




Data Mining: From Raw Data to Valuable Insights

Data Mining: From Raw Data to Valuable Insights
What is Data Mining?
Data mining is a technique to discover patterns, trends, and valuable insights from large amounts of data. It helps businesses and researchers make better decisions by uncovering hidden connections that aren’t obvious at first glance. By using techniques like classification, clustering, and association rule mining, data mining turns raw data into valuable insights. Whether predicting customer behavior, detecting fraud, or improving search results, data mining plays a key role in shaping modern technology.
How Data Mining Works?
Data mining analyzes large datasets to find hidden patterns, relationships, and trends that can be used for decision-making. It utilizes statistical methods, machine learning algorithms, and database management techniques to process raw data into actionable insights. The process follows a series of steps to clean, organize, and extract useful information from data. To understand this better, consider an e-commerce platform that wants to predict which customers will likely purchase based on their browsing behavior.
Steps in the Data Mining Process
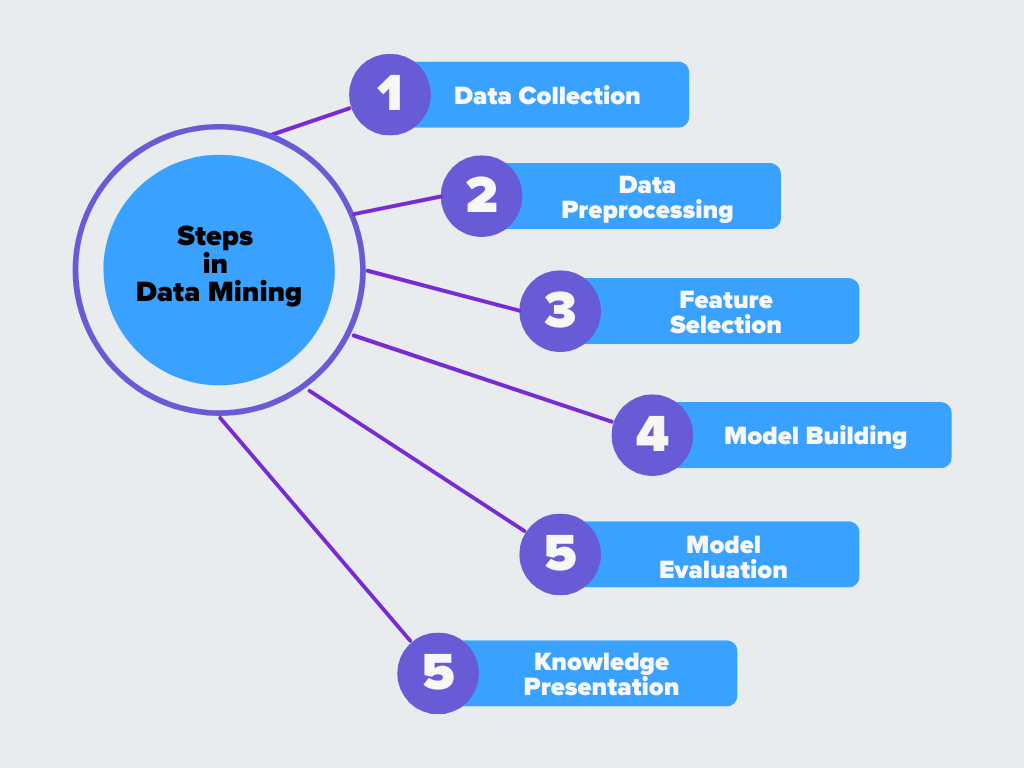 Figure- Steps in Data Mining
Figure- Steps in Data Mining
Figure: Steps in Data Mining
1. Data Collection
The first step is to gather data from different sources, such as databases, spreadsheets, IoT devices, or cloud storage. Since data often comes in various formats and structures, it must be integrated into a single system. This step also handles duplicate records and merges datasets to create a unified view.
For Example, An e-commerce platform collects data from website logs, user accounts, and purchase history to build a complete view of customer behavior.
