




マルチモーダルRAGを構築する3つの主要パターン:包括的ガイド
大規模言語モデル(LLM)は、パーソナライズされたチャットボット、文書要約、文書質問応答、文書分類など、数多くのAIアプリケーションで使用できるため、その汎用性の高さが高く評価されている。
しかし、LLMを使用する際の重要な問題の1つは、幻覚のリスクである。幻覚とは、LLMが私たちのクエリに対して、非常に説得力があるにもかかわらず、真実味のない応答を返す現象を指す。LLMの幻覚を見破るのはかなり厄介で、特に私たちがあまり詳しくないトピックについてLLMに質問している場合はなおさらです。
他の多くの手法の中でも、RAG(Retrieval Augmented Generation)は、LLMの幻覚のリスクを軽減するのに役立つアプローチである。初期の実装では、RAGはテキスト入力のみに使われるのが一般的だった。AI技術の進歩により、現在では画像、音声、動画など、さまざまなモダリティのデータでRAGを使用できるようになり、私たちはこれをマルチモーダルRAGと呼んでいる。
この記事では、AIアプリケーションにマルチモーダルRAGを実装する方法について、様々なアプローチから説明します。マルチモーダルRAGを掘り下げる前に、まずRAGの基礎を復習しておこう。
RAG の基礎
RAG**は、プロンプトにユーザークエリに関連するコンテキストを提供することで、LLMの幻覚のリスクを軽減する新しいアプローチである。LLMはユーザーからの問い合わせに応答する前に、この関連するコンテキストを応答の基礎として使用することができ、その結果、よりコンテキスト化された回答が得られる。
その名前が示すように、RAGには3つの主要なコンポーネントがある:検索、補強、生成。
検索**:このコンポーネントでは、ユーザーのクエリに最も関連するコンテキストがフェッチされる。このコンポーネントには、候補検索と再ランク付けの2つの段階がある。候補検索の段階では、上位n個の最も有望なコンテキストがフェッチされる。一方、再ランク付けの段階では、これらのコンテキストは、コサイン類似度やユークリッド距離などの類似度メトリクスによってランク付けまたはソートされる。
拡張**:このコンポーネントでは、最も有望なコンテキストが元のユーザー のクエリと統合され、最終的な一貫性のあるプロンプトが形成される。この最終的なプロンプトは、LLMの入力となる。
