




Introducing IBM Data Prep Kit for Streamlined LLM Workflows
Large Language Models (LLMs) have been widely adopted across healthcare, retail, and e-commerce industries, generating billions of dollars in overall revenue. A key ingredient behind the success of these LLMs is the data on which they are trained. The general intelligence of these models depends on the quantity, quality, and variety of the data used; therefore, ensuring efficient preprocessing becomes critical.
At a recent NYC Unstructured Data Meetup hosted by Zilliz, Santosh Borse, a Senior Engineer at IBM Research, talked about an open-source Data Prep Kit (DPK) they created to streamline the data preparation process for LLM workflows. He discussed the challenges faced with data quality, how they tackled them, and the pipeline for implementing the open-source DPK.
This blog will recap his key points and explore how DPK can be further integrated with Milvus for applications such as semantic search and Retrieval Augmented Generation (RAG).
Data Is the New Oil!
“Data is the new oil”—this statement can be aptly applied to LLM growth. Like oil drives the economy, data is the source of LLMs' success.
Here is a list of data sources many LLMs, such as OpenAI’s GPT models, have leveraged to extract data for LLM training.
Common Crawl: A massive data source containing petabytes of data, equivalent to nearly 250 billion web pages. It is also a superset for many other datasets available. This data serves as the foundational source for general-purpose language models.
Processed Datasets: C4, The Pile, Red Pajama, and Wikipedia offer high-quality, curated data tailored for specific tasks.
Domain-Specific Data: Domain-specific data can be utilized to address more targeted use cases. Some examples are BookCorpus for literary analysis, MathQA for mathematical problem solving, and StarCoder for coding-related tasks.
HuggingFace: It has more than 210K datasets, enabling customization for fine-tuning tasks.
Your Own Data: LLMs are usually trained using a combination of the company’s and open-source data.
Data Quality is the Key!
Ensuring data quality is the most important step for obtaining optimal LLM performance. Some of the key aspects that should be considered when processing your training data are:
Variety—Data should contain a variety of information and come from various sources to ensure that there is enough information to learn for model generalization.
Linguistic Pattern—Diverse linguistic patterns should be present in the data to make the LLMs more generalizable across languages and domains.
Overfitting vs. Underfitting—If news appears on over 100 pages on the Internet, then the model will be trained on all those pages, causing it to overfit on that particular data. In contrast, for other news, it would underfit. Hence, a balance needs to be maintained between both.
Bias—Biases in training data, such as gender or cultural stereotypes, can propagate harmful outputs in LLMs. Hence, bias mitigation is a crucial preprocessing step.
Personal Information—Personal information should be encoded or removed to protect the privacy and security of the individual.
Bad Data—Data that contains harmful content (abuse, profanity, or hate speech) should be removed to maintain the ethical and professional standards of the models’ outputs.
| Bad Data | Good Data |
|---|---|
| Duplicated | Unique & Distinct |
| Typos & Spelling Errors | Accurate & Error Free |
| Inconsistent | Consistent |
| Hallucinations | Validated |
| Toxic | Safe and Secure |
| … | … |
Table: Good Data vs Bad Data
If the data remains of poor quality, it will increase the computational cost and time required to train LLMs effectively.
Data Cleaning
Data cleaning is another essential step for LLM data preprocessing. It ensures that the training data is free from inconsistencies, inaccuracies, or irrelevant information. Below are some of the major steps for data cleaning.
 Figure- Data Cleaning Examples .png
Figure- Data Cleaning Examples .png
Figure: Data Cleaning Examples
Deduplication—Duplicate dataset entries can skew training results, leading to inefficient resource utilization and overfitting.
Quality Filters—Filters to remove inconsistent data (e.g., two languages in the same sentence), impute missing values, normalize formats, remove unwanted patterns or text, and purify the data further.
Content Filters—Toxic or biased data is filtered by replacing specific harmful words with moderated and ethical words that are more inclusive for everyone.
Privacy Reduction—Personally identifiable information (PII) is encoded with certain keywords to protect the privacy of the individuals' or organizations’ data.
Rule-based Cleansing—Certain rules are set to remove errors relating to typos, unnecessary punctuation marks, issues with formatting, etc.
