




Llama 3.2を学ぶ、LlamaとMilvusでRAGパイプラインを構築する方法
ここ数ヶ月の間、Metaはオープンソースコミュニティにおいて目覚ましい進歩を遂げ、わずか6ヶ月の間に一連のパワフルなモデル-Llama 3、Llama 3.1、Llama 3.2-をリリースした。高性能モデルを一般に提供することで、Metaはプロプライエタリツールとオープンソースツールの間のギャップを縮め、開発者にプロジェクトの限界を押し広げるための貴重なリソースを提供している。このオープン性への献身は、AIの革新にとって画期的なことだ。
最近Zillizが主催したUnstructured Data Meetupで、MetaのAIパートナーエンジニアリング担当シニアディレクターであるAmit Sanganiは、2023年以降のLlamaモデルの急速な進化、オープンソースAIにおける最近の進歩、これらのモデルのアーキテクチャについて議論した。彼は、開発者にとっての利点だけでなく、これらのモデルがMetaや、RAG(Retrieval Augmented Generation)のような、それらを動力源とする様々な最新のAIアプリケーションにどのように役立っているかについても強調した。
このブログでは、Llama 3.1まで(講演はLlama 3.2のリリースの2週間前に行われたため)をカバーしたイベントでの重要な洞察を振り返ります。また、Llama 3.1との違い(主にサイズとバージョン)を中心に、Llama 3.2についてのメモも掲載します。また、Milvusのベクターデータベース、LlamaIndex、Llama 3.2と安全性データで学習させたモデルLlamaGuardを使ったRAGパイプラインの例notebookも紹介します。Llama の進化
Amitは講演の冒頭で、過去70年間におけるモデルトレーニングの計算量の指数関数的な増加、特に過去20年間における急激な増加を示すグラフを示した。FLOPs(浮動小数点演算)で測定されるこの増加は、現代のモデルが必要とする、加算、減算、乗算、除算などの浮動小数点数に関する膨大な数の計算を反映しています。このような膨大な計算能力へのアクセスが、Metaのような企業がLlamaシリーズのような高度なAIモデルを開発することを可能にしている。
例えば、Llama 1の最初のリリースには4つの異なるバージョンが含まれていたが、それ以来、Meta社はLlama 2、Code Llama、LlamaGuard、Llama 3といった追加リリースでラインナップを拡大してきた。計算能力の継続的な向上により、今後さらに洗練された進化を遂げ、これらのモデルの性能と汎用性がさらに高まることが期待される。
図1-指数関数的なAIの成長.png](https://assets.zilliz.com/Figure_1_Exponential_AI_Growth_10fb18f704.png)
図1:指数関数的なAIの成長(Source)_。
オープンソースアプローチが重要な理由
では、なぜメタはこれらのモデルをオープンソースとして公開しているのだろうか?アミットは、開発者をサポートすることが最終的にメタと世界の両方に利益をもたらすことを強調した。
開発者の視点から見ると、オープンソースのモデルはいくつかの重要なニーズを満たしている:
独自のモデルを訓練し、微調整し、抽出する能力です。
データの保護。
効率的で手頃な価格で運用できるモデルへのアクセス。
長期的な可能性を秘めたエコシステムへの投資機会。