生成**:このコンポーネントでは、LLMは入力されたプロンプトに基づいて、ユーザーのクエリに答える有望なコンテキストを含むレスポンスを生成する。このレスポンスはユーザーに送り返される。
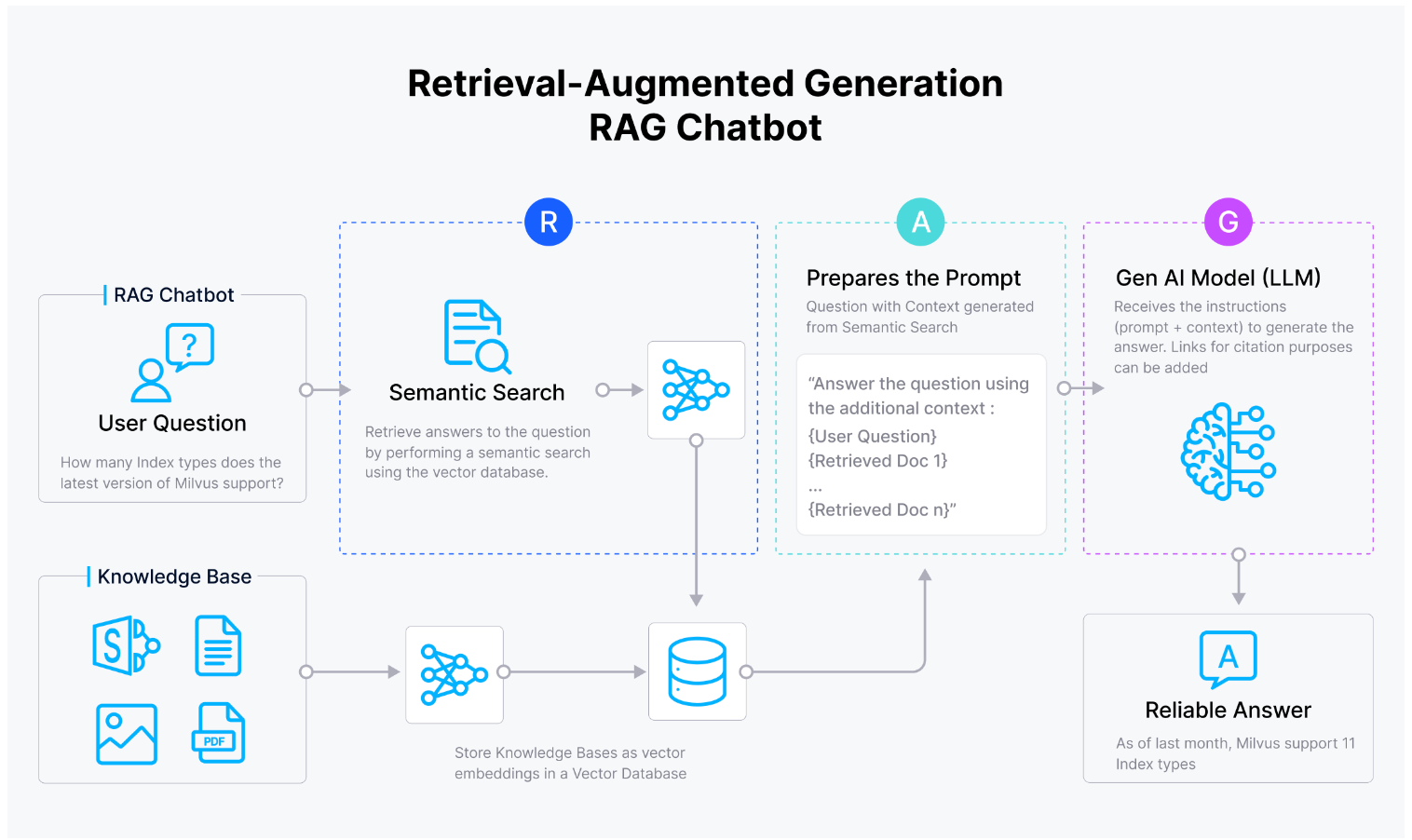
図:RAG._の完全なワークフロー
しかし、アプリケーションにRAGを実装する前に、いくつかのことを設定する必要がある。
例えば、フェッチする前に、すべての可能なコンテキストを格納するための効率的でスケーラブルなストレージシステムが必要である。RAGに通常有用なコンテキストは非構造化データ(テキスト、画像など)であるため、ベクトルデータベースはRAGアプリケーションで使用される最も一般的なストレージシステムである。
ベクトルデータベース](https://zilliz.com/learn/what-is-vector-database)では、通常、生のコンテキストの代わりに、コンテキストの埋め込み表現を格納する。埋め込み表現があれば、類似検索を実行して、与えられたクエリに対して最も有望なコンテキストを見つけることができる。したがって、生のコンテキストを埋め込みに変換するための深層学習モデル(埋め込みモデル)も必要である。
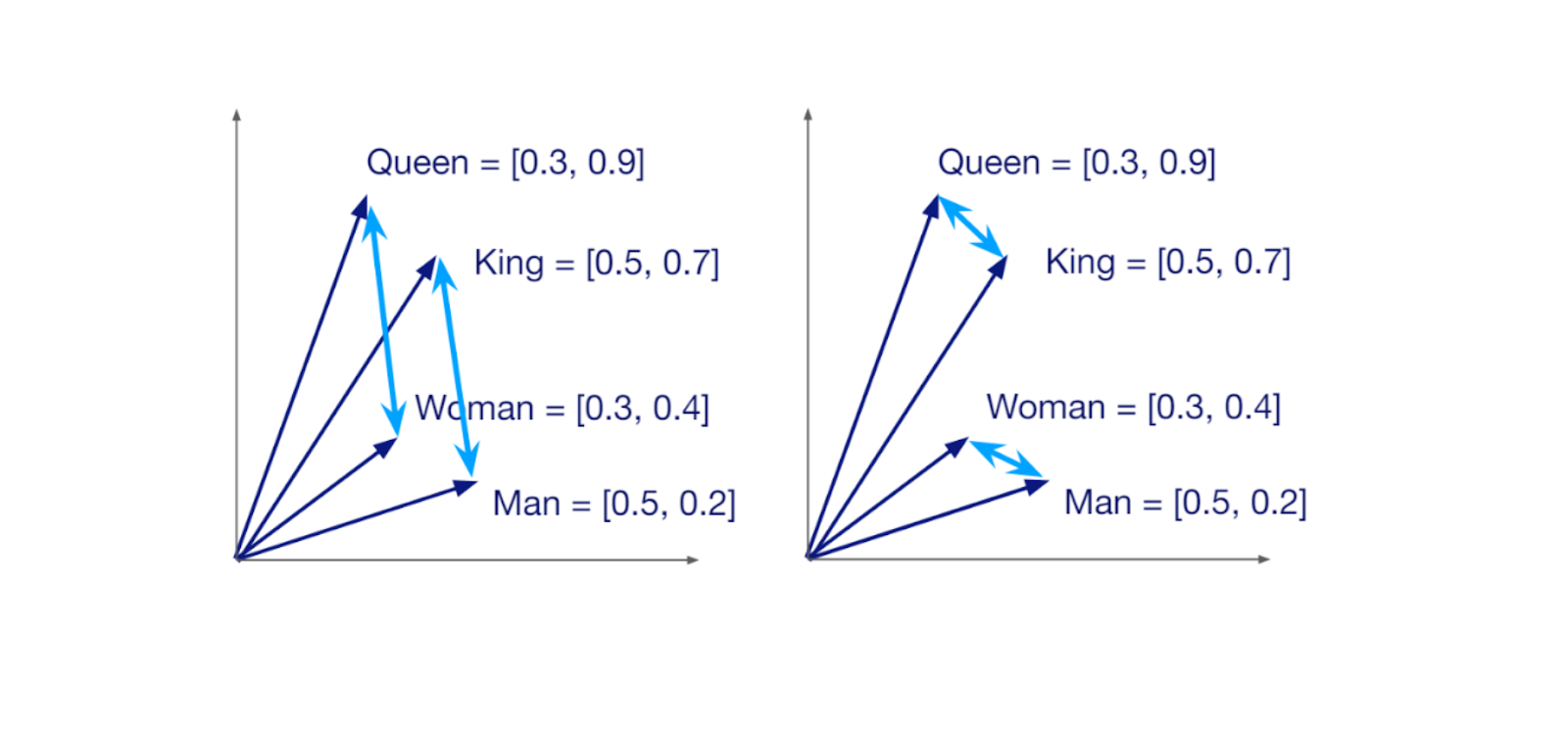
2次元ベクトル空間における類似語の埋め込み。
RAGパイプラインのワークフローは以下のようになる:
1.埋め込みモデルの助けを借りて、生のコンテキストを埋め込みに変換する。
2.これらの埋め込みをベクトルデータベースに格納し、インデックスを付ける。
3.任意のクエリに対して、生のコンテキストに使用したのと同じ埋め込みモデルを使用して、クエリを埋め込みに変換する。
4.ベクトルデータベース内で、クエリ埋め込みとコンテキスト埋め込み間の類似性検索を行う。
5.最も関連性の高い上位n個のコンテキストを取得し、それらのコンテキストを元のクエリと統合して、LLMの入力として1つのまとまったプロンプトにする。
6.LLMは、より正確な結果を得るために、提供された関連するコンテキストを使用して、クエリに対する応答を生成する。
マルチモーダルRAGの基礎
前のセクションで説明したRAGの実装は、LLMの幻覚のリスクを軽減し、LLMの応答の全体的な質を向上させるのに非常に役立つ。しかし、RAGでコンテキストについて話すとき、通常、コンテキストをテキストと呼ぶ。一方、実世界のアプリケーションでは、テキストだけでなく、他のモダリティをコンテキストとして提供したい場合があることがわかっている。
