




Claude CodeのGrepオンリー検索に反対する理由?トークンを消費しすぎるだけだから
AIコーディングアシスタントが爆発的に普及している。わずかこの2年で、Cursor、Claude Code、Gemini CLI、Qwen Codeのようなツールは、物珍しい存在から、何百万人もの開発者にとって日常的な相棒へと変わった。しかし、この急速な台頭の裏には、一見すると単純な問題をめぐる争いが起こりつつある。AIコーディングアシスタントは、コンテキストを得るために実際どのようにコードベースを検索すべきなのか?
現時点では、2つのアプローチがある。
ベクトル検索を活用したRAG(セマンティック検索)。
grepによるキーワード検索(リテラルな文字列マッチング)。
Claude CodeとGeminiは後者を選んでいる。実際、ClaudeのエンジニアはHacker Newsで、Claude CodeはRAGをまったく使っていないと公然と認めた。代わりに、リポジトリを行ごとにgrepしているだけだ(彼らが「agentic search」と呼ぶもの)—セマンティクスも構造もなく、ただの生の文字列マッチングである。

この発言はコミュニティを二分した。
支持派はgrepのシンプルさを擁護する。高速で、正確で、そして何よりも予測可能だという。プログラミングでは精度がすべてであり、現在の埋め込みはまだ曖昧すぎて信頼できない、というのが彼らの主張だ。
批判派はgrepを行き止まりだと見ている。無関係なマッチに埋もれ、トークンを浪費し、ワークフローを停滞させる。意味理解がなければ、AIに目隠しをしてデバッグさせているようなものだ。
どちらにも一理ある。そして自分自身のソリューションを構築してテストした後で、私はこう言える。ベクトル検索ベースのRAGアプローチは状況を一変させる。検索を劇的に高速かつ高精度にするだけでなく、トークン使用量も40%以上削減する。(私のアプローチについてはClaude Contextの部分まで読み飛ばしてほしい)
では、なぜgrepはこれほど制約が大きいのか?そしてベクトル検索は実際にどのようにしてより良い結果をもたらせるのか?順に見ていこう。
Claude CodeのGrepのみのコード検索の何が問題なのか?
厄介な問題をデバッグしているときに、私はこの問題にぶつかった。Claude Codeは私のリポジトリ全体にgrepクエリを走らせ、無関係なテキストの巨大な塊をこちらに投げ返してきた。1分経っても、まだ関連するファイルは見つからなかった。5分後、ようやく正しい10行にたどり着いたが、それらは500行のノイズの中に埋もれていた。
これは特殊なケースではない。Claude CodeのGitHub issuesをざっと見るだけでも、同じ壁にぶつかっている苛立った開発者が数多くいることがわかる。
issue1: https://github.com/anthropics/claude-code/issues/1315
issue2: https://github.com/anthropics/claude-code/issues/4556
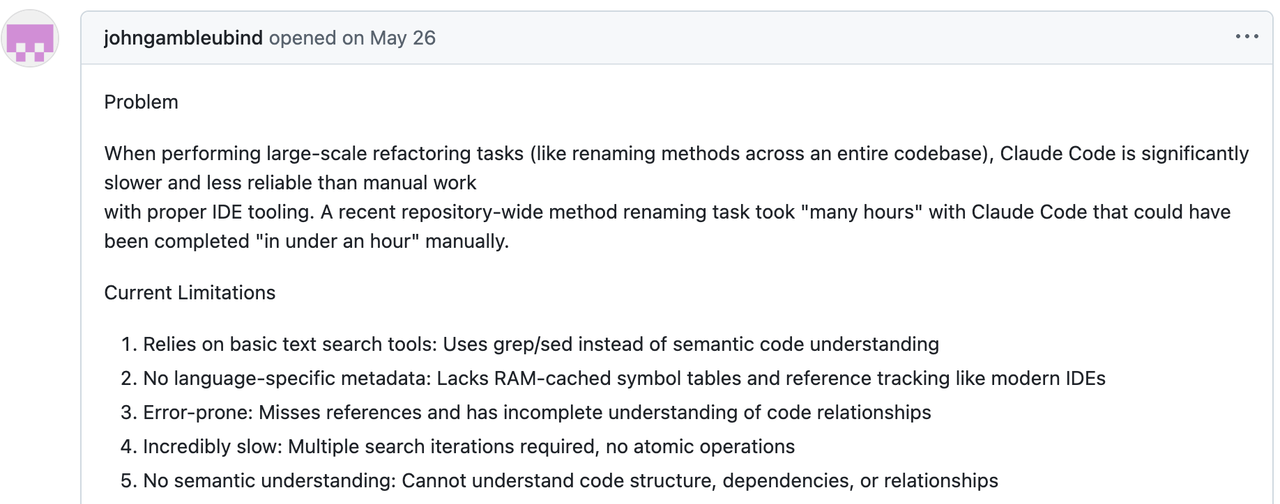
コミュニティの不満は、3つの痛点に集約される。
トークン肥大化。 grepのダンプは毎回、大量の無関係なコードをLLMに押し込み、リポジトリサイズに対してひどくスケールするコストを押し上げる。
時間の負担。 AIがコードベース相手に二十の質問をしている間、待たされ続け、集中力とフローが削がれる。
コンテキストゼロ。 Grepはリテラルな文字列にマッチする。意味や関係性を理解しないため、実質的には手探りで検索していることになる。
だからこそ、この議論は重要なのだ。grepは単に「古い流儀」なのではなく、AI支援プログラミングの足を積極的に引っ張っている。
