




ディープシーク対オープンAI:現代AIにおける革新の戦い
#はじめに
AI技術の急速な進歩により、複雑なタスクに秀でるだけでなく、幅広い用途にシームレスに適応し、業界を問わずその有用性を高めるモデルが登場しています。この分野のパイオニアであるOpenAIは、自然言語処理と機械学習機能を再定義する革新的なモデルで境界を押し広げ続けています。これらの進歩はイノベーションの波を引き起こし、AIをより身近で効率的なものにし、かつては手が届かないと思われていたタスクを実行できるようにした。
しかし、OpenAIの優位性は、現在、中国のAI企業であるDeepSeekのような新興の競合他社によって挑戦されている。DeepSeekは、DeepSeek R1を発表しており、利用可能な最も高度なモデルのいくつかに匹敵するオープンソースモデルである。DeepSeek R1は、コスト効率を重視し、運用コストを大幅に抑えながらハイエンドモデルの性能に匹敵する能力を備えている点で際立っている。この新興プレーヤーは、特に性能と手頃な価格のバランスを求める組織や開発者の注目を集め始めている。
このブログでは、OpenAIの2つの傑出したモデル、高度な推論能力と意図的な「反応する前に考える」アプローチで有名なOpenAI o1と、STEMアプリケーションに最適化された、より高速でコスト効率の高いOpenAI o3-miniを紹介します。さらに、DeepSeek R1とこれらのモデルを比較します。それぞれの主な特徴、性能ベンチマーク、ユースケースを検証することで、研究、ソフトウェア開発、ヘルスケアなど、複雑な推論とコスト効率が最重要視される分野に携わる皆様が、特定のニーズに適したAIモデルを選択するためのヒントを提供することを目的としています。
OpenAI o1の概要
2024年9月(プレビュー版、フルバージョンは2024年12月リリース)に発表されたOpenAI o1は、AI推論における大きな飛躍を象徴しています。o1 はその前身とは異なり、chain-of-thought 推論アプローチを用いて複雑なマルチステップタスクに取り組むよう特別に設計されており、大規模 強化学習 によって強化されています。この革新的な方法によって、モデルは問題を段階的に考えることができるようになり、問題解決能力が向上し、困難なシナリオにおける論理的推論と意思決定に特に効果的となる。
