




検索補強世代(RAG)アプリケーション導入のベストプラクティス
検索支援型生成(RAG)は、LLMの反応を改善し、LLMの幻覚に対処するのに非常に効果的であることが証明されている方法である。一言で言えば、RAGはLLMに文脈を提供することで、LLMがより正確で文脈に沿った応答を生成できるようにする。コンテキストは、社内文書、ベクターデータベース、CSVファイル、JSONファイルなど、どこからでも得ることができる。
RAGは、一緒に機能する多くのコンポーネントで構成される斬新なアプローチである。これらのコンポーネントには、クエリ処理、コンテキスト・チャンキング、コンテキスト検索、コンテキスト・リランキング、そしてレスポンスを生成するLLM自体が含まれる。各コンポーネントはRAGアプリケーションから生成される最終的なレスポンスの品質に影響を与える。問題は、最も最適なRAGパフォーマンスにつながる各コンポーネントにおける手法の最適な組み合わせを見つけることが難しいということである。
この記事では、すべてのRAGコンポーネントで一般的に使用されているいくつかのテクニックについて説明し、各コンポーネントに最適なアプローチを評価し、そして最も最適なRAG生成レスポンスにつながる最適な組み合わせを見つけることを、本論文に従って説明します。それでは早速、RAGコンポーネントの紹介から始めよう。
RAG コンポーネント
前述したように、RAGはLLMの幻覚問題を緩和する強力な手法である。LLMのトレーニングデータを超えた質問をした時や、専門的な知識が必要な時によく起こる問題である。例えば、LLMに内部データに関する質問をすると、不正確な答えが返ってくる可能性が高い。RAGは、LLMに我々のクエリに答えるのに役立つコンテキストを提供することで、この問題を解決します。
RAGは、ワークフローを形成する一連のコンポーネントで構成されています。典型的なRAGコンポーネントには以下のものがある:
クエリの分類:クエリがコンテキストの検索を必要とするか、LLMが直接処理できるかを決定する。
コンテキスト検索**:クエリに最も関連するコンテキストの上位k個の候補を取得する。
コンテキストの再ランキング**:検索コンポーネントから取得された上位k個の候補を、最も類似したものからソートする。
コンテキスト・リパッキング(Context repacking):**最も関連性の高いコンテキストをより構造化された形式に整理し、より良い応答を生成する。
コンテキスト要約(Context summarization):** 関連するコンテキストから重要な情報を抽出し、応答生成を改善する。
クエリと関連するコンテキストに基づいてレスポンスを生成する。
図- RAGコンポーネント.png](https://assets.zilliz.com/Figure_RAG_Components_d88965cf8b.png)
図- RAGコンポーネント:RAGコンポーネント._ ソース
これらのRAGコンポーネントは、レスポンス生成プロセス中(つまり、すべてのコンテキストをすでに格納しており、それらをフェッチする準備ができているとき)に便利ですが、RAGメソッドを実装する前に、他のいくつかの要素を考慮する必要があります。
RAG手法でコンテキスト文書を有用なものにするためには、コンテキスト文書をベクトル埋め込みに変換する必要がある。したがって、入力文書を埋め込みとして表現するための 最も適切な埋め込みモデル と戦略を選択することが重要である。
埋め込みは、入力文書を意味的に豊かに表現します。しかし、文脈として使われる文書が長すぎると、適切な応答を生成する際にLLMを混乱させる可能性がある。この問題を解決する一般的なアプローチは、チャンキング法を適用することです。チャンキング法では、入力文書をいくつかのチャンクに分割し、それぞれのチャンクを埋め込みに変換します。チャンクが短すぎると十分な情報を含んでいない可能性が高いため、最適なチャンキング手法とサイズを選ぶことが重要です。
図- RAGワークフロー.png](https://assets.zilliz.com/Figure_RAG_workflow_5bfbcccddf.png)
図:RAGワークフロー