Claude Code vs Cursor: 後者のほうが優れたコードコンテキストを持つ理由
コードコンテキストに関しては、Cursorのほうがうまくやっている。Cursorは初日からコードベースのインデックス化に注力してきた。つまり、リポジトリを意味のあるチャンクに分割し、それらのチャンクをベクトルに埋め込み、AIがコンテキストを必要とするたびにセマンティックに取得する。これはコードに適用された教科書的なRetrieval-Augmented Generation(RAG)であり、その結果は明らかだ。より引き締まったコンテキスト、無駄になるトークンの削減、そして高速な検索である。

Claude Code は対照的に、シンプルさをさらに徹底しています。インデックスも埋め込みもなく、ただ grep するだけです。つまり、すべての検索はリテラルな文字列マッチングであり、構造や意味の理解はありません。理論上は高速ですが、実際には、開発者は本当に必要な一本の針を見つける前に、無関係な一致の山をふるい分けることになることがよくあります。
| Claude Code | Cursor | |
|---|---|---|
| Search Accuracy | 完全一致のみを表示し、異なる名前が付けられたものは見逃す。 | キーワードが完全に一致しなくても、意味的に関連するコードを見つける。 |
| Efficiency | Grep が大量のコードの塊をモデルに流し込み、トークンコストを押し上げる。 | より小さく、シグナルの高いチャンクにより、トークン負荷を 30~40% 削減する。 |
| Scalability | 毎回リポジトリを再 grep するため、プロジェクトが成長するほど遅くなる。 | 一度インデックス化し、その後は最小限の遅延で大規模に取得する。 |
| Philosophy | 最小限に保つ—追加のインフラはなし。 | すべてをインデックス化し、賢く取得する。 |
では、なぜ Claude(あるいは Gemini や Cline)は Cursor の先例に従っていないのでしょうか?理由は一部は技術的で、一部は文化的です。ベクトル検索は簡単ではありません—チャンク化、増分更新、大規模インデックス化を解決する必要があります。 しかしそれ以上に重要なのは、Claude Code がミニマリズムを中心に構築されていることです。サーバーもインデックスもなく、クリーンな CLI だけです。埋め込みやベクトル DB は、その設計思想に合いません。
そのシンプルさは魅力的です—しかし同時に、Claude Code が提供できるものの上限も制限します。Cursor が本格的なインデックス基盤に投資する意思を持っているからこそ、今日より強力に感じられるのです。
Claude Context: Claude Code にセマンティックコード検索を追加するためのオープンソースプロジェクト
Claude Code は強力なツールですが、コードコンテキストが弱いという問題があります。Cursor はコードベースのインデックス化でこれを解決しましたが、Cursor はクローズドソースで、サブスクリプションに縛られており、個人や小規模チームにとっては高価です。
そのギャップが、私たちが独自のオープンソースソリューションを構築し始めた理由です: Claude Context。
Claude Context は、セマンティックコード検索を Claude Code(および MCP を扱える他のあらゆる AI コーディングエージェント)にもたらすオープンソースの MCP プラグインです。grep でリポジトリを総当たりする代わりに、ベクトルデータベースを埋め込みモデルと統合し、コードベース全体から LLM に 深く、的を絞ったコンテキスト を提供します。その結果、より鋭い検索、より少ないトークン浪費、そしてはるかに優れた開発者体験が得られます。
