




Infrastructure Challenges in Scaling RAG with Custom AI Models
Retrieval Augmented Generation (RAG) systems have significantly enhanced AI applications by providing more accurate and contextually relevant responses. However, scaling and deploying these systems in production have presented considerable challenges as they become more sophisticated and incorporate custom AI models.
During a recent Unstructured Data Meetup hosted by Zilliz, Chaoyu Yang, the Founder and CEO of BentoML, shared his insights on the infrastructure hurdles when scaling RAG systems with custom AI models and highlighted how tools like BentoML could simplify the deployment and management of these components. This post will recap Chaoyu Yang’s key points and explore advanced inference patterns and optimization techniques. These strategies will help you build RAG systems that are not only powerful but also efficient and cost-effective.
Watch the replay of Chaoyu’s talk on Youtube
How RAG Empowers AI Applications
Retrieval Augmented Generation (RAG) systems have emerged to tackle the issue of hallucinations in GenAI applications. By integrating the vector similarity retrieval capabilities of vector databases such as Milvus and Zilliz Cloud with the generative power of large language models (LLMs), RAG systems enable AI models to produce responses that are:
More accurate
Contextually relevant
Incredibly informative
Without hallucinations
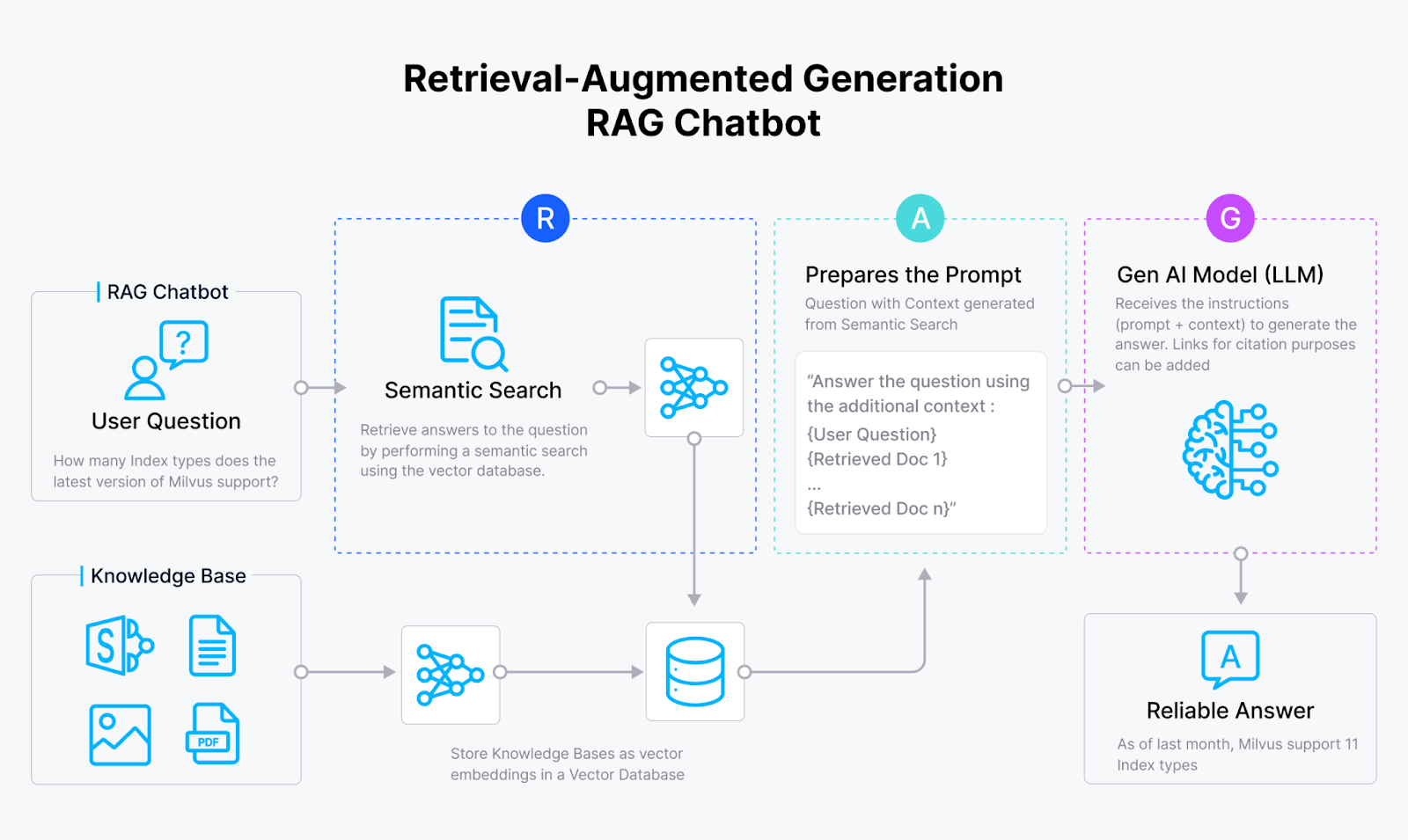
How a RAG Chatbot works
These systems have the potential to transform a wide range of domains, including:
Question-answering
Document summarization
Personalized content generation
And more.
