




Building RAG with Snowflake Arctic and Transformers on Milvus
This article explored the integration of Snowflake Arctic with Milvus.
Read the entire series
- Effortless AI Workflows: A Beginner's Guide to Hugging Face and PyMilvus
- Building a RAG Pipeline with Milvus and Haystack 2.0
- How to Pick a Vector Index in Your Milvus Instance: A Visual Guide
- Semantic Search with Milvus and OpenAI
- Efficiently Deploying Milvus on GCP Kubernetes: A Guide to Open Source Database Management
- Building RAG with Snowflake Arctic and Transformers on Milvus
- Vectorizing JSON Data with Milvus for Similarity Search
- Building a Multimodal RAG with Gemini 1.5, BGE-M3, Milvus Lite, and LangChain
The Retrieval Augmented Generation (RAG) model has emerged as a pivotal innovation, merging the best of large language models (LLM) with information retrieval. RAG applications take the format shown in Figure 1. This article aims to guide you through constructing a RAG application by integrating Snowflake Arctic's embedding models, the Hugging Face Transformers library, and Milvus, a popular open-source vector database.
 Fig 1. Flowchart of a standard RAG application
Fig 1. Flowchart of a standard RAG application
Snowflake's Arctic-embed-l models represent a state-of-the-art suite of text embedding tools designed for optimal retrieval quality across various size profiles. Released on April 16, 2024, these models have quickly set a new standard for retrieval performance, as evidenced by their leading positions on the MTEB/BEIR leaderboard. From the ultra-compact 'xs' variant to the expansive 'l' model, the Arctic-embed family is built on a foundation of open-source text representation models like bert-base-uncased. These models are designed with a flexible architecture that accommodates a range of parameters from the compact 22 million in the x-small variant to 335 million in the large model, ensuring scalability and precision across various retrieval tasks. The lineup includes sizes from x-small to large, each optimized for specific applications such as high-speed retrieval in resource-constrained environments to deep, comprehensive embeddings in data-intensive settings. Furthermore, their availability on platforms like Hugging Face broadens access and fosters community collaboration, making these models a practical choice for developers looking to implement state-of-the-art embedding solutions in real-world applications like Zilliz Cloud, as we shall show briefly.
Transformers library provides a suite of APIs and tools designed to streamline the process of utilizing state-of-the-art pretrained models for machine learning. This accessibility not only saves time and reduces both computational costs and environmental impact but also eliminates the need to build models from the ground up. With support for a variety of tasks across different modalities, the library includes:
Natural Language Processing (NLP): Tasks like text classification, question answering, and summarization.
Computer Vision: Capabilities such as image classification and object detection.
Audio: Includes automatic speech recognition and audio classification.
Multimodal: Supports complex tasks like optical character recognition and video classification.
Moreover, Transformers promote flexibility by facilitating interoperability among major frameworks like PyTorch, TensorFlow, and JAX. This feature allows developers to train models in one framework and deploy them in another, enhancing the model’s adaptability across different stages of development.
Milvus is a popular open-source vector database designed to manage large-scale embeddings, such as those generated by Snowflake Arctic models. It excels in storing, indexing, and retrieving vector data, facilitating efficient and fast search capabilities essential for real-time applications, as illustrated in Figure 2. Milvus supports multiple indexing methods, including flat, IVF, and HNSW, which optimize query performance and scalability to handle billions of vectors. Milvus’s robust architecture ensures high throughput and provides horizontal scalability and hybrid search capabilities, integrating seamlessly with popular machine learning frameworks. This makes Milvus an indispensable tool for developers looking to leverage advanced vector search in their applications, enhancing both the precision and speed of retrieval tasks.