例えば、社内のチャットボットアプリケーションのコンテキストとして、ドキュメントのコレクションを使いたいとします。すでにご存知のように、ドキュメントは通常、テキストだけでなく、画像、図表などで構成されており、ユーザーの問い合わせに答えるための有用な情報がたくさん含まれています。テキストベースのRAGでは、これらの画像や図表に含まれる情報をコンテキストとして保存することはできません。
マルチモーダルRAGは、この問題を解決するものである。このRAG手法では、異なる情報源から得られるすべてのコンテキストを格納することができるため、LLM回答の全体的な精度も向上する。
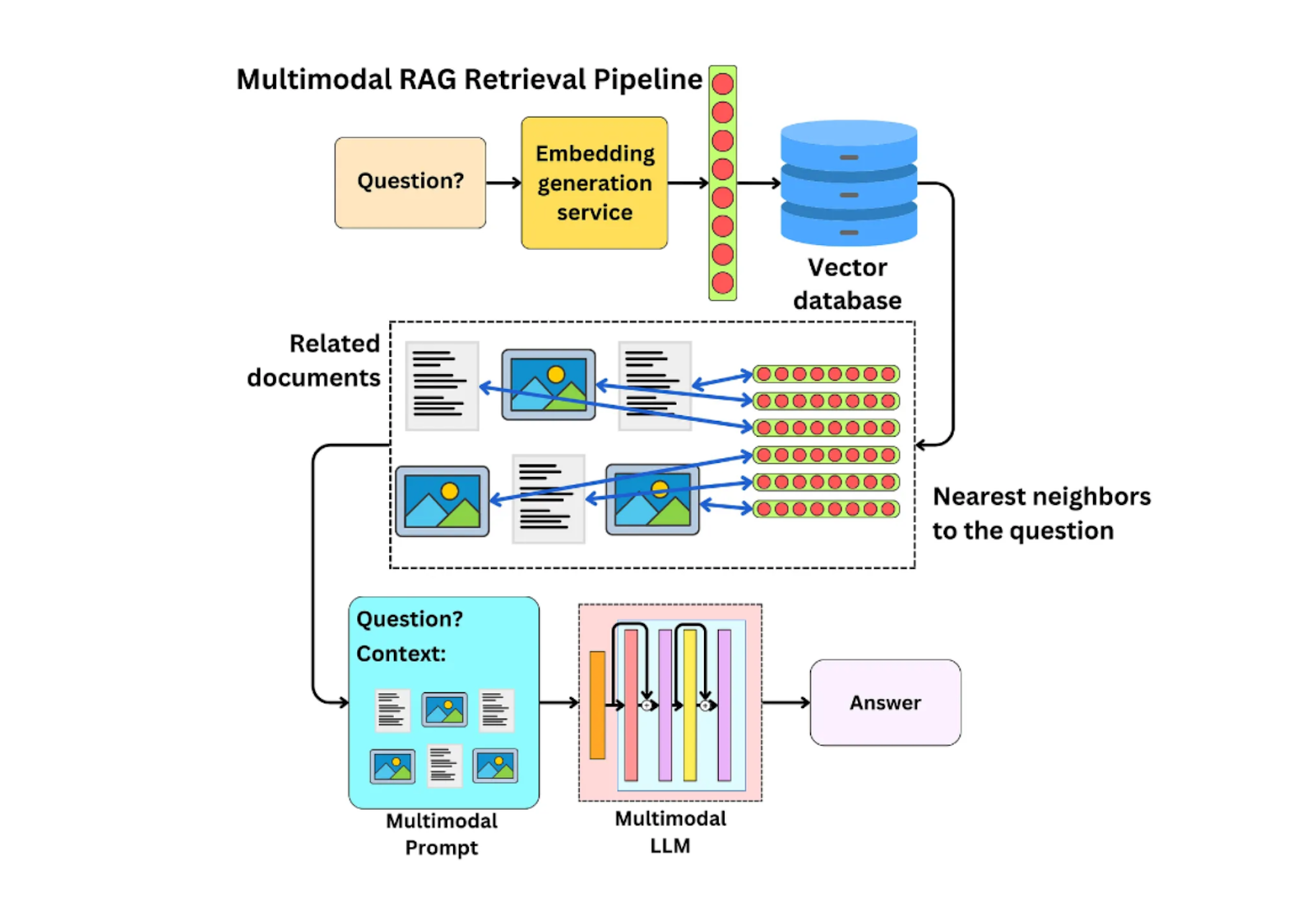
図:マルチモーダルRAGパイプライン_。
マルチモーダルLLM](https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know)と同様に、マルチモーダル埋め込みが登場したおかげで、マルチモーダルRAGの実装が可能になりました。マルチモーダルRAGの考え方は、通常のRAGと全く同じですが、画像、音声、動画などの異なるモダリティのデータを埋め込むことができるようになりました。しかし、マルチモーダルRAGを実装するためには、マルチモーダルLLMだけでなく、マルチモーダル埋め込みモデルも使用する必要があります。
一般的に、マルチモーダルRAGは様々な方法で実装することができる。具体的には、以下の3つのパターンがある:
1.**すべてのモダリティを1つの主要なモダリティに統合する。
2.**すべてのモダリティを同じベクトル空間に埋め込む。
3.**生画像アクセスとのハイブリッド検索。
それでは、これらのパターンについて一つずつ説明していこう。
パターン1:すべてのモダリティを1つの主要モダリティに統合する(マルチメディアからテキストへ)
最初のパターンは、すべてのモダリティを1つの主要なモダリティに変換することです。どのモダリティをプライマリモダリティとして選択しても構いませんが、マルチモーダルRAGで最もよく使われるのはテキストです。したがって、このセクションでは、テキストを主要モダリティとして使用します。