各チャンクをエンベッディングに変換した後は、これらのエンベッディングの適切な保存方法を検討する必要があります。エンベッディングの数が少なければ、デバイスのローカルメモリに直接保存することができます。しかし、実際には数百から数百万の埋め込みを扱うことが一般的です。この場合、Milvus(https://zilliz.com/what-is-milvus)やZilliz Cloud(https://zilliz.com/cloud)のような ベクトルデータベースが必要になります。RAGアプリケーションを成功させるためには、適切なベクトルデータベースを選択することが重要です。
最後の検討事項は、LLMそのものである。もし可能であれば、LLMを微調整することで、我々の特定のニーズをより正確に満たすことができる。しかし、特に多くのパラメータを持つ高性能なLLMを使用する場合、微調整にはコストがかかり、ほとんどの場合不要です。
以下のセクションでは、RAGの各コンポーネントに最適なアプローチについて説明する。次に、これらの最適なアプローチの組み合わせを検討し、パフォーマンスと効率のバランスをとるRAGの導入戦略をいくつか提案する。
クエリの分類
前のセクションで述べたように、RAGは、LLMが正確で文脈に沿った応答を生成することを保証するために有用である。しかし、RAGは応答生成プロセスの実行時間を増加させる。すべてのクエリが検索プロセスを必要とするわけではなく、その多くはLLMが直接処理できる。したがって、コンテキスト検索を必要としないクエリであれば、コンテキスト検索処理をスキップする方が有益である。
応答生成プロセスの前に、クエリがコンテキスト検索を必要とするかどうかを判断するために、クエリ分類モデルを実装することができる。このような分類モデルは、通常、BERTのような教師ありモデルで構成され、クエリが検索を必要とするかどうかを予測することを主な目的としている。しかし、他の教師ありモデルと同様に、推論に使用する前にモデルを訓練する必要があります。モデルを訓練するには、プロンプトの例とそれに対応するバイナリラベルのデータセットを生成する必要がある。
図- クエリ分類データセット例.png](https://assets.zilliz.com/Figure_Query_classification_dataset_example_157161163d.png)
図:クエリ分類データセットの例_ Source
論文](https://arxiv.org/pdf/2407.01219)では、クエリ分類にBERTベース多言語モデルを用いている。学習データには、翻訳、要約、書き換え、文脈内学習など、全部で15種類のプロンプトが含まれている。ラベルは2種類ある:プロンプトが完全にユーザから与えられた情報に基づいており、検索の必要がない場合は「sufficient」、プロンプトの情報が不完全で、専門的な情報が必要であり、検索プロセスが必要な場合は「sufficient」である。このアプローチを用いて、モデルは精度とF1スコアの両方で95%を達成した。
このクエリ分類ステップは、LLMが直接処理できるクエリに対する不必要な検索を回避することで、RAGプロセスの効率を大幅に改善することができる。これはフィルターとして機能し、追加コンテキストを必要とするクエリのみが、より時間のかかる検索プロセスに送られることを保証する。
図-クエリ分類結果.png](https://assets.zilliz.com/Figure_Query_classifier_result_3aaa0173d7.png)
図:クエリ分類器の結果._ ソース
チャンキング手法
チャンキングは、長い入力文書をより小さなセグメントに分割するプロセスを指す。このプロセスは、LLMにより詳細なコンテキストを提供するのに非常に有用である。チャンキングにはいくつかの方法があり、トークン・レベルやセンテンス・レベルのアプローチがある。文レベルでのチャンキングは、単純さとコンテキストの意味的保存のバランスがよくとれていることが多い。チャンキングの方法を選択する際には、チャンクサイズに注意する必要がある。チャンクが短すぎると、LLMに有益なコンテキストを提供できない可能性があるからだ。
図- 長い文書を小さなチャンクに分割する.png](https://assets.zilliz.com/Figure_Splitting_a_long_document_into_smaller_chunks_0929fcee85.png)
図:長いドキュメントを小さなチャンクに分割する。
最適なチャンクサイズを見つけるために、Lyft 2021の文書で評価が行われた。文書の最初の60ページがコーパスとして選ばれ、いくつかのサイズにチャンクされた。そして、LLMを用いて、これら60ページに基づいて170のクエリを生成した。埋め込みにはtext-embedding-ada-002 モデルを用い、LLMにはZephyr 7Bモデルを用いて、選択されたクエリに基づく応答を生成した。