2. Data Preprocessing
Raw data is rarely perfect. It may contain missing values, inconsistencies, or errors that can impact the accuracy of results. Data preprocessing involves cleaning the data by removing duplicates, filling in missing values, and correcting errors. Preprocessing techniques like normalization and transformation help structure the data so it’s ready for analysis.
For Example, Some customers may have incomplete profiles, missing purchase history, or duplicate records that need cleaning before analysis.
3. Feature Selection
Not all data points are useful for mining. In feature selection, the data is transformed into a more suitable format, and essential features are selected while irrelevant ones are removed. Feature engineering creates new variables based on existing data, which is also part of this step to improve model performance.
For Example, Features like time spent on product pages, past purchases, and cart abandonment rate might be selected, while less useful data like IP addresses may be removed.
4. Model Building
Once the data is cleaned and prepared, algorithms are applied to find patterns and relationships. Techniques like clustering, classification, and association rule mining help identify meaningful insights. Machine learning models may be trained at this stage to recognize trends, classify data, or make predictions based on historical patterns.
For Example, The platform might use a classification model to predict whether a user will likely make a purchase based on their browsing behavior and past purchases.
5. Model Evaluation
Not all patterns discovered during mining are helpful. This step validates the results to ensure they are accurate and meaningful. Analysts compare findings with known data, use performance metrics like accuracy and recall, and refine the models if needed. The goal is to confirm that the patterns found are reliable and applicable to real-world scenarios.
