




Evaluating Multimodal RAG Systems Using Trulens
As multimodal architectures become more prominent in Generative AI (GenAI), organizations increasingly build solutions using multimodal models such as GPT-4V and Gemini Pro Vision. These models offer a key advantage: they can semantically embed and interpret various data types—text, images, and more—making them more versatile and effective than traditional large language models (LLMs) across a broader range of applications.
However, as interest in multimodal models grows, so do the challenges of ensuring their reliability and accuracy. Like LLMs, multimodal models are prone to "hallucinations," where they produce incorrect or irrelevant outputs—particularly when tasked with processing different types of input data simultaneously. Multimodal Retrieval Augmented Generation (RAG) addresses these limitations by enriching models with relevant contextual information from external sources.
At an Unstructured Data Meetup hosted by Zilliz, Josh Reini, Developer Advocate at TruEra (now acquired by Snowflake), shared insights into the challenges and solutions of working with multimodal frameworks. Josh emphasized how we could mitigate AI hallucinations using open-source tools like Trulens and how integrating the Milvus vector database can enhance the performance of multimodal RAG systems.
 Josh Reini speaking at the November SF Unstructured Data Meetup
Josh Reini speaking at the November SF Unstructured Data Meetup
In this blog, we’ll recap Josh’s insights and discuss the critical role evaluations (or "Evals") play in improving multimodal RAG systems, ensuring these systems deliver accurate and relevant results when handling complex data. You can also catch Josh’s full talk on YouTube for more insights.
Understanding Multimodal Models and MultiModal RAG
Multimodal models are machine learning models that can process and integrate multiple types of data or modalities, such as text, images, audio, and video. Unlike traditional language models focusing on a single input type, multimodal models combine information from various sources to create more contextually accurate outputs. This versatility makes them particularly useful in scenarios where data comes from different formats. For example, a multimodal model might use an image and a text description to generate a more precise response than a model relying on just one input type.
Like LLMs, multimodal models are optimized for generalization, allowing them to respond to various inputs. However, this optimization comes at a cost. Models are often penalized for memorizing specific data, creating a tension between being flexible and accurate. This balancing act becomes tricky when the task involves cross-referencing multiple modalities, such as diagnosing an illness based on text-based symptoms and X-ray images.
To provide these general-purpose models with long-term memories, we can offload specific "memorized" knowledge to external resources, like a vector store (e.g., Milvus). This technique is known as Multimodal RAG.
Traditional RAG systems focus on retrieving relevant text to enhance the generative process of LLMs, producing more accurate and personalized responses. Multimodal RAG expands beyond text by integrating additional data types—images, audio, videos, and more—into the retrieval and generation process using multimodal models and vector databases. This approach allows Multimodal RAG systems to perform more effectively in tasks requiring a deeper understanding of textual and non-textual inputs.
For example, Multimodal RAG can retrieve relevant images or videos in visual question-answering systems to generate more precise answers. Similarly, in tasks like image captioning or multimodal dialogue systems, the ability to combine visual and textual data ensures that the system provides more contextually relevant and accurate outputs.
By leveraging the complementary strengths of multimodal models and advanced retrieval mechanisms, Multimodal RAG offers a powerful solution for handling complex, multi-format data and generating rich, context-aware responses across a wide range of applications.
How Does Multimodal RAG Work?
