




Running Llama 3, Mixtral, and GPT-4o
There are so many different ways to run the G-Generation part of RAG! Today I’ll show a few ways to run some of the hottest contenders in this space: Llama 3 from Meta, Mixtral from Mistral, and the recently announced GPT-4o from OpenAI.
As we can see from the LMSYS Leaderboard below, the gap (in light blue) between closed-source models and open-source models just took a widening hit this week with OpenAI’s new announcement.
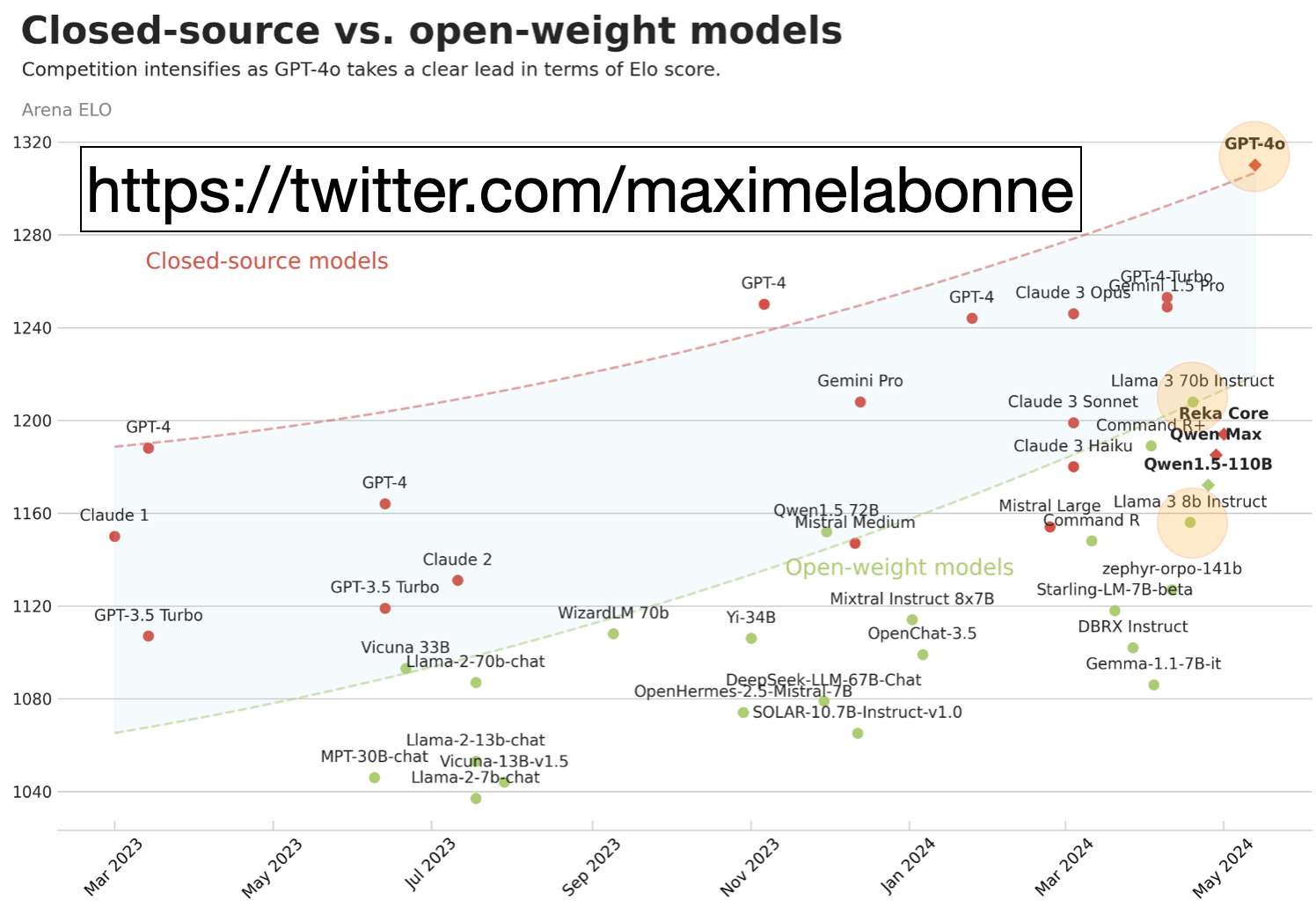 closed-source vs open
closed-source vs open
Image source: https://twitter.com/maximelabonne based on https://chat.lmsys.org/?leaderboard.
