




Enhancing Your RAG with Knowledge Graphs Using KnowHow
Retrieval Augmented Generation (RAG) is a popular technique that provides the LLM with additional knowledge and long-term memories through a vector database like Milvus and Zilliz Cloud (the fully managed Milvus). A basic RAG can address many LLM headaches but is insufficient if you have more advanced requirements like customization or greater control of the retrieved results.
At our recent Unstructured Data Meetup, Chris Rec, the co-founder of WhyHow, shared how he incorporates Knowledge Graphs (KG) into the RAG pipeline for better performance and accuracy. The blog will cover the key points of his talk, including an overview of Knowledge Graphs, RAG, and how to integrate knowledge graphs into RAG systems for better performance.
If you want to learn more about this topic, we recommend you watch the entire talk on YouTube.
An Overview of RAG and Its Challenges
RAG is a method that harnesses the strengths of both retrieval-based and generative artificial intelligence systems. A vanilla RAG usually comprises a vector database like Milvus, an embedding model, and a large language model (LLM).
A RAG system first uses the embedding model to transform documents into vector embeddings and store them in a vector database. Then, it retrieves relevant query information from this vector database and provides the retrieved results to the LLM. Finally, the LLM uses the retrieved information as context to generate more accurate outputs.
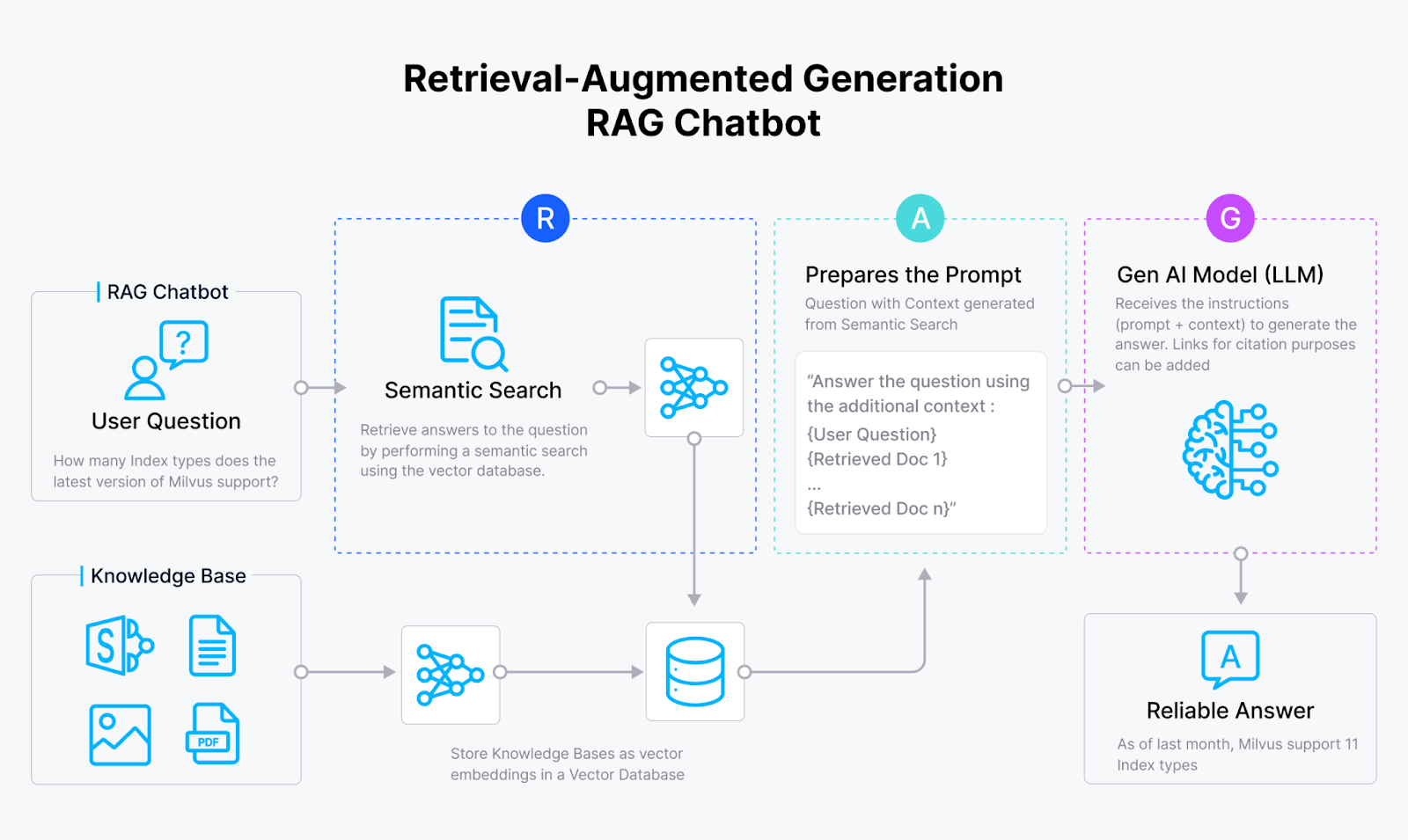 RAG workflow
RAG workflow
Fig 1: How RAG works
Although a vanilla RAG is wonderful at generating more up-to-date and accurate results, it still has several limitations.