Now that we've introduced the concept of Multimodal RAG, let's explore how these systems operate. We'll use a retrieval-augmented visual question-answering system as an example to illustrate the process:
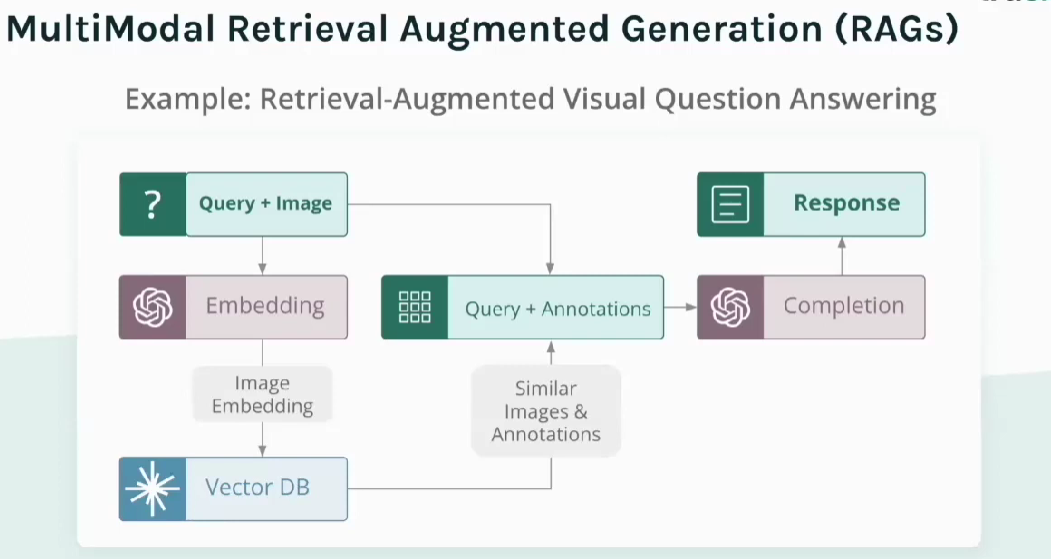 Figure- How a multimodal RAG system works
Figure- How a multimodal RAG system works
Multimodal Input Processing: The RAG system receives a user query alongside an image.
Embedding: Both the image and the text query are transformed into vector embeddings using a multimodal embedding model. These embeddings allow the system to analyze and compare the input across different modalities (text and image), making it capable of understanding the relationships between the two.
Vector Database Retrieval: The system uses image embeddings to query a vector database, such as Milvus or its managed version, Zilliz Cloud, to retrieve similar images and their associated annotations or relevant data. This retrieval step enriches the model's knowledge by providing additional context from real-world data.
Completion: The retrieved data (similar images and their annotations) are combined with the original input query. The multimodal model uses this enriched context to generate a comprehensive response or completion that leverages both the original input and the retrieved information.
Response: Finally, the system generates an accurate response integrating the retrieved external data with the original input. This allows the model to produce a more context-aware, relevant, and precise answer to the user's query.
By incorporating external data through retrieval, Multimodal RAG systems go beyond what the model knows internally, ensuring more accurate and contextually relevant outputs.
The Need for Systematic Evaluations
Despite the powerful combination of multimodal models and retrieval systems, challenges remain. While impressive demos can showcase the potential of Multimodal RAG, turning a demo into a robust, production-ready application is much more difficult.
The key to overcoming these challenges is systematic evaluation. These evaluations help identify weaknesses, failure modes, and areas for improvement in multimodal applications, enabling developers to refine and optimize them over time. In the AI field, we often see two types of teams:
Teams that build exciting prototypes that work around 80% of the time.
Teams that successfully deploy these systems in production, which is a much more complex and demanding task.
For the second group—those focused on production—systematic iteration and evaluation are essential, particularly in fields such as education (LLM-based tutors), customer support (summarizing transcripts), and financial services (internal or customer-facing chatbots), where reliability and accuracy are critical.
This is where evaluation tools, often called Evals, become indispensable. Evaluation tools enable developers to monitor performance, test reliability, and identify areas for improvement as they iterate toward a production-grade solution. Popular evaluation tools include Trulens, Ragas, LangFuse, OpenAI Evals, DeepEval, Phoenix, and LangSmith.
In the following sections, we’ll use TruLens, an open-source evaluation tool, as a case study to demonstrate how systematic evaluations can be applied to multimodal RAG systems.
How TruLens Helps with Multimodal RAG Evaluation
Trulens is an open-source tool for evaluating large language models (LLMs) and multimodal RAG applications. Its strength lies in its ability to monitor, test, and debug applications, making it especially useful for identifying areas for improvement and ensuring app reliability.
Once developers connect their app to TruLens, they can log records and define evaluation functions that systematically assess the model's performance. These evaluations are crucial for detecting hallucinations, which can lead to inaccurate or irrelevant responses, especially in complex multimodal RAG systems.