私たちは次のように構築しました:
使用している技術
🔌 インターフェース層: ユニバーサルコネクタとしての MCP
私たちは、これを Claude だけでなく、どこでも機能させたいと考えました。MCP (Model Context Protocol) は LLM のための USB 標準のように機能し、外部ツールがシームレスに接続できるようにします。Claude Context を MCP サーバーとしてパッケージ化することで、Claude Code だけでなく、Gemini CLI、Qwen Code、Cline、さらには Cursor でも動作します。
🗄️ ベクトルデータベース: Zilliz Cloud
基盤として、私たちは Zilliz Cloud(Milvus 上に構築されたフルマネージドサービス)を選びました。高性能で、クラウドネイティブ、エラスティックであり、コードベースのインデックス化のような AI ワークロード向けに設計されています。つまり、低レイテンシの検索、ほぼ無限のスケール、そして非常に堅牢な信頼性を意味します。
🧩 埋め込みモデル: 柔軟性を前提に設計チームごとにニーズは異なるため、Claude Context は複数の埋め込みプロバイダーを標準でサポートしています。
OpenAI embeddings は安定性と幅広い採用実績のため。
Voyage embeddings はコード特化の性能のため。
Ollama はプライバシー優先のローカルデプロイメントのため。
要件の変化に応じて、追加のモデルを組み込むことができます。
💻 言語の選択: TypeScript
私たちは Python と TypeScript のどちらにするか議論しました。TypeScript が勝ちました。アプリケーションレベルの互換性(VSCode プラグイン、Web ツール)だけでなく、Claude Code と Gemini CLI 自体も TypeScript ベースだからです。これにより統合がシームレスになり、エコシステムの一貫性が保たれます。
システムアーキテクチャ
Claude Context は、クリーンなレイヤー化された設計に従っています。
コアモジュール は、コード解析、チャンク化、インデックス化、検索、同期といった重い処理を担います。
ユーザーインターフェース は、MCP サーバー、VSCode プラグイン、その他のアダプターなどの統合を扱います。
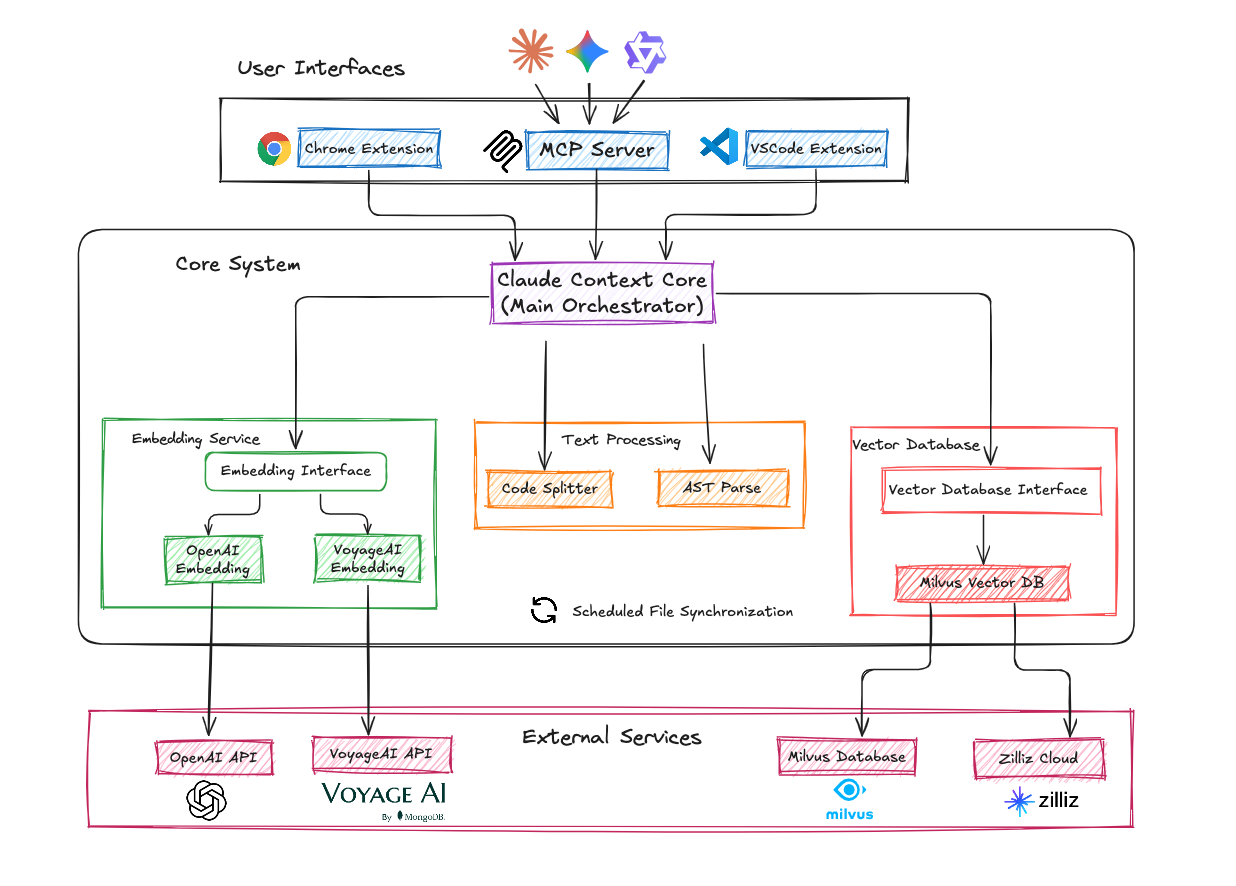
この分離により、コアエンジンはさまざまな環境で再利用可能になり、新しい AI コーディングアシスタントが登場するにつれて統合を迅速に進化させることができます。
コアモジュールの実装
コアモジュールはシステム全体の基盤を形成します。ベクトルデータベース、埋め込みモデル、その他のコンポーネントを、Context オブジェクトを作成する構成可能なモジュールとして抽象化し、シナリオに応じて異なるベクトルデータベースや埋め込みモデルを利用できるようにします。
import { Context, MilvusVectorDatabase, OpenAIEmbedding } from '@zilliz/claude-context-core';
// Initialize embedding provider
const embedding = new OpenAIEmbedding(...);
// Initialize vector database
const vectorDatabase = new MilvusVectorDatabase(...);
// Create context instance