First, LLMs may struggle to fully understand a question's specific context or domain, leading to incorrect or irrelevant answers. For instance, the term "vehicular capacity" could refer to either the number of passengers a car can hold or the number of cars that can fit on a road, creating ambiguity.
Second, it is challenging to handle various query types accurately. For example, responding to location-based queries like "I want to go to London" differs significantly from addressing more abstract wellness-related inquiries, such as "I'm stressed out at work and want to take a vacation."
Third, it is not easy to distinguish between similarity and relevance. For example, it can be difficult to differentiate between a "beach house" a mile from the shore and a "beachfront house" directly on the sand.
Fourth, the completeness of answers is also a concern. Retrieving all relevant information for comprehensive questions can be challenging, especially for complex queries, such as listing all limited partners (LPs) in a fund who have invested at least $10 million and have special data access rights.
Finally, multi-hop queries add another layer of complexity, as they require accurately combining multiple pieces of information. This approach requires breaking down a query into several sub-queries, each with specific conditions, ensuring the final response is accurate and complete.
While solutions such as prompt improvement, advanced chunking strategies, better embedding models, and reranking can address many of the challenges associated with RAG, WhyHow takes a different approach by incorporating knowledge graphs into the RAG pipeline.
What are Knowledge Graphs (KGs)?
A Knowledge Graph (KG) is a type of data structure that not only stores data but also links similar or dissimilar data based on their relationship. This approach leads to having a collection of things (which can be any type of data) linked in a way that can provide related or relevant information.
A Knowledge Graph consists of nodes, edges, and properties.
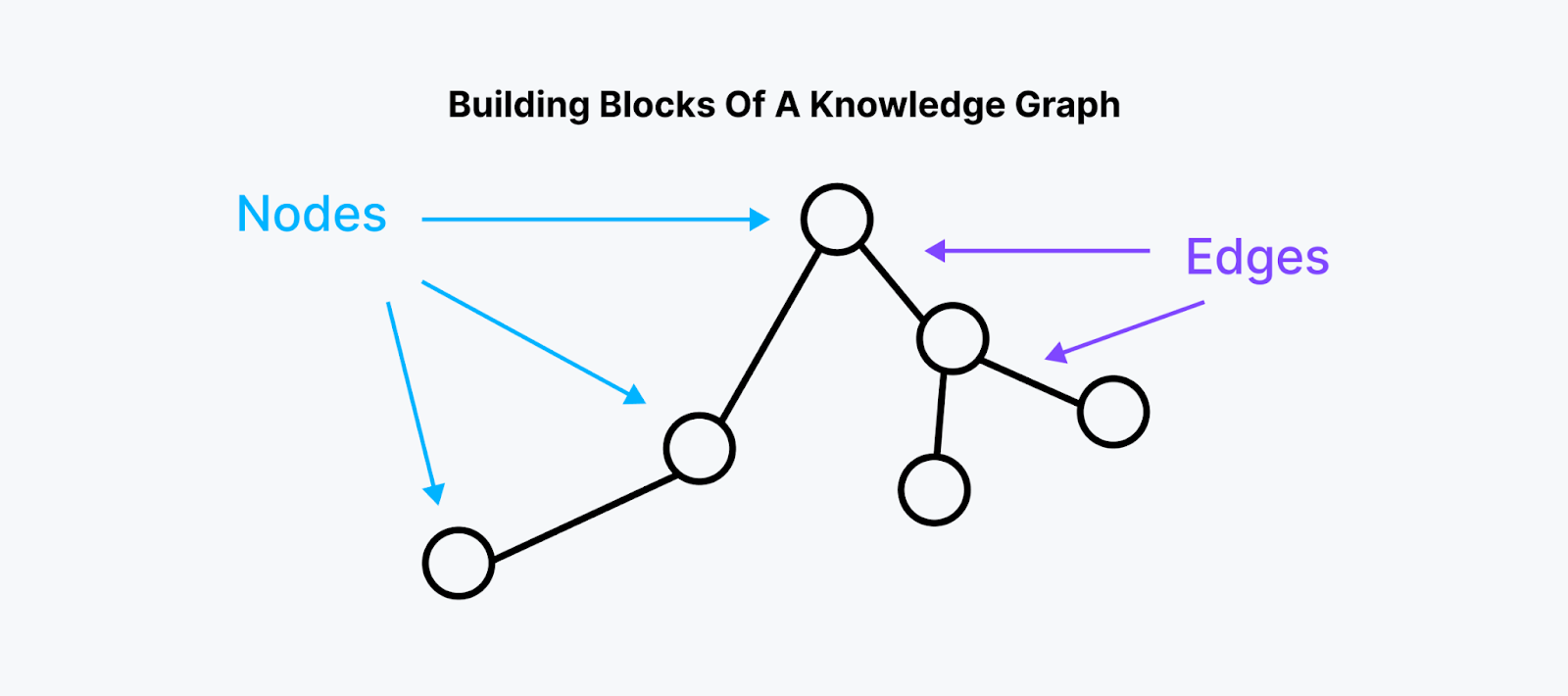 Fig 2- Building Blocks of a Knowledge Graph
Fig 2- Building Blocks of a Knowledge Graph
Fig 2: Building Blocks of a Knowledge Graph
Nodes:
Represent the entities or objects in the graph.
Store values of these entities can be any type of data.
Edges:
Represent the relationships between the entities.
Hold information about the nature of the relationship between the connected nodes.
Properties: Characteristics or features associated with individual entities.
Unlike traditional tabular databases, knowledge graphs use a graph structure for flexible representation of relationships and focus on semantic understanding. This approach enables complex queries and easier extraction of specific information.
Benefits of Integrating Knowledge Graphs into RAG Systems
