




Multimodal RAG locally with CLIP and Llama3
With the recent release of GPT-4o and Gemini, multimodal has been a hot topic lately. Another one that has been on top of the lighting spot is Retrieval Augmented Generation (RAG) for the past year, but it was mostly focused on text. This tutorial will show you how to build a Multimodal RAG System.
By using Multimodal RAG, you don’t have to use text only; you can use different types of data such as images, audio, videos, and text, of course. It’s also possible to return different kinds of data; just because you use text as input for your RAG system doesn’t mean you have to return text as output. We will showcase that during this tutorial.
Prerequisites
Before starting to set up the different components of our tutorial, make sure your system has the following:
Docker & Docker-Compose—Ensure Docker and Docker-Compose are installed on your system.
Milvus Standalone—For our purposes, we'll utilize the efficient Milvus Standalone, which is easily managed via Docker Compose; explore our documentation for installation guidance.
Ollama—Install Ollama on your system. This will allow us to use Llama3 on our laptop. Visit their website for the latest installation guide.
OpenAI CLIP
The core idea behind the CLIP (Contrastive Language-Image Pretraining) model is to understand the connection between a picture and text. It is a foundational AI model trained on text-image pairs. It then learns to create a point in the vector space for both text and images. In this space, similar text descriptions will be close to relevant images and vice versa.
CLIP can be used for different applications, including:
Image retrieval: Imagine searching for images using a text description or finding the perfect caption to match an image.
Multimodal learning: CLIP's strength in connecting text and images makes it a perfect building block for systems like multimodal RAG, which deal with information in different formats.
This allows our RAG system to understand and respond to queries that can involve both text and images.
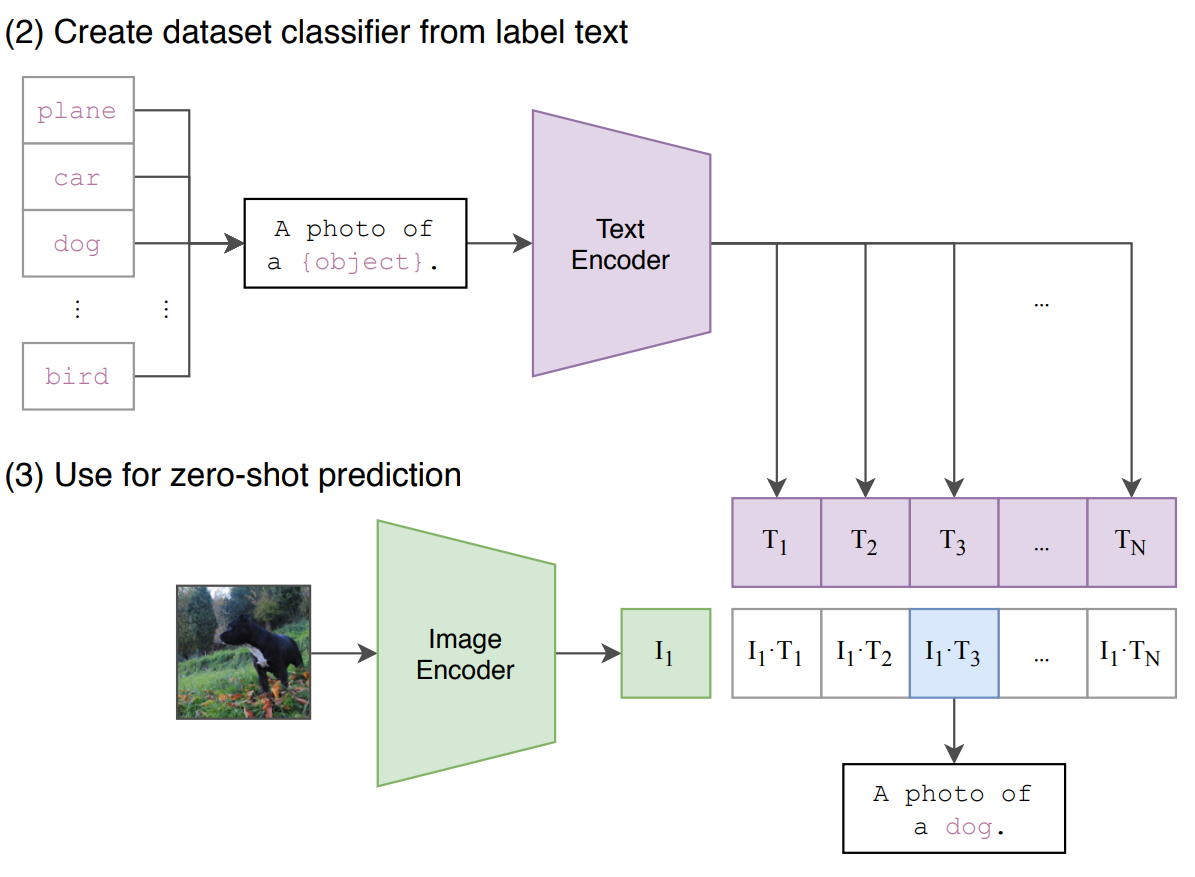 Fig1: Architecture of OpenAI CLIP
Fig1: Architecture of OpenAI CLIP
Multimodal Embeddings
What are embeddings? In simpler terms, embeddings are compressed representations of data. CLIP takes an image or text as input and transforms it into a numerical code capturing its key features.
