




TDAクラスタリングによる埋め込みモデル選択の最適化:ベクトルデータベースのための戦略的ガイド
Zillizが主催し、Gunnar CarlssonとGabriel Alonが登壇した最近のウェビナーからの洞察を解釈して – 執筆 Wania Shafqat
大規模言語モデル(LLM)はデータ処理を変革しましたが、その性能は、それらを支える埋め込みの品質と密接に結びついています。最近のウェビナーでは、Blue Light AIの共同創業者兼CTOであるGunnar Carlsson、シニアデータサイエンティストのGabriel Alon、そしてZilliz,のDeveloper AdvocateであるStefan Webbが、位相的データ解析(TDA)クラスタリングが埋め込みモデルの隠れた弱点をどのように明らかにするかを探りました。本記事では、このセッションから得られた主要な洞察と性能向上のための手法を、追加の研究や実践的なヒントとともに解説し、独自のニーズに合ったモデルを自信を持って選択・開発できるよう支援します。
課題:埋め込みモデルの評価
埋め込みモデルは、生の非構造化データ(テキスト、画像、動画)を、意味的な意味を内包する高次元ベクトルに変換します。しかし、どのベクトルデータベース導入においても、適切な埋め込みモデルを選択することは困難です。
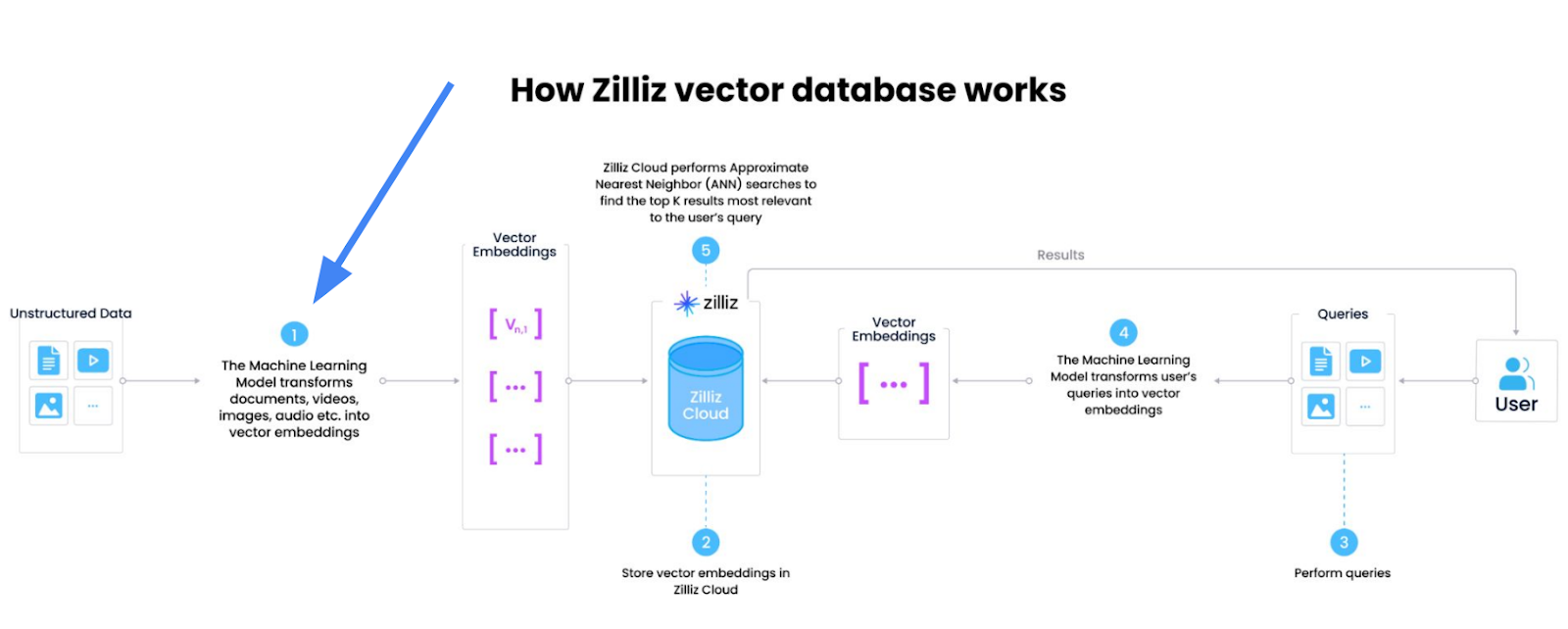
図:適切な埋め込みモデルの選択。
従来の埋め込み手法は、多くの場合、以下に依存しています。
公開リーダーボード(MTEB): モデルが公開データに過剰適合し、実世界のタスクで性能が低下します。
平均指標: NDCG@10のような指標は、重要なクエリの性能が低い失敗クラスタを隠してしまいます。
スケーラビリティの問題: 100K件以上のクエリを含む大規模データセットを手作業で検査するのは現実的ではありません。
ウェビナーでGabriel Alonが述べたように、0.34 NDCG(Normalized Discounted Cumulative Gain)という平均スコアは許容範囲に見えるかもしれませんが、クエリのかなりの部分が0.1未満のスコアであれば、そのモデルは実世界のアプリケーションには不適切であり、ユーザーの信頼を損なうリスクがあります。したがって、train-test mismatchを克服し、公開ベンチマークへの過剰適合を避けるために、自分のデータでモデルを評価することが強く推奨されました。
たとえば、‘Television Stands’に対する検索結果を返す2つのモデルを考えてみましょう。
モデルAは[Mobile TV Cart, Universal TV Stand, Black Television]を返します
モデルBは[Mobile TV Cart, Universal TV Stand, TV Stand (2 feet)]を返します
モデルBの方がリコールは高いものの、平均指標やリーダーボードではこの違いは明らかになりません。
解決策:ナビゲーション可能なTDAクラスタリング
位相的データ解析(TDA)はデータの「形状」を研究する数学的フレームワークであり、ナビゲーション可能なクラスタリングは、粒度の細かい洞察を得るためにハイパーパラメータ(例:解像度)を調整する柔軟性を加えます。MapperアルゴリズムなどのTDAクラスタリング手法を適用することで、従来の平均指標では見落とされる、高次元埋め込み内の基礎構造、クラスタ、外れ値を明らかにする視覚的表現を作成できます。ナビゲーション可能なTDAクラスタリングは、これを以下のように拡張します。
