




Building RAG Applications with Milvus, Qwen, and vLLM
Introduction
In August 2023, the Alibaba Group released a family of state-of-the-art open-source models called Qwen that combine multilingual fluency, advanced reasoning capabilities, and high efficiency. Qwen introduces a scalable transformer-based architecture optimized for diverse applications, including natural language understanding, vision and audio capabilities, mathematical problem-solving, and code generation. This series of decoder-only Large Language Models (LLMs) unlocks powerful possibilities for building Retrieval Augmented Generation (RAG) systems and introduces innovative capabilities to the current competitive open-source ecosystem.
While LLMs can be run on CPUs or through dedicated inference endpoints, tools like vLLM offer specialized solutions for efficient large-scale model deployment. vLLM is an open-source library designed to optimize the inference process of transformer-based models, particularly for massive model sizes like Qwen. By leveraging state-of-the-art memory optimization and parallelization techniques, vLLM enhances the performance of large models, making them more accessible and scalable for production environments. Integrating Qwen with vLLM enables seamless and efficient deployment of complex models, which facilitates the utilization of LLMs in real-time applications across various industries.
In this blog, we will explore Qwen and vLLM and how combining both with the Milvus vector database can be used to build a robust RAG system. These three technologies combine the strengths of retrieval-based and generative approaches, creating a system capable of addressing complex queries in real time. Milvus enhances the system by efficiently managing and querying large-scale embeddings, while Qwen’s advanced language capabilities provide the foundation for responses. With vLLM optimizing the deployment, this integration delivers a high-performance solution for a wide range of AI-driven applications.
Qwen Series Models Overview
In their first technical report , Alibaba Group explained that the name Qwen is derived from "Qianwen," which means "thousands of prompts" in Chinese. The Qwen models were trained using up to 3 trillion tokens of multilingual text and code, incorporating advanced fine-tuning techniques such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
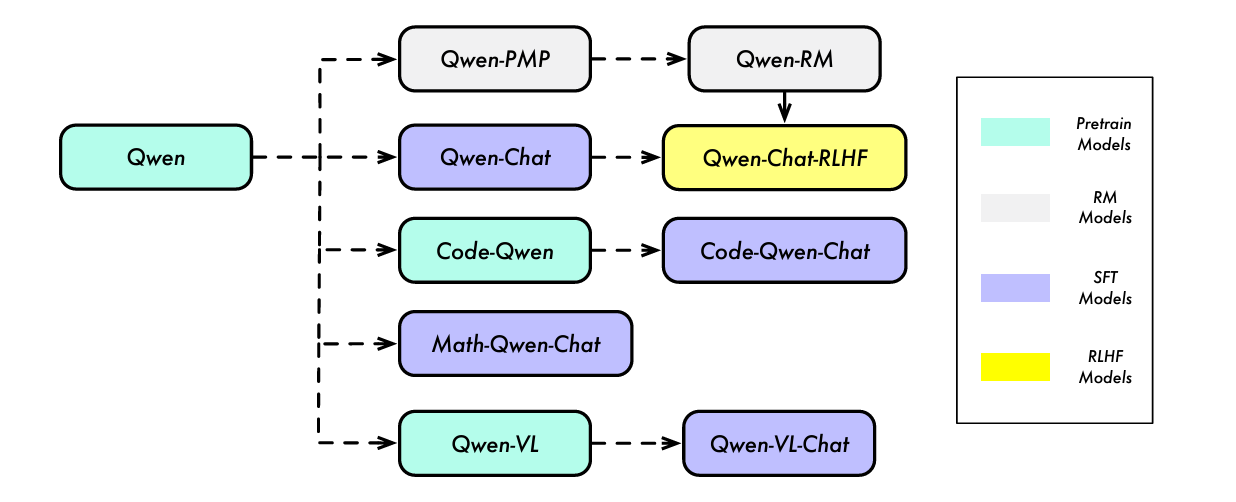 Figure 1- Model Lineage of the Qwen Series
Figure 1- Model Lineage of the Qwen Series
Figure 1: Model Lineage of the Qwen Series (Source)
The base Qwen models come in four sizes, ranging from 1.8 billion to 72 billion parameters. The models have specialized versions for tasks such as mathematics and coding. Since their initial release, Qwen models have evolved, improving the model size, performance, language capabilities, and context length. Currently, Qwen models are categorized as follows:
First releases: Qwen 1.8B, 7B, 14B and 72B
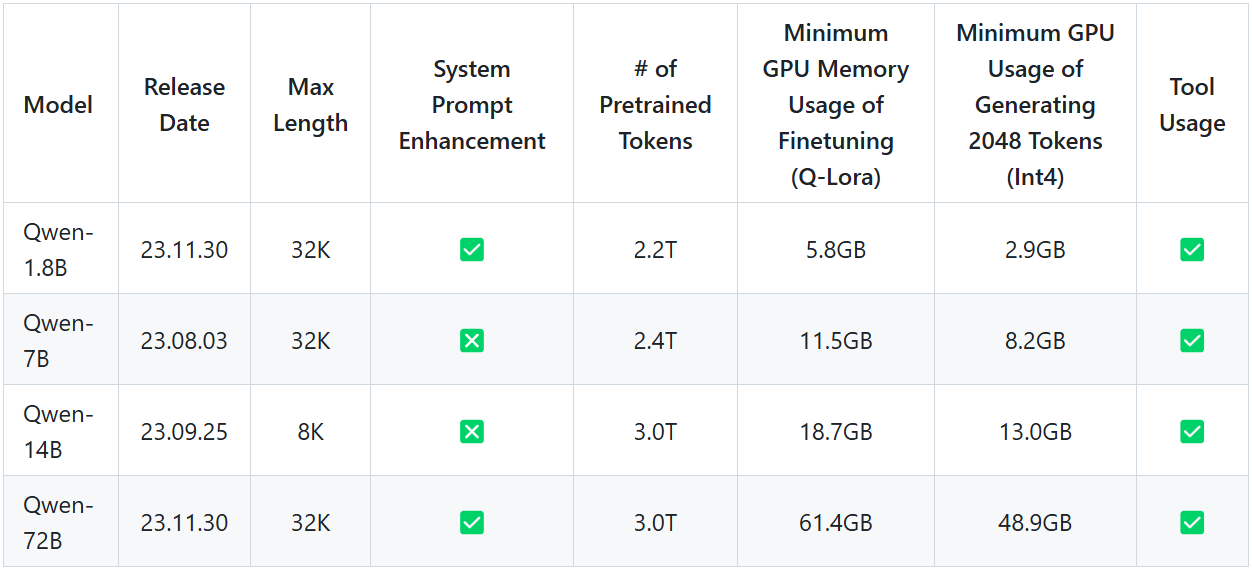 Figure 2- Qwen First Releases .png
Figure 2- Qwen First Releases .png
Figure 2: Qwen First Releases (Source)
Qwen Vision Model Series
The Qwen Vision Model was initially released with two versions: Qwen-VL and Qwen-VL-Chat. These models were designed to handle vision-based tasks like document reading, mathematical reasoning, and visual question answering. They have since been upgraded to the Qwen-VL and Qwen2-VL versions, the latest being the most advanced, which provide significant performance improvements, outperforming models like Google’s Gemini and OpenAI’s GPT in various vision benchmarks:
Qwen-VL: Qwen-VL-Plus and Qwen-VL-Max.