Data Prep Kit and the Data Journey for IBM Granite Model
After talking about the major issues with data quality and handling them with data cleaning, Santosh Borse talked about the data processing journey for their very own IBM Granite model, shown below. He also mentions some interesting statistics on the volume of data (ultimately 2.5 trillion tokens for training) after some preprocessing steps, as mentioned below. Over 70% of the raw data is useless, which signifies that data preprocessing and cleaning are crucial steps.
The Data Prep Kit (DPK) is an open-source toolkit by IBM Research designed to streamline unstructured data preparation for developers building LLM-enabled applications. It is tailored for use cases like fine-tuning, instruction-tuning, and retrieval augmented generation (RAG), offering modular and scalable solutions to manage diverse data processing challenges. DPK has been beneficial and effective in producing pre-training datasets for the Granite open-source LLM models.
DPK Workflow
The Data Prep Kit (DPK) simplifies data preparation with reusable transforms (modules) designed for code and language data. It is also envisioned to expand its support to images, speech, and multimodal data. DPK provides high-level APIs that allow developers to quickly start processing their data without requiring deep knowledge of the underlying frameworks or runtimes.
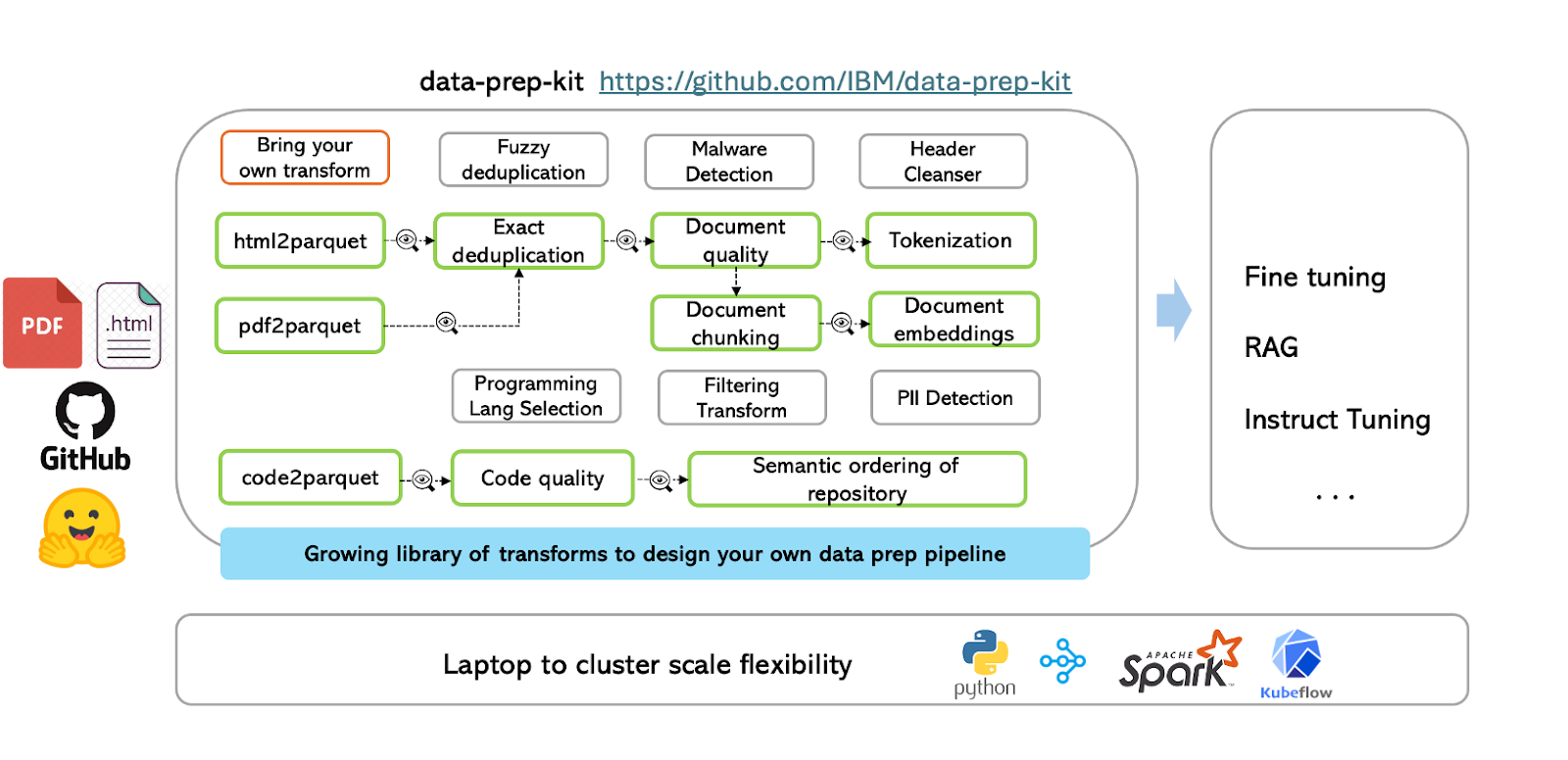 Figure- Data Prep Kit Workflow.png
Figure- Data Prep Kit Workflow.png
Figure: Data Prep Kit Workflow
The workflow begins by converting input files (such as HTML, PDFs, or code) into the standardized Parquet format, ensuring consistent data schemas. At its core, DPK includes a robust data processing library that enables users to apply predefined or custom transforms, chaining multiple transforms to process data systematically. For instance, text data can go through exact deduplication and then proceed to steps like document quality analysis and tokenization or document chunking and embedding generation.