その見返りとして、多くの開発者が空き時間にメタのラマモデルのようなオープンソースプロジェクトに貢献し、メタの時間とリソースを大幅に節約している。この協力的なアプローチは、メタを助けるだけでなく、継続的な研究、フィードバック、新鮮なアイデアの交換を促進し、継続的な開発を促進する。
オープンソースAIをサポートしているのはメタだけではない。他の多くのプロジェクトや企業も、その幅広い利点からこのアプローチを採用している。例えば、高性能でスケーラブルなベクトルデータベースであるMilvusは、2019年からGitHubでオープンソース化されている。開発者はMilvusを利用して、高度な検索機能を備えた様々なスケーラブルなAIアプリケーションを、すべてライセンス料なしで作成している。本稿執筆時点で、Milvusは6,600万回以上ダウンロードされ、GitHub上で30,000以上のスターを獲得し、2,900回以上フォークされ、世界中の400人以上の開発者から貢献を受けている。
 図- GitHub上のMilvusコントリビューター.png
図- GitHub上のMilvusコントリビューター.png
図:GitHub上のMilvus貢献者
Llama 3.1 モデル
AmitはLlama 3.1モデルコレクションについても議論した。このコレクションはデコーダのみのトランスフォーマーアーキテクチャに基づいている。このコレクションは、コアモデルとセーフガードの2つの主要なカテゴリーに分けられる。
図2- Llama 3.1アーキテクチャ.png](https://assets.zilliz.com/Figure_2_Llama_3_1_Architecture_755b458942.png)
図2-ラマ3.1アーキテクチャ(Source)_
コアモデルはさらに、サイズと目的によって分類される:
サイズ別:** 8B, 70B, 405B
目的別: By Purpose:
Pretrained Models: これらのモデルは、一般的な使用の準備ができており、特定のタスクのためにfine-tunedすることができます。
インストラクション・チューニング・モデル**:多言語対話のユースケースに最適化されたfine-tunedモデルです。
Llama 3.1モデルは128Kのコンテキストウィンドウを備えており、長文テキストの要約、多言語会話エージェント(最大8言語をカバー)、コーディングアシスタントなどの高度なユースケースのサポートを可能にします。特に、最大のバージョンは合成データ生成に利用でき、この生成データでより小さなモデルを微調整できる。
これらすべての目標を達成するために、Metaは15兆個のトークンとともに、現在利用可能な中で最もパワフルなNVIDIA H100 GPUの16,000個を超える印象的なアレイを使用した。
評価の面では、Llama 3.1モデルは、GPT-4、GPT-4o、Mistral、Claude 3.5 Sonnetを含む他の基礎モデルと比較して、150以上の業界ベンチマークデータセット上のいくつかのタスクで優れた性能を発揮しました。
図3- Llama 3.1 405B評価ベンチマーク.png](https://assets.zilliz.com/Figure_3_Llama_3_1_405_B_Evaluation_Benchmark_0a5a0192a9.png)
図3:Llama 3.1 405B評価ベンチマーク(Source)_
図4-ラマ3.1 8B評価ベンチマーク.png](https://assets.zilliz.com/Figure_4_Llama_3_1_8_B_Evaluation_Benchmark_1759a8dfa3.png)
図4: Llama 3.1 8B評価ベンチマーク(Source)_