Qwen2-VL: Qwen2-VL-2B, Qwen2-VL-7B and Qwen2-VL-72B.
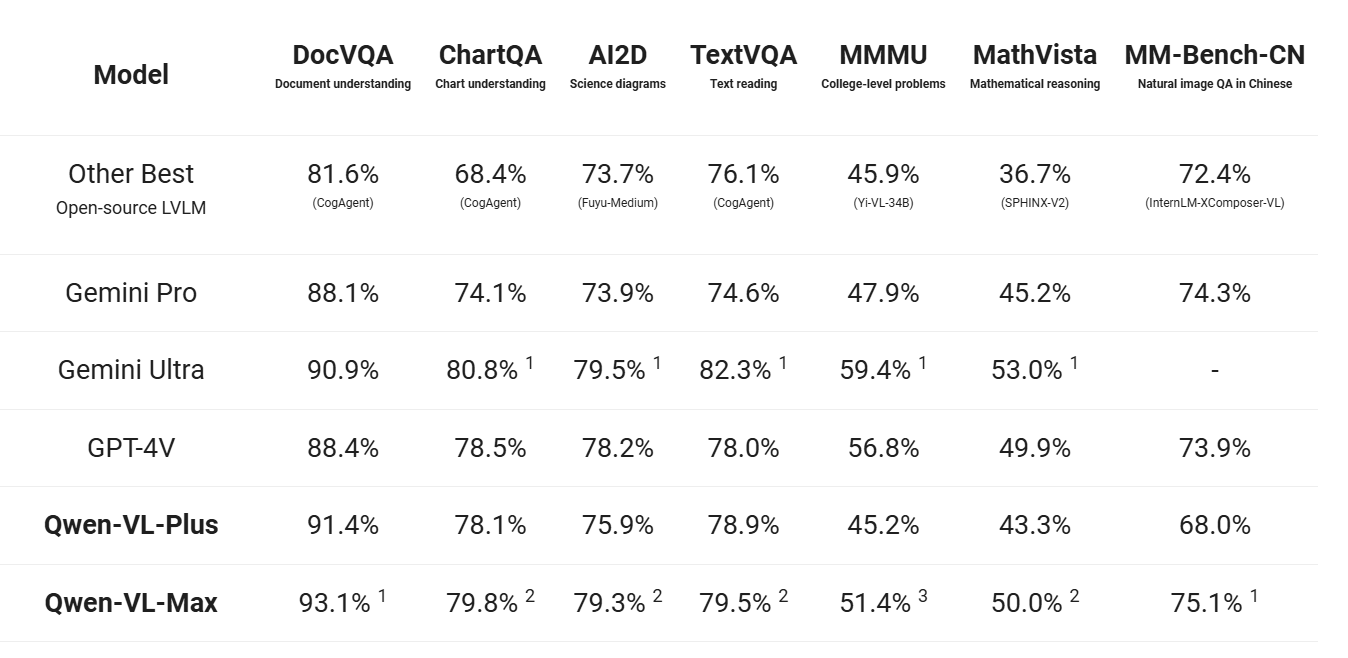 Figure 3- Qwen-VL Benchmark Comparison.png
Figure 3- Qwen-VL Benchmark Comparison.png
Figure 3: Qwen-VL Benchmark Comparison (Source)
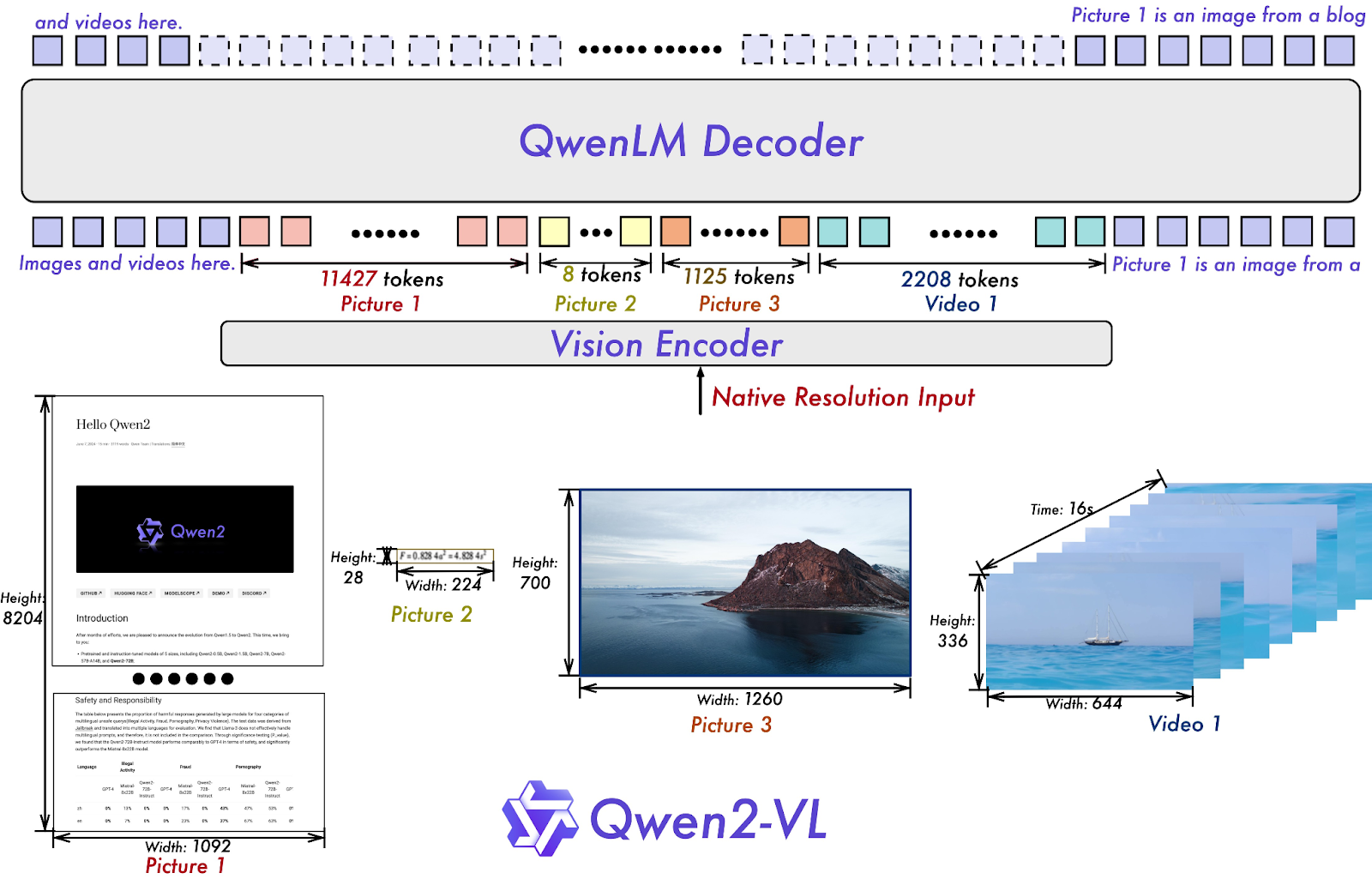 Figure 4- Qwen2-VL Architecture.png
Figure 4- Qwen2-VL Architecture.png
Figure 4: Qwen2-VL Architecture (Source)
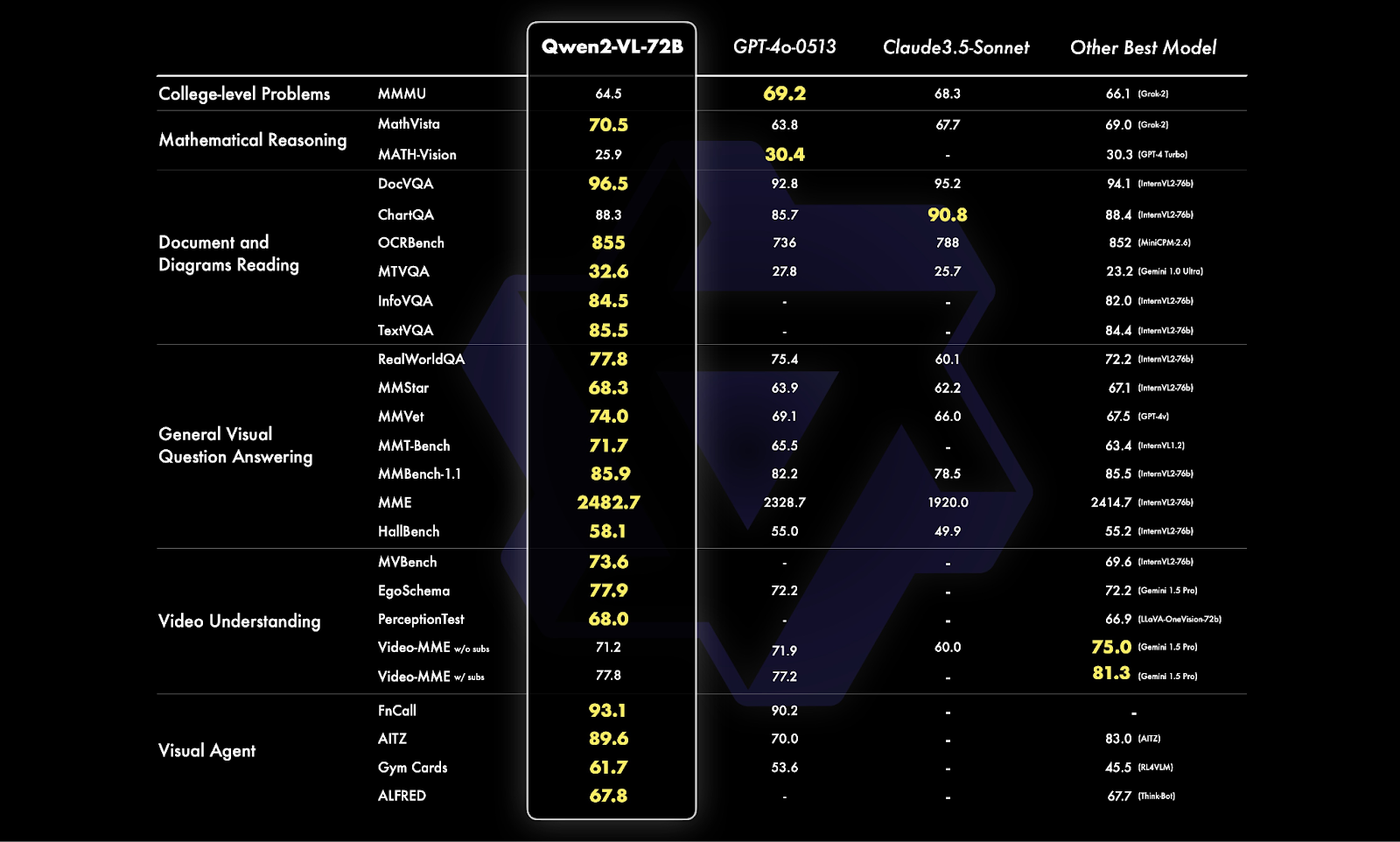 Figure 5- Qwen2-VL-72B Benchmark Comparison.png
Figure 5- Qwen2-VL-72B Benchmark Comparison.png
Figure 5: Qwen2-VL-72B Benchmark Comparison (Source)
Qwen Audio Series
Similar to the vision model, the Qwen Audio series was initially released with two versions: Qwen-Audio (a multi-task audio-language