const context = new Context({embedding, vectorDatabase});
// Index your codebase with progress tracking
const stats = await context.indexCodebase('./your-project');
// Perform semantic search
const results = await context.semanticSearch('./your-project', 'vector database operations');
主要な技術的課題の解決
Claude Context の構築は、単に埋め込みとベクトル DB をつなぎ合わせるだけではありませんでした。本当の作業は、大規模なコードインデックス化の成否を左右する難しい問題を解決することにありました。ここでは、最も大きな 3 つの課題にどのように取り組んだかを紹介します。
課題 1: インテリジェントなコードチャンク化
コードは、行や文字数だけで単純に分割することはできません。そうすると、乱雑で不完全な断片が生成され、コードを理解可能にするロジックが失われてしまいます。
私たちはこれを 2 つの相補的な戦略 で解決しました。
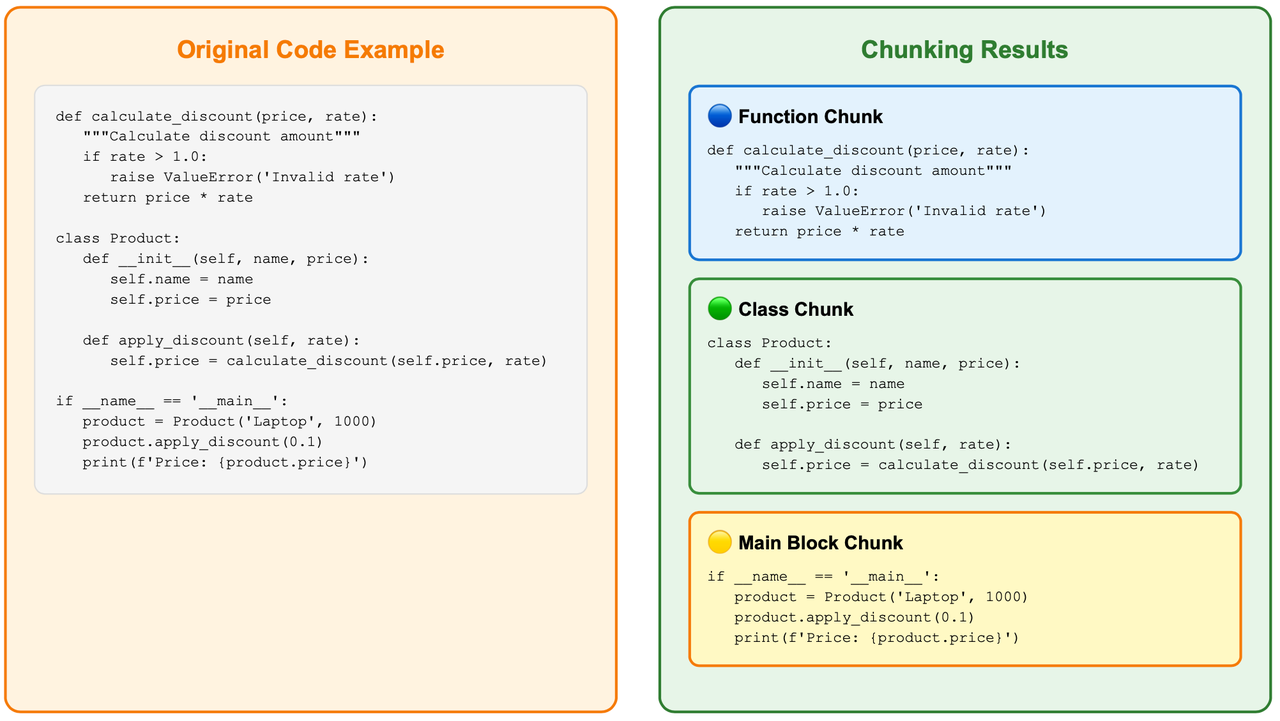
AST ベースのチャンク化(主要戦略)
これはデフォルトのアプローチであり、tree-sitter パーサーを使用してコードの構文構造を理解し、関数、クラス、メソッドといった意味的境界に沿って分割します。これにより、以下が実現されます。
構文の完全性 – 関数が途中で切れたり、宣言が壊れたりしません。
論理的一貫性 – 関連するロジックがまとまるため、より優れたセマンティック検索が可能になります。
多言語サポート – tree-sitter grammar により、JS、Python、Java、Go などで動作します。
LangChain テキスト分割(フォールバック戦略)
AST が解析できない言語や解析に失敗した場合、LangChain の RecursiveCharacterTextSplitter が信頼できるバックアップを提供します。
// Use recursive character splitting to maintain code structure
const splitter = RecursiveCharacterTextSplitter.fromLanguage(language, {
chunkSize: 1000,
chunkOverlap: 200,
});
AST ほど「インテリジェント」ではありませんが、非常に信頼性が高く、開発者が行き詰まることがないようにします。これら 2 つの戦略を組み合わせることで、意味的な豊かさと普遍的な適用性のバランスを取っています。
課題 2: コード変更の効率的な処理
コード変更の管理は、コードインデックス化システムにおける最大の課題の 1 つです。軽微なファイル変更のためにプロジェクト全体を再インデックス化するのは、まったく現実的ではありません。
この問題を解決するために、私たちは Merkle Tree ベースの同期メカニズムを構築しました。
Merkle Tree: 変更検出の基盤
Merkle Tree は階層的な「フィンガープリント」システムを作成します。各ファイルは独自のハッシュフィンガープリントを持ち、フォルダーはその内容に基づくフィンガープリントを持ち、最終的にコードベース全体に対して一意のルートノードフィンガープリントへと集約されます。
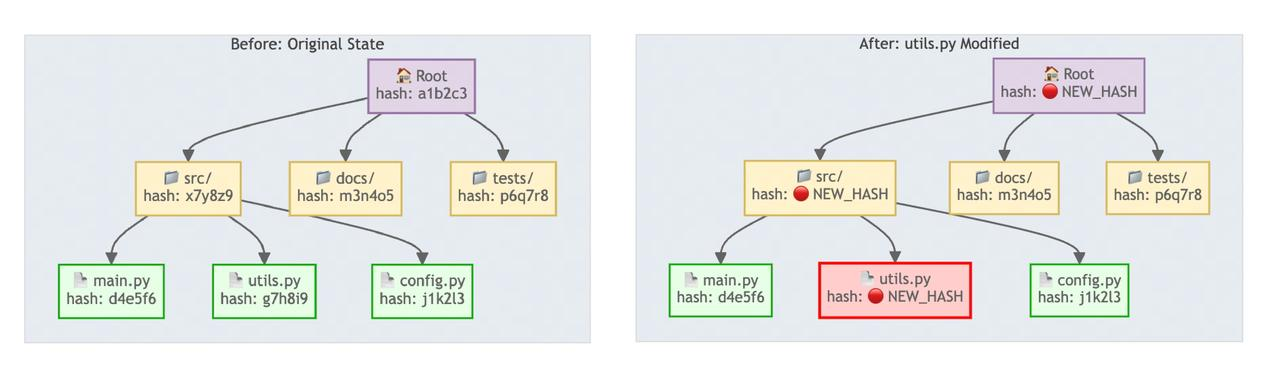