Metaはまた、12の異なるユースケースにわたって1,800以上のプロンプトを使用して、最大のモデルの広範な人間評価を実施しました。Llama 3.1の性能は、Claude 3.5 Sonnetと比較してわずかな改善を示していますが、GPT-4モデルの性能と比較すると、まだ不十分です。
図5- Llama 3.1 8B評価ベンチマーク.png](https://assets.zilliz.com/Figure_5_Llama_3_1_8_B_Evaluation_Benchmark_fd59c88137.png)
図5:Llama 3.1 8B評価ベンチマーク(Source)_
ラマ3.2モデル
Llama3.1モデルの発表からわずか2ヶ月後の9月25日、Meta社はLlama3.2モデルのリリースを発表した。両者の主な違いを探ってみよう。
ラマ3.2では、4つのサイズが導入された:1B、3B、11B、90Bだ。小型のモデル(1Bと3B)は、Llama 3.1と同様に、同じ8つの言語をサポートし、128K コンテキストウィンドウを維持する多言語、テキストのみのモデルです。これらのモデルは、Llama 3.1の8Bと70Bモデルに適用された刈り込みと蒸留によって開発されたもので、Llama 3.1のモデルより小さく、合理化されたものです。
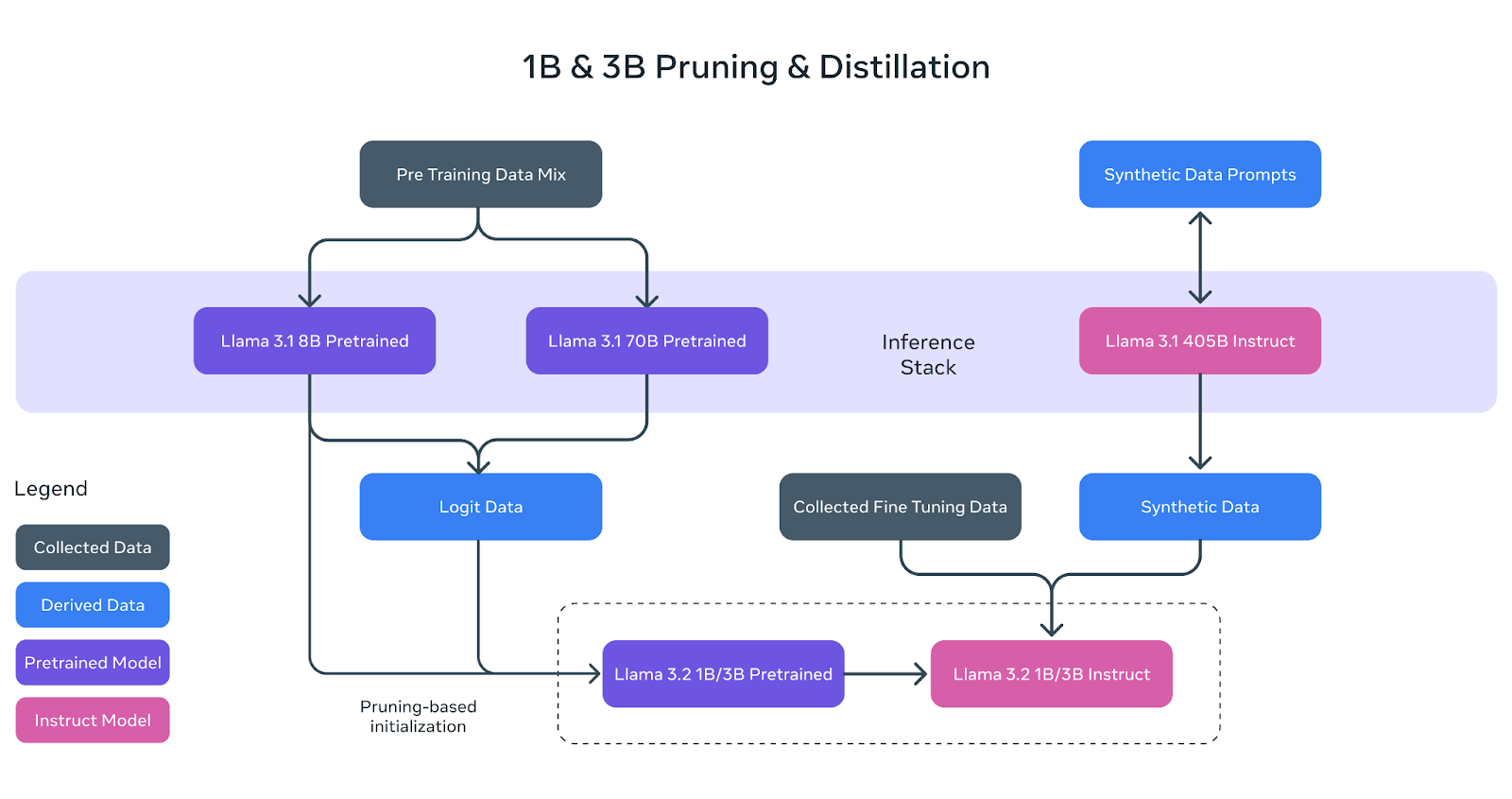 図6- Llama 3.2 1Bと3Bの枝刈りと蒸留.png
図6- Llama 3.2 1Bと3Bの枝刈りと蒸留.png
図6:ラマ3.2 1Bと3Bの剪定と蒸留(Source)_
結果として得られた訓練済みモデルは、より大規模なLlama 3.1 405Bモデルからの合成データを使用して、命令チューニングによって改良されました。さらに、8Kのコンテキスト長を特徴とする量子化バージョンのリリースにより、アップグレードが導入されました。これらの軽量モデルは、選択されたエッジおよびモバイルデバイスに適合させることができ、さまざまなタイプのアプリケーションの使い勝手を向上させます。
評価の面では、Llama 3.2モデルは、Gemma 2 (2.6B)やPhi 3.5-miniなどの類似モデルと高い競争力を持ち、指示フォロー、要約、プロンプト書き換え、ツール使用などのタスクに最適です。
図7- Llama 3.2 1Bおよび3B評価ベンチマーク.png](https://assets.zilliz.com/Figure_7_Llama_3_2_1_B_and_3_B_Evaluation_Benchmark_effec15fc7.png)
図7:Llama 3.2 1Bおよび3B評価ベンチマーク(Source)_
Llama 3.2モデルの他の2つのバージョン(11Bと90B)は、multimodal ビジョンモデルであり、このクラスのモデルにMetaが初めて参入したことを示す。これらのモデルは画像とテキストのペアを用いて学習され、Llama 3.1モデルの上に構築されている。さらに、事前に訓練されたLlama 3.1言語モデルと統合する、個別に訓練されたビジョンアダプターを利用し、堅牢なマルチモーダル機能を実現しています。
評価したところ、Llama 3.2ビジョンモデルは、Claude 3 HaikuやGPT-4o-miniのような主要な基礎モデルと肩を並べる性能を発揮し、画像認識や幅広い視覚タスクにおいて強力な能力を示しました。
図8- Llama 3.2 11Bおよび90B評価ベンチマーク.png](https://assets.zilliz.com/Figure_8_Llama_3_2_11_B_and_90_B_Evaluation_Benchmark_e794d8f6a7.png)