For Example, The platform tests the prediction model by comparing its results with actual purchases to check its accuracy.
6. Knowledge Presentation
The final step is presenting the insights clearly and understandably. This might include visual reports, dashboards, or summaries that decision-makers can use. The extracted knowledge is then applied to improve processes, make business decisions, or enhance AI-driven systems.
For Example, The e-commerce platform uses this knowledge to create personalized product recommendations, targeted ads, and promotional offers to increase sales.
Techniques and Algorithms in Data Mining
Data mining techniques are divided into categories based on how they analyze data and extract meaningful patterns. These techniques include supervised learning, unsupervised learning, semi-supervised learning, and anomaly detection. Each approach is suited for different types of problems, ranging from classification and prediction to uncovering hidden structures in data.
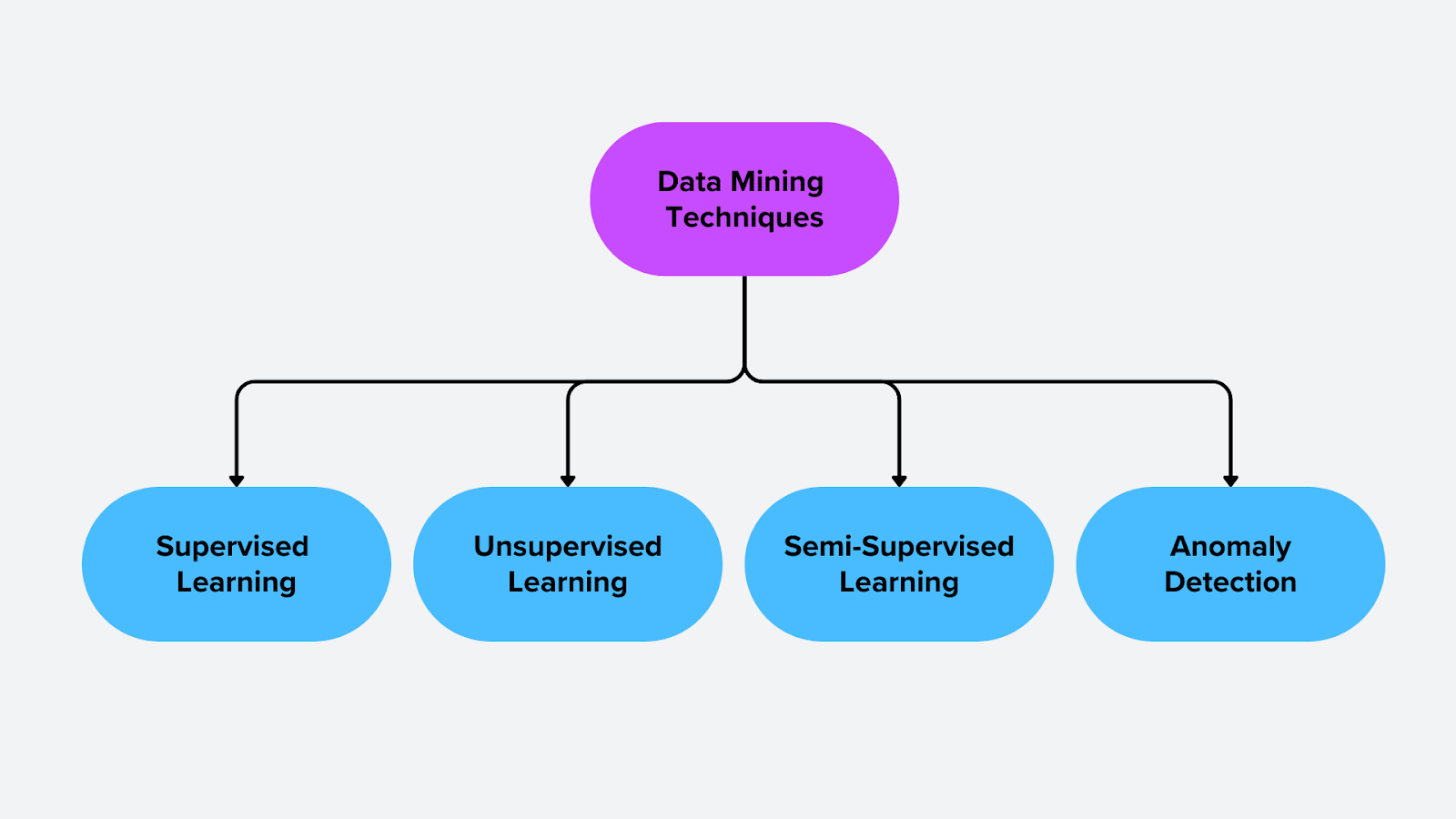 Figure- Techniques in Data Mining
Figure- Techniques in Data Mining
Figure: Techniques in Data Mining
1. Supervised Learning
Supervised learning trains a model on labeled data, where each input has a corresponding known output. The model learns from these examples to predict outcomes for new, unseen data. This approach is commonly used in classification, regression, and time series forecasting tasks.
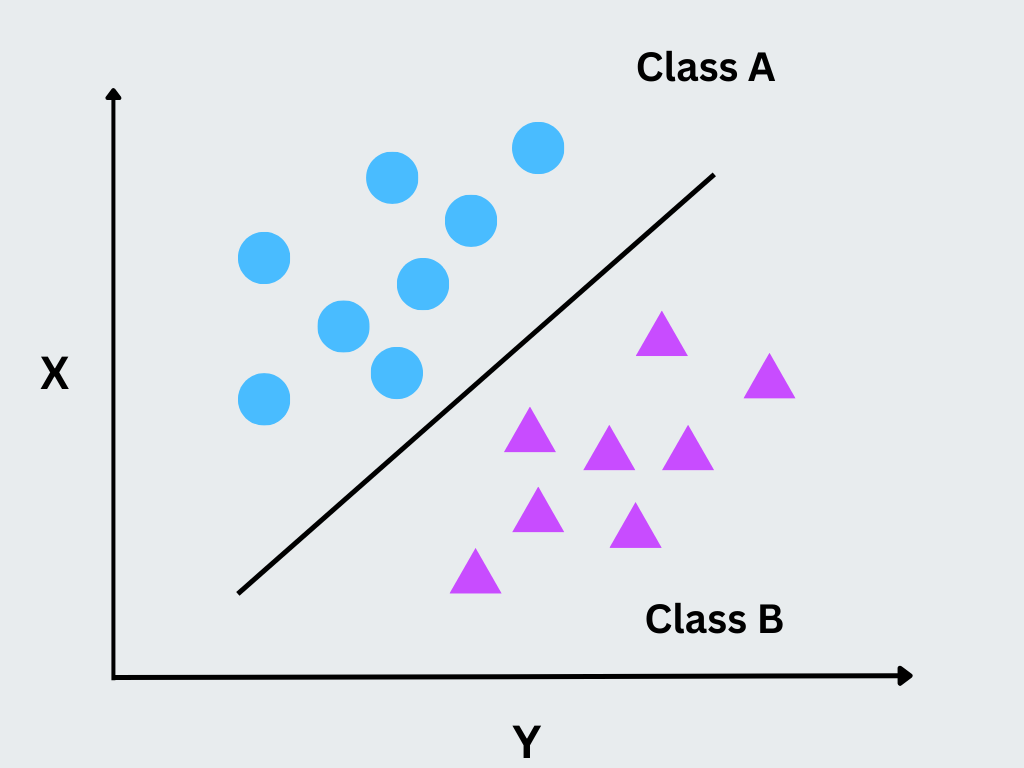 Figure- Supervised machine learning techniques
Figure- Supervised machine learning techniques
Figure: Supervised machine learning techniques
Decision Trees: A rule-based model that splits data into smaller subsets based on feature values, forming a tree-like structure for decision-making.