Outline for this blog:
The fastest ways to run open-source Llama 3 or Mixtral
Locally with Ollama
Anyscale endpoints
OctoAI endpoint
Groq endpoint
Run the latest gpt-4o from OpenAI
Evaluate answers: GPT-4o, Llama 3, Mixtral
Let’s get started!
Run Llama 3 Locally using Ollama
First, run RAG the usual way, up to the last step, where you generate the answer, the G-part of RAG. We have many tutorials for getting started with RAG, including this one in Python.
To run Llama 3 locally using Ollama.
Follow the instructions to install ollama and pull a model.
That page says
ollama run llama3will by default pull the latest "instruct" model, which is fine-tuned for chat/dialogue use cases AND fits on your computer. Run that command.For Python,
pip install ollama.In your RAG Python code, define a Prompt and a Question, and invoke the API call to your locally installed Llama 3 model.
In my case, I have an M2 16GB laptop, so the downloaded Ollama model is the highest quantized gguf-compiled version of Llama3-8B. That is, a very small version of Llama 3 is now installed on my laptop!
# Separate all the context together by space, reverse order.
# See “Lost in the middle” arxiv.org paper.
contexts_combined = ' '.join(reversed(contexts))
source_combined = ' '.join(reversed(sources))
# Define a Prompt.
SYSTEM_PROMPT = f"""Given the provided Context, your task is to
understand the content and accurately answer the question based
on the information available in the context.
Provide a complete, clear, concise, relevant response in fewer
than 4 sentences and cite the unique Sources.
Answer: The answer to the question.
Sources: {source_combined}
Context: {contexts_combined}
"""
# Send the Question and Prompt to local! llama 3 chat.
import ollama
start_time = time.time()
response = ollama.chat(
messages=[
{"role": "system", "content": SYSTEM_PROMPT,},
{"role": "user", "content": f"question: {SAMPLE_QUESTION}",}
],
model='llama3',
stream=False,
options={"temperature": TEMPERATURE, "seed": RANDOM_SEED,
"top_p": TOP_P,
# "max_tokens": MAX_TOKENS, # not recognized
"frequency_penalty": FREQUENCY_PENALTY}
)
ollama_llama3_time = time.time() - start_time
pprint.pprint(response['message']['content'].replace('\n', ' '))
print(f"ollama_llama3_time: {format(ollama_llama3_time, '.2f')} seconds")

The answer looks pretty good; I see three parameters, but only the citation looks garbled. The local model took 13 seconds to run inference on my laptop, but the cost was free.
Run Llama 3 from Anyscale endpoints
To run Llama 3 inference from Anyscale endpoints:
Follow the instructions on the Anyscale endpoints github page to install the command line and then install the plugin.
Get your Anysclae endpoint API token and update your environment variables.
For Python,
pip install openai.Read about the Llama 3 model downloaded from HuggingFace and invoke it using the OpenAI API. I used the default Llama 3 on Anyscale playground, which was a 70B-Instruct model.
import openai
LLM_NAME = "meta-llama/Llama-3-70b-chat-hf"
anyscale_client = openai.OpenAI(
base_url = "https://api.endpoints.anyscale.com/v1",
api_key=os.environ.get("ANYSCALE_ENPOINT_KEY"),
)
start_time = time.time()
response = anyscale_client.chat.completions.create(
messages=[
{"role": "system", "content": SYSTEM_PROMPT,},
{"role": "user", "content": f"question: {SAMPLE_QUESTION}",}
],
model=LLM_NAME,
temperature=TEMPERATURE,
seed=RANDOM_SEED,
frequency_penalty=FREQUENCY_PENALTY,
top_p=TOP_P,
max_tokens=MAX_TOKENS,
)
