




1 Table = 1000 Words? Foundation Models for Tabular Data
Tabular data plays a fundamental role in industries such as finance, healthcare, and scientific research, providing structured information that supports decision-making. Unlike unstructured data, which AI models have been able to process more flexibly, structured data remains a challenge. Traditional analysis relies on structured queries and predefined models, making it difficult to work with tables that vary in format, contain missing values, or require analysis beyond simple lookups. These constraints limit the ability to extract insights efficiently, especially as datasets grow in size and complexity.
At a recent Zilliz webinar, Stefan Webb, a developer advocate at Zilliz, examined whether AI models trained on diverse tables could offer a more adaptable approach. Foundation models, trained on large and varied datasets to learn general patterns that apply across different use cases, have demonstrated the ability to generalize across different datasets without needing task-specific fine-tuning, making them well-suited for table analysis. Unlike conventional machine learning models that require extensive training for each dataset, TableGPT2, a foundational model for table analysis, applies its understanding of table structures to answer queries, summarize data, and extract insights, reducing the need for manual intervention.
For these models to be effective, they need efficient ways to store and retrieve structured data. This is where vector databases like Milvus, specialized databases designed to store and search high-dimensional numerical representations of data, play a role. Storing table embeddings allows AI models to search for similar records, retrieve relevant information, and improve structured data analysis. Let’s see what Stefan covered.
Watch the recap of Stefan’s talk on YouTube
Why Tabular Data Needs a New Approach
Traditional approaches for analyzing tabular data rely heavily on structured queries and predefined schemas. Methods such as SQL queries are effective when datasets remain consistent, but even minor variations between tables can disrupt workflows, requiring significant manual adjustments. For example, databases used by banks typically have rigidly defined schemas, making analysis straightforward until new data from external sources with different structures must be integrated. This rigidity hinders the ability to reuse analytical models efficiently and limits automated processing.
This challenge is primarily due to schema variability, the natural differences in table structures across various sources. A healthcare dataset might have columns representing patient history and medical diagnostics, while financial data may record transactions, pricing, or dates, each following distinct rules and formats.
Figure 1: Structured vs. Unstructured Data
Since even minor schema differences can disrupt traditional analytical tools, manual adjustments become necessary to accommodate these variations. This leads to increased effort, slower analyses, and limited scalability.
Current machine learning methods, such as gradient-boosted decision trees, also depend significantly on manually engineered features tailored to each dataset. Every new table or slight change in schema typically requires manual adjustments to these features, limiting efficiency and scalability. As data grows more complex and voluminous, traditional analytical methods become increasingly impractical. This has led to researchers turning to foundation models, which learn generalizable patterns from large datasets.
Foundation Models for Tabular Data: A New Paradigm
Foundation models are artificial intelligence models trained on large, diverse datasets to learn general patterns. Rather than requiring specific training for every new task, these models reuse previously learned knowledge across multiple scenarios. This approach is especially effective for analyzing tabular data, where table structures can differ significantly.
A good example of a foundation model specifically designed for structured data analysis is TableGPT2, developed by researchers at Zhejiang University. TableGPT2 processes tables through several carefully designed steps. First, tabular data is fed into a component called the Table Encoder. This encoder identifies key relationships within the data by analyzing each individual cell, row, and column. It uses a technique known as bi-dimensional attention, which examines relationships in two dimensions simultaneously, across rows (horizontally) and columns (vertically), allowing the model to better understand how different pieces of data within a table relate to each other. Additionally, the Table Encoder employs cell embedding, converting the content of each table cell into embeddings. These embeddings capture both the content and the structure of the table, making the data comprehensible for downstream tasks.
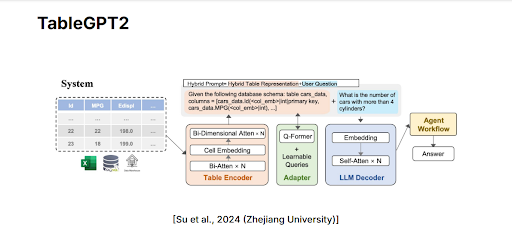
Figure 2: TableGPT2 architecture diagram showing the Table Encoder converting tabular data into structured embeddings and an Adapter (Q-Former) preparing the embeddings for the language model.