model) and Qwen-Audio-Chat (a version fine-tuned with instructions). These models were designed to handle both audio and text inputs, generating text-based outputs. With the advent of the Qwen2 series, both models have been further enhanced:
- Qwen2-Audio-7B and Qwen2-Audio-7B-Instruct: These models can accept both audio and text inputs and generate text outputs, improving multilingual capabilities for applications such as speech recognition, transcription, and voice-based AI assistants
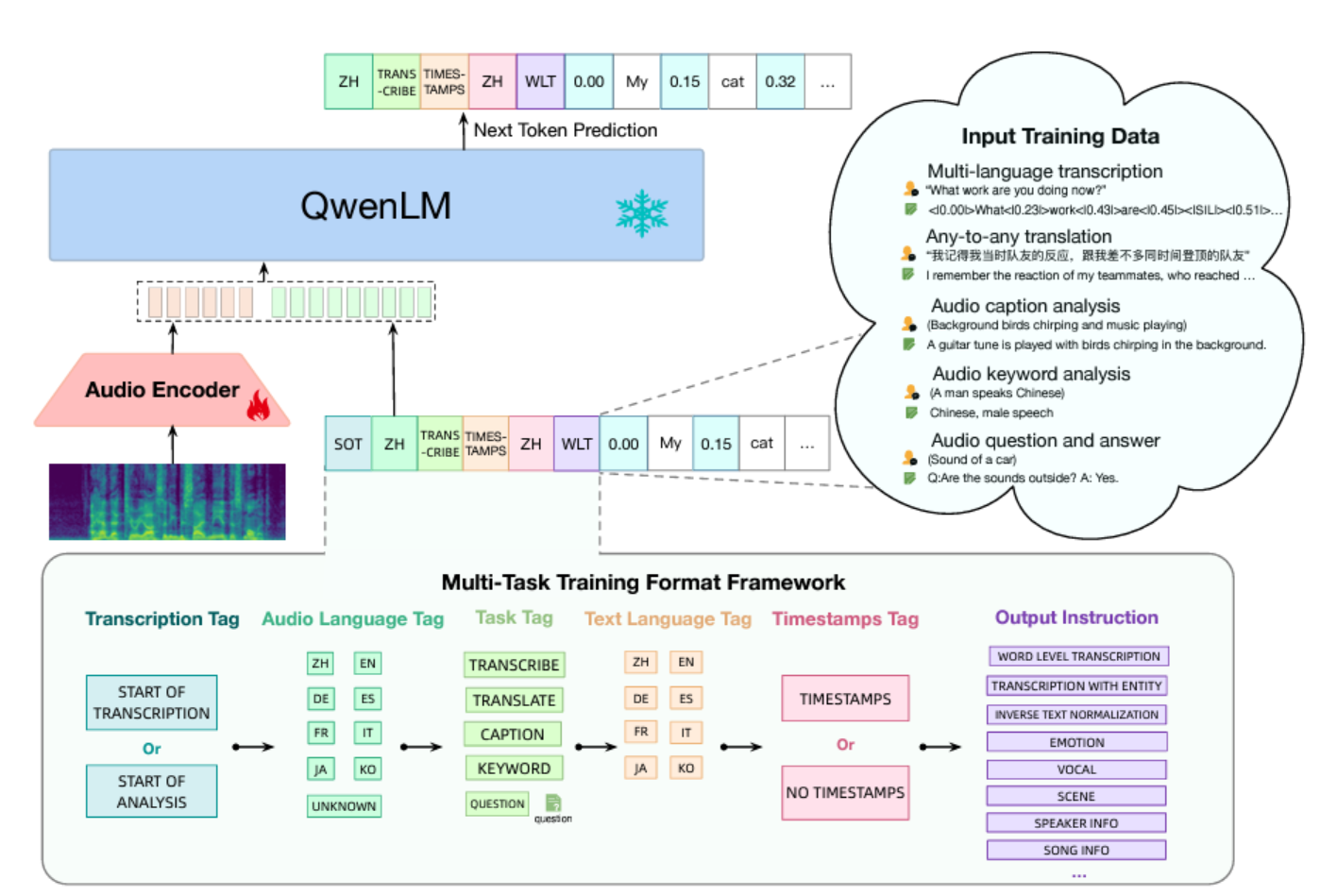 Figure 6- Qwen-Audio Architecture
Figure 6- Qwen-Audio Architecture
Figure 6: Qwen-Audio Architecture (Source)
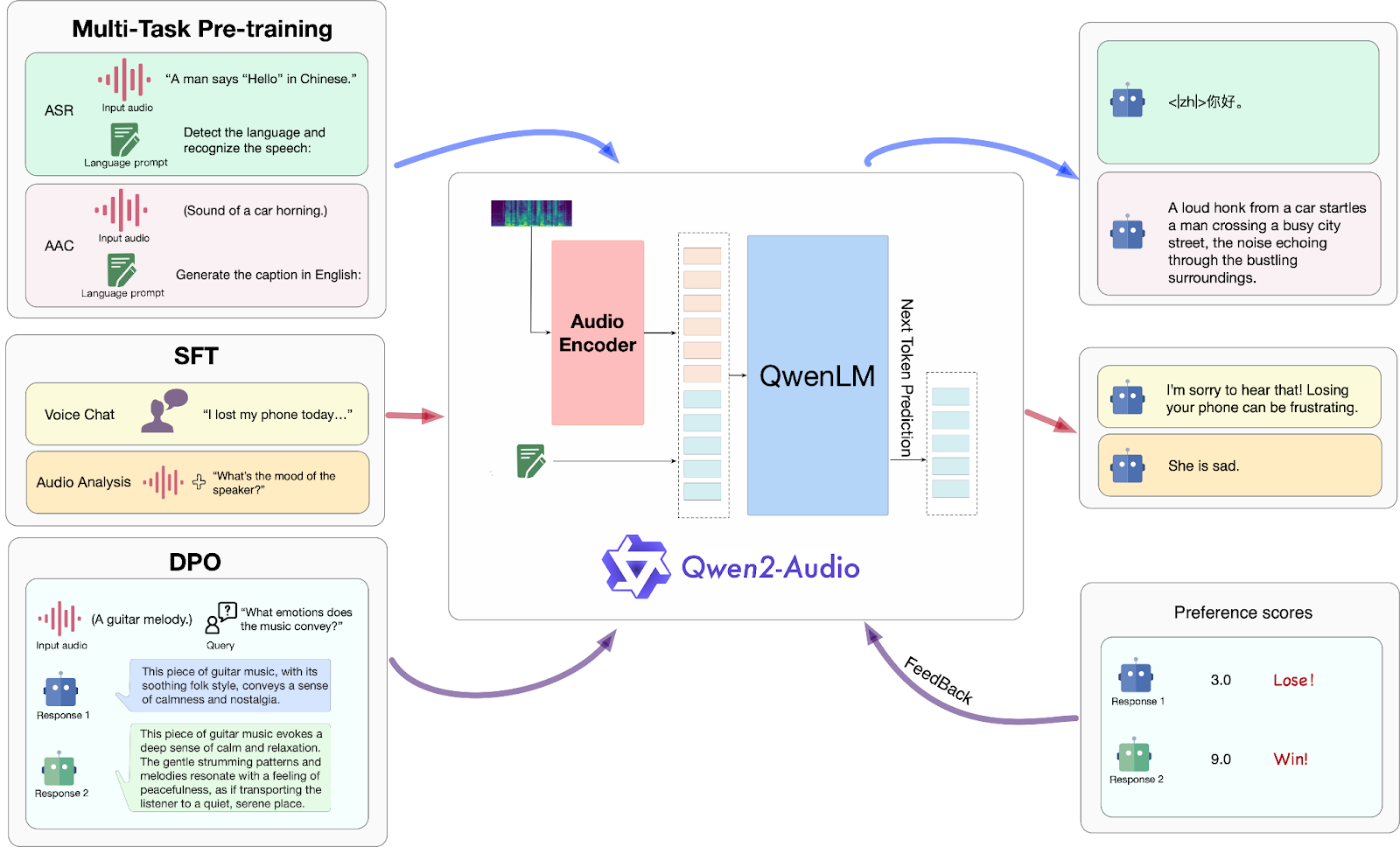 Figure 7- Qwen2-Audio Architecture
Figure 7- Qwen2-Audio Architecture
Figure 7: Qwen2-Audio Architecture (Source)
Qwen 2.5 Series
The Qwen 2.5 series builds on the foundations of the original Qwen models with two significant upgrades: Qwen 1.5 and Qwen 2. These series introduce specialized models designed to extend the capabilities of the Qwen family further, offering advanced enhancements across various domains such as mathematics, coding, and general language understanding. Notably, the Qwen 1.5 release also included a Mixture of Experts (MoE) version, adding versatility and performance improvements to the model suite. These developments make the Qwen 2.5 series highly adaptable for specialized tasks while retaining broad applicability.
