




Implementing Agentic RAG Using Claude 3.5 Sonnet, LlamaIndex, and Milvus
As AI systems continue to evolve rapidly, relying solely on large language models (LLMs) is no longer sufficient to meet the diverse needs of today’s industries. These increasing challenges require the development of more complex architectures that can solve problems more efficiently and effectively.
At the Unstructured Data Meetup hosted by Zilliz, Bill Zhang, Director of Engineering at Zilliz, introduced the concept of Compound AI Systems, which was featured in the Berkeley AI Research (BAIR) blog. This modular approach integrates multiple components to handle various tasks rather than relying on a single AI model, delivering more tailored and efficient results. You can watch Bill’s presentation on the Zilliz YouTube channel.
In this blog, we'll recap Bill’s key points, including the evolution of LLM app architectures, the concepts of Retrieval Augmented Generation (RAG) and Agentic RAG, and their challenges and benefits. We’ll also walk you through building an Agentic RAG using Claude 3.4 Sonnet, LlamaIndex, and the Milvus vector database.
The Architecture Development of LLM Applications
LLMs have been part of the AI landscape for over a decade, but the emergence of publicly available foundation models, particularly OpenAI’s ChatGPT, over the last three years has significantly accelerated the development of LLM applications, driving their rapid expansion. At the Unstructured Data Meetup, Bill summarized the key components of the current AI architectures and their development.
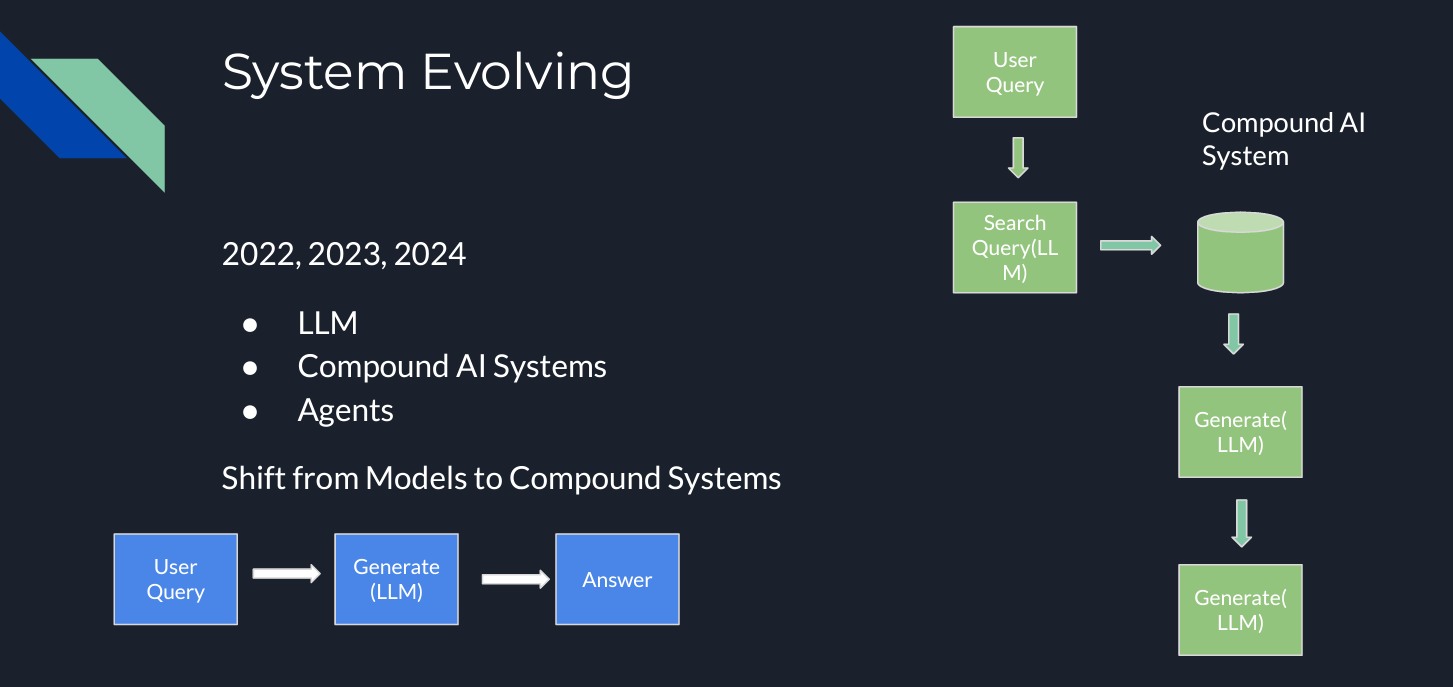 Figure 1- LLM System Evolution .png
Figure 1- LLM System Evolution .png
Figure 1: LLM System Evolution
Rely solely on LLMs’ pre-trained knowledge
The simplest way to use an LLM is to rely on its “own” knowledge to answer your query. However, this method has a limitation: LLMs can’t cover all topics or use cases, which can lead to inaccurate or “hallucinated” answers. One way to address this problem is by using multiple LLMs, each tailored to different types of questions, but this method would make the system overly complex and hard to scale.
