




Local Agentic RAG with LangGraph and Llama 3.2
Updated September 25, 2024 with Llama 3.2
In this post, we’ll demonstrate how to build agents that can intelligently call tools to perform specific tasks using LangGraph and Llama 3, while also leveraging Milvus Lite for efficient data storage. These agents bring together several important capabilities, including planning, memory, and tool-calling to improve the performance of retrieval-augmented generation (RAG) systems.
Introduction to LangGraph and Llama 3
LangGraph is an extension of LangChain, designed to build robust, stateful multi-actor applications with large language models (LLMs). While LangChain offers a framework for integrating LLMs into various workflows, LangGraph advances this by modeling tasks as nodes and edges in a graph structure. This allows for more complex control flows, enabling LLMs to plan, learn, and adapt to the task at hand. LangGraph provides the flexibility to implement systems where agents use multi-step reasoning, dynamically selecting the right tools for each step. Additionally, LangGraph can be used to build reliable RAG agents that follow a user-defined control flow every time they are run, ensuring consistency and predictability in their responses.
LangGraph also allows for more intricate, agent-like behaviors by enabling the incorporation of cycles in workflows. These cycles allow the agents to loop back to previous steps if necessary, enabling dynamic adjustments to the actions they take based on new information or reflections. This results in more intelligent agents capable of refining their reasoning over time, creating more robust and adaptive RAG systems.
Llama 3, an open-source large language model, serves as the agent memory core reasoning engine. When combined with LangGraph, Llama 3 can analyze input, decide which actions to take, and invoke the necessary tools. Rather than just generating text, Llama 3—powered by LangGraph—enables agents to plan, execute, and reflect on their actions, making them more intelligent and capable.
In this post, we will show how to create a langgraph agentic rag system using LangGraph with Llama 3 and Milvus Lite. This setup allows you to run everything locally without needing external servers, making it ideal for privacy-conscious users and offline environments.
Building a Tool-Calling Agent with LangGraph
LangGraph’s workflow is built around the concept of nodes, where each node represents a specific task or tool. These tasks can include calling LLMs, retrieving information, or invoking custom tools. In a tool-calling agent, two key components are at play:
LLM Node: This node decides which tool to use based on the user’s input. It analyzes the query and outputs the tool name and relevant arguments.
Tool Node: This node takes the tool name and arguments from the LLM node, invokes the appropriate tool, and returns the result to the LLM.
By structuring tasks (like web search) as nodes and edges, LangGraph enables the creation of intelligent, multi-step workflows where LLMs can reason about user question about which actions to take, which tools to use, which answers question, and how to refine their answers. Milvus Lite plays a key role here by providing efficient storage and retrieval of vectorized data locally.
How Milvus Lite Enhances Local Tool-Calling Agents
Milvus Lite is a lightweight, local version of Milvus that doesn’t require Docker or Kubernetes to operate. This makes it easy to run Milvus on your laptop, Jupyter notebook, or even in Google Colab. The local deployment of Milvus Lite allows you to store vectors generated from different web sources or documents without needing to rely on external databases. It integrates seamlessly with LangGraph to handle vector searches, making it an ideal solution for local RAG systems.
For example, Milvus Lite can be used to store indexed documents that are retrieved by the agent during a web search. When the agent queries for information, the vector database enables fast, accurate retrieval of relevant documents.
Creating a Local RAG System with LangGraph and Llama 3
We use LangGraph to build a custom local Llama 3.2 powered RAG agent that uses different approaches:
We implement each approach as a control flow in LangGraph:
Routing (Adaptive RAG) - Allows the agent to intelligently route user queries to the most suitable retrieval method based on the question itself. The LLM node analyzes the query, and based on keywords or question structure, it can route it to specific retrieval nodes.
Example 1: Questions requiring factual answers might be routed to a document retrieval node searching a pre-indexed knowledge base (powered by Milvus).
Example 2: Open-ended, creative prompts might be directed to the LLM for generation tasks.
Fallback (Corrective RAG) - Ensures the agent has a backup plan if its initial retrieval methods fail to provide relevant results. Suppose the initial retrieval nodes (e.g., document retrieval from the knowledge base) don't return satisfactory answers (based on relevance score or confidence thresholds). In that case, the agent falls back to a web search node.
