




From Text to Image: Fundamentals of CLIP
News flash: Teenagers are turning to TikTok as their favorite search engine, and apparently it works better than you'd think. This is not surprising because traditional search engines do not always find what you want. Especially if you're a visual person like me, you would probably find images and videos much more intuitive and pleasant than having to crawl through lines of text. Have you ever wondered, though, how machines understand a given text and match it with the images they return?
In this blog series, we will introduce you to retrieving images based on texts, or text-to-image services. Text-to-image has always been an important cross-modal application, and the industry used to rely on roundabout solutions that require a huge amount of user-generated data to group images and find out their semantic relations. That is, until last year, when OpenAI dropped a bomb on the industry with the release of CLIP. OpenAI used an astounding number of 400 million text-image pairs to build CLIP so that it can learn visual concepts based on natural language input. Now, we need to know about some basic knowledge in order to understand the basic components of search algorithms, CLIP, and text-to-image.
Search algorithms and semantic similarity
Search algorithms, be it traditional or new school, or unimodal or cross-modal, cannot do without the measure of semantic similarity, or rather, the semantic distance between two things. This may sound a bit abstract, so let’s see a few examples. Let’s start with the one-dimensional space of integers, which has probably been engraved in your DNA since elementary school (though probably not phrased as such back then). Now, we have 5 positive integers {1, 5, 6, 8, 10}, tell me, which number is closest to 5? Yes, it’s 6. Congrats on graduating from your childhood. The reason is that 6 has the shortest distance from 5, which is 1. The distance here is the semantic distance between 5 and 6.
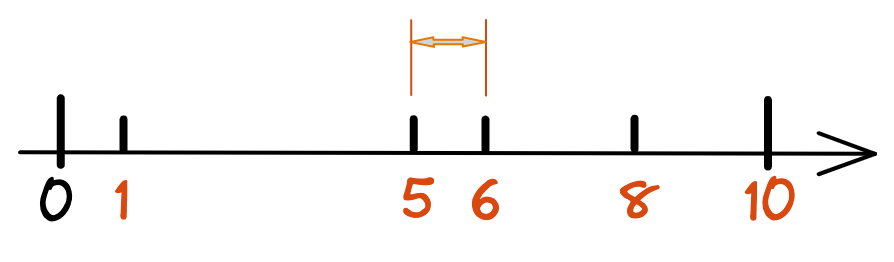 Figure 1 A One-Dimensional Space of Integers
Figure 1 A One-Dimensional Space of Integers
Now that you are in machine learning, let’s take a tiny step forward to see how traditional text search is done. If you talk to somehow who’s done text search before, then you will most likely hear TF-IDF a lot. TF refers to term frequency, that is, word frequency. Imagine there is a high-dimensional space with as many dimensions as there are words in a dictionary. If we count the number of occurrences of each word in an article and set this number as the value in the corresponding dimension of this space, we can describe any article as a distribution of sparse vectors on this word vector space (sparse because an article usually covers only a very small fraction of the words in the dictionary).
 Figure 2 A Demonstration of Word Vector Space
Figure 2 A Demonstration of Word Vector Space
This is a very simple yet practical way of thinking. As shown above, if two articles are similar in their field or content, then the vectors corresponding to these two articles should not be that far apart in the word vector space. If the two articles are identical, then the distance between their word vectors will be 0. In text search, we extend the one-dimensional positive integer space in our first example to a high-dimensional word vector space, but they basically share the same approach: define a space that can be used to describe the semantics of the data and determine the distance between them.
Let’s take another tiny step (yes, you saw this coming). Now that we have texts done, why not map the semantics of images into the word vector space too so that we can achieve text-image cross-modality?
But of course, it’s not that easy. Texts basically are giving their semantics to us for free: they have "words" as a natural semantic unit. Images don’t have that. We can’t use their individual pixels to define their meanings.
The puzzle of vectorizing without natural semantic units used to plague the field of image search and unstructured data in general. Most data types (images, videos, audio, point clouds, etc.) do not come with natural semantic units. It could not be effectively solved until data and computing power became cheap enough and neural networks became popular. Let’s see how this problem is solved by neural networks.