ファイルの内容が変更されると、ハッシュフィンガープリントは各レイヤーを通じてルートノードまで上方向にカスケードします。これにより、ルートから下方向へレイヤーごとにハッシュフィンガープリントを比較することで迅速な変更検出が可能になり、プロジェクト全体を再インデックス化することなく、ファイルの変更をすばやく特定して局所化できます。
システムは、合理化された3フェーズのプロセスを使用して、5分ごとにハンドシェイク同期チェックを実行します。
フェーズ1: 超高速検出 は、コードベース全体のMerkleルートハッシュを計算し、前回のスナップショットと比較します。ルートハッシュが同一であれば変更が発生していないことを意味し、システムはすべての処理をミリ秒単位でスキップします。
フェーズ2: 精密比較 は、ルートハッシュが異なる場合にトリガーされ、追加、削除、または変更されたファイルを正確に特定するために詳細なファイルレベル分析を実行します。
フェーズ3: インクリメンタル更新 は、変更されたファイルに対してのみベクトルを再計算し、それに応じてベクトルデータベースを更新して、効率を最大化します。
ローカルスナップショット管理
すべての同期状態は、ユーザーの ~/.context/merkle/ ディレクトリにローカルに永続化されます。各コードベースは、ファイルハッシュテーブルとシリアライズされたMerkleツリーデータを含む独立したスナップショットファイルを保持し、プログラム再起動後でも正確な状態復旧を保証します。
この設計は明らかな利点をもたらします。変更が存在しない場合、ほとんどのチェックはミリ秒単位で完了し、本当に変更されたファイルのみが再処理をトリガーし(大規模な計算資源の無駄を回避)、状態復旧はプログラムセッションをまたいで完璧に機能します。
ユーザー体験の観点からは、単一の関数を変更しても、そのファイルのみが再インデックス化され、プロジェクト全体ではないため、開発効率が劇的に向上します。
課題3: MCPインターフェースの設計
どれほど賢いインデックスエンジンであっても、開発者向けのクリーンなインターフェースがなければ役に立ちません。MCPは当然の選択でしたが、特有の課題ももたらしました。
🔹 ツール設計: シンプルに保つ
MCPモジュールはユーザー向けインターフェースとして機能するため、ユーザー体験が最優先事項です。
ツール設計は、標準的なコードベースのインデックス化と検索操作を、コードベースをインデックス化する index_codebase とコードを検索する search_code という2つのコアツールに抽象化することから始まります。
ここで重要な疑問が生じます。追加で必要なツールは何でしょうか?
ツールの数には慎重なバランスが必要です。ツールが多すぎると認知的負荷が生じ、LLMのツール選択を混乱させます。一方で、少なすぎると重要な機能を見落とす可能性があります。
現実世界のユースケースから逆算することで、この問いに答える助けになります。
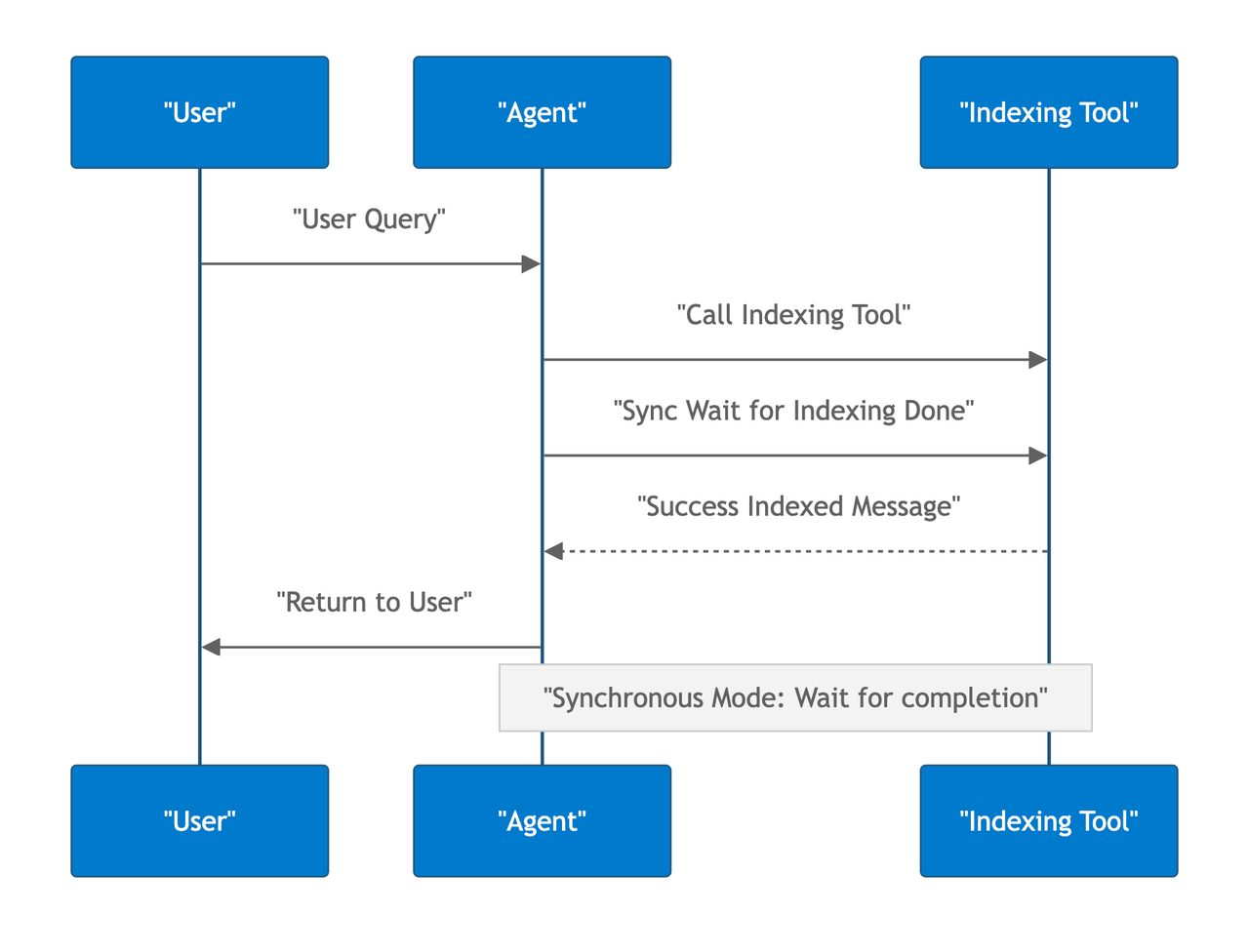
バックグラウンド処理の課題への対応
大規模なコードベースは、インデックス化にかなりの時間がかかる場合があります。同期的に完了を待つ素朴なアプローチでは、ユーザーは数分間待たされることになり、これは到底受け入れられません。非同期のバックグラウンド処理が不可欠になりますが、MCPはこのパターンをネイティブにはサポートしていません。
 8.png
8.png
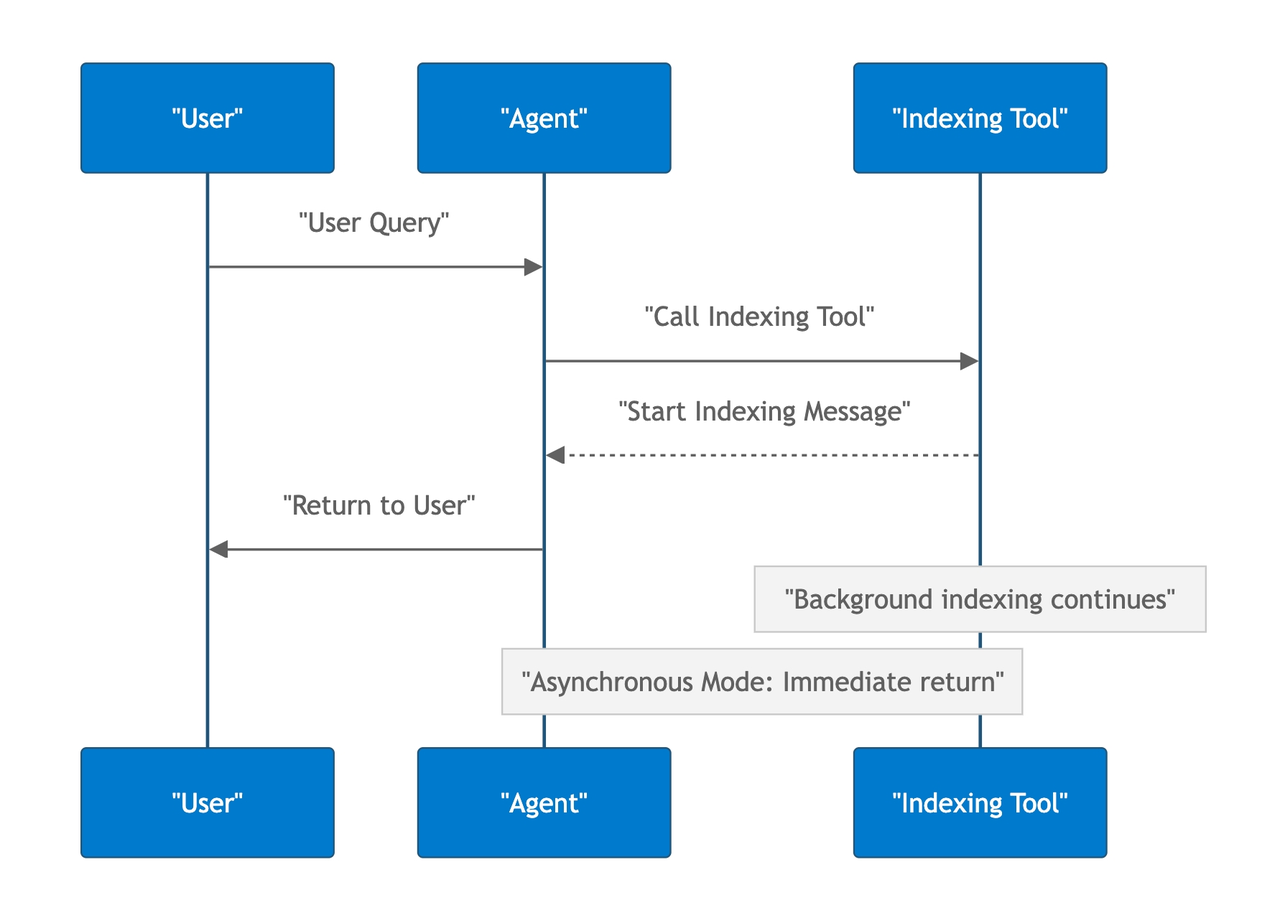
私たちのMCPサーバーは、インデックス化を処理するためにMCPサーバー内でバックグラウンドプロセスを実行しつつ、ユーザーには起動メッセージを即座に返すことで、作業を継続できるようにしています。
 9.png
9.png
これにより新たな課題が生まれます。ユーザーはインデックス化の進捗をどのように追跡するのでしょうか?