llama3_anyscale_endpoints_time = time.time() - start_time
# Print the response.
pprint.pprint(response.choices[0].message.content.replace('\n', ' '))
print(f"llama3_anyscale_endpoints_time: {format(llama3_anyscale_endpoints_time, '.2f')} seconds")
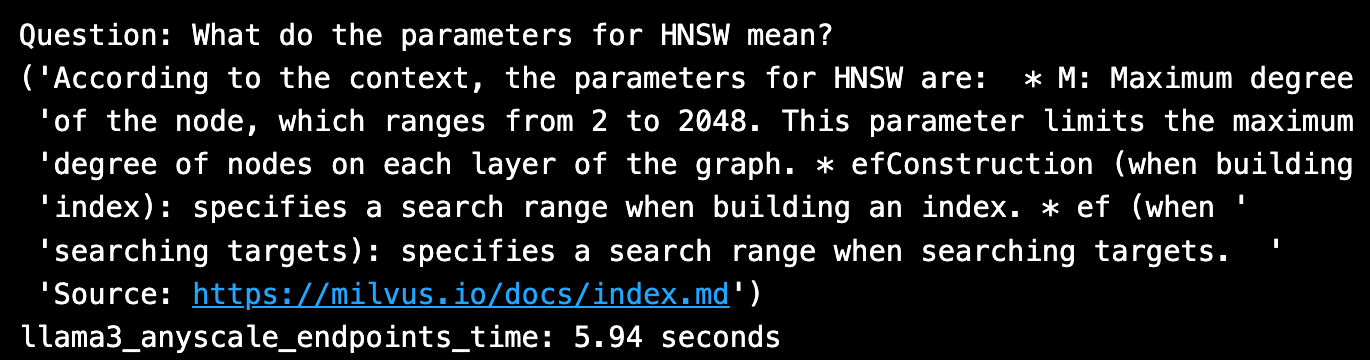
The answer looks good, including a perfect citation. The HuggingFace Llama 3 70B took ~6 seconds to invoke from Anyscale endpoints.
Run Llama 3 from OctoAI Endpoints
To run Llama 3 inference from OctoAI endpoints:
Go to https://octoai.cloud/text, choose the Llama 3 8B model, click on the model link and you’ll see sample code.
Get your OctoAI endpoint API token and update your environment variables.
For Python,
pip install octoai.Read about the Llama 3 8B model downloaded from Meta and invoke it.
from octoai.text_gen import ChatMessage
from octoai.client import OctoAI
LLM_NAME = "meta-llama-3-70b-instruct"
octoai_client = OctoAI(
api_key=os.environ.get("OCTOAI_TOKEN"),
)
start_time = time.time()
response = octoai_client.text_gen.create_chat_completion(
messages=[
ChatMessage(
content=SYSTEM_PROMPT,
role="system"
),
ChatMessage(
content=SAMPLE_QUESTION,
role="user"
)
],
model=LLM_NAME,
temperature=TEMPERATURE,
# seed=RANDOM_SEED, # not recognized
frequency_penalty=FREQUENCY_PENALTY,
top_p=TOP_P,
max_tokens=MAX_TOKENS,
)
llama3_octai_endpoints_time = time.time() - start_time
# Print the response.
pprint.pprint(response.choices[0].message.content.replace('\n', ' '))
print(f"llama3_octai_endpoints_time: {format(llama3_octai_endpoints_time, '.2f')} seconds")

The answer looks good and the citation is perfect. The Llama 3 70B took under ~4 seconds to invoke from OctoAI endpoints.
Run Llama 3 from Groq LPU endpoints
To run Llama 3 inference from Groq endpoints:
Go to console.groq.com and follow the instructions.
Get your Groq endpoint API token and update your environment variables.
For Python,
pip install groq.Read about the Llama 3 8B model downloaded from HuggingFace and invoke it.
from groq import Groq
LLM_NAME = "llama3-70b-8192"
groq_client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
start_time = time.time()
response = groq_client.chat.completions.create(
messages=[
{"role": "system", "content": SYSTEM_PROMPT,},
{"role": "user", "content": f"question: {SAMPLE_QUESTION}",}
],
model=LLM_NAME,
temperature=TEMPERATURE,
seed=RANDOM_SEED,
frequency_penalty=FREQUENCY_PENALTY,
top_p=TOP_P,
max_tokens=MAX_TOKENS,
)
llama3_groq_endpoints_time = time.time() - start_time
# Print the response.
pprint.pprint(response.choices[0].message.content.replace('\n', ' '))
print(f"llama3_groq_endpoints_time: {format(llama3_groq_endpoints_time, '.2f')} seconds")

The answer looks slightly more succinct, and the citation is perfect. The Llama 3 20B took ~1 second to invoke from Groq LPU endpoints, which is the fastest inference so far!
