




Effortless AI Workflows: A Beginner's Guide to Hugging Face and PyMilvus
In this comprehensive guide, you will learn how to utilize PyMilvus and Hugging Face datasets to supercharge your machine-learning projects.
Read the entire series
- Effortless AI Workflows: A Beginner's Guide to Hugging Face and PyMilvus
- Building a RAG Pipeline with Milvus and Haystack 2.0
- How to Pick a Vector Index in Your Milvus Instance: A Visual Guide
- Semantic Search with Milvus and OpenAI
- Efficiently Deploying Milvus on GCP Kubernetes: A Guide to Open Source Database Management
- Building RAG with Snowflake Arctic and Transformers on Milvus
- Vectorizing JSON Data with Milvus for Similarity Search
- Building a Multimodal RAG with Gemini 1.5, BGE-M3, Milvus Lite, and LangChain
Introduction
Regarding artificial intelligence and machine learning, access to high-quality datasets and efficient data management systems is essential for building efficient and scalable applications. Hugging Face repository contains datasets that suit many domains, from natural language processing to complex data analysis. It has become a destination for many developers who want access to a vast curated dataset repository.
With this vast amount of data, there is a need for an efficient data management mechanism. This is where PyMilvus comes in. PyMilvus is built on the robust foundation of Milvus which specializes in managing and querying high-dimensional vector data. PyMilvus provides a Python interface that enables data scientists and AI developers to harness the power of vector databases for a wide range of applications, including recommendation systems, content-based search, and similarity matching.
In this comprehensive guide, you will learn how to utilize PyMilvus and Hugging Face datasets to supercharge your machine-learning projects.
What are Hugging Face Datasets?
Hugging Face Datasets are a part of the Hugging Face Hub, a platform for sharing and collaborating on models, datasets, and other AI resources. They consist of a diverse collection of high-quality datasets sourced from various domains, including text, speech, image, and video data. These datasets serve as the foundational resources for training and evaluating AI models.
The true power of Hugging Face datasets lies in their versatility. They are not limited to a single application or use case. Whether you're working on language translation, sentiment analysis, image classification, or question answering, Hugging Face Datasets have got you covered.
Quick Datasets Library
To access the datasets listed in the Hugging Face Datasets Hub you need a library called Datasets. To use it, you must first install it to your Python environment using the command below:
pip install datasets
Then import the library and load the dataset you require from Hugging Face Hub.
from datasets import load_dataset
# Load a dataset from the Hugging Face dataset hub
dataset = load_dataset('squad')
print(dataset)
In the above code, we are loading the Stanford Question Answering Dataset (SQuAD). Below is a screenshot of what the structure of the dataset looks like:
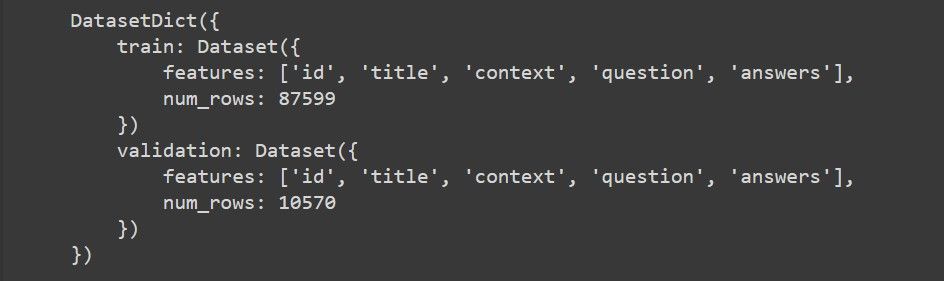
The structure shows that our dataset has two splits: train and validation. The train split has nearly 87,599 data points, each containing features like id, title, context, etc. Similarly, the validation split has over 10,570 data points with the same features. These features will be extremely useful to us later in the guide.
Benefits of Integrating Hugging Face Datasets with PyMilvus
The integration of Hugging Face datasets with PyMilvus revolutionizes the way data is managed, queried, and utilized in AI and machine learning applications. The benefits of leveraging PyMilvus for handling vectorized data from Hugging Face datasets include:
- Efficient Data Management: Milvus offers optimized data storage and retrieval mechanisms, allowing for seamless integration with Hugging Face datasets and eliminating the need for manual data management tasks. This shifts the focus on model development and experimentation without being bogged down by tedious data handling processes.
- Scalability and Performance: Milvus is designed to scale horizontally, enabling it to handle massive volumes of vectorized data with ease. This scalability is particularly beneficial when working with large-scale Hugging Face datasets, which may contain millions or even billions of data points.