In a typical RAG system, three core components need evaluation:
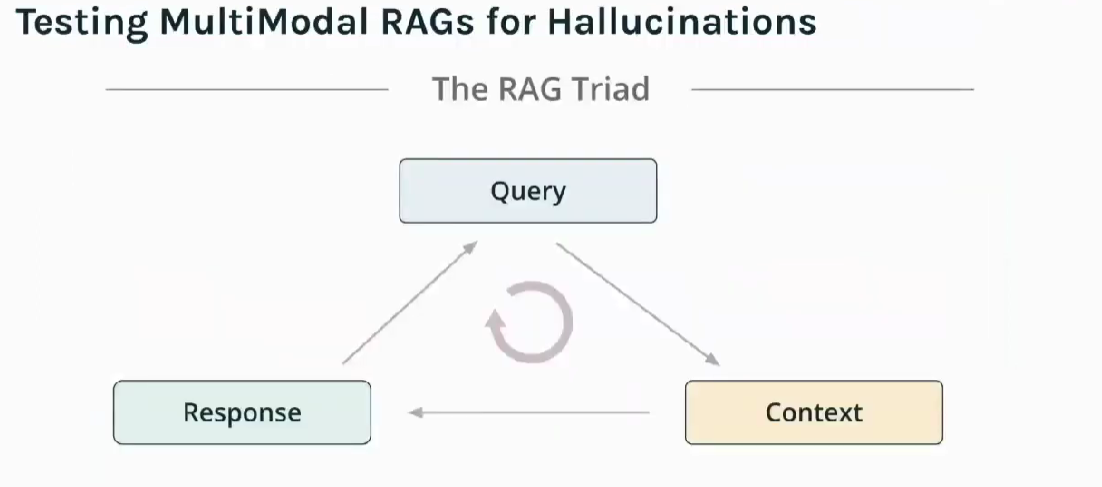 Figure- Three Pillars of RAG (RAG Triad)
Figure- Three Pillars of RAG (RAG Triad)
Query: The user sends a query, which could be in the form of text or combined text and images.
Context: The system retrieves relevant information, such as images and text, from a vector database to provide context for the model.
Response: The LLM or multimodal model generates an answer based on the retrieved context and the original query.
To ensure the model remains accurate and reliable, evaluations are performed at each step to detect hallucinations and assess how well the system is working. This is often called the RAG Triad, as shown in the accompanying diagram.
There are three critical types of evaluations to ensure the system’s output is trustworthy:
Context Relevance: This checks how closely the retrieved information (text or images) aligns with the original query. Is the context retrieved relevant and useful to the query at hand?
Groundedness: Groundedness evaluates whether the retrieved context supports the generated response. Does the response rely on retrieved information, or is it generating unsupported or incorrect data?
Answer Relevance: This measures the usefulness and accuracy of the model’s response. Is the answer meaningful and relevant to the user's question?
By integrating TruLens, developers can continuously track and improve the performance of their multimodal RAG systems, ensuring that the model remains accurate, grounded in evidence, and contextually relevant while minimizing hallucinations.
For a step-by-step guide on how to implement and evaluate RAG using Trulens, read this tutorial: Evaluations for Retrieval Augmented Generation: TruLens + Milvus.
Real-World Example: Evaluating a Visual Question-Answering RAG System
To better understand this, let’s consider an example of a visual question-answering RAG system. In this system, the user provides both a query and an image. The model generates an embedding from the image and searches a vector database for similar images, which are then paired with annotations to generate the final response.
At each step, we must evaluate whether the retrieved images are relevant to the original query, whether the LLM’s response is grounded in the context provided, and whether the final answer is relevant to the original question. If the system retrieves irrelevant images or generates incorrect diagnoses, the evaluations will help us pinpoint the failure mode and improve the model.
One team, X-ray Insight, built an app during a hackathon that illustrates these evaluations in action. They scraped X-ray images and annotations (diagnoses), transformed the images into image embeddings, loaded these embeddings along with metadata (the diagnoses) into the Milvus/Zilliz vector database, and used a user-supplied image (which has also been transformed into embeddings) to retrieve similar cases. The metadata (e.g., diagnoses) associated with these images was used to generate a final diagnosis through a multimodal model.