インデックス化の進捗またはステータスを照会する専用ツールによって、この問題はエレガントに解決されます。バックグラウンドのインデックス化プロセスは進捗情報を非同期にキャッシュし、ユーザーはいつでも完了率、成功ステータス、または失敗状態を確認できます。さらに、手動のインデックスクリアツールは、ユーザーが不正確なインデックスをリセットしたり、インデックス化プロセスを再開したりする必要がある状況に対応します。
最終的なツール設計:
index_codebase - コードベースをインデックス化
search_code - コードを検索
get_indexing_status - インデックス化ステータスを照会
clear_index - インデックスをクリア
シンプルさと機能性の完璧なバランスを取る4つのツールです。
🔹 環境変数管理
環境変数管理は、ユーザー体験に大きな影響を与えるにもかかわらず、見落とされがちです。MCP Client ごとに個別の API キー設定を要求すると、Claude Code と Gemini CLI を切り替える際に、ユーザーは認証情報を何度も設定しなければならなくなります。
グローバル設定アプローチは、ユーザーのホームディレクトリに ~/.context/.env ファイルを作成することで、この摩擦を解消します。
# ~/.context/.env
OPENAI_API_KEY=your-api-key-here
MILVUS_TOKEN=your-milvus-token
このアプローチには明確な利点があります: ユーザーは一度設定すればすべての MCP クライアントでどこでも利用でき、すべての設定が単一の場所に集約されるため保守が容易になり、機密性の高い API キーが複数の設定ファイルに散らばることもありません。
また、3 層の優先順位階層も実装しています。プロセス環境変数が最優先、グローバル設定ファイルが中位の優先度、デフォルト値がフォールバックとして機能します。
この設計は非常に高い柔軟性を提供します。開発者は一時的なテスト用の上書きに環境変数を使え、本番環境ではセキュリティ強化のためにシステム環境変数を通じて機密設定を注入でき、ユーザーは一度設定するだけで Claude Code、Gemini CLI、その他のツールをシームレスに利用できます。
