




マトリョーシカ表現学習の説明:OpenAIの効率的なテキスト埋め込みを支える手法
現実の機械学習モデルの開発には、常にコストと性能のトレードオフが伴う。例えば、学習時に使用するモデルやデータセットが大きければ大きいほど、最終的に学習済みモデルの能力は向上する。しかし、この能力の向上は、訓練に要する時間が大幅に長くなり、計算コストが高くなることを意味する。同じ原理が推論中にも適用され、より大きなモデルはより大きな特徴表現を生成する傾向があり、より大きなメモリをストレージに必要とします。
機械学習の学習と推論におけるニーズは、ユースケースによって大きく異なるため、コスト削減と引き換えにモデルの性能の一部をトレードオフできるような手法が不可欠である。そこで【マトリョーシカ表現学習(MRL)】(https://arxiv.org/abs/2205.13147)のような手法が登場する。例えば、OpenAIのtext-embedding-3-small モデルは、MRLを利用することで、概念を表現するコアとなる特性を維持したまま、埋め込みを短くすることを可能にしています。埋め込み次元の調整を可能にすることで、MRLはコスト効率とモデル性能の完璧なバランスを実現します。
この記事では、MRLがどのように機能し、どのように実装され、どのようにスケーラブルで効率的な機械学習モデルを実現するのかを探ります。まずはMRLの動機から。
マトリョーシカ表現学習(MRL)の動機
機械学習モデルを開発したり使用したりする前に、コストと性能のトレードオフを常に考慮する必要があります。
学習中、モデルのパラメータと学習データの量は最終的なパフォーマンスに直接影響します。モデルや学習データセットが大きいほど、より高性能なモデルになる傾向があります。しかし、これらのモデルを訓練するための計算コストも高くなります。
一方、推論中、より大きなモデルはより大きな特徴表現を生成する。特徴表現が増えるということは、それを保存するためのメモリがより多く必要になるということだ。
情報検索の文脈でBERTを例にしてみよう。BERTは初期のTransformerベースの深層学習モデルの一つで、テキスト分類、名前付き固有表現認識(NER)、質問応答(QnA)などのいくつかのベンチマークデータセットで最先端の性能を達成した。
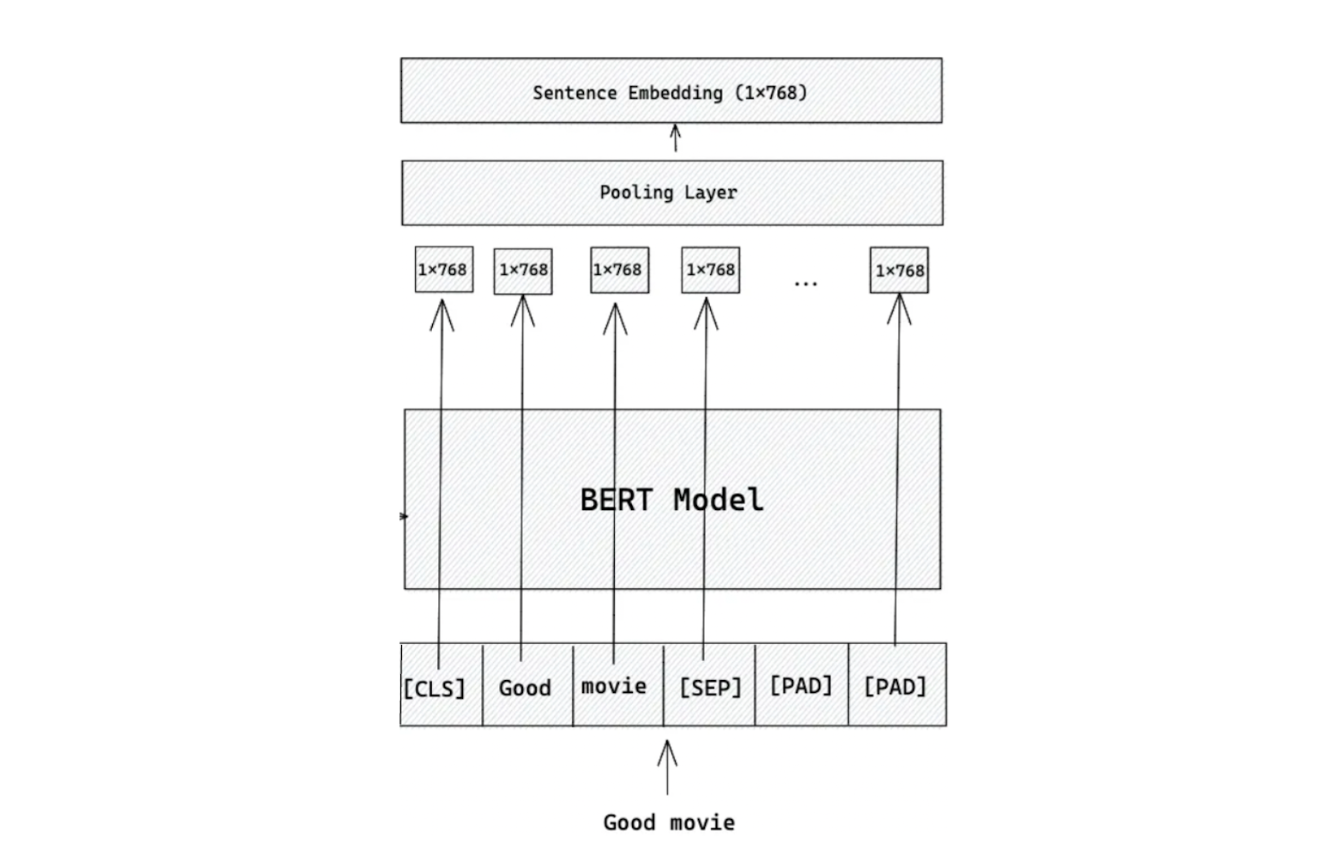
図:BERTベースモデルを用いた埋め込み生成のワークフロー_。
一言で言えば、BERTは文や単語を入力とし、それを固定サイズの埋め込みに変換します。この埋め込みは、元の入力の意味的な意味をキャプチャし、そのサイズは、使用される特定のモデルのバリアントに依存します。
BERT には、ベースモデルとラージモデルの 2 つの主要なバリアントがある。ベースモデルは768次元の埋め込みを生成し、ラージモデルは1024次元の埋め込みを生成します。