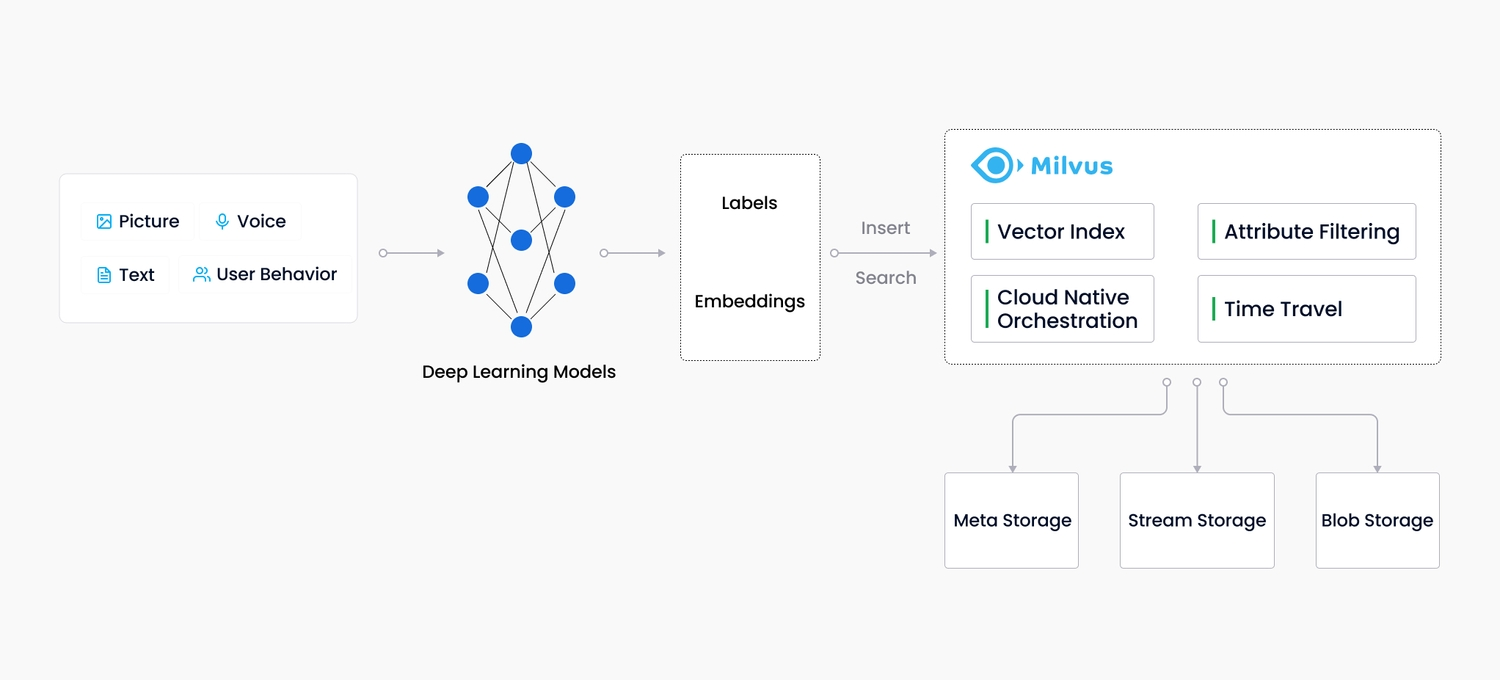 Fig 2. Milvus vector database
Fig 2. Milvus vector database
(Image Source: https://milvus.io/docs/overview.md)
Let's build a RAG application using Snowflake Arctic, Transformers, and Milvus
In this colab notebook, we explore the use of Snowflake Arctic embedding models with Zilliz Cloud, powered by Milvus, to manage and utilize vector embeddings effectively. We use Snowflake Arctic models to embed a dataset of book titles sourced from Kaggle, transforming the textual information into high-dimensional vector space. Once embedded, these vectors are stored in Zilliz Cloud, leveraging Milvus's robust vector database capabilities to handle large-scale embeddings. This setup enables efficient vector similarity searches, a crucial component for RAG applications. By performing similarity searches, we can identify and retrieve the most relevant book titles based on vector proximity, demonstrating how embedded vectors can power advanced search and retrieval tasks in real-world applications. The flowchart in Figure 3 delineates a guide to setting up and deploying a RAG pipeline using Snowflake Arctic models and Milvus.