データトポロジーのマッピング: 埋め込み空間のグラフベース構造を作成します。
重要なクラスターの特定: 万能な解決策ではなく、的を絞った改善のために、パフォーマンスの低いクエリ群を明らかにします。
自動化された解釈可能性: クラスターとモデルの挙動を説明するために、キーワードとヒートマップを生成します。
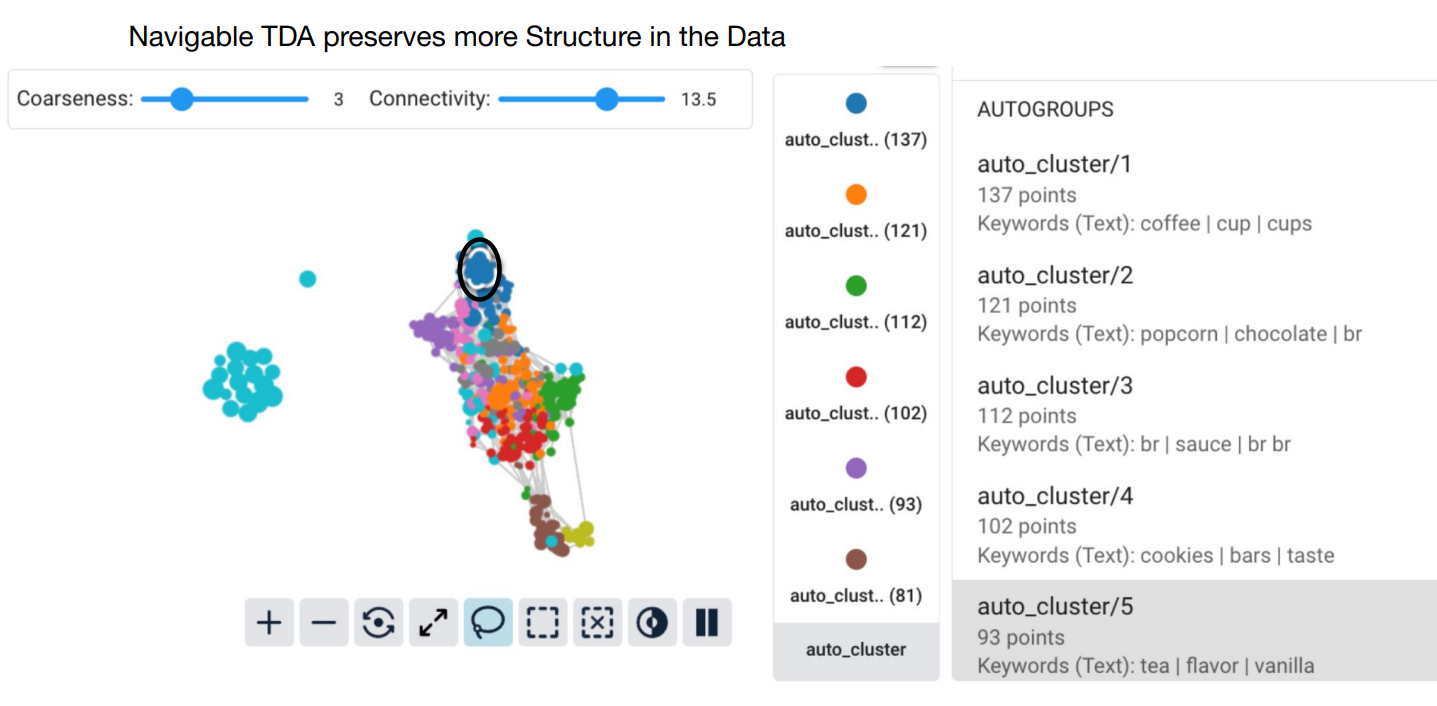
図: TDAクラスタリングワークフロー: パフォーマンスの低いグループの強調表示。
仕組み:
類似性によるクエリのクラスタリング: ベクトル埋め込みを使用してクエリをグループ化します。
クラスターごとの指標の評価: 各クラスターのprecision、recall、またはNDCGを計算します。
戦略的な最適化: 弱いクラスターに対してハイパーパラメーターを調整するか、モデルを切り替えます。
静的なクラスタリング手法(例: K-meansやDBSCAN)とは異なり、ナビゲート可能なTDAクラスタリングは、平均指標では見えない失敗のホットスポットを検出し、あなたのデータ上でモデル(E5 vs. SBERT)を客観的にランク付けし、100K以上のクエリを数分で処理します。
ケーススタディ: Eコマースクエリの最適化
Marqo-GS-10Mデータセット(10M件のGoogle Shoppingクエリ)のサブセットを使用して、Blue Light AIは人気の埋め込みモデル(E5)に深刻な欠陥があることを明らかにしました。TDAクラスタリングを適用した後:
| クエリクラスター | サイズ | NDCG |
| マタニティウェア | 35 | 0.10 |
| エスプレッソマシン | 32 | 0.11 |
| 男の子用トラックスーツ | 35 | 0.13 |
要点:
平均NDCGは0.34であるにもかかわらず、約30%のクラスターははるかに低いパフォーマンス(<0.15)でした。
ファインチューニングにより、重要なクラスターのパフォーマンスは悪化しました。
TDAがなければ、こうした微妙な欠陥は隠れたままです。
機械学習ライフサイクル: TDAの洞察
モデル比較:
E5(NDCG 0.34)は平均ではSBERT(0.26)を上回りましたが、SBERTは「novelty wallets」のようなクラスターで優れていました:
| クラスター | E5 NDCG | SBERT NDCG | 最適なモデル |
| Novelty wallets | 0.16 | 0.28 | SBERT |
| Air mattresses | 0.38 | 0.38 | 同率 |
コスト削減のトレードオフ:
E5-largeからE5-smallに切り替えるとストレージは節約できましたが、重要なクラスターでは大幅なパフォーマンス低下が発生しました:
| クエリタイプ | パフォーマンス低下 |
| Adaptive waistbands | -35% |
| Polo activities | -65% |
ファインチューニングの落とし穴
デプロイ後のモニタリングにより、ファインチューニングは平均NDCGを0.35から0.45に改善した一方で、特定のクラスターを悪化させたことが明らかになりました:
| クエリタイプ | パフォーマンス低下 |
| Privacy films | -29% |
| Garlic peeling | -22% |
教訓: ファインチューニングは全体だけでなく、必ずクラスター単位で検証してください。