この時点で、MCP サーバーのコアアーキテクチャは完成しており、コード解析とベクトルストレージからインテリジェントな検索、設定管理までをカバーしています。すべてのコンポーネントは、強力でありながらユーザーフレンドリーなシステムを作るために、慎重に設計・最適化されています。
実践テスト
では、Claude Context は実際にはどのように機能するのでしょうか?私は、最初に自分を苛立たせたのとまったく同じバグ探しシナリオでテストしました。
Claude Code を起動する前のインストールは、たった 1 つのコマンドでした。
claude mcp add claude-context -e OPENAI_API_KEY=your-openai-api-key -e MILVUS_TOKEN=your-zilliz-cloud-api-key -- npx @zilliz/claude-context-mcp@latest
コードベースのインデックス作成が完了した後、以前は Claude Code を 5 分間の grep 頼みの無駄な探索 に陥らせたのと同じバグ説明を与えました。今回は、claude-context MCP 呼び出しを通じて、問題の説明付きで 正確なファイルと行番号を即座に特定 しました。
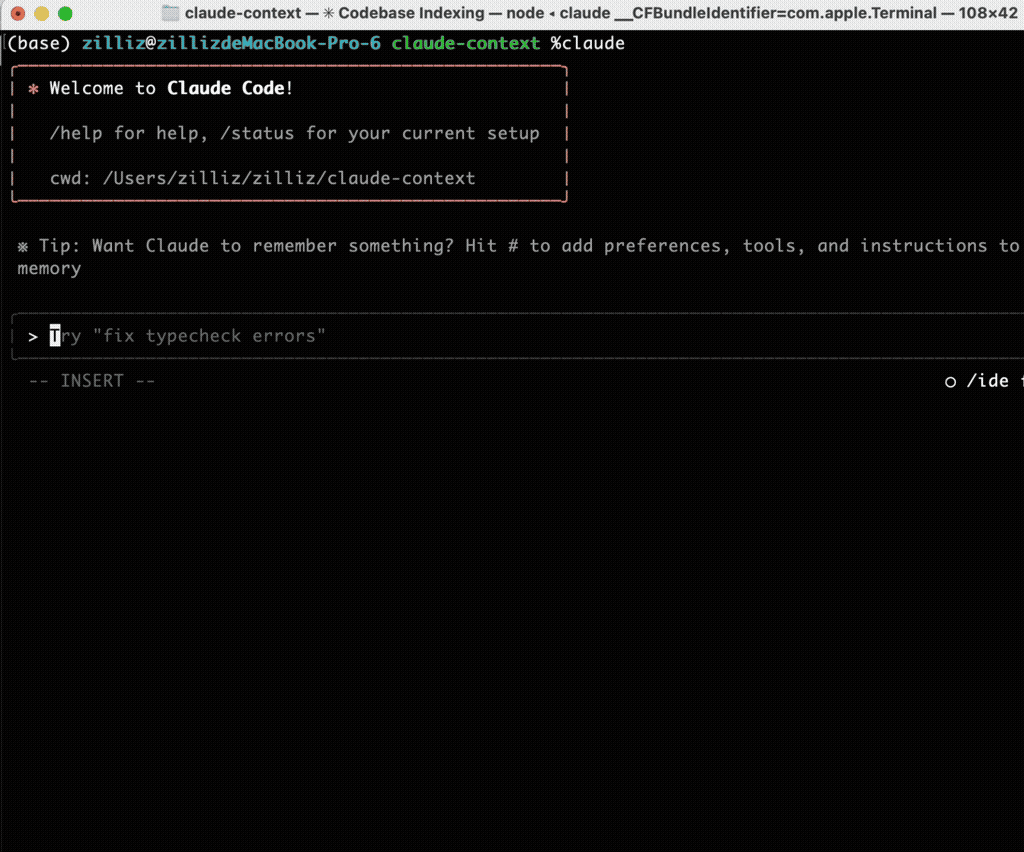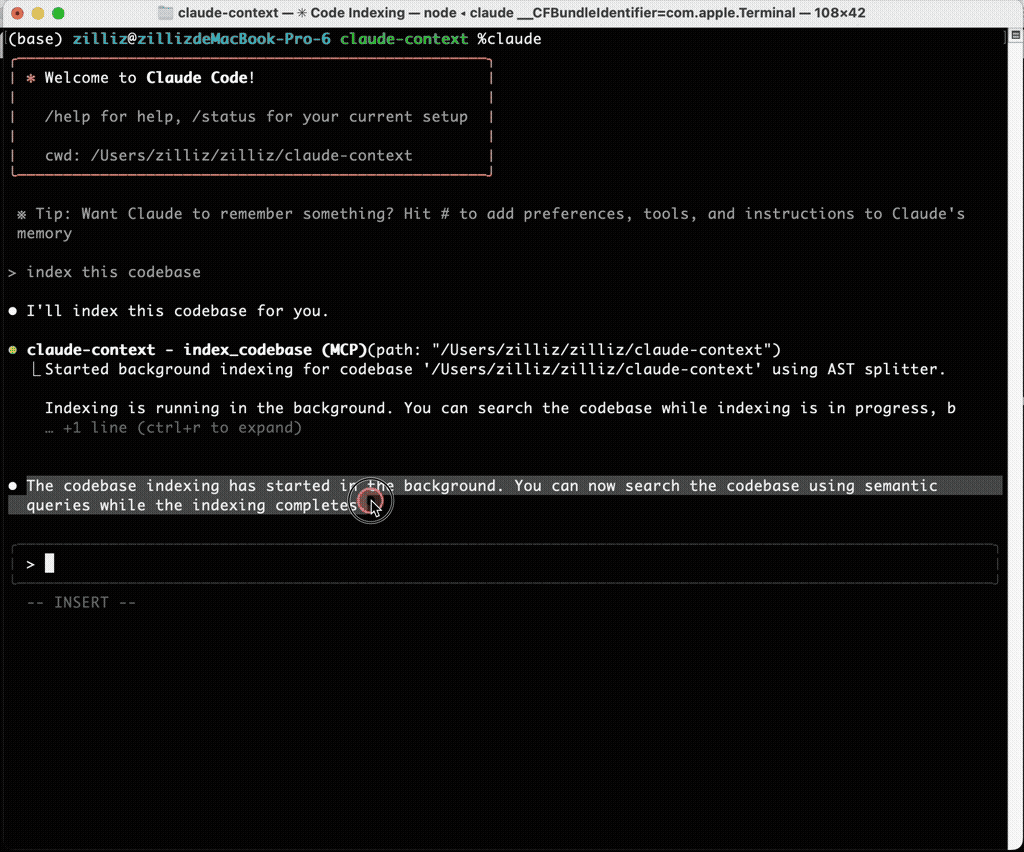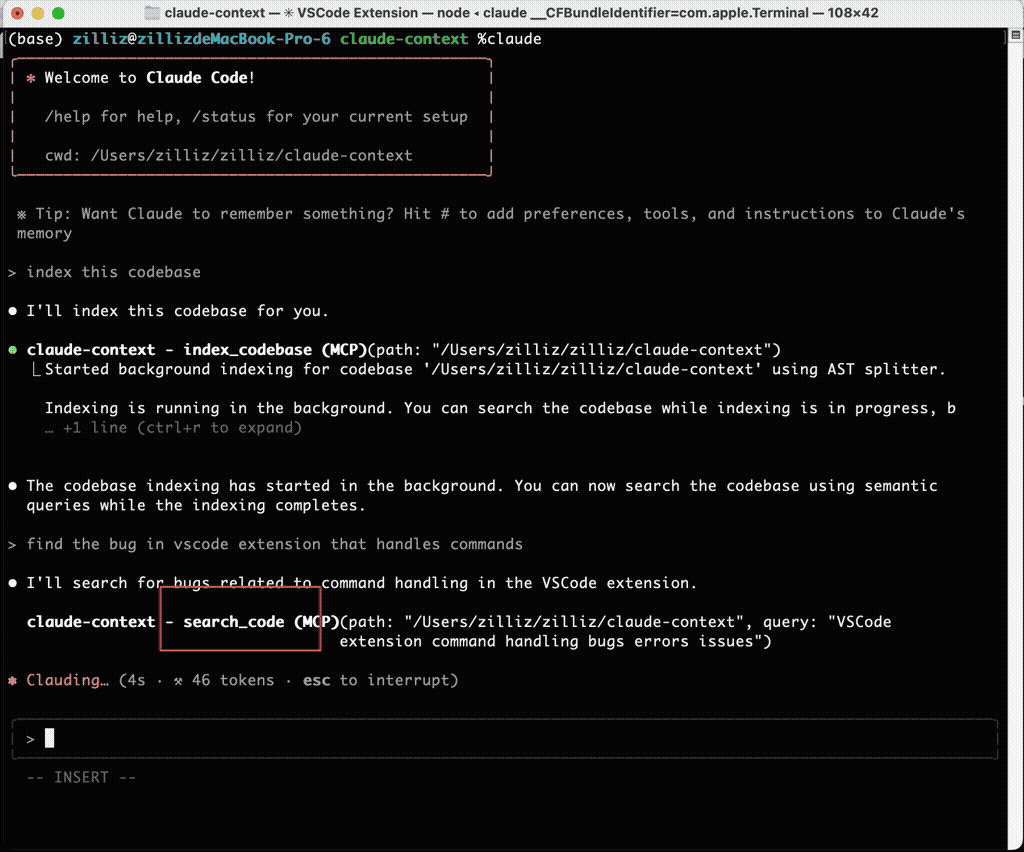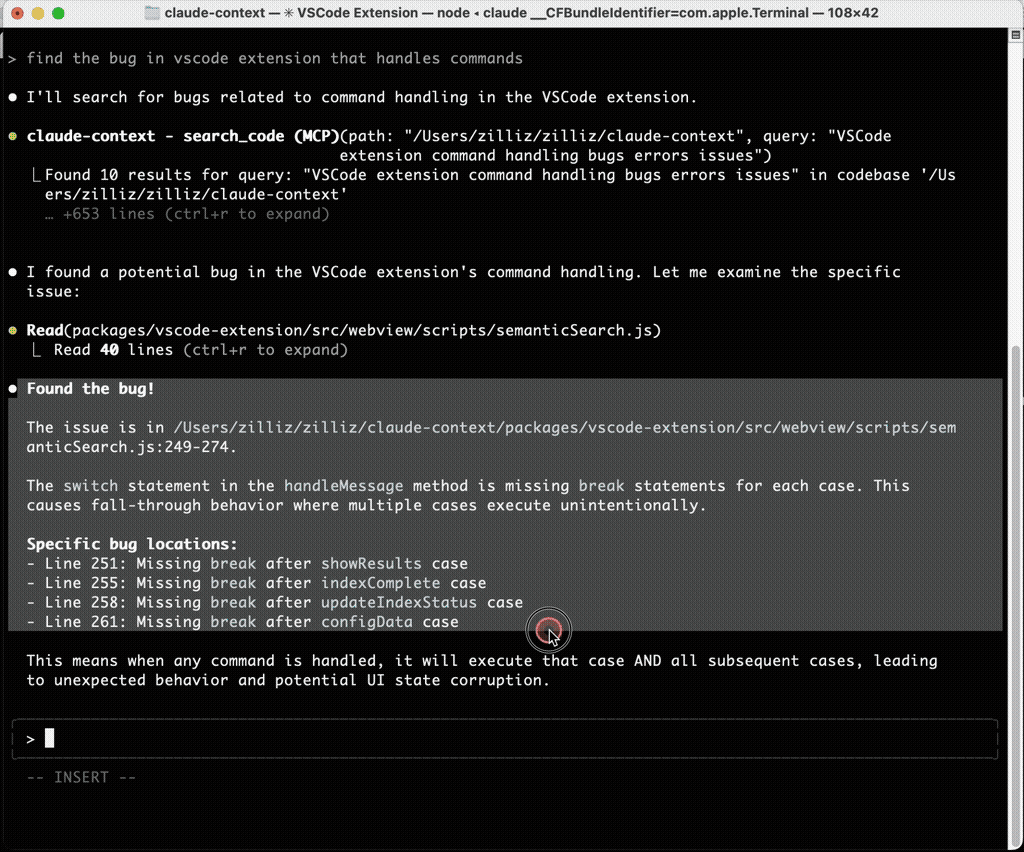
その違いはわずかなものではなく、まさに昼と夜ほどの差でした。
しかも、バグ探しだけではありません。Claude Context を統合すると、Claude Code は以下の領域で一貫してより高品質な結果を出しました。
課題解決
コードリファクタリング
重複コード検出
包括的なテスト
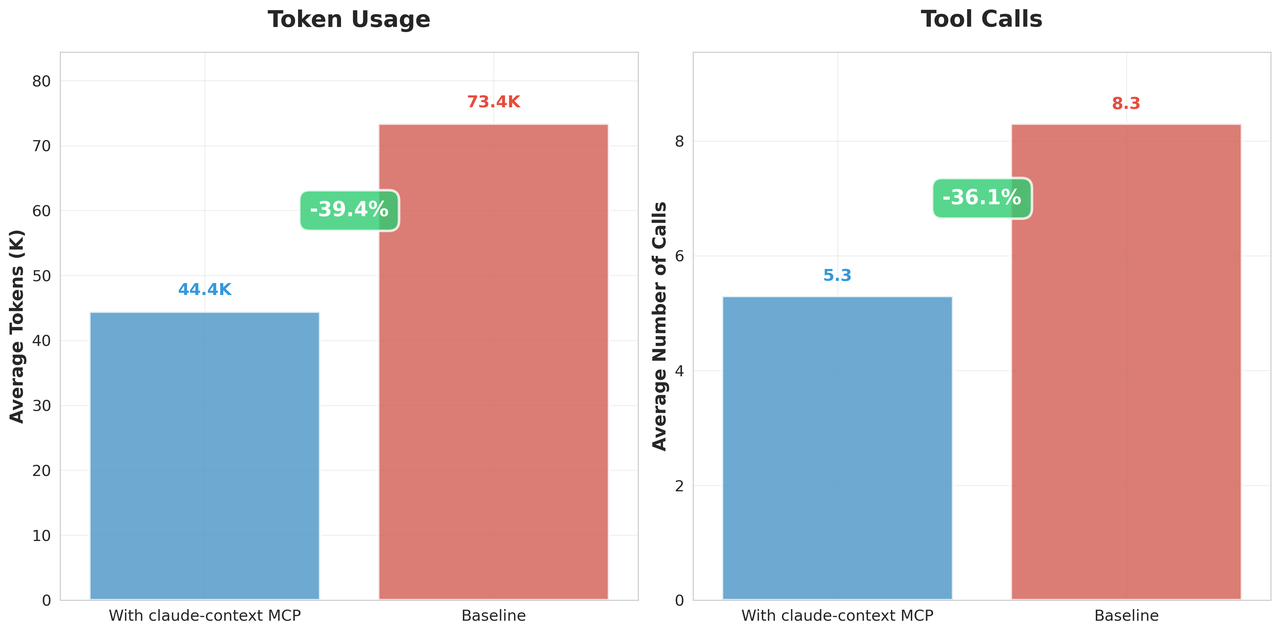
パフォーマンス向上は数値にも表れています。並行テストでは次のような結果でした。
リコールを損なうことなく、トークン使用量が 40% 以上減少しました。
