




RocketQA:オープンドメイン質問応答のための最適化された密なパッセージ検索
誰が電気を発明したのか?"**と質問し、システムが多様なトピックや形式にまたがる何十億もの構造化されていない文書から、最も関連性の高い一節をピンポイントで見つけ出すことを期待していることを想像してみてほしい。これは、オープンドメインの質問応答(QA)の挑戦を示している。システムは、ウィキペディアやウェブアーカイブのような大規模でキュレーションされていないデータセットから、関連する情報を素早く検索し、ランク付けしなければならない。初期のQAシステムは、質問分析や文書検索のようなタスクのための複雑なパイプラインを通してこの課題に取り組んでいた。その後、2段階のアプローチが、文章を検索し、密な検索技術を使って正確な答えを抽出することで、プロセスを単純化した。
デュアルエンコーダーアーキテクチャを使用する密な検索は、効率的な意味的マッチングのために、質問と文章を密な埋め込みとして表現する。しかし、これらのモデルを訓練することは、訓練と推論の間の不一致、誤ラベル付けされた陽性、限られた注釈付きデータセットなど、いくつかの課題をもたらす。これらの障害に対処するために、論文Optimized Training of Dense Retrieval Models with Hard Negativesで紹介されたRocketQAは、クロスバッチネガティブ、ハードネガティブのノイズ除去、データ増強などの一連の戦略を提示する。これらの方法は、デュアルエンコーダ学習のロバスト性を改善し、通過検索精度を向上させる。
本稿では、RocketQAのアーキテクチャや学習戦略など、オープンドメインQAのための高密度検索への貢献について述べる。
オープンドメインQAの課題を理解する
オープンドメインQAシステムは、膨大な文書コーパスから最も関連性の高い文章を探し出すことで、ユーザーのクエリに答えることを目的としている。これらのドキュメントは通常、検索と取得をより効率的にするために、より小さなパッセージに分割されている。検索された関連性の高い各パッセージについて、システムは質問の答えとなるテキストの正確なスパンも特定しなければならない。
このタスクは、データのサイズと複雑さのために特に困難である。システムは、リアルタイム検索のための速さ、最も関連性の高い文章を正確に特定するための正確さの維持、重要な情報を見逃さないための再現性の最大化という3つの重要な側面のバランスをとらなければならない。このバランスをとることが、効果的なオープンドメインのQAには不可欠である。
高密度検索システムは、キーワードベースのアプローチのみに頼るのではなく、セマンティックマッチングに焦点を当てることで、これらの課題に対処する上で大きな進歩を遂げた。しかし、特定の分野では効率と精度を向上させる一方で、パフォーマンスを制限する特定の障害にも直面している。
従来の高密度検索におけるギャップ
密集検索システムは、いくつかの重要な制限に直面している:
1.トレーニング対実世界の不一致:モデルは多くの場合、小規模で精選されたデータセットで学習されるが、実世界のシステムは何十億もの文章を扱わなければならない。この不一致は、より大規模で複雑なデータセットに対して一貫した性能を発揮する能力を低下させる。
2.疎な注釈:多くのQAデータセットでは、ラベル付けされたデータが限られており、1つか2つの肯定的な文章とクエリがペアになっていることが多い。このため、トレーニング中に、関連する文章が誤って無関係なものとして扱われ、偽陰性となる。
3.ハードネガ:これらのシステムは、関連性があるように見えるが、実際にはクエリに答えていない文章に苦労することが多い。例えば、"Who discovered electricity?"に関するクエリは、ベンジャミン・フランクリンの実験に関する文章を検索するかもしれない。このような文章が学習中に誤って管理されると、モデルを混乱させ、検索精度を低下させる可能性がある。
学習ストラテジーを改善し、モデルのデータ処理方法を洗練させるテクニックを導入することで、RocketQAがこれらの課題にどのように対処しているかを見てみよう。
RocketQAとは?
RocketQAは、オープンドメインの質問応答(QA)システムを強化するために設計された、高度に最適化された密な通路検索フレームワークである。Baiduによって開発されたRocketQAは、関連する文章を検索するためのデュアルエンコーダーモデルアーキテクチャを採用しており、検索性能を向上させるために、クエリーとドキュメントのエンコーダーが協調的に学習される。このフレームワークは、クロスバッチネガティブサンプリングやノイズ除去といった革新的な学習技術を導入しており、疎なネガティブサンプルやノイズの多い学習データといった一般的な課題に対処している。
RocketQA はどのように高密度検索を改善するのか?