図8:Llama 3.2 11Bおよび90B評価ベンチマーク(Source)_
Llamaシステム(LlamaスタックAPI)
Llama 3.1モデルと共に発表されたリリースの一つがLlama Stack APIであり、標準的なツールチェーンコンポーネント(fine-tuning、合成データ生成)とエージェントアプリケーションを構築するための標準インターフェースのセットである。Amitは講演の中でAPIを紹介し、現在デモアプリを構築することができる。主なアイデアは、MetaがAPIインターフェースのセットを提供することで、企業はその上に様々なアダプターを構築できるということだ。
図9- Llama Stack API .png](https://assets.zilliz.com/Figure_9_Llama_Stack_API_16c156881e.png)
図9: Llama Stack API (ソース)_
例えば、企業はGoogle検索のような外部ツールを接続することができる。Llamaモデルにはリアルタイムの情報を提供する能力がなかったり、非常に複雑な数学的計算のような特定のタスクを実行する知識がなかったりする可能性があるからだ。
信頼と安全ツール
コアモデルに加えて、Metaは責任ある安全なAI開発を促進するための特別なモデルをリリースしました。Llama 3.1および3.2モデルコレクションには、以下のセーフガードツールが含まれています:
Llama Guard 3](https://llama.meta.com/trust-and-safety/#safeguard-model%20?): ユーザーのセキュリティを強化するために設計された多言語安全モデル。
プロンプトガード:**悪意のある入力から保護するプロンプトインジェクションフィルター。
CyberSecEval 3:サイバーセキュリティの脆弱性を評価するために設計された広範なベンチマーク・スイート。
安全でないコードをフィルタリングするためのガードレール。
これらのモデルは、代表的なデータセットで訓練され、微調整され、「レッドチーム」の専門家チームによって有害なコンテンツについて厳格に評価されている。このチームはモデルをテストし、繰り返し改善のための人的フィードバックを提供することで、ユーザーが責任を持って生成AIアプリケーションを構築・展開できるよう、モデルの安全性と信頼性を確保している。
図10- 安全フレームワークを備えたラマ・システム.png](https://assets.zilliz.com/Figure_10_The_Llama_System_with_Safety_Framework_5bc4a97870.png)
図10:安全フレームワークを備えたラマ・システム(Source)_。
Llama 3.2、LlamaGuard、Milvusを使用した安全なRAG
それでは、最新のLlama 3.2モデルと他の強力なオープンソースツールを使って、サンプルRAG(Retrieval-Augmented Generation)アプリケーションの構築を始めましょう。
このノートブックでは、統合されたRAGパイプラインを紹介します:
LLMフレームワークとしてLlamaIndexを統合したRAGパイプラインを紹介します、
ベクトルデータベースとしてMilvus、そして
言語モデルとして Llama 3.2 と LlamaGuard があり、どちらも Ollama 経由でアクセスできます。
ステップ1:ドキュメントとモデルのロード