By incorporating knowledge graphs into the RAG pipeline, we can significantly enhance the system's retrieval capabilities and answer quality, resulting in superior performance, accuracy, traceability, and completeness. Here are the key advantages of a knowledge graph-based RAG system:
Enhanced Contextual Understanding
Knowledge graphs provide a rich, interconnected representation of information, allowing the RAG system to grasp complex relationships between entities. This deeper contextual understanding leads to more nuanced and relevant responses.
Improved Accuracy and Factual Consistency
The structured nature of knowledge graphs helps maintain factual consistency across generated content. By anchoring responses to verified information within the graph, the system can reduce errors and hallucinations common in traditional language models.
Multi-hop Reasoning Capabilities
Knowledge graphs enable the RAG system to perform multi-hop reasoning, connecting disparate pieces of information through logical pathways. This capability allows for more sophisticated query answering and inference generation.
Efficient Information Retrieval
The graph structure facilitates rapid and precise information retrieval, even for complex queries. This efficiency translates to faster response times and more relevant content generation. Additionally, knowledge graph-based RAG systems allow for a hybrid retrieval approach, combining graph traversal with vector and keyword searches, capabilities provided by vector databases like Milvus and Zilliz Cloud.
To be more specific, this hybrid approach enables:
Precise entity and relationship matching through graph traversal
Semantic similarity matching using vector embeddings
Traditional keyword-based search for text-heavy content
This multi-faceted retrieval strategy enhances the system's ability to find the most relevant information across various data types and structures, leading to more comprehensive and accurate responses.
Transparent and Traceable Outputs
With knowledge graphs, the system can provide clear provenance for the information used in generating responses. This traceability enhances user trust and allows for easier fact-checking and verification.
Cross-domain Knowledge Synthesis
By representing diverse domains within a single graph structure, knowledge graph-based RAG systems can more easily synthesize information across different fields, leading to more comprehensive and interdisciplinary insights.
Improved Handling of Ambiguity
The relational structure of knowledge graphs helps disambiguate entities and concepts, reducing confusion in situations where terms or names might have multiple meanings or references.
By leveraging these benefits, RAG applications enhanced with knowledge graphs can provide more accurate, contextually relevant, and comprehensive responses to user queries.
What is WhyHow? How Does It Enhance RAG with Knowledge Graphs?