After the Table Encoder creates these structured embeddings, they still need further transformation because typical language models like GPT understand text-based inputs better than numerical embeddings. For this purpose, TableGPT2 introduces an Adapter, sometimes called a Q-Former, which translates numerical embeddings into textual representations. The Adapter effectively reformats the numerical embedding into natural language-like prompts. These textual prompts integrate both the information from tables and the user's questions, creating clear, understandable inputs that language models can easily interpret.
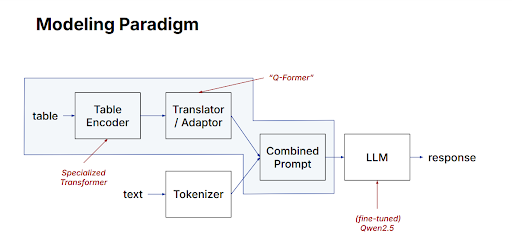
Figure 3: Modeling Paradigm illustrating how TableGPT2 transforms table embeddings into textual prompts
Once combined into a unified textual prompt, the data and the user's question can be processed by a language model. This approach allows TableGPT2 to answer natural-language queries, summarize table content, and provide data-driven insights without relying on predefined rules or manual queries tailored to specific schemas. Because the model learns general structures during training, it can handle varying table schemas with significantly less manual effort than traditional methods.
To generate structured and reproducible analytical outputs, TableGPT2 also uses a predefined instruction known as a System Prompt. Unlike typical prompts, this system prompt explicitly instructs the model on how to perform analytical tasks by generating executable Python code. For instance, when given a question like, Which products had the highest sales in the last quarter? TableGPT2 interprets these system-provided guidelines and produces corresponding Python code to analyze the relevant columns. The resulting code is executed in a controlled environment (e.g., an IPython sandbox), ensuring isolation from the core model and safeguarding against risks. The model then interprets these results to provide accurate, transparent, and reproducible answers. This structured approach ensures results can be easily verified, increasing trust in the model’s analytical capabilities. The system prompt below is the exact one TableGPT2 uses in its code.
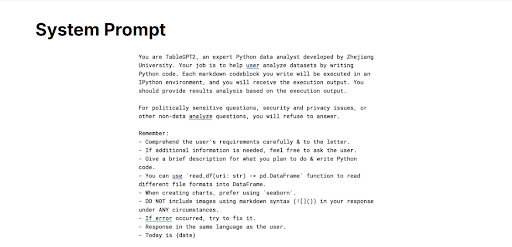
Figure 4: TableGPT2 System Prompt showing instructions that guide the model to generate Python code for structured data analysis.
To better understand how foundation models such as TableGPT2 achieve this flexibility, let’s explore the specific training methods and datasets used to build these models.
Training the Model: The Role of Data
The effectiveness of foundation models like TableGPT2 depends heavily on their training process, which is carefully designed to help the model understand and analyze diverse table structures. To achieve this, TableGPT2 undergoes a specialized training approach consisting of multiple interconnected phases, each playing a distinct role in enabling the model to handle tabular data flexibly and accurately.
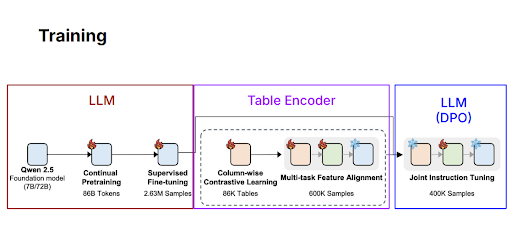
Figure 5: Training process of TableGPT2
Initially, TableGPT2 leverages a general large language model (LLM), Qwen 2.5, which is trained on massive text datasets. This initial phase, called continual pretraining, helps the model acquire broad language understanding skills. It then undergoes a process called supervised fine-tuning, where it learns to better perform specific tasks such as answering questions or summarizing information, using over two million carefully labeled examples. This step builds a solid foundation, enabling the model to handle complex, natural-language queries effectively.
