




LLaVA:視覚命令チューニングによる視覚言語モデルの進化
ChatGPT、LLAMA、Claude Sonnetのような最新の大規模言語モデル(LLMs)は、人間の言語ベースの指示が応答品質を向上させるための強力なツールになることを実証している。プロンプトエンジニアリング](https://zilliz.com/glossary/prompt-as-code-(prompt-engineering))のようなテクニックを使うことで、LLMが私たちの特定のユースケースにより近い応答を生成するように導くことができる。
当初、LLMはテキストベースの入力専用に設計されていた。LLMは、テキストによる指示が与えられると、それに対応する応答を生成する。このアプローチは大きな成功を収めたが、この機能を視覚的入力に拡張することは自然な流れである。視覚ベースのモデルは、テキスト命令と画像の両方を入力として受け取り、画像の内容を要約したり、情報を抽出したり、画像内のテキストを翻訳したりといったタスクを可能にする。
この記事では、ビジュアルベースモデルにテキストベースの命令を実装する先駆的な取り組みの1つである、LLaVA (Large Language and Vision Assistant)について説明します。その実装について詳しく説明する前に、ビジュアル・ベース・モデルの進化と、それがどのようにこの分野を変革しつつあるのかを理解するために、一歩下がってみましょう。
ビジュアル・ベース・モデルの発展
初期の開発段階では、視覚ベースのモデルのほとんどは、一般的な視覚タスクを実行するために、畳み込みニューラルネットワーク(CNN)ベースのアーキテクチャに依存していました。最も単純な形では、視覚ベースのモデルは、与えられた画像が犬か猫かを判断するような単純な画像分類タスクを実行するために、一対のCNN層で構築することができる。
しかし、より複雑な画像をより多くのクラスで分類するためには、数百のCNN層からなるより深いモデルを構築する必要がある。モデルの層が深くなればなるほど、消失勾配問題に遭遇するリスクは高くなる。消失勾配とは、モデル学習中に勾配が非常に小さくなり、モデルが何も学習できず、重みを更新できなくなる現象を指す。
この問題に対処するため、residual connectionsのような洗練されたアルゴリズムがモデルのアーキテクチャ内に実装され、ディープラーニングモデルで一般的に発生する消失勾配問題を回避した。この方法は効果的であることが証明され、ResNetの創始につながり、その後多くの画像分類ベンチマークデータセットで最先端の性能を達成した。
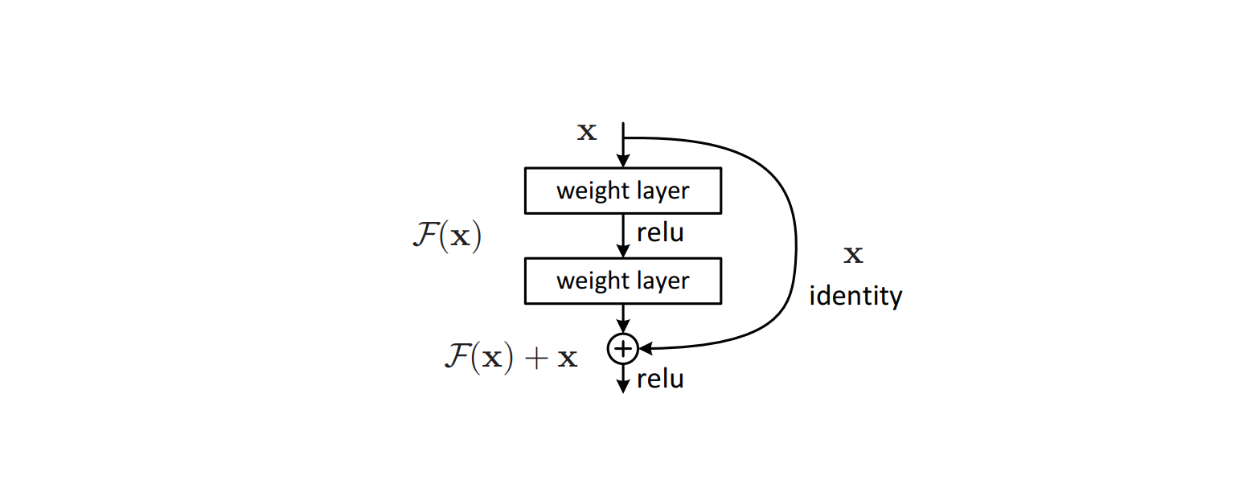
図:モデルのアーキテクチャ内部の残差接続のビルディングブロック_ Source..