- The web search node can utilize external search APIs.
Self-correction (Self-RAG) - Enables the agent to identify and fix its own errors or misleading outputs. The LLM node generates an answer, and then it's routed to another node for evaluation. This evaluation node can use various techniques:
Reflection: The agent can check its answer against the original query to see if it addresses all aspects.
Confidence Score Analysis: The LLM can assign a confidence score to its answer. If the score is below a certain threshold, the answer is routed back to the LLM for revision.
General ideas for Agents
Reflection— The self-correction mechanism is a form of reflection where the LangGraph agent reflects on its retrieval and generations. It loops information back for evaluation and allows the agent to exhibit a form of rudimentary reflection, improving its output quality over time.
Planning— The control flow laid out in the graph is a form of planning, the agent doesn't just react to the query; it lays out a step-by-step process to retrieve or generate the best answer.
Tool use— The LangGraph agent’s control flow incorporates specific nodes for various tools. These can include retrieval nodes for the knowledge base (e.g., Milvus), demonstrating its ability to tap into a vast pool of information, and web search nodes for external information.
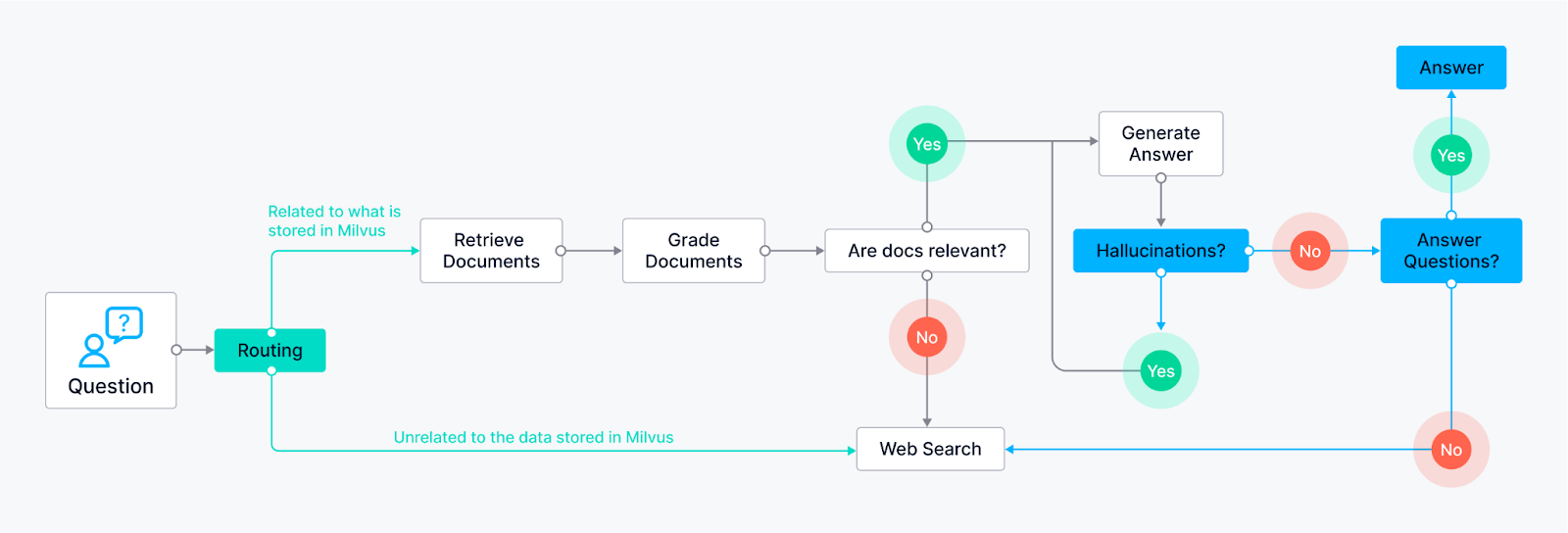
Examples of Agents
To showcase the capabilities of our LLM agents, let's look into two key components: the Hallucination Grader and the Answer Grader. While the full code is available at the bottom of this post, these snippets will provide a better understanding of how these agents work within the LangChain framework.