主な特徴
モデルアーキテクチャ:OpenAI o1 は、推論と問題解決に最適化された 変換器ベース アーキテクチャ上に構築されています。拡張された思考の連鎖を生成する独自のメカニズムを採用しており、モデルが答えを提供する前に、より深く、より徹底的な分析を行うことができます。この拡張推論プロセスにより、複雑なクエリの精度と信頼性が向上します。
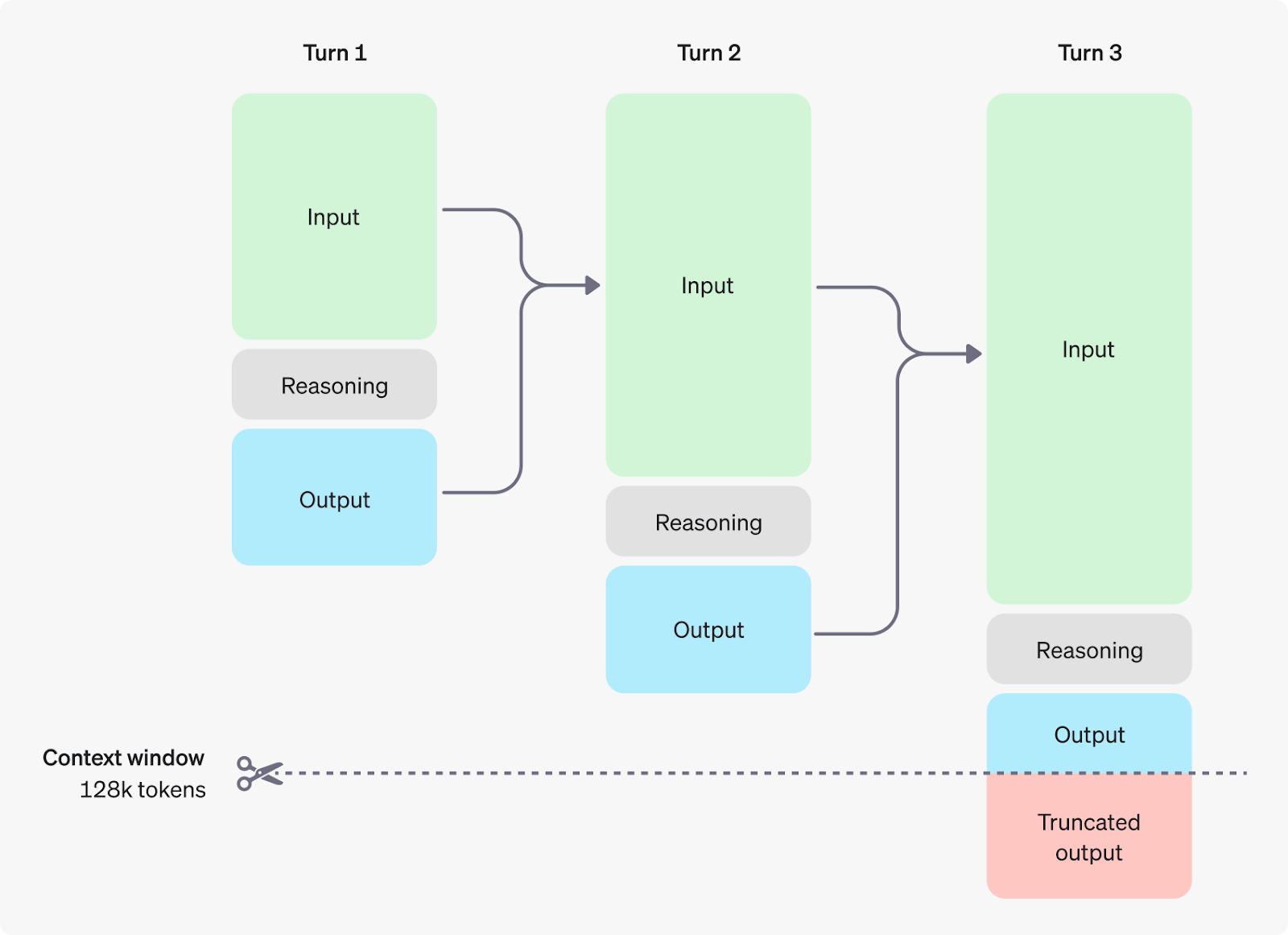
図1:推論トークンによるマルチステップ会話(Source)_。
**学習データOpenAI o1は、その推論と技術的能力を強化するために、フィルタリングされた一般に利用可能なデータセットとパートナーシップからの専有データの組み合わせで訓練された。学習データには、ウェブデータ、オープンソースデータセット、推論データセット、有料コンテンツ、専門アーカイブ、業界固有のリソースが含まれ、一般知識と複雑な問題解決の両方で強力なパフォーマンスを保証します。
パフォーマンスベンチマーク:OpenAI o1は、推論プロセスによりGPT-4oのような初期のモデルよりも遅いですが、複雑なタスク、特に科学、数学、コーディングのようなSTEM分野では、常に高い精度を誇っています。米国数学検定試験(AIME)では83%という驚異的な成績を収め、Codeforcesの競技プログラミング課題では89パーセンタイルにランクインした。さらに、物理学、生物学、化学の問題のベンチマークで博士号レベルの精度を実証している。
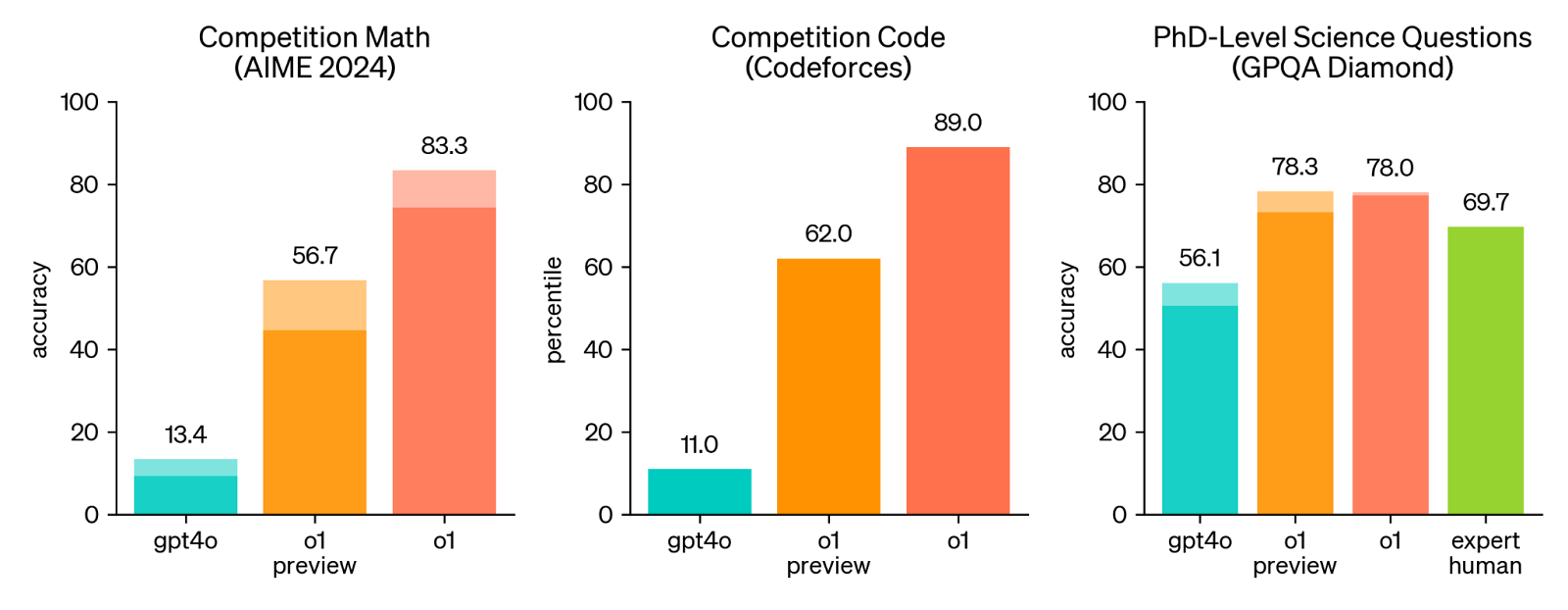
図2:パフォーマンス・ベンチマーク OpenAI o1 (Source)_
使用例と応用分野:OpenAI o1は、科学研究(データ分析、仮説検証)、ソフトウェア開発(マルチステップワークフロー、デバッグ)、ヘルスケア(診断開発)、教育アプリケーション(複雑なパズルやクロスワードを解く)など、高度な推論を必要とする分野に広く適用できます。
OpenAI o3-miniの概要