- Fast and Accurate Search: Another key advantage of using Milvus for handling vectorized data is its ability to perform fast and accurate similarity search operations. Milvus leverages advanced indexing techniques and similarity search algorithms to retrieve relevant information quickly, even from large-scale datasets. This enables data scientists to efficiently search and retrieve similar data points within Hugging Face datasets.
- Seamless Integration with AI Workflows: PyMilvus offers a seamless Python interface that integrates with popular AI and machine learning frameworks such as TensorFlow, PyTorch, and scikit-learn. This allows for the seamless incorporation of vector databases into existing workflows, leveraging the power of Milvus for handling vectorized data from Hugging Face datasets without the need for extensive retooling or redevelopment.
Imagine searching for similar questions within a large question-answering dataset from Hugging Face. Vector databases would enable fast retrieval of relevant questions based on semantic similarity, significantly faster than traditional keyword-based searches.
Setting Up Your Environment
Before you can integrate Hugging Face datasets with PyMilvus, you need to set up our environment. This involves installing the necessary libraries and configuring PyMilvus for seamless integration.
Start by launching any Python IDE. Then, create a virtual environment and use PIP to install the required libraries using the following command:
pip install transformers datasets pymilvus torch
Here is a breakdown of what you will use each library for:
transformers: You will use this library to load pre-trained transformer models and perform tokenization for generating embeddings.
datasets: You will use this library to load datasets from the Hugging Face dataset hub for tasks such as question answering.
pymilvus: You will use this library to connect to the Milvus server, create collections, insert embeddings, and perform similarity searches.
torch: You will use this library for tensor operations and working with deep learning models, such as generating embeddings using pre-trained transformer models.
After installing the libraries, we need to install Milvus, This is the actual vector database that PyMilvus is built on. It needs to be running either locally or on the cloud via managed Milvus. To install Milvus, follow this quickstart guide.
Milvus by default runs on port 19530. If you are running Milvus on any other port, take note of it as we will require the port number during connection. Here is a screenshot showing Milvus running on port 19530 in Docker.
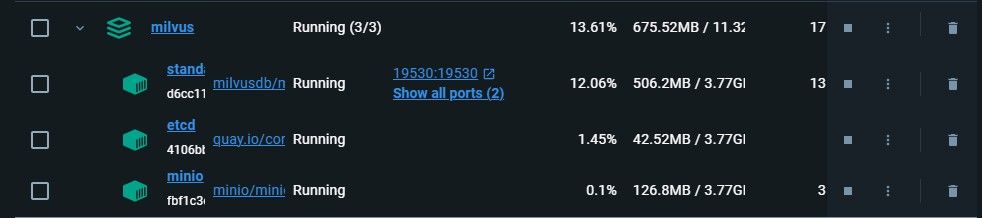
The first container is the Milvus standalone service and the rest are its two dependencies.
After installing Milvus and starting it you are now ready to integrate PyMilvus with Hugging Face datasets.
Integrating PyMilvus with Hugging Face Datasets
Let us take a look at a step-by-step process of how to integrate PyMilvus with Hugging Face datasets. We will break the code into functions to promote code reusability.
Importing Libraries and Declaring Necessary Parameters
Start by importing the necessary libraries to your code:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
from datasets import load_dataset_builder, load_dataset, Dataset
from transformers import AutoTokenizer, AutoModel
from torch import clamp, sum
The imports will help us establish connections to Milvus, define collection schemas, load datasets, tokenize text, load transformer models, and perform tensor operations.
Then define various parameters that you will use in the code:
# Parameters
DATASET = 'squad' # Hugging Face dataset to use
MODEL = 'bert-base-uncased' # Transformer model for embeddings
TOKENIZATION_BATCH_SIZE = 1000 # Batch size for tokenizing operations
INFERENCE_BATCH_SIZE = 64 # Batch size for embedding generation
INSERT_RATIO = 0.001 # Proportion of data to embed and insert into Milvus
COLLECTION_NAME = 'huggingface_db' # Name of the Milvus collection
DIMENSION = 768 # Dimension of embeddings
LIMIT = 5 # Number of search results to return
MILVUS_HOST = "localhost"
MILVUS_PORT = "19530"
If you would like to use your full dataset, set INSERT_RATIO to 1.0. Also if you are running Milvus on another port make sure you pass it to the MILVUS PORT parameter.
Creating a Milvus Collection
The next step after defining the parameters is creating a Milvus collection. This is the collection where we will perform operations such as retrieval and insertion.
def create_collection():
# Connect to Milvus Database
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
# Remove collection if it already exists
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
# Define schema for the collection
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR,
dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
#Create an IVF_FLAT index for efficient similarity search
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":1536}
}
collection.create_index(field_name="original_question_embedding",
index_params=index_params)
collection.load()
return collection
The function establishes a connection with the Milvus database. After a successful connection, it checks whether a collection with the name specified in the parameter exists. If it exists, it drops that collection in the database. It then defines the schema for the collection, which includes fields for ID, original question, answer, and embedding. It finally creates an index for the collection to optimize similarity search and loads the collection.