Qwen 2.5 models are available in a range of sizes, including 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B, offering flexibility for different use cases:
Qwen 2.5-Math: This model is specifically designed for solving complex mathematical problems. It delivers accurate solutions across various fields, from basic arithmetic to advanced calculus. The series includes models of different sizes: 1.5B, 7B, and 32B, as well as the Qwen 2.5-Math-RM-72B, a specialized version optimized with a mathematical reward model for even greater precision in mathematical tasks.
Qwen 2.5-Coder: A model fine-tuned for code generation and debugging, Qwen 2.5-Coder is ideal for automating programming tasks, including script writing, code completion, and code reviews. The model is available in sizes 0.5B, 1.5B, 3B, 7B, 14B, and 32B, providing flexibility for developers working on a wide range of coding applications.
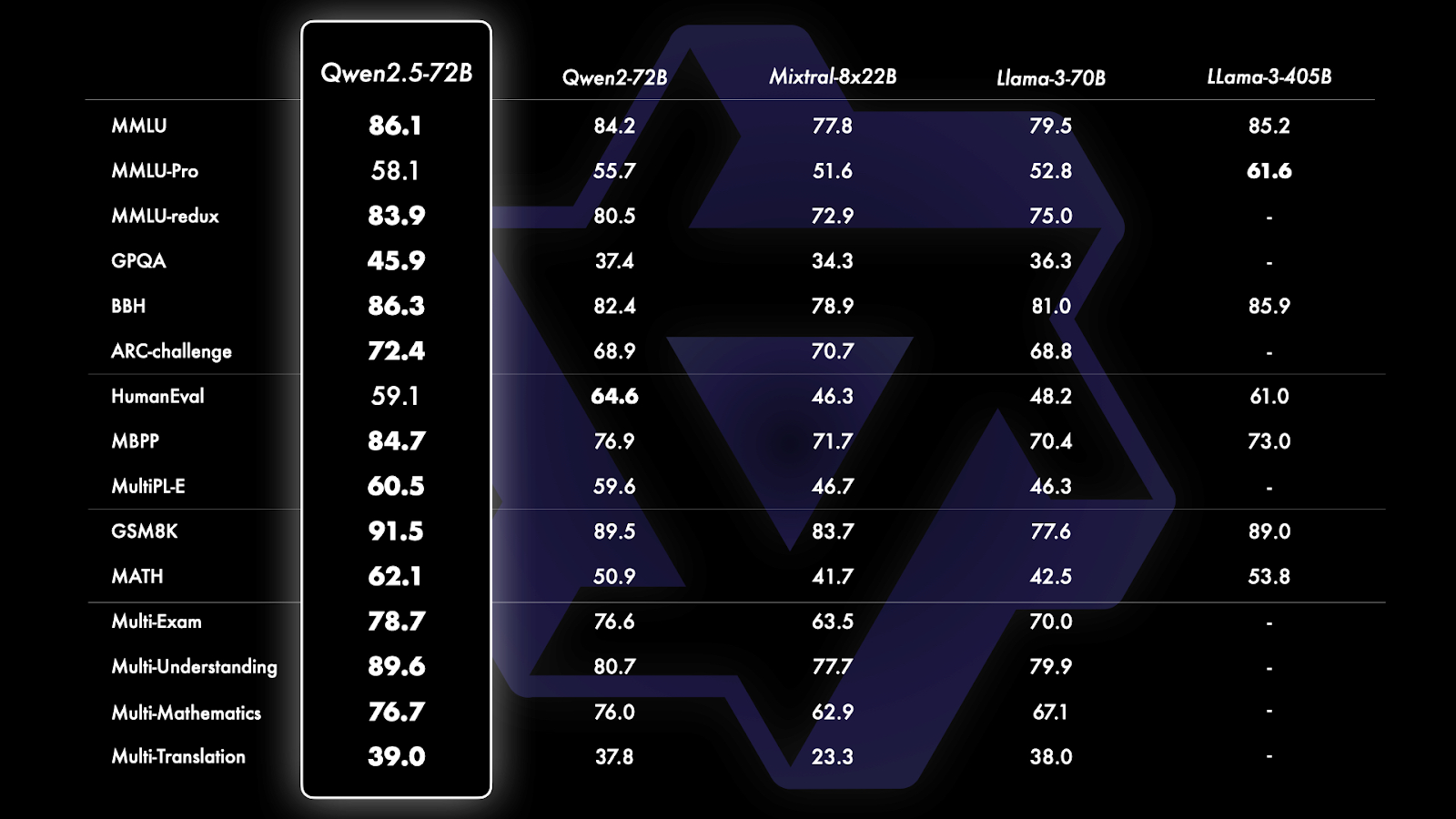 Figure 8- Qwen 2-5 Benchmark Comparison.png
Figure 8- Qwen 2-5 Benchmark Comparison.png
Figure 8: Qwen 2-5 Benchmark Comparison (Source)
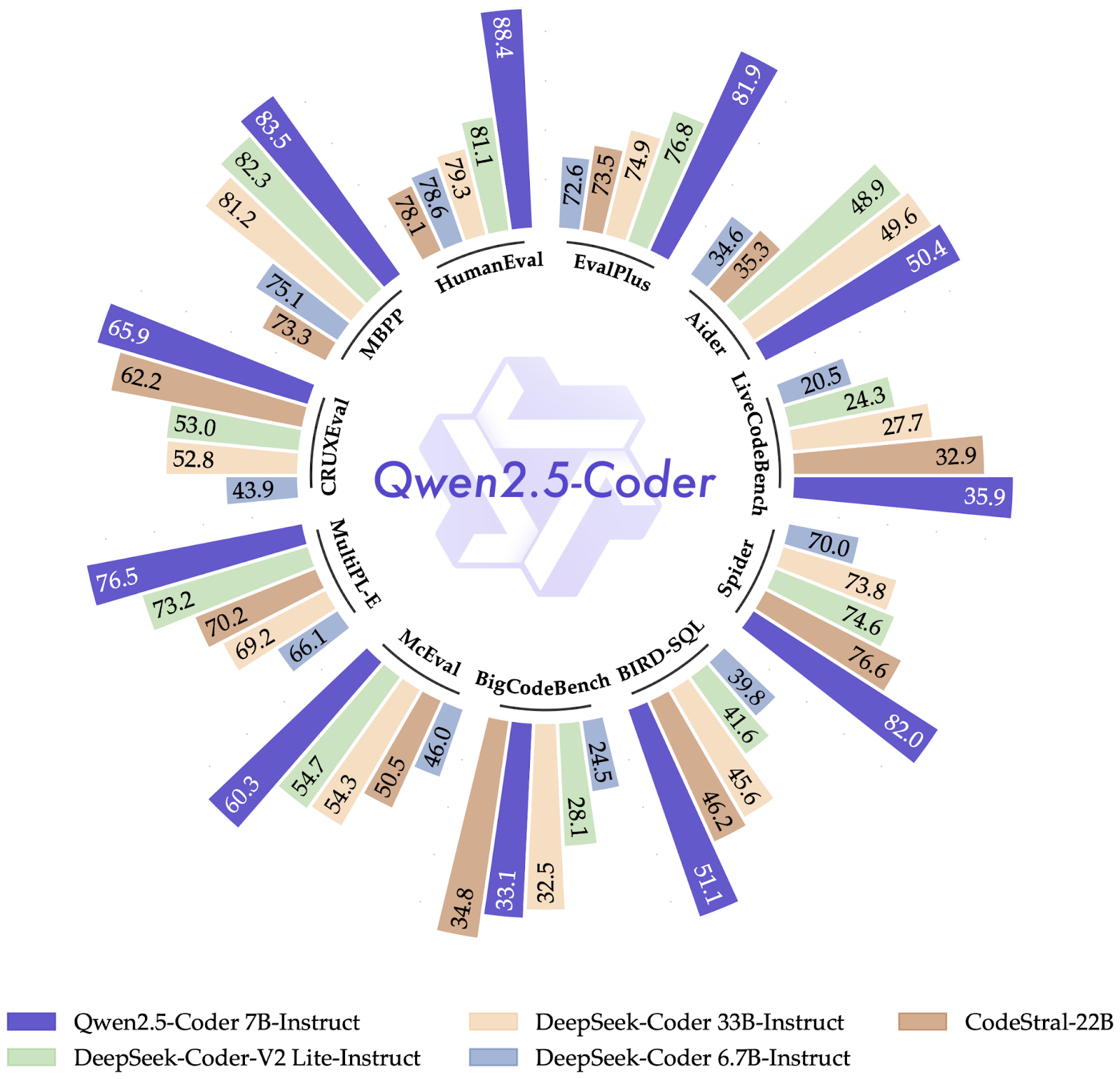 Figure 9- Qwen 2-5-Coder Benchmark Comparison
Figure 9- Qwen 2-5-Coder Benchmark Comparison
Figure 9: Qwen 2-5-Coder Benchmark Comparison (Source)
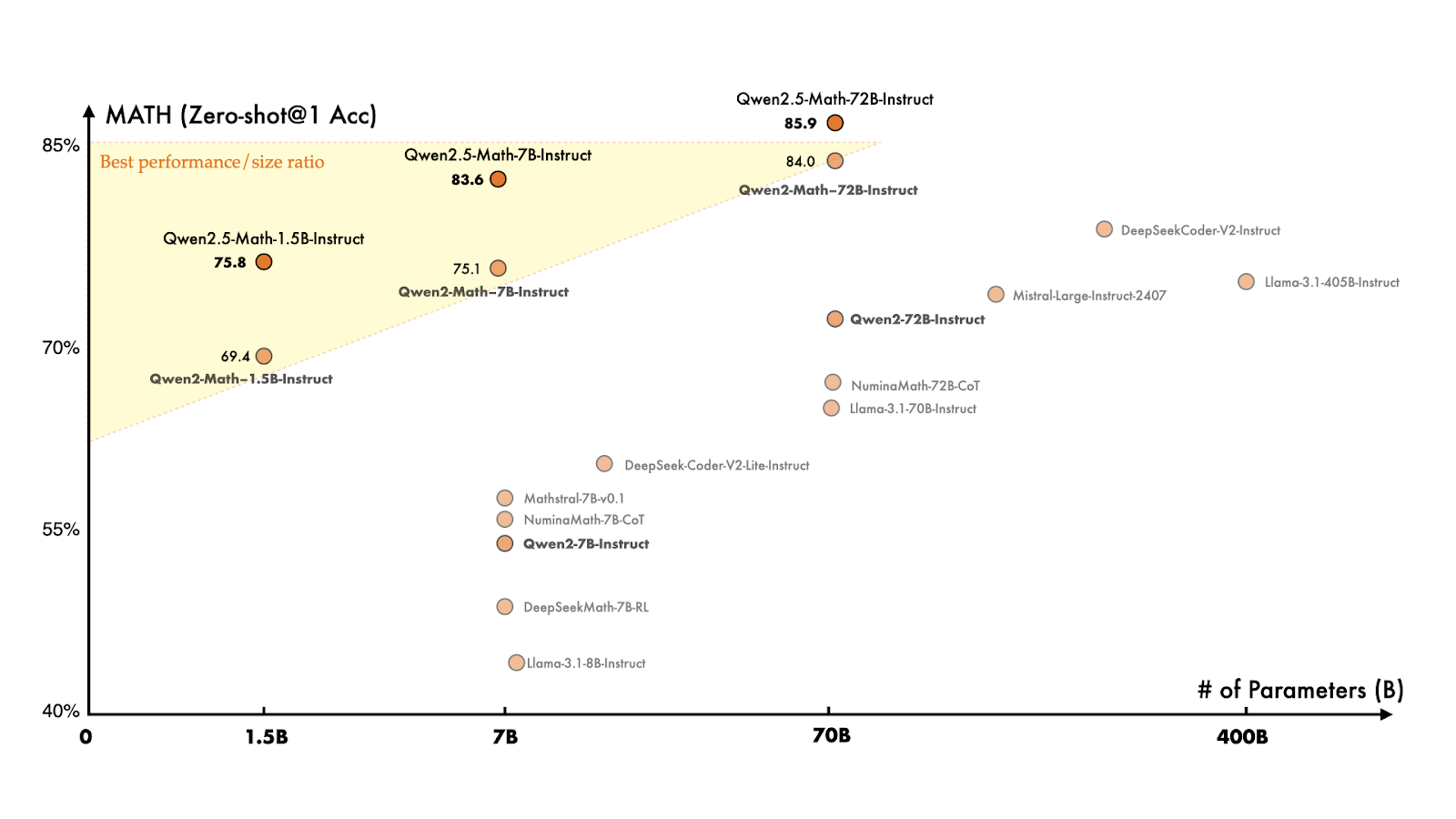 Figure 10- Qwen 2-5-Math Benchmark .png
Figure 10- Qwen 2-5-Math Benchmark .png
Figure 10: Qwen 2-5-Math Benchmark (Source)
QwQ Series
The QwQ series, currently an experimental research model, represents a bold leap into advanced AI reasoning. The model acts like a thoughtful student, embodies curiosity, questioning its own reflections before offering insights. Focused on solving complex problems in mathematics, coding, and reasoning, the inaugural release, QwQ-32B-Preview, showcases exceptional performance in benchmarks such as GPQA, AIME, and MATH-500.