RAG systems achieve this goal by tapping into the vast knowledge hidden in external sources, like some AI librarian!
Challenges in Deploying RAG Systems in Production
RAG systems have their own challenges to overcome before they can save the day in production environments. One of the biggest hurdles is ensuring top-notch retrieval performance, which involves:
Optimizing recall: Making sure all the relevant information is retrieved
Optimizing precision: Minimizing the amount of irrelevant information
To make matters more interesting, RAG systems often have to deal with complex, unstructured data sources. Imagine making sense of a PDF with more layouts, tables, and images than a comic book! This problem calls for some seriously sophisticated document processing and understanding techniques.
Another challenge that RAG systems face is generating responses that are accurate, contextually appropriate, and aligned with the user's intent. It's like writing a coherent story using only snippets from different books!
Plus, ensuring the safety and trustworthiness of the generated content is also crucial, especially when the stakes are high. We don't want our AI systems going rogue and spreading misinformation!
Custom AI models are the trusty sidekick in this story. By fine-tuning and adapting AI models to specific domains and datasets, developers can give their RAG systems the superpowers they need to tackle these challenges head-on.
Leveraging Custom AI Models for Higher RAG Performance
To unlock the full potential of RAG systems, it's crucial to leverage custom AI models tailored to our specific use case. By fine-tuning and optimizing these models, we can significantly boost their performance. Let's explore some key areas where custom AI models can make a significant impact.
Text Embedding Models: The Foundation of RAG Success
Default text embedding models, like "text-embedding-ada-002," often fall short in capturing the nuances of our specific domain. This model is ranked 57th on the MTEB leaderboard, indicating significant room for improvement.
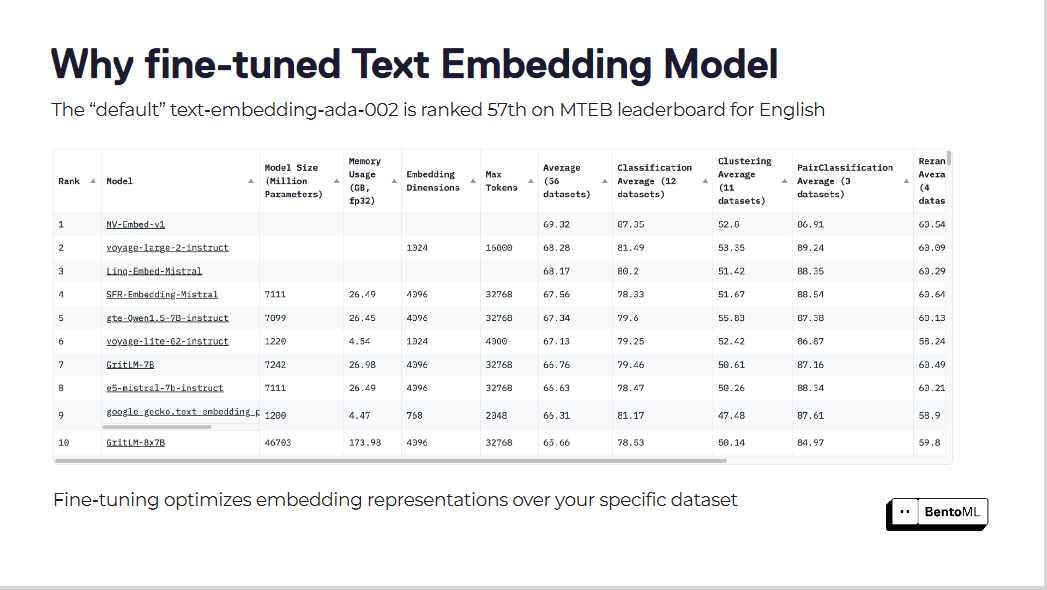
Fine-tuning optimizes embedding representations over your specific dataset
Fine-tuning these embedding models can lead to remarkable improvements in retrieval scores. By optimizing embedding models for their specific datasets, RAG systems have seen substantial gains in performance.
