




Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Discover how Chain-of-Agents enhances Large Language Models by effectively managing context injection, improving response quality while addressing token limitations.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Many approaches have been introduced in recent years to improve the quality of responses generated by Large Language Models (LLMs). Among these, context injection can be seen as one of the most effective methods. Context injection helps LLMs generate correct and personalized answers by incorporating relevant context into the prompt that might help address any given query.
The challenge, however, is that providing relevant context in the prompt significantly increases the number of input tokens that the LLM needs to encode. In some cases, the context may be so lengthy that it exceeds the LLM's context window, resulting in a query that cannot be processed.
To address this issue, an approach called Chain-of-Agents (CoA) has been introduced. In this article, we'll discuss this approach in detail, starting with the background of why it's needed, how it works, and its performance compared to other context injection methods. So, without further ado, let's dive in.
Context Injection Method and Its Impact on LLMs
One of the main problems of using LLMs is the risk of hallucination. Hallucination is when an LLM produces a wrong yet convincing answer to a query. This typically occurs when we ask the LLM about something it's unfamiliar with, such as recent news or internal documents.
Context injection is one of the most effective solutions to mitigate the risk of LLM hallucination. The idea is straightforward: for any given query, we provide the LLM with relevant context that it can use as a source to generate the answer.
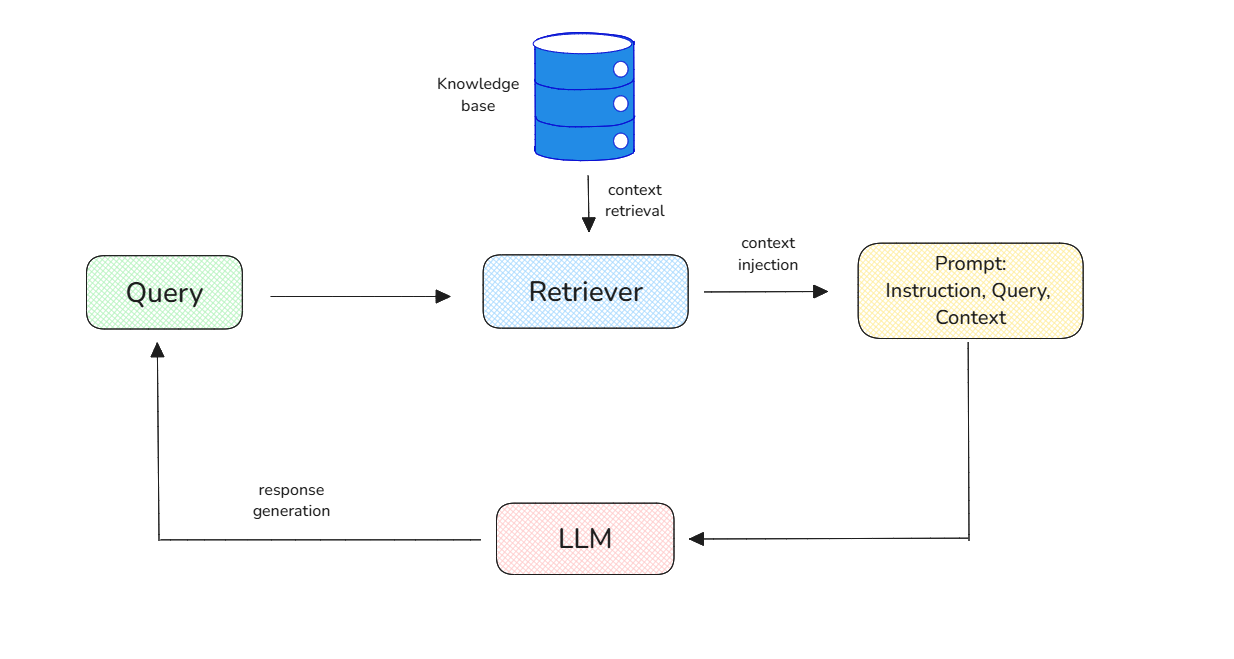
Context injection workflow.
A context can be fetched from anywhere, such as web search, internal documents, databases, etc., and it doesn't have to be text; it could be an image as well. Now the question is: how can relevant context be fetched to help LLMs generate contextual answers to any given query?
Let's use the Retrieval-Augmented Generation (RAG) method to better understand this process. RAG can be seen as the most popular context injection method out there, and it's quite straightforward to implement.
A typical RAG workflow begins by transforming candidate contexts into embeddings using an embedding model. Then, we store these embeddings inside a vector database like Milvus alongside the raw texts.