OpenAI o3-miniは、2024年12月のプレビューに続き、2025年1月下旬に正式にリリースされました。このモデルは、複雑なタスクに対する推論能力を強化するOpenAIの進歩を引き継いでおり、特にコーディング、数学、科学の課題におけるスピード、効率、パフォーマンスにおいて、o1のような以前のモデルよりも顕著な改善を提供しています。
主な特徴
**モデルアーキテクチャOpenAI o1と同様に、o3-miniは高度な推論のために特別に最適化されたトランスフォーマーアーキテクチャに基づいています。推論を強化するために大規模な強化学習と組み合わせて、ステップバイステップの問題解決を可能にする思考の連鎖技術を活用しています。o3-miniの際立った特徴は、o1と比較してレイテンシが短縮されていることで、複雑なタスクでも高い精度を維持しながら、より速い結果を得ることができます。
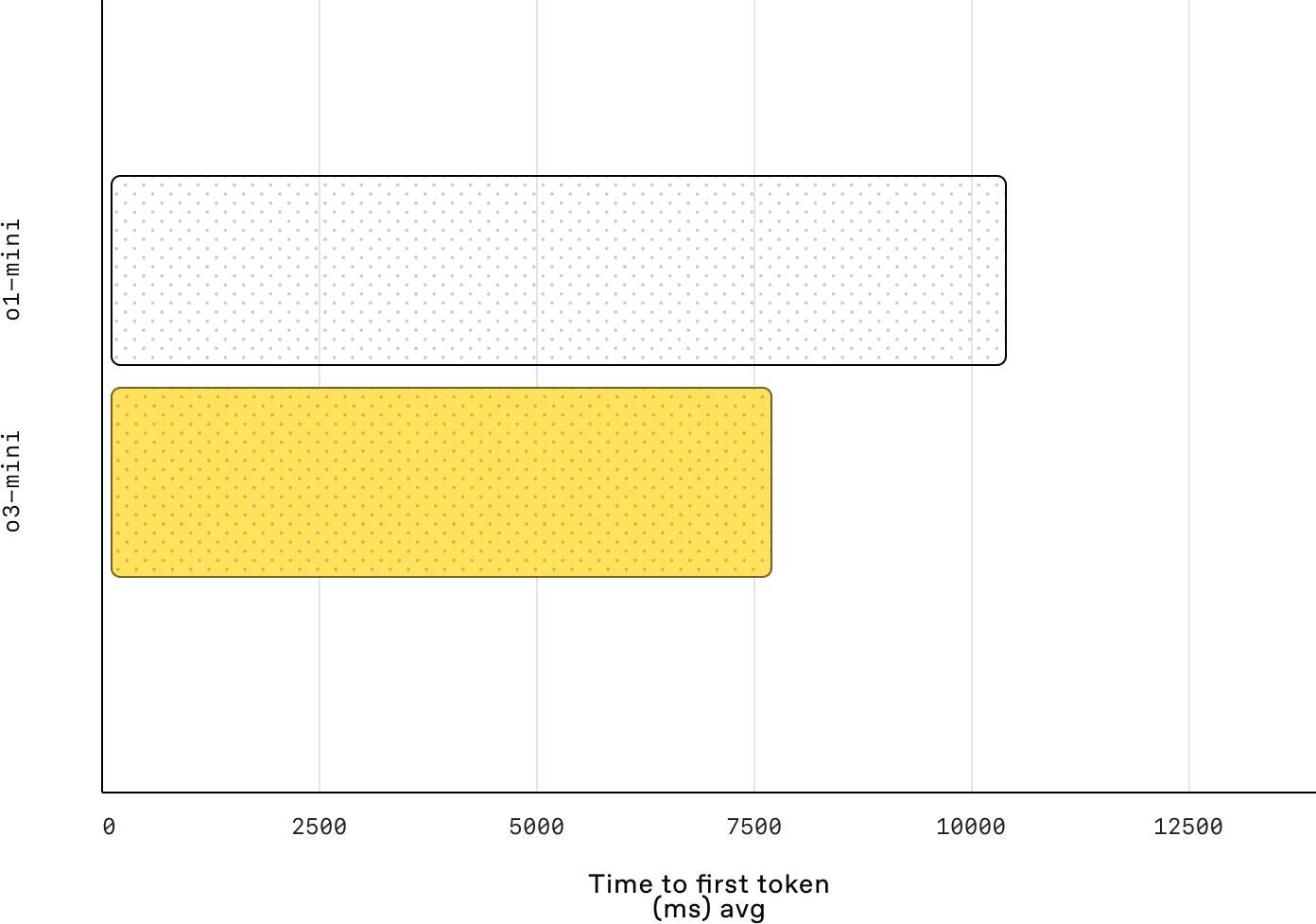
図3:o3-miniとo1のレイテンシ比較 (Source)_。
トレーニングデータ: o3-miniは、その前身と同様に、安全で効果的なトレーニングセットアップを確実にするために、一般に利用可能なデータセット、独自のOpenAIデータ、および高度なフィルタリング技術を組み合わせてトレーニングされました。
パフォーマンスベンチマーク:OpenAI o3-miniは、ベンチマークデータセットで卓越した性能を実証しており、競技レベルの数学問題で87.3%、博士号レベルの科学問題で79.7%、ソフトウェアプログラミングで49.3%の精度を達成し、より高い推論レベルではOpenAI o1を上回っています。
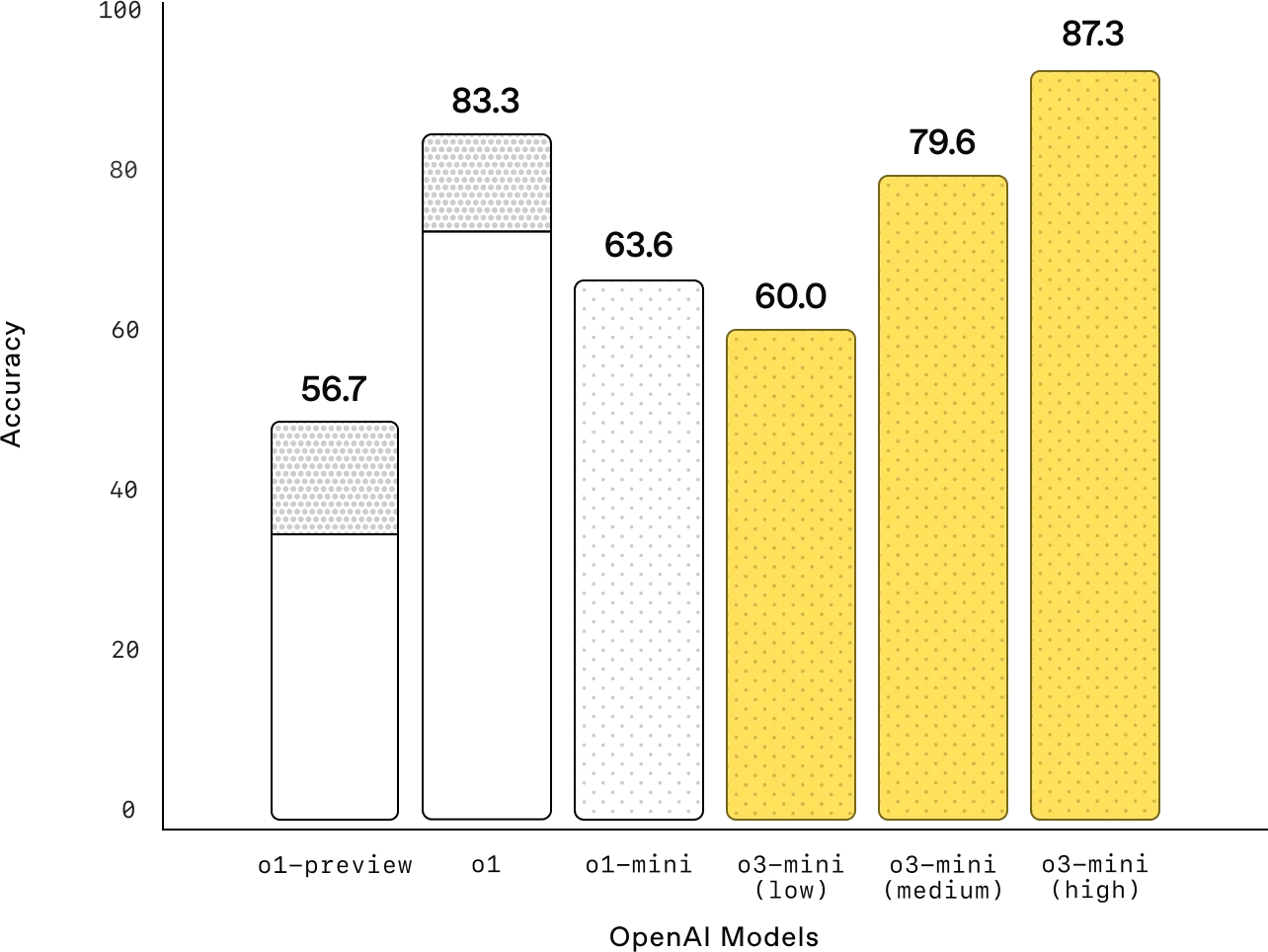
図4:パフォーマンスベンチマークo3-mini vs o1:数学、AIME (Source)_。
図5:パフォーマンスベンチマークo3-mini対o1:博士号レベルの科学](https://assets.zilliz.com/Figure_5_Performance_Benchmarks_o3_mini_vs_o1_Ph_D_level_science_cd0d76dae5.png)
図5:パフォーマンスベンチマークo3-mini対o1:博士号レベルの科学 (Source)_。