Hallucination Grader
The Hallucination Grader tries to fix a common challenge with LLMs: hallucinations, where the model generates answers that sound plausible but lack factual grounding. This agent acts as a fact-checker, assessing if the LLM's answer aligns with a provided set of documents retrieved from Milvus.
### Hallucination Grader
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether
an answer is grounded in / supported by a set of facts. Give a binary score 'yes' or 'no' score to indicate
whether the answer is grounded in / supported by a set of facts. Provide the binary score as a JSON with a
single key 'score' and no preamble or explanation.
Here are the facts:
{documents}
Here is the answer:
{generation}
""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
Answer Grader
Following the Hallucination Grader, another agent steps in. This agent checks another crucial aspect: ensuring the LLM's answer directly addresses the user's original question. It utilizes the same LLM but with a different prompt, specifically designed to evaluate the answer's relevance to the question.
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers questions.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
grade = score['score']
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question,"generation": generation})
grade = score['score']
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
You can see in the code above that we are checking the predictions by the LLM that we use as a classifier.
Compiling the LangGraph graph
This will compile all the agents that we defined and will make it possible to use different tools for your RAG system.
# Compile
app = workflow.compile()
# Test
from pprint import pprint
inputs = {"question": "What is prompt engineering?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
'Finished running: generate:'
('Prompt engineering is the process of communicating with Large Language '
'Models (LLMs) to steer their behavior towards desired outcomes without '
'updating the model weights. It focuses on alignment and model steerability, '
'requiring experimentation and heuristics due to varying effects among '
'models. The goal is to improve controllable text generation by optimizing '
'prompts for specific applications.')
Conclusion
In this blog post, we showed how to build a RAG system using agents with LangChain/ LangGraph, Llama 3.2, and Milvus. These agents make it possible for LLMs to have planning, memory, and different tool use capabilities, which can lead to more robust and informative responses.
Next Steps for Improvement
While the current implementation of the agentic RAG system is effective for local, single-agent workflows, there are several exciting directions for further improvement and innovation.
Multi-Agent Coordination: Currently, LangGraph is used to design single-agent systems that operate within a predefined control flow like a web search. However, a natural progression would be to extend this system to support multiple agents working in parallel or in coordination. In scenarios where a task requires specialized knowledge or multiple retrieval sources, agents can collaboratively process different parts of the task. For example, one agent could focus on retrieving factual information, while another handles creative tasks or user interaction, and a third evaluates the overall quality of the output. Such multi-agent systems would allow more complex operations, leading to higher efficiency and accuracy in handling diverse queries.
Real-Time Data** Updates:** Another potential improvement could be enabling agents to update their data sources in real-time. Currently, Milvus Lite serves as a static knowledge base; however, in dynamic domains, the information can quickly become outdated. Agents could be designed to continuously monitor and update their local vector store with fresh data from the web or other APIs, ensuring that the system’s outputs remain relevant and up-to-date. For example, if an agent is asked about the latest stock prices or breaking news, it could automatically fetch the most recent data, making the system far more adaptable and useful in fast-paced environments.
Enhanced Reflection and Self-Improvement: While the current reflection mechanism is useful, there is room for improvement in terms of self-correction. Future versions of the agent could incorporate more advanced techniques, such as reinforcement learning or continuous learning mechanisms, allowing the agent to learn from its past experiences and mistakes over time. By enabling the the agent memory work to improve its response quality iteratively, we could achieve a system that not only retrieves and generates high-quality answers but also refines its processes based on feedback.
By incorporating these next steps, we can significantly enhance the capabilities of agentic RAG systems, making them more flexible, adaptive, and effective in solving complex tasks across a variety of industries.
Feel free to check out the code available in the Milvus Bootcamp repository.
If you enjoyed this blog post showing how to build langgraph agentic rag, consider giving us a star on , and share your experiences with the community by joining our
This is inspired by the Github Repository from Meta with recipes for using Llama 3

Keep Reading

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.