例えば、情報検索のユースケースのために、1,000万個の埋め込みをベクトルデータベースに格納したいとします。FP32形式のBERT基本モデルを使用すると、これらの埋め込みを格納するために、およそ768×10M×4=30.72GBのメモリが必要になります。対照的に、同じシナリオでBERTラージモデルを使用すると、約40.9GBが必要になります。さらに、より大きな埋め込みサイズは、類似検索の計算複雑度を増加させることによって、検索プロセスを遅くする可能性があります。しかし、より大きな埋め込みを使用する主な利点は、より小さな埋め込みと比較して、関連性の高い情報を検索する能力が向上することです。
情報検索におけるこれらの問題に対する一つの理想的な解決策は、全体のプロセスを2つの部分に分割することです:**ショートリストとリランキングである。Shortlistingとは、Milvusのようなベクトルデータベースの膨大なコレクションから、候補となる文書の初期セットを検索することである。再順位付けは、これらのショートリストされた候補を取り出し、最終結果の関連性を最大化するように並べ替える。
図-ショートリストと再ランク付けのワークフロー](https://assets.zilliz.com/Figure_Shortlisting_and_reranking_workflow_fc910bea3d.png)
図:選考と再ランキングのワークフロー。
ショートリストを実行するために、アルゴリズムは、クエリ埋め込みとベクトルデータベースに格納された埋め込みの大規模なコレクションとの間の類似度を計算します。したがって、より小さな埋め込みサイズを使用することで、この計算をより効率的かつ高速に行うことができます。逆に、リランキングは精度を重視するため、埋め込みサイズを大きくすることが有効である。
この方法の問題点は、一度特定のモデルを選択すると、そのモデルが生成する埋め込みや特徴表現のサイズが固定されてしまうことです。この柔軟性の欠如により、1つのモデルから異なるサイズの埋め込みを使用する能力が制限されます。
図- 固定サイズの埋め込みを生成するモデルのワークフロー.png](https://assets.zilliz.com/Figure_Workflow_of_a_model_generating_a_fixed_size_embedding_39d7f8e642.png)
図:固定サイズの埋め込みを生成するモデルのワークフロー。
マトリョーシカ表現学習(Matryoshka Representation Learning: MRL)**アプローチは、この問題に対する興味深い解決策を提供します。この手法で学習されたモデルは、様々なサイズの埋め込みを生成することができる。
マトリョーシカ表現学習(MRL)とは?
