




Understanding Multimodal Artificial Intelligence
Understanding Multimodal Artificial Intelligence
The launch of ChatGPT and many other large language models (LLMs) marked a crucial milestone in AI development. During this time, AI models transitioned from niche applications to everyday uses like writing, coding, customer service, and content creation. However, much of this progress was limited to a single modality: text.
Focusing on just one modality is not enough to achieve the vision of general artificial intelligence (AGI). By its very definition, AGI requires the ability to understand, reason, and act across multiple domains, from language and vision to auditory and sensory input. Hence, multimodality was born; this article will guide you through this technique.
What is Multimodal AI?
Artificial intelligence systems are multimodal if they process and analyze information from multiple modalities, such as text, images, audio, and videos. On the other hand, AI that can only process one type of modality is Uni-modal.
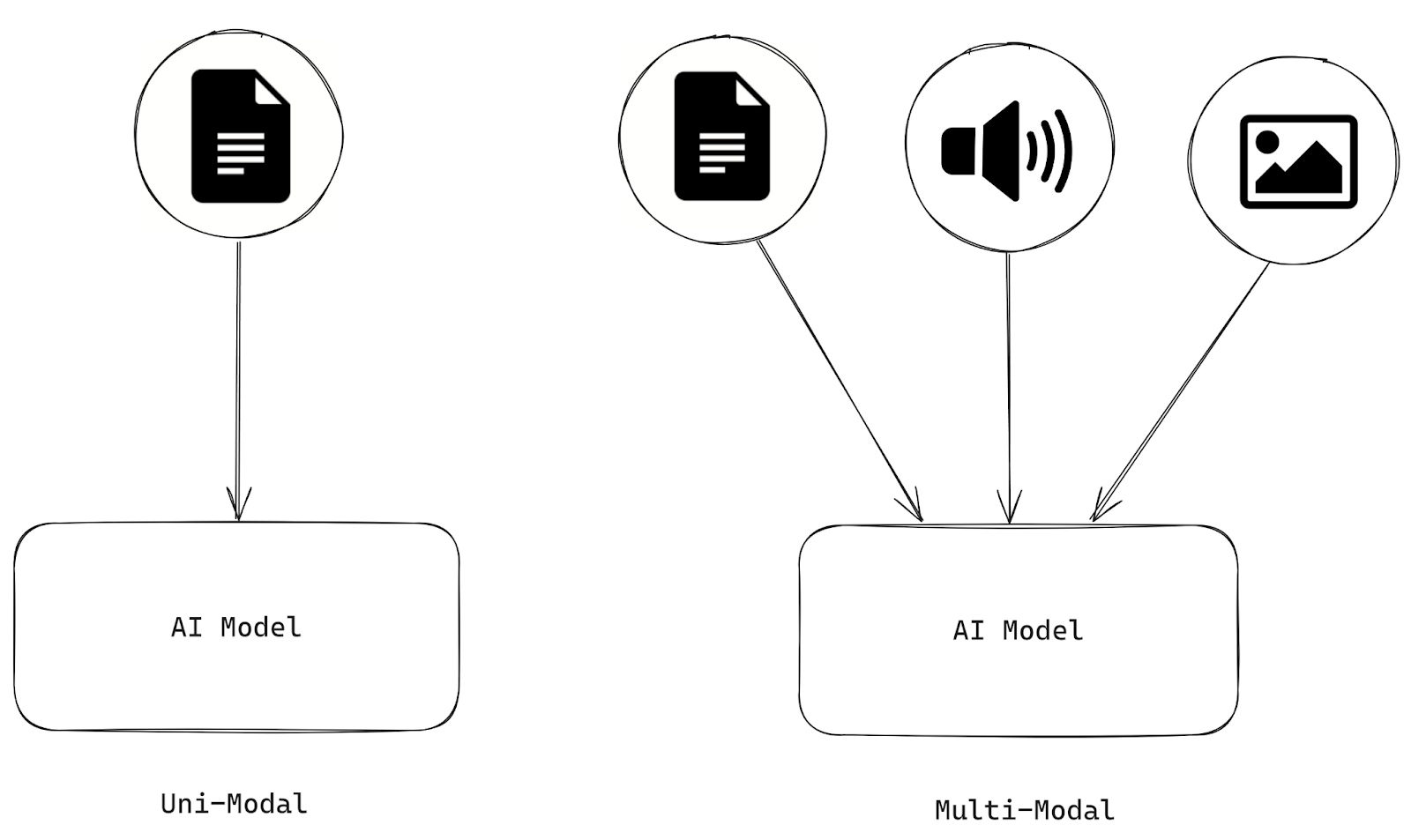 Figure 1- Differences between Uni and Multi-Modal AI.png
Figure 1- Differences between Uni and Multi-Modal AI.png
Figure 1: Differences between Uni and Multi-Modal AI
It's important to clarify the distinction between two often-confused terms: multimodal and multi-model. Multimodal refers to systems integrating and processing information from multiple data types. In contrast, multi-model describes using multiple independent models that work in parallel or in combination to accomplish a task. These models may operate on the same or different data types but remain separate rather than integrated.
