




Milvus 2.4 Unveils CAGRA: Elevating Vector Search with Next-Gen GPU Indexing
What is a GPU-based Index?
Vector search is inherently computation-intensive. Standing at the forefront as the most performant vector database, Milvus allocates over 80% of its computing resources to its vector databases and search engine, Knowhere. Given the computational demands of high-performance computing, GPUs emerge as a pivotal element of our vector database platform, especially within the vector search domain.
Milvus set a precedent by becoming the first vector database to leverage GPU acceleration with its Milvus version 1.1 in 2021. In version 2.3, by harnessing NVIDIA’s RAFT library for vector search, Milvus introduced GPU-accelerated indexes and integration with the NVIDIA Merlin recommendation framework (used to build recommender systems). The introduction of IVFFLAT and IVFPQ indexes in this version showcased remarkable performance enhancements.
Despite these advancements, challenges such as optimizing performance for small-batch queries and enhancing the cost-efficiency of GPU-based indexes persist, prompting ongoing exploration for innovative solutions. The industry’s shift towards graph-based vector search algorithms, recognized for their superior performance over IVF-based methods, signifies a pivotal evolution. Yet, the adaptation of these algorithms to GPUs is not straightforward due to their sequential execution and random memory access patterns, making efficient GPU implementation challenging for algorithms like GGNN and SONG
Addressing these challenges, NVIDIA’s latest innovation, the GPU-based graph index CAGRA, represents a significant milestone. With NVIDIA’s assistance, Milvus integrated support for CAGRA in its 2.4 version, marking a significant stride toward overcoming the obstacles of efficient GPU implementation in vector search.
What is CAGRA?
Build CAGRA
CAGRA (CUDA Anns GRAph-based) introduces a novel approach to graph construction, diverging from the iterative insert-update method used by hierarchical navigable small worlds (HNSW) graphs on CPUs. This change addresses the challenge of fully leveraging the highly parallel graph construction capabilities of GPUs, which the CPU-based HNSW construction process does not capitalize on. CAGRA begins by creating an initial graph using either IVFPQ or NN-DESCENT, where each node is connected to numerous neighbors. The next steps involve sorting these connections by importance, pruning less critical edges and merging directed graphs to finalize the structure and build an initial graph. In the initial graph, each node has a large number of neighboring nodes. CAGRA then sorts all the adjacent edges according to their importance based on the initial graph and prunes the unimportant edges.
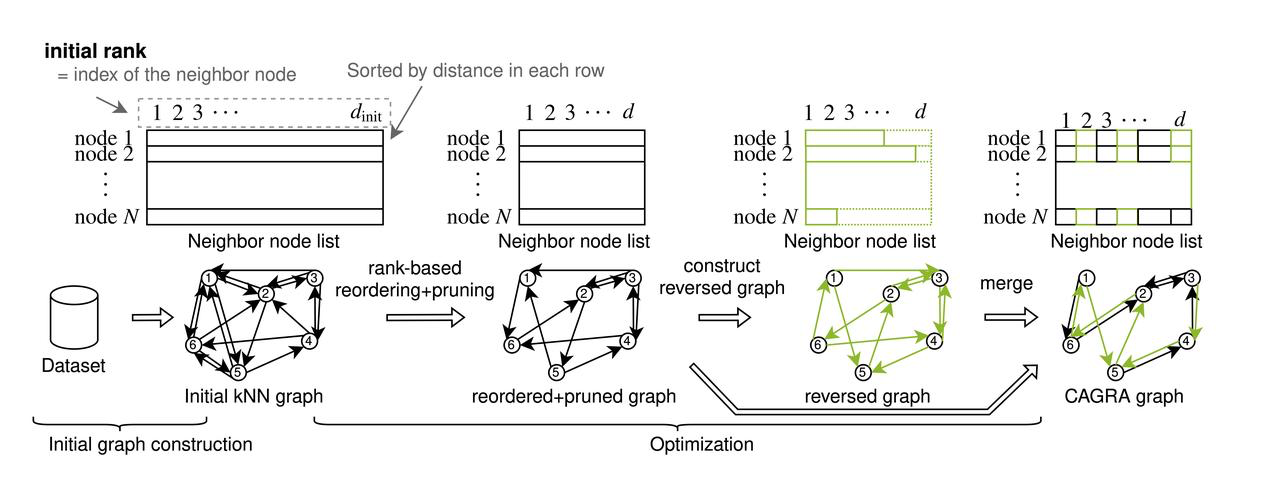 The build process of CAGRA
The build process of CAGRA
Initial Graph Construction
IVFPQ
In IVFPQ mode, CAGRA leverages the dataset to build an IVFPQ index, utilizing the quantization feature of the Product Quantization (PQ) index to minimize video memory usage. Following the creation of this index, CAGRA performs a search for each point in the dataset, using the approximate nearest neighbors identified by the IVFPQ index as adjacent points nearest neighbor search. This process forms the basis for constructing the initial graph, ensuring efficient setup without significantly occupying too much memory.