Hosting Our LLMs: Taking Control
Proprietary LLMs offer convenience but may not always meet our needs or constraints. Open-source LLMs allow us to customize and adapt the models to our requirements. When hosting our LLMs, we should consider the following key factors:
Security and data privacy
Latency and performance
Specific capabilities needed
Cost and scalability
Maintenance and support
Document Processing and Understanding: Extracting Insights from Unstructured Data
RAG systems often need to process and understand complex, unstructured documents like PDFs, images, etc. Integrating various models and techniques can help extract valuable insights. For example, we can conduct:
Layout analysis with LayoutLM
Table detection with Table Transformers TATR
OCR with EasyOCR or Tesseract
Visual document QA with LayoutLM v3 or Donut
Fine-tuning these models for your specific document types can greatly enhance their performance.
Advanced Techniques for Improved Retrieval Accuracy
To further improve retrieval accuracy, we can consider implementing the following techniques:
Context-aware chunking and global concept-aware chunking: These methods help identify the most relevant information for retrieval by considering the context and overarching concepts within the documents.
Metadata extraction: Extracting metadata from documents can provide additional context for enhanced retrieval and response synthesis.
Reranker models: Fine-tuning re-ranker models on custom datasets can lead to 10-30% better performance than generic models.
By leveraging custom AI models across these key areas, we can significantly enhance the performance of our RAG system.
However, deploying and serving these models efficiently brings its own set of challenges. In the next section, we'll discuss some infrastructure challenges in scaling RAG with Custom Models.
Infrastructure Challenges in Scaling RAG with Custom Models
As RAG systems become more complex and incorporate multiple custom models, the demands on computational resources and the need for efficient deployment and management increase significantly. Scaling Retrieval Augmented Generation (RAG) systems with custom AI models becomes an urgent requirement but comes with a unique set of infrastructure challenges.
Efficient Serving of Custom Model Inference APIs
One of the primary challenges is the efficient serving of custom model inference APIs. RAG systems often require the integration of multiple models, such as:
Text embedding models
Large language models (LLMs)
Document processing models
Each model may have different computational requirements and performance characteristics. Deploying these models as inference APIs that can handle real-time requests and scale with demand is complex.
To address this challenge, it's essential to have a robust and scalable infrastructure for serving model inference APIs. This infrastructure should be able to handle each model's specific requirements, such as GPU allocation, memory management, and latency constraints. Containerization technologies like Docker can help encapsulate model dependencies and provide a consistent runtime environment across different systems.
Efficient Scaling Mechanisms
However, simply containerizing models is not enough. The infrastructure must also support efficient scaling mechanisms to handle varying workloads. This requirement includes automatically scaling the number of model instances based on incoming request traffic, ensuring optimal resource utilization, and minimizing response times.
Optimization of Model Serving
Another critical challenge is optimizing model serving for performance and cost-efficiency. Custom AI models, especially large language models, can be computationally expensive. Naive deployment strategies can lead to sub-optimal resource utilization and increased costs. Techniques like dynamic batching, where multiple requests are grouped to leverage the parallelism of GPUs, can significantly improve throughput and reduce response times.
In addition to dynamic batching, other optimization techniques, such as quantization, pruning, and model distillation, can be applied to reduce the memory footprint and computational requirements of custom models. However, implementing these optimizations requires careful consideration of the trade-offs between model performance and resource efficiency.
Efficient Resource Allocation and Auto-Scaling
Efficient resource allocation and auto-scaling are also critical aspects of scaling RAG systems with custom models. The infrastructure should be able to dynamically allocate resources based on each model's workload requirements. This approach involves monitoring key metrics such as GPU utilization, memory usage, and request latency to make informed scaling decisions. Auto-scaling mechanisms should be able to handle sudden spikes in traffic and scale resources accordingly to maintain optimal performance.
