




Advancing LLMs: Exploring Native, Advanced, and Modular RAG Approaches
Imagine relying on textbooks written years ago to answer today’s pressing questions. While you might explain established concepts or historical events, you would struggle to provide accurate information on recent developments. This challenge parallels the limitations of Large Language Models (LLMs), which rely on static training data that quickly becomes outdated. Retrieval-Augmented Generation (RAG), explored in the paper Retrieval-Augmented Generation for Large Language Models: A Survey, addresses these limitations by integrating external knowledge sources into the generation process.
Unlike traditional LLMs, which rely solely on knowledge encoded in their neural network parameters, RAG systems retrieve relevant information dynamically to enhance their responses. This capability makes RAG useful for knowledge-intensive tasks such as legal research, medical diagnosis, and real-time technical support.
In this article, we will explore the key components of RAG, its evolution, technical implementation, integration with vector databases, evaluation methods, and potential for real-world applications.
The Architecture and Process of RAG
RAG, or retrieval augmented generation, introduces a process that enhances the capabilities of LLMs by retrieving and incorporating external knowledge during response generation. This process can be divided into three main stages: indexing, retrieval, and generation, as shown in the image below:
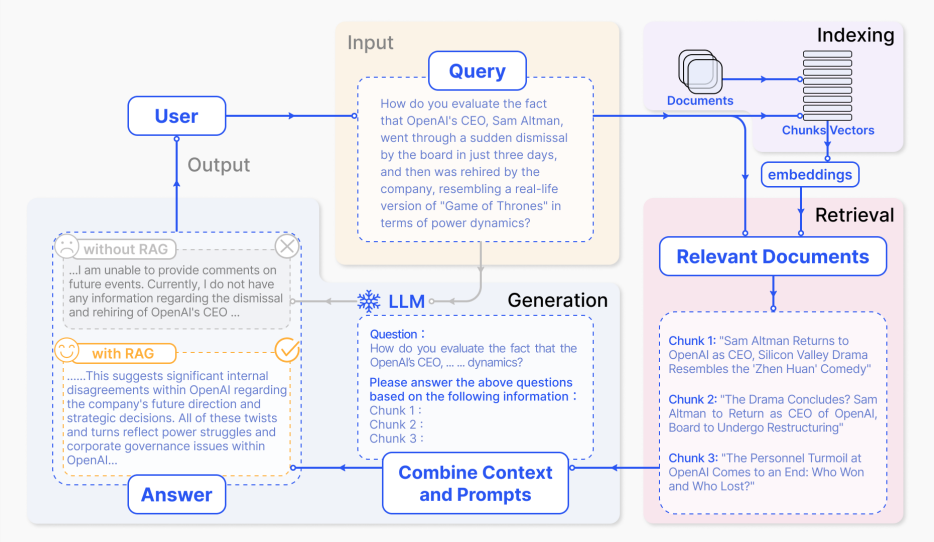 Figure: Representative instance of the RAG process applied to question answering
Figure: Representative instance of the RAG process applied to question answering
Figure: Representative instance of the RAG process applied to question answering.
Let's explore what happens in each key stage of RAG.
Key Stages of RAG
Indexing Phase: Documents are segmented into manageable chunks, which are then encoded into numerical vectors, capturing their semantic meaning. These vectors are stored in a vector database such as Milvus optimized for efficient similarity searches.
Retrieval Phase: The system processes the user’s query by converting it into a vector, numerical representation of data, and searching for semantically similar chunks in the vector database. This ensures that the most relevant information is retrieved, even when exact words differ.
Generation Phase: The retrieved information is combined with the query to form an improved query with context, and then the LLM generates a coherent and contextually accurate response. This integration helps reduce errors and improves the factual reliability of the output.
By incorporating these steps, RAG systems enable LLMs to handle complex, knowledge-intensive tasks that traditional models struggle with, such as answering questions about recent events or specialized domains. Understanding these stages provides the foundation for exploring how RAG systems have evolved through various paradigms.
RAG Evolution Through Three Paradigms
The development of RAG has progressed through three paradigms, each addressing specific challenges while building on earlier advancements: Naive RAG, Advanced RAG, and Modular RAG as shown in the image below.
