることがわかった。
図6:おもちゃのデータセット上での相対近傍グラフ(RNG)の構築](https://assets.zilliz.com/6_85405bdabb.png)
RNGの構築プロセスを紹介する前に、まずlune(,)の概念を定義する。図6(b)に示すように、頂点8と6に注目すると、lune(8, 6)(赤いルーン)は、対応する2つの頂点(すなわち、8, 6と番号付けされた頂点)を中心とし、距離(すなわち、d(8, 6))を半径とする2つの円の交点によって形成される[5]。
データセットSが与えられたとき、任意の2つの頂点(x, yと記されている)に対して、RNGにおいてその2つが連結しているかどうかを以下のルールで判定する。なお、任意の頂点xについて、xと他の頂点(例えばy)との間の以下のルールを距離値の昇順に判定するものとする。
- ルール1:S内の任意の頂点z(≠x,y)に対して、zがlune(x,y)内にない場合、xとy**を双方向辺で結ぶ。
- ルール2: lune(x,y)内の任意の頂点z (≠x,y)について、x (またはy)からzへの有向辺がない場合、x (またはy)とy (またはx)を有向辺で結ぶ。
図6(b)のRNGは(S内の任意の2頂点に対して)規則1と規則2に従って構築される。例えば、lune(8, 6)(赤いルーン)には他に頂点がないので、頂点8と6は双方向辺(別名、無向辺)で結ばれている。一方、頂点6と1については、lune(6, 1)(緑のルーン)に頂点3が存在し、この頂点は頂点6と1の両方と有向辺で結ばれている(すなわち、6→3と1→3)、したがって6(または1)と1(または6)は結ばれない。
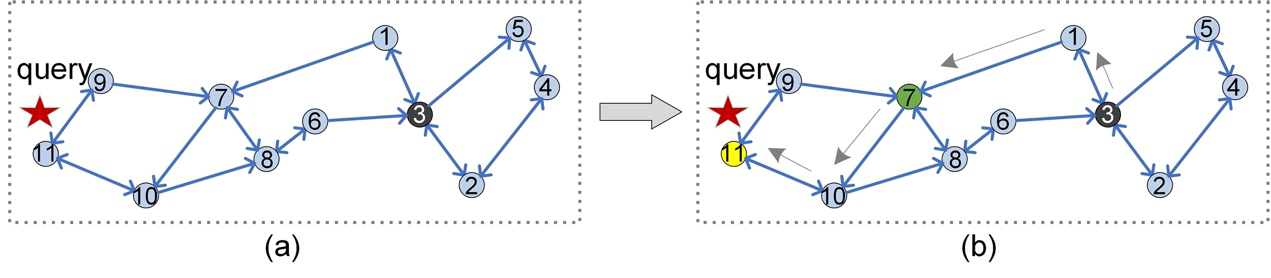 図7: 相対近傍グラフ(RNG)上のルーティング手順
図7: 相対近傍グラフ(RNG)上のルーティング手順
図7(b)に示すように、図3(b)と同じクエリqに対して、RNG上のルーティングは正確な検索結果(黄色の頂点)を得ることができる。また、図4(b)や図5(b)と比較して、図7(b)はインデックスサイズが小さく、検索効率が高いことがわかる。例えば、図7(b)は22近傍を記憶するだけでよく(図3では22近傍、図4では28近傍、図5では33近傍)、頂点3から頂点7へのルーティングでは、距離計算の回数は5回である(図3(b)では6回、図4(b)では8回、図5(b)では7回)。
従って、ほとんど全ての最新のPGベースのANNSアルゴリズム(例えば、HNSW[6]、NSG[5])は、RNGの近似を追加する。とはいえ、RNGは完全ではなく(インデックス構築の複雑性が高いなど)、実用上のニーズをさらに満たすためには、まだ改良が必要である。
検索最適化
上記の最適化されたPGは、探索において同じルーティング戦略を共有していることに気づくだろう。実際、HNSW[6]やNSG[5]のようないくつかの現在のPGベースのANNSアルゴリズ ムは、ルーティングプロセス全体を通して、そのルーティング戦略として、素直で貪欲な探索 を採用している。貪欲探索は実装が簡単であるが、ルーティング効率が低いという制限に直面する。この限界を図7(b)に示す。貪欲探索を用いてPG上でルーティングを行う場合、訪問する各頂点の近傍は完全に探索される。つまり、ルーティング経路(矢印で示す)上の各頂点の全ての近傍からクエリまでの距離を計算するため、どうしても時間がかかってしまう。例えば、頂点3にアクセスする場合、d(2, q)とd(5, q)を評価する必要はない。
図8: 同じPG上で与えられたクエリに対する異なるルーティング戦略での距離計算の回数(緑色の頂点の数)](https://assets.zilliz.com/8_b05eea708a.png)
この問題を解決するために、"Hierarchical clustering-based graphs for large scale approximate nearest neighbor search" では、guided searchと呼ばれる最適化されたルーティング戦略が提案されている。[8].ガイド付き探索では、クエリと同じ方向の近傍探索のみが行われる。そのため、ルーティングは大幅に高速化される。図8は、貪欲探索とガイド付き探索という2つの異なるルーティング戦略において、距離が何回計算されるかを比較したものである。クエリq(赤い星)とシード頂点(番号3)が与えられたとき、貪欲探索はルーティング中に9つの頂点(図8(a)ではすべて緑の頂点)を訪問するが、ガイド付き探索は5つの頂点(図8(b)ではすべて緑の頂点)しか訪問しない。ガイド付き探索は、qが位置する垂直点線の側にある訪問頂点の近傍のみに注目する。
しかし、"近接グラフ上の最適化されたガイド付き探索と貪欲アルゴリズムによる2段階ルーティング "で指摘されているように、ガイド付き探索にはまだいくつかの限界がある。[7].最近、最適化に対する機械学習ベースのアプローチがいくつか提案されており[9, 10]、これらのアプローチは一般に、より多くの時間とメモリ消費を代償として、効率と精度の間のより良いトレードオフを得ることができる[1]。
パフォーマンス
PGベースのANNSアルゴリズムと他の方法(例えばPQ)の比較については、"Benchmarking nearest neighbors"[11] を参照してください。異なるPGベースのANNSアルゴリズムの性能については、"A Comprehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search" [1]を参照のこと。[1]を参照のこと。
今後の展望