Compound AI systems: adding extra components to your LLM pipeline
So, how can we solve this problem? The solution lies in Compound AI systems. Adding extra components to the LLM pipeline can enhance the system's performance. A common example is Retrieval Augmented Generation (RAG). RAG introduces a "knowledge base" or "context," typically stored in a vector database like Milvus or Zilliz Cloud (the managed Milvus), where specific information is saved for similarity searches. You can access information customized for your use case by feeding your knowledge into the RAG system. RAG leverages the power of the LLM combined with a tailored prompt composed of the user query and the context retrieved from the vector database, producing more accurate and relevant responses.
Agents
So, do we need to implement more modules? That depends on the specific use case. However, like LLMs, RAG also has limitations, as it relies on the specific model. For instance, what if your query involves performing a comparison task, but your model has been trained for summarization? How can different types of questions be managed effectively? Here is where an additional module comes into practice: Agents. AI agents are complex systems adding “human-like” steps into the pipeline, like reasoning, tools used, or planning. Let’s dig into the basics of RAG first to understand the benefits of agents.
Retrieval Augmented Generation (RAG)
As mentioned above, RAG systems enhance LLM output by incorporating a vector database as a knowledge base. The basic steps of building a RAG system can be summarized as follows:
Chunking: Splitting documents into smaller pieces to improve the relevance of the content retrieved from the vector database using semantic search, a core characteristic of vector databases such as Zilliz Cloud and Milvus.
Embedding: Vectorizing (creating numerical representations of) the chunks that will be ingested into the vector database.
Prompt: Instructions were given to the LLM to search in the vector database based on the query to get the answer
Query: The question given to the LLM
These steps are primarily based on similarity. The model searches for the most similar chunks in the database and generates the most accurate response based on that.
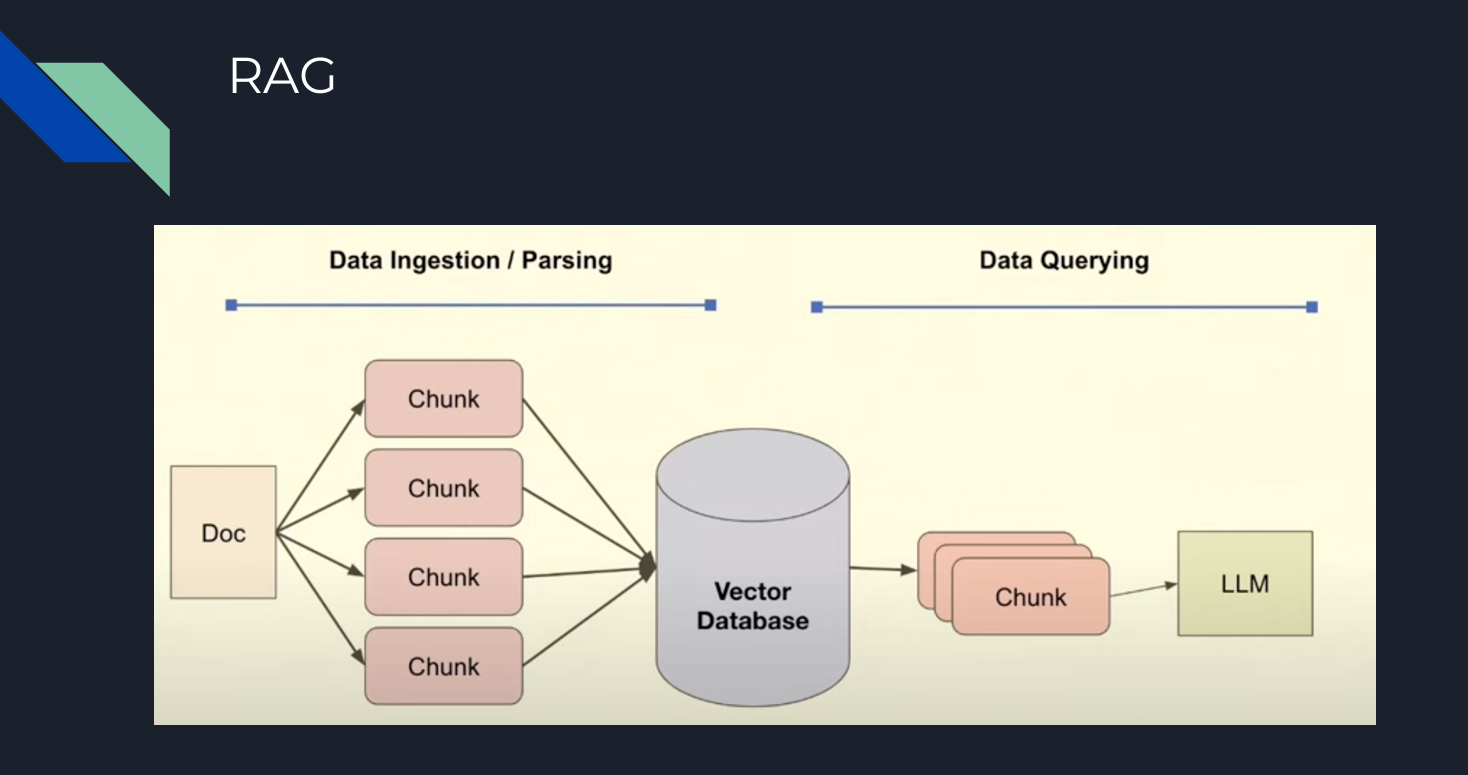 Figure 2- Basic steps of RAG .png
Figure 2- Basic steps of RAG .png
Figure 2: Basic steps of RAG
However, a semantic similarity search is not a magic solution. The resulting answer will also fall short if the most similar chunks are not accurate enough. Bill explored some of the weaknesses of RAG systems, particularly in use cases where LLMs may not perform optimally, including summarization, comparison, and multi-part questions.
However, the problem with RAG, namely its lack of reasoning capabilities and inability to retrieve the required documents accurately, can be effectively addressed by the introduction of Agents. These Entities play a crucial role in the entire process, offering a potential solution to the challenges posed by RAG.