Composition and Orchestration of Multiple Models
Furthermore, the infrastructure must support the composition and orchestration of multiple models within a RAG system. RAG systems often involve complex pipelines where the output of one model serves as the input of another. The infrastructure should provide tools and frameworks for defining and managing these pipelines, ensuring seamless data flow and efficient execution.
Monitoring and Observability
Monitoring and observability are crucial for maintaining the health and performance of RAG systems with custom models. The infrastructure should provide comprehensive monitoring capabilities to track key metrics, logs, and traces across all system components. This enables quick detection and diagnosis of issues and optimizes and fine-tunes the system based on real-world performance data.
Continuous Integration and Deployment (CI/CD)
Finally, the infrastructure should support custom models' continuous integration and deployment (CI/CD). As models are updated and refined, a streamlined process for deploying new versions should be established without disrupting the overall system. This requires robust versioning, testing, and rollback mechanisms to ensure the stability and reliability of the RAG system.
Addressing these infrastructure challenges requires a combination of tools, frameworks, and best practices. In the next section, we'll explore how BentoML, a platform for serving and deploying machine learning models, can help tackle these challenges and simplify the scaling of RAG systems with custom AI models.
Building Inference APIs for Custom Models with BentoML
BentoML simplifies the process of building and deploying inference APIs for custom models in RAG systems. It provides a seamless transition from model development to production-ready APIs, enabling faster iteration and easier integration with existing systems. Let’s see how it can help us overcome the infrastructure challenges for scaling RAG.
From Inference Script to Serving Endpoint
With just a few lines of code, you can easily convert your inference script into a serving endpoint using BentoML. Let's take a look at an example of creating a BentoML service for a fine-tuned text embedding model:
import torch
from sentence_transformers import SentenceTransformer, models
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
sentences: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
This code snippet defines the SentenceTransformers class to encapsulate the embedding model and its associated methods. Inside the __init__` `` method, the SentenceTransformer`` model is initialized with a fine-tuned model and set to run on the "cuda" device. The ``` encode `` method takes a list of sentences as input and returns their embeddings as a NumPy array.
To turn this into a BentoML service, you can add the @bentoml.service` `` and @bentoml.api` `` decorators:
import bentoml
@bentoml.service
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
sentences: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
To serve the model, you can use the BentoML CLI:
bentoml serve .
This command starts the BentoML server and serves the model defined in the current directory. The CLI output shows that the service is listening on [http://localhost:3000](http://localhost:3000).
You can then make requests to the served model using the BentoML client:
import bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
result: np.NDArray = client.encode(
sentences=["sample input sentence"],
)
Serving Optimizations
BentoML provides several out-of-the-box service optimizations. One of the most powerful optimizations is dynamic batching. By adding the ``` batchable=True` `` parameter to your API definition, BentoML automatically batches incoming requests, optimizing GPU utilization and improving throughput for the model serving.
@bentoml.api(batchable=True)
def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
Dynamic batching intelligently forms small batches by grouping incoming requests, breaking down large batches, and auto-tuning the batch size. This optimization can bring up to a 3x faster response time and a ~200% improvement in throughput for embedding serving.
Deployment and Serving Infrastructure
BentoML offers a flexible and scalable deployment and infrastructure for serving. It supports various deployment options, including containerization with Docker and orchestration with Kubernetes. You can easily specify the resource requirements, such as the number and type of GPUs, and configure traffic settings like concurrency and external queues.
import bentoml
@bentoml.service(
resources={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
traffic={
"concurrency": 512,
"external_queue": True
}
)
class SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
BentoML's adaptive micro-batching and elastic scaling capabilities ensure optimal resource utilization and automatic scaling based on incoming traffic. It also provides a user-friendly deployment dashboard that offers insights into request rate, response time, and resource utilization. Next, let’s see how to scale LLM inference with BentoML.
Scaling LLM Inference Services with BentoML
BentoML provides comprehensive features and optimizations to help you scale your LLM inference services efficiently.
Autoscaling Strategies
Autoscaling ensures your LLM inference services can handle varying workloads and maintain optimal performance. However, traditional autoscaling metrics like GPU utilization and queries per second (QPS) may not accurately reflect the desired number of replicas for LLM services.