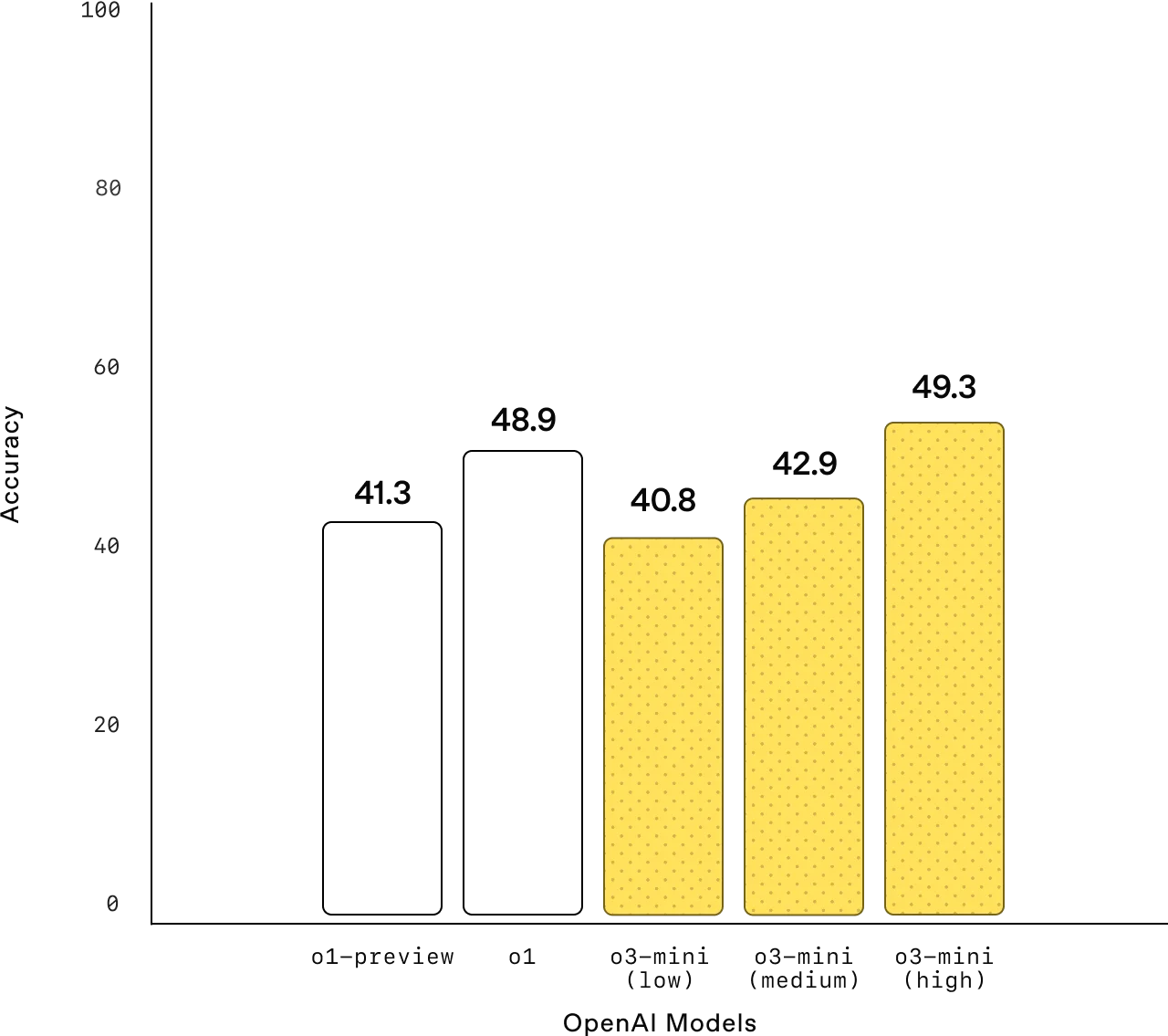
図6:パフォーマンスベンチマークo3-miniとo1の比較:ソフトウェア工学 (Source)_。
使用例と応用分野:OpenAI o3-miniは、科学研究、ソフトウェア開発、ヘルスケア、教育の問題解決など、o1と多くのユースケースを共有していますが、より低いレイテンシで高レベルの推論が不可欠なドメインでは際立っています。例えば、金融分析において、o3-miniは大量のデータを迅速に処理しながら、複雑なリスク予測、詐欺検出、投資戦略シミュレーションを効率的に処理することができる。
Deepseek R1の概要
2025年1月にリリースされたDeepSeek R1は、中国のDeepSeek社が開発したオープンソースのAIモデルである。高度な推論と問題解決のために特別に設計されており、論理的推論を強化するためにchain-of-thought 推論、教師あり fine-tuning およびreinforcement learning の組み合わせを活用している。その際立った特徴の一つは、OpenAI o1のような主要なAIモデルに匹敵する性能レベルを達成しながら、大幅に低い運用コストを維持できることです。
主な特徴
モデル・アーキテクチャ:DeepSeek R1 は、推論タスクに最適化された 変換器ベース アーキテクチャを採用しています。その学習方法は、DeepSeek V3をベースとし、大規模強化学習、教師ありfine-tuning、およびchain-of-thought例のキュレートされたデータセットという複数のステップを含みます。特徴的なのは、3つの重要な要素の組み合わせで、効率と問題解決の深さを大幅に向上させている:
Mixture-of-Experts (MoE):**この技術は、各入力に対して専門化されたニューラルネットワークの「エキスパート」のサブセットを動的に選択し、効率を向上させながら計算量を削減する。
多頭潜在的注意(Multi-Head Latent Attention: MLA)**:MLAのコアとなる考え方は、アテンションキーと値の低ランク結合圧縮であり、推論中のKV(Key-Value)キャッシュの最適化に役立つ。