Multimodal AI can significantly impact many applications. For example, a multimodal AI healthcare system may employ medical images, voice recordings from patients, and clinical notes to build a diagnosis more precisely than could have been produced by a system relying solely on one data source. In this respect, multimodal AI systems approach human cognition much more closely and are highly effective in tasks with a critical need for an overarching understanding.
Multimodal can be one or more of the following:
Input and output are in different modalities, such as text-to-image or image-to-text.
Inputs are multimodal (for example, text and images).
Outputs are multimodal, such as one system that gives text and images.
In the following section, we will discuss how multimodal systems operate.
How Does Multimodal AI Work?
Various components work together in a multi-modal model. Here are the most important elements and their working:
Data Types: Multimodal AI integrates multiple data types, including text, images, audio, and videos, allowing for a comprehensive understanding and generation of content across different modalities.
Representation: Multimodal representations in machine learning combine data from different modalities into more meaningful features that models can use. Two different approaches are used to achieve this.
Joint Representations: Data from different modalities is transformed into a unified representation space, suitable when multimodal data is available during training and inference. Standard techniques include neural networks and probabilistic graphical models. While these methods can enhance performance, they face challenges with missing data.
Coordinated Representations: Each modality is processed separately, with constraints enforced to align them in a shared space.
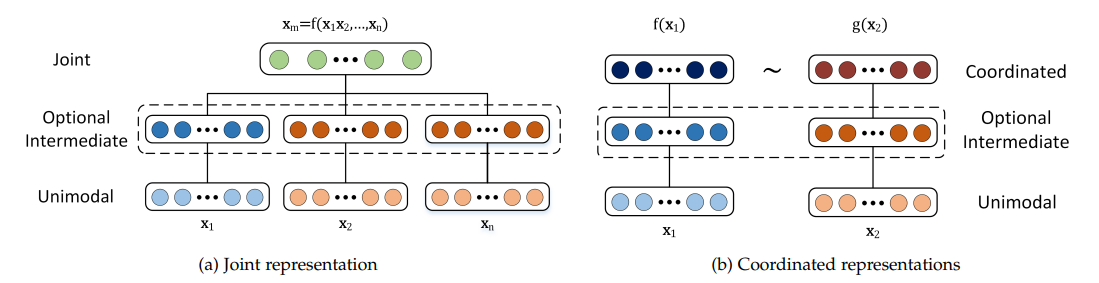 Figure 2- Structure of joint and coordinated representations.png
Figure 2- Structure of joint and coordinated representations.png
Figure 2: Structure of joint and coordinated representations | Source
Feature Extraction: Specialized techniques are employed for extracting features from each data type, such as natural language processing (NLP) for text, computer vision for images, and signal processing for audio.
Data Fusion: Fusion combines information from two or more modalities for a prediction task. The approaches are as follows:
Early Fusion: Data is integrated before analysis, typically at a low-dimensional subspace using methods like PCA (Principal Component Analysis) or ICA (Independent Component Analysis). This approach requires synchronization of modalities, which can be challenging due to varying data formats and sampling rates. While efficient for feature extraction, it may lead to data loss and synchronization issues.
Late Fusion: Individual modality outcomes are combined at the decision level using ensemble methods like bagging, boosting, or rule-based approaches (e.g., Bayes, max, or average fusion). This method excels when uncorrelated modalities, offering flexibility akin to human cognition.
Modeling: Neural networks capable of processing multiple modalities, such as transformers or convolutional neural networks (CNNs), are used to learn from diverse inputs. There are more sophisticated models that have superior results and are often termed LMMs (Large Multimodal Models).
Popular Multimodal Models and Their Architectures
Many multimodal models are available in the market. Below are popular models and architectures.
Video-Audio-Text Transformer (VATT)
The Video-Audio-Text Transformer (VATT) is a convolution-free architecture designed to handle multiple modalities (video, audio, and text) using a unified Transformer-based framework. VATT begins by feeding each modality into a tokenization layer, where the raw input is projected into an embedding vector that a Transformer subsequently processes.
