




Augmented SBERT: A Data Augmentation Method to Enhance Bi-Encoders for Pairwise Sentence Scoring
Introduction
Pairwise sentence scoring is fundamental to various natural language processing (NLP) tasks, including semantic similarity, paraphrase detection, and information retrieval. These tasks power critical applications like search engines, recommendation systems, and chatbots, which use accurate sentence comparisons to understand and respond to user queries. However, existing methods, like cross-encoders and bi-encoders, face significant challenges.
Cross-encoders like BERT (Bidirectional Encoder Representations from Transformers) compare sentences directly for optimal results but are slow and costly for large-scale use. In contrast, Bi-encoders like SBERT (Sentence-BERT) are faster and more scalable due to independent sentence processing, though they struggle with limited data representations.
![]() Comparison of Spearman rank correlation (ρ) between Cross-Encoders and Bi-Encoders on the STSb (English) dataset, showcasing performance across varying training sizes (in thousands)
Comparison of Spearman rank correlation (ρ) between Cross-Encoders and Bi-Encoders on the STSb (English) dataset, showcasing performance across varying training sizes (in thousands)
Figure: Comparison of Spearman rank correlation (ρ) between Cross-Encoders and Bi-Encoders on the STSb (English) dataset, showcasing performance across varying training sizes (in thousands) | Source
Augmented SBERT (AugSBERT) is an extension of SBERT that addresses bi-encoder limitations through data augmentation and generates extra training data. This approach maintains high performance in data-scarce scenarios. AugSBERT employs seed optimization, training multiple models with varied seeds to identify the best one. The selection of sentence pairs is vital; it uses BM25 sampling for efficiently selecting relevant pairs, enhancing performance.
AugSBERT achieves a 1-6% improvement in in-domain accuracy and up to 37-point gains in domain adaptation scenarios. It offers a practical solution for accurate and scalable sentence-scoring tasks.
This blog will discuss the challenges that traditional methods like cross-encoders and bi-encoders face and how augmented SBERT addresses these issues. We will also go over how AugSBERT works, its innovative use of data augmentation, and its ability to enhance bi-encoders' performance. For a detailed understanding, please refer to the following paper.
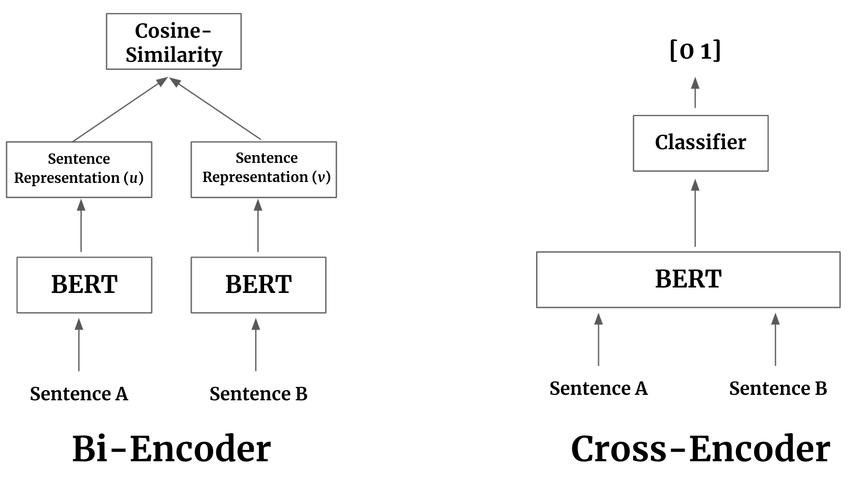
Figure: A cross-encoder (right) takes both sentences as a single input in one BERT inference step and outputs a similarity score. On the other hand, bi-encoders (left) process each sentence independently, outputting sentence vectors | Source
Why is Data Augmentation Critical for AugSBERT?