RocketQAはデュアルエンコーダーアーキテクチャを基盤としており、問題とパッセージの密な埋め込みを事前に計算することで、効率的なセマンティックマッチングを可能にします。デュアルエンコーダは2つの別々のエンコーダで構成されています:
質問エンコーダ(Eq(q))**:クエリを密なベクトル表現に変換する。
パッセージ・エンコーダ (Ep(p))**:各パッセージを密なベクトル表現に変換する。
質問とパッセージ間の類似度は、それらの埋め込み値のドット積として計算されます:
sim(q, p) = Eq(q) ⋅ Ep(p).
この事前に計算された構造により、すべてのパッセージの埋め込みがインデックスに格納され、複数のクエリに再利用されるため、高速な検索が可能になります。しかし、デュアルエンコーダはスケーラビリティを提供する反面、クエリとパッセージ間の微妙な関係を捉える性能には限界がある。
これに対処するため、RocketQAは学習の質を向上させるためにクロスエンコーダを組み込んでいる。クロスエンコーダはクエリとパッセージを一緒に処理することで、より豊かな文脈的相互作用を可能にする。デュアルエンコーダのスケーラビリティとクロスエンコーダの洗練性を組み合わせることで、RocketQAは効率と精度のバランスを実現している。デュアルエンコーダとクロスエンコーダの仕組みは以下の通りです。
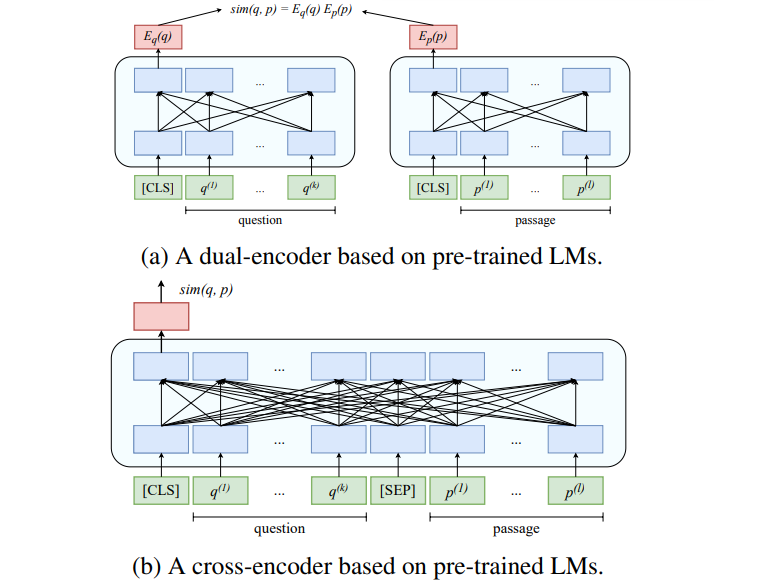
図:デュアル・エンコーダとクロス・エンコーダのアーキテクチャの図解_。
デュアル・エンコーダは、クエリとパッセージをそれぞれ独立に高密度の埋め込みにエンコードする。例えば、"Who invented electricity? "というクエリはその意味に基づいてベクトル表現にエンコードされ、"Michael Faraday made major contributions to electromagnetism "や "Benjamin Franklin's kite experiment "のようなパッセージもベクトルにエンコードされる。システムはこれらのベクトルを比較して、どのパッセージがクエリに最も類似しているかを判断する。このプロセスは、パッセージの埋め込みを事前に計算し、再利用できるため、非常に効率的である。
一方、クロスエンコーダはクエリとパッセージを一緒に処理する。別々にエンコードするのではなく、両者の関係を調べる。例えば、同じクエリとパッセージを評価する場合、クロスエンコーダはベンジャミン・フランクリンの凧の実験に言及したパッセージが電気に関連しているが、クエリに直接答えていないことをよりよく理解することができる。この豊かな理解は計算効率を犠牲にするため、微調整や学習データの生成に適している。
クロスバッチネガティブによるよりスマートなサンプリング
高密度検索における課題の1つは、多様な否定例(クエリに答えていない文章)のセットでモデルをトレーニングすることである。従来のアプローチでは、同じバッチ内の文章に限定されるバッチ内否定を使用します。RocketQAでは、クロスバッチネガティヴを導入することで、この制限に対処しています。クロスバッチネガティヴは、トレーニング中に複数のGPUでネガティヴ例を共有します。
このアプローチは、ネガティブサンプルのプールを大幅に拡大し、実世界のシナリオをより代表的にします。より多様で挑戦的な否定文にモデルをさらすことで、RocketQAはオーバーフィッティングを減らし、関連する文章と無関係な文章を区別する能力を高めます。