There are two main configurations: one in which separate Transformers with unique weights are used for each modality and another in which a single Transformer backbone with shared weights handles all modalities.
Regardless of the configuration, the Transformer extracts modality-specific representations and maps them to a shared space for further tasks. The architecture follows the standard Transformer pipeline, commonly used in NLP and Vision Transformers (ViT), using input tokens.
Additionally, VATT incorporates a learnable relative bias for text, making it compatible with models like T5. This approach allows VATT to model multimodal data effectively for tasks such as classification.
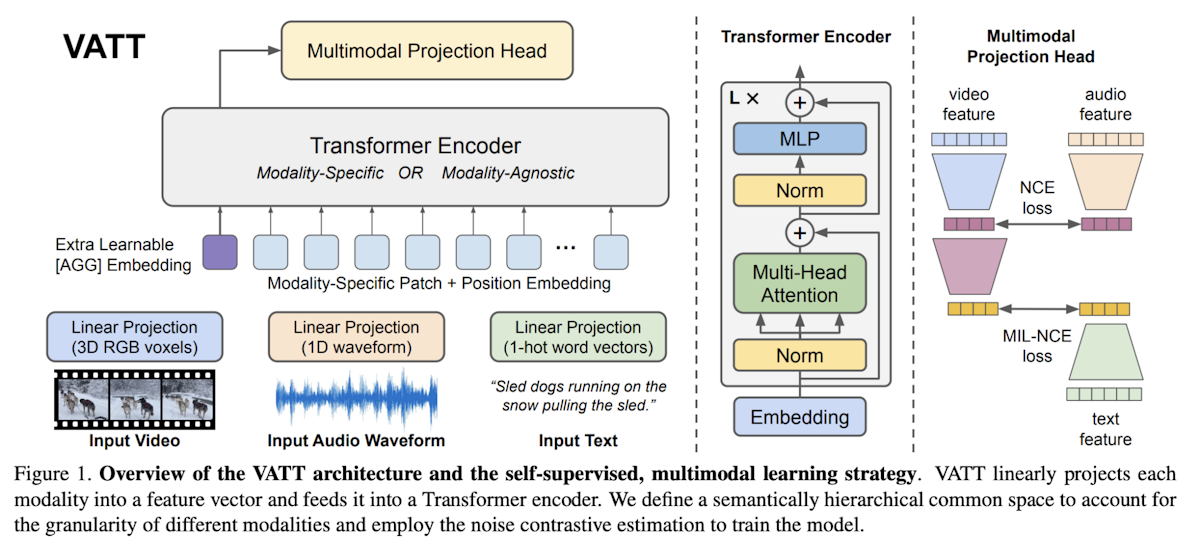 Figure 3- Vision Transformers for Multimodal Learning.png
Figure 3- Vision Transformers for Multimodal Learning.png
Figure 3: Vision Transformers for Multimodal Learning | Source
Multimodal Variational Autoencoder (MVAE)
The Multimodal Variational Autoencoder (MVAE) architecture is designed to learn a unified representation of text and images. The MVAE has three main components: an encoder, a decoder, and an application module (a fake news detector, in this case).
 Figure 4- Multimodal Variational Autoencoder Architecture.png
Figure 4- Multimodal Variational Autoencoder Architecture.png
Figure 4: Multimodal Variational Autoencoder Architecture | Source
Encoder: This component processes text and image inputs to generate a shared latent representation. It consists of two sub-encoders:
Textual Encoder: Converts a sequence of words from a post into word embeddings using a pre-trained deep network.
Visual Encoder: This process extracts visual features from images using CNNs (like VGG-19) to capture spatial and object semantics.
Decoder: The decoder reconstructs the original text and image from the shared latent representation. It mirrors the structure of the encoder and is divided into:
Textual Decoder: This decoder reconstructs the text by passing the latent representation through bidirectional LSTM units and a fully connected layer, predicting each word's probability.
Visual Decoder: Reverses the visual encoding by reconstructing VGG-19 image features through fully connected layers.
Fake News Detector: This component predicts whether a news post is real or fake using the shared multimodal latent representation.
CLIP (Contrastive Language-Image Pretraining)
The CLIP (Contrastive Language-Image Pretraining) model is designed to learn joint representations of images and text by training on a vast dataset of image-text pairs. CLIP uses two separate neural networks: one for images (often a Vision Transformer or a CNN) and one for text (typically a Transformer).