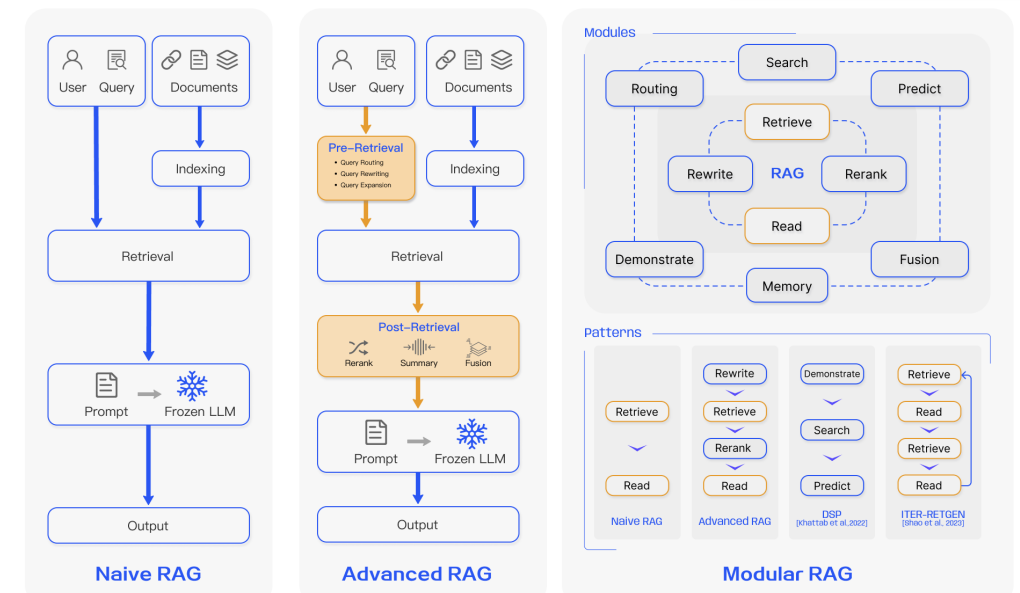 Figure: Naive RAG vs Advanced RAG vs Modular RAG
Figure: Naive RAG vs Advanced RAG vs Modular RAG
Figure: Naive RAG vs Advanced RAG vs Modular RAG
Naive RAG: Foundational Beginnings
Naive RAG established the groundwork for retrieval-augmented systems by combining document retrieval with language model generation. This paradigm follows a simple pipeline: documents are indexed and segmented into chunks, relevant chunks are retrieved based on similarity scores within a vector database, and the retrieved information is synthesized with the user query for the LLM to produce an answer. This approach introduced the foundational Retrieve-Read framework, which, while groundbreaking at the time, demonstrated several limitations.
A key challenge in Naive RAG lies in the accuracy of retrieval. The system often retrieves irrelevant chunks or fails to capture crucial context, resulting in incomplete or noisy outputs. Additionally, the generation phase can suffer from hallucinations, where the model fabricates information not supported by the retrieved content. Furthermore, redundancy in the retrieved documents can dilute the relevance of the response. Despite these issues, Naive RAG laid the foundation for more advanced paradigms by demonstrating the benefits of combining retrieval and generation.
Advanced RAG: Bridging the Gaps
Advanced RAG addresses several limitations of Naive RAG by introducing optimizations in both the pre-retrieval and post-retrieval phases. In the pre-retrieval phase, query optimization techniques, such as query expansion and rewriting, are used to improve retrieval accuracy. For instance, a user query like “What are the latest developments in quantum computing?” might be expanded to include related technical terms and synonyms, ensuring that the retrieval captures a broader range of relevant documents.
In the post-retrieval phase, Advanced RAG incorporates reranking algorithms to refine the set of retrieved documents. These algorithms evaluate the semantic similarity, document authority, and relevance of each chunk, prioritizing the most useful information. For example, when answering a medical query, the system might rank recent peer-reviewed studies higher than older or less authoritative sources. This refinement process significantly improves the quality of the retrieved context, enabling the generation phase to produce more accurate and coherent responses.
Advanced RAG also benefits from more sophisticated integration of retrieved content. By strategically managing the relationship between retrieval and generation, it reduces the likelihood of hallucination and ensures that the generated answers are firmly grounded in the retrieved evidence.
Modular RAG: A Flexible and Adaptive Framework
The most recent evolution, Modular RAG, introduces a flexible framework designed to handle a wide range of tasks and contexts. Unlike the fixed pipeline approach of its predecessors, Modular RAG employs specialized modules that can be dynamically reconfigured based on the requirements of the query. These modules include:
Search Module: Extends retrieval capabilities to diverse data sources, such as knowledge graphs, structured databases, and traditional search engines. For example, when querying corporate financials, the system might retrieve data from financial statements, regulatory filings, and news articles.
