




Function Calling with Ollama, Llama 3.2 and Milvus
Updated September 25 2024 with Llama 3.2
Function calling with LLMs is like giving your AI the power to connect with the world. By integrating your LLM with external tools such as user-defined functions or APIs, you can build applications that solve real-world problems.
In this blog post, we'll check how to integrate Llama 3.2 with external tools like Milvus and APIs to build powerful, context-aware applications.
Introduction to Function Calling
LLMs like GPT-4, Mistral Nemo, and Llama 3.2 can now detect when they need to call a function and then output JSON with arguments to call that function. This makes your AI applications more versatile and powerful.
Functional calling enables developers to create:
LLM-powered solutions for extracting and tagging data (e.g., extracting people’s names from a Wikipedia article)
applications that can help convert natural language to API calls or valid database queries
conversational knowledge retrieval engines that interact with a knowledge base
The tools
Ollama: Brings the power of LLMs to your laptop, simplifying local operation.
Milvus: Our go-to vector database for efficient data storage and retrieval.
Llama 3.2-3B: The upgraded version of the 3.1 model, it is multilingual and has a significantly longer context length of 128K, and can leverage tool use.
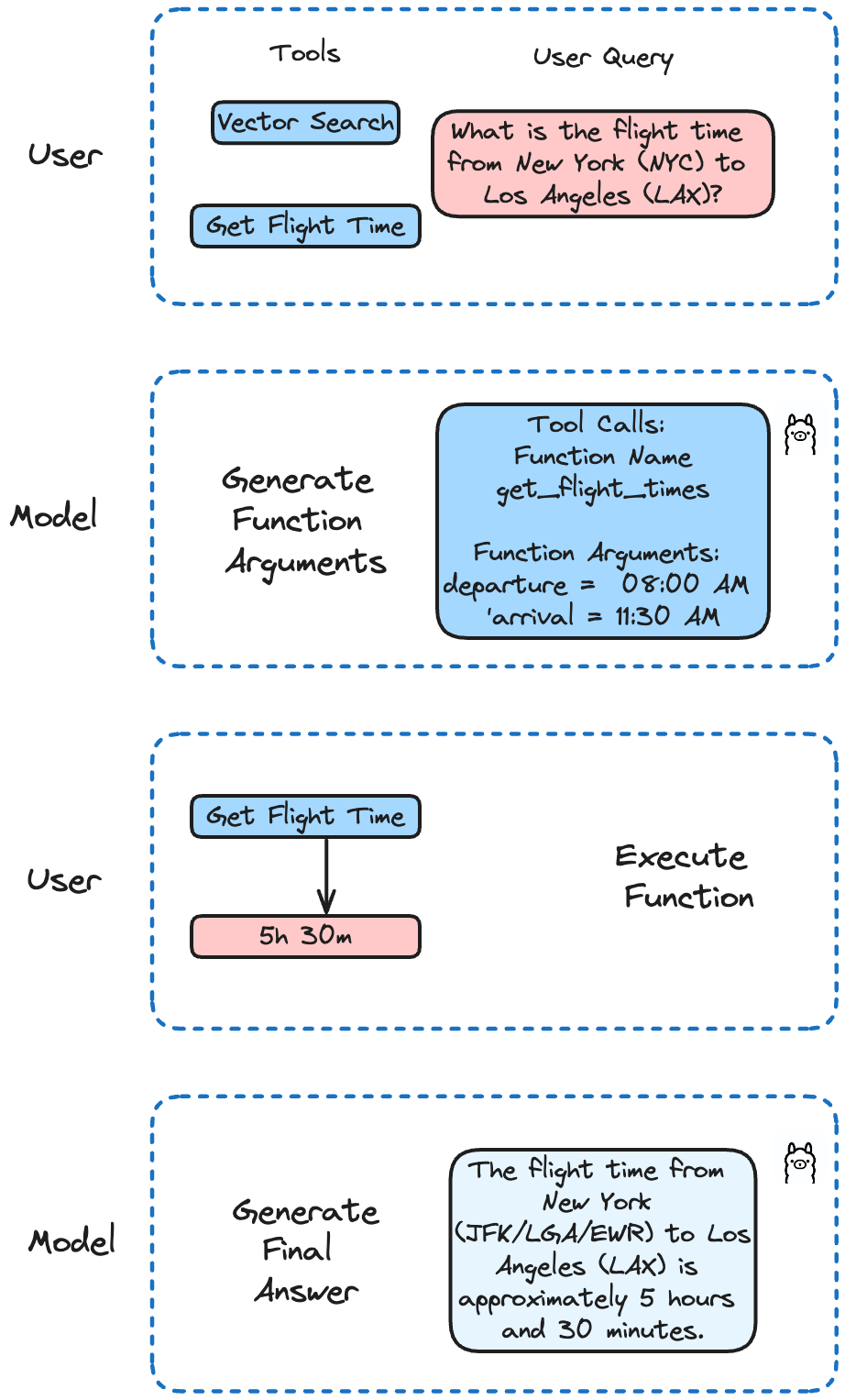
Using Llama 3.2 and Ollama
Llama 3.2 has been fine-tuned on function callings. It supports single, nested, and parallel function calling, as well as multi-turn function calling. This means your AI can handle complex tasks that involve multiple steps or parallel processes.
In our example, we'll implement different functions to simulate an API call to get flight times and perform searches in Milvus. Llama 3.2 will decide which function to call based on the user's query.
Install Dependencies
First, let's get everything set up. Download Llama 3.2 using Ollama:
ollama run llama3.2
This will download the model to your laptop, making it ready to use with Ollama. Next, install the necessary dependencies:
! pip install ollama openai "pymilvus[model]"
We're installing Milvus Lite with the model extension, which allows you to embed data using the models available in Milvus.
Insert Data into Milvus
Now, let's insert some data into Milvus. This is the data that Llama 3.2 will decide to search later if it thinks it's relevant!
Create and insert the data
from pymilvus import MilvusClient, model
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
vectors = embedding_fn.encode_documents(docs)
# The output vector has 768 dimensions, matching the collection that we just created.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# Each entity has id, vector representation, raw text, and a subject label.
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
print("Data has", len(data), "entities, each with fields: ", data[0].keys())
print("Vector dim:", len(data[0]["vector"]))
# Create a collection and insert the data
client = MilvusClient('./milvus_local.db')
client.create_collection(
collection_name="demo_collection",
dimension=768, # The vectors we will use in this demo has 768 dimensions
)
client.insert(collection_name="demo_collection", data=data)
You should then have 3 elements in your new collection.
Define the functions to be used
In this example, we're defining two functions. The first one simulates an API call to get flight times. The second one runs a search query in Milvus.
from pymilvus import model
import json
import ollama
embedding_fn = model.DefaultEmbeddingFunction()
# Simulates an API call to get flight times
# In a real application, this would fetch data from a live database or API
def get_flight_times(departure: str, arrival: str) -> str:
flights = {
'NYC-LAX': {'departure': '08:00 AM', 'arrival': '11:30 AM', 'duration': '5h 30m'},
'LAX-NYC': {'departure': '02:00 PM', 'arrival': '10:30 PM', 'duration': '5h 30m'},
'LHR-JFK': {'departure': '10:00 AM', 'arrival': '01:00 PM', 'duration': '8h 00m'},
'JFK-LHR': {'departure': '09:00 PM', 'arrival': '09:00 AM', 'duration': '7h 00m'},
'CDG-DXB': {'departure': '11:00 AM', 'arrival': '08:00 PM', 'duration': '6h 00m'},