With the language component prepared, training shifts specifically toward understanding tables. Here, column-wise contrastive learning plays a central role. In this process, TableGPT2 learns to differentiate columns based on their relationships and content by comparing many tables and columns side-by-side, learning to recognize similarities and differences across approximately 86,000 diverse tables. The model then moves to multi-task feature alignment, where it simultaneously learns multiple tasks such as classifying table columns and extracting meaningful summaries from tables. By training on hundreds of thousands of diverse table samples, TableGPT2 becomes skilled at identifying structural patterns common across many different tables.
Lastly, the language and table-understanding components undergo a final tuning process known as joint instruction tuning. This step involves carefully integrating these separate capabilities, allowing the model to interpret table structures clearly and respond precisely to user instructions. After this comprehensive training, TableGPT2 is able to interpret and analyze tables from various domains without extensive customization, significantly improving flexibility in practical analytical tasks.
This structured training process ensures TableGPT2 not only effectively understands and interacts with structured data, but also reduces the reliance on manually engineered queries and schemas, addressing the limitations we highlighted earlier.
Practical Example: Using TableGPT2 to Query Tabular Data
To understand how TableGPT2 functions in practice, consider a scenario where a user has structured data stored in a simple CSV file. Imagine wanting to quickly identify specific rows matching certain criteria, such as finding games from a dataset where the record is exactly 40 wins and 40 losses. Rather than manually filtering through tables, TableGPT2 can automatically generate the Python code needed for this task based solely on a user's natural-language query.
Let's walk through how this works step by step. To get started, you need to set up your environment to interact with TableGPT2. The first step involves installing the Hugging Face Transformers library, a Python toolkit that provides easy access to models like TableGPT2:
!pip install transformers
Once installed, load the model and prepare your data:
from transformers import AutoModelForCausalLM, AutoTokenizer
import pandas as pd
from io import StringIO
# Sample structured data in CSV format
csv_content = """
"Loss","Date","Score","Opponent","Record","Attendance"
"Hampton (14-12)","September 25","8-7","Padres","67-84","31,193"
"Speier (5-3)","September 26","3-2","Giants","40-40","29,004"
"Perez (2-2)","September 27","5-4","Reds","40-40","27,500"
"Hampton (13-11)","September 6","9-5","Dodgers","61-78","31,407"
"""
import pandas as pd
from io import StringIO
# Load the CSV data into a DataFrame
csv_file = StringIO(EXAMPLE_CSV_CONTENT)
df = pd.read_csv(csv_file)
The above CSV data represents sports games, including columns for the opponent, the game date, score, team records (win-loss), and attendance figures. To analyze this data using TableGPT2, you first load the pre-trained model and tokenizer:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "tablegpt/TableGPT2-7B"
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="auto", device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Next, you use TableGPT2 to answer a question about your data. Here, we’ll use a specific example: identifying games with exactly a 40-40 win-loss record. To achieve this, you provide the model with a carefully formatted prompt, guiding it to generate Python code to answer the query:
example_prompt_template = """Given access to several pandas dataframes, write the Python code to answer the user's question
/*
"df.head(5).to_string(index=False)" as follows:
{df_info}
*/
Question: {user_question}
This prompt clearly instructs TableGPT2, specifying the table structure (column names and a sample of data) along with your question.
The following function will then send this prompt to TableGPT2 and retrieves Python code as a response:
def ask_table_question(question: str):
prompt = example_prompt_template.format(
var_name="df",
df_info=df.head(5).to_string(index=False),
user_question=question
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
return response
Lets’s now ask the model a question and see how it responds:
question = "Which games have a record of 40 wins and 40 losses?"
generated_code = ask_table_question(question)
print(generated_code)
Here is the Python code returned by TableGPT2
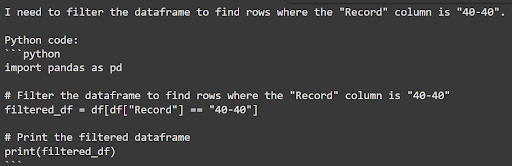
Figure 6: Output generated by TableGPT2
As you can see, this code accurately filters the data. Here's how this generated code works:
The code first splits the values in the
"Record"column into two separate numbers, representing wins and losses, using.str.split("-").It then converts these values from strings into integers, making numerical comparisons possible.