マルチトークン予測(MTP)**:一度に複数の将来のトークンを予測することが可能。
トークン](https://assets.zilliz.com/Figure_7_Basic_architecture_of_Deep_Seek_V3_e1c138b7fe.png)
図 7: DeepSeek-V3 の基本アーキテクチャ (Source)_。
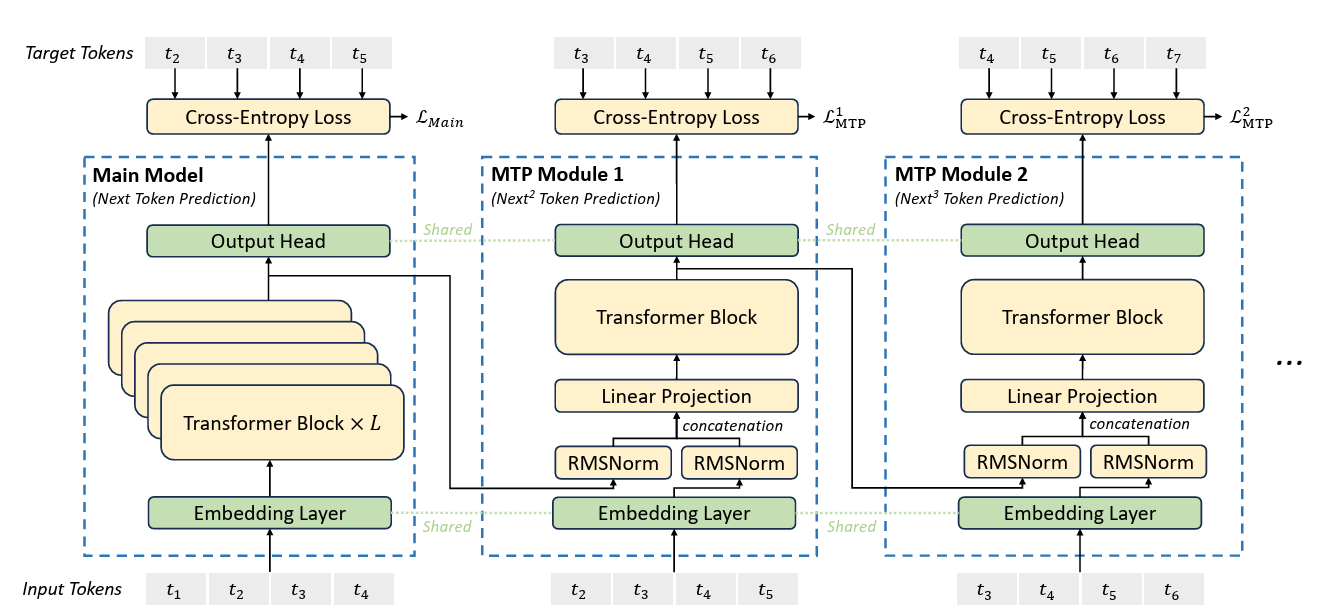
図 8: マルチトークン予測(MTP)実装の図解(Source)_。
**学習データDeepSeek R1 は、一般には公開されていない 2 つの独自のデータセットを組み合わせてトレーニングされま した。一方のデータセットでは推論機能が追加され、もう一方のデータセットでは汎用タスクが強化されています:
非推論**:後続の教師ありfine-tuningステップのためのラベル付きデータで、ライティング、翻訳、事実QAなどの汎用タスクを強化。
性能ベンチマーク:DeepSeek R1 は、推論や深い分析的思考を必要とするタスクに優れており、AIME で 79.8%、MATH-500 で 97.3%、Codeforces で 96.3% の精度を達成しました。また、MMLUでは90.8%、GPQA Diamondでは71.5%と、一般知識のベンチマークでも高いパフォーマンスを発揮しました。
MMLU](https://assets.zilliz.com/Figure_9_Performance_Benchmarks_Deep_Seek_dc61c68091.png)
図 9: パフォーマンス・ベンチマーク DeepSeek (Source)_。
使用例と応用分野:DeepSeek R1 は、数学とコーディングのタスクで高い性能を発揮するため、科学研究、ソフトウェア開 発、および学術教育に適しています。オープンソースであるため、幅広いユーザーや業界が低コストで利用できます。
モデルバージョン
OpenAIは、コンテキストウィンドウサイズと最大出力トークンの違いで、o1、プレビュー、ミニ、フルの3つのモデルバージョンと、o3-ミニの1つをリリースした。一方、DeepSeekは2つのDeepSeek R1モデルを発表した。最初のZeroバージョンは、彼らの最初のトレーニングの試みであり、推論ベンチマークでは優れているが、可読性と言語混合に関する課題に直面している。さらに、DeepSeekは、QwenやLlamaなどのオープンソースモデルを微調整することで、蒸留モデルを開発しました。