ResNetの成功は、より複雑な画像タスクを実行できる他のモデル・アーキテクチャにインスピレーションを与えました。YOLOのような視覚モデルは、物体検出タスクを実行するために、そのアーキテクチャに残差接続を実装しました。同時に、U-NetはU字型アーキテクチャと残差結合を組み合わせて画像分割タスクを実行した。
これらの視覚モデルは視覚ベースのタスクを実行できるが、それぞれが実行できるのは特定の1つのタスクのみである。画像分類のために学習されたモデルは、その目的にしか使用できない。さらに、学習データと大きく異なる画像を分類するようモデルに求めると、モデルの予測にランダム性が見られることがあります。
2017年に有名なTransformersモデルが登場したことをきっかけに、ディープラーニングモデル全般が急速に発展した。Transformersをアーキテクチャに採用したモデルは、より伝統的なモデルを大幅に上回った。当初はテキストベースのモデルのみを対象としていたが、Transformersアーキテクチャは視覚ベースのモデルにも使用できるほど汎用性が高いことが証明された。
Vision Transformers (ViT)](https://zilliz.com/learn/understanding-vision-transformers-vit)のようなTransformersベースの視覚モデルは、画像分類タスクの実行において高い能力を示した。その結果、ViTは現在、CLIP,のような多くの一般的なテキストビジョンモデルにバックボーンアーキテクチャとして使用されている。
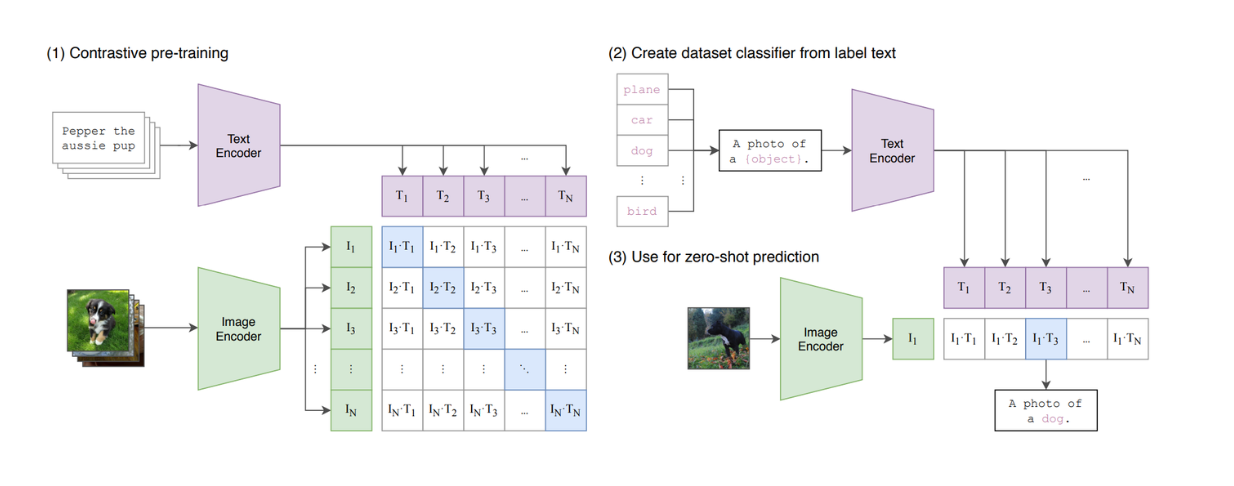
図:CLIPモデルの概要_ ソース..
CLIPは、そのアーキテクチャにおいて、ViTとBERT類似モデルを組み合わせたモデルである。ViTは画像入力を処理し、BERT様モデルはテキスト入力を処理する。CLIPは対照学習を使って学習されており、入力ペアとしてテキストと画像が与えられると、CLIPはテキストと画像の間の類似度を計算する。しかし、CLIPは生成モデルではないため、テキストベースのLLMを模倣するという点ではまだ限界があることがわかる。
LLaVAは、テキストベースの指示と画像を入力として受け取り、適切な応答を生成することができる、最も初期の視覚ベースのLLMの一つである。 LLaVAの詳細については次節で説明する。
LLaVaとは?