異なるモダリティをテキストに変換するには、マルチモーダルLLMを使ってデータのテキスト要約を生成するのがコツである。例えば、大量のテキストと画像を含む文書があるとしよう。テキストが主要なモダリティなので、ドキュメント内のテキストには何もする必要はない。一方、画像とテキストの両方を入力として受け付けるLLAVA, Gemini, Claude Sonnet, Qwen-VL, Pixtralなどのビジョン言語モデル(VLM)を使って、画像のテキスト要約を生成することができます。
画像のテキスト要約ができたら、text-based embedding model を使って、文書中の他のテキストと一緒にこのテキストを埋め込みに変換することができます。SentenceTransformers、OpenAI、VoyageAIなど、多くのテキスト埋め込みモデルがあります。これらのテキストの埋め込みは、ベクトルデータベースに格納され、インデックス化されます。
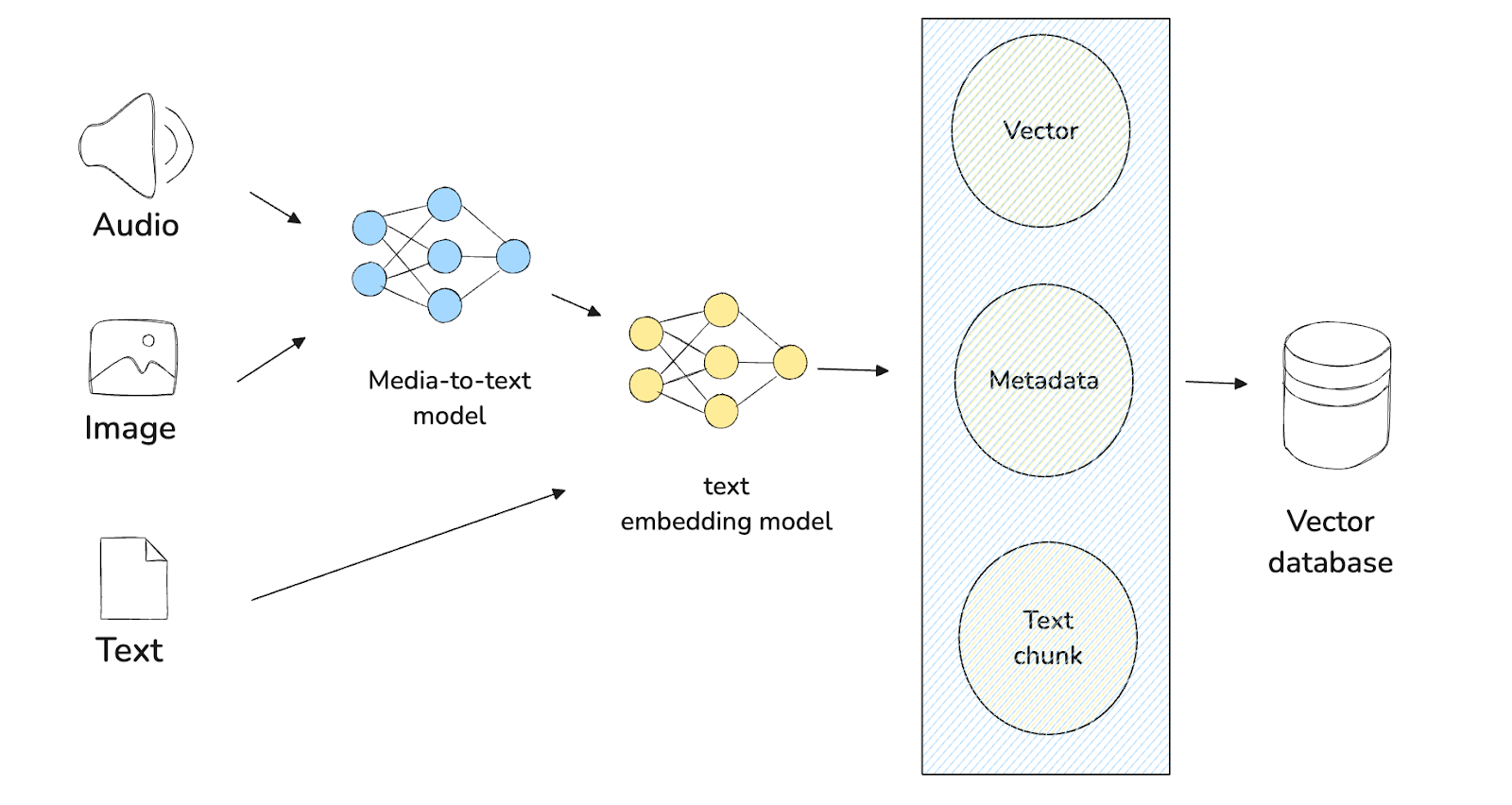
図:パターン1のワークフロー
これで、任意のクエリに対して、前に使ったのと同じテキストベースの埋め込みモデルを使って、埋め込みに変換することができる。その後、最も関連性の高いコンテキストを見つけるために類似検索を実行し、テキストベースのコンテキストをテキストベースまたはマルチモーダルLLMのプロンプトの一部として使用することができます。
このパターンの実装の詳細についてもっと知りたい方は、このパターンを使ってマルチモーダルRAGを構築する手順を説明した 専用記事 があります。
このパターンは、ユースケースにおいてテキスト以外の生のデータにアクセスする必要がない場合に使うのに最適です。アプリケーションは入力として画像を受け入れるかもしれませんが、出力は常にテキストベースです。例えば、社内文書に含まれる画像の内容を説明する機能を持つアプリケーションを構築するような場合です。
しかし、このパターンでは、通常のRAGシステムと同じように、テキストベースのコンテキストに頼っていることに変わりはありません。現実のアプリケーションでは、画像や他のモダリティをコンテキストとして使いたいと思うかもしれない。そこで、2つ目のパターンについて説明しよう。
パターン2:すべてのモダリティを同じベクトル空間に埋め込む
つ目のパターンは、すべてのモダリティのデータを同じベクトル空間に埋め込むというものです。このアプローチの秘密は、CLIPやALIGNのようなマルチモーダル埋め込みモデルの実装にあります。CLIPを例に説明しよう。