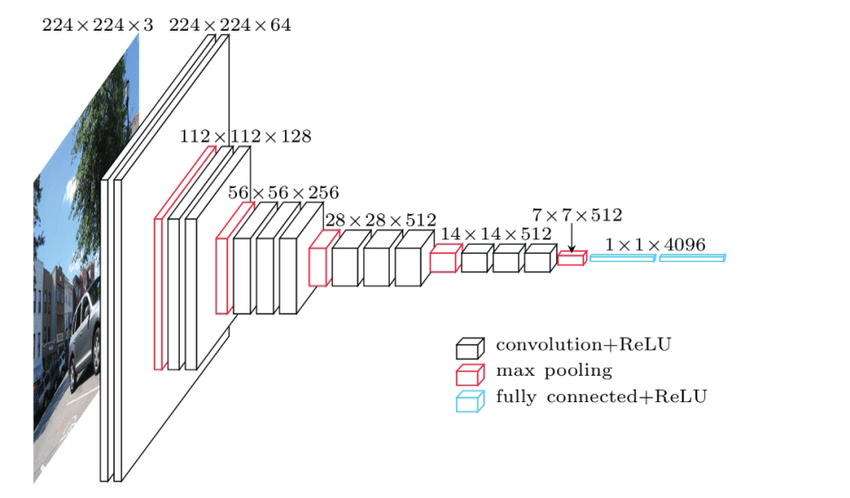 Figure 3 Convolutional Neural Network Layers and Architectures
Figure 3 Convolutional Neural Network Layers and Architectures
One of the great features of a deep neural network is that it is "deep enough" (You're welcome). In the figure above, the input on the left is a 224 x 224 image, and the output on the right is a 4096-dimensional vector. From left to right, an image passes through many neural network layers, and the neural network gradually compresses the spatial information on the original picture’s pixels into semantic information. In this process, we can see that the spatial dimension is getting narrower but the semantic dimension is getting longer (not the most accurate statement, but I haven’t found a better way to put it). Essentially, this process is a mapping of the semantics of the image to a real vector space with 4096 dimensions. Compared to the previously described techniques, vectorizing via deep neural networks has several obvious advantages:
- It does not require the original data to have natural, directly segmentable semantic units, such as “words”.
- The definition of “data similarity” is flexible and is determined by the training data and the objective function, and can be customized for application-specific features.
- The data vectorization process is the model’s inference process, which mainly involves matrix operations and can take advantage of the acceleration capabilities of modern GPUs.
What CLIP has done is connect texts and images cross-modally. On the data side, OpenAI has developed a large-scale dataset of text-image pairs, WIT (WebImageText). The model is trained using a contrast learning approach to predict whether images and texts are to be paired. Its design is rather simple:
- Perform feature encoding for texts and images respectively;
- Project text and image features from their respective unimodal feature spaces into a multimodal feature space;
- Within the multimodal space, the distance between the feature vectors of texts and images that are supposed to be pairs (positive samples) should be as close as possible, and vice versa for negative samples.
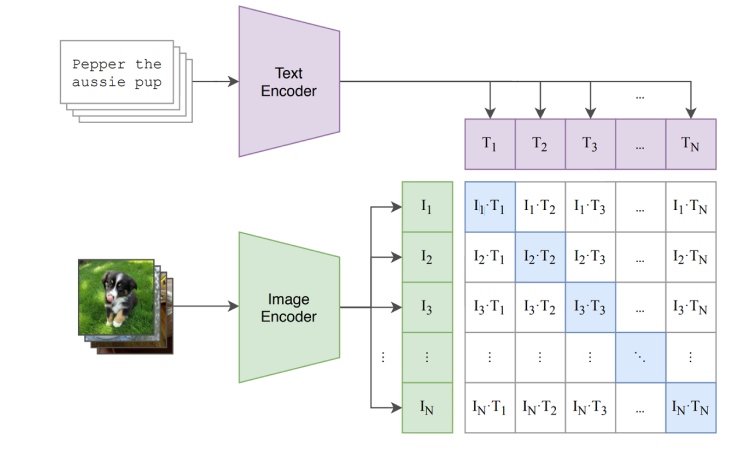 Figure 4 Learning Transferable Visual Models From Natural Language Supervision. Image source: https://arxiv.org/pdf/2103.00020.pdf
Figure 4 Learning Transferable Visual Models From Natural Language Supervision. Image source: https://arxiv.org/pdf/2103.00020.pdf
The key here is the second step, which is to project unimodal features from texts and images into a multimodal feature space through the projection layer. This means that we can map the semantics of images and texts into the same high-dimensional space. This semantic space is the bridge that CLIP has in store for text-image cross-modal search. Now we can encode a piece of descriptive text as a vector, find the vectors of images with similar semantics, and then find the original image we want through these image vectors!