Next, for any given query, we transform the query into an embedding using the same embedding model. Now, since we have a query embedding and a collection of context embeddings inside the vector database, we can perform a similarity search between the query embedding and context embeddings. The most similar context can then be fetched and injected into the prompt of the LLM. The LLM can then use the provided context to generate a more accurate response to the query.
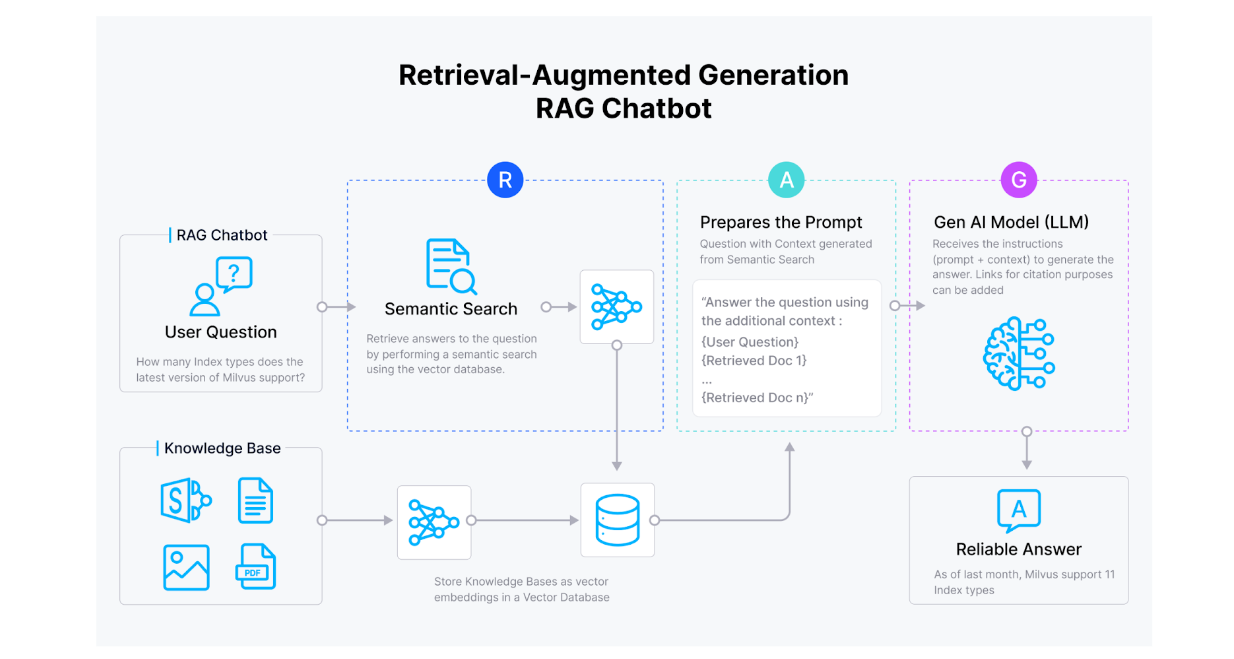
RAG workflow
Injecting relevant context into the prompt has proven effective in mitigating the risk of LLM hallucination. However, the context is normally quite lengthy and can potentially lead to a problem because each LLM has a context window limit.
Context window refers to the maximum amount of text (tokens) that an LLM can process at once. For example, the Claude-3 model has a context window of 200K tokens. This is more than enough if our prompt doesn't contain context. However, some contexts can be really long and potentially consist of way more than 200K tokens, therefore can't be processed by the model.
There are two popular methods implemented to solve the problem caused by an overly long context: input reduction and window extension.
Input reduction: refers to a method of splitting an overly long context into several chunks.
Window extension: refers to a method to increase the context window limit of an LLM.
Input reduction is widely implemented in RAG applications, as the contexts are split into small chunks in the early stage. Then, each chunk is transformed into an embedding and stored inside a vector database. Meanwhile, window extension is normally implemented via retraining of an LLM.
Despite the success of each method in real-world applications, there are still limitations in both approaches.

Input reduction via chunking method.
Even after using input reduction, i.e., splitting long context into chunks, we still need to rely on the performance of both embedding models and rerankers. We need them to retrieve the most relevant chunk to be used as a context that will be helpful for our LLM to generate an answer. If the retrieved chunk is not really helpful in answering the user's query, the quality of the LLM response will also be negatively affected.