これは API コストの削減と応答の高速化に直接つながります。
あるいは、同じ予算で Claude Context ははるかに正確な検索結果を提供しました。
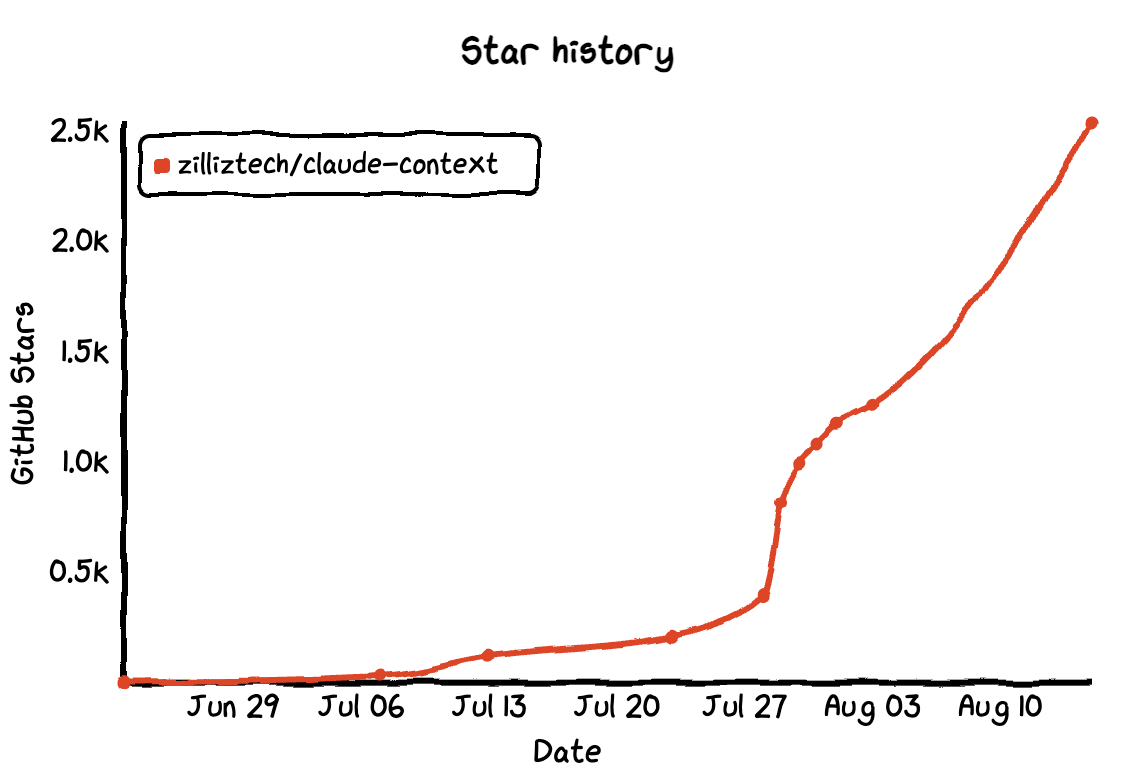
私たちは Claude Context を GitHub でオープンソース化しており、すでに 2.6K+ のスターを獲得しています。皆さまのご支援といいねに感謝します。
ぜひご自身で試してみてください。
詳細なベンチマークとテスト手法はリポジトリで公開しています。ぜひフィードバックをお寄せください。
今後に向けて
Claude Code における grep への不満から始まったものは、確かな解決策へと成長しました。Claude Context は、Claude Code やその他のコーディングアシスタントに、セマンティックでベクトル駆動の検索をもたらすオープンソースの MCP プラグインです。メッセージはシンプルです。開発者は非効率な AI ツールに甘んじる必要はありません。RAG とベクトル検索を使えば、デバッグを高速化し、トークンコストを 40% 削減し、ついに自分のコードベースを本当に理解する AI 支援を得ることができます。
そして、これはClaude Codeに限ったことではありません。Claude Contextはオープン標準に基づいて構築されているため、同じアプローチがGemini CLI、Qwen Code、Cursor、Cline、そしてそれ以外でもシームレスに機能します。パフォーマンスよりもシンプルさを優先するベンダーのトレードオフに縛られることは、もうありません。
私たちは、あなたにその未来の一員になっていただきたいと考えています。
お試しください Claude Context: オープンソースで、完全に無料です
開発に貢献してください
または独自のソリューションを構築してください Claude Contextを使用して
👉 フィードバックを共有したり、質問したり、サポートを受けたりするには、Discordコミュニティにご参加ください。

読み続けて

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.