'DXB-CDG': {'departure': '03:00 AM', 'arrival': '07:30 AM', 'duration': '7h 30m'},
}
key = f'{departure}-{arrival}'.upper()
return json.dumps(flights.get(key, {'error': 'Flight not found'}))
# Search data related to Artificial Intelligence in a vector database
def search_data_in_vector_db(query: str) -> str:
query_vectors = embedding_fn.encode_queries([query])
res = client.search(
collection_name="demo_collection",
data=query_vectors,
limit=2,
output_fields=["text", "subject"], # specifies fields to be returned
)
print(res)
return json.dumps(res)
Give the instructions to the LLM to be able to use those functions
Now, let's give the instructions to the LLM so it can use the functions we defined.
def run(model: str, question: str):
client = ollama.Client()
# Initialize conversation with a user query
messages = [{"role": "user", "content": question}]
# First API call: Send the query and function description to the model
response = client.chat(
model=model,
messages=messages,
tools=[
{
"type": "function",
"function": {
"name": "get_flight_times",
"description": "Get the flight times between two cities",
"parameters": {
"type": "object",
"properties": {
"departure": {
"type": "string",
"description": "The departure city (airport code)",
},
"arrival": {
"type": "string",
"description": "The arrival city (airport code)",
},
},
"required": ["departure", "arrival"],
},
},
},
{
"type": "function",
"function": {
"name": "search_data_in_vector_db",
"description": "Search about Artificial Intelligence data in a vector database",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query",
},
},
"required": ["query"],
},
},
},
],
)
# Add the model's response to the conversation history
messages.append(response["message"])
# Check if the model decided to use the provided function
if not response["message"].get("tool_calls"):
print("The model didn't use the function. Its response was:")
print(response["message"]["content"])
return
# Process function calls made by the model
if response["message"].get("tool_calls"):
available_functions = {
"get_flight_times": get_flight_times,
"search_data_in_vector_db": search_data_in_vector_db,
}
for tool in response["message"]["tool_calls"]:
function_to_call = available_functions[tool["function"]["name"]]
function_args = tool["function"]["arguments"]
function_response = function_to_call(**function_args)
# Add function response to the conversation
messages.append(
{
"role": "tool",
"content": function_response,
}
)
# Second API call: Get final response from the model
final_response = client.chat(model=model, messages=messages)
print(final_response["message"]["content"])
Example Usage
Let’s check if we can get the time for a specific flight:
question = "What is the flight time from New York (NYC) to Los Angeles (LAX)?"
run('llama3.2', question)
Which results in:
The flight time from New York (JFK/LGA/EWR) to Los Angeles (LAX) is approximately 5 hours and 30 minutes. However, please note that this time may vary depending on the airline, flight schedule, and any potential layovers or delays. It's always best to check with your airline for the most up-to-date and accurate flight information.
Now, let’s see if Llama 3.2 can do a vector search using Milvus.
question = "When was Artificial Intelligence founded?"
run("llama3.2", question)
Which returns a Milvus Search:
data: ["[{'id': 0, 'distance': 0.5738513469696045, 'entity': {'text': 'Artificial intelligence was founded as an academic discipline in 1956.', 'subject': 'history'}}, {'id': 1, 'distance': 0.4090226888656616, 'entity': {'text': 'Alan Turing was the first person to conduct substantial research in AI.', 'subject': 'history'}}]"]
Artificial Intelligence was founded as an academic discipline in 1956.
Conclusion
Function calling with LLMs opens up a world of possibilities. By integrating Llama 3.2 with external tools like Milvus and APIs, you can build powerful, context-aware applications that cater to specific use cases and practical problems.
Feel free to check out Milvus, the code on Github, and share your experiences with the community by joining our Discord

Keep Reading

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.