CLIPはOpenAIによって開発されたモデルで、テキストと画像の両方を入力のペアとして受け取り、テキストと画像の類似性を判断するように訓練されている。その結果、CLIPは、テキストが画像と一致していれば高い類似性スコアを与え、その逆もまた同様である。
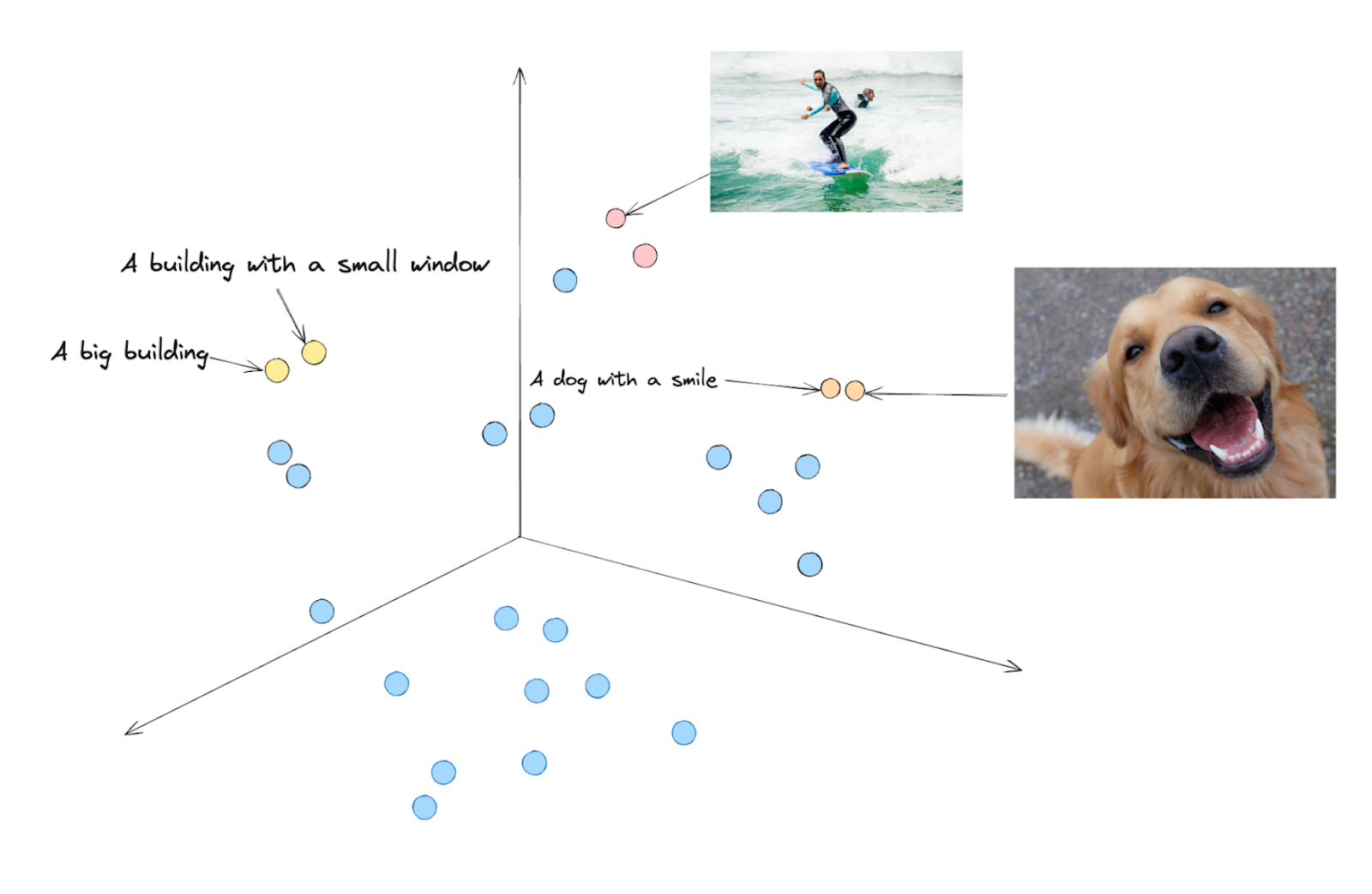
図:CLIPによる異なるモダリティのデータの3次元ベクトル空間への埋め込み_。
上の図のように、「微笑む犬」という文章と微笑む犬の画像があるとします。CLIPは、まずテキストと画像の両方を同じような次元の埋め込みに変換し、ベクトル空間を確認すると、両方の埋め込みは互いに近くに配置される可能性が高い。
我々はマルチモーダル埋め込みモデルを持っているので、このパターンの最初のステップは、異なるモダリティのデータを、このマルチモーダル埋め込みモデルを使って埋め込みに変換することである。次に、これらの埋め込みデータをMilvusやZilliz Cloudのようなベクトルデータベースに格納し、インデックスを作成する。ユーザークエリがあれば、同じマルチモーダル埋め込みモデルを用いて変換し、類似検索を実行して、最も関連性の高いコンテキストを見つけることができる。
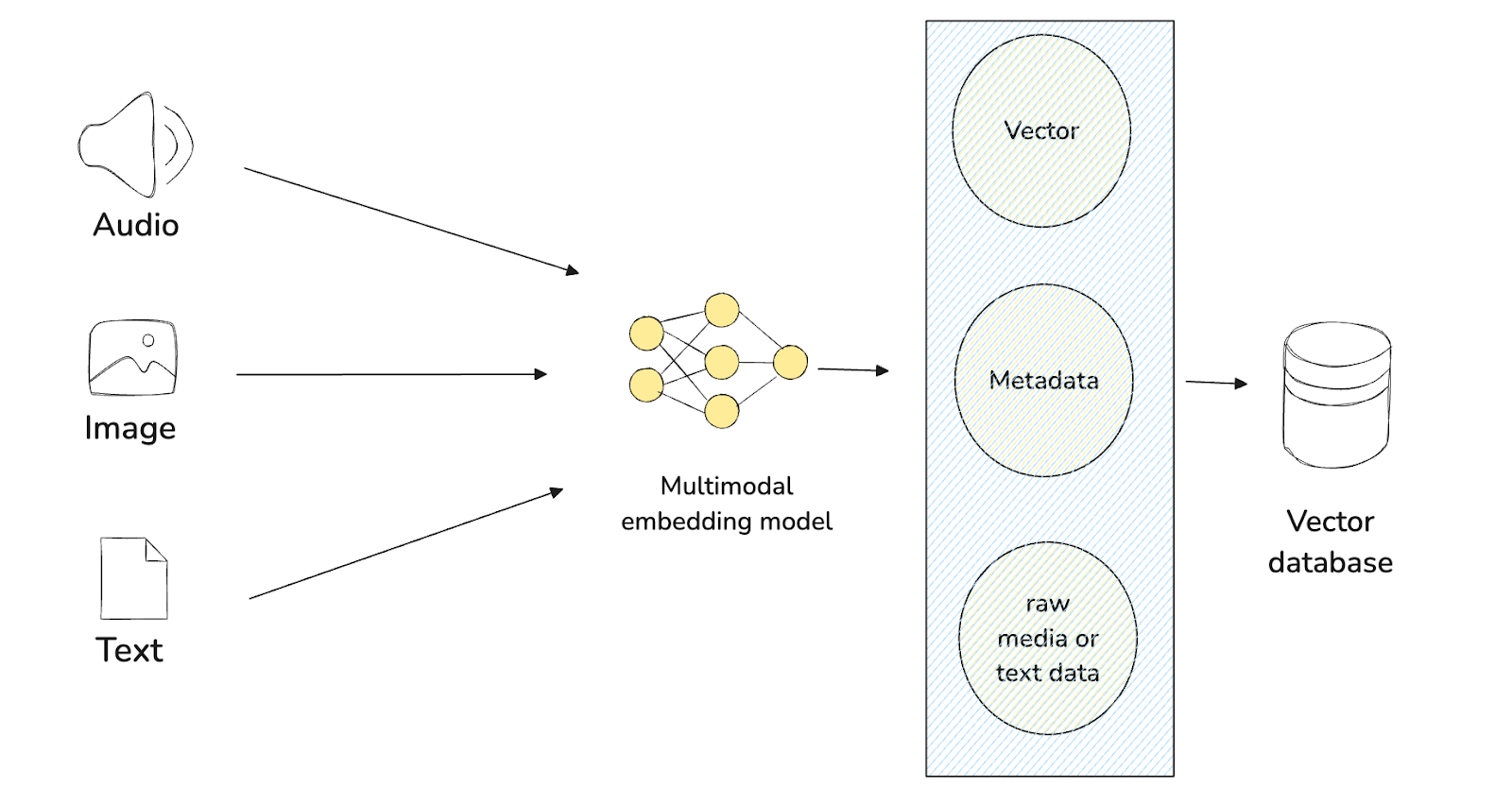
図:パターン2のワークフロー
このパターンを適用する際に検索されるコンテキストは、画像やテキストなど、さまざまなモダリティを持つデータになりうる。したがって、これらのコンテキストを考慮して最終的な応答を生成するために、マルチモーダルLLMを使用する必要がある。データが画像とテキストで構成されている場合、LLAVA、Gemini、Claude Sonnet、Qwen-VL、Pixtralなどのような視覚言語モデル(VLM)を使うことができる。
このパターンの実装の詳細についてもっと学びたいのであれば、このパターンを使ってマルチモーダルRAGを構築する手順を説明する 専用記事 があります。ただし、その記事では、生の画像はベクターデータベースに直接保存されるのではなく、ローカルメモリに保存されることに留意してください。
このパターンの主な利点は、汎用性とシンプルさである。マルチモーダル埋め込みモデルを実装しているため、最初のパターンで行ったように、すべてのモダリティの内容を主要なモダリティに変換する追加ステップが必要ない。また、類似検索の後に検索されるコンテキストは、特定のモダリティだけでなく、あらゆるモダリティのデータとすることができる。