On the whole, it’s the same, classical formula: vector space plus semantic similarity. The importance of CLIP is that it helps us to make a high-dimensional space that unifies the semantics of texts and images, where the closer the semantics of texts and images, the smaller the distance between the corresponding vectors.
Basic components of a text-to-image service
A typical text-to-image service contains three parts: request side (texts), search algorithm (the “to”), and underlying databases (images).
The databases contain original images, their vectors, and the inference model that encode the original images into semantic vectors. Correspondingly, the request side mainly involve the inference model that encode texts into semantic vectors.
The “to” part is the process that connects requests, the vector database, and the image database. A text from the request side is passed through a model for its vector that will then be compared in the vector database for the topK most similar image vectors. Results are returned once the program locates the original images that correspond to the vectors.
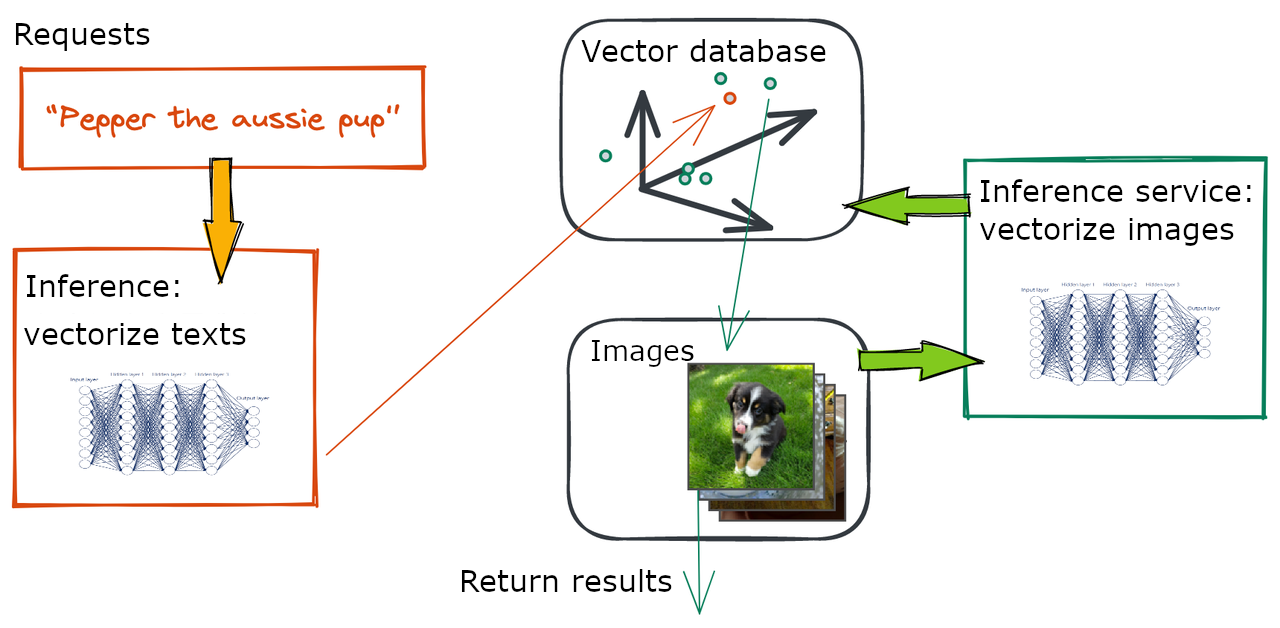 Figure 5 Basic Components of a Text-to-Image Service
Figure 5 Basic Components of a Text-to-Image Service
Conclusion
You now know the fundamentals of text-to-image search and CLIP! In the next article, we will practice what we have learned here by building a prototype text-to-image service, in just five minutes!
If you like this article, why not take a look at our project? We appreciate stars, forks, or even just a little click from you. Feel free to hit us with your questions on Slack, too!
About the series
“From Text to Image” is a series of blogs that introduce how to use CLIP to construct a large-scale text-to-image service, including:
- Understanding search algorithms, CLIP, and text-to-image;
- Building a text-to-image demo in 5 minutes;
- Advanced Topic 1: Deploy a vector database for large-scale vector recall
- Advanced Topic 2: Deploy an inference service that allows you to process over 1000 QPS of inference requests
- Advanced Topic 3: Vector data compression

Keep Reading

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.