Random Forests: An ensemble of multiple decision trees that improves accuracy and reduces overfitting by averaging predictions from multiple models.
Gradient Boosted Trees (GBTs): A sequential decision tree approach that corrects previous errors in each iteration, leading to higher predictive performance.
Support Vector Machines (SVMs): A classification algorithm that finds the optimal boundary (hyperplane) to separate different categories of data.
K-Nearest Neighbors (K-NN): A distance-based algorithm that classifies new data points based on the majority class of their closest neighbors.
Neural Networks: Multi-layered models inspired by the human brain that learn complex relationships between input and output data.
Support Vector Regression (SVR): A variation of SVM used to predict continuous values instead of categorical labels.
2. Unsupervised Learning
Unsupervised learning analyzes data without labeled outputs, identifying hidden structures and relationships within a dataset. It is commonly used for clustering, anomaly detection, and dimensionality reduction.
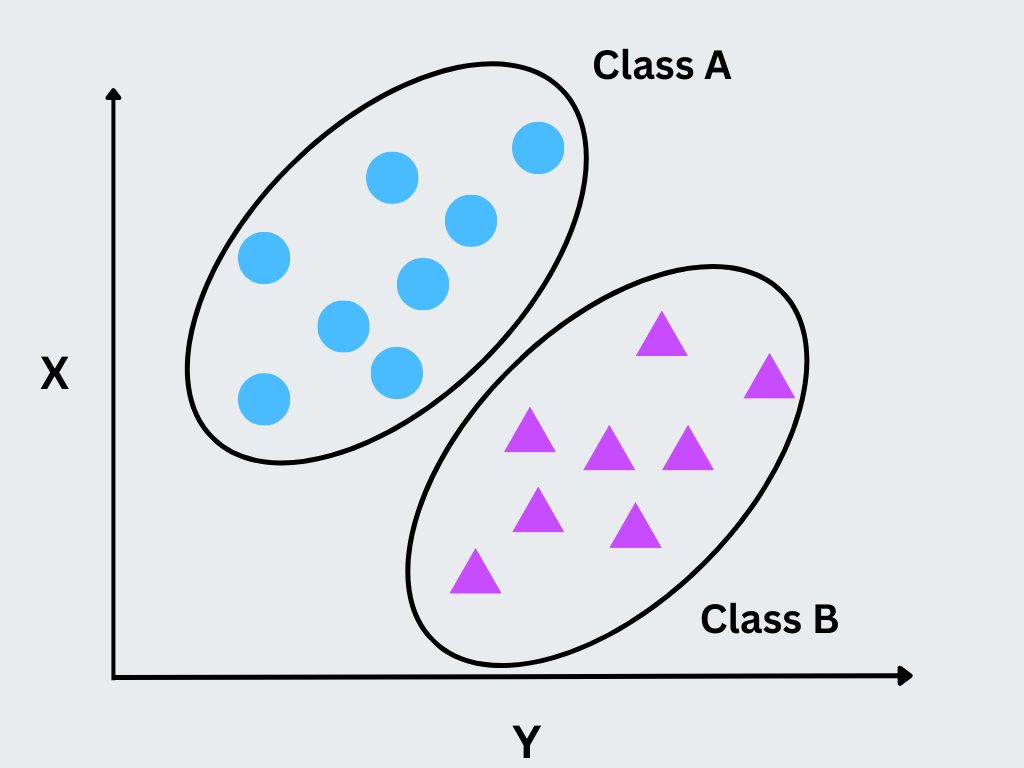 Figure- Unsupervised Machine Learning Techniques
Figure- Unsupervised Machine Learning Techniques
Figure: Unsupervised Machine Learning Techniques
K-Means Clustering: A partitioning algorithm that divides data into K clusters by assigning each point to the nearest cluster center.