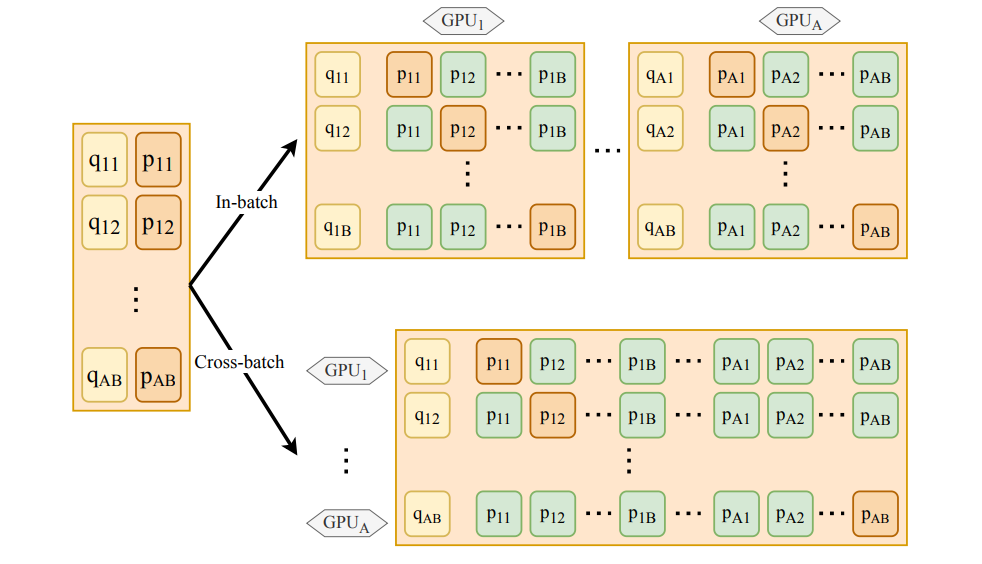
図:図:マルチGPUトレーニングにおけるバッチ内否定とクロスバッチ否定の比較(AはGPU数、Bはバッチサイズ)。
ネガティブサンプリングをバッチレベルに制限する従来の方法とは異なり、RocketQAは各問題を他のバッチのネガティブとペアにすることができ、追加のメモリを必要とせずに多様性を高めることができます。
最適化されたトレーニング目標
RocketQAのトレーニングプロセスは、損失関数を最適化することで、与えられたクエリに関連する文章を特定するモデルの能力を向上させることに重点を置いています。この損失関数は、正のクエリとパッセージのペア(関連性のあるパッセージ)には高い類似度スコアを、負のクエリとパッセージのペア(関連性のないパッセージ)には低いスコアを割り当てるようにモデルを促します。
損失関数は次のように表される:
L(qi, p⁺i, {p-i,j}) = - log ( exp(sim(qi, p⁺i))/ ( exp(sim(qi, p⁺i))+ Σj=1^m exp(sim(qi, p-i,j)) ))
最適化の仕組みはこうだ:
1.肯定的な文章 (p⁺i):各クエリqiに対して、モデルは関連するとラベル付けされた肯定的なパッセージを識別します。目的は類似度スコアsim(qi, p⁺i)を最大化することです。
2.ネガティブパッセージ(p-i,j):同じクエリqiに対して、複数の否定的なパッセージ(クエリとは無関係)が導入される。モデルはこれらの文章に低い類似度スコアsim(qi, p-i,j)を割り当てるように学習される。
3.スコアのバランス:損失関数の分母には、肯定的な文章と否定的な文章の類似度スコアが含まれる。この損失を最小化することで、モデルは肯定的なパッセージの類似性スコアを否定的なパッセージに対して増加させることを学習する。
4.プロセスを視覚化する:この最適化は意味空間の再形成と考える。関連するパッセージの埋め込みは意味空間においてクエリに近づけられ、関連しないパッセージの埋め込みは遠ざけられる。
5.**ランキングの改善この最適化の結果、与えられたクエリに対して、肯定的な文章を否定的な文章よりも上位にランク付けするモデルとなり、システムが関連情報を正確に検索する能力が向上する。
この損失関数を最適化することで、RocketQAは、否定文が文脈的に類似しているシナリオであっても、関連する文章と無関係な文章をより効果的に区別する密な検索モデルを保証する。この改善により、検索システムの精度と想起が直接的に向上し、オープンドメインのQAタスクにおいてより優れたパフォーマンスを実現する。
RocketQAのトレーニング:4段階の最適化パイプライン
RocketQAのトレーニングプロセスは、検索能力を向上させるためにデュアルエンコーダを体系的に改良する、構造化された4段階のパイプラインによって実装されている。各ステージは、ハードネガティブの処理、学習例の多様化、疎なアノテーションの補正など、我々が議論した主要な課題に対処するために、前のステージを基に構築されている。
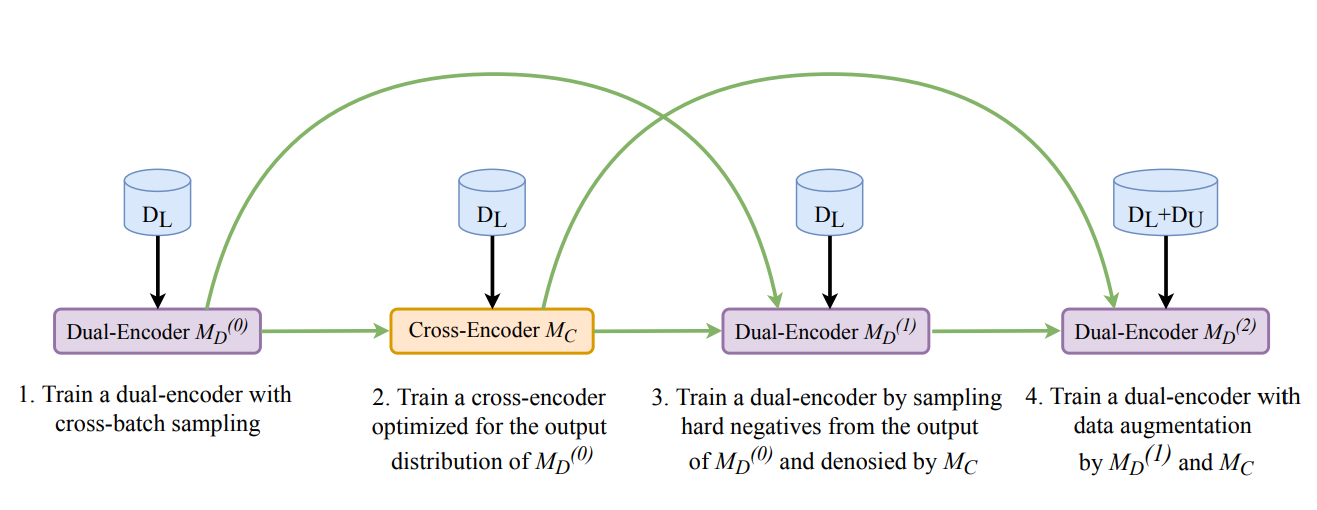
図:RocketQAのトレーニングパイプラインの4つのステージ:_。