LLaVA(Large Language and Vision Assistant)は、テキストベースの大規模言語モデル(LLM)と視覚処理機能を組み合わせたマルチモーダルモデルで、テキストと画像の入力を扱うことができる。視覚コンテンツの要約、画像からの情報抽出、視覚データに関する質問への回答などのタスクを実行するように設計されています。
LLaVAは、LLMの成功の上に、視覚的理解を取り入れ、テキストベースの指示を画像解析と整合させることによって構築されている。この統合により、このモデルは、テキストプロンプトと画像という対になった入力を処理し、首尾一貫した、文脈に関連した応答を提供することができる。
LLaVA アーキテクチャ
LLaVAのアーキテクチャは比較的シンプルである。テキスト命令を処理するために事前に訓練されたLLMを使用し、画像情報を処理するために事前に訓練されたViTモデルであるCLIPの視覚エンコーダを使用する。
LLaVAの作者は、一般に公開されているいくつかの事前学習済みLLMの中から、Vicunaをバックボーンとして選び、テキスト情報を処理し、テキストと画像のペアの入力が与えられたときに、最終的な応答を生成するようにした。
ほとんどのテキストベースLLMはTransformerアーキテクチャをベースにしているため、応答生成までのテキスト変換プロセスは非常に単純である。入力テキストの各トークンは埋め込みに変換され、その後、固定サイズの次元を持つ最終的な特徴出力を生成する前に、注目層と高密度層のいくつかのスタックを通過する。
画像入力を処理するために、LLaVAはCLIP内部の事前学習されたViTモデルを用いて、入力画像を固定サイズの次元を持つ特徴表現に変換する。しかし、CLIPから得られる画像特徴量の次元は、Vicunaから得られるテキスト特徴量とは異なる。そこでLLaVAでは、画像特徴量をVicunaからのテキスト特徴量と同じサイズに投影するために、単純な密なレイヤーを後から実装する。
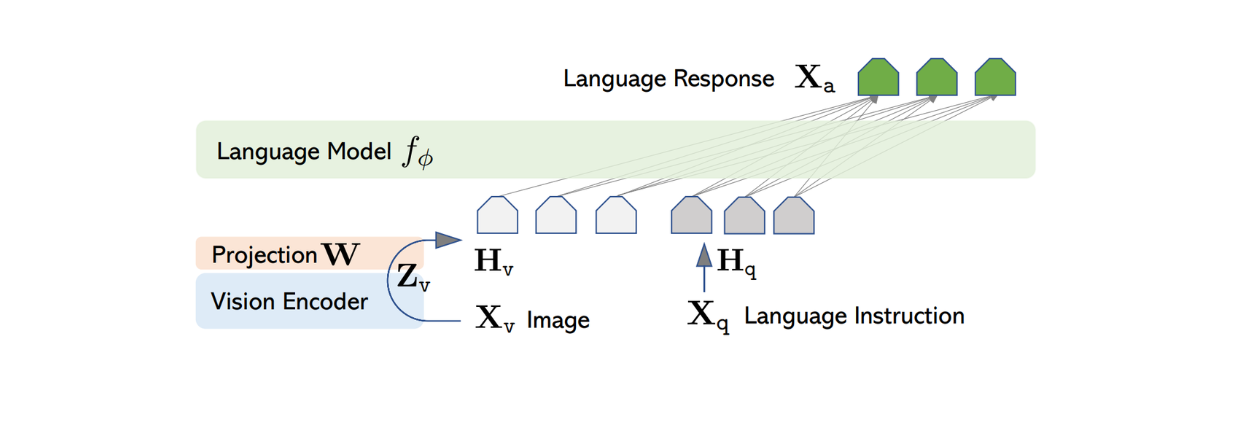
図:LLaVAのアーキテクチャ出典。
画像特徴とテキスト特徴が同じサイズになった今、これら2つの特徴を1つにまとめるアプローチが必要です。例えば、トークン特徴の前に画像特徴を付加する方法([画像特徴] + [テキスト特徴])や、ゲーテッドクロスアテンションやQ-formerのような高度なアルゴリズムを使用する方法があります。画像特徴とテキスト特徴の組み合わせがVicunaに入力され、適切な応答が生成される。
しかし、上記のようなアプローチを採用した場合、Vicunaや他の同様のLLMが生成するレスポンスの質は最適とはならない可能性がある。これは、LLMが純粋にテキストデータに基づいて学習されることから予想されることである。そのため、LLaVAは画像とテキストの入力ペアに基づいて首尾一貫した応答を生成できるようになる前に、微調整を行う必要がある。この微調整プロセスは視覚命令チューニングと呼ばれ、次のセクションで説明する。