Hierarchical Clustering: Builds a hierarchy of clusters through either bottom-up (agglomerative) or top-down (divisive) methods.
DBSCAN (Density-Based Spatial Clustering): Groups densely packed data points while treating outliers as noise, making it useful for irregular data distributions.
Principal Component Analysis (PCA): A dimensionality reduction technique that transforms data into a lower-dimensional space while preserving variance.
Autoencoders: A type of neural network that learns compressed representations of data for anomaly detection and feature extraction.
Association Rule Mining: Identifies relationships between items in a dataset, commonly used in market basket analysis.
Apriori Algorithm: A frequent pattern mining technique that finds relationships among items by iteratively identifying frequent itemsets.
FP-Growth Algorithm: A more efficient alternative to Apriori that uses a tree structure (FP-tree) to extract frequent patterns with reduced computation.
3. Semi-Supervised Learning
Semi-supervised learning is a hybrid approach that combines a small amount of labeled data with a large amount of unlabeled data to improve learning accuracy. This technique is useful when labeling data is expensive or time-consuming.
 Figure- Semi-supervised learning.png
Figure- Semi-supervised learning.png
Figure: Semi-supervised learning
Self-Training: A model is initially trained on labeled data, then makes predictions on unlabeled data, adding high-confidence predictions to the labeled dataset for further training.
Graph-Based Semi-Supervised Learning: It uses graph structures to propagate labels through a network of related data points, which is commonly used in recommendation systems.
Generative Adversarial Networks (GANs): GANs generate new labeled samples to improve learning in low-label scenarios, making them useful in image and speech recognition.
Consistency Regularization: Ensures that a model’s predictions remain consistent even when slight variations are introduced to the input, improving robustness in semi-supervised learning.
4. Anomaly Detection & Outlier Analysis
Anomaly detection identifies data points that significantly deviate from normal patterns. These algorithms are commonly used in fraud detection, cybersecurity, and industrial fault detection.
 Figure- Anomaly detection
Figure- Anomaly detection
Figure: Anomaly detection
Z-Score Method: Detects outliers by measuring how many standard deviations a point is from the mean.
Interquartile Range (IQR): Identifies outliers by analyzing the range between the first and third quartiles, flagging extreme values.
Isolation Forest: A tree-based model that isolates anomalies faster by randomly partitioning data points.
Local Outlier Factor (LOF): Measures the relative density of data points to identify anomalies in a dataset.
One-Class SVM: A variation of SVM designed to detect deviations from the majority class, commonly used for fraud detection.
Autoencoder-Based Anomaly Detection: Uses deep learning to reconstruct input data, flagging anomalies when reconstruction error is high.
Applications of Data Mining Across Industries
Data mining is used across various industries to analyze large datasets, uncover patterns, and improve decision-making. Below are some industry-specific use cases:
1. Finance
Fraud Detection: Banks use data mining to analyze transaction patterns and detect suspicious activities, such as unusual spending behaviors or multiple failed login attempts.
Credit Scoring & Risk Assessment: Financial institutions assess a borrower’s risk level by analyzing credit history, income patterns, and previous loan repayments.
Algorithmic Trading: Investment firms use predictive analytics to analyze market trends and automate high-frequency trading strategies.