しかし、どのようなモダリティのデータでもマルチモーダルLLMの関連するコンテキストとして使用できるため、このパターンを実装する際には生データも保存する必要がある。問題は、画像のような非テキストデータのメモリサイズは大きく、ベクターデータベースに直接格納するとリソースの非効率的な利用につながることだ。これは結局、クエリー時間の低下やストレージコストの増大にもつながる。
したがって、異なるモダリティのデータをコンテクストとして使用する必要があるが、ユースケースにおいてスケーラビリティを気にする必要がない場合は、このパターンを使用することをお勧めします。
パターン3:生画像アクセスによるハイブリッド検索。
様々なモダリティのデータをコンテキストとして使用する必要があり、スケーラビリティも懸念される場合、このパターンを実装することができる。このパターンの主なアイデアは、懸念事項の分離である。関連するコンテキストを見つけるために高速かつ効率的な類似検索を実行するためにベクトルデータベースを使用し、生データを保存するためにAWS S3やGoogle Cloud Storageのような専用のオブジェクトストレージシステムを使用する。
このパターンの実装では、2つの異なるステップを実行する必要がある。まず、実際の生データをAWS S3やGoogle Cloud Storageのような専用のオブジェクトストレージシステムに保存する。第二に、ベクターデータベース内に生データのメタデータを格納する。
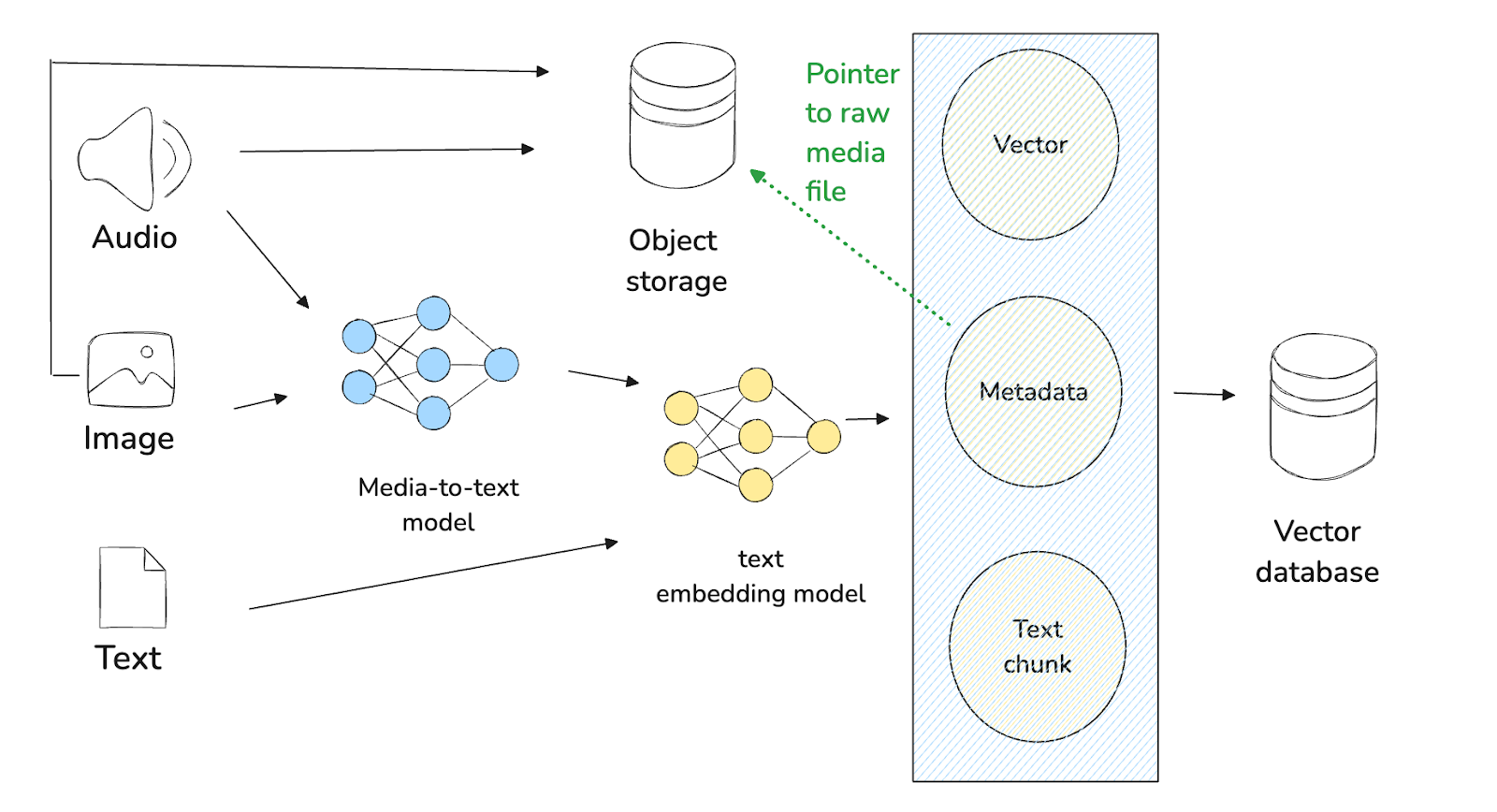
図:パターン3のワークフロー
生データを保存するために別のシステムを使うので、RAGを実行する方法は最初のパターンとほぼ同様である。テキストが主要なモダリティであるとしよう。最初に必要なことは、マルチモーダルLLMを使って生データのテキスト要約を生成することである。次に、テキストベースの埋め込みモデルを使って、テキスト要約を埋め込みに変換します。そして、埋め込みデータと生データのメタデータ(専用ストレージシステム内の生データのURL)をベクトルデータベースに格納する。
任意のクエリに対して、同じマルチモーダルLLMを使ってテキスト要約を生成し、同じテキストベースの埋め込みモデルを使ってクエリの要約を埋め込みに変換する。次に、類似検索を実行し、テキストの要約と関連するコンテクストのURLを取得する。最後に、取得したURLを介して、生データをマルチモーダルLLMに渡すことができる。