視覚命令チューニングのためのデータ生成プロセス
ビジュアル・インストラクション・チューニングは、画像や動画などの視覚入力と対になったテキストベースの指示を理解し応答するために、マルチモーダルAIモデルを訓練するプロセスである。この技術により、視覚的理解と自然言語処理機能が連携し、画像キャプション、視覚的質問応答、物体認識、情報抽出などのタスクをモデルが実行できるようになります。
視覚的インストラクションチューニングの重要な課題の1つは、一般に利用可能なマルチモーダルインストラクションフォローデータの不足である。CCやLAIONのような画像とテキストのペアで構成されるデータセットはいくつか存在するが、それらは我々が視覚ベースのLLMをユーザーの指示に従うように微調整するために使いたいタイプのデータセットではない。
図:CCデータセットの例。出典。
一方、LLaVAをチューニングするために大量のマルチモーダルな指示追従データを手作業で作成するには、多大な労力と時間を必要とします。そこで、GPT-4やChatGPTを活用することで、マルチモーダルな指示追従データの作成プロセスを高速化することができます。
上記のCC画像の例に見られるように、一般的なマルチモーダルデータセットは、各データレコードの画像とキャプションテキストの組で構成されています。ChatGPTを使えば、画像とそのキャプションが与えられたとき、画像の内容を説明するようLLMに指示することを意図した、可能な質問のセットを生成することができる。マルチモーダルな指示フォローデータのフォーマットは次のようになる:Human: Xq Xv
しかし、ChatGPTはテキストしか入力できないことが分かっています。特定の画像に関する質問のリストを作成するために使用するには、画像に関する情報やメタデータを提供する必要があります。著者らは、ChatGPTに任意の入力画像に関する必要な情報を与えるために、2つの異なるアプローチを使用しました:キャプションとバウンディングボックスです。キャプションは通常画像の詳細な説明からなり、バウンディングボックスは画像内のオブジェクトの正確な位置に関する有用な情報をChatGPTに提供します。

図:キャプションとバウンディングボックスの例。出典。
著者らは、3種類のマルチモーダルな指示追従データセットを作成した:
1.会話:これは、LLMとユーザの間の前後の会話からなる。LLMの回答は、画像を見ているようなトーンで設定され、ユーザーの質問に答える。典型的な質問には、画像の視覚的な内容、画像内のオブジェクトのカウント、画像内のオブジェクトの相対的な位置などが含まれます。
2.詳細説明:画像の包括的な説明を生成することを目的とした質問のリストから構成される。
3.複雑な推論:上記2つのタイプを超える質問で構成される。これらの質問は、単に画像の視覚的な内容を説明するのではなく、LLMにその回答の背後にある論理を説明させることを目的としており、段階的な推論を必要とします。

図:図:3つのタイプのマルチモーダルな指示に従うデータセットの例_ Source..