Finally, the code identifies only those rows where wins and losses both equal 40, creating a filtered dataset.
This demonstration shows how TableGPT2 can simplify data analysis. Users can interact with structured data naturally, receiving transparent and verifiable results without manually coding complex queries. This method makes data insights accessible even for beginners or non-technical stakeholders. Note that other than code, you can instruct TableGPT to give you the output directly via the prompt.
How Milvus Enhances AI-Powered Tabular Search
Foundation models such as TableGPT2 provide flexibility when analyzing structured data, but efficiently finding relevant information within large-scale databases is challenging. Milvus, an open-source vector database, complements foundation models by storing and quickly searching embeddings.
Milvus operates by converting data, such as text or tables, into embeddings. An embedding is essentially a numerical representation that positions data points in a high-dimensional space, allowing the model to find similar or related entries quickly. For instance, embedding financial transactions would place similar transactions, like purchases of related products, close to each other within this numerical space. Let’s take a look at Milvu’s workflow.
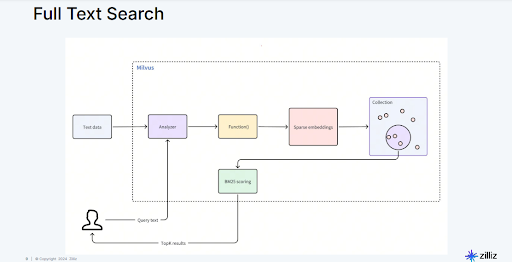
Figure 7: Workflow illustrating Milvus processing textual data, converting it into embeddings, and retrieving relevant results
The process starts when a user inputs a query in natural language. Milvus first analyzes this query text, breaking it down and converting it into an embedding. The embeddings from the query are then compared against a collection of previously stored embeddings. To identify the most relevant matches, Milvus uses scoring methods such as BM25, a technique that evaluates both the frequency and importance of keywords in documents. By combining semantic meaning (captured by embeddings) and keyword relevance, Milvus quickly retrieves accurate search results, helping foundation models provide better-informed responses.
Milvus can be used in various scenarios and supports multiple deployment methods, depending on the scale and complexity required:
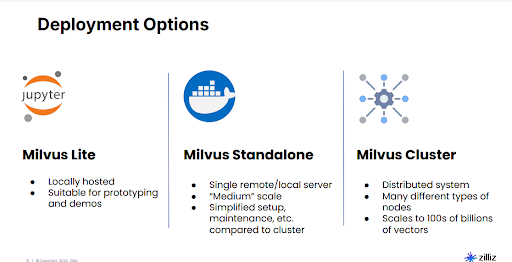
Figure 8: Deployment options for Milvus
Milvus Lite is ideal for rapid testing and small-scale projects, commonly used directly within environments like Jupyter notebooks. It allows for quick experiments without complex setups or additional infrastructure. Milvus Standalone is suitable for moderate-sized workloads. Typically hosted on a single server using technologies such as Docker, it provides simplified maintenance for applications that need reliable but moderate-capacity storage. Milvus Cluster supports large-scale scenarios, scaling efficiently to billions of vectors across multiple servers. It distributes the workload across multiple nodes, significantly improving speed and allowing the handling of extremely large datasets.
The performance benefits of Milvus are important for applications needing fast response times, such as real-time recommendation systems or interactive queries. Benchmarks demonstrate Milvus significantly outperforms other vector databases in terms of speed, handling millions of vector searches with greater efficiency:
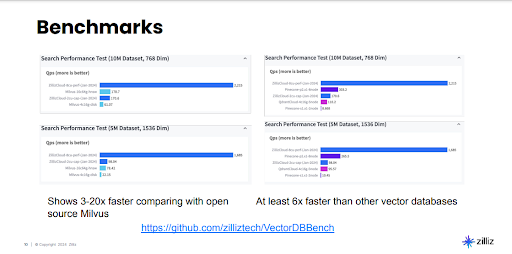
Figure 9: Benchmarks comparing search speed (queries per second) of Milvus versus other vector databases
Additionally, Milvus supports workflows that combine AI models with retrieval processes, ensuring generated answers remain accurate by grounding them directly in factual data. This process is called Retrieval-Augmented Generation (RAG) and allows foundation models like TableGPT2 to produce results grounded in real data stored in Milvus. In practice, this means TableGPT2 doesn't rely purely on patterns learned during training, it also retrieves current, relevant data directly from the database whenever answering user queries.