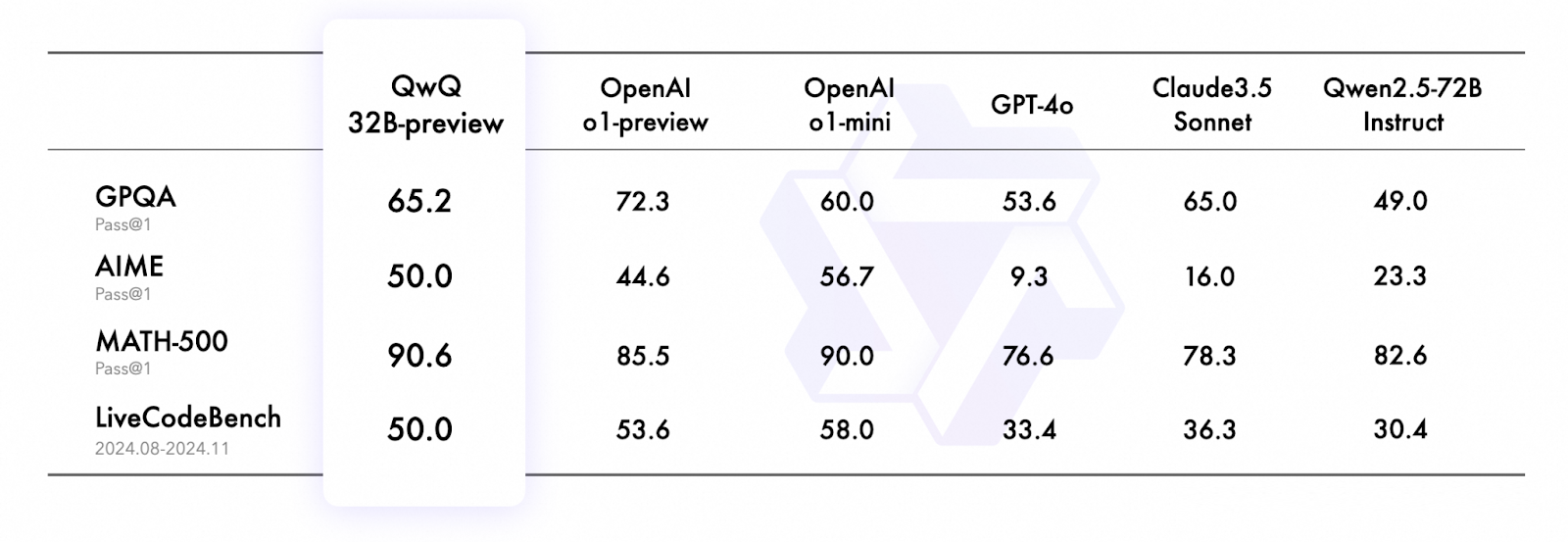 Figure 11- QwQ Benchmark Comparison
Figure 11- QwQ Benchmark Comparison
Figure 11: QwQ Benchmark Comparison (Source)
vLLM: Optimizing Large Model Inference
vLLM (Virtual Large Language Model) is an open-source library designed to optimize inference for large language models, addressing key challenges in deploying transformer-based architectures at scale. Through innovative techniques such as PagedAttention, tensor parallelism, and efficient caching strategies, vLLM achieves significant reductions in computational overhead and memory usage during inference. These optimizations enable the deployment of larger and more complex models with enhanced efficiency, reducing the cost and effort required to run state-of-the-art AI systems.
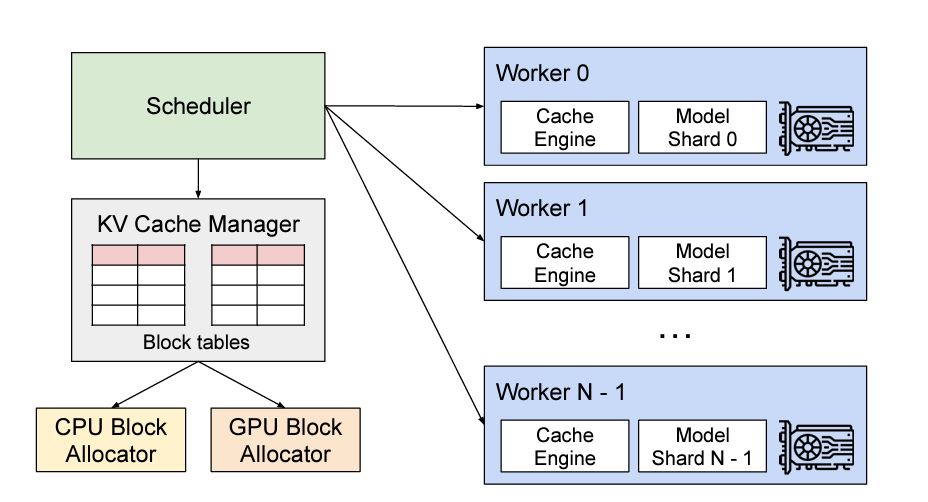 Figure 12- vLLM System Overview.png
Figure 12- vLLM System Overview.png
Figure 12: vLLM System Overview (Source)
Key Features and Innovations
PagedAttention
The standout feature of vLLM, PagedAttention, revolutionizes GPU memory management by adopting principles from operating system memory management. This approach enables dynamic allocation and paging of memory during inference, significantly improving throughput and reducing latency. By efficiently managing GPU resources, PagedAttention facilitates the use of larger models without requiring extensive hardware resources, making it a practical choice for scaling AI applications.
Tensor Parallelism and Caching
In addition to PagedAttention, vLLM employs advanced tensor parallelism to distribute workloads effectively across multiple GPUs. It also incorporates efficient caching mechanisms to minimize redundant computations, further enhancing model performance during inference. These techniques collectively ensure that vLLM delivers high-speed, cost-effective inference for transformer models.
Applications
vLLM supports real-time deployment of large language models across diverse domains:
Natural Language Processing (NLP): Tasks like text summarization, sentiment analysis, and named entity recognition.
Conversational AI: Real-time chatbot systems and virtual assistants.
Retrieval-Augmented Generation (RAG): Integration of large models with retrieval systems for advanced question-answering and knowledge retrieval tasks.
RAG Application with Milvus, vLLM and Qwen
This tutorial demonstrates how to implement a RAG pipeline using Milvus as a vector database, Qwen as the language model, vLLM for optimized inference and LangChain as the framework. The full code of this tutorial can be found in the following notebook.
Step 1: Set Environment
To efficiently use vLLM, we would need a GPU. The following notebook was run in Google Colab using an A100 GPU. Additionally, an OpenAI API Key is required to generate the embeddings.