The resulting document embeddings can be leveraged for advanced applications such as fine-tuning models, implementing RAG pipelines, or instruct-tuning. By automating and standardizing the data preparation process, DPK empowers developers to focus on building and refining their AI models, scaling from laptops to cluster-based environments with ease.
DPK also allows users to create and add their custom transforms to fit specific needs. Here’s how you can get started:
Step-by-Step Tutorial to help you add your own transform.
Comprehensive Demo to implement all the document preprocessing steps in a single workflow.
Integrating DPK with Milvus for RAG
After passing the raw data through the DPK, the outcome is text embeddings, which can be further integrated with vector databases like Milvus to create interesting LLM applications. Let’s look at an example RAG pipeline by integrating DPK with Milvus.
Retrieval Augmented Generation (RAG) is an advanced technique that enhances the accuracy, relevance, and factual grounding of LLM outputs by combining retrieval and generation methods. It consists of two key components: the retriever, which fetches relevant contextual information from a vector database like Milvus filled with external data, and the generator, which uses this context to create precise and meaningful responses.
Below is the RAG pipeline built with Milvus and DPK. Milvus serves as the retriever in this pipeline, efficiently managing and querying large-scale external data. DPK preprocesses the data, ensuring it is clean, consistent, and high-quality before being stored in Milvus. The LLM is the generator, producing accurate and context-aware responses tailored to user needs.
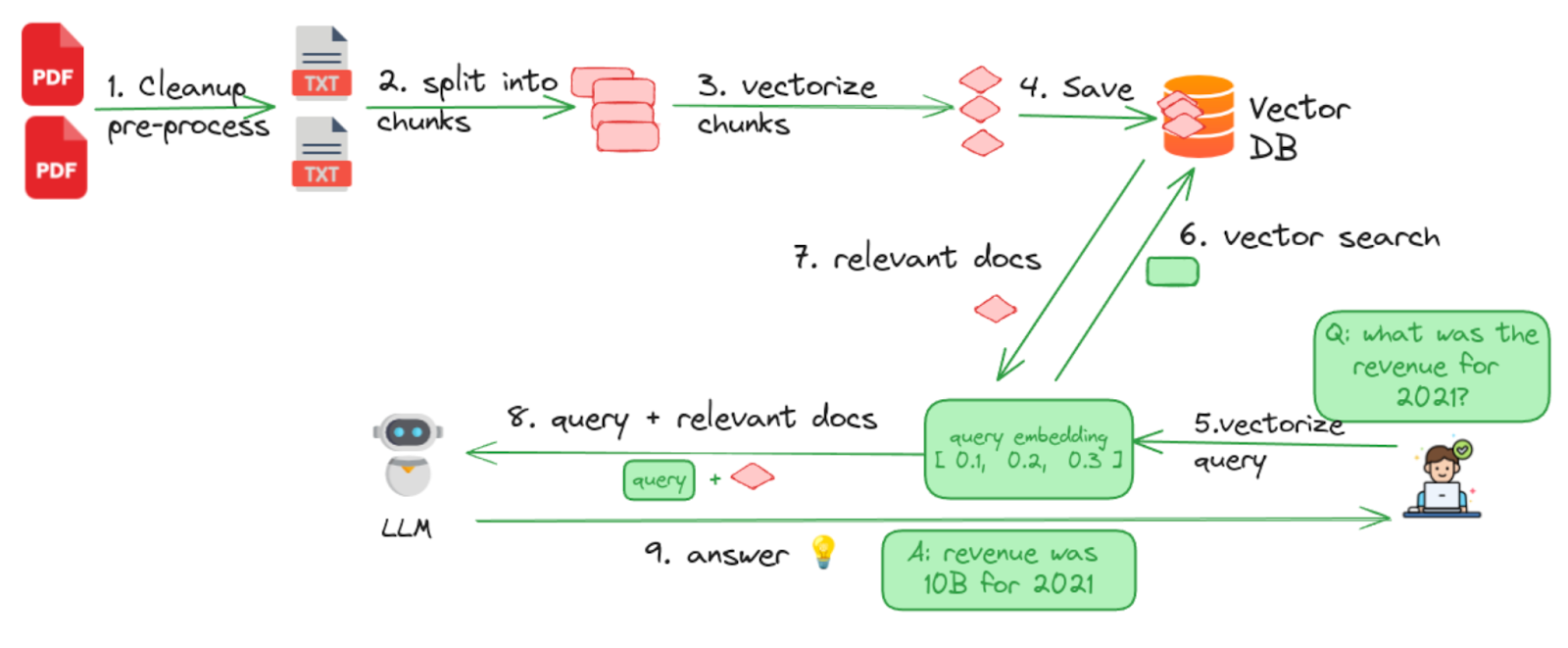 Figure- Overall Workflow of Data Prep Kit with Milvus for RAG.png
Figure- Overall Workflow of Data Prep Kit with Milvus for RAG.png
Figure: Overall Workflow of Data Prep Kit with Milvus for RAG (Source)
Cleanup documents - This step performs all the data preprocessing functions, such as removing markups, performing exact and fuzzy deduplication, etc.