These networks encode images and text into fixed-length vectors in a shared embedding space. During training, CLIP leverages a contrastive learning objective, which pulls together the embeddings of matched image-text pairs and pushes apart those of mismatched pairs.
Through this process, CLIP learns to correlate visual and textual information. This approach enables the model to perform zero-shot image classification, allowing it to recognize objects in images based on natural language descriptions without needing task-specific training. This powerful architecture can be used in text-image-based tasks to improve generalization ability.
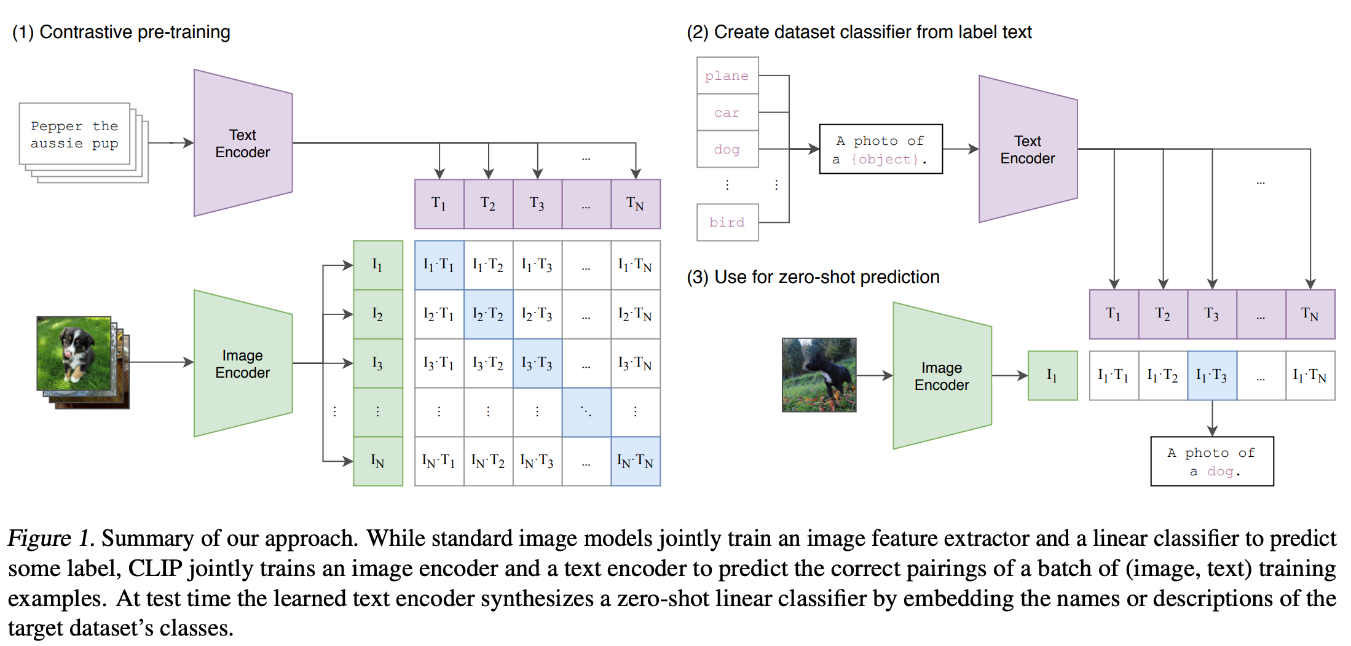 Figure 4- Architecture of CLIP Model.png
Figure 4- Architecture of CLIP Model.png
Figure 4: Architecture of CLIP Model
Some closed-source models of these architectures include:
Google Gemini: A multimodal LLM excelling in text, images, video, and audio, outperforming GPT-4 on multiple benchmarks.
ChatGPT (GPT-4V): Supports text, voice, and images, allowing users to interact with AI-generated voices and generate images via DALL-E 3.
Inworld AI: Creates intelligent NPCs for digital worlds, enabling communication through natural language, voice, and emotion.
Meta ImageBind: Processes six modalities, combining data for tasks like creating images from audio and enabling machines to perceive their environments.
Runway Gen-2: Generates and edits videos from text, images, or existing videos, offering versatile content creation capabilities.
Check out this post for more multimodal models.
Multimodal RAG: Expanding Beyond Text
Retrieval Augmented Generation (RAG) is a method for retrieving contextual information for large language models from external sources and generating more accurate output. It also helps mitigate AI hallucinations and address some data security concerns. Traditional RAG has been highly effective in improving the LLM output, but it remains limited to textual data. In many real-world applications, knowledge extends beyond text, incorporating images, charts, and other modalities that provide critical context.