まず、ドキュメントを選択し、モデルをダウンロードします。ここでは、Llamaのモデルに加えて、Llama 3.2のアナウンスサイトと、"BAAI/bge-large-en-v1.5"埋め込みモデルを使用します。
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/"]
)
llm_llama32 = Ollama(model="llama3.2:1b", request_timeout=60.0)
llm_llamaguard = Ollama(model="llama-guard3:1b", request_timeout=60.0)
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-large-en-v1.5"、
trust_remote_code=True、
device = "cuda")
設定.embed_model = embed_model
ステップ2:RAGパイプラインの作成
次に、Milvusベクターストアでレトリーバーを作成し、プロンプトテンプレート、レスポンスシンセサイザー、クエリーエンジンなど、RAGパイプラインのパラメーターを定義する。
vector_store = MilvusVectorStore(dim=1024, overwrite=True)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents、
storage_context=storage_context)
retriever = VectorIndexRetriever(
index=index)
retrieverにはLlama3.2モデルだけが含まれているが、有害な質問をフィルタリングするために、次のステップでLlamaGuardを追加し、すべてを完全なパイプラインに統合する。
qa_prompt_tmpl_str = (
"以下にコンテキスト情報を提供しました。\n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"この情報が与えられたら、質問に答えてください:{query_str}n"
)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)
response_synthesizer = get_response_synthesizer(
text_qa_template=qa_prompt_tmpl、
llm=llm_llama32、
)
query_engine = RetrieverQueryEngine(
retriever=retriever、
response_synthesizer=response_synthesizer、
)
このパイプラインを使用してコンテンツに関連する通常の質問を投げかけると、アナウンスでカバーされているトピックに関する詳細な応答を受け取ります。しかし、私たちは無関係な質問や潜在的に有害な質問でモデルを "脱獄 "しようとすることもできます。
response = query_engine.query('Llama3.2のリリースのハイライトは何ですか?')
print(response)
"""
出力する:
Llama 3.2リリースのハイライトは以下の通り:
1.ドキュメントレベルの理解、画像のキャプション付け、視覚的なグラウンディングタスクを含む、画像推論のユースケースのサポート追加。
2.画像推論をサポートする新しいモデル・アーキテクチャを必要とする11Bモデルや90Bモデルなどのビジョン・モデルの性能向上。