NN-DESCENT
CAGRA employs the NN-DESCENT algorithm for another approach to initial graph construction, which involves the following detailed steps:
Initialization: Randomly select k points from the dataset v to create the initial adjacency list B[v].
Reversal and Merging: Take the inverse of B[v] to generate the reversed adjacency list R[v], and then merge the B and R to form H[v].
Neighbor Expansion: For any node v in the dataset, identify all neighbors of neighbors based on H[v], selecting the closest topk nodes as its new neighbors.
Iteration: Repeat the process of Reversal and Merging and Neighbor Expansion until B stabilizes and no longer changes or until a preset iteration threshold is met.
Compared to HNSW, NN-Descent offers easier parallelization and less data interaction between tasks, significantly boosting the graph construction time and efficiency of the CAGRA adjacency graph on GPUs. However, it should be noted that the initial graph quality in NN-DESCENT may slightly lag behind that achieved with IVFPQ mode.
CAGRA Optimization
CAGRA's graph optimization strategy is informed by two principal assumptions:
Importance Sorting: Preference is given to path-based sorting over traditional distance-based sorting for determining the importance of edges. This method argues that graph connectivity may not necessarily benefit from distance-based importance sorting.
Reverse graph merging: The principle that a node deemed important to one may also find the latter important underpins the strategy of merging reverse graphs.
The optimization process includes two major steps:
- Pruning: Initially, each node’s adjacent edges are assigned various weights (‘w’) based on distance. CAGRA employs a pruning strategy where edges are cut if they connect nodes that are most ‘detourable,’ based on condition ‘max(w_{x to z},w_{z to y}) < w_{x to y}’. This focuses on eliminating less critical connections to streamline the graph.
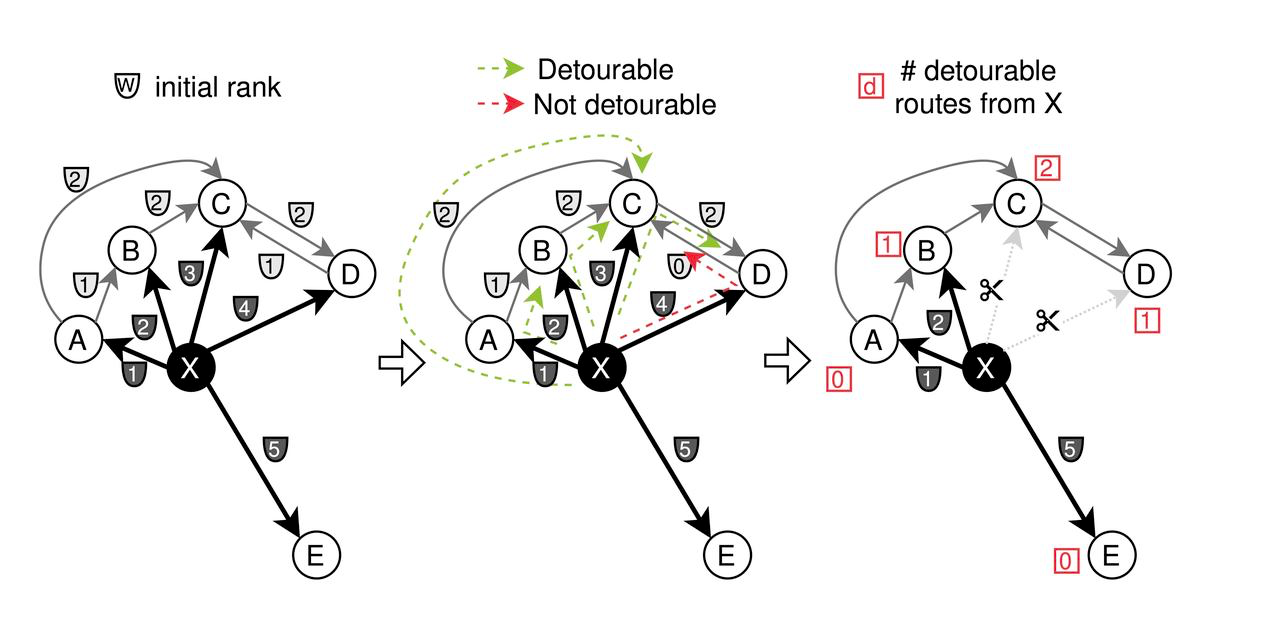 Pruning Process for CAGRA Optimization
Pruning Process for CAGRA Optimization
- Merging: After pruning the forward graph based on path significance, edges are inverted and merged. Specifically, half of the edges are selected from both the forward and reverse graphs to create the final optimized CAGRA graph.