Data augmentation is at the heart of Augmented SBERT (AugSBERT). It helps generate new sentence pairs by sampling the existing sentence pairs. Data augmentation can resolve SBERT's challenges with small datasets and limited sentence pairs. Here’s why it is essential:
Generating Diverse Sentence Pairs: AugSBERT uses data augmentation to generate diverse sentence pairs. It reuses individual sentences from the existing labeled sentence pairs (gold training set) and recombines them to create new sentence pairs.
Boosts Low-Resource Learning: Augmentation generates synthetic sentence pairs to increase the training data for SBERT fine-tuning. It allows AugSBERT to be fine-tuned into a high-performing sentence transformer even with small datasets, which was previously a limitation.
The Problem with Traditional Sentence Scoring Methods
Traditional sentence-scoring methods laid the foundation for modern techniques. However, they have notable limitations. These drawbacks highlight the need for better approaches, like Augmented SBERT. Below are the key issues with traditional methods:
No Independent Sentence Representations: Cross-encoders like BERT work well on sentence-scoring tasks by encoding both sentences together. However, this doesn’t create independent embeddings for each sentence. It requires a full inference step to get a single pairwise similarity, making it unusable for most use cases.
Inefficiency in Large-Scale Retrieval: Cross-encoders are accurate but cannot generate fixed-sized sentence embeddings. This makes them difficult to use in large-scale retrieval tasks. Poly-encoders also face challenges in indexing, making them less suitable.
Large Data Requirements: Bi-encoders require a large amount of data with sentence pairs for training. Gathering this labeled data can be time-consuming and resource-intensive. Without sufficient data, their performance can suffer.
Asymmetric Scoring: Poly-encoders address some issues with bi-encoders and cross-encoders. However, the score function is asymmetric, limiting its use in tasks needing symmetric similarity.
Augmented SBERT solves these problems. It uses data augmentation and sampling to create high-quality sentence embeddings. It is efficient and works well across different tasks.
Augmented SBERT
Augmented SBERT is a cutting-edge method to improve bi-encoder performance for sentence-pair tasks. It addresses critical limitations in existing models by using data augmentation and semi-supervised learning, making it a robust solution for in-domain and domain adaptation scenarios. This method focuses on sentence-pair tasks, such as semantic textual similarity, question-answer matching, and information retrieval. Augmented techniques tailored to these tasks are used to improve performance.
How is Augmented SBERT Different?
Augmented SBERT (AugSBERT) improves upon SBERT with key changes in data handling, training, and performance. Here’s how they differ:
Reduced Data Requirements: SBERT requires large amounts of high-quality labeled data. AugSBERT reduces this need by using automatically labeled data and smarter techniques.
Data Augmentation: SBERT uses a fixed set of labeled sentence pairs, which can limit its performance, especially with small datasets. AugSBERT applies data augmentation to generate new sentence pairs, expanding the training data.
Cross-Encoder for Sentence Pair Labeling: AugSBERT uses cross-encoders to label new sentence pairs, adding more data for fine-tuning. It combines gold (high-quality) and silver (automatically generated) datasets to improve the model’s performance.
Sentence Pair Sampling: AugSBERT employs smart sampling techniques to select sentence pairs that enhance training quality.
Performance in Different Domains: AugSBERT adapts better to in- and out-of-domain scenarios. Its diverse, augmented dataset helps the model generalize more effectively to new tasks and domains.
How Augmented SBERT Works?
Augmented SBERT generates new sentence pairs through data augmentation. Next, it labels these pairs using a cross-encoder to create a silver dataset. The silver dataset is combined with the gold dataset to fine-tune the bi-encoder (SBERT).