異なるチャンクサイズに対するモデルの性能を評価するために、GPT-3.5ターボを使用した。レスポンスの品質を評価するために、忠実性と関連性という2つの指標を採用した。忠実度は応答が幻覚であるか、検索されたコンテキストと一致するかを測定し、関連性は検索されたコンテキストと応答がクエリと一致するかを測定する。
図-異なるチャンクサイズの比較。.png](https://assets.zilliz.com/Figure_Comparison_of_different_chunk_sizes_4156be62c9.png)
図:異なるチャンクサイズの比較_ Source
この結果から、LLMから関連性の高い応答を生成するには、最大512トークンのチャンクサイズが好ましいことがわかる。256トークンのような短いチャンクサイズも良好なパフォーマンスを示し、RAGアプリケーションの全体的なランタイムを改善することができる。small2bigやスライディングウィンドウのような高度なチャンキング技術は、異なるチャンクサイズの利点を組み合わせるために使用することができる。
Small2bigはチャンクのブロック関係を整理するチャンキング手法である。小さいサイズのチャンクはクエリーのマッチングに使用され、小さいチャンクの情報を含む大きいチャンクはLLMの最終的なコンテキストとして使用される。スライディングウィンドウは、チャンク間のトークン重複を提供し、コンテキスト情報を保持するチャンキング手法である。
図-異なるチャンキング手法の比較.png](https://assets.zilliz.com/Figure_Comparison_of_different_chunking_techniques_2ac7bcdb48.png)
図:異なるチャンキング技術の比較_ Source
実験によると、チャンクサイズを175トークンと小さくし、チャンクサイズを512トークンと大きくし、チャンクの重なりを20トークンとした場合、どちらのチャンキング手法もLLM応答の忠実度と関連性スコアを向上させる。
次に、各チャンクをベクトル埋め込みとして表現するための最適な埋め込みモデルを見つけることが重要である。この目的のために、namespace-Pt/msmarco上でのテストが行われた。その結果、LLM Embedderとbge-large-enの両モデルが最適であることがわかった。しかし、LLM Embedderはbge-large-enより3倍小さいので、実験ではデフォルトの埋め込みとして選ばれた。
namespace-Pt:msmarco.Figure-異なる埋め込みモデルの結果]()。.png](https://assets.zilliz.com/Figure_Results_for_different_embedding_models_on_namespace_Pt_msmarco_5e4b6f5e16.png)
図:namespace-Ptmsmarco.での異なる埋め込みモデルの結果_ Source
ベクターデータベース
ベクトルデータベースは、RAGアプリケーションにおいて、特に関連するコンテキストの保存と検索において重要な役割を果たす。一般的な実世界のRAGアプリケーションでは、膨大な量の文書を扱うため、膨大な数のコンテキスト埋め込みを保存する必要がある。このような場合、これらの埋め込みをローカルメモリに格納することは不十分であり、大量の埋め込みコレクションから関連するコンテキストを検索する計算にはかなりの時間がかかる。
ベクトルデータベースは、このような問題を解決するために設計された。ベクトルデータベースを使えば、数百万から数十億のベクトル埋め込みを保存し、一瞬でコンテキスト検索を実行することができます。ユースケースに最適なベクトルデータベースを選択する際には、インデックスタイプのサポート、億単位のベクトルのサポート、ハイブリッド検索のサポート、クラウドネイティブの機能など、いくつかの要素を考慮する必要がある。
これらの基準の中で、Weaviate、Chroma、Faiss、Qdrantなどの競合と比較して、Milvusは最高のオープンソースベクターデータベースとして際立っています。
 各種ベクターデータベースの比較.png
各種ベクターデータベースの比較.png
様々なベクターデータベースの比較. ソース._.