Meanwhile, while we can potentially inject a long context into the LLM after performing window extension, there is no guarantee that the generation quality from the LLM improves. Many studies have shown that LLMs tend to struggle to focus on the needed context to answer the query when provided with overly long contexts.
So, is there any other method we can use to handle an overly long context in a GenAI application? This is where Chain-of-Agents (CoA) comes in.
How Chain-of-Agents (CoA) Works
CoA or Chain-of-Agents, is a method that utilizes a collection of LLMs (agents) to effectively handle an overly long context. The general idea is simple: given a collection of LLMs, we arrange these LLMs to work sequentially, i.e., one LLM receives input from the previous LLM and generates output for the next LLM.
In a nutshell, the CoA approach consists of two stages.
In the first stage, we split the context into chunks for any given long context. Next, an agent processes each chunk. The agent produces evidence about whether or not the chunk provides helpful information to answer the query for the next agent. The next agent then receives the evidence from the previous agent and its own chunk to process, producing evidence to be given to the next agent. This process happens sequentially until the last agent.
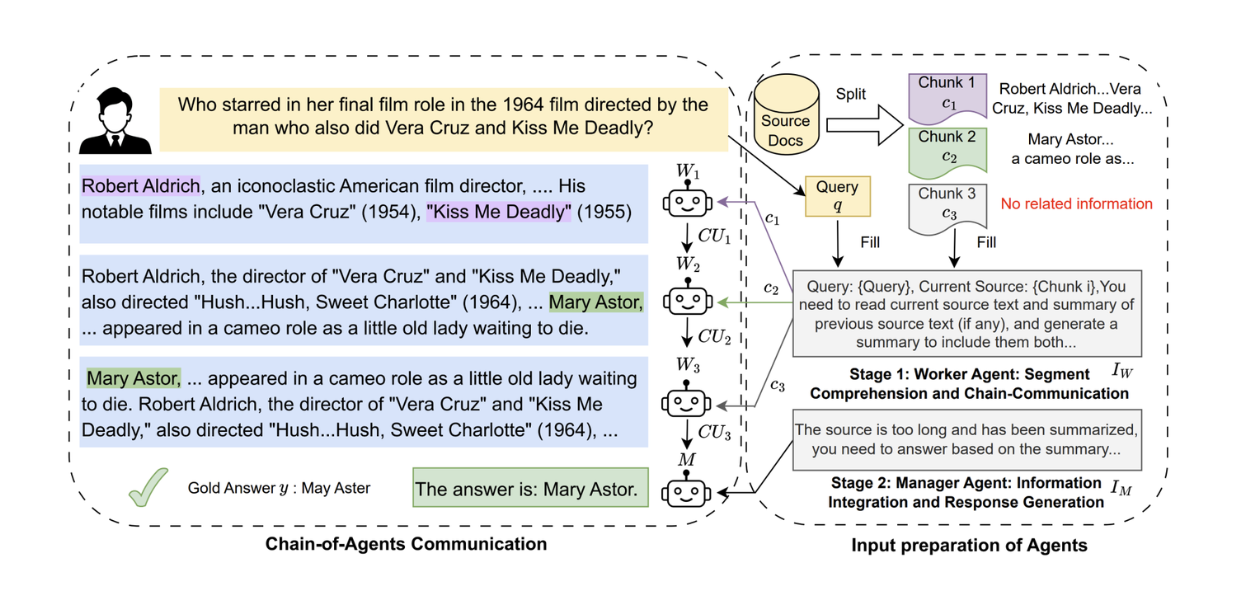
Overview of CoA workflow. Source.
In the second stage, there is an LLM (a manager) that gathers the evidence from the last agent and generates the final response to the user's query. Now let's talk about each stage in more detail.
First Stage of CoA
In the first stage of CoA, we set a particular number of agents in advance. Let's say we'd like to have 3 agents: W1, W2, and W3. Next, we split the input long context into 3 chunks: C1, C2, and C3. As you can see, we can adjust the number of agents depending on how long the input context is.
Each agent receives four different inputs: the instruction, the query, a context chunk, and the so-called communication unit (CU) from the previous agent. The content of the CU differs depending on the task. For example, for a text summarization task, the CU contains the summary of the chunk processed by the previous agent. Meanwhile, for a question-answering task, the CU contains evidence about whether or not the chunk processed by the previous agent contains the answer to the query asked.