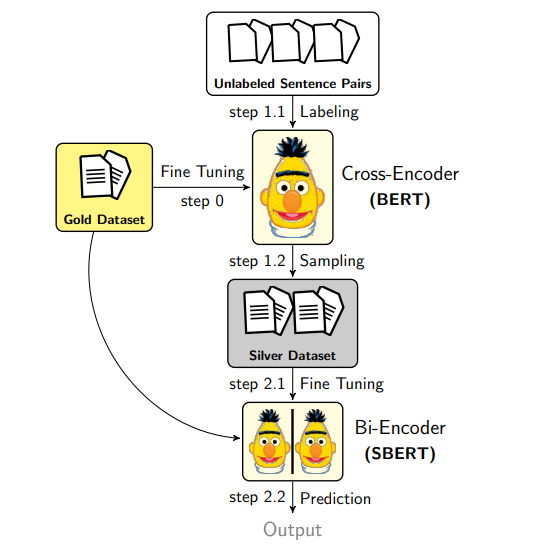 Figure: Augmented SBERT In-domain approach
Figure: Augmented SBERT In-domain approach
Figure: Augmented SBERT In-domain approach | Source
Now, let's break down the specific steps involved in the process:
Step 0: Fine-Tuning the Cross-Encoder
A cross-encoder (BERT) is first fine-tuned on the gold dataset, a collection of high-quality, human-annotated sentence pairs. This fine-tuned cross-encoder is later used to generate weak labels for new unlabeled sentence pairs. Weak labels from cross-encoder support the fine-tuning of the bi-encoder later in the process.
Step 1: Creating the Silver Dataset
Labeling (Step 1.1): Unlabeled sentence pairs are passed through the fine-tuned cross-encoder. The model assigns labels and creates the silver dataset. This dataset is called "silver" because the labels are machine-generated, not human-annotated.
Sampling (Step 1.2): Labeling every possible sentence pair would be too costly and inefficient. To address this, AugSBERT uses sampling strategies to select the most relevant pairs for labeling. Sampling improves efficiency and ensures that labeling is done more effectively. This helps the model perform better without wasting resources on unnecessary combinations. Some sampling methods include Random Sampling, Kernel Density Estimation (KDE), BM25, and Semantic Search. You can learn more about each of these methods in the next section.
Step 2: Training and Prediction
Fine-Tuning the Bi-Encoder (Step 2.1): The silver dataset is combined with the gold dataset to fine-tune the bi-encoder (SBERT). The bi-encoder is trained to map each sentence independently to a dense vector space during this process.
Prediction (Step 2.2): The fine-tuned bi-encoder generates sentence embeddings that can be compared for tasks like similarity scoring.
This pipeline combines precise cross-encoder labeling with bi-encoder efficiency, improving performance across sentence-pair tasks. The architecture diagram captures this process from labeling to final predictions.
Experimental Setup: Data, Sampling, Baseline, and Evaluation
Here is the setup for the experiment, including the dataset used, the sampling approaches, and other key components such as baselines and evaluation methods.
Dataset
The study uses both single-domain (e.g., Quora, AskUbuntu) and multi-domain datasets (e.g., Quora, Sprint, SuperUser). These datasets are designed for sentence-pair tasks, with multi-domain tasks focusing on domain adaptation across specialized communities.
 Figure: Summary of all datasets being used for diverse in-domain sentence pair tasks
Figure: Summary of all datasets being used for diverse in-domain sentence pair tasks
Figure: Summary of all datasets being used for diverse in-domain sentence pair tasks | Source
Sampling
Pair sampling is essential in Augmented SBERT. Choosing the right sentence pairs is not simple and is key to the success of AugSBERT. Labeling all possible sentence pairs would be too expensive and inefficient. To solve this problem, AugSBERT uses sampling strategies to focus on the most relevant pairs for labeling.
Poor sampling can introduce irrelevant pairs, which can hurt the model performance and likely not lead to any improvement.
One key variable in sampling is the top k. The impact of k is minimal in AugSBERT, with the best results typically achieved using k = 3 or k = 5.
Here are some common sampling strategies used in AugSBERT:
Random Sampling (RS): This method randomly selects sentence pairs for labeling. It often results in dissimilar (negative) and few positive pairs. This causes an imbalance in the silver dataset, making it less useful.