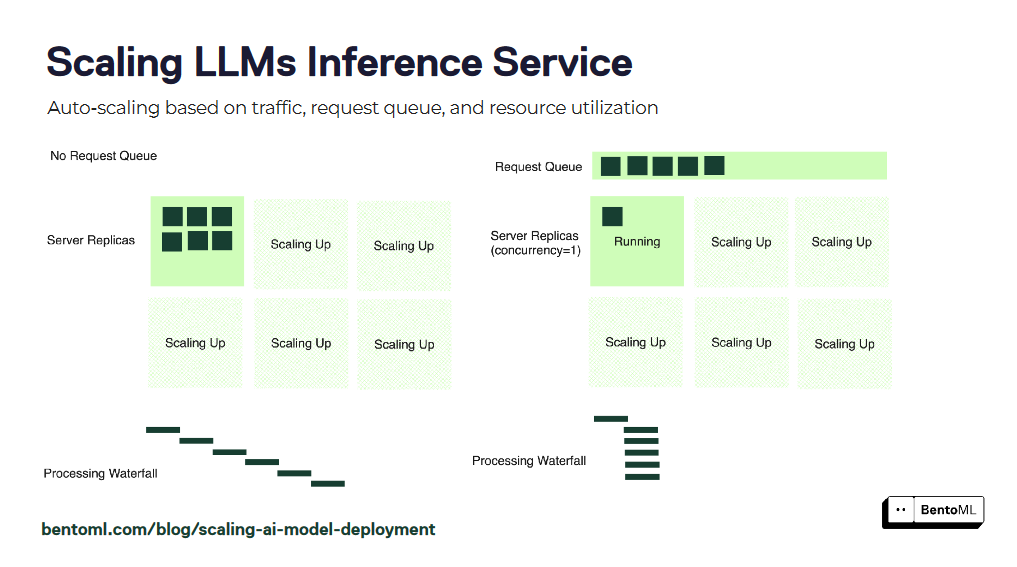
BentoML introduces concurrency-based autoscaling, a more effective approach for scaling LLM inference services. Concurrency-based autoscaling considers the number of concurrent requests that each model replica can handle, providing a more accurate representation of the service's capacity.
Cold Start Optimization
Cold starts can be a significant challenge when scaling LLM inference services, especially with large container images and model files. BentoML offers several optimization techniques to mitigate cold start latency.
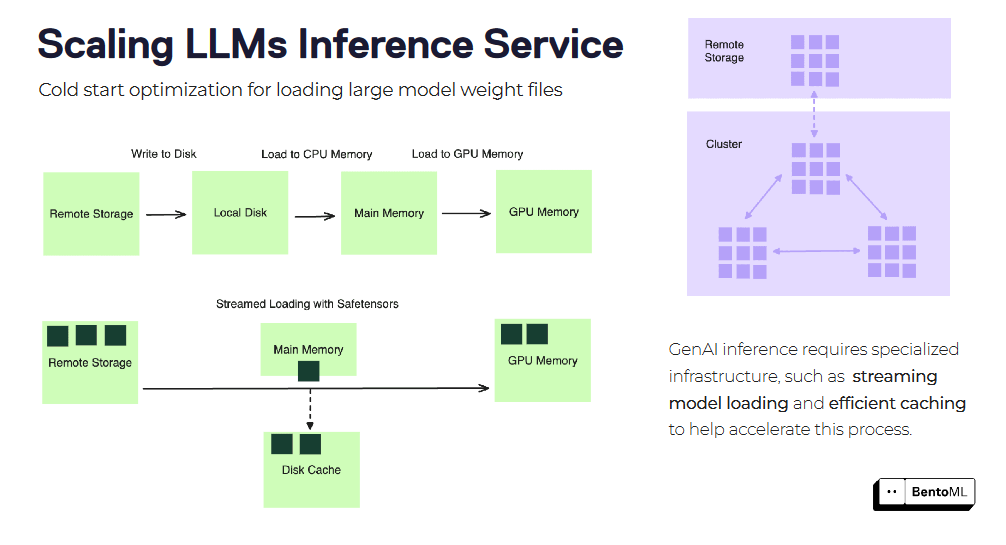
One such technique is stream-loading container images. Instead of downloading the entire container image before starting the service, BentoML can stream load the image, fetching only the necessary files on demand. This can significantly reduce the startup time of new replicas.