Memory Module: Retains and manages a growing pool of contextual knowledge throughout multi-turn interactions. This module ensures that the system builds on prior queries and maintains a consistent context across interactions.
Routing Module: Acts as a decision-making layer, dynamically determining whether a query requires retrieval, summarization, or a combination of approaches.
Fusion Module: The Fusion module addresses limitations in traditional search strategies by employing multi-query techniques. It expands user queries into diverse perspectives, using parallel vector searches and intelligent re-ranking to uncover a broader range of knowledge. For example, a query about climate change might retrieve documents covering scientific research, policy discussions, and real-world impacts, synthesizing them into a unified response.
Predict Module: Designed to reduce redundancy and noise in retrieved results; the Predict module uses the LLM to generate context directly. This ensures that only relevant information is included in the response, streamlining the retrieval process and improving the overall quality of generated answers.
Demonstrate Module: The Demonstrate module plays a crucial role in refining responses by incorporating examples or step-by-step explanations. This is particularly valuable in educational or technical support contexts, where users benefit from detailed demonstrations of processes or concepts.
One of the key innovations in Modular RAG is its support for advanced retrieval augmentation techniques. These include iterative, recursive, and adaptive retrieval.
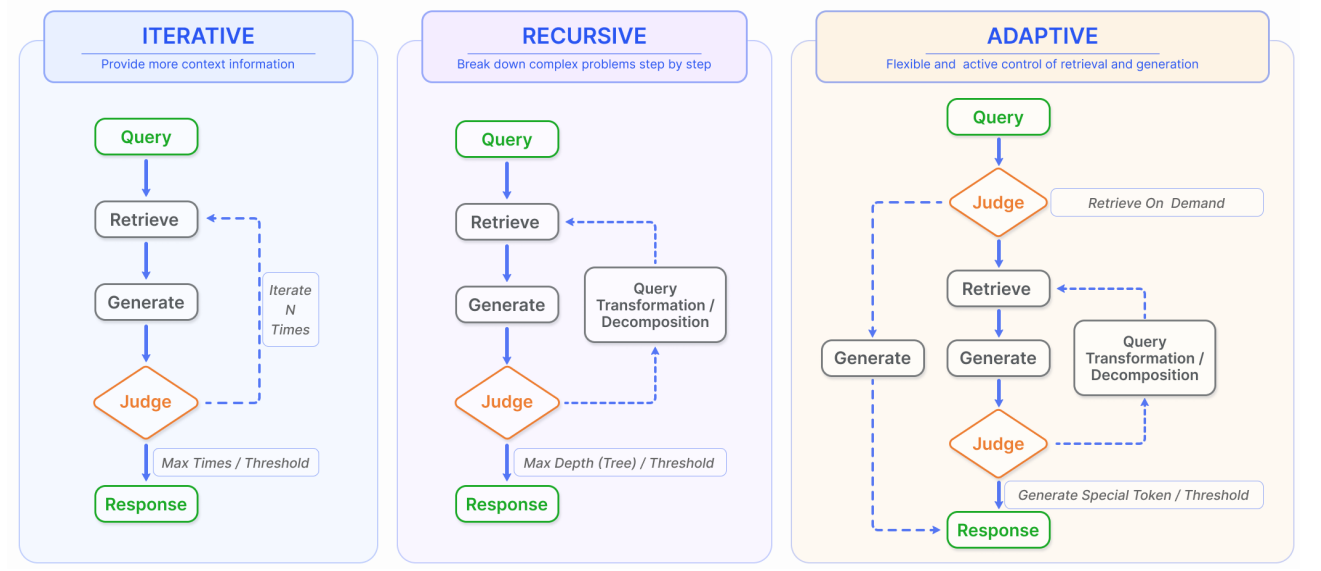 Figure: Types of advanced retrieval augmentation processes: Iterative, recursive, and adaptive retrieval
Figure: Types of advanced retrieval augmentation processes: Iterative, recursive, and adaptive retrieval
Figure: Types of advanced retrieval augmentation processes: Iterative, recursive, and adaptive retrieval.
Iterative Retrieval: Allows multiple rounds of retrieval and generation, refining the context with each iteration. For example, a complex query about climate change impacts might begin with a general overview, followed by more targeted retrievals addressing specific regions or mitigation strategies.