Step 2: Load the Data
As a source for our knowledge base we will load a few blogs about Qwen models during its releases and split them in chunks with the RecursiveCharacterTextSplitter method from LangChain.
# Load documents
loader = WebBaseLoader(
web_paths=(
"https://qwenlm.github.io/blog/qwq-32b-preview/",
"https://qwenlm.github.io/blog/qwen2.5/",
"https://qwenlm.github.io/blog/qwen2.5-coder-family/",
)
)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
Step 3: Create Milvus Retriever
Next we will configure the Milvus retriever with the text content and metadata for efficient retrieval as metadata adds additional supporting context to the knowledge base.
# Set Milvus retriever
embeddings = OpenAIEmbeddings()
vectorstore = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={
"uri": "./milvus_demo.db",
},
text_field="page_content",
metadata_field="metadata",
drop_old=True,
)
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4})
Step 4: Initialize LLM Engine
The vLLM engine must be efficiently initialized to load the specific model, in this case, "Qwen/Qwen2.5-1.5B”. With configurations such as, optimized GPU memory usage (80%), and bfloat16 for efficient computation, we ensure running out of memory, and a quick and resource-aware operation for generating up to 500 tokens.
# Initialize vLLM
llm = VLLM(
model="Qwen/Qwen2.5-1.5B",
max_new_tokens=500,
enforce_eager=True,
dtype="bfloat16",
gpu_memory_utilization=0.8)
Step 5: Implement RAG Pipeline
Then, we build a RAG pipeline with the Qwen model, the Milvus retriever and a prompt template to ingest our context and question. Additionally we add a display response function to visualize not only the response but also the source context.
# Set QA chain
template = """
You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the
question.
If you don't know the answer, just say that you don't know.
Please provide the answer in the English language.
Question: {question}
Context: {context}
Answer:
"""
prompt = PromptTemplate.from_template(template)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=retriever,
chain_type_kwargs={"prompt": prompt },
return_source_documents=True
)
# Print statements for response details
def display_response_details(response):
print("Query:", response["query"])
print("Result:", response["result"])
# Extract metadata from the first source document
source_doc = response["source_documents"][0].metadata
print("Source:", source_doc["source"])
print("Description:", source_doc["description"])
print("Title:", source_doc["title"])
# Set the question
question = "What can you tell me about QwQ model?"
# Initialize the query
response = qa_chain.invoke({"query": question, "context": retriever})
Output:
Query: What can you tell me about QwQ model?
Result: The QwQ model (Qwen with Questions) shows that it can think, question, and understand in a deep way. It is like a student who always wonders and thinks carefully before giving an answer. Just like learning new things, it knows that it knows nothing and keeps asking questions to learn more. It also has some limitations and needs to learn more as it goes. Just like everyone, it's always growing and improving.
Source: https://qwenlm.github.io/blog/qwq-32b-preview/
Description: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD
Note: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”.
What does it mean to think, to question, to understand? These are the deep waters that QwQ (Qwen with Questions) wades into. Like an eternal student of wisdom, it approaches every problem - be it mathematics, code, or knowledge of our world - with genuine wonder and doubt. QwQ embodies that ancient philosophical spirit: it knows that it knows nothing, and that’s precisely what drives its curiosity.
Title: QwQ: Reflect Deeply on the Boundaries of the Unknown | Qwen
We can add a second question about the other models as well. We see that in both cases the responses are detailed and accurate, which show a high performance of both Milvus and Qwen, together with vLLM, which provided the answer in less than 1 s.
# Set the question
question = "What can you tell me about Qwen2.5 open-source models: Qwen2.5, Qwen2.5-Coder, Qwen2.5-Math?"
# Initialize the query
response = qa_chain.invoke({"query": question, "context": retriever})
Output:
Query: What can you tell me about Qwen2.5 open-source models: Qwen2.5, Qwen2.5-Coder, Qwen2.5-Math?
Result: The Qwen2.5 models, namely Qwen2.5, Qwen2.5-Coder, and Qwen2.5-Math, have acquired significant improvements in various aspects compared to their predecessors. Here are some key takeaways:
1. **Academic Performance:**
- Qwen2.5 achieved the best performance among open-source models on multiple popular code generation benchmarks (EvalPlus, LiveCodeBench, BigCodeBench).
- Qwen2.5 also scored highly on an Instructive evaluation task, indicating strong alignment with human-like instruction-following abilities.
- Qwen2.5 provided competitive performance with GPT-4o, demonstrating superiority over its predecessors.
2. **Practical Applications:**
- Qwen2.5 models excel in handling different programming languages, showcasing their adaptability and versatility.
- Qwen2.5 models have undergone significant enhancements, extending their skills to handle more complex reasoning tasks.
3. **Model Training:**
- Qwen2.5, along with Qwen2.5-Coder and Qwen2.5-Math, have been trained on large-scale datasets covering 18 trillion tokens. This includes code-related data, enabling smaller coding models to perform competitively with larger and more comprehensive ones.
4. **Model Support:**
- All Qwen2.5 models are capable of supporting a wide range of programming languages, providing accessibility and applicability for users.
5. **General Capabilities:**
- Qwen2.5 models now demonstrate enhanced performance in reasoning and generation tasks such as code repair and code writing.
6. **Specialized Models:**
- Qwen2.5-Coder is focused on coding tasks, offering better performance in coding generation, repair, and even reasoning capabilities.
- Qwen2.5-Math improves on the foundational model Qwen2-Math, extending the support for Chinese and incorporating sophisticated reasoning methods, such as Chain-of-Thought (CoT), Program-of-Thought (PoT), and Tool-Integrated Reasoning (TIR).
7. **Model Licensing:**
- All open-source models are licensed under Apache 2.0, ensuring compatibility and ease of use across different development environments.
These enhancements collectively contribute to the development of powerful and versatile intelligent programming assistants with broader capabilities and improved performance.
Source: https://qwenlm.github.io/blog/qwen2.5/
Description: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD
Introduction In the past three months since Qwen2’s release, numerous developers have built new models on the Qwen2 language models, providing us with valuable feedback. During this period, we have focused on creating smarter and more knowledgeable language models. Today, we are excited to introduce the latest addition to the Qwen family: Qwen2.5. We are announcing what might be the largest opensource release in history!
Title: Qwen2.5: A Party of Foundation Models! | Qwen
Conclusion
The technical innovations showcased in this exploration—particularly the integration of PagedAttention in vLLM and the efficient vector management of Milvus—highlight the critical importance of infrastructure in making large language models practical and accessible. These technologies address key challenges in model deployment, such as memory optimization, inference speed, and scalable knowledge retrieval. By solving these technical bottlenecks, developers and organizations can now implement sophisticated Retrieval-Augmented Generation (RAG) systems that were previously complex or resource-intensive, opening new frontiers in AI-driven applications across industries like healthcare, education, software development, and scientific research.
Related Resources

Keep Reading

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.