WhyHow is a platform for building and managing knowledge graphs to support complex data retrieval. Constructing comprehensive Knowledge Graphs is challenging and time-consuming. WhyHow solves this problem by creating small KGs and iterating over them multiple times until a satisfactory KG for a specific domain emerges. This approach helps make it highly domain-specific, simpler, and easy to work with, as KGs are complex.
WhyHow also provides developers the building blocks to organize, contextualize, and reliably retrieve unstructured data to perform complex RAG. By integrating WhyHow into your existing RAG pipelines powered by a vector database, you can make your RAG system with better structure, consistency, and control. The diagram below shows how a Knowledge Graph-enhanced RAG works.
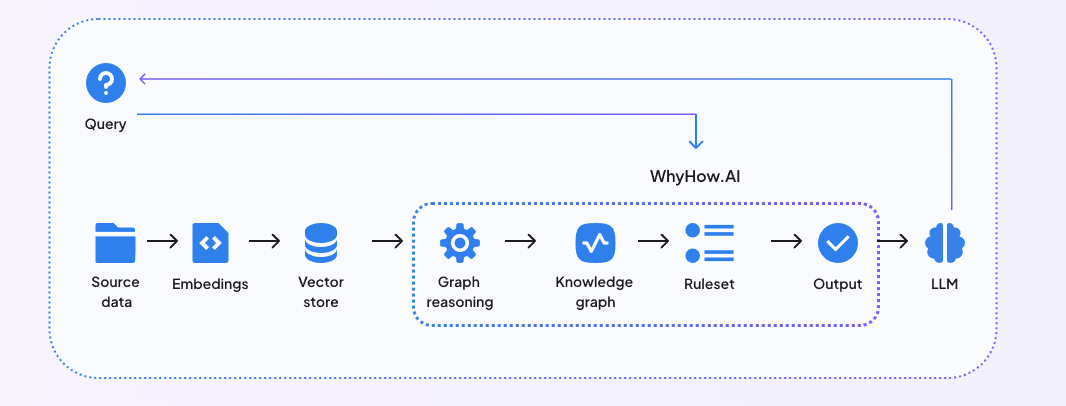 Fig 3- Integration of RAG with WhyHow
Fig 3- Integration of RAG with WhyHow
Fig 3: Integration of RAG with WhyHow
By incorporating WhyHow in your RAG workflow, you can take a hybrid graph and vector approach by leveraging the best of both knowledge graphs and vector search capabilities provided by vector databases.
For a more detailed guide on how to build a Knowledge Graph-enhanced RAG with WhyHow, we recommend you watch the live demo shared by Chris during the Unstructured Data Meetup hosted by Zilliz.
Having More Control over Your Retrieval Workflows Within RAG Using WhyHow and Zilliz Cloud
In addition to making RAG applications more performant and traceable, many developers also hope to have greater control over what their RAG retrieves. This is because RAG applications sometimes fail to consistently retrieve the correct data chunks when users send poorly phrased queries or when users need to include contextually relevant but semantically dissimilar data in responses.
To address such issues, WhyHow builds a Rule-based Retrieval Package by integrating with Zilliz Cloud. This Python package enables developers to build more accurate retrieval workflows with advanced filtering capabilities, giving them more control over the retrieval workflow within the RAG pipelines. This package integrates with OpenAI for text generation and Zilliz Cloud for storage and efficient vector similarity search with metadata filtering.
The rule-based retrieval solution performs these tasks:
Vector Store Creation: Creates a Milvus collection for storing chunk embeddings.
Splitting, Chunking, and Embedding: Automatically splits, chunks, and creates embeddings for uploaded documents using LangChain's PyPDFLoader and RecursiveCharacterTextSplitter, and supports OpenAI's text-embedding-3-small model.
Data Insertion: Uploads embeddings and metadata to Milvus or Zilliz Cloud.
Auto-filtering: Builds a metadata filter based on user-defined rules to refine queries against the vector store.