マトリョーシカ表現学習(Matryoshka Representation Learning: MRL)とは、ニューラルネットワークを学習し、1つのモデル内でマルチスケール表現を生成する手法である。マトリョーシカ人形に着想を得ており、マトリョーシカ人形は大きな人形の中に小さな人形が収まるようになっています。MRLは、モデルが1回のフォワードパスで様々なサイズ(粗いものから細かいものまで)の表現を出力することを可能にします。このアプローチにより、ディープラーニング・モデルはデータの複雑な関係やニュアンスをよりよく理解できるようになります。MRLはセマンティック検索、情報検索、多言語処理、様々な抽象度にわたるデータのニュアンス表現を必要とするアプリケーションなどのタスクに特に効果的です。
マトリョーシカ埋め込みを多層的に可視化](https://assets.zilliz.com/Visualization_of_Matryoshka_embeddings_with_multiple_layers_of_detail_274f2c7aba.png)
図:マトリョーシカ埋め込みの多層化による可視化
マトリョーシカ表現学習(MRL)を採用した埋め込みモデルとしては、OpenAIのtext-embedding-3-large、Nomicのnomic-embed-text-v1、Alibabaのgte-multilingual-baseなどが有名です。
MRLアプローチの仕組み
MRLアプローチにより、あらゆる機械学習モデルから様々なサイズの特徴表現を抽出することができる。例えば、エンベッディングの元の1024次元を使う代わりに、最初の16次元、32次元、64次元、128次元、256次元(あるいは任意の次元)を使うことができます。この機能の鍵は、MRLアプローチを実装する際のモデルの学習方法にあります。
図- MRL損失関数の学習と推論時の使用例](https://assets.zilliz.com/Figure_MRL_loss_function_training_and_its_use_case_during_inference_43da634906.png)
図:MRL損失関数の学習と推論時の使用例_ ソース..
MRLによるモデル学習では、標準的なモデル学習のように1つの損失関数を最適化するのではなく、複数の損失関数を最適化します。各損失関数は事前に定義した特定の次元の特徴表現を最適化することを目的としています。もし5つの異なる特徴次元を設定した場合、トレーニング中に5つの異なる損失関数を最適化する必要があります。
MRLアプローチを使ってBERT大規模モデルを訓練したいとしよう。前節で述べたように、このモデルはサイズ1024の埋め込みを生成する。特徴次元を32、64、128、256、1024に設定すると、これらの次元で最適化された埋め込みを生成するようにモデルが学習するように、学習中に5つの異なる損失関数を最適化することになります。
これらの様々な次元における最適化は簡単です:MRLは全体の損失関数を個々の次元の損失の合計に分解します。MRLは全体の損失関数を個々の次元の損失の合計に分解します:
(https://assets.zilliz.com/equation_loss_function_6d91936452.png)
MRLで学習されたモデルの最適化プロセスは、より正式には以下のように表すことができる:

図:MRLアプローチの最適化方程式_ Source.
お分かりのように、上記の損失関数の定義は非常に一般的です。従って、MRLアプローチはほとんど全てのモデルに適用でき、モデルのアーキテクチャに全く依存しません。また、BERTのような事前に訓練されたモデルや、その他の変換器ベースのモデルを微調整して、様々なサイズの埋め込みを出力することもできます。上記のシナリオを続けると、学習済みのBERTラージモデルから1024次元の埋め込みを生成し、32、64、128、256次元の埋め込みを生成することができます。
全体として、MRL でモデルを訓練した後、訓練されたモデルによって生成された特徴の最初の次元は、後の次元よりも重要な情報を含んでいます。最初の数次元は高レベルの詳細情報を含み、後の次元はマトリョーシカ人形の構造を模倣した、より粒度の細かい情報に焦点を当てます。
しかし、これは短い埋め込みが常に長い埋め込みを単に切り捨てたものであるという意味ではありません。短いエンベッディングの各要素の値は、学習時に各特徴次元に適用されるスケーリングファクタによって、長いエンベッディングの値と異なる可能性があります。しかし、各次元のスケーリング係数を等しくすれば、短い埋め込みと長い埋め込みでは、各要素の値は同じに見えるかもしれません。
MRL 実験結果
MRLアプローチは、テキスト、視覚、視覚-テキストを含む様々なモダリティの機械学習モデルで評価されています。ResNet50とViTは視覚ベースのモデル、BERTはテキストベースのモデル、 ALIGNは視覚とテキストの組み合わせを表しています。これらのモデルは、主に2つの一般的なユースケースについて評価されている:分類** と 検索である。まず分類について説明しよう。
ImageNet-1Kデータセットで学習したResNet50モデルの性能を、独自に学習した標準的なResNet50と比較すると、MRLモデルは様々な特徴表現サイズでトップ1の精度を達成しています。
下流のタスクにおける特徴表現の有用性をさらに評価するため、各特徴表現サイズにおける1-nearest neighbor(1-NN)の精度も測定しました。1-NNの計算設定は以下の通り:データベース内の1.3Kの画像サンプルが与えられた場合、タスクは50Kのクエリのそれぞれについて最近傍を見つけることである。この設定により、MRLを用いて学習されたResNet50は、固定特徴量と比較して、各特徴量サイズにおいて最大2%精度が向上します。
図- ImageNet-1KにおけるResNet50の精度と1-NNの精度](https://assets.zilliz.com/Figure_Top_1_accuracy_and_1_NN_accuracy_of_Res_Net50_on_Image_Net_1_K_d438630984.png)
図:ResNet50のImageNet-1Kにおけるトップ1精度と1-NN精度_ ソース..