デプロイ後の戦略
リスク軽減: モデルが改善されるまで、スコアの低いクラスター内の商品をプロモーションしないようにします。
Human-in-the-Loop: パフォーマンスの低いクエリを人間の担当者に振り分けます。
モデルルーティング: クラスターのパフォーマンスに基づいてモデルを動的に切り替えます(例: 特定のクエリタイプにはSBERTを使用)。
TDAとZilliz CloudおよびMilvusの統合
Zilliz CloudとMilvusは、埋め込みの保存とクエリを簡素化します。TDAクラスタリングを適用することで、検索効率、インタラクティビティ、リソース割り当ての最適化が向上します。TDAと組み合わせる方法は次のとおりです:
埋め込みを保存する
インデックス作成前に埋め込みを検証し、無駄なリソースを削減します:
from pymilvus import connections, Collection
# Zilliz Cloud に接続
connections.connect(
alias="default",
uri="YOUR_CLUSTER_ENDPOINT", # 例: "https://your-cluster.zillizcloud.com"
token="YOUR_API_KEY"
)
# コレクションをロード
collection = Collection("product_embeddings")
collection.load()
TDA で評価およびクラスタリングする
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# Zilliz から埋め込みをロード
embeddings = collection.query(expr="", output_fields=["embedding"])
# 可視化のために次元削減
tsne = TSNE(n_components=2)
embeddings_2d = tsne.fit_transform(embeddings)
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], c=cluster_labels)
plt.title("クエリクラスタの T-SNE 可視化")
plt.show()
TDA ワークフローで Zilliz が優れている理由
スケーラビリティ: 数十億のベクトルを処理でき、大規模な TDA に最適です。
リアルタイムの洞察: 新しいデータが流入するたびにクラスタを動的に更新できます。
シームレスな統合: Python SDK と REST API が既存のパイプラインに適合します。
より深い洞察については、Zilliz の ベクトルデータベースガイドをご覧ください。
埋め込みモデル開発のベストプラクティス
ローカルで検証する: ベンチマークだけに頼るのではなく、自分のデータでモデルをテストします。
早期に TDA を採用する: プロトタイピング中に問題を検出するため、ナビゲート可能なクラスタリングを統合します。
デプロイ後に監視する: Zilliz Cloud のツールを使ってクラスタのパフォーマンスを継続的に追跡します。
Q&A: ウェビナーからの主な質問
ウェビナー中にいくつかの質問をいただきました。以下は、よく寄せられた質問の一部と、それに対する Gunnar と Gabriel の回答です。
Q: TDA クラスタリングを適用して最も驚いたことは何ですか?