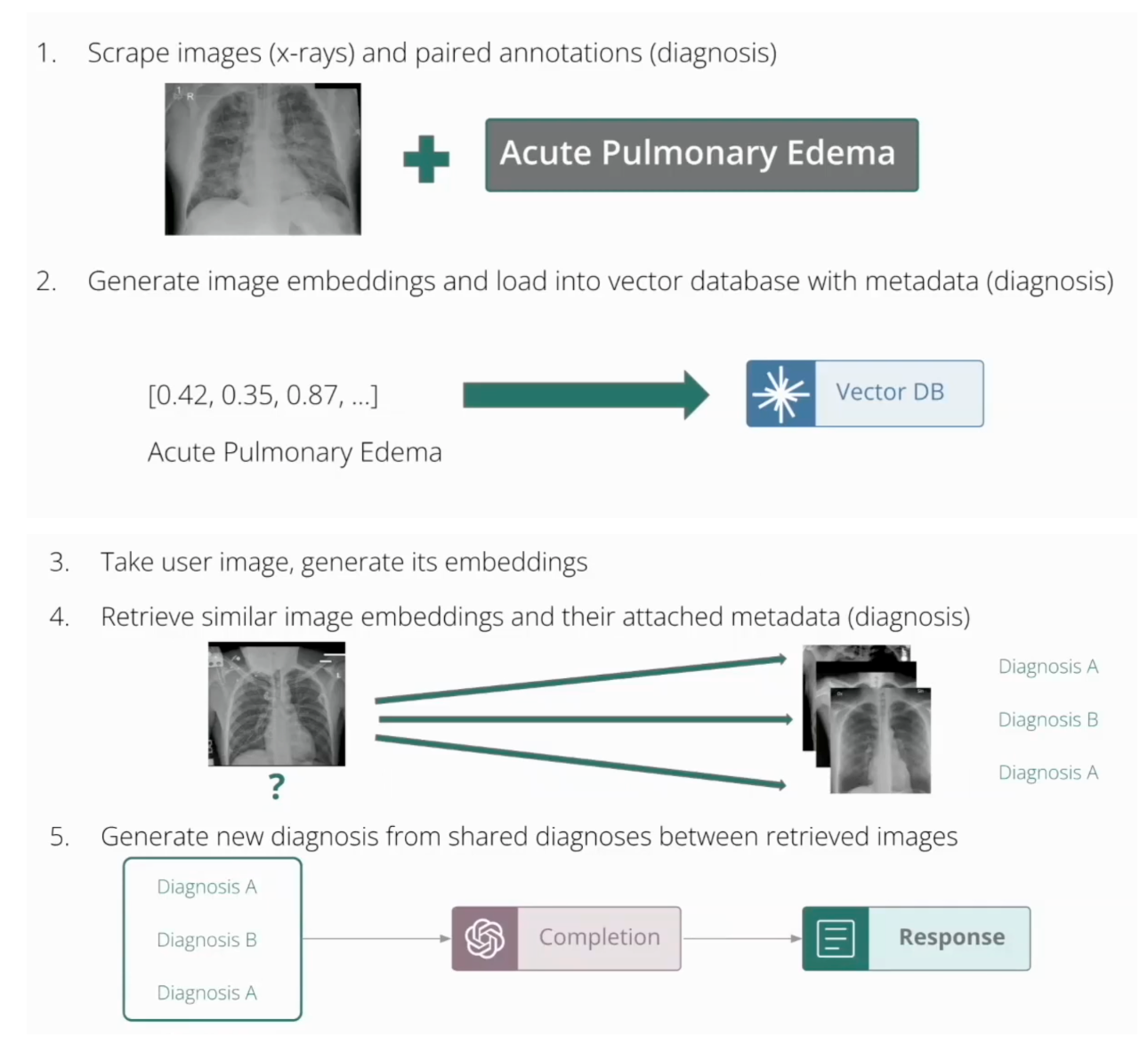 Figure: How X-ray Insight system works
Figure: How X-ray Insight system works
Using TruLens, the X-ray Insight team was able to assess the performance of their model at multiple stages:
Embedding Generation: Pre-processing the image, computing the embedding (a time-intensive process), and ensuring the embedding quality.
Case Retrieval: Searching for relevant cases in the vector database based on the computed embeddings.
Final Diagnosis: Generating a diagnosis from patient notes and comparing it against the retrieved data.
Once these evaluations are in place, TruLens enables the team to analyze shared features across diagnoses, identify failure modes, and improve based on the insights gained.
Conclusion
In summary, deploying multimodal models and RAG systems in production requires more than building a cool prototype. Systematic iteration through evaluations like context relevance, groundedness, and answer relevance is essential to ensure these models are reliable and accurate. Tools like TruLens provide a framework for tracking, testing, and debugging these apps, helping developers refine their models and avoid hallucinations.
As we continue to push the boundaries of what multimodal models can do, evaluations will remain a cornerstone in the development process. They will ensure that these models generate output in a grounded and relevant way.
Further Resources

Keep Reading

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.