一方、JFT-300MデータセットでMRLを用いて学習したViTモデルの性能も、すべての表現サイズにおいて非常に競争力があります。その1-NN精度は、固定サイズの特徴表現で学習したViTの精度に匹敵します。下図に示すように、MRLモデルの性能は、低次元を表現するために固定サイズモデルからランダムな特徴が選択されることもあり、低次元特徴表現では固定サイズモデルよりも優れています。同様の傾向はMRLアプローチで学習されたALIGNモデルにも見られ、その性能は固定サイズ表現で学習されたALIGNモデルの性能と一致します。
図1-ImageNet-1KにおけるViTとALIGNのNN精度](https://assets.zilliz.com/Figure_1_NN_accuracy_of_Vi_T_and_ALIGN_on_Image_Net_1_K_fd1314074a.png)
図1-ImageNet-1KにおけるViTとALIGNのNN精度ImageNet-1KにおけるViTとALIGNの1-NN精度_ ソース..
MRLアプローチを使用する主な利点は、同じモデルから異なるサイズの特徴表現を切り替えられる柔軟性です。この強みを十分に活用するために、ImageNet-1K上でResNet50を用いた適応的分類のテストも実施されました。
この設定では、小さい特徴表現から大きい特徴表現への遷移を決定するために、最大ソフトマックス確率を学習する。テストの結果、37次元の特徴表現を持つMRLモデルは、512次元の固定特徴表現で学習されたResNet50モデルと同程度の精度を持つ一方、2048次元モデルよりも0.8%だけ精度が低いことが示された。
図-適応的分類におけるResNet50モデルの精度(左)と画像検索ユースケースにおけるResNet50のmAP(右)](https://assets.zilliz.com/Figure_Top_1_accuracy_of_Res_Net50_model_in_adaptive_classification_left_and_m_AP_of_Res_Net50_in_image_retrieval_use_case_right_340adbb369.png)
図:適応的分類におけるResNet50モデルのトップ1精度(左)と画像検索ユースケースにおけるResNet50のmAP(右)_ ソース..
次に検索について説明しよう。ご存知のように、検索の目的は与えられたクエリに対して類似したコンテキストの集合を見つけることです。そこで、平均平均精度(mAP)を用いて、MRLで学習したResNet50と固定サイズの特徴表現との検索品質をテストした。MRLモデルはどの特徴表現サイズでも、固定サイズモデルと比較してmAPが最大3%向上していることが、上のビジュアライゼーションで示されています。
MRLでは複数の特徴表現サイズを利用することができるため、MRLを用いて精度を維持しながら検索プロセスを高速化する方法を探ることも特に興味深い。適応検索と呼ばれるシナリオでそれを試すことができます。
前述したように、検索プロセスには主にショートリストと再ランク付けという2つの段階があります。適応検索のセットアップでは、200の候補のショートリストに16次元の特徴表現を用い、リランキングには2048次元の特徴表現を用いる。この手法は、2048次元の特徴表現をショートリストと再ランク付けの両方に用いる別の手法と比較される。
ImageNet-1Kでは、MRLモデルを使用することで、理論的には検索処理を最大128倍高速化できる。実際のアプリケーションでは、検索タスクに素朴な最近傍アルゴリズムを使用することはほとんどないため、これを理論的と呼ぶ。その代わりに、FAISS、ANNOY、HNSWのような近似最近傍(ANN)アルゴリズムが検索速度を向上させるために一般的に実装されている。この場合、MRLモデルを使用したセットアップは、同一のハードウェア上でHNSWアルゴリズムを使用した検索処理と比較して14倍のスピードアップを達成する。
同様の結果がImageNet-4Kデータセットでも観測され、著者らは64次元の特徴表現を持つMRLモデルをショートリストに、2048次元の特徴表現を持つMRLモデルをリランキングに使用した。その結果、理論値で32倍、実測値で6倍の高速化が確認された。
ImageNet-1K(左)とImageNet-4K(右)における適応検索(AR)のmAP@10とMFLOPs/Queryのトレードオフ。](https://assets.zilliz.com/The_trade_off_between_m_AP_10_vs_MFLO_Ps_Query_for_Adaptive_Retrieval_AR_on_Image_Net_1_K_left_and_Image_Net_4_K_right_9a54e41df2.png)
ImageNet-1K(左)とImageNet-4K(右)における適応検索(AR)のためのmAP@10とMFLOPs/Queryのトレードオフ_ Source..