インデックスタイプのサポート](https://zilliz.com/learn/vector-index)に関しては、Milvusは様々なニーズに対応するために、ナイーブフラットインデックス(FLAT)や、inverted file index(IVF-FLAT)やHierarchical Navigable Small World(HNSW)のような検索プロセスを高速化するために設計されたインデックスタイプなど、いくつかのインデックス方法を提供している。また、コンテキストの格納に必要なメモリを圧縮するために、埋め込みインデックス作成時に積量子化 (PQ)を実装することもできます。
Milvusはハイブリッド検索アプローチもサポートしています。このアプローチにより、文脈検索の過程で2つの異なる手法を組み合わせることができる。例えば、密な埋め込みと疎な埋め込みを組み合わせることで、関連するコンテキストを検索し、クエリに対する検索されたコンテキストの関連性を高めることができる。これにより、LLMが生成する応答も向上する。さらに、必要であれば、密な埋め込みをメタデータフィルタリングと組み合わせることもできる。
GCPでもAWSでも、クラウド上でMilvusを使い、何十億ものエンベッディングを保存したい場合は、 マネージドサービス: Zilliz Cloud を選ぶことができます。
Zilliz Cloudでは、容量と性能の両方に最適化されたクラスタユニット(CU)を作成し、大規模な埋め込みデータを保存することができます。例えば、13億個の128次元ベクトルに対応する256個の性能最適化CUや、30億個の128次元ベクトルに対応する128個の容量最適化CUを作成することができます。
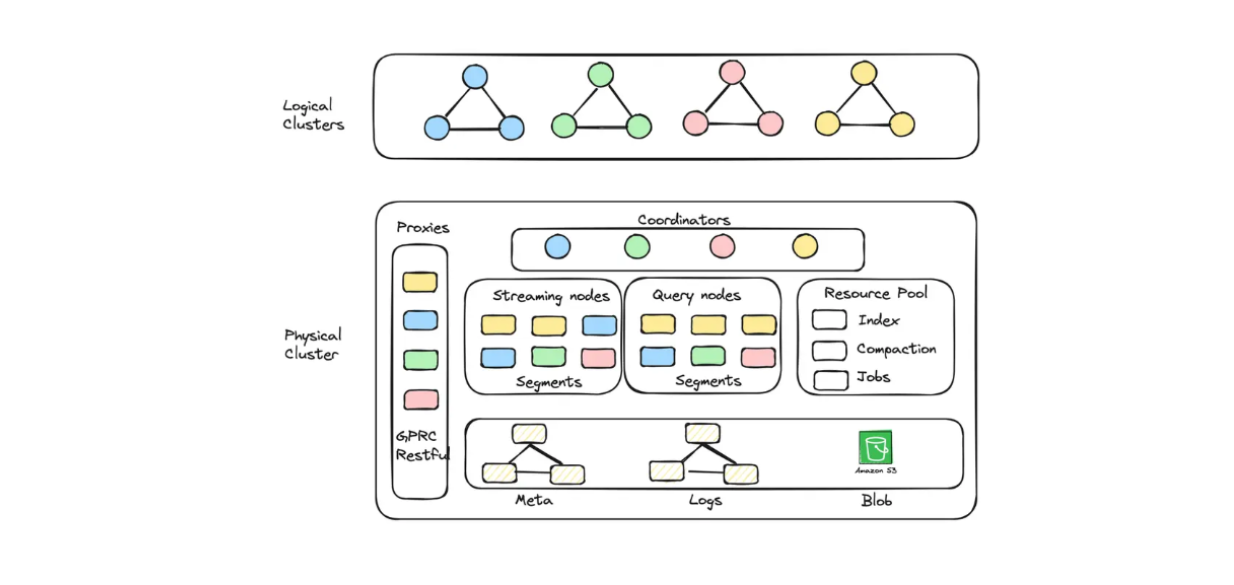 Zillizクラウドサーバーレスに実装された論理クラスタとオートスケーリングの図.png
Zillizクラウドサーバーレスに実装された論理クラスタとオートスケーリングの図.png
Zilliz Cloud Serverlessに実装された論理クラスタとオートスケーリングの図.png]()