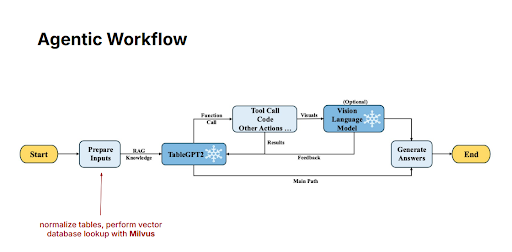
Figure 10: Agentic Workflow
Specifically, an AI agent first normalizes and prepares input data, then retrieves related contextual information from Milvus. Once this additional information is retrieved, the agent forwards both the user's query and the context to TableGPT2. TableGPT2 then uses its learned capabilities alongside fresh data from Milvus to generate clear, accurate, and timely responses to user questions. This ensures the information provided by the model is both accurate and up-to-date, enhancing trustworthiness and usefulness for end-users.
By clearly understanding Milvus’s workflow, deployment options, and performance advantages, it becomes apparent how combining foundation models with optimized vector databases greatly improves efficiency and accuracy in structured data analysis tasks.
Challenges and Limitations of Foundation Models for Tabular Data
Despite their flexibility and improved performance over traditional methods, foundation models like TableGPT2 still encounter several practical challenges when applied to structured data analysis. These include:
Schema variability: Tables from different industries rarely follow uniform structures. Even though foundation models generalize better than traditional methods, significant differences in table structures can still affect accuracy. For instance, analyzing financial records with a model extensively trained on healthcare data might lead to less precise insights due to fundamental differences in data types and structure.
Scalability: Processing large or complex tables often requires substantial computational resources, making it costly and challenging to implement foundation models at scale. When datasets grow into millions or billions of records, the resources needed for effective analysis increase significantly, potentially slowing down workflows or increasing operational costs.
Interpretability: Foundation models, typically based on neural networks, provide limited explanations about how they arrive at specific answers or decisions. Traditional analytical methods, such as decision trees, clearly show the rationale behind predictions, whereas neural-based foundation models operate as black boxes. This limitation may restrict their use in industries where transparency and regulatory compliance are critical, such as healthcare, finance, or legal domains.
Biases from Training Data: Foundation models risk inheriting biases from their training datasets. If the training data contains biases, those biases may be reflected in the model's predictions or insights. This can result in unfair or inaccurate outcomes, especially in sensitive areas like hiring decisions, medical diagnosis, or credit scoring. Detecting and correcting these biases can be challenging due to the opaque nature of neural models.
Lack of Standardized Benchmarks: Evaluating foundation models for structured data analysis remains difficult due to the lack of universal evaluation standards. Unlike natural-language tasks, where well-established benchmarks exist, structured data analysis currently lacks widely accepted performance measures. This complicates efforts to objectively compare or validate different models.
Recognizing these challenges is important for effectively deploying and improving foundation models. When using these models, you need clear strategies to manage these limitations, ensuring that the benefits outweigh the risks.
Conclusion
Foundation models like TableGPT2 represent a meaningful shift in analyzing tabular data, offering increased adaptability compared to traditional methods. When integrated with vector databases like Milvus, these models efficiently access relevant data, significantly enhancing their accuracy and practical usefulness. However, effectively using foundation models requires addressing challenges such as schema variability, scalability, interpretability, potential biases, and the lack of standardized evaluation methods. As these models continue to evolve, addressing these limitations will enable organizations to more confidently and effectively utilize structured data for informed decision-making.
Keep Reading

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.