Data Loading and Tokenization
Since you have the collection ready, proceed to load the data from your preferred dataset.
def load_data():
data_dataset = load_dataset(DATASET, split='all')
data_dataset = data_dataset.train_test_split(test_size=INSERT_RATIO,
seed=42)['test']
data_dataset = data_dataset.map(lambda val: {'answer': val['answers'][
'text'][0]}, remove_columns=['answers'])
return data_dataset
In this step, the above function loads a dataset from the Hugging Face Hub and splits it into a test set for embedding and insertion. An embedding is a numerical representation of some unstructured data. It then maps the data to extract the answer text.
Having loaded the dataset and extracted the data we need, it's time to tokenize the extracted data. Tokenizing is breaking down the text into smaller parts, also known as tokens.
def tokenize_question(batch):
results = tokenizer(batch['question'], add_special_tokens=True,
truncation=True, padding="max_length",
return_attention_mask=True, return_tensors="pt")
batch['input_ids'] = results['input_ids']
batch['token_type_ids'] = results['token_type_ids']
batch['attention_mask'] = results['attention_mask']
return batch
data_dataset = data_dataset.map(tokenize_question,
batch_size=TOKENIZATION_BATCH_SIZE, batched=True)
data_dataset.set_format('torch', columns=['input_ids',
'token_type_ids', 'attention_mask'],
output_all_columns=True)
return data_dataset
The function tokenizes the questions in the dataset using the specified transformer model. It then defines a helper function that tokenizes a batch of questions and adds the resulting token ids, token_type_ids, and attention_mask to the dataset. The tokenized dataset is then set to PyTorch format and returned.
Embedding the Dat
After tokenizing our data we need to represent it in numerical values. This process is called embedding. It is the format that vector databases expect the data to be inserted to conform to. This is because vector databases are designed to store and manipulate these embeddings.
def embed_data(data_dataset):
model = AutoModel.from_pretrained(MODEL)
def embed(batch):
sentence_embs = model(
input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask'])[0]
input_mask_expanded = batch['attention_mask'].unsqueeze(-1).expand(
sentence_embs.size()).float()
batch['question_embedding'] = sum(sentence_embs * input_mask_expanded, 1) / clamp(input_mask_expanded.sum(1), min=1e-9)
return batch
data_dataset = data_dataset.map(embed, remove_columns=['input_ids',
'token_type_ids',
'attention_mask'],
batched=True, batch_size=INFERENCE_BATCH_SIZE)
return data_dataset
The function takes the tokenized dataset and generates embeddings for the questions using the specified transformer model. It then defines a helper function embed that computes the embeddings for a batch of tokenized questions by passing them through the transformer model and summing the token embeddings weighted by the attention mask. The resulting embeddings are added to the dataset as the question_embedding field. The dataset is then mapped with the embed function, removing the tokenization columns.
Inserting the Data into Milvus
This is the last step in integrating Hugging Face datasets with Milvus. It is performed once you have your data in the form of embeddings.
def insert_data(collection, data_dataset):
def insert_function(batch):
insertable = [
batch['question'],
[x[:995] + '...' if len(x) > 999 else x for x in batch['answer']],
batch['question_embedding'].tolist()
]
collection.insert(insertable)
data_dataset.map(insert_function, batched=True, batch_size=64)
collection.flush()
The function takes the collection and the embedded dataset from Hugging Face as input and inserts the data into the Milvus collection. It defines a helper function insert_function that creates a list of insertable data for each batch, including the original question, the truncated answer (if longer than 999 characters), and the question embedding vector.
Then, the insert method of the collection is called with this insertable data for each batch. Finally, the flush method is called to ensure that all data is persisted in the collection. Create a main function to execute the steps in a structured way.
if __name__ == "__main__":
collection = create_collection()
data_dataset = load_data()
data_dataset = tokenize_data(data_dataset)
data_dataset = embed_data(data_dataset)
insert_data(collection, data_dataset)
This finalizes integrating Pymilvus with Hugging Face Datasets.
Practical Applications and Use Cases
There are several practical use cases for integrating Hugging Face datasets with PyMilvus across various domains:
Natural Language Understanding: Enhancing language understanding models for tasks such as question answering, text summarization, and sentiment analysis.
Recommendation Systems: Building content-based recommendation systems for personalized recommendations based on user preferences and item similarities.