We can express the input of each agent as:
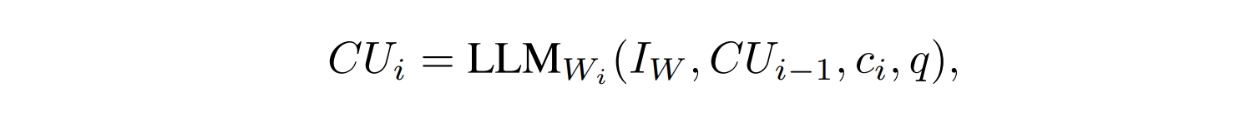
As you can see, what sets CoA apart from other multi-agent frameworks is the fact that it's processed sequentially instead of in parallel. Each context chunk is processed by an agent before the information about that chunk is passed to the next agent.
The sequential design of CoA offers a performance boost in terms of its accuracy when handling overly long contexts, and we'll see this in more detail in the next section.
Second Stage of CoA
After sequential processing by agents, the CU of the last agent is then used by the so-called manager. The manager is also an LLM that takes three different inputs: the instruction, the query, and the CU of the last agent, as expressed below:
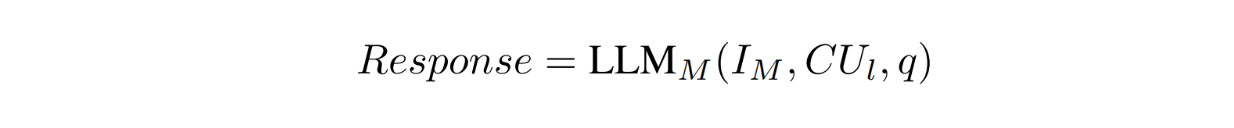
As you can imagine, the CU of the last agent contains the accumulation of information over the long context that can help the manager in answering a query. The manager will then synthesize the CU and use it as a basis to generate the response back to the user for any given query.
You might be wondering: do we even need a manager in this CoA system? What if we just use the last agent to directly output the response to the query? It turns out that CoA's performance would be way worse without a manager, as you can see from the result on several benchmarks below:
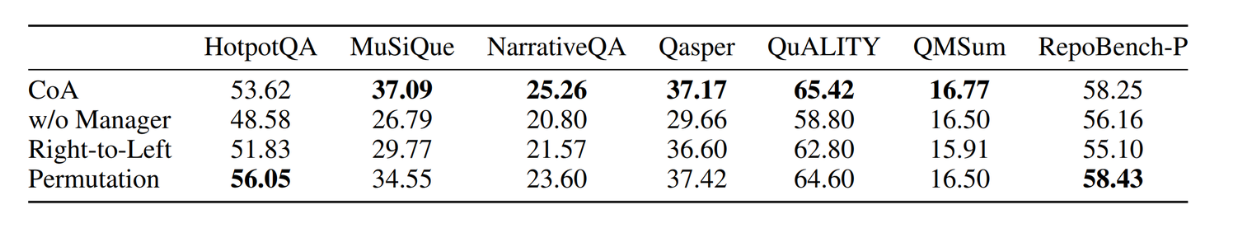
CoA performance comparison with and without a manager. Source.
In the next section, we'll see how this CoA workflow compares against other state-of-the-art methods.
CoA Performance Compared to Other Methods
To assess the performance of CoA against other methods, the author used six different LLMs: PaLM 2 (text-bison@001 and text-unicorn@001), Gemini 1.0 (gemini-ultra), and Claude 3 (claude-3-haiku, claude-3-opus, and claude-3-sonnet). For each experiment, the author used the same LLM as the chain of agents (e.g., using 5 gemini-ultra instead of 2 text-unicorn and 3 gemini-ultra). The manager is also of the same series of LLM used as the chain of agents.
These six LLMs have different context window limits: the PaLM 2 models have an 8k tokens context window limit, the Gemini 1.0 model has a 32k tokens context window limit, while the Claude 3 models have a 200K tokens context window limit.
In general, three use cases were considered during the experiment: summarization, question-answering, and code completion.
Comparison with Other Context Injection Methods
The CoA method has been compared with other context injection methods: Vanilla and RAG.
The vanilla method refers to injecting context into LLMs until their context window is fully utilized. Meanwhile, in the RAG method, the input long context is split into chunks, each consisting of 300 words. The top-n chunks are then fetched into the LLMs until their context window is fully utilized.