MilvusでRAGアプリケーションを構築したいが、運用コストも抑えたいという方は、 Zilliz Cloud Serverless を選択することができます。このサービスはMilvusのオートスケーリング機能を提供し、ビジネスの成長に応じてのみコストが増加します。また、サーバーレスオプションは、アイドル時ではなく、サービスを利用した時のみ料金を支払うため、コスト削減に最適です。
Zilliz Cloudは最近、新しいマイグレーションサービス、複数のレプリカ、Fivetranコネクタとの新しい統合、オートスケーリング機能、その他多くの本番環境対応機能など、複数のエキサイティングなアップデートを開始した。詳細は以下をご覧ください:
Zilliz Cloudアップデート:マイグレーションサービス、Fivetranコネクタ、マルチレプリカ、その他](https://zilliz.com/blog/zilliz-sep-24-launch)
Zilliz Cloudにおけるモニタリングと監視機能の強化](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
FivetranとMilvusでAIを活用した検索を実現】(https://zilliz.com/blog/unlock-ai-powered-search-with-fivetran-and-milvus)
オープンソースMilvusからZilliz Cloudへ移行する5つの理由 ](https://zilliz.com/blog/top-5-reasons-to-migrate-milvus-to-zilliz-cloud)
検索テクニック
検索コンポーネントの主な目標は、与えられたクエリに対して最も関連性の高い上位k個のコンテキストをフェッチすることである。しかし、RAGの全体的な品質に影響を与える可能性のあるこのコンポーネントの重要な課題は、クエリ自体に由来する。元のクエリは、多くの場合、RAGアプリケーションが関連するコンテキストをフェッチするために必要な意味的な情報を欠いている、不十分な書き方や表現である。
この問題を解決するために一般的に適用されている技術には、以下のようなものがある:
クエリの書き換え:クエリの書き換え:元のクエリを書き直すようLLMに促し、クエリの明確さと意味情報を改善する。
クエリの分解:**元のクエリをサブクエリに分解し、これらのサブクエリに基づいて検索を実行する。