Another optimization is efficient model weight file loading and caching. BentoML can cache the loaded model weights across replicas, reducing the time required to load the model for each new request. This is particularly beneficial for large language models with extensive weight files.
By leveraging BentoML's autoscaling strategies and cold start optimizations, you can effectively scale your LLM inference services to handle the demands of your RAG system. BentoML abstracts away the complexities of infrastructure management, allowing you to focus on developing and iterating your models while ensuring optimal performance and scalability.
Advanced Inference Patterns for RAG Systems
RAG systems often require advanced inference patterns to handle complex workflows and optimize performance. BentoML provides a flexible and extensible framework to support these patterns, enabling the creation of sophisticated RAG systems with ease.
Document processing pipelines can be built by combining multiple models and processing steps, such as layout analysis, table extraction, and OCR.
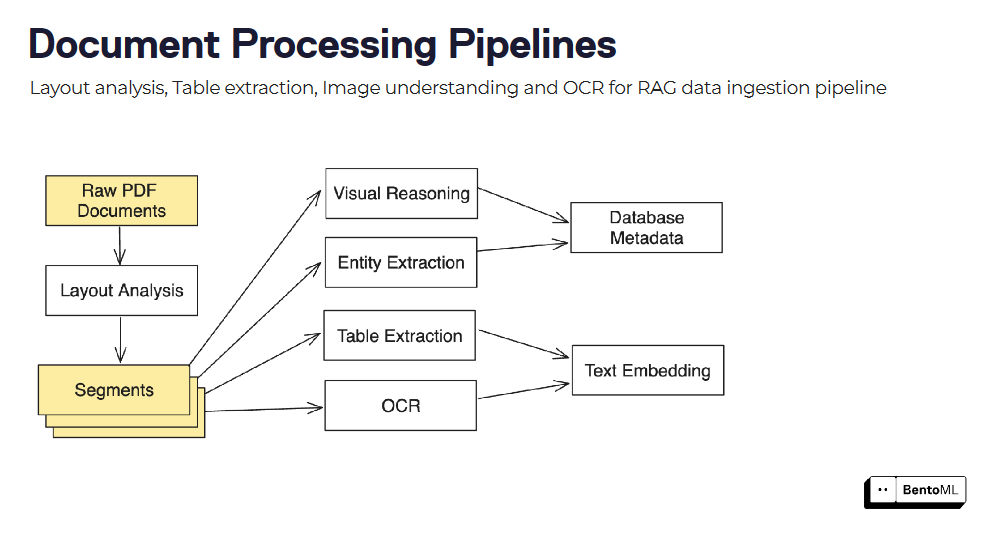
BentoML's asynchronous inference interface efficiently handles long-running tasks, while its batch inference support enables processing large datasets leveraging parallelism and optimizations.
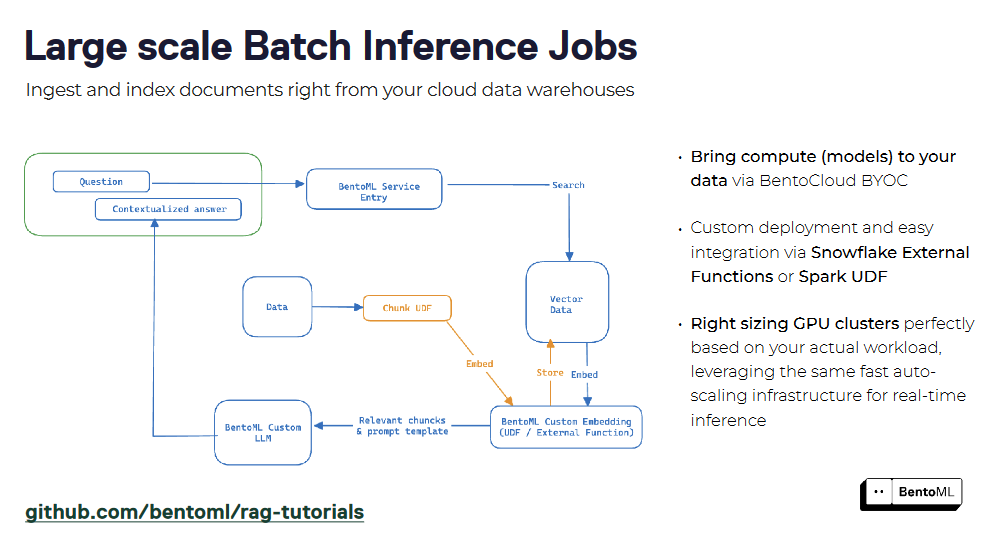
RAG systems can be packaged as a service using BentoML, creating a unified interface for querying and interaction. By encapsulating retriever and generator components, you can deploy a RAG service easily and integrate it with other applications. BentoML's support for containerization and orchestration simplifies the scaling and management of RAG services in production environments.