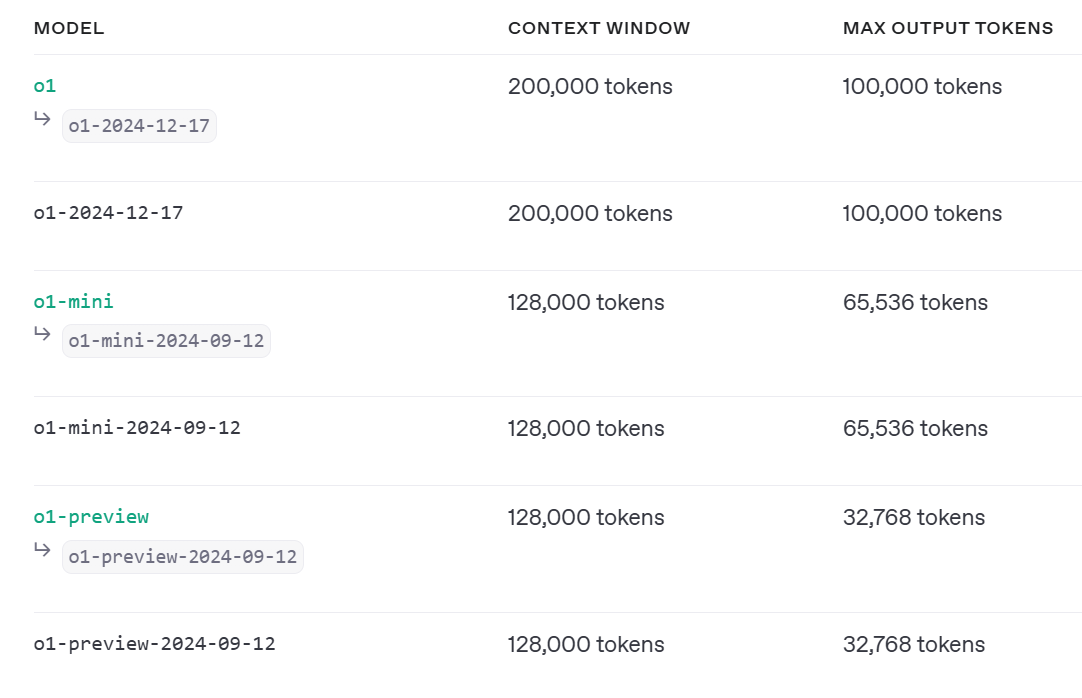
図10:OpenAI o1モデルのバージョン(Source)_。
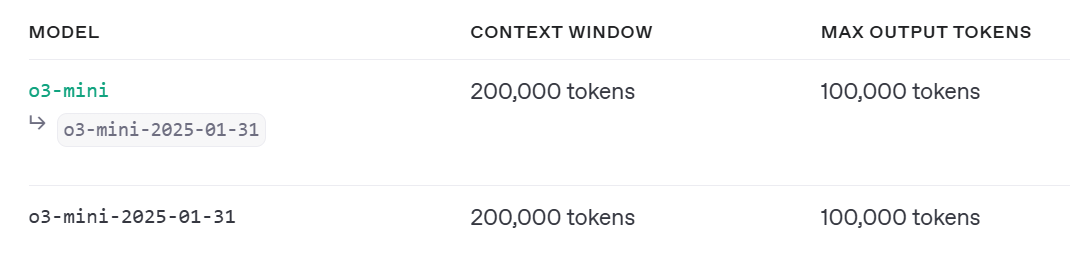
図11:OpenAI o3-miniモデルのバージョン(Source)_。

図 12:DeepSeek R1 モデルのバージョン(Source)_。
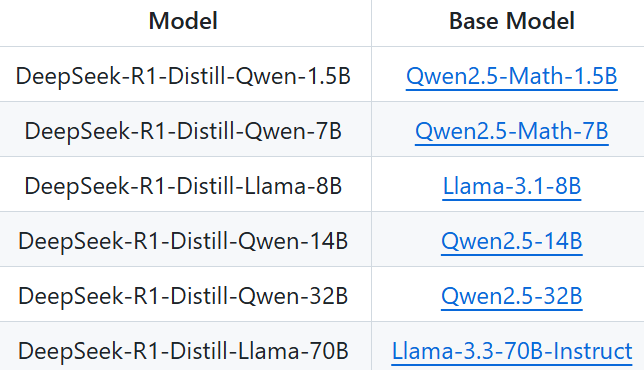
図 13: DeepSeek R1 distill モデル・バージョン (Source)_。
コスト比較
価格は、特定のユースケースのためにAIモデルを選択する際の重要な要素です。以下は、OpenAI o1、OpenAI o3-mini、DeepSeek R1に関連するコストの比較で、100万トークンあたりの入力および出力トークン価格とキャッシュ価格を含みます。
| モデル | キャッシュ価格* (1Mトークンあたり)** | インプット・トークン価格(1Mトークンあたり) | アウトプット・トークン価格* (1Mトークンあたり)** |
| OpenAI o1 | $7.5 | $15.00 | $60.00 |
| オープンAI o1-mini**|0.55ドル|1.10ドル|4.40ドル||です。 |
| ディープシークR1**|0.14ドル|0.55ドル|2.19ドル||です。
この表は、モデル間のコストの違いを強調しています。DeepSeek R1は、OpenAIの最も手頃なモデルの半分と、大幅に低い価格設定となっており、コスト効率と拡張性が高くなっています。
比較表:Deepseek R1 vs. OpenAI o1 vs. OpenAI o3-mini
より明確な比較を行うために、以下の表は主な特徴、性能ベンチマーク、適用分野、およびコストに関する考慮事項の概要を示しています。OpenAIの主な強みはo3-miniモデルの低レイテンシにあり、DeepSeek R1はコスト効率で際立っています。