擬似文書生成:元のクエリに基づいて仮想的または合成的な文書を生成し、これらの仮想文書を使用してデータベース内の類似文書を検索する。この手法の最も有名な実装はHyDE (Hypothetical Document Embeddings)である。
実験によると、HyDEとハイブリッド検索を組み合わせることで、TREC DL19/20において、クエリ書き換えやクエリ分解と比較して最高の結果が得られた。実験に挙げたハイブリッド検索は、密な埋め込みを得るためにLLM Embedderを組み合わせ、疎な埋め込みを得るためにBM25を組み合わせている。
HyDe+ハイブリッド検索のワークフローは以下の通り:まず、HyDEでクエリに答える仮想文書を生成する。次に、この仮説的文書を元のクエリと連結してから、それぞれLLM EmbedderとBM25を使って[密埋め込み]と疎埋め込みに変換する。
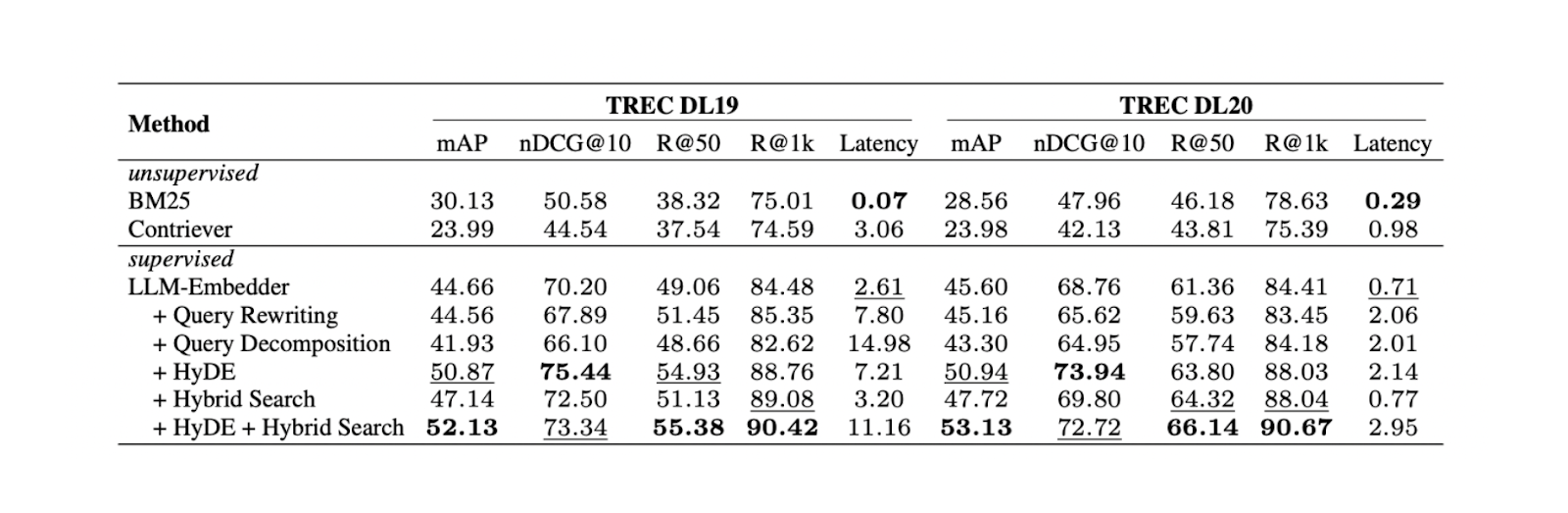 検索方法を変えた場合の結果。.png
検索方法を変えた場合の結果。.png
異なる検索方法の結果._ ソース
HyDEとハイブリッド検索の組み合わせは最良の結果をもたらすが、計算コストも高くなる。いくつかのNLPデータセットでの更なるテストに基づくと、ハイブリッド検索と密な埋め込みのみを使用した検索はどちらもHyDE+ハイブリッド検索と同等の性能をもたらすが、レイテンシはほぼ10倍低くなる。したがって、ハイブリッド検索を使うことがより推奨されるだろう。
我々はハイブリッド検索を使っているので、検索されたコンテキストは密な埋め込みと疎な埋め込みからベクトル検索に基づいている。したがって、この式に従って、密な埋め込みと疎な埋め込み間の重み付け値が、全体の関連性スコアに与える影響を調べることも興味深い:
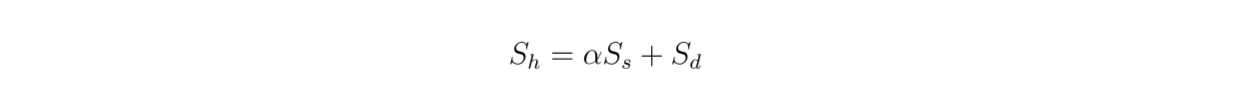 数式.png
数式.png
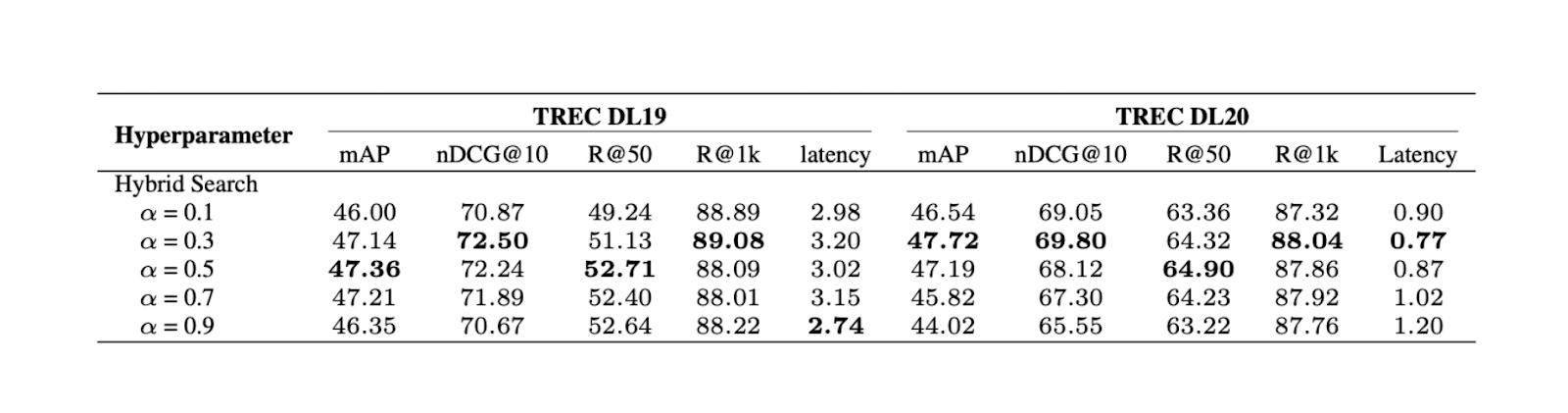 図-アルファ値を変えたハイブリッド検索の結果.png
図-アルファ値を変えたハイブリッド検索の結果.png
図:アルファ値を変えたハイブリッド検索の結果 Source._.