以下は、著者らが会話型データセットを生成するために用いたプロンプトの例である:
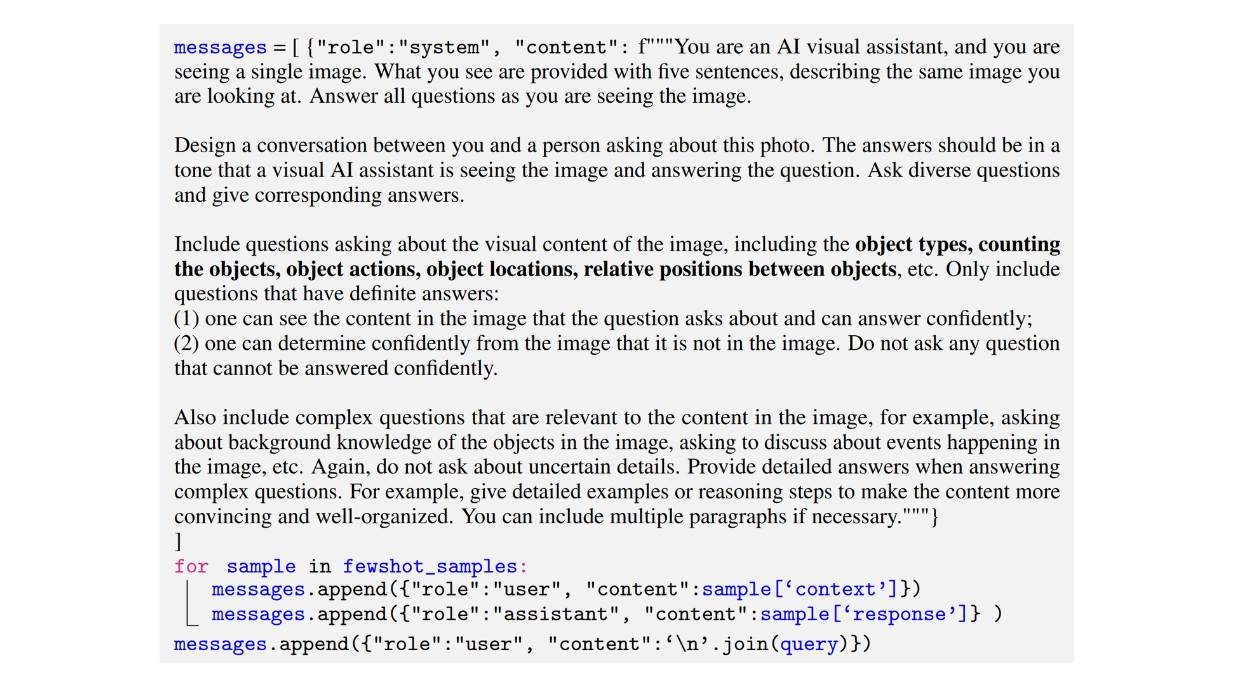
図:会話型マルチモーダル指示追従データセットの生成に用いたプロンプトの例_ Source..
LLMで生成されたマルチモーダル指示追従データから、正しいフォーマットで目的の出力を得るのは、かなり厄介です。そのため、ChatGPTに3種類すべてのマルチモーダル指示追従データセットを生成させる際、著者らはコンテキスト内学習の力を活用するために、数ショットのサンプルを使用した。
数ショットのサンプルでは、著者らはプロンプトと一緒に、LLMとユーザーとの会話例をいくつか手動で作成しました。これらのサンプルはChatGPTが期待されるアウトプットの構造を理解するのに役立ちます。以下は著者らが会話データセットを生成するためにプロンプトに実装した数ショットサンプルの例である。

図:図:文脈内学習のためにプロンプトと一緒に渡される数ショットの例_ ソース..
LLaVA の学習手順
上記のアプローチで生成されたマルチモーダルな指示追従データの合計は約158Kであった。次に、これらのマルチモーダルデータを用いてLLaVAモデルの微調整を行った。
このデータセットでは、各画像Xvに対して、LLMとユーザとの間で複数ターンの会話(X1q, X1a, - - , XTq, XTa)があり、Tはターンの総数である。各ターンtについて、答えXtaはLLMの応答として扱われるので、ターンtでの命令は次のようになる:
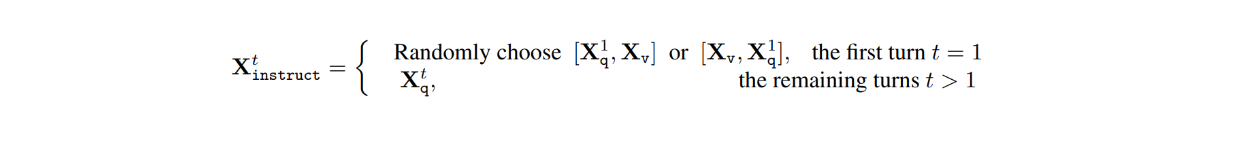
次に、視覚命令のチューニング過程では、特徴アライメントのための事前学習と、エンド・ツー・エンドの微調整の2段階が行われた。
特徴整列のための事前訓練段階では、主な目的は、事前訓練されたCLIPエンコーダからのViTモデルの出力を、テキスト特徴と同じ次元を持つ最終的な視覚特徴にマッピングする投影層を訓練することである。この段階では、596Kの画像とテキストのペアを含むフィルタリングされたCCデータセットを用いて学習が行われた。各画像Xvに対して、質問Xqが質問のプールからランダムにサンプリングされ、対応するXcがグランドトゥルースラベルとして使用される。したがって、トレーニングのためにサンプリングされた質問は、下の画像でわかるように、LLMに画像を簡単に説明するよう求めるものです:

図:画像の内容を簡潔に説明するプロンプトの例_ Source..