| :-----------------:| :--------------------------------------------------------------:| :---------------------------------------------------------------------------:| :-----------------------------------------------------------:| | Feature | OpenAI o1 | OpenAI o3-mini | DeepSeek R1 | | リリース日|2024年12月|2025年1月|2025年1月|2025年1月|2025年1月 | アーキテクチャ|トランスフォーマーベース、思考連鎖型推論|トランスフォーマーベース、低レイテンシに最適化された思考連鎖型推論|トランスフォーマーベース、MoE、MLA、MTP | トレーニングデータ|公開データ+専有データ|公開データ+専有データ|専有データ | ベンチマーク|83%(AIME)、89%(Codeforces)、79.7%(PhDレベルSTEM精度)|87.3%(AIME)、79.7%(サイエンス)、49.3%(コーディング)|79.8%(AIME)、97.3%(MATH-500)、96.3%(Codeforces)|。 | レイテンシ|推論の拡張により高い|低いレイテンシ、速いレスポンス|中程度のレイテンシ | 使用例|科学研究、ソフトウェア開発、ヘルスケア、教育|金融分析、リアルタイム意思決定、ソフトウェア開発、研究|科学研究、学術教育、ソフトウェア開発|オープンソース|科学研究、学術教育、ソフトウェア開発|オープンソース|科学研究、学術教育、ソフトウェア開発 | オープンソース|いいえ|いいえ|はい | コスト効率|高コストの独自モデル|高コストの独自モデル|運用コストの低減
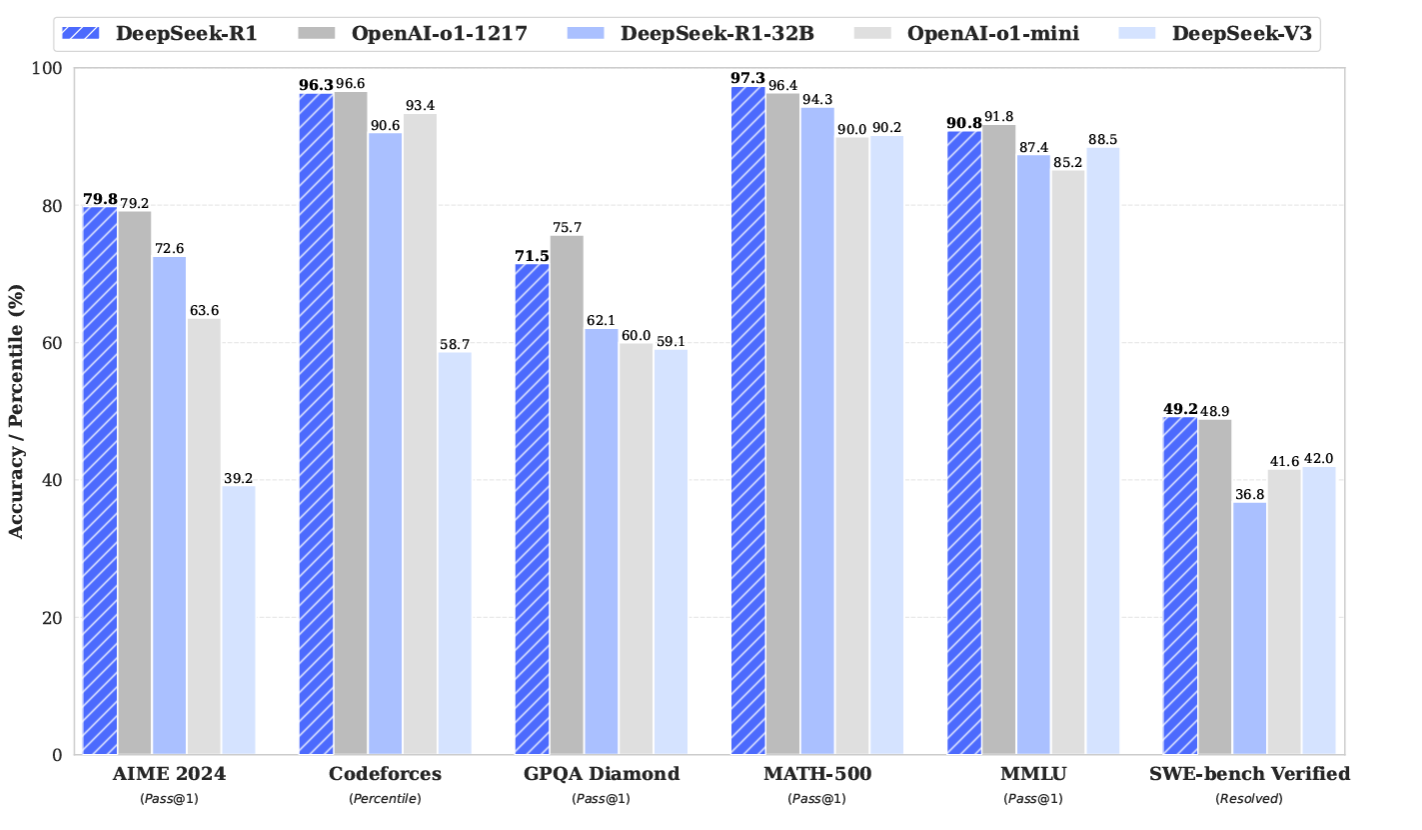
図14:ベンチマーク性能比較 DeepSeek vs OpenAI (_Source))