The workflow is as follows:
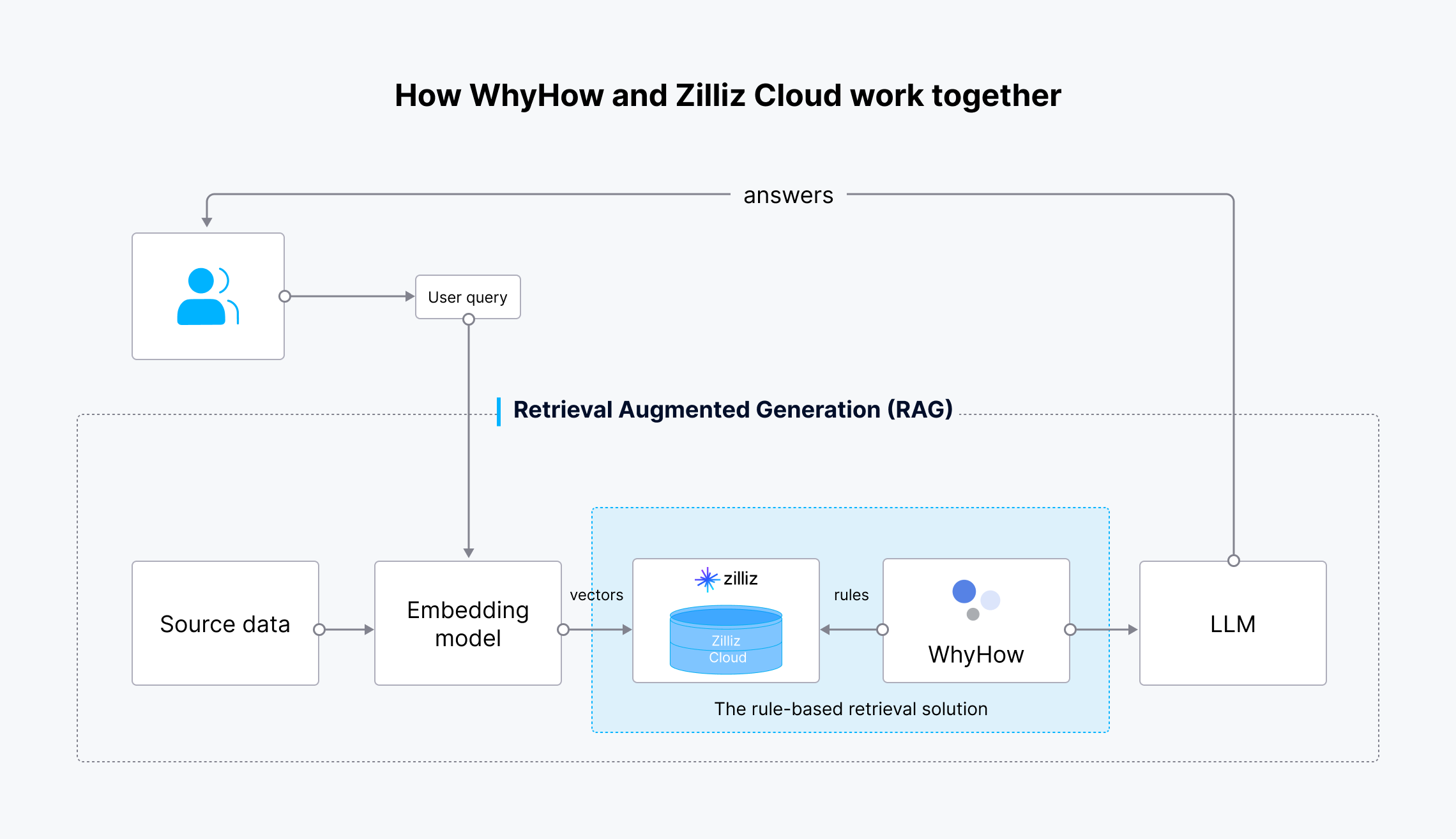 How WhyHow and Zilliz Cloud work together
How WhyHow and Zilliz Cloud work together
Fig 4: Workflow of the Rule-based Retrieval Solution
The source data is transformed into vector embeddings using OpenAI’s embedding model and ingested into Zilliz Cloud for storage and retrieval. When a user query is made, it is also transformed into vector embeddings and sent to Zilliz Cloud to search for the most relevant results. WhyHow sets rules and adds filters to the vector search. The retrieved results, along with the original user query, are then sent to the LLM, which generates more accurate results and sends them to the user.
Conclusion
LLM has truly eased our burden in finding answers to various problems. They are smart enough to understand the provided query but hallucinate, and it is hard to keep them up-to-date due to resource constraints. Hence, the retrieval augmented generation (RAG) technique empowers them by providing context to the query; however, RAG systems also have limitations, as discussed.
WhyHow identified those limitations, highlighting that the solution lies in incorporating Knowledge Graphs into RAG pipelines. By enhancing RAG with knowledge graphs, your RAG systems can retrieve more relevant and contextual information and generate more determinable answers with fewer hallucinations and high accuracy.
If you want to dive deeper into this topic, watch Chris’ presentation on YouTube.
Further Resources

Keep Reading

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.