Let us see how we can create a simple similar questions recommendation system. This system will take a user question, retrieve the best possible answer and give recommendations to other questions the user might be interested in. Here is an example of such a system being used by an AI provider.

To do that, add the following code before the main function.
def recommendation_system(collection, query):
# Tokenize and embed the query
tokenizer = AutoTokenizer.from_pretrained(MODEL)
query_tokenized = tokenizer(query, add_special_tokens=True, truncation=True,
padding="max_length", return_attention_mask=True,
return_tensors="pt")
# Embed the query
model = AutoModel.from_pretrained(MODEL)
query_embedding = model(
input_ids=query_tokenized['input_ids'],
token_type_ids=query_tokenized['token_type_ids'],
attention_mask=query_tokenized['attention_mask']
)[0]
query_embedding = sum(query_embedding * query_tokenized['attention_mask']
.unsqueeze(-1).expand(query_embedding.size()).float(), 1) / clamp(query_tokenized['attention_mask'].sum(1), min=1e-9)
# Search for similar questions
search_results = collection.search(query_embedding.tolist(),
anns_field='original_question_embedding', param={},
output_fields=['original_question', 'answer'], limit=LIMIT)
# Extract the most relevant result to get the answer
most_relevant_result = search_results[0][0] # Assuming the first hit is the most relevant
answer_to_query = most_relevant_result.entity.get('answer')
# Format the recommendations
recommendations = []
for hits in search_results:
for hit in hits:
recommendations.append({
'id': hit.id,
'distance': hit.distance,
'original_question': hit.entity.get('original_question')
})
return answer_to_query, recommendations
The function first tokenizes and embeds the input query using the same transformer model and process as the data embedding step. Then, it performs a vector similarity search on the collection, passing the query embedding vector as the search vector, the field name for the embeddings (original_question_embedding), and the fields to include in the output (original_question and answer).
The function then assumes the most relevant result is the first hit in the search results, and the corresponding answer is extracted from the entity attribute of this result. Finally, the function formats the recommendations by iterating over the search results and appending a dictionary containing the ID, distance score, and original question text for each hit.
Then test the recommendation system function with a sample query by adding this code to the main function and running it.
# Test the recommendation system with the answer
query = "When will the movie be launched?"
answer, recommendations = recommendation_system(collection, query)
print("Answer to the query '{}': {}".format(query, answer))
print("nRecommendations for similar questions:")
for rec in recommendations:
print("Recommended Question: {}, Distance: {}".format(rec[
'original_question'], rec['distance']))
Here is the output of our recommendation system:
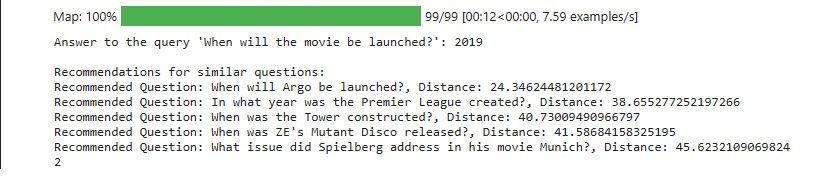
The results show the recommended questions about the release or launch dates of various events or products. This aligns with the query about the launch date of a movie. The distance values indicate the degree of similarity between the query and each recommended question. Lower distances indicate higher similarity.
It is important to note the quality of the output is also subject to the quality of the data you are using and the subset of the dataset you will use.
Further Resources
Here are more resources to help you understand how vector databases and Hugging Face Datasets work:
The full code used in this guide can be found in this notebook.
https://github.com/huggingface/notebooks/blob/main/datasets_doc/en/quickstart.ipynb
https://milvus.io/docs/integrate_with_hugging-face.md
https://www.ibm.com/topics/vector-database#:~:text=Vector%20databases%20create%20indexes%20on,nearest%20neighbor%20search%20between%20vectors.
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- Introduction
- What are Hugging Face Datasets?
- Quick Datasets Library
- Benefits of Integrating Hugging Face Datasets with PyMilvus
- Setting Up Your Environment
- Integrating PyMilvus with Hugging Face Datasets
- Practical Applications and Use Cases
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Building a RAG Pipeline with Milvus and Haystack 2.0
This guide will demonstrate the integration of Milvus and Haystack 2.0 to build a powerful RAG applications.

Semantic Search with Milvus and OpenAI
In this guide, we’ll explore semantic search capabilities through the integration of Milvus and OpenAI’s Embedding API, using a book title search as an example use case.

Building a Multimodal RAG with Gemini 1.5, BGE-M3, Milvus Lite, and LangChain
Multimodal RAG extends RAG by accepting data from different modalities as context. Learn how to build one with Gemini 1.5, BGE-M3, Milvus, and LangChain.