Recursive Retrieval: This breaks down multifaceted queries into smaller, manageable components. When answering a question about the economic impacts of historical events, the system might first retrieve information about the events themselves, followed by retrievals focused on their economic consequences.
Adaptive Retrieval: Introduces dynamic control over the retrieval process. The system evaluates the complexity and requirements of the query, deciding when and how to retrieve additional information. This flexibility ensures efficient use of computational resources while maintaining response quality.
The modular design of this paradigm also supports hybrid approaches, such as combining retrieval and summarization within the same query, or selectively choosing which components to activate based on task requirements. This adaptability makes Modular RAG particularly well-suited for complex, knowledge-intensive applications.
Implementation and Technical Framework
The implementation of RAG includes a series of technical components that ensure its effectiveness and scalability in practical scenarios.
Document Processing and Embedding
The first step in RAG is to process and encode documents into vector representations. These vectors capture the semantic meaning of text and are stored in a database for efficient retrieval. Modern systems often use hybrid approaches that combine Dense Embeddings, for capturing semantic relationships and Sparse Embeddings for lexical precision.
Here’s an example of a document processing pipeline:
```
class DocumentProcessor:
def __init__(self):
self.chunker = SemanticChunker(
chunk_size=512,
overlap=50,
respect_boundaries=True
)
self.embedder = DualEmbedder(
dense_model='sentence-transformers/all-mpnet-base-v2',
sparse_model='bm25'
)
def process_document(self, document):
chunks = self.chunker.split_document(document)
embeddings = self.embedder.encode_chunks(chunks)
return chunks, embeddings
```
This process ensures that each document is encoded into a vector format that can be stored in a vector database for efficient retrieval. The combination of semantic and lexical features improves the system’s ability to understand and retrieve contextually relevant information.
Retrieval and Generation
The retrieval phase uses approximate nearest neighbor (ANN) search algorithms to identify relevant chunks efficiently. The generation phase combines retrieved content with the query using structured prompts to guide the language model’s response. For example:
def create_generation_prompt(query, contexts):
prompt = f"""
Question: {query}
Retrieved Information:
{format_contexts(contexts)}
Answer:"""
return prompt
This structured input ensures that the language model has all the necessary context to generate an informative response.
Evaluation Framework and Quality Metrics
Evaluating RAG systems requires a multi-dimensional approach that considers both the retrieval and generation components. A comprehensive evaluation framework ensures that these systems not only provide accurate information but also do so efficiently and reliably. Below are the core metrics used to evaluate RAG systems:
Context Relevance: This metric measures how well the retrieved documents align with the user query. High relevance indicates that the system has successfully retrieved information directly applicable to the question or task. For example, when a user queries “What are the recent advances in renewable energy?” context relevance would ensure the retrieval of documents specifically addressing innovations in solar, wind, or battery technologies, rather than unrelated environmental topics.
Answer Faithfulness: Faithfulness evaluates whether the generated response accurately reflects the retrieved content. The system must avoid introducing inaccuracies or unsupported claims while synthesizing the retrieved information into a coherent response. For instance, if a retrieved document states that solar panel efficiency will improve by 20% in 2024, the generated answer should not generalize this improvement to all renewable energy technologies.
Efficiency and Latency: These metrics assess the system’s ability to deliver responses quickly while maintaining computational efficiency. Low latency is critical for user-facing applications such as chatbots or customer support systems. Modern RAG systems often rely on optimized vector searches and hardware acceleration to achieve fast retrieval and response times.
Scalability: Scalability measures the system's ability to maintain performance when handling large-scale data. This includes the capacity to manage billions of document embeddings while ensuring accurate retrieval and efficient query processing.
In addition to these metrics, there are specialized evaluation frameworks that offer structured methods for assessing RAG systems across diverse dimensions:
Retrieval Generation Benchmark (RGB):
Retrieval Generation Benchmark (RGB) evaluates both the retrieval and generation of RAG systems. It emphasizes noise robustness, ensuring the system can operate effectively even when the retrieved data contains ambiguities or inconsistencies. It also measures negative rejection, the system’s ability to avoid generating answers when reliable information is unavailable. Other criteria include counterfactual robustness and the integration of retrieved information into coherent responses. RGB uses benchmarks such as cosine similarity and normalized discounted cumulative gain (NDCG) to assess retrieval accuracy and output quality.