Kernel Density Estimation (KDE): KDE aims to balance the label distribution of the silver dataset with the gold dataset. It weakly labels a large set of sentence pairs and then selects pairs to match the distribution of positive and negative labels. The goal is to minimize the differences between the distributions. However, KDE is computationally expensive because it requires labeling many random, discarded samples.
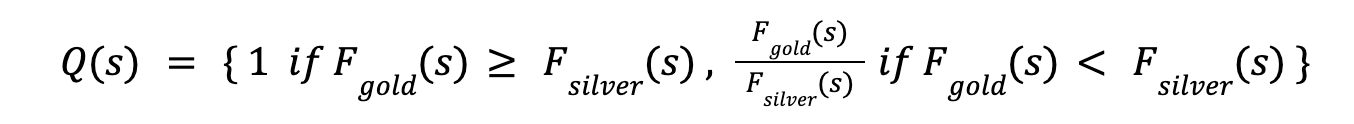
BM25: BM25 is a lexical overlap-based retrieval method that quickly identifies the top k most similar sentences. It creates a strong similarity distribution and works well for the silver dataset.
Semantic Search (SS): This method looks for semantically similar sentences, even if they don’t share many common words. It uses a pre-trained bi-encoder (SBERT) to find the top k most similar sentences based on cosine similarity.
BM25 + Semantic Search: This combines both BM25 and Semantic Search. It captures both lexical and semantic similarities. However, it can introduce too many negative pairs, hurting performance.
Performance in Experiments
Experiments show that BM25 and KDE perform the best. KDE does slightly better in some cases, but BM25 is faster and more efficient. Random Sampling doesn’t work well because it produces too many dissimilar pairs. BM25 + SS performs worse than BM25 alone in some datasets. Overall, BM25 is the best choice for both performance and efficiency.
Seed Optimization for Improved Results: Transformer models like BERT can produce different results depending on the random seed used during training. This variability is more pronounced for small training datasets. To address this, AugSBERT applies seed optimization by training multiple models with different seeds and selecting the one that performs best on the development set.
To save time, only a small portion (20%) of the training steps is completed for all seeds initially. The most promising model is then fully trained. This approach ensures better generalization and improved final performance.
Baseline
AugSBERT was evaluated against several baselines. Jaccard similarity measured the word overlap of the two input sentences for regression tasks. The majority label baseline was used for classification tasks. The Universal Sentence Encoder (USE), a state-of-the-art pre-trained model, was also tested. AugSBERT was further compared to NLPAug’s data augmentation methods. Among these, synonym replacement with a BERT model performed best.
Evaluation
The experiments were carried out to evaluate the performance of AugSBERT across various tasks and configurations. Below is a summary of the models, hyperparameters, and evaluation metrics used.
- Models: The experiments were implemented using PyTorch, Huggingface’s Transformers, and the Sentence-Transformers framework.
English datasets: The bert-base-uncased model was used.
Spanish datasets: The bert-base-multilingual-cased model was used.
All AugSBERT models exhibited computational speeds comparable to SBERT.
- Hyperparameters: Different hyperparameters were tested for cross-encoder fine-tuning, bi-encoder fine-tuning and sampling. Here are the optimal hyperparameters that were used during the experiments.
- Cross-Encoder Fine-Tuning: The following fine-tuning parameters were optimized for the cross-encoder (BERT):
Learning rate: 1 × 10⁻⁵
Hidden-layer sizes: {200, 400}
Batch size: 16
A linear layer with a sigmoid activation was added on top of the [CLS] token to output similarity scores between 0 and 1.
- Bi-Encoder Fine-Tuning: The SBERT bi-encoder was fine-tuned with these hyperparameters:
Batch size: 16
Learning rate: 2 × 10⁻⁵
Optimizer: AdamW
- Sampling Strategy: For BM25 and Semantic Search sampling, various top k values were evaluated in the range {3, 18}. It was found that the choice of k had minimal impact on performance, with the best results achieved using k = 3 or k = 5.