Agentic RAG
Now that we understand the limitations of LLMs and RAG, we can explore agents' benefits more deeply. In the diagram below, LLM agents contain several components that interact with each other in an iterative process. Now, it is not just about similarity but also planning, reasoning, tool use, and memorization.
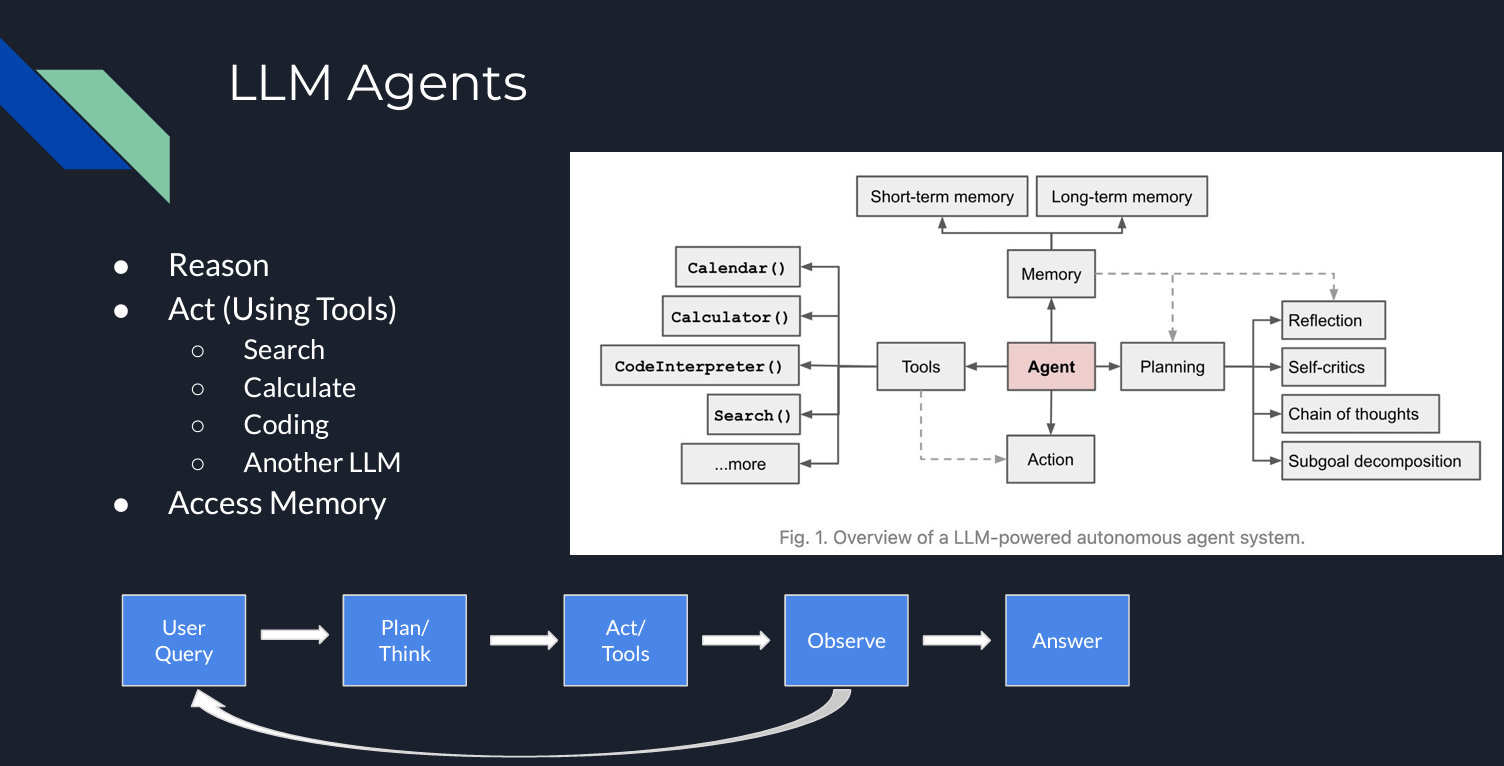 Figure 3- LLM Agents .png
Figure 3- LLM Agents .png
Figure 3: LLM Agents
Although there are several agentic architectures and frameworks, one of the most popular ones is ReAct (Reasoning/Acting). ReAct involves several steps: planning/reasoning, acting (using tools), observation/evaluation, and answer generation. Bill highlighted these steps as part of an iterative process.
In the observation/evaluation step, if the model does not find the answer, it will keep searching for alternatives by returning to the reasoning step or even requesting an additional prompt from the user.
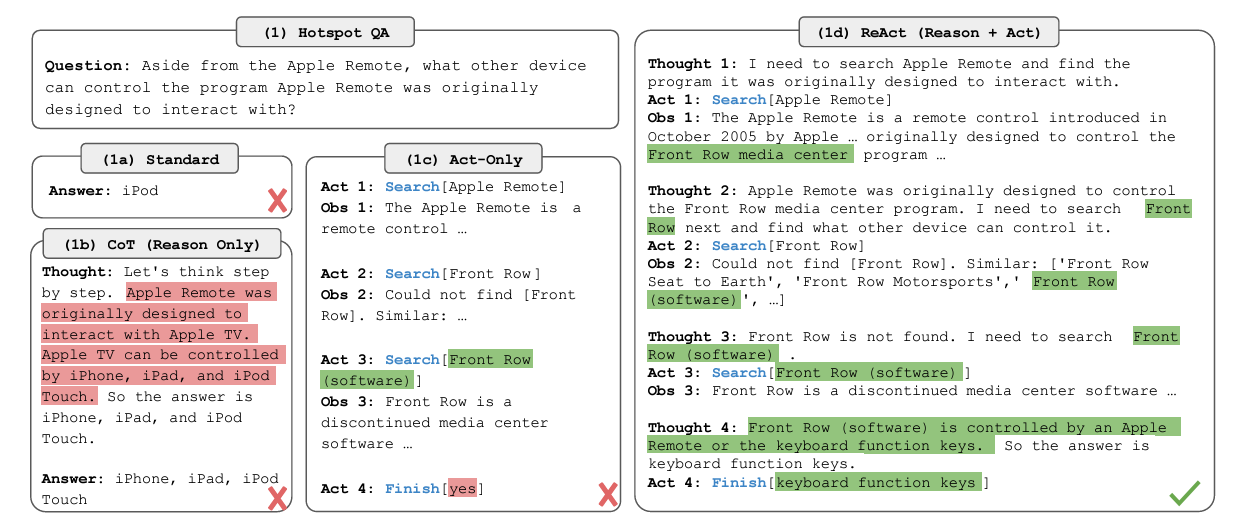 Figure 4- ReAct Framework.png
Figure 4- ReAct Framework.png
Figure 4: ReAct Framework (Source)
So, how can we use these agents in a RAG pipeline? The good thing is that they can be implemented within all the steps of the pipeline, whether routing/planning into the downstream RAG pipeline or tool calling. Even the knowledge base can be considered a tool or a ReAct framework.