投影層の学習だけなので、この段階ではViTとLLMの重みは凍結されている。
一方、エンド・ツー・エンドの微調整である第2段階では、158Kで生成されたマルチモーダル命令追従データを用いてLLaVAモデルを微調整する。この段階では、ViTの重みのみが凍結され、投影層とLLMの重みは微調整の過程で更新される。
LLaVAの結果
LLaVAの性能を評価するために、GPT-4のような他の最先端モデルや、BLIP-2やOpenFlamingoのような視覚ベースのモデルとの比較が行われた。結果の評価では、著者らはテキストのみのGPT-4を審査員として使用し、有用性、関連性、正確性、詳細度に基づいて回答の品質をスコア化した。
最初の評価として、COCO-Val-2014データセットからランダムに30枚の画像を選択し、前節で説明したデータ生成プロセスを用いて、3種類のデータセットを生成した。その結果、合計90点のデータが得られた:会話30点、詳細説明30点、複雑な推論30点である。次に、LLaVAからの回答を、ラベルとしてテキスト記述/キャプションを、視覚入力としてバウンディングボックスを使用するテキストのみのGPT-4モデルからの出力と比較した。結果は以下の通りである:
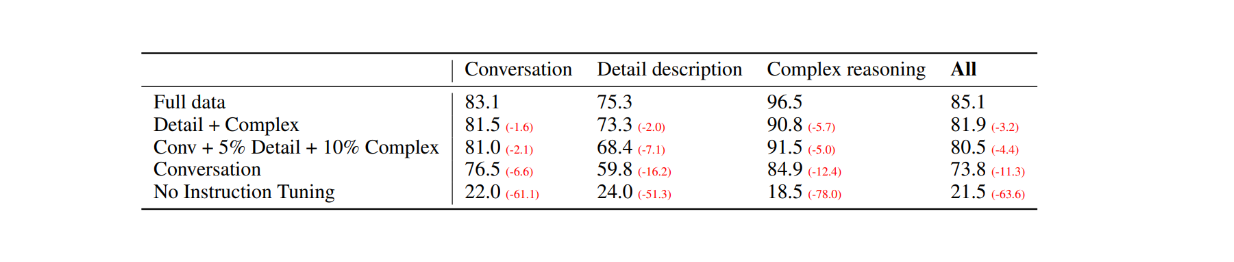
図:30枚のランダム画像に対するLLaVAとテキストのみのGPT-4の性能比較_ Source..
視覚的指示のチューニングにより、モデルの指示に従う能力は、各データセットタイプで少なくとも50ポイント増加した。一方、LLaVAの相対スコアは、各カテゴリの括弧内の数字が示すように、画像のキャプションを視覚入力として使用するテキストのみのGPT-4モデルと比較して、遠く及ばなかった。
LLaVAの性能は、BLIP-2やOpenFlamingoのような視覚ベースのモデルとも比較された。下の表に示すように、LLaVAの性能は他の2つの視覚ベースモデルよりはるかに優れている。これは、BLIP-2やOpenFlamingoがマルチモーダルな指示追従データセットを用いて明示的にファインチューニングされていないため、視覚的指示チューニングの威力を示しています。

図:LLaVAとBLIP-2およびOpenFlamingoの性能比較_ ソース..
それでは、モデルの反応の例を実際に見てみよう。チキンナゲットが世界地図を形成している写真を考え、"_このミームを詳しく説明できますか?"と尋ねます。以下は、LLaVA、テキストのみのGPT-4、BLIP-2、OpenFlamingoの回答例です。

図:LLaVA、GPT-4、BLIP-2、OpenFlamingoからの回答例_ ソース..