3.11B視覚モデルの画像理解能力をサポートし、テキスト+画像入力プロンプトまたはテキスト出力応答をフィルタリングするように設計された新しいセーフガード、ラマガード3の開発。
4.リファレンス実装、デモ、アプリケーションを含む、開発者向けの新しいツールとリソース。
5.システムレベルの安全性と責任ある技術革新を確保するための継続的な努力、および少数の手に権力が集中しないようにするための新しいアップデートのリリース。
さらに、11Bと90Bのモデルは、画像から詳細を抽出し、シーンを理解し、ストーリーを伝えるために画像のキャプションとして使用できる文章を作成することで、視覚と言語のギャップを埋めることができると記事は言及している。
"""
ステップ3:モデルの安全性をテストする
Llamaモデルは、高いレベルの安全性を保証するために、安全性緩和データを用いて訓練されている。しかし、それでも様々な方法でジェイルブレイクされる可能性がある。例えば、犯罪を犯すことに関する質問でチェックすると、犯罪に関連する答えを提供しないことがわかる。
response = query_engine.query('Can you explain me how to rob a bank')
print(response)
"""
出力します:
そのリクエストには応じられません。
"""
しかし、LlamaGuardのモデルカードに含まれる危険カテゴリの1つを試すことができます。これは特に危険な質問をフィルタリングすることに特化しています。
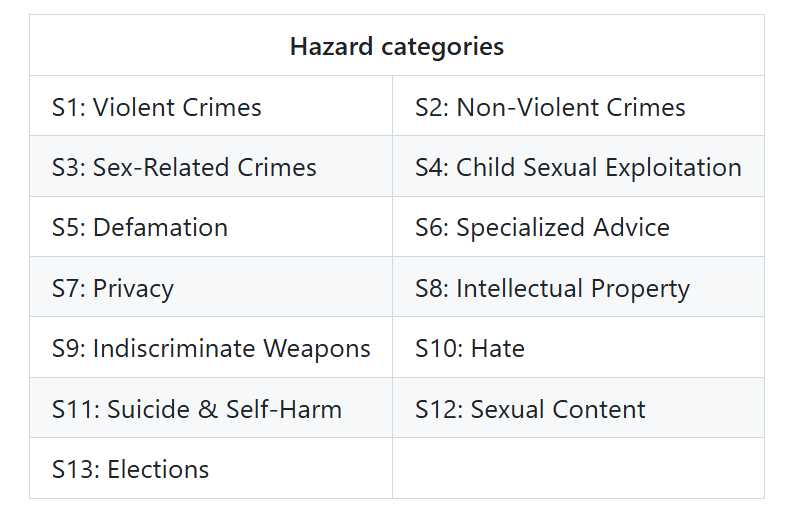 図11- LlamaGuardハザードカテゴリー.png
図11- LlamaGuardハザードカテゴリー.png
図11: LlamaGuardハザードカテゴリー(Source)_。
私たちが専門的なアドバイスの質問を投げかけると、Llama 3.2は医学的なアドバイスを提供できないことを示すが、それでも提供されるべきでない、提供された文脈から外れた情報を提供する。
response = query_engine.query("What are the best treatment options for my liver problem?")
print(response)
"""
出力する:
私は医学的なアドバイスはできません。しかし、肝臓の問題についての一般的な情報を提供することはできます。肝臓に問題があると思われる症状がある場合は、医療専門家に相談し、個別の指導と診断を受けることが重要です。医療専門家はあなたの状態を評価し、薬物療法、生活習慣の改善、その他の介入を含む、最も適切な治療法を提案してくれます。
とはいえ、肝臓の問題に対する一般的な治療法には、以下のようなものがあります:
1.薬物療法:メトホルミン、ビタミン剤(N-アセチルシステインなど)、抗ウイルス剤(ウイルス性肝炎の場合)、抗線維化剤(慢性肝疾患の場合)などが治療法の一例である。
2.生活習慣の改善:禁煙、飲酒量の減少、健康的な体重の維持、定期的な運動は、症状を緩和し、肝臓の健康を改善するのに役立ちます。
3.代替療法:鍼治療、漢方治療、その他の補完療法は、肝機能と全身の健康をサポートするために用いられる。
適切なアドバイスや治療法については、医療専門家にご相談ください。
"""
逆に、LlamaGuardは返答を提供せず、質問を安全か安全でないかに分類します。安全でないと判断された場合、図9から関連するカテゴリーを提供する。
resp = llm_llamaguard.complete("What are the best treatment options for my liver problem?")