私たちのケーススタディでは、微調整によって 30〜40% のクラスタでパフォーマンスが悪化しました。たとえば、エスプレッソマシン関連のクエリは、チューニング後にはるかに悪い結果になりました。さらに重要なのは、eコマースでは 1 つのクエリが 20 ドルの商品を表す可能性があるということです。ここでモデルが失敗すれば、それは実際の収益損失になります。
Q: 検索モデルの微調整と埋め込みモデルの微調整を比較して検討したことはありますか?
はい!RAG の構成では、曖昧なクエリを別々のクラスタに分割するために TDA を使用してきました。たとえば、‘tell me about the draft’ というクエリでは、TDA は結果を NBA draft と military draft のクラスタに分離します。これにより、検索モデルは文脈を優先しやすくなり、無関係な結果を避けられます。
Q: TDA は DBSCAN のような手法と比べてどうですか?
TDA は、ナビゲート可能なハイパーパラメータを通じて柔軟性を提供します。DBSCAN のような従来の手法は、固定されたデータマップ上で動作します。TDA では、地理投影法を切り替えるように「マップ解像度」を調整し、局所的な最小値(例: パフォーマンスの低いクエリクラスタ)を分離できます。
Q: クエリ依存の埋め込みモデルについてどう考えていますか?
TDA のトポロジーマッピングは、この潮流を自然に補完します。たとえば、OpenAI のようなモデルのスパースオートエンコーダ特徴は、従来の手法では見逃されるクラスタを明らかにします。あるケースでは ‘rules’ が compliance と breaking rules のクラスタに分割され、埋め込みがクエリの文脈に適応できることを示しています。
Q: チームはどのように TDA を始められますか?
pip install cobalt-ai を実行して Python パッケージ Cobalt を試し、トラブルシューティングに役立つ documentation や GitHub、Slack のリソースを確認してください。このパッケージは、TDA クラスタリングを既存のワークフローに統合することを簡素化します。100K 件のクエリを数分で処理し、Zilliz と統合できます。
結論
このウェビナーでは、TDAクラスタリングが埋め込みモデル評価をどのように変革できるかについて、包括的な概要が提供されました。ナビゲート可能なクラスタリングを通じて詳細なパフォーマンス内訳を明らかにすることで、チームはモデル選択を最適化し、リソース配分を改善し、ユーザー体験を向上させることができます。Zilliz Cloud または Milvus と組み合わせることで、これらのインサイトは以下につながります。
透明性: 埋め込みに潜む欠陥を明らかにします。
精度: 詳細なパフォーマンスインサイトに基づいてモデルをデプロイします。
コスト削減: 無駄なコンピューティングおよびストレージリソースを削減します。
今すぐより賢くクラスタリングを始めるには、Zilliz Cloud をご覧ください。
ウェビナー録画とスライド全体を見る
Zilliz の YouTube チャンネルでウェビナー録画を視聴でき、Topological Data Analysis (TDA) クラスタリングや Gunnar と Gabriel の議論についてさらに詳しく知るために、プレゼンテーションスライドにアクセスできます。
関連リソース

読み続けて

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.