These advanced inference patterns showcase BentoML's flexibility and extensibility in building powerful and efficient RAG services that handle various tasks and workloads.
Apart from the infrastructure to serve LLMs, we also need a robust vector database to store our vector embeddings and perform a similarity search. This is where the Milvus vector database helps us. In the next section, we will look into building a simple RAG app using BentoML and Milvus.
Integrating BentoML and the Milvus Vector Database
Milvus is an open-source vector database designed for high-performance similarity search and is a pivotal infrastructure component for building Retrieval Augmented Generation (RAG).
Milvus has integrated with BentoML, making it easier to build scalable RAG applications. This section will walk you through building a RAG app with BentoML and the Milvus vector database. In this example, we’ll use Milvus Lite, the lightweight version of Milvus, for quick prototyping.
The dataset we use can be found here: City data.
Step 1: Set Up the Environment
First, install the necessary libraries as shown below:
# Install required libraries
pip install -U pymilvus bentoml
Step 2: Prepare Your Data
Let’s download and process the City data.
import os
import requests
import urllib.request
# Set up the data source
repo = "ytang07/bento_octo_milvus_RAG"
directory = "data"
save_dir = "./city_data"
api_url = f"https://api.github.com/repos/{repo}/contents/{directory}"
# Download files from GitHub
response = requests.get(api_url)
data = response.json()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for item in data:
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# Process the downloaded data
def chunk_text(filename):
with open(filename, "r") as f:
text = f.read()
sentences = text.split("\n")
return [s for s in sentences if len(s) > 7]
cities = os.listdir("city_data")
city_chunks = []
for city in cities:
chunked = chunk_text(f"city_data/{city}")
city_chunks.append({
"city_name": city.split(".")[0],
"chunks": chunked
})
Step 3: Setup BentoML Clients
Now we'll set up BentoML clients for both the embedding model and the LLM as shown below.
import bentoml
# Set up endpoints and API token
EMBEDDING_ENDPOINT = "YOUR_EMBEDDING_MODEL_ENDPOINT"
LLM_ENDPOINT = "YOUR_LLM_ENDPOINT"
API_TOKEN = "YOUR_API_TOKEN"
# Initialize BentoML clients
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
Replace the placeholder endpoints and token with your actual BentoML deployment endpoints and API token. These clients will allow us to generate embeddings and use the language model for text generation.
Step 4: Generate Embeddings
Before generating embeddings, let’s create an embedding function as shown below:
Create Embedding Function
def get_embeddings(texts):
# Handle large batches of texts
if len(texts) > 25:
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
embeddings = []
for split in splits:
embedding_split = embedding_client.encode(sentences=split)
embeddings += embedding_split
return embeddings
# Handle small batches directly
return embedding_client.encode(sentences=texts)
This function handles batching for large sets of texts, as the embedding model might have input size limitations.
Generate embeddings for all chunks.
entries = []
for city_dict in city_chunks:
# Get embeddings for each city's text chunks
embedding_list = get_embeddings(city_dict["chunks"])
# Create entries with embeddings and metadata
for i, embedding in enumerate(embedding_list):
entry = {
"embedding": embedding,
"sentence": city_dict["chunks"][i],
"city": city_dict["city_name"],
}
entries.append(entry)
Here, we're creating a list of entries, each containing the embedding, the original sentence, and the city name. This structure will be useful when you insert data into Milvus.
Step 5: Setup Milvus
Now we’ll initialize a vector database using Milvus to add the embeddings.