繰り返しになるが、このパターンを使ってマルチモーダルRAGを構築する手順を説明したこの 記事を参照することができる。ただし、この記事では、生画像はAWSやGCPのような典型的な本番用ストレージシステムではなく、ローカルメモリに保存されていることに留意してください。
3つの選択肢の中で、このパターンは生データのストレージを分離しているため、最もスケーラブルなものである。すでにご存知のように、ベクターデータベースは非構造化データのクエリ用に最適化されており、画像のような大きなバイナリオブジェクトの保存や提供には向いていない。実際、ベクトル・データベースからバイナリ・オブジェクトを検索するのは、専用のオブジェクト・ストレージ・システムから検索するよりも遅いことが多い。
従って、様々なモダリティのデータをコンテキストとして使いたい場合や、スケーラビリティがユースケースにとって大きな関心事である場合は、このパターンを使うことをお勧めします。
どのようにMilvusベクターデータベースはマルチモーダルRAGをサポートするか?
前のセクションで述べたように、ベクトルデータベースは、検索拡張生成(RAG)の応用において重要な役割を果たしている。Milvusは、その高度な機能により、RAGシステムやその他のAIアプリケーションに最適なベクトルデータベースです。
Milvusには、IVFFLAT、HNSW、SCANNなど、最も単純なものからより高度なものまで、さまざまなインデックス作成方法が用意されており、膨大なデータの集合を高速かつ効率的に格納することができます。これらの高度なインデクシング手法の実装は、RAGの実装において、関連するコンテキストを見つけるための類似性検索プロセスも高速化する。
マルチモーダルRAGのための一般的なツールとのMilvusの容易な統合_。
Milvusは、エンベッディングモデル、LLM、オーケストレーションツールなど、前節で説明したすべてのRAGコンポーネントと簡単に統合することもできます。埋め込みモデルに関しては、OpenAI、Cohere、SentenceTransformers、HuggingFace、VoyageAIなどの人気オプションを、pymilvusというMilvusのPython SDKを使って直接利用することができます。pymilvusはpipコマンドでインストールできます:
pip install -U pymilvus