ご覧のように、BLIP-2とOpenFlamingoの両モデルは、視覚的な命令チューニングを施していないため、命令に従うことができなかった。一方、LLaVAはユーモアの理解において視覚的推論能力を発揮した。GPT-4と並んで、指示通りの簡潔な答えを出すことができた。
また、ScienceQAデータセットを約12エポック微調整した場合、LLaVAは、このデータセットにおける現在の最先端モデル(SOTA)であるMM-CoTモデルと比較して、非常に競争力のある結果を達成した。以下の表に示すように、LLaVAは、MM-CoTモデルの91.68%と比較して、複数の異なる被験者にわたって90.92%の総合的な精度を達成しました。しかし、LLaVAの出力をGPT-4と組み合わせると、ScienceQAデータセットにおいて92.53%の精度で新たなSOTAを達成しました。
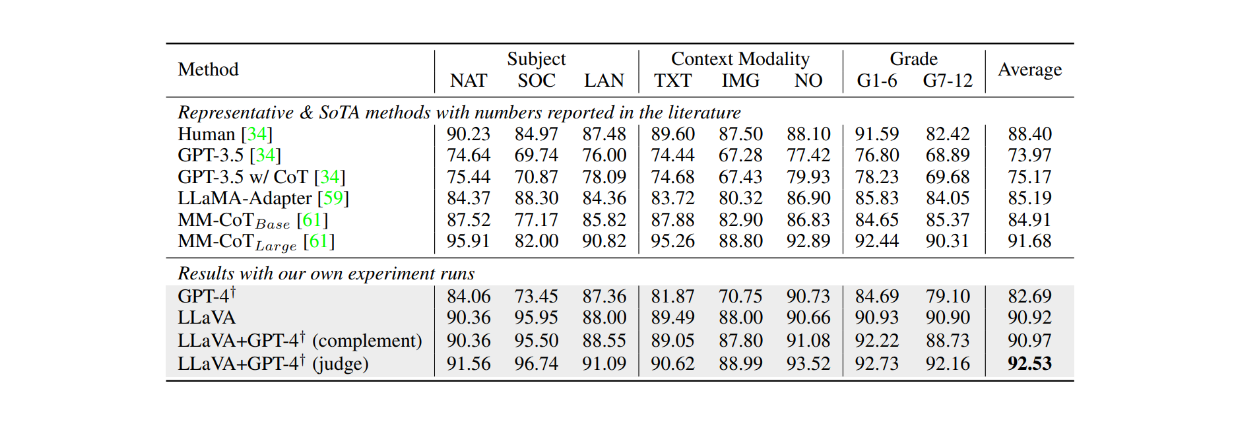
図:ScienceQAデータセットにおけるLLMの精度_ ソース..
結論
LLaVAは、テキストの指示に従うことができる視覚ベースの大規模言語モデル(LLM)の開発における初期の進歩である。このモデルは、CLIPのVision Transformer(ViT)を画像処理用に事前に訓練し、Vicunaを言語モデルのバックボーンとして組み合わせたもので、2つのコンポーネント間の特徴次元を揃えるために射影レイヤーを使用している。このモデルは、15万8000個のマルチモーダル指示に従うデータサンプルで微調整される。
この視覚的命令チューニングアプローチのおかげで、LLaVAは、プロンプト内の命令に従って、与えられた画像上で複雑な推論を記述し、実行することができる。評価結果は、LLaVAの性能が他の2つの視覚ベースモデルを一貫して上回ることから、視覚命令チューニングの有効性を実証している:BLIP-2とOpenFlamingoである。
参考文献
ALIGNモデル解説 ](https://zilliz.com/learn/align-explained-scaling-up-visual-and-vision-language-representation-learning-with-noisy-text-supervision)
ColPali: VLMとColBERTエンベッディングによるより良い文書検索 ](https://zilliz.com/blog/colpali-enhanced-doc-retrieval-with-vision-language-models-and-colbert-strategy)
Mamba: A Potential Transformer Replacement ](https://zilliz.com/learn/mamba-architecture-potential-transformer-replacement)
検出トランスフォーマー(DETR)とは何か ](https://zilliz.com/learn/detection-transformers-detr-end-to-end-object-detection-with-transformers)
ColBERT: トークン・レベルの埋め込みとランキング・モデル ](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
XLNet: 一般化された自己回帰的事前学習による自然言語処理強化](https://zilliz.com/learn/xlnet-explained-generalized-autoregressive-pretraining-for-enhanced-language-understanding)
ベクトルデータベースとは何か?
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)

読み続けて

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.