Note - to run Mixtral, follow all the same steps, just change the LLM_NAME to the name used by each Endpoint Platform for the Mixtral model.
Run GPT-4o from OpenAI
To run the latest GPT-4o inference from OpenAI:
Get your OpenAI API token and update your environment variables.
Follow instructions for how to call the new model.
For Python,
pip install --upgrade openai --quiet.Read about the new GPT-4o model and invoke it.
import openai, pprint
from openai import OpenAI
LLM_NAME = "gpt-4o" # "gpt-3.5-turbo"
openai_client = OpenAI(
# This is the default and can be omitted
api_key=os.environ.get("OPENAI_API_KEY"),
)
start_time = time.time()
response = openai_client.chat.completions.create(
messages=[
{"role": "system", "content": SYSTEM_PROMPT,},
{"role": "user", "content": f"question: {SAMPLE_QUESTION}",}
],
model=LLM_NAME,
temperature=TEMPERATURE,
seed=RANDOM_SEED,
frequency_penalty=FREQUENCY_PENALTY,
top_p=TOP_P,
max_tokens=MAX_TOKENS,
)
chatgpt_4o_turbo_time = time.time() - start_time
# Print the question and answer along with grounding sources and citations.
print(f"Question: {SAMPLE_QUESTION}")
for i, choice in enumerate(response.choices, 1):
message = choice.message.content.replace('\n', '')
pprint.pprint(f"Answer: {message}")
print(f"chatgpt_4o_turbo_time: {format(chatgpt_4o_turbo_time, '.5f')}")
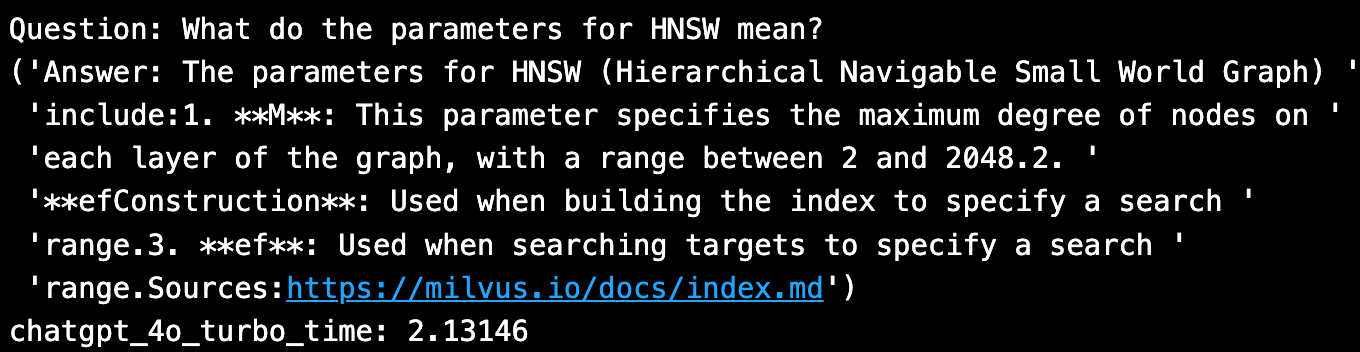
The new GPT-4o model looks good and it includes a grounding source citation. It took 2 seconds to run inference.
Quick Answer Evaluation using Ragas
I explain in this blog about how to use open source Ragas to evaluate RAG systems. I’m only using one Q&A below. A more realistic evaluation would use ~20 questions.
import os, sys
import pandas as pd
import numpy as np
import ragas, datasets
from langchain_community.embeddings import HuggingFaceEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
from ragas.metrics import (
# context_recall,
# context_precision,
# faithfulness,
answer_relevancy,
answer_similarity,
answer_correctness
)
# Read ground truth answers from file.
eval_df = pd.read_csv(file_path, header=0, skip_blank_lines=True)
# Possible LLM model choices to evaluate:
# openai gpt-4o = 'Custom_RAG_answer'
LLM_TO_EVALUATE = 'Custom_RAG_answer'
# LLM_TO_EVALUATE = 'llama3_ollama_answer'
# LLM_TO_EVALUATE = 'llama3_anyscale_answer'
# LLM_TO_EVALUATE = 'llama3_octoai_answer'
# LLM_TO_EVALUATE = 'llama3_groq_answer'
# LLM_TO_EVALUATE = 'mixtral_8x7b_anyscale_answer'
CONTEXT_TO_EVALUATE='Custom_RAG_context'
eval_metrics=[
answer_relevancy,
answer_similarity,
answer_correctness,]
metrics = ['answer_relevancy', 'answer_similarity', 'answer_correctness']
# Change the default llm-as-critic, to save $.
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = ragas.llms.llm_factory(model=LLM_NAME)
# Change the default embeddings to HuggingFace models.
EMB_NAME = "BAAI/bge-large-en-v1.5"
lc_embeddings = HuggingFaceEmbeddings(model_name=EMB_NAME)
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Change each metric.