ほとんど全ての最新アルゴリズムはRNG(例えばHNSWやNSG)に基づいていることは注目に値する。RNGに基づく最適化は、PGに基づくANNSの有望な研究方向である。コアとなるアルゴリズムに基づき、研究者はハードウェアを介し てPGベースのANNSアルゴリズムの性能を改良、改善している[14]。他の文献では、データの増加に対処するために、定量的なスキームやディスクベースのスキームを追加している[15]。ハイブリッドクエリ(ラベル制約を満たすベクトルのみを検索する)の要件を満たすために、最新の研究では、PGベースANNSアルゴリズムの検索プロセスに構造化ラベル制約を追加している[12, 13]。
参考文献
[^2]董W, Moses C, 李K.汎用の類似性尺度に対する効率的なk-最近傍グラフの構築[C].第20回ワールドワイドウェブ(WWW)国際会議論文集.2011:577-586.
また、このようなグラフは、類似性尺度のための効率的なk-最近傍グラフの構築[C]、第20回ワールド・ワイド・ウェブ(WWW)国際会議[WWW]予稿集[C]、2011: 577-577.Information Systems (IS), 2014, 45(SEP.):61-68.
[高次元データにおける近似最近傍探索-実験・分析・改善[J].IEEE Transactions on Knowledge and Data Engineering (TKDE), 2019, 32(8):1475-1488.
[^5]福C、翔C、王C、他、ナビゲート拡散グラフによる高速近似最近傍探索[J].Proceedings of the VLDB Endowment, 2019, 12(5):461-474.
[^6] Malkov YA, Yashunin DA.階層的航行可能スモールワールドグラフを用いた効率的でロバストな近似最近傍探索[J].IEEE transactions on pattern analysis and machine intelligence (TPAMI).2018, 42(4):824-836.
[^7]Xu、Wang M、Wang Y、ら.最適化されたガイド付き探索と近接グラフ上の貪欲アルゴリズムによる二段階ルーティング[J]。知識ベースシステム.2021, 229: 107305.
[このようなグラフを利用することで、大規模な近似最近傍探索が可能となる。Pattern Recognition (PR).2019, 96: 106970.
[^9] Li C, Zhang M, Andersen DG, et al. Improving approximate nearest neighbor search through learned adaptive early termination[C].データ管理に関する国際会議(SIGMOD)の議事録。2020: 2539-2554.
このような問題意識は、「学習された適応的早期終了による近似最近傍探索の改善」[C] と呼ばれ、その学習された適応的早期終了は、「学習された適応的早期終了による近似最近傍探索の改善」[C] と呼ばれる。International Conference on Machine Learning (ICML).2019: 475-484.
[^11] 最近傍のベンチマーク[EB/OL].[2021-12-12]. https://github.com/erikbern/ann-benchmarks.
[^12]WangJ、Yi X、Guo R、et al. Milvus: A Purpose-Built Vector Data Management System[C].データ管理に関する国際会議(SIGMOD)予稿集.2021: 2614-2627.
[^13] オープンソースのベクトル類似検索エンジン[EB/OL].[2021-06-12] https://milvus.io/scenarios.
[SONG: GPU上での近似最近傍探索.IEEE 36th International Conference on Data Engineering (ICDE).2020: 1033-1044.
[DiskANN: Fast accurate billion-point nearest neighbor search on a single node[C].Advances in Neural Information Processing Systems (NeurIPS).2019, 13771-13781.
[^16] 岩崎正樹. 近接探索のための刈り込み二方向k-最近傍グラフ[C].類似検索と応用に関する国際会議.2016: 20-33.
著者について
Mengzhao Wang杭州甸子大学コンピュータサイエンス修士課程修了。主な研究テーマは近接グラフベースのベクトル類似性検索とマルチモーダル検索。関連分野で3件の特許を取得。VLDB](https://vldb.org/2021/index.php)カンファレンスと人工知能分野の国際的かつ学際的な査読付き学術雑誌であるKBSで2本の論文を発表。
余暇はギターと卓球。また、ランニングと読書も好きである。GitHub](https://github.com/whenever5225)で彼をフォローできる。

読み続けて

ベクトル類似性検索によるインテリジェントなビデオ重複排除システムの構築
Milvusベクターデータベースを使用して、アーカイブストレージから重複するビデオコンテンツを特定し、フィルタリングする自動化ソリューションを構築する方法をご紹介します。

ベクターデータベースを活用した次世代Eコマース・パーソナライゼーション
ベクトル埋め込みとベクトルデータベースの概念と、eコマースにおけるユーザーエクスペリエンスの向上におけるその役割を探る。

Zilliz Cloudでベクトルを使ったテキスト類似検索をマスターする
我々は、ベクトル埋込みの基礎を探求し、Zilliz CloudとOpenAIの埋込みモデルを用いて、実用的な書名検索への応用を実証した。