The beauty of CLIP is that it works for both text and images. You can give it an image, and it will generate an embedding that captures the visual content. However, you can also provide text, and CLIP will generate an embedding that reflects the meaning of the text.
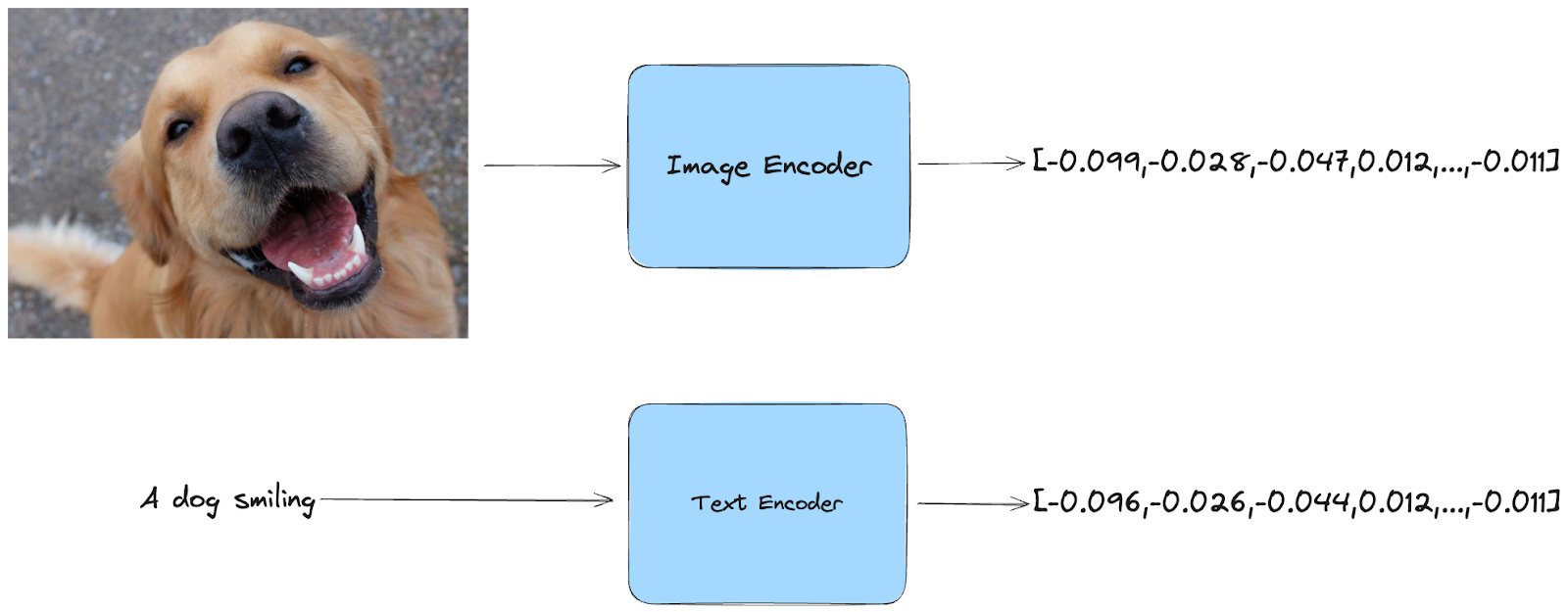 Multimodal Embeddings
Multimodal Embeddings
If you were to imagine a projection in the vector space, you would have embeddings with similar meanings close to each other. For example, the text “A dog with a smile” and the picture of a dog that appears to be smiling are close together.