オープンソースであるため、DeepSeek R1 は Hugging Face や Ollama を含む複数のプラットフォームで利用可能である一方、OpenAI のモデルは様々なエンタープライズソリューションやクラウドプラットフォームに統合されています。しかし、OpenAIはまだモデルの重みを公開しておらず、ユーザーはOpenAIプラットフォームからfine-tunedモデルをダウンロードすることはできません。また、DeepSeek R1は、LiteLLM、Langfuse、Ragflowを含む、以下のリポジトリにある統合の厳選されたリストを備えています。さらに、AWSとAzure上で見つけることができます。
結論
AIの時代がさらに進むにつれ、OpenAIのo1やo3-miniのような主要モデルと、DeepSeek R1のような新規参入モデルとの間の競争は激化する一方である。OpenAIのモデルは、特に高レベルの推論、スケーラビリティ、ロバストなパフォーマンスが不可欠な様々なアプリケーションでその有効性を証明してきました。その革新性、スピード、高度な機能は、業界にとって高いハードルとなっている。
しかし、DeepSeek R1は、特に他のモデルに関連する高い運用コストをかけずに高度なAI機能を活用しようとしている人々にとって、魅力的な代替手段を提供します。そのオープンソースの性質と印象的なパフォーマンスベンチマークは、推論の深さと問題解決能力を犠牲にすることなく、費用対効果の高いソリューションを求める組織や開発者にとって魅力的な選択肢となっています。
最終的に、これらのモデルのどちらを選択するかは、特定のユースケースによる。厳密で段階的な推論を必要とする複雑性の高いタスクに取り組んでいる場合は、OpenAI o1が最適かもしれません。スピードとコスト効率がより重要な場合、特にSTEM関連分野や金融アプリケーションでは、OpenAI o3-miniが正しい選択かもしれません。数学やソフトウェア開発のようなタスクで卓越したパフォーマンスを発揮する、オープンソースで予算に見合ったソリューションをお探しの方には、DeepSeek R1が優れた選択肢となるでしょう。

読み続けて

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.