Split into chunks - Splits the documents into manageable chunks or segments using various chunking strategies. Documents can be split either into pages, paragraphs or sections. The right chunking strategy depends on the document types being processed.
Vectorize/Generate Embeddings - The chunks obtained are then vectorized using embedding models. This step is to make the text searchable.
Saving Data into Milvus Vector Database - Milvus stores all the encoded embeddings and prepares them ready for similarity retrieval.
Vectorize the Question - When a user prompts a question, it is vectorized using the same embedding model.
Vector Search - The encoded query is sent to Milvus for a vector similarity search.
Retrieve Relevant Documents - Milvus returns top-K documents most relevant to the query.
Form a new prompt: The retrieved documents and the original query are combined to form a new prompt for the LLM.
LLM Outputs Answer— Finally, LLM generates a more accurate answer using its knowledge and the contextual information retrieved from the Milvus vector database.
To check out the complete implementation of the above workflow, check out this tutorial.
Conclusion
IBM’s open-source Data Prep Kit (DPK) simplifies data preprocessing for LLM workflows by tackling common challenges like toxicity, overfitting, and bias in data. With over 20 modular transforms, DPK streamlines essential tasks such as deduplication, filtering, and privacy protection. The DPK pipeline starts by preprocessing raw inputs such as PDFs or HTML and converting them into structured formats like Parquet. Quality checks, data cleaning, and embedding generation follow this step. These embeddings can be stored in vector databases like Milvus to support applications such as fine-tuning and Retrieval-Augmented Generation (RAG).
This blog also demonstrated how integrating Milvus with DPK enables the retrieval of contextually relevant documents and enhances LLM outputs with reliable and fact-based responses.
Relevant Resources
Keep Reading

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.