2. Healthcare
Disease Prediction & Diagnosis: Hospitals analyze patient records and symptoms to predict diseases early, improving treatment plans and reducing hospitalizations.
Drug Discovery & Development: Pharmaceutical companies use data mining to identify potential drug candidates by analyzing genetic and clinical trial data.
Patient Readmission Prediction: Healthcare providers analyze patient history to predict the likelihood of readmission and take preventive measures.
3. E-commerce & Retail
Personalized Recommendations: Online retailers analyze customer browsing and purchase history to offer tailored product recommendations.
Dynamic Pricing Strategies: E-commerce platforms adjust prices based on demand, competitor pricing, and customer behavior.
Churn Prediction: Retailers use data mining to identify customers at risk of leaving and target them with special offers to improve retention.
4. Cybersecurity
Intrusion Detection Systems (IDS): Organizations use data mining to detect unusual network activity, such as unauthorized access attempts or malware infections.
Threat Intelligence & Risk Assessment: Security teams analyze historical attack data to predict and prevent future cyber threats.
Phishing & Fraud Detection: Machine learning models identify phishing attempts by analyzing email patterns, URLs, and sender behaviors.
5. Manufacturing & Industrial IoT
Predictive Maintenance: Factories analyze machine sensor data to predict failures before they occur, reducing downtime and repair costs.
Supply Chain Optimization: Manufacturers use data mining to predict demand fluctuations, optimize inventory, and reduce waste.
Quality Control & Defect Detection: Data analysis helps identify production defects early by detecting anomalies in manufacturing processes.
6. Telecommunications
Network Optimization: Telecom companies analyze usage patterns to optimize bandwidth allocation and reduce congestion.
Customer Segmentation & Retention: Operators classify customers based on usage behavior and offer customized plans to improve retention.
Spam & Robocall Detection: Data mining techniques help filter spam calls and messages based on call patterns and user reports.
7. Energy & Utilities
Power Consumption Forecasting: Energy companies analyze past consumption patterns to predict future demand and optimize grid performance.
Fault Detection in Power Grids: Sensors monitor power lines and detect anomalies to prevent outages and improve maintenance.
Smart Meter Analytics: Utility providers use data mining to detect unusual energy usage patterns and identify potential energy theft.
8. Education
Student Performance Prediction: Schools analyze student data to identify at-risk students and provide personalized learning support.
Adaptive Learning Systems: Educational platforms use data mining to personalize learning materials based on student strengths and weaknesses.
Course Recommendation Systems: Universities analyze student performance to recommend suitable courses based on interests and career goals.
Advantages of Data Mining
Uncovers Hidden Patterns: Helps businesses and researchers discover insights not immediately obvious in raw data.
Enhances Decision-Making: Provides data-driven insights that improve strategic planning and forecasting accuracy.
Automated Trend Analysis: This tool identifies trends and shifts in consumer behavior, market conditions, and financial patterns without manual intervention.
Boosts Customer Personalization: Enables highly targeted marketing by analyzing customer preferences and past interactions.
Optimizes Business Operations: Improves supply chain efficiency, reduces waste, and enhances productivity by predicting demand and resource needs.
Improves Healthcare Diagnostics: Assists in early disease detection and personalized treatment plans by analyzing patient data.
Speeds up Scientific Research: Accelerating drug discovery, genetic analysis, and climate modeling by quickly analyzing vast datasets.
How Milvus Helps in Data Mining?
Data mining often requires analyzing vast amounts of structured and unstructured data to discover meaningful patterns. Traditional relational databases struggle with high-dimensional and unstructured data, making them inefficient for modern applications like recommendation systems, anomaly detection, and semantic search. Milvus, an open-source vector database developed by Zilliz ****engineers, is specifically designed to handle large-scale, high-dimensional data, making it a powerful tool for data mining tasks.
1. Handling High-Dimensional Data
Modern data mining applications rely on high-dimensional data, such as image embeddings, text representations, and time-series data, to extract meaningful insights. Traditional relational databases are inefficient at handling these types of data, as they are designed for structured tables rather than multi-dimensional vector representations.
Milvus provides a dedicated vector database to store and manage high-dimensional embeddings, which makes it a core infrastructure component for AI-driven data mining.