This detailed approach to both constructing and optimizing the graph ensures CAGRA’s efficiency and effectiveness in vector search operations, leveraging the unique capabilities of GPUs while addressing the challenges inherent in graph-based search algorithms.
Searching with CAGRA
The CAGRA search mechanism employs a methodical approach using a fixed-size ordered priority queue for efficient graph navigation. This detailed process is outlined through a series of steps within a structured framework:
CAGRA Search Framework
CAGRA operates with a sequential memory buffer comprising an internal top-M list and a candidate list. The internal top-M list acts as a priority queue, with its length set to M (where M ≥ k), ensuring it can store the most relevant results up to the desired number of nearest neighbors, k. The candidate list’s size is determined by p × d, with p representing the number of source nodes explored in each iteration and d indicating the graph’s degree. Each element within these lists pairs a node index with the distance to the query, enabling efficient search management.
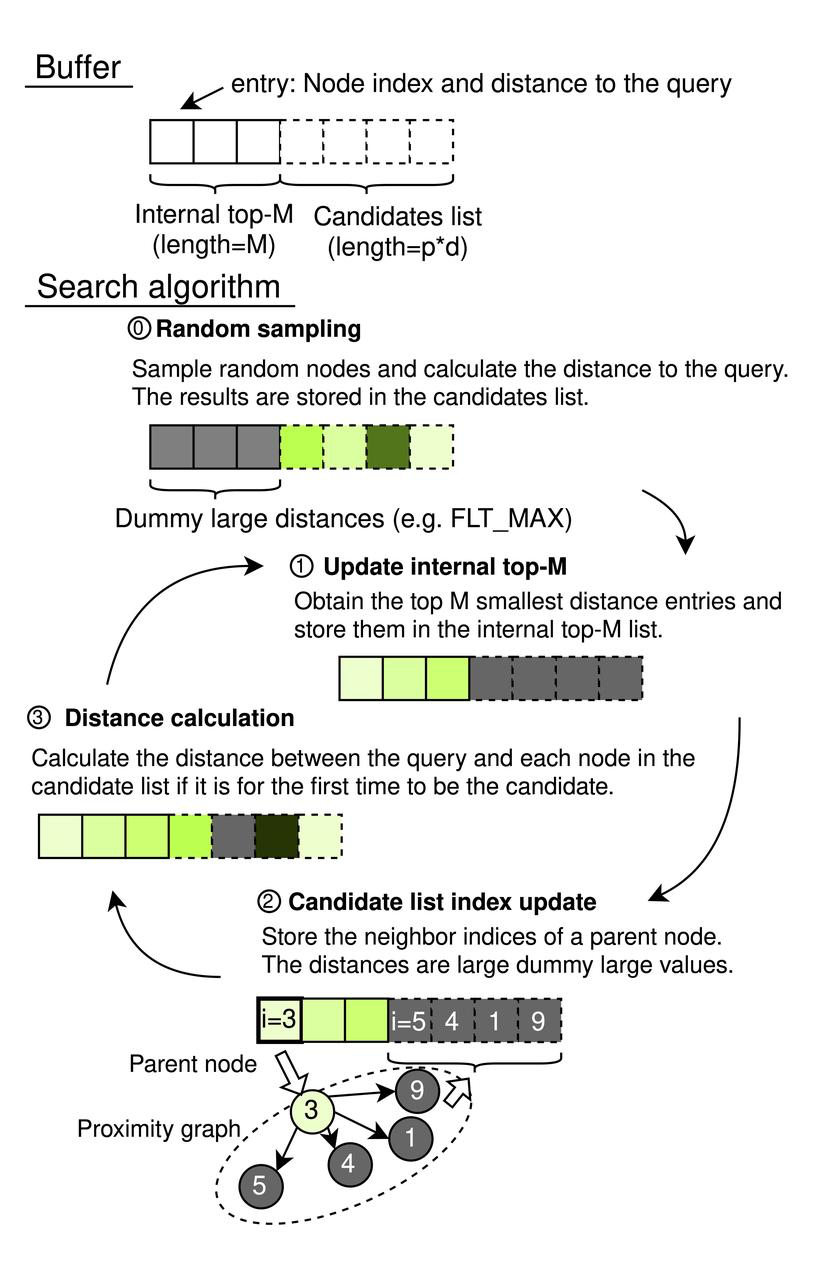 CAGRA Search Process
CAGRA Search Process
Search Process Steps
- Random Sampling (Initialization)
- Utilizes a pseudo-random generator to select p × d random node indices, calculating the distance between each node and the query.
- Results populate the candidate list, while the internal top-M list initializes with virtual entries (set to FLT_MAX) to avoid influencing initial sorting outcomes.
Internal Top-M List Update: Select the top-M nodes based on the smallest distances across the entire buffer for inclusion in the internal top-M list.
Candidate List Index Update (Graph Traversal):
- Identifies all neighboring nodes of the top p nodes from the internal top-M list, excluding previously used nodes via a hash-table filter.