RECALL (Reappearance Rate Evaluation):
RECALL focuses on the fidelity of retrieved knowledge in the generated response. The R-Rate metric measures how frequently critical information from retrieved documents reappears accurately in the final output. This framework highlights whether the retrieval phase effectively supports the generation process. For example, in a question-answering task, RECALL ensures that a RAG system accurately incorporates all relevant points from retrieved documents into the generated answer.
CRUD (Creative Generation, Robustness, Understanding, and Domain-Specific Tasks)
The CRUD framework extends evaluation to a broader range of capabilities. It tests creative generation by assessing how effectively the system synthesizes new insights from retrieved information. Robustness measures the system’s performance under challenging conditions, such as noisy or incomplete queries. Understanding focuses on the system’s ability to interpret and respond to complex queries accurately. Domain-specific tasks evaluate the system’s effectiveness in specialized areas like legal research or financial analysis, ensuring applicability across diverse industries.
By systematically evaluating these metrics, we can identify areas for improvement, refine system designs, and ensure that RAG systems meet the needs of real-world applications. But keep in mind that the effectiveness of these evaluation metrics often hinges on the underlying retrieval infrastructure, where vector databases play a crucial role in ensuring speed and accuracy.
RAG and Vector Databases: A Powerful Synergy
Vector databases play a crucial role in the operation of RAG systems, providing the infrastructure required for storing and retrieving high-dimensional embeddings of contextual information needed for LLMs. These embeddings capture the semantic and contextual meaning of unstructured data, enabling precise similarity searches that underpin the effectiveness of retrieval-augmented generation.
Milvus is an open-source vector database, which is capable of handling billion-scale vector data with ultra-low latency. Its capabilities align closely with the needs of RAG systems, making it an ideal choice for developers building RAG systems.
Scalability: Milvus is designed to manage billions of embeddings, making it suitable for enterprise-scale applications like e-commerce recommendation systems or global customer support networks.
Advanced Indexing: Milvus supports over 10 indexing techniques, including IVF and HNSW, allowing developers to choose the most appropriate method based on their performance and latency requirements.
Hybrid Search: By combining dense and sparse embeddings, Milvus ensures that retrieved results are both semantically and lexically accurate, improving the overall relevance of the system’s responses.
Seamless Integration: Milvus integrates easily with popular frameworks like LangChain and LlamaIndex, streamlining the development of complex RAG pipelines.
Future Directions for RAG Systems
Several promising research directions have emerged as Retrieval-Augmented Generation (RAG) technology evolves. These advancements aim to enhance retrieval accuracy, improve adaptability, and expand the scope of RAG systems for diverse applications.
Advanced Contextual Adaptive Retrieval
Future RAG systems will employ advanced retrieval strategies that adjust dynamically based on user intent and query complexity. These systems will optimize searches for intricate, multi-layered questions by refining search depth and breadth in real time, enabling more precise results in areas like technical troubleshooting or regulatory compliance.
Iterative Feedback-Driven Systems
RAG systems will integrate feedback loops that allow generation outputs to guide subsequent retrievals. This iterative refinement will improve accuracy, especially for multi-step or ambiguous queries. For example, if an initial response lacks detail, the system will adjust its query to retrieve supplemental information.
Temporal and Context-Aware Retrieval
The next generation of RAG systems will incorporate temporal reasoning, enabling responses that account for changes over time. This will be essential for applications like financial analysis, where understanding trends across quarters or years provides a more comprehensive view than single-instance data.
Cross-lingual and Cultural Adaptability
Future RAG systems will handle multilingual and cross-cultural queries more effectively by using context-driven embeddings that reflect semantic nuances and cultural differences. These systems will enable seamless global applications, such as retrieving and synthesizing knowledge across languages while maintaining accuracy and relevance.
Conclusion
Retrieval-Augmented Generation (RAG) combines the strengths of large language models with retrieval systems, addressing challenges like static knowledge and inaccuracies. By integrating retrieval into generation, RAG systems deliver more accurate and context-aware outputs, making them effective for applications requiring current or specialized knowledge.
Future developments in areas like dynamic retrieval, feedback-driven refinement, and cross-lingual capabilities will enhance their functionality. With tools like Milvus supporting efficient vector database integration, RAG systems are becoming increasingly practical for various industries such as healthcare, customer support, and education.
As research progresses, RAG systems will continue to improve their ability to provide reliable, efficient, and context-sensitive knowledge, enabling broader use in real-world scenarios.
Further Resources
Keep Reading

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.