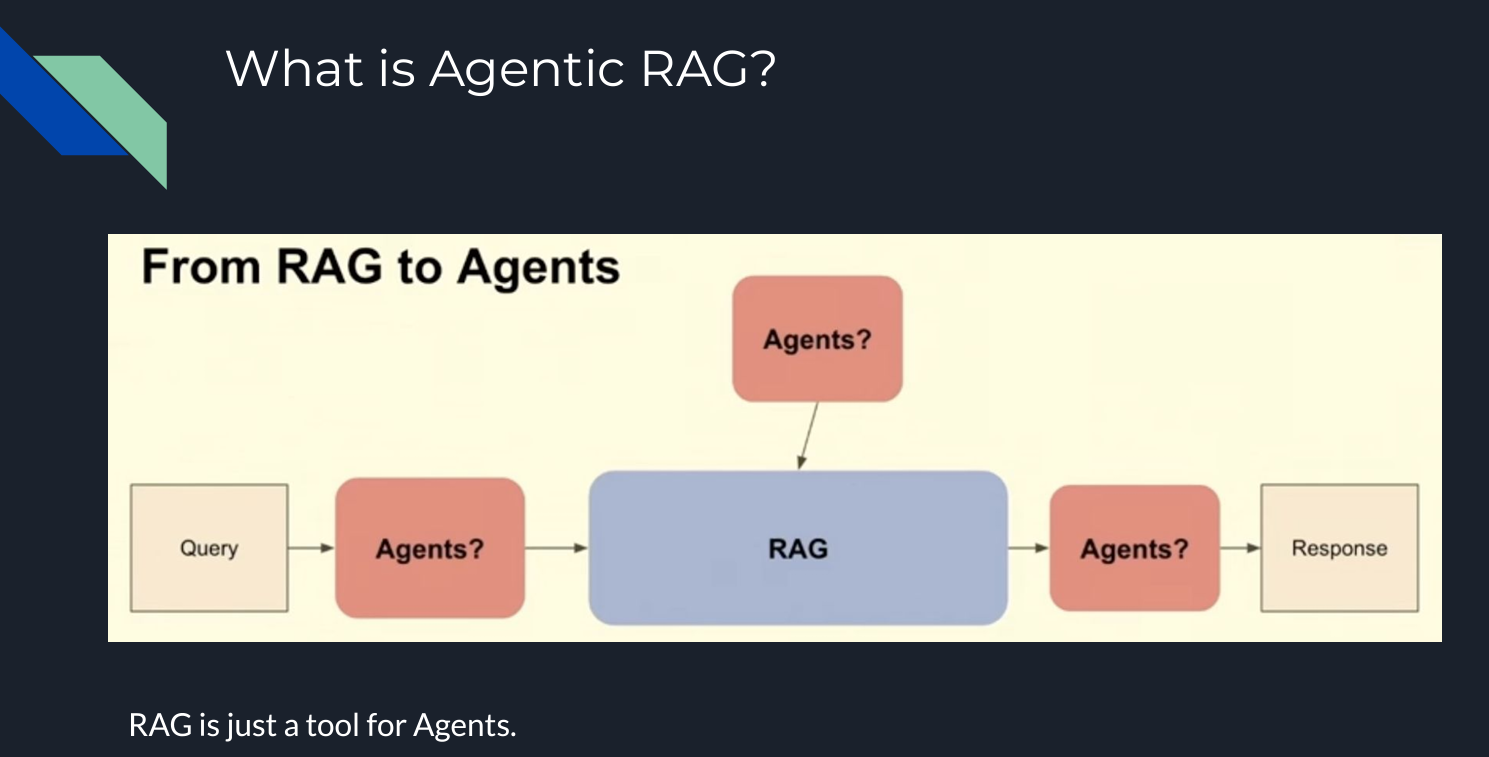 Figure 5- How An Agentic RAG works .png
Figure 5- How An Agentic RAG works .png
Figure 5: How An Agentic RAG works
During the talk, Bill explained five possible agentic implementations within a RAG pipeline:
Routing: The user query is redirected to a specific knowledge base relevant to the query.
- Example: If the user asks for recommendations for specific types of books, the query can be routed to the knowledge base, which contains information on those types of books.
Query Planning: The query is split into sub-queries, with each sub-query directed to the relevant RAG pipeline.
- Example: If you want to know a company's financial results over the last three years, the agent creates sub-queries for each year and directs each to the appropriate knowledge base.
Tool Use: An LLM interacts with an external API or tool, determining the necessary parameters for the interaction.
- Example: If a user requests a weather forecast, the LLM calls a weather API, determines parameters like location and date, and processes the API's response to provide the answer.
ReAct: An iterative process incorporating reasoning and acting, including planning, tool use, and observation steps.