- Adds these neighbors to the candidate list without recalculating distances at this stage.
- Distance Calculation:
- Performs distance calculations for nodes newly appearing in the candidate list, avoiding redundant computations for nodes evaluated in previous iterations.
- Ensures nodes are only added to the top-M list if their distances justify their relevance, based on whether they are sufficiently small to belong or too large to be considered.
The algorithm iteratively processes these steps, cycling through all nodes in the internal top-M list until they've all served as starting points for the search. The search concludes by extracting the top k entries from the internal top-M list, delivering the Approximate Nearest Neighbor Search (ANNS) results.
Performance
The decision to leverage GPU indexes was primarily motivated by performance considerations. We undertook a comprehensive evaluation of Milvus’ performance utilizing an open-source vector database benchmark tool, focusing on comparisons among HNSW, GPU-based IVFFLAT, and CAGRA indexes.
Benchmarking Setup
For a realistic assessment, our benchmarks were conducted on AWS-hosted machines equipped with NVIDIA T4 and A10G GPUs, ensuring the test environments reflected commonly available resources. The selected machines were comparably priced, providing a level playing field for performance evaluation. All tests aimed to achieve top100@98% recall, utilizing an AWS m6i.4xlarge instance (16C64G) as the client.
 Basic Info for Selected Machine
Basic Info for Selected Machine
Performance Insights
Small-Batch Performance:
In situations with small search batches (batch size of 1), where GPUs are generally underutilized, CAGRA significantly outperformed its counterparts. Our tests revealed that CAGRA could deliver nearly 10 times the performance of traditional methods in these conditions.