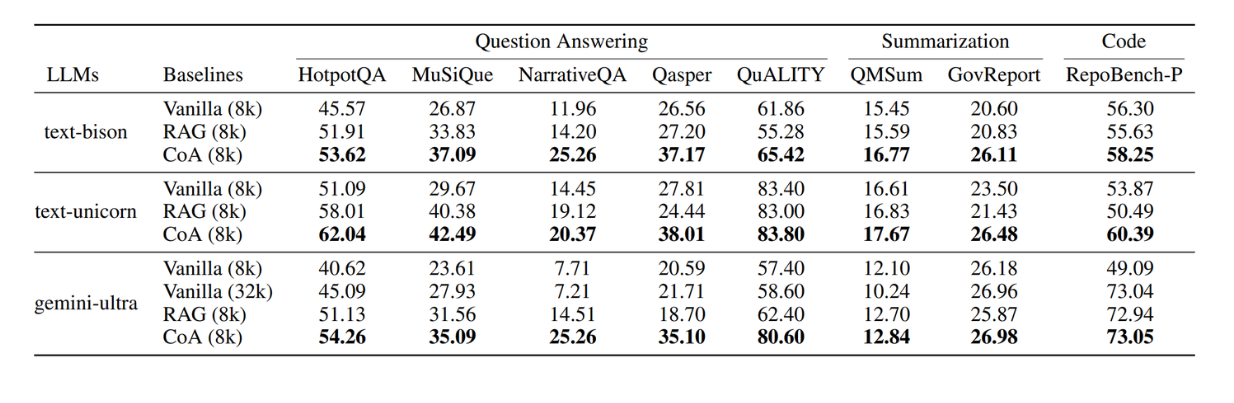
Overall CoA results against other context injection methods. Source.
As you can see in the table above, the CoA performance with different LLMs outperforms alternative context injection methods across different benchmarks.
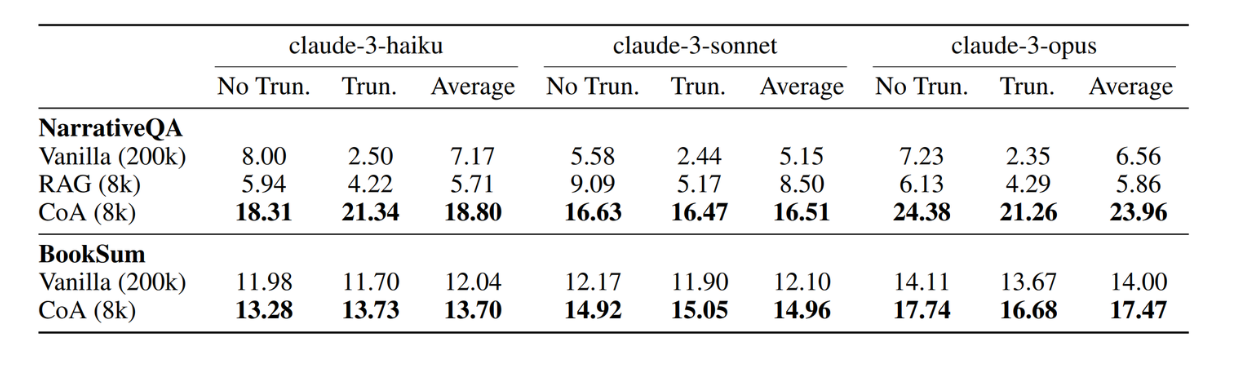
Overall CoA results against other context injection methods with LLM that have a long context window. Source.
Interestingly, the experiment results have also shown that the CoA method is far more effective compared to the vanilla method. Utilizing several agents that work sequentially, where each agent uses only an 8k context window, results in far better performance compared to using one LLM that's able to hold an overly long context (200k context window limit). This demonstrates CoA's effectiveness over an approach where we just put the long context into the LLM at once.
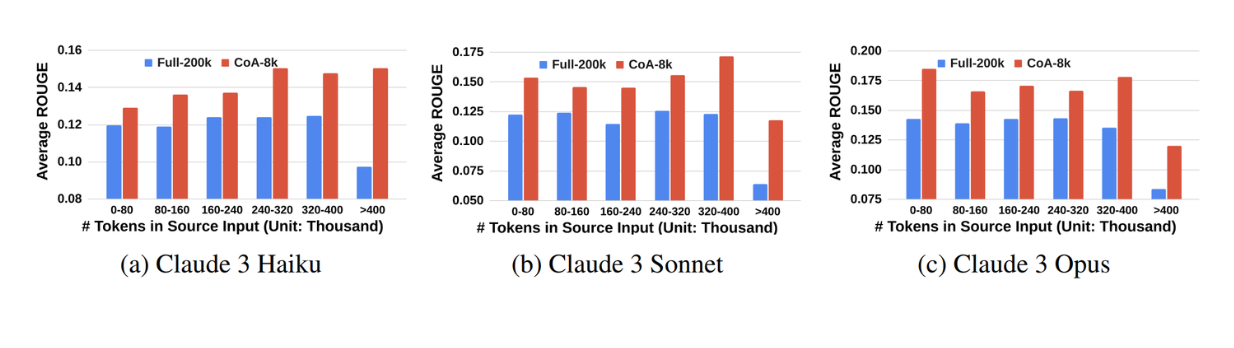
Improvement from using CoA is more obvious for longer inputs. Source.