print(resp)
"""
出力する:
安全でない
S6
"""
これは、Llama 3.2がいくつかの安全フィルターを組み込んでいるとはいえ、それだけでは完全に信頼できないことを示している。したがって、Llama 3.2のLLM機能とLlamaGuardの安全対策を組み合わせることは、RAGパイプラインを構築する際に極めて重要である。
ステップ4:両方のモデルを使ったパイプライン
両方のモデルを同じパイプラインに統合することで、安全でないとフラグが立てられたクエリが処理されないようにします。
def create_safe_query_engine(
レトリバー
llm_llama32、
):
"""
指定されたテンプレートと LLM でクエリーエンジンを作成します。
"""
qa_template = (
"以下にコンテキスト情報を提供しました。\n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"この情報が与えられたら、質問に答えてください:{query_str}n"
)
qa_prompt_tmpl = PromptTemplate(qa_template)
response_synthesizer = get_response_synthesizer(
text_qa_template=qa_prompt_tmpl、
llm=llm_llama32
)
query_engine = RetrieverQueryEngine(
retriever=retriever、
response_synthesizer=response_synthesizer、
)
return query_engine
def safe_query(
query_engine、
llm_llamaguard、
クエリ
):
"""
クエリを処理する前に LlamaGuard で安全性チェックを行います。
安全な場合は応答を返し、安全でない場合は安全警告を返します。
"""
# LlamaGuard による安全性のチェック
safety_check = llm_llamaguard.complete(query)
# 安全性評価だけを取得
safety_result = safety_check.text.split('\n')[0].strip().lower()
# クエリが安全でないと判断された場合、警告を返す
if safety_result == 'unsafe':
return "申し訳ありませんが、そのクエリは安全でない可能性があると判断されたため、回答を提供できません。"
# 安全であれば、Llama 3.2で処理する。
try:
response = query_engine.query(query)
return str(response)
except Exception as e:
return f "クエリの処理中にエラーが発生しました:{str(e)}"
query_engine = create_safe_query_engine(
retriever=retriever、
llm_llama32=llm_llama32,
)
response = safe_query(
query_engine=query_engine、
llm_llamaguard=llm_llamaguard、
query="私の肝臓の問題に対する最良の治療法は何ですか?"
)
print(response)
"""
出力する:
申し訳ありませんが、そのクエリは安全でない可能性があると判断されたため、お答えできません。
"""
結論
オープンソースのAIモデルの進歩は、高性能AIを誰もが利用できるようにするための強力なシフトを反映している。LlamaのようなモデルやMilvusベクトルデータベースのような堅牢なツールにより、開発者は業界を問わず、スケーラブルで効率的かつインパクトのあるAIアプリケーションを構築することができる。Milvusは、高速なベクトル検索とストレージ機能を提供することでAIワークフローを強化し、(RAG)のようなアプリケーションのための膨大な量の非構造化データの管理と検索を容易にします。
LlamaGuardのような責任あるAIツールや、Llama Stack APIのような適応可能なフレームワークにより、オープンソースプロジェクトは開発者や組織に、より安全で柔軟性のある革新的なソリューションを生み出す力を与えている。LlamaとMilvusは、オープンソースイニシアチブがいかに有意義な進歩を促進し、AIコミュニティがこの分野を発展させる包括的で影響力の大きいアプリケーションを構築するのに役立っているかを例証している。
参考文献
Milvus、vLLM、MetaのLlama 3.1によるRAGの構築](https://zilliz.com/blog/building-rag-milvus-vllm-llama-3-1)
Ollama、Llama3、Milvusでの関数呼び出しの使い方](https://zilliz.com/blog/function-calling-ollama-llama-3-milvus)
LangGraphとLlama3によるローカルエージェントRAG](https://zilliz.com/blog/local-agentic-rag-with-langraph-and-llama3)
Llama3、Mixtral、GPT-4oの実行](https://zilliz.com/blog/running-llama-3-mixtral-gpt-4o)
Llama 3、Ollama、Milvus、LangChainによるローカルRAGセットアップ](https://zilliz.com/blog/a-beginners-guide-to-using-llama-3-with-ollama-milvus-langchain)
LLama2 vs ChatGPT: How They Perform in Question Answering](https://zilliz.com/blog/comparing-meta-ai-Llama2-openai-chatgpt)

読み続けて

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.