この実験から、TREC DL19/20では、重み付け値0.3が最高の総合関連性スコアをもたらすことがわかる。
再ランク付けと再パッキングのテクニック
再ランク付け技術](https://zilliz.com/learn/what-are-rerankers-enhance-information-retrieval)の主な目的は、検索メソッドからフェッチされた最も関連性の高い上位k個のコンテキストを並べ替え、最も類似したコンテキストがリストの先頭に返されるようにすることである。コンテキストを再順序付けするには、2つの一般的なアプローチがある:
DLM再順位付け**:この方法では、再ランク付けにディープラーニングモデルを使用する。このモデルは、元のクエリとコンテキストからなるペアを入力として、バイナリラベル「true」(ペアが互いに関連する場合)または「false」を出力として学習される。コンテキストは、モデルがクエリとコンテキストのペアを "true "と予測したときに返す確率に基づいてソートされる。
TILDE Reranking**:このアプローチは、元のクエリにおける各用語の尤度を再ランク付けに使用する。推論時に、クエリ尤度コンポーネント(TILDE-QL)だけを使用してリランキングを高速化するか、TILDE-QLと文書尤度コンポーネント(TILDE-DL)を組み合わせて、より高い計算コストでリランキング結果を改善することができる。
図-異なるリランキング手法の結果.png](https://assets.zilliz.com/Figure_Results_of_different_reranking_methods_0174dc1792.png)
図:異なる再ランク付け方法の結果._ ソース
MS MARCO Passageランキングデータセットでの実験によると、Llama 27Bモデルを用いたDLMリランキング法が最も優れたリランキング性能を示した。しかし、Llama 27Bは大きなモデルであるため、これを使用するには多大な計算コストがかかる。したがって、DLMリランキングでは、性能と計算効率のバランスがとれるmono T5の使用がより推奨される。
リランキングフェーズの後、リランキングされたコンテキストをどのようにLLMに提示するかについても検討する必要がある。本稿で実施した実験に基づくと、「逆順」構成で最も良い応答品質が生成されると結論づけることができる。仮説は、より関連性の高いコンテキストをクエリの近くに配置することで、最適な結果が得られるというものである。
要約テクニック
前のコンポーネントから取得した長いコンテキストがある場合、それらをよりコンパクトにし、冗長な情報を取り除きたいと思うかもしれない。この目的を達成するために、要約のアプローチが一般的に実装されている。
コンテキストの要約手法には2種類ある:**抽出的手法と抽象的手法である。
抽出的要約は入力文書をより小さなセグメントに分割し、重要度に基づいてランク付けする。一方、抽象的要約法は、関連する情報のみを含む新しいコンテキスト要約を生成する。
図-異なる要約方法の比較.png](https://assets.zilliz.com/Figure_Comparison_between_different_summarization_methods_3e8e54c91c.png)
図:異なる要約方法の比較_ Source
3つの異なるデータセット(NQ、TriviaQA、HotpotQA)での実験に基づくと、Recompを用いた抽象的要約は、他の抽象的手法や抽出的手法と比較して最高のパフォーマンスをもたらす。
最良のRAG手法のまとめ
特定のベンチマークデータセットに対するRAGの各コンポーネントの最適なアプローチがわかったので、さらに多くのデータセットで前のセクションで述べたすべてのアプローチをテストすることができる。その結果、各コンポーネントがRAGアプリケーションの全体的な性能に貢献していることがわかった。以下は、5つの異なるデータセットに基づく各コンポーネントの各アプローチの結果の要約である:
図-最適なRAGプラクティスの探索結果.png](https://assets.zilliz.com/Figure_Results_of_the_search_for_optimal_RAG_practices_5d8abe4f90.png)
図:最適なRAGプラクティスの探索結果._ Source