As you can see from the figure above, we can see even greater performance improvement as we use stronger LLMs as the chain of agents and the manager.
The CoA also consistently outperforms RAG, especially when the query needs complex reasoning and long context to solve. As discussed in the previous section, RAG retrieves the context that's semantically most similar to the query. If the query is ambiguous and the answer is spread across different chunks, RAG will struggle to respond with the correct answer. Thanks to its sequential nature of chunk processing and evidence accumulation, CoA manages to generate the correct answer.

A case study of RAG (left) and CoA (right) on HotpotQA. Source.
Comparison with Other Multi-Agent Systems
Since the CoA method is basically a multi-agent system, it only makes sense to compare this method with other multi-agent systems. Specifically, two other methods are compared to CoA: Multi-Agent Voting (Merge) and Multi-Agent Hierarchical Structure (Hierarchical).
In the Merge method, each agent works independently and in parallel. For any given chunk, all agents generate their own answer independently, and then there is a majority voting at the end to decide the final answer that can be deduced from the chunk.
Meanwhile, in the Hierarchical method, each agent works in a tree-based structure and has a similar framework as CoA with agents and a manager. Each agent processes a particular chunk, and only if the chunk contains useful information will an agent send the CU to the manager. The manager will then use the CUs from agents to come up with the final response.

Comparison between CoA and other multi-agent frameworks. Source.
As you can see, the CoA also managed to outperform the other multi-agent systems. This is because unlike CoA, the Merge and Hierarchical systems work in parallel, i.e., each agent works independently. Therefore, each agent can only maintain the information of each chunk without seeing the context of the previous chunk, hurting the overall performance of the system. This also shows the effectiveness of sequential processing in CoA to improve the generation quality from the LLM.
CoA Limitations and Further Research
One obvious limitation of using the CoA method is the high latency during response generation, which in turn also has a direct impact on the cost. This is because we need to make several calls to the LLM sequentially for each request. To reduce the latency and the high cost, future studies will focus on replacing LLMs with more effective models via model routing.
Also, the current experiment of the CoA approach doesn't take other forms of communication between agents into account, such as debating or complex discussion. This means that the next agent only takes the CU of the previous agent as additional information to help it process a particular chunk to answer the query. Therefore, exploring more advanced agent communication mechanisms would also be noteworthy in the future.
Conclusion
The Chain-of-Agents (CoA) method presents a significant improvement in handling overly long contexts for LLMs. By structuring multiple agents sequentially, CoA ensures a more effective accumulation of evidence across chunks, which leads to better response generation in summarization, question-answering, and code completion tasks.
The experiments demonstrated that CoA consistently outperforms other context injection methods like Vanilla and RAG. CoA also outperformed other multi-agent systems, which highlights the benefits of its sequential approach over parallel processing. Despite its effectiveness, CoA comes with challenges, particularly in terms of high latency and cost due to multiple sequential LLM calls. Future research will focus on optimizing model routing to reduce these limitations and explore more advanced agent communication mechanisms.

- Context Injection Method and Its Impact on LLMs
- How Chain-of-Agents (CoA) Works
- CoA Performance Compared to Other Methods
- Comparison with Other Context Injection Methods
- Comparison with Other Multi-Agent Systems
- CoA Limitations and Further Research
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Introduction to the Falcon 180B Large Language Model (LLM)
Falcon 180B is an open-source large language model (LLM) with 180B parameters trained on 3.5 trillion tokens. Learn its architecture and benefits in this blog.
Unlocking the Power of Many-Shot In-Context Learning in LLMs
Many-Shot In-Context Learning is an NLP technique where a model generates predictions by observing multiple examples within the input context.

Everything You Need to Know About LLM Guardrails
In this blog, we'll examine LLM guardrails, technical systems, and processes designed to ensure LLMs' safe and reliable operation.