Below is an overview of a typical text-based RAG workflow:
The user submits a text query to the system.
The query is transformed into a vector embedding, which is then used to search a vector database , such as Milvus, where text passages are stored as embeddings. The vector database retrieves passages that closely match the query based on vector similarity.
The relevant text passages are passed to the LLM as supplementary context, enriching its understanding of the query.
The LLM processes the query alongside the provided context, generating a more informed and accurate response.
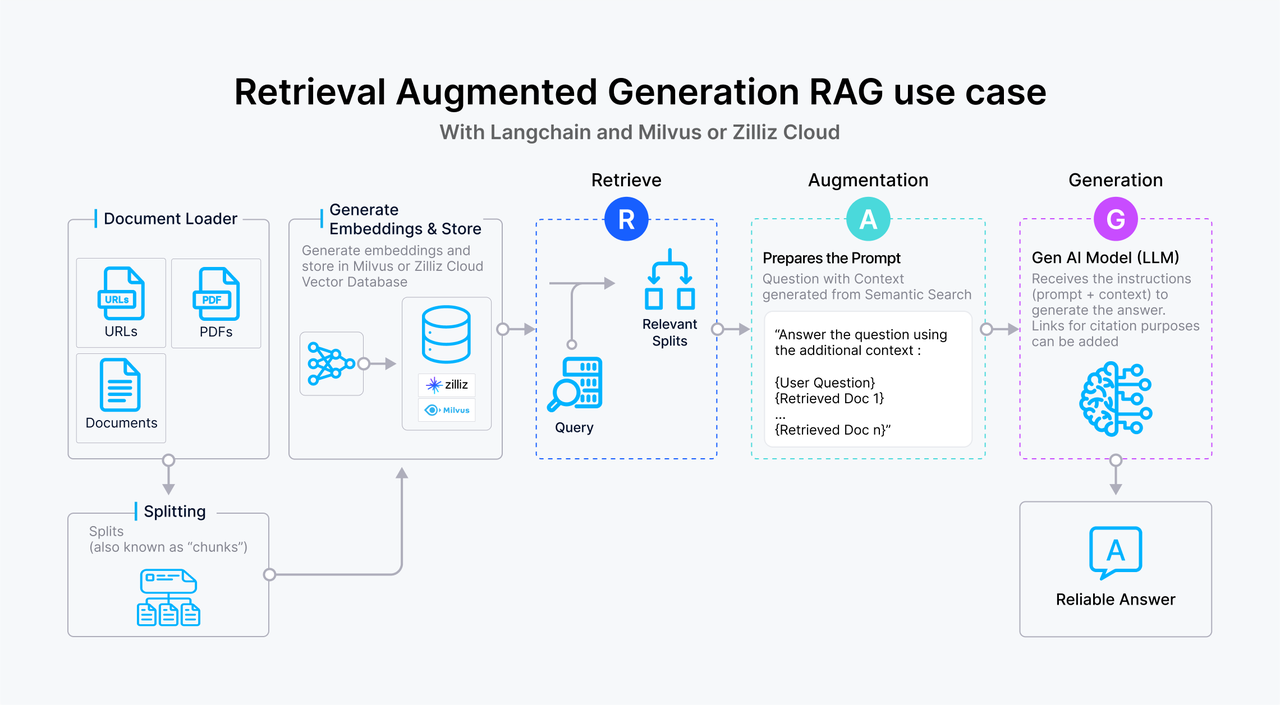 Figure 1- How RAG works.png
Figure 1- How RAG works.png
Figure: How RAG works
Multimodal RAG addresses the above limitation by enabling the use of different data types, providing better context to LLMs. Simply put, in a multimodal RAG system, the retrieval component searches for relevant information across different data modalities, and the generation component generates more accurate results based on the retrieved information.
To build such a system, we need to use multimodal models to generate embeddings and LLMs with multimodal capabilities, such as LLAVA, GPT4-V, Gemini 1.5, Claude 3.5 Sonnet, etc., to generate answers.
There are a couple of ways we can implement multimodal RAG:
Use a multimodal embedding model like CLIP to transform texts and images into embeddings. Next, retrieve relevant context by performing a similarity search between the query and text/image embeddings. Finally, pass the most relevant context's raw text and/or image to our multimodal LLM.