- Example: To generate a detailed travel itinerary, the system reasons the user's needs, uses APIs to gather information on attractions, dining, and accommodation, observes the results for accuracy and relevance, and then provides a comprehensive travel plan.
Dynamic Query Planning: The agent executes multiple tasks or sub-queries in parallel rather than sequentially and aggregates the results
Example: If you want to compare the financial results of two companies and calculate the difference in a specific metric, the agent processes data for both companies in parallel and then combines the results to provide the comparison. LLMCompiler is an example framework that enables an efficient and effective orchestration of parallel function calling.
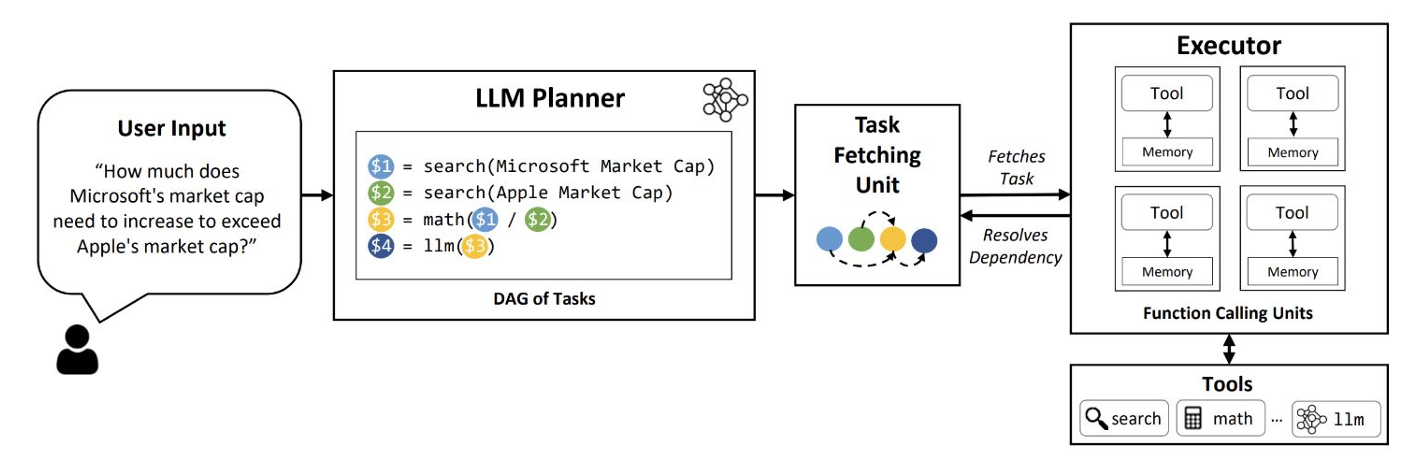 Figure 6- LLM Compiler.png
Figure 6- LLM Compiler.png
Figure 6: LLM Compiler (Source)
So, agents add an additional layer to the RAG pipeline, enhancing and improving the overall efficiency of the process. However, just like LLMs and RAG as standalone systems, agents also present some challenges, such as controlling their internal steps and customizing them to achieve the best results for specific use cases.
Let’s now showcase a simple agentic pipeline using the Milvus vector database.
Agentic RAG Using Claude 3.5 Sonnet, LlamaIndex, and Milvus
The following notebook is an example of an Agentic RAG pipeline built with LlamaIndex as the agentic framework, Milvus as the vector database, and Claude 3.5 Sonnet as the LLM. In this section, I’ll walk you through how to build this agentic RAG.
You can also check the full code in this notebook.
Step 1: Data Loading
We use the FAQ pages from the Milvus Documentation 2.4.x as private knowledge in our RAG, which is a good data source for a simple RAG pipeline.
!pip install -qq llama-index pymilvus llama-index-vector-stores-milvus llama-index-llms-anthropic
!wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
!unzip -q /content/milvus_docs_2.4.x_en.zip -d /content/milvus_docs
from llama_index.core import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(
input_files=["/content/milvus_docs/en/faq/operational_faq.md"]
).load_data()
print("Document ID:", documents[0].doc_id)
Step 2: Environmental Variables
We need to import two API KEYS: Anthropic and OpenAI.
import os
from google.colab import userdata
os.environ["ANTHROPIC_API_KEY"] = userdata.get('ANTHROPIC_API_KEY')
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
Step 3: Data Indexing
An index of the documents is created using the Milvus vector database. This will be our knowledge base. As OpenAI is the default embedding model in LlamaIndex (it can be changed), we need to define the same dimensions (dim = 1536) in the MilvusVectorStore. Additionally a local database will be created after running the following code, which will contain our knowledge base.