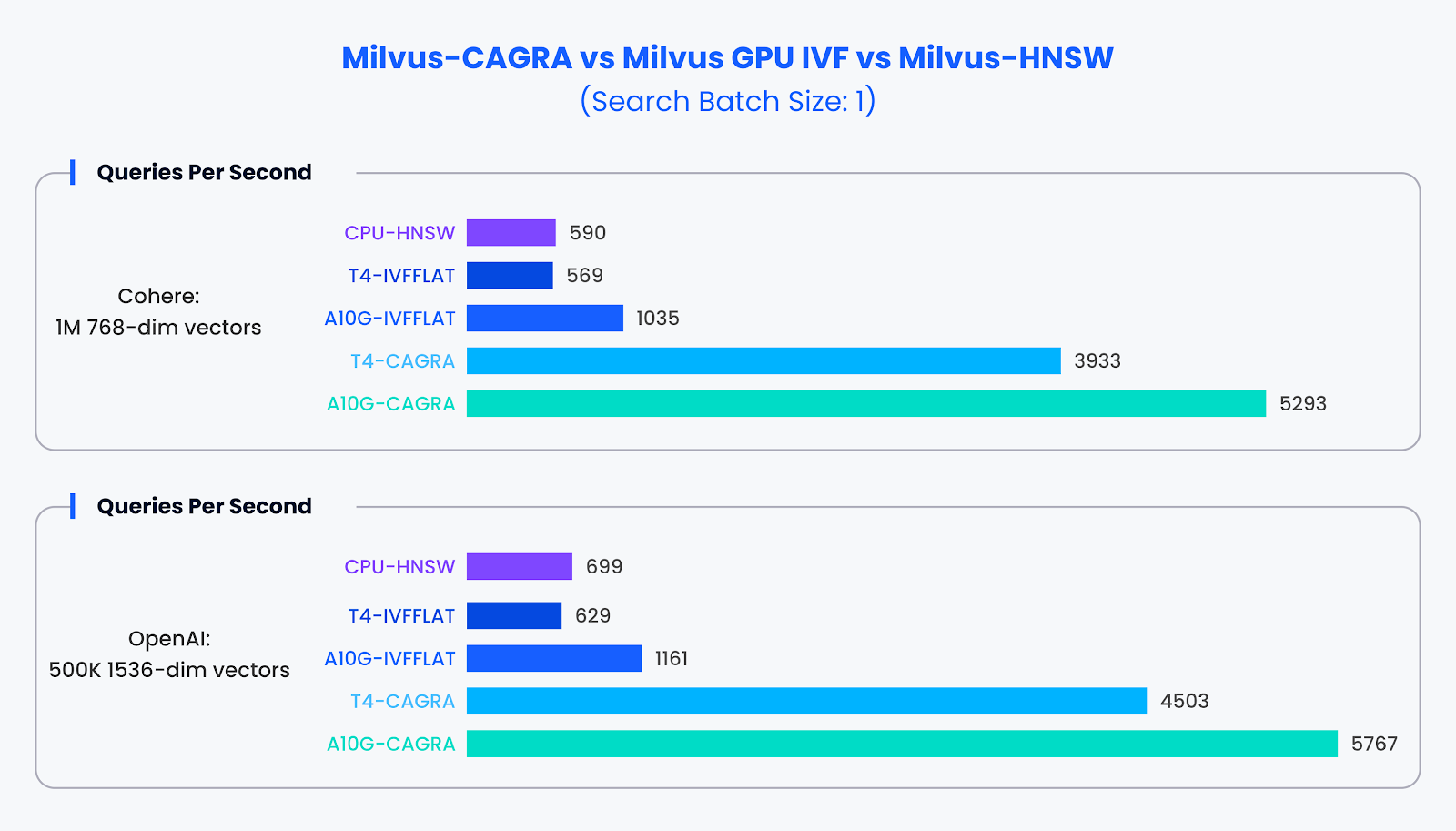 Performance Comparison for Small-Batch Data Set
Performance Comparison for Small-Batch Data Set
Large-Batch Performance:
When examining larger search batches (sizes of 10 and 100), CAGRA’s advantage became even more pronounced. Against HNSW, CAGRA showcased a dramatic performance increase, improving search efficiency by tens of times.
 Performance Comparison for Large-Batch Data Set
Performance Comparison for Large-Batch Data Set
Index Building Efficiency:
Beyond search capabilities, CAGRA’s proficiency extends to index building. With GPU acceleration, CAGRA demonstrated the ability to construct indexes approximately 10 times faster than alternative methods.