- Evaluation Metrics: Different evaluation metrics were used for different tasks. You can find the details about evaluation metrics below:
In-domain regression tasks (e.g., STS, BWS):
- To evaluate performance, Spearman’s rank correlation (ρ × 100) between predicted and gold similarity scores was used.
In-domain classification tasks (e.g., Quora-QP, MRPC):
- F1 score of the positive label was reported. The optimal threshold was selected based on the development set and applied to the test set.
Domain adaptation tasks:
- AUC(0.05) was used as the evaluation metric. It measures the area under the curve of the true positive rate (TPR) as a function of the false positive rate (FPR), from FPR = 0 to FPR = 0.05. This metric is more robust against false negatives.
- Seed Optimization: The in-domain experiments were repeated with 10 random seeds to ensure reliability. The mean scores and standard deviations were reported for each configuration. Additionally, seed optimization was used to account for variability across runs.
In-Domain and Domain Adaptation Results
The performance of AugSBERT across both in-domain and domain adaptation tasks demonstrates its effectiveness in improving bi-encoder capabilities. AugSBERT offers a practical solution for various NLP tasks by combining the strengths of cross-encoders and bi-encoders. Let’s evaluate the detailed results from both in-domain and domain adaptation experiments.
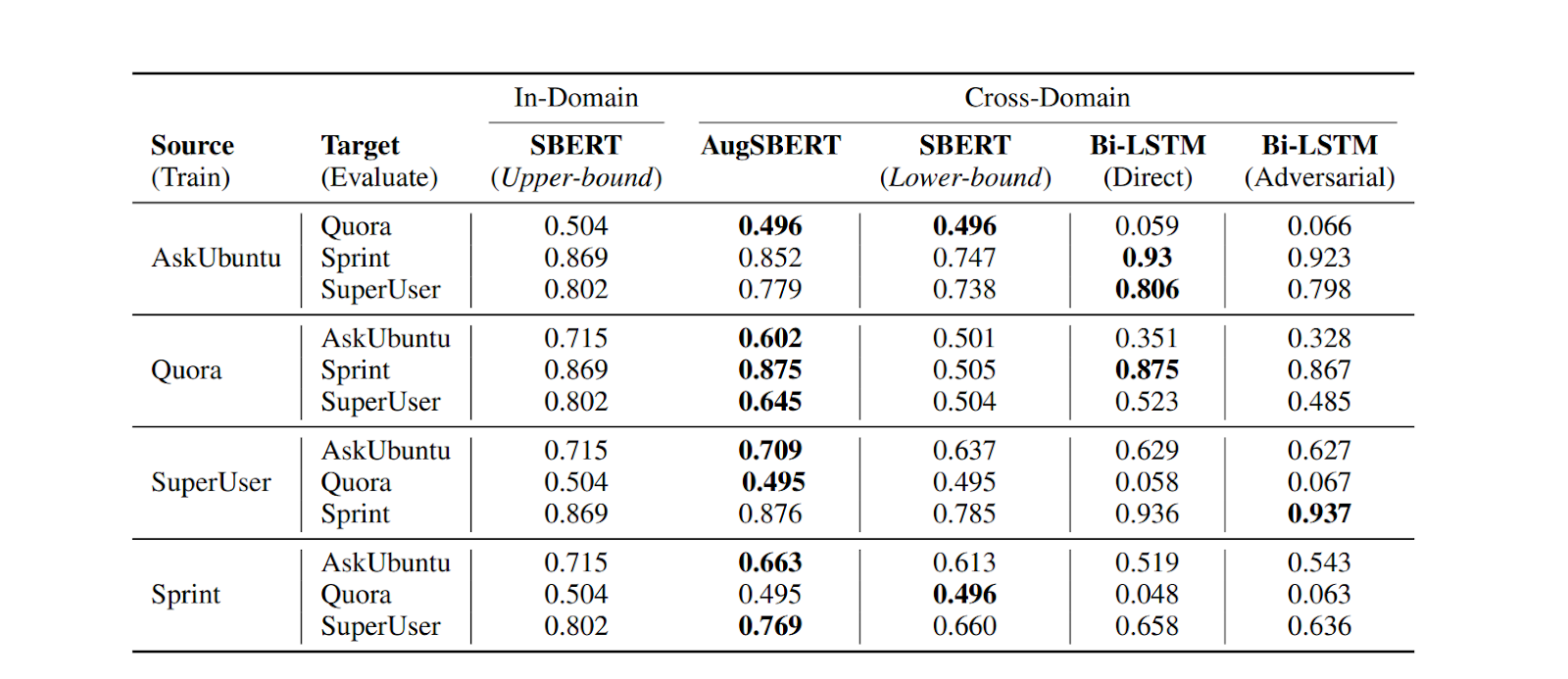 Figure: AUC(0.05) scores for both In-Domain and Cross-Domain experiments
Figure: AUC(0.05) scores for both In-Domain and Cross-Domain experiments
Figure: AUC(0.05) scores for both In-Domain and Cross-Domain experiments | Source
In-Domain Results
Performance of Bi-Encoder (SBERT without SeedOpt.): The plain bi-encoder (SBERT without SeedOpt.) consistently underperforms the cross-encoder across all in-domain tasks, with performance gaps ranging from 4.5 to 9.1 points.
AugSBERT Performance: AugSBERT improves performance for all tasks by 1 to 6 points, significantly outperforming the bi-encoder SBERT and reducing the performance gap with the cross-encoder BERT.
Comparison to Synonym Replacement (NLPAug): AugSBERT outperforms synonym replacement data augmentation techniques (NLPAug) in all tasks.