MRL アプローチの実装
このセクションでは、MRLアプローチの簡単な実装を見ていきます。特に、NLIデータセットに対してMRLアプローチで学習させたMPNet基本モデルを使って、様々なサイズの埋め込みを生成してみます。既にご存知かもしれませんが、オリジナルのMPNetベースモデルは768次元の埋め込みしか生成できません。しかし、この学習済みMPNetモデルは、768, 512, 256, 128, 64次元の埋め込みを生成することができます。
このモデルは、SentenceTransformersライブラリの助けを借りて、以下のコードで使うことができる。
from sentence_transformers import SentenceTransformer
matryoshka_dim_short = 64
マトリョーシカの長さ = 768
text = ["天気はとてもいいですね!"]]。
short_embedding = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka", truncate_dim=matryoshka_dim_short).encode(text)
long_embedding = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka", truncate_dim=matryoshka_dim_long).encode(text)
print(f "Shape: {short_embedding.shape, long_embedding.shape}")
print(short_embedding[0][0:10])
print(long_embedding[0][0:10])
"""
出力
形状: ((1, 64), (1, 768))
[-0.33891088 0.01647538 -0.29915053 0.24952686 -0.04321517 -0.31616145
-0.12996909 -0.05221268 0.02296597 0.07074839]
[-0.33891088 0.01647538 -0.29915053 0.24952686 -0.04321517 -0.31616145
-0.12996909 -0.05221268 0.02296597 0.07074839]
"""
上のコードでは、学習済みのMPNetベースモデルを用いて、2つの異なるサイズの埋め込みデータを生成しています:64と768です。各次元の重みまたはスケーリング係数は1に設定されているので、上の2つのエンベッディングの最初の10要素を見てわかるように、2つのエンベッディングは同じ要素を持ちます。
各要素の値は同じなので、2つの埋め込み間の類似度は1になります。
from sentence_transformers.util import cos_sim
similarities = cos_sim(short_embedding[0], long_embedding[0][:matryoshka_dim_short])
print(similarities)
# テンソル([[1.]])
MRLアプローチで独自のモデルをトレーニングしたい場合は、このメソッドの 公式GitHubリポジトリを参照してください。
結論
MRLアプローチは、機械学習におけるコストと性能のトレードオフのバランスを取るためのソリューションを紹介する。どのような機械学習モデルでも様々なサイズの特徴表現を生成できるようにすることで、MRLはユースケースやリソースに応じて速度や精度を最適化できる柔軟性を提供します。この適応性は分類や検索のようなアプリケーションにおいて有用であり、より小さな表現とより大きな表現を切り替えることで、パフォーマンスを大幅に犠牲にすることなく効率を大幅に向上させることができます。
実験結果は、MRLがテキスト、視覚、マルチモーダルタスクを含む複数のドメインにおいて、従来の固定サイズモデルの精度に匹敵し、しばしばそれを上回ることを実証しています。また、ResNet50、ViT、BERTのような既存のアーキテクチャとの互換性により、様々なモダリティのモデルに対して適用可能であることが強調されています。実世界のシナリオにおける大幅な高速化と検索品質の向上の可能性を持つMRLは、より効率的で汎用的な機械学習ソリューションのための有望な進歩である。
関連リソース
チュートリアルマトリョーシカ埋め込みによるファネルサーチ
Top Performing AI Models for Your GenAI Apps | Zilliz](https://zilliz.com/ai-models)
MilvusでAIアプリを作る: チュートリアルとノートブック](https://zilliz.com/learn/milvus-notebooks)
読み続けて

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.