It supports various data formats, including dense and sparse vectors, to ensure flexibility for different machine learning and deep learning models.
Optimized vector indexing structures (such as IVF, HNSW, and PQ) enhance storage efficiency, reducing redundancy and improving query performance in large datasets.
Batch processing and parallelization capabilities provide fast insertion and retrieval of millions of vectors for AI applications that require continuous updates.
For Example, A video analytics company stores frame-by-frame embeddings in Milvus, allowing efficient content-based search and retrieval for automated video tagging and classification.
2. Scalability for Big Data Mining Applications
Big data mining requires databases that can scale with increasing volumes of information. Milvus provides:
Cloud-native architecture for large-scale deployments across distributed environments.
Efficient resource utilization for cost-effective query performance even on massive datasets.
It is easy to integrate with AI-based data mining pipelines because it is integrated with machine learning frameworks such as TensorFlow, PyTorch, and Hugging Face.
For example, In genomics, Milvus stores and searches DNA sequence embeddings to help researchers find genetic similarities across millions of records quickly.
3. Efficient Semantic and Similarity Search
Semantic and similarity searches are essential for modern data mining applications that involve unstructured data, such as images, text, and multimedia. Unlike traditional keyword-based searches, similarity search relies on vector embeddings to retrieve the most relevant results based on meaning rather than exact matches.
Milvus enables high-performance similarity search by leveraging vector embeddings. It allows users to find results based on context rather than exact words.
It supports Approximate Nearest Neighbor (ANN) search algorithms, such as HNSW, IVF, and PQ, to accelerate retrieval in large-scale datasets.
Multi-modal search capabilities allow cross-domain search across text, images, and videos, making it ideal for recommendation systems, content retrieval, and NLP applications.
For Example, A legal document search system can use Milvus to retrieve case laws based on semantic meaning rather than just keyword matches, improving accuracy in legal research.
Conclusion
Data mining is a transformative process that turns vast datasets into actionable insights, driving innovation across finance and healthcare industries. Organizations can uncover hidden patterns, optimize operations, and make data-driven decisions by leveraging advanced techniques like supervised and unsupervised learning, anomaly detection, and frequent pattern mining. Milvus enhances these capabilities by providing a robust platform for storing and retrieving high-dimensional data, powering efficient semantic and similarity searches. Its ability to scale seamlessly with big data applications makes it an invaluable tool for modern data mining needs.
FAQs on Data Mining
1. What are the main techniques used in data mining?
Data mining uses various techniques, including supervised learning (decision trees, SVMs, neural networks), unsupervised learning (clustering, association rule mining), anomaly detection, and frequent pattern mining (Apriori, FP-Growth). Each technique helps extract meaningful insights from large datasets.
2. How is data mining different from traditional data analysis?
Traditional data analysis relies on predefined queries and human interpretation, whereas data mining uses automated algorithms to uncover hidden patterns, trends, and relationships in data. Data mining is also more scalable, making it suitable for handling big data and AI applications.
3. What are the biggest challenges in data mining?
Some key challenges in data mining include handling noisy and incomplete data, data privacy and security concerns, managing computational complexity, and scaling to massive datasets. Effective preprocessing and the use of advanced AI models help mitigate these issues.
4. How is data mining used in real-world applications?
Data mining is widely used for fraud detection in banking, recommendation systems in e-commerce, predictive maintenance in manufacturing, disease diagnosis in healthcare, and cybersecurity threat detection. It helps organizations optimize decision-making and automate processes.
5. What role do vector databases play in data mining?
Vector databases, like Milvus, help store and retrieve high-dimensional data efficiently, making similarity search, clustering, and anomaly detection faster. These databases are beneficial for AI-driven applications like image recognition, natural language processing, and recommendation systems.
Related Resources
- What is Data Mining?
- How Data Mining Works?
- Techniques and Algorithms in Data Mining
- Applications of Data Mining Across Industries
- Advantages of Data Mining
- How Milvus Helps in Data Mining?
- Conclusion
- FAQs on Data Mining
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free