クエリ分類コンポーネントは、応答の精度を向上させ、全体的なランタイムレイテンシを削減するのに役立つことが証明されている。この最初のステップは、クエリがコンテキスト検索を必要とするか、LLMによって直接処理できるかを決定するのに役立ち、システムの効率を最適化する。
検索コンポーネントは、クエリに関して関連するコンテキスト候補を確実に得るために重要である。このコンポーネントには、MilvusやそのマネージドサービスであるZilliz Cloudのような、よりスケーラブルで高性能なベクトルデータベースが推奨される。さらに、ハイブリッド検索や密な埋め込み検索を推奨する。これらの方法は、包括的なコンテキスト・マッチングと計算効率のバランスをとる。
再順序付けコンポーネントは、検索コンポーネントから取得された上位k個のコンテキストを再順序付けすることで、最も関連性の高いコンテキストを確実に取得する。monoT5モデルは、性能と計算コストのバランスから、再ランク付けに推奨される。このステップでは、コンテキストの選択を絞り込み、クエリに最も関連するコンテキストを優先する。
コンテキストを再パックするには、逆の方法が推奨される。このアプローチでは、最も関連性の高いコンテキストがクエリに最も近い位置に配置されるため、LLMからの応答がより正確で首尾一貫したものになる可能性がある。
最後に、Recompを用いた抽象化手法は、コンテキストの要約において最高の性能を示した。この手法は、重要な情報を保持したまま長いコンテキストを凝縮するのに役立ち、LLMが処理しやすく、関連性の高い応答を生成しやすくする。
LLMの微調整
多くの場合、LLMの微調整は必要ありません。特に、多くのパラメーターを持つ高性能なLLMを使っている場合はそうです。しかし、ハードウェアの制約があり、より小さなLLMしか使えない場合は、ユースケースに関連するレスポンスを生成する際に、よりロバストになるようにLLMを微調整する必要があるかもしれません。LLMを微調整する前に、トレーニングデータとして使用するデータを検討する必要があります。
データ準備中に、プロンプトとコンテキストのトレーニングデータを入力のペアとして収集し、生成されたテキストの例を出力として使用することができます。実験によると、トレーニング中に、関連するコンテキストとランダムに選択されたコンテキストを混ぜてデータを補強すると、最高のパフォーマンスが得られる。この背景には、微調整の際に関連するコンテキストとランダムなコンテキストを混ぜることで、LLMのロバスト性を向上させることができるという直観がある。
結論
本稿では、クエリの分類からコンテキストの要約に至るまで、様々なRAGのコンポーネントを探索した。各コンポーネントにおいて最適なパフォーマンスを持つアプローチを議論し、強調した。
これらの最適化されたコンポーネントは、RAGシステムの全体的なパフォーマンスを向上させるために協働する。計算効率を維持しながら、生成される回答の品質と関連性を向上させているのだ。これらのベストプラクティスを各コンポーネントに実装することで、様々なクエリやタスクに対応できる、より強固で効果的なRAGシステムを構築することができる。
続きを読む
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
MilvusでAIアプリを作る:チュートリアル&ノートブック](https://zilliz.com/learn/milvus-notebooks)
Milvus、LangChain、OpenAIを使った多言語RAGの作り方】(https://zilliz.com/blog/building-multilingual-rag-milvus-langchain-openai)
Gemini、BGE-M3、Milvus、LangChainを使った多言語RAGの構築](https://zilliz.com/learn/build-multimodal-rag-gemini-bge-m3-milvus-langchain)
GraphRAGとは? 知識グラフでRAGを拡張する ](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
RAGアプリケーションの評価方法 ](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)

読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.