Comparison to Universal Sentence Encoder (USE): AugSBERT significantly outperforms the off-the-shelf USE model in most tasks. The exception is Spanish-STS, where USE performs well due to prior exposure to the test set during training
Comparison to Cross-Encoder: For known topics (in-topic), AugSBERT performs well, even outperforming the cross-encoder. The improved performance is likely due to the better generalization capability of the SBERT bi-encoder compared to the BERT cross-encoder.
Pairwise Sampling Strategy:
Random sampling leads to poor performance due to a high number of dissimilar pairs, which skews the label distribution.
BM25 and Kernel Density Estimation (KDE) sampling methods improve performance by generating more similar pairs.
KDE improves performance by creating a better distribution of positive and negative pairs, but it is computationally inefficient.
BM25 provides the best balance between computational efficiency and performance, generating more similar pairs.
Domain Adaptation Results
AugSBERT in Domain Adaptation: AugSBERT consistently outperforms SBERT trained on out-of-domain data (cross-domain) across most source-target domain combinations. For instance, on the Sprint dataset (target), AugSBERT achieves up to 87.5% AUC (source: Quora), representing a significant improvement of 37 points over SBERT (50.5% AUC).
Source and Target Domain: AugSBERT performs particularly well when the source domain is generic (e.g., Quora) and the target domain is specific (e.g., Sprint). This is likely because Quora covers diverse topics, allowing a cross-encoder to adapt effectively to the more specific target domain. When moving from a specific domain (e.g., Sprint) to a more generic target (e.g., Quora), AugSBERT shows little to no improvement. For example, with Sprint as the source and Quora as the target, AugSBERT achieves an AUC of 49.5%, the same as SBERT. This shows that adapting from specific to generic domains is challenging.
Comparison to Bi-LSTM: AugSBERT outperforms the state-of-the-art Bi-LSTM bi-encoder model in many cases, except the Sprint dataset (target). For example, on the Sprint dataset (target) with AskUbuntu as the source, Bi-LSTM (adversarial) achieves an AUC of 92.2%, surpassing AugSBERT's 85.2% AUC. Despite this, AugSBERT performs better in most other domain pairs, especially when adapting from generic to specific domains.