Use a multimodal LLM to produce text summarizations of images or tables. Next, transform those text summarizations into embeddings with a text-based embedding model. Then, perform a text similarity search between the query and summarization embeddings. Finally, pass the raw image of the most relevant summary to our LLM for response generation.
To learn more details about how to build a multimodal RAG application, check out our tutorials using the different approaches shown below:
Build a Multimodal RAG with Gemini, BGE-M3, Milvus and LangChain
Build Better Multimodal RAG Pipelines with FiftyOne, LlamaIndex, and Milvus
Comparison Between Unimodal and Multimodal
Multimodal systems differ from traditional (unimodal) systems in the way that they simultaneously process and integrate data from multiple types of input modalities (e.g., text, images, and audio).
Multimodal systems have an advantage in understanding context because they extract information from two sources: vision and language. Traditional approaches are more straightforward and focus on specific application domains. The following table illustrates some critical differences between unimodal and multimodal systems.
| Aspect | Traditional AI | Multimodal AI |
| Input Type | Uses a single type of input (e.g., only text, only image) | Processes multiple types of input (e.g., text, images, audio) |
| Processing Focus | Focuses on one sensory or data modality | Integrates and relates information across multiple modalities |
| Complexity | Simpler and often domain-specific | It is more complex due to the need to integrate diverse data types |
| Context Understanding | Limited to information available in a single modality | Can understand the context better by using different modalities |
| Applications | Text classification, Object detection, Speech recognition, etc. | Human-Computer Interaction, Robotics, Autonomous Vehicles, Augmented Reality etc. |
Benefits and Challenges of Multimodal AI
This section will list some critical benefits and associated challenges of building and evaluating multimodal systems.
Benefits
Some of the benefits of using multimodal AI are listed below:
Enhanced Context: Multimodal systems capture broader context by integrating complementary information from different sources, such as combining visual cues with language for better interpretation.
Improved performance: By incorporating data from multiple modalities, multimodal AI can make more accurate predictions and decisions. For instance, a medical diagnosis system might be more reliable considering patient images and medical records.
Versatility: Multimodal AI can be applied to various complex tasks, including image captioning, visual question answering, medical diagnostics, autonomous driving, etc., making them highly adaptable to multiple domains.
More Human-Like Understanding: Multimodal AI can better mimic human cognition and enable better human-computer interaction in real-time applications by processing data from various senses (modalities).
Challenges
Some challenges linked to the use of multimodal AI include:
Representation: The method or format in which modalities are represented extracts the complementary or redundant information between multiple modalities. Multimodal data representation is very important but challenging due to its heterogeneous nature. For example, the sound is a signal, and the image is a 3D representation with varying scales and dimensions to represent. How to bring them into the same common representation space is an essential implementation point.
Translation: The procedure can explain how to convert or transform data from one modality to another once it is heterogeneous. The relation between different modalities is mainly subjective. For example, translating a video to its corresponding text description.
Fusion: Refers to combining data from multiple modalities for improved predictions. For example, in audio-visual speech recognition, the visual description of lip motion is integrated with the speech signal to predict spoken words. The information may come from different modalities and has various levels of predictive strength, importance, contribution, and noise topology. There are missing data values in at least one of the modalities.
Explainability: A recent term, Explainable AI (XAI), aims to explain meaningful explanations and reasoning about a model. In the case of multiple modalities, it is more challenging to understand how models arrive at conclusions with different data sources.
FAQs of Multimodal AI
- What is multimodal AI?
Multimodal AI is a type of artificial intelligence system that can process and analyze information from various modalities, including text, images, audio, and video.
- What data types can Multimodal AI use?
Multimodal AI uses various data types, including text, images, audio, video, sensor, and graph data.
- Is Multimodal AI replacing traditional AI?
Multimodal AI is not replacing traditional AI but expanding its capabilities by integrating multiple data modalities. It's an extension. Traditional methods remain essential, while Multimodal AI provides additional capabilities.
- What are some typical applications of multimodal AI?
Typical applications of multimodal AI include image captioning, visual question answering, emotion recognition, and autonomous driving.
- What are the advantages of Multimodal AI?
Multimodal AI has several advantages, including robustness, efficiency, context awareness, a diverse application domain, and improved human-computer interaction.
Related Resources
- What is Multimodal AI?
- How Does Multimodal AI Work?
- Popular Multimodal Models and Their Architectures
- Multimodal RAG: Expanding Beyond Text
- Comparison Between Unimodal and Multimodal
- Benefits and Challenges of Multimodal AI
- FAQs of Multimodal AI
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free