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
vector_store = MilvusVectorStore(dim=1536)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
Step 4: Simple Query Engine
Let’s first test the query engine without an agent. It is powered by Claude 3.5 Sonnet and searches for relevant content within our index.
llm = Anthropic(model="claude-3-5-sonnet-20240620")
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)
res = query_engine.query("What is the maximum vector dimension supported in Milvus?")
print(res)
"""
Output:
Milvus supports vectors with up to 32,768 dimensions by default. However, if you need to work with vectors of even higher dimensionality, you have the option to increase the value of the 'Proxy.maxDimension' parameter. This allows Milvus to accommodate vectors with dimensions exceeding the default limit.
"""
Step 5: Agentic Query Engine
Now, we add the QueryEngineTool, which will act as a wrapper tool for the query engine, which will be used by the agent.
from llama_index.core import VectorStoreIndex
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.llms.anthropic import Anthropic
llm = Anthropic(model="claude-3-5-sonnet-20240620")
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)
query_engine_tool = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="knowledge_base",
description=(
"Provides information about Milvus FAQ."
"Use a detailed plain text question as input to the tool."
),
),
)
Step 6: AI Agent Creation
The agent used in this case is the FunctionCallingAgentWorker from LlamaIndex, which employs critic reflection on the query response using the query engine tool to generate an improved answer.
from llama_index.core.agent import FunctionCallingAgentWorker
agent_worker = FunctionCallingAgentWorker.from_tools(
[query_engine_tool], llm=llm, verbose=True
)
agent = agent_worker.as_agent()
response = agent.chat("What is the maximum vector dimension supported in Milvus?")
print(str(response))
"""
Output:
Added user message to memory: What is the maximum vector dimension supported in Milvus?
=== LLM Response ===
To answer your question about the maximum vector dimension supported in Milvus, I'll need to consult the Milvus FAQ knowledge base. Let me do that for you.
=== Calling Function ===
Calling function: knowledge_base with args: {"input": "What is the maximum vector dimension supported in Milvus?"}
=== Function Output ===
Milvus supports vectors with up to 32,768 dimensions by default. However, if you need to work with vectors of even higher dimensionality, you have the option to increase the value of the 'Proxy.maxDimension' parameter. This allows Milvus to accommodate vectors with dimensions exceeding the default limit.
=== LLM Response ===
Based on the information from the Milvus FAQ knowledge base, I can provide you with the following answer:
The maximum vector dimension supported in Milvus is 32,768 by default. This means that out of the box, Milvus can handle vectors with up to 32,768 dimensions, which is suitable for most applications.
However, it's important to note that Milvus offers flexibility for cases where you might need to work with even higher-dimensional vectors. If your use case requires vectors with dimensions exceeding 32,768, you have the option to increase this limit. This can be done by adjusting the 'Proxy.maxDimension' parameter in Milvus configuration.
So, to summarize:
1. Default maximum dimension: 32,768
2. Can be increased: Yes, by modifying the 'Proxy.maxDimension' parameter
This flexibility allows Milvus to accommodate a wide range of use cases, from typical machine learning and AI applications to more specialized scenarios that might require extremely high-dimensional vectors.
Based on the information from the Milvus FAQ knowledge base, I can provide you with the following answer:
The maximum vector dimension supported in Milvus is 32,768 by default. This means that out of the box, Milvus can handle vectors with up to 32,768 dimensions, which is suitable for most applications.
However, it's important to note that Milvus offers flexibility for cases where you might need to work with even higher-dimensional vectors. If your use case requires vectors with dimensions exceeding 32,768, you have the option to increase this limit. This can be done by adjusting the 'Proxy.maxDimension' parameter in Milvus configuration.
So, to summarize:
1. Default maximum dimension: 32,768
2. Can be increased: Yes, by modifying the 'Proxy.maxDimension' parameter
This flexibility allows Milvus to accommodate a wide range of use cases, from typical machine learning and AI applications to more specialized scenarios that might require extremely high-dimensional vectors.
"""
The agent's output provides a more detailed answer, including the source of information, the reasoning behind the answer, and some additional suggestions related to the topic. This helps us better understand the answer given by the LLM model.
The Agentic RAG Architecture
The complete architecture of the agentic RAG we just built is like below.