Key Findings
AugSBERT Improvement: AugSBERT boosts performance by 1 to 6 points across all tasks. It narrows the gap with the cross-encoder and outperforms SBERT.
Domain Adaptation: AugSBERT outperforms SBERT trained on out-of-domain data by up to 37 points, especially when transferring from a generic to a specific domain.
Pairwise Sampling: BM25 strikes the best balance between performance and efficiency. KDE improves performance but is computationally inefficient.
Comparison with USE: AugSBERT outperforms the Universal Sentence Encoder (USE) in most tasks, except Spanish-STS, where USE performs better due to prior exposure.
Bi-Encoder and Vector Databases
Bi-encoder models, such as AugSBERT, create dense vector representations of sentences, capturing their semantic meaning in a fixed-length embedding. These models encode each input independently, generating a unique vector representing its content. By transforming textual data into high-dimensional embeddings, bi-encoders enable efficient semantic similarity comparison. This capability powers applications like semantic search, document ranking, and information retrieval, where understanding the meaning behind the text is crucial.
Vector databases provide a specialized infrastructure to handle these embeddings at scale. They store, index, and retrieve these high-dimensional embeddings for tasks like similarity searches using metrics like cosine similarity or Euclidean distance. When a query vector is submitted, the database retrieves the most semantically similar vectors, enabling use cases like question-answering systems, recommendation engines, and cross-domain retrieval. The combination of bi-encoders for generating meaningful representations and vector databases for efficient retrieval forms the backbone of modern AI-driven search and recommendation systems, offering both scalability and speed.
One of the leading platforms for managing and querying vector data is Milvus, an open-source vector database developed by Zilliz. Milvus supports large-scale similarity searches and has been optimized for both high-dimensional data and fast indexing and querying.
With Milvus, you can store billions of vectors generated by models like AugSBERT and perform real-time searches to find the most relevant data based on similarity. It supports various indexing algorithms that can scale to large datasets while ensuring low-latency searches.
Zilliz also provides Zilliz Cloud, a cloud-based solution based on Milvus for enterprise customers. It is hassle-free and 10x faster than Milvus. This offering makes it easier to integrate vector search and management into cloud-native architectures. It enables users to deploy vector databases for large-scale AI applications without worrying about infrastructure management.
Conclusion and Potential Future Research Directions
The AugSBERT approach powerfully enhances bi-encoders for pairwise sentence-scoring tasks. AugSBERT bridges the performance gap between bi-encoders and cross-encoders using data augmentation with soft labels generated by cross-encoders. Its model-agnostic design enables seamless adaptation across various sentence-scoring applications. This makes it a versatile tool for improving semantic representations.
AugSBERT delivers significant performance improvements, with gains of up to 6 points in in-domain tasks and 37 points in domain adaptation scenarios. Despite its effectiveness, AugSBERT relies on computationally intensive sampling strategies, such as KDE, which may limit scalability in large-scale implementations. Additionally, while identifying meaningful sentence pairs, it faces challenges in multilingual and adversarial settings.
Future Research Directions for AugSBERT
There are several future research directions to improve the Binoculars method and address its limitations:
The efficiency of Sampling Strategies: While AugSBERT benefits from strategies like BM25 and KDE, further exploration into more computationally efficient sampling methods is essential. These methods should balance performance improvements with scalability, particularly for large datasets.
Multilingual and Low-Resource Settings: AugSBERT's performance in multilingual tasks can be improved using stronger multilingual models. Future work could focus on improving its effectiveness in low-resource languages, where training data and pre-trained models are limited.
Related Resources
Augmented SBERT Paper: https://arxiv.org/pdf/2010.08240
Zilliz Cloud Platform: https://www.zilliz.com
Milvus Documentation: https://milvus.io/docs
Understanding Transformer Models Architecture and Core Concepts
10 Open-Source LLM Frameworks Developers Can’t Ignore in 2025

Keep Reading

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.