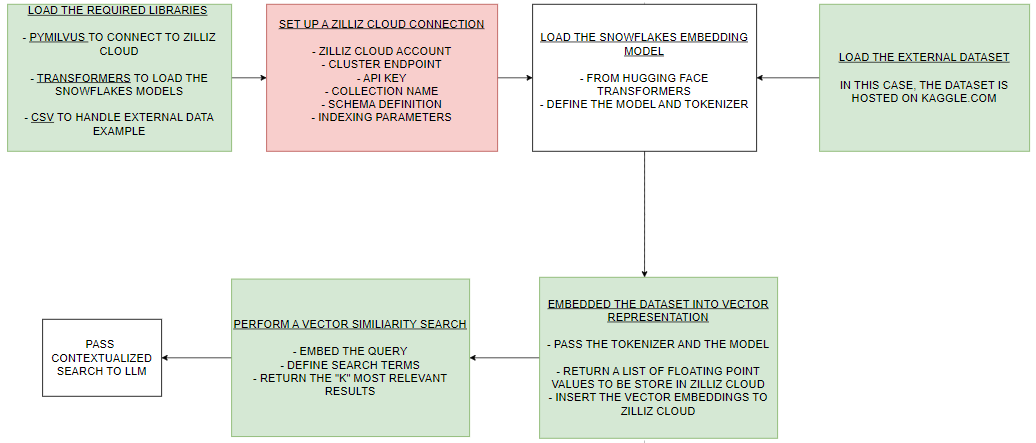 Fig 3. Flowchart of the colab notebook implementation
Fig 3. Flowchart of the colab notebook implementation
Use Cases and Applications
The integration of Snowflake Arctic and Milvus into a RAG system unlocks a multitude of applications across various industries. For example, according to a Forbes article, RAG technology is revolutionizing sectors such as healthcare, legal, customer support, and finance by enhancing the precision and relevance of information retrieval.
In healthcare, RAG can assist medical professionals by quickly sourcing the latest research, patient histories, and treatment guidelines, thereby aiding in more informed decision-making.
Legal professionals benefit from RAG by gaining streamlined access to case law and statutes, which improves the efficiency of legal research and argumentation.
In customer service, RAG-powered chatbots can provide personalized responses based on real-time data, significantly enhancing customer interaction and satisfaction.
Financial analysts use RAG to pull live market data and comprehensive reports, enabling quicker and more accurate market analyses and investment strategies.
Each of these applications demonstrates the transformative potential of RAG in harnessing proprietary and internet-based knowledge to deliver specialized, timely solutions across various fields.
Conclusion
This article explored the integration of Snowflake Arctic with Milvus. This integration represents a significant leap forward in building advanced RAG applications. This powerful combination leverages the high-performance embedding capabilities of Snowflake Arctic and the robust vector management features of Milvus to create dynamic and efficient AI systems. These systems are capable of enhancing information retrieval, which in turn enriches the user experience across various industries by providing precise and contextually relevant responses.
As technology continues to evolve, the potential for customization and adaptation of this setup grows. Organizations and developers are encouraged to experiment with and adapt this framework to meet specific or more complex needs. Whether it's refining the model's accuracy, expanding the database for broader retrieval, or integrating additional AI tools, there's ample opportunity to innovate and enhance the capabilities of RAG applications. By embracing this adaptable and cutting-edge technology, users can not only address their immediate requirements but also position themselves at the forefront of AI development in their respective fields. Consider joining the discord channel of Milvus, as well as following the discussion in other open source platforms to stay up to date.
Resources

- Let's build a RAG application using Snowflake Arctic, Transformers, and Milvus
- Use Cases and Applications
- Conclusion
- Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Effortless AI Workflows: A Beginner's Guide to Hugging Face and PyMilvus
In this comprehensive guide, you will learn how to utilize PyMilvus and Hugging Face datasets to supercharge your machine-learning projects.

Building a RAG Pipeline with Milvus and Haystack 2.0
This guide will demonstrate the integration of Milvus and Haystack 2.0 to build a powerful RAG applications.

Efficiently Deploying Milvus on GCP Kubernetes: A Guide to Open Source Database Management
Self-hosting Milvus on Kubernetes (K8s), especially in the Google Cloud Platform (GCP) environment, offers numerous benefits. Read about the benefits and how to set up the Kubernetes cluster on GCP in the blog.