Initialize Milvus client and create schema
from pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # This should match your embedding model's output dimension
# Initialize Milvus client
milvus_client = MilvusClient("milvus_demo.db")
# Create schema
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
We’re using Milvus lite here, which is embedded in the application. The schema defines our data structure in Milvus, including an auto-generated ID and the embedding vector.
Prepare Index parameters and create a collection
# Prepare index parameters
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Create or recreate collection
if milvus_client.has_collection(collection_name=COLLECTION_NAME):
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
milvus_client.create_collection(
collection_name=COLLECTION_NAME, schema=schema, index_params=index_params
)
We're using AUTOINDEX, which automatically selects the best index type based on the data. Cosine similarity is used as the distance metric for vector comparisons.
Insert data into Milvus
Now, we’ll insert the data into Milvus as shown below
# Insert preprocessed data into Milvus
milvus_client.insert(collection_name=COLLECTION_NAME, data=entries)
This step inserts all our preprocessed data (embeddings and metadata) into the Milvus collection.
Step 6: Implement RAG
To implement RAG efficiently, we will create three functions to generate the RAG response, retrieve the relevant context from the collection, and generate the answer as shown below:
Create a function for the LLM to generate answers
def generate_rag_response(question, context):
# Prepare prompt for the LLM
prompt = (
f"You are a helpful assistant. Answer the user question based only on the context: {context}. \n"
f"The user question is {question}"
)
# Generate response using the LLM
results = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(results)
This function constructs a prompt using the retrieved context and the user's question and then uses the LLM to generate a response.
Create a function to retrieve relevant context
def retrieve_context(question):
# Generate embedding for the question
embeddings = get_embeddings([question])
# Search for similar vectors in Milvus
res = milvus_client.search(
collection_name=COLLECTION_NAME,
data=embeddings,
anns_field="embedding",
limit=5,
output_fields=["sentence"],
)
# Extract and combine relevant sentences
sentences = [hit["entity"]["sentence"] for hits in res for hit in hits]
return ". ".join(sentences)
This function embeds the user's question, searches for similar vectors in Milvus, and retrieves the corresponding text chunks for context.
Combine the above functions to create the RAG pipeline
def ask_question(question):
# Retrieve relevant context
context = retrieve_context(question)
# Generate answer based on context and question
return generate_rag_response(question, context)
This function ties everything together, creating our RAG pipeline.
Step 7: Use Your RAG System
Now we can use our RAG system to answer questions as shown below:
# Example usage
question = "What state is Cambridge in?"
answer = ask_question(question)
print(f"Question: {question}")
print(f"Answer: {answer}")
This example demonstrates how to use the RAG system to answer a specific question about a city.
Important Notes:
Before running this code, ensure your embedding and large language models are properly deployed on BentoML.
The dimension of your embeddings (384 in this example) should match your embedding model's output.
This setup uses Milvus Lite, which is suitable for smaller datasets. Consider using a full Milvus deployment on Docker or K8s for larger-scale applications.
The effectiveness of the RAG system depends on the quality and coverage of your initial city data. Ensure your dataset is comprehensive and accurate for the best results.
This integration of BentoML and Milvus creates a powerful RAG system capable of answering questions based on the provided city information. You can extend this system by adding more data or fine-tuning it for specific use cases.
Conclusion
Building and scaling Retrieval Augmented Generation (RAG) systems with custom AI models presents unique challenges. Developers can create highly performant and scalable RAG systems by leveraging the power of custom models, optimizing deployment and serving infrastructure, and adopting advanced inference patterns.
BentoML is a valuable tool in this journey. It simplifies the process of building and deploying inference APIs, optimizes serving performance, and enables seamless scaling.
By integrating BentoML with the Milvus vector database, organizations can build more powerful, scalable RAG systems. This combination enables efficient retrieval of relevant information and generation of context-aware responses, opening up possibilities for advanced AI applications across various domains and industries.
For further reading on BentoML and RAG, go through the following resources
RAG Without OpenAI: BentoML, OctoAI and Milvus - Zilliz blog
How to Enhance the Performance of Your RAG Pipeline - Zilliz blog
Mastering LLM Challenges: An Exploration of RAG - Zilliz blog
Ingesting Chaos: The MLOps Behind Handling Unstructured Data Reliably at Scale for RAG (milvus.io)
Why Milvus Makes Building RAG Easier, Faster, and More Cost-Efficient - Zilliz blog
Keep Reading

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.