各ステージの内容は以下の通り:
**1.クロスバッチネガティブサンプリング
デュアル・エンコーダは、まずクロスバッチ・ネガティブを使用してトレーニングされる。これにより、トレーニングに利用できるネガティブの多様性が増し、モデルがより効果的に実世界の状況をシミュレートできるようになります。このテクニックを活用することで、RocketQAはモデルをより難しい否定文にさらし、関連する文章と関連しない文章を区別する能力を磨きます。
**2.クロスエンコーダのファインチューニング
最初のトレーニングの後、クロスエンコーダは、より文脈を理解した上でクエリとパッセージのペアを評価するために微調整されます。クロスエンコーダは困難なハードネガティヴを特定し、それを用いてデュアルエンコーダをさらに改良する。このステップにより、デュアルエンコーダはクロスエンコーダの深い関係性の洞察から恩恵を受けることができる。
3.ハードネガをノイズ除去する。
デュアル・エンコーダはクロス・エンコーダによってキュレーションされたハード・ネガをノイズ除去して再トレーニングされる。このプロセスは、誤ったラベル付けや情報量の少ないネガを除外することで、学習データのノイズを低減する。その結果、モデルは関連性のある文章と関連性のない文章を区別することに集中し、精度が向上します。
4.データの拡張。
最終段階では、クロスエンコーダは擬似ラベルを生成し、学習データセットを充実させる。これらの擬似ラベルは、追加のラベル付きデータを作成することによって、疎な注釈の問題を解決するのに役立ち、デュアルエンコーダが多様なクエリに対してより良く汎化できるようにする。
この構造化されたプロセスにより、RocketQAは前述の改善点を効果的に統合し、最適化されたワークフローを実現し、最終的に高密度な検索タスクにおけるパフォーマンスを向上させることができる。
ベンチマークにおけるRocketQAのパフォーマンス
トレーニングパイプラインを最適化した後、RocketQAは様々なオープンドメインの質問応答(QA)ベンチマークで高いパフォーマンスを示しています。これらのベンチマークは、複雑なクエリ、疎なアノテーション、誤解を招く否定文など、それぞれユニークな課題を持つさまざまなデータセットにおいて、RocketQAがどれだけ適切な文章を検索できるかを評価するものです。
RocketQAはMS MARCO、Natural Questions、TriviaQAでテストされている。MS MARCOは、検索精度を重視し、ユーザーのクエリと関連する文章および関連しない文章のペアリングに重点を置いています。Natural QuestionsはGoogle検索からの実際のユーザークエリを含み、システムはWikipediaから関連する文章を特定する必要がある。TriviaQA は、正確な答えを検索するために、しばしば文脈推論とより深い理解を必要とするトリビア形式の問題を出題します。
TriviaQAはMS MARCOデータセットで37.0の平均逆順位(MRR@10)を達成し、それぞれ32.7と33.0を獲得したDPRやANCEのような他の高密度検索を凌駕している。このモデルはNatural Questions (NQ)データセットでも良好な結果を示し、ANCEの87.5、DPRの85.4と比較して、88.5の想起率(R@100)を達成した。これらの結果は、RocketQAが最適化後、より高い精度と再現率で関連する文章を検索する能力を持っていることを示しています。