ここで、SentenceTransformersの埋め込みモデルを使いたいとすると、以下のようにpymilvusを使えば簡単にできる:
pip install "pymilvus[model]"
from pymilvus import モデル
sentence_transformer_ef = model.dense.SentenceTransformerEmbeddingFunction(
model_name='all-MiniLM-L6-v2', # モデル名を指定する。
device='cpu' # 使用するデバイスを指定(例:'cpu'または'cuda:0'
)
doc = [
「人工知能は1956年に学問分野として創設された。]
doc_embedding = sentence_transformer_ef.encode_documents(doc)
Pymilvusがサポートする様々な埋め込みモデルについては、 この統合ページ を参照してください。
LLMやオーケストレーションツールに関しては、MilvusはvLLM、Ollama、Gemini、LlamaIndex、Langchainのような一般的なフレームワークと簡単に統合することができます。Milvusとこれらのツールの統合についてより詳しく知りたい方は、チュートリアルをまとめたこちらのページをご覧ください。また、Milvusを使用したシンプルなマルチモーダルRAGの構築方法を学ぶことができる簡単なチュートリアルもありますこちらのドキュメントページ。
結論
マルチモーダルRAGは、LLM応答の精度を向上させるために多様なデータモダリティを利用する上で大きな進歩である。本稿では、マルチモーダルRAGを実装するための3つの主要なパターンについて説明した:全てのモダリティを主要なモダリティに統合する、それらを統一されたベクトル空間に埋め込む、または生データアクセスとのハイブリッド検索を採用する。適切なパターンの選択は、AIアプリケーションの特定のニーズに依存する。
Milvusベクトルデータベースは、その高度なインデックス作成方法と、埋め込みモデル、LLM、オーケストレーションツールとの容易な統合により、マルチモーダルRAGシステムの実装に適したシステムを提供します。AIアプリケーションの範囲と複雑さが拡大するにつれ、Milvusのようなスケーラブルなベクトルデータベースシステムの活用がますます重要になります。
読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.