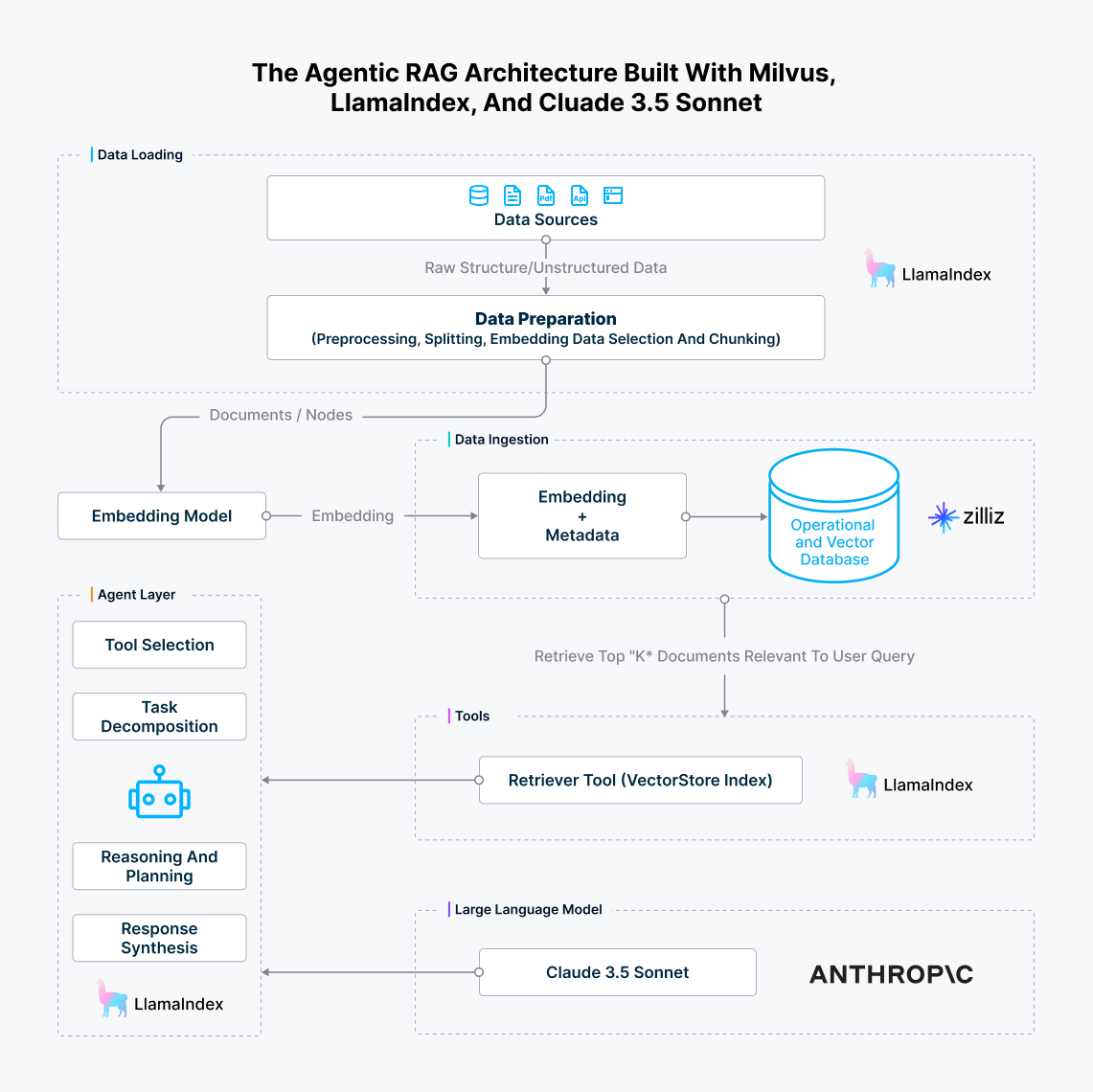 The agentic RAG architecture built with Milvus, LlamaIndex, and Cluade 3.5 Sonnet.png
The agentic RAG architecture built with Milvus, LlamaIndex, and Cluade 3.5 Sonnet.png
Figure 7: The agentic RAG architecture built with Milvus, LlamaIndex, and Cluade 3.5 Sonnet
Conclusion
In his talk, Bill Zhang explored the evolving landscape of LLM systems, highlighting the shift from standalone models to more complex architectures that incorporate RAG and agents. Each component—LLMs, RAG, and agents—has strengths and weaknesses. The concept of Compound AI allows for the creation of modular systems designed to address various bottlenecks, thereby improving the overall efficiency of the pipeline.
While the results of these advanced systems are promising and production-ready implementations are becoming more common, several challenges remain, particularly in managing and customizing agent behavior within these systems. Fine-tuning these components to work efficiently in specific use cases is an ongoing development area.
Further Resources about GenAI, VectorDB, and ML

Keep Reading

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.