RocketQAの今後の方向性
RocketQAが様々なベンチマークで成功したことは、高密度な検索システムとしての強みを強調している。しかし、オープンドメインの質問応答がより複雑になるにつれて、新たな課題やユースケースに対応するために、その機能を改良し、制限に対処し、機能を拡張する機会が明らかにあります。
**マルチモーダル検索の統合
テキストだけでなく、画像、動画、構造化データなどのマルチモーダルデータを含めることで、RocketQAはよりリッチで多様なクエリを処理できるようになる。例えば、「地球温暖化についてこのグラフの情報を説明してください」というようなクエリでは、視覚とテキストを統合して理解する必要がある。モダリティを組み合わせることで、RocketQAは医療診断、科学研究、マルチメディア検索などの分野に応用できるだろう。
**コンテキストを考慮したパーソナライゼーション
ユーザー固有のコンテキストをRocketQAの検索プロセスに組み込むことで、結果の関連性を向上させることができる。ユーザーの履歴や嗜好からのシグナルを埋め込むことで、モデルは個々のニーズに合わせて回答を調整することができる。例えば、エネルギーについて研究している学生は簡略化された説明を好むかもしれないが、専門家は詳細でソースの多い検索結果を好むだろう。
**ドメインに特化したカスタマイズ
法律文書や医学文献のようなドメイン固有のデータセットで RocketQA を微調整することで、専門分野でのパフォーマンスを向上させることができる。また、知識グラフと統合することで、構造化された関係(例えば、医療における症状→病気)を活用し、精度を向上させることができる。このアプローチにより、RocketQAは法律、医療、工学などの業界でより効果的になるだろう。
結論
RocketQAは、疎なアノテーション、困難な否定、大規模な検索要求などの課題を克服することで、オープンドメインの質問応答に対する高密度な検索を再定義した。デュアルエンコーダとクロスエンコーダアーキテクチャの組み合わせ、クロスバッチネガや最適化されたトレーニングなどの戦略により、スケーラビリティと精度の両方を実現しています。
実証済みのベンチマークの成功と、マルチモーダル検索、ドメイン固有のアプリケーション、およびパーソナライズされたシステムへの拡張の可能性により、RocketQAは質問応答の進歩をリードする態勢を整えています。RocketQAは、オープンドメインQAの要求が進化するにつれ、複雑なクエリに正確かつ効率的に取り組むための強力で適応性の高い基盤を提供します。
その他のリソース
[2010.08191] RocketQA:Open-Domain Question Answeringのための密なパッセージ検索の最適化されたトレーニングアプローチ
クロスエンコーダとスパース行列因数分解がkNN探索を再定義する - Zilliz Learn](https://zilliz.com/learn/how-cross-encoders-and-sparse-matrix-factorization-redefine-knn-search)
MS MARCO](https://microsoft.github.io/msmarco/)
読み続けて

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.