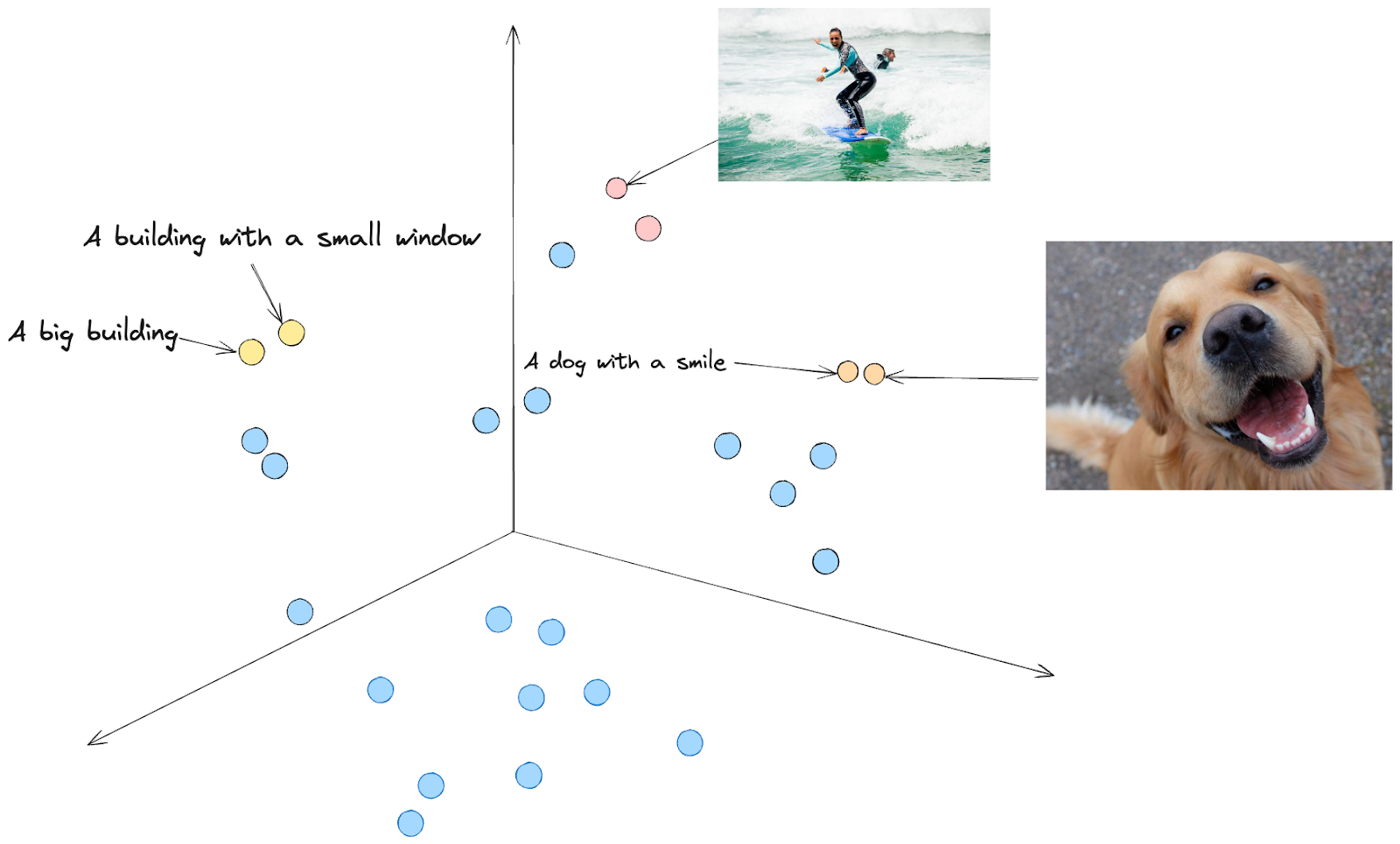 Fig2. Representation in a Vector Space
Fig2. Representation in a Vector Space
Building a Multimodal RAG
We will use data from Wikipedia, download the text data associated with what we want to learn more about and do the same with images.
We will generate Embeddings with the CLIP ViT-B/32 model and use Llama3 as the LLM.
We store the embeddings in Milvus, which is designed to manage large-scale embeddings so we can perform a quick and efficient search.
LlamaIndex is used as the Query Engine in combination with Milvus as the Vector Store.
The entire code is quite long, as we need to browse Wikipedia, process the text and images, and then create an RAG application. However, it is fully available on Github, so you should definitely check it out!
Once you have it working, you should be able to run queries similar to the following:
# https://en.wikipedia.org/wiki/Helsinki
query2 = "What are some of the popular tourist attraction in Helsinki?"
# generate image retrieval results
image_query(query2)
# generate text retrieval results
text_retrieval_results = text_query_engine.query(query2)
print("Text retrieval results: \n" + str(text_retrieval_results))
Which should output something like similar to
Some popular tourist attractions in Helsinki include Suomenlinna (Sveaborg), a fortress island with a rich history, and Korkeasaari Zoo, located on one of Helsinki's main islands. Additionally, the city has many nature reserves, including Vanhankaupunginselkä, which is the largest nature reserve in Helsinki.

And with that, you will have a multimodal RAG application that is able to process either images or text and can also return images or text.
You can access the code on Github, feel free to ask questions on our Discord, and give us a star on Github.

Keep Reading

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.