for metric in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Execute the evaluation.
ragas_result, score = _eval_ragas.evaluate_ragas_model(
eval_df, eval_metrics, LLM_TO_EVALUATE,
CONTEXT_TO_EVALUATE, EVALUATE_WHAT)
# Display the results.
print(f"Using {eval_df.shape[0]} eval questions, Mean Score = {score}")
display(ragas_result.head())

Below is a table summarizing the results.
| Model endpoint | Answer | Latency (seconds) | Cost | Ragas Answer Score |
Ollama Llama 3 | According to the provided context and sources [1, 65535], in Hierarchical Navigable Small World Graph (HNSW), there are two main parameters: * `M`: Maximum degree of nodes on each layer of the graph. It ranges from 2 to 2048. * `ef` or `efConstruction`: This parameter specifies a search range, which can be used during index construction or target searching. These parameters aim to improve performance and control the trade-off between recall rate (improved by increasing ef) and search time (increased with larger M values). | 13.74 | Free | 0.76 |
Anyscale endpoints Llama 3 | `According to the context, the parameters for HNSW are: * M: Maximum degree of the node, which ranges from 2 to 2048. This parameter limits the maximum degree of nodes on each layer of the graph. * efConstruction (when building index): specifies a search range when building an index. * ef (when searching targets): specifies a search range when searching targets. | |||
Source:[ https://milvus.io/docs/index.md](https://milvus.io/docs/index.md)'` | 5.94 | Free playground | 0.80 | |
Anyscale Mixtral | `The parameter M for HNSW refers to the maximum degree of the node, which is the maximum number of connections a node can have in the graph structure. It ranges from 2 to 2048. Additionally, efConstruction and ef are parameters used to specify the search range during index building and target searching, respectively. | |||
Sources: 1.[ https://milvus.io/docs/index.md](https://milvus.io/docs/index.md) 2. [https://milvus.io/docs/index.md](https://milvus.io/docs/index.md)'` | 3.57 | Free playground | 0.79 | |
OctoAI Llama 3 | `According to the provided context, the parameters for HNSW (Hierarchical Navigable Small World Graph) are: * M: Maximum degree of the node, which ranges from 2 to 2048. This parameter limits the maximum degree of nodes on each layer of the graph. * efConstruction: A parameter used when building an index to specify a search range. * ef: A parameter used when searching targets to specify a search range. | |||
Source:[ https://milvus.io/docs/index.md](https://milvus.io/docs/index.md) ` | 4.43 | $0.15 per million tokens | 0.73 | |
Groq Llama 3 | `According to the provided context, the parameters for HNSW are: * M: Maximum degree of the node, which ranges from 2 to 2048. * efConstruction: A parameter used when building the index to specify a search range. * ef: A parameter used when searching targets to specify a search range. | |||
Source: [https://milvus.io/docs/index.md`](https://milvus.io/docs/index.md) | 1.21 | `Free | ||
| beta` | 0.79 | |||
Openai gpt-4o | The parameters for HNSW are as follows:``- M: Maximum degree of the node, limiting the connections each node can have in the graph. Range is [2, 2048].``- efConstruction: Parameter used during index building to specify a search range.``- ef: Parameter used when searching for targets to specify a search range.``Sources:https://milvus.io/docs/index.md | 2.13 | `$5/M input | |
| $15/M output` | 0.803 |
Source: Author’s code and https://console.anyscale.com/v2/playground, https://console.groq.com/playground?model=llama3-70b-8192, https://octoai.cloud/text?selectedTags=Chat, https://openai.com/api/pricing/.
Conclusion
Today, we have many options for models and inference endpoints to choose from for the G-Generation part of RAG! All the endpoints tried in this blog have varying answer quality (as rated by a GPT-critic), latencies, and costs to consider.

Keep Reading

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.