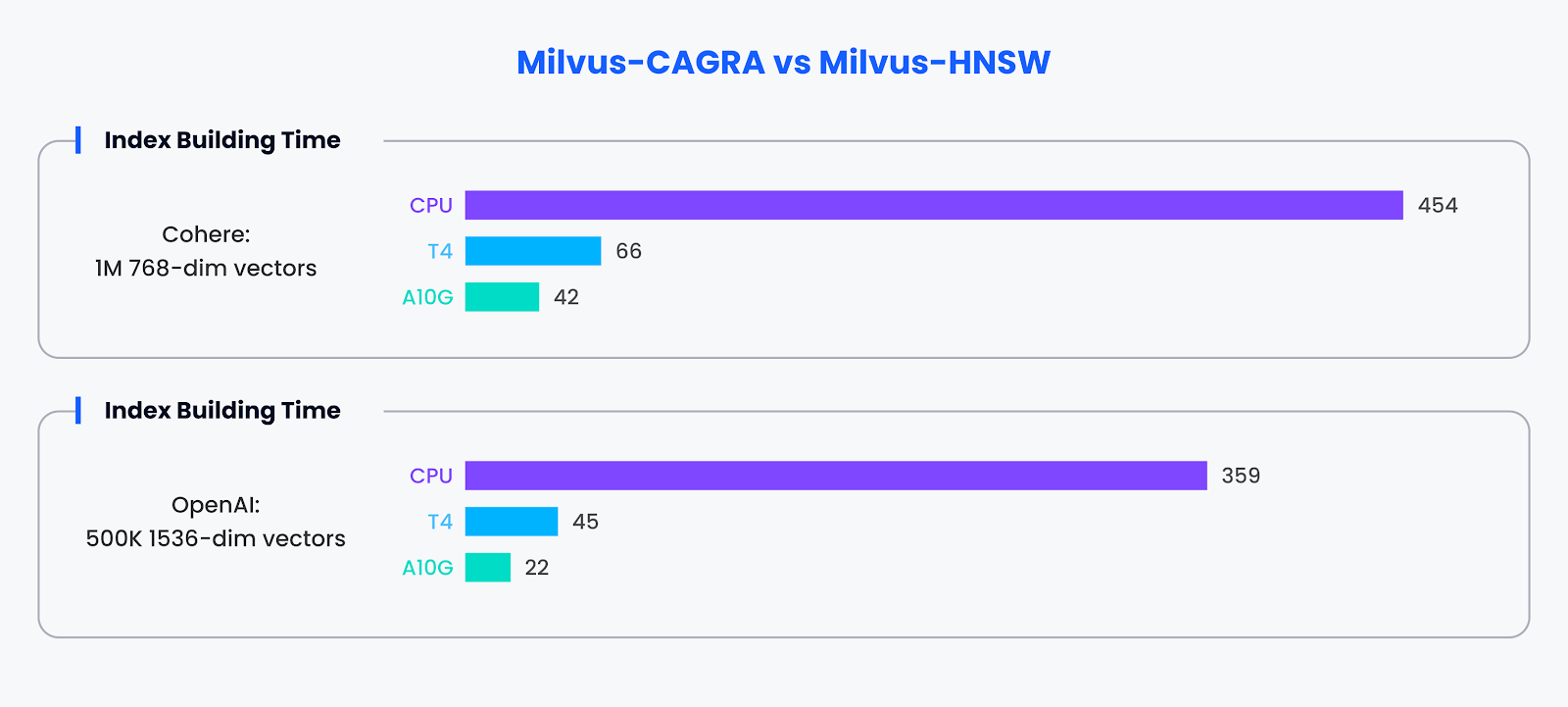 Performance Comparison for Index Building
Performance Comparison for Index Building
The benchmark results underscore the substantial performance benefits of adopting GPU-accelerated indexes like CAGRA in Milvus. Not only does it excel in accelerating search tasks across batch sizes, but it also significantly enhances index construction speed, affirming the value of GPUs in optimizing vector database performance.
What’s next?
CAGRA marks a significant leap forward in our quest to redefine the boundaries of vector search, showcasing the potential of GPU-based search to tackle the most demanding production challenges. As we move forward, Milvus is set on exploring deeper into the aspects of high recall, low latency, cost efficiency, and scalability in vector search. Our commitment extends beyond current achievements to embrace more flexible data management, enriched search capabilities, and breakthrough performance optimizations.
This vision drives us to innovate continually, ensuring that Milvus leads and pioneers the future of accelerated search for unstructured data. By pushing the limits of what's possible today, we aim to unlock new possibilities for tomorrow, making vector search more powerful, efficient, and accessible.
 Practical Tips and Tricks for Developers Using Vector Databases.png
Not sure which Index to choose for your solution? We have a blog that helps you make the right choice!
Practical Tips and Tricks for Developers Using Vector Databases.png
Not sure which Index to choose